当我们在终端运行 vite dev,Vite 启动开发服务器的首个关键步骤就是解析配置。本文将深入剖析 Vite 加载配置文件的三种模式。
loadConfigFromFile 的完整流程
loadConfigFromFile 是配置文件加载的核心函数,其完整流程如下:
- 确定配置文件路径(自动查找或使用
--config 指定的路径)。
- 根据文件后缀和
package.json 中的 type 字段判断模块格式(是否为 ESM)。
- 根据
configLoader加载器配置来加载配置文件和转换代码。
-
bundle模式,调用 bundleConfigFile 使用 rolldown 打包配置文件,获取转换后的代码和依赖列表。调用 loadConfigFromBundledFile 将打包后的代码转成配置对象。
-
runner模式,使用 Vite 的 ModuleRunner 动态转换任何文件。它的核心机制是利用 RunnableDevEnvironment 提供的 runner.import 函数,在独立的执行环境中加载并运行模块
-
native模式,利用原生动态引入。
- 如果用户导出的是函数,则调用该函数传入
configEnv(包含 command、mode 等参数),获取最终配置对象。
- 返回配置对象、配置文件路径以及依赖列表
dependencies
let { configFile } = config
if (configFile !== false) {
// 从文件加载配置
const loadResult = await loadConfigFromFile(
configEnv,
configFile,
config.root,
config.logLevel,
config.customLogger,
config.configLoader,
)
if (loadResult) {
config = mergeConfig(loadResult.config, config)
configFile = loadResult.path
configFileDependencies = loadResult.dependencies
}
}
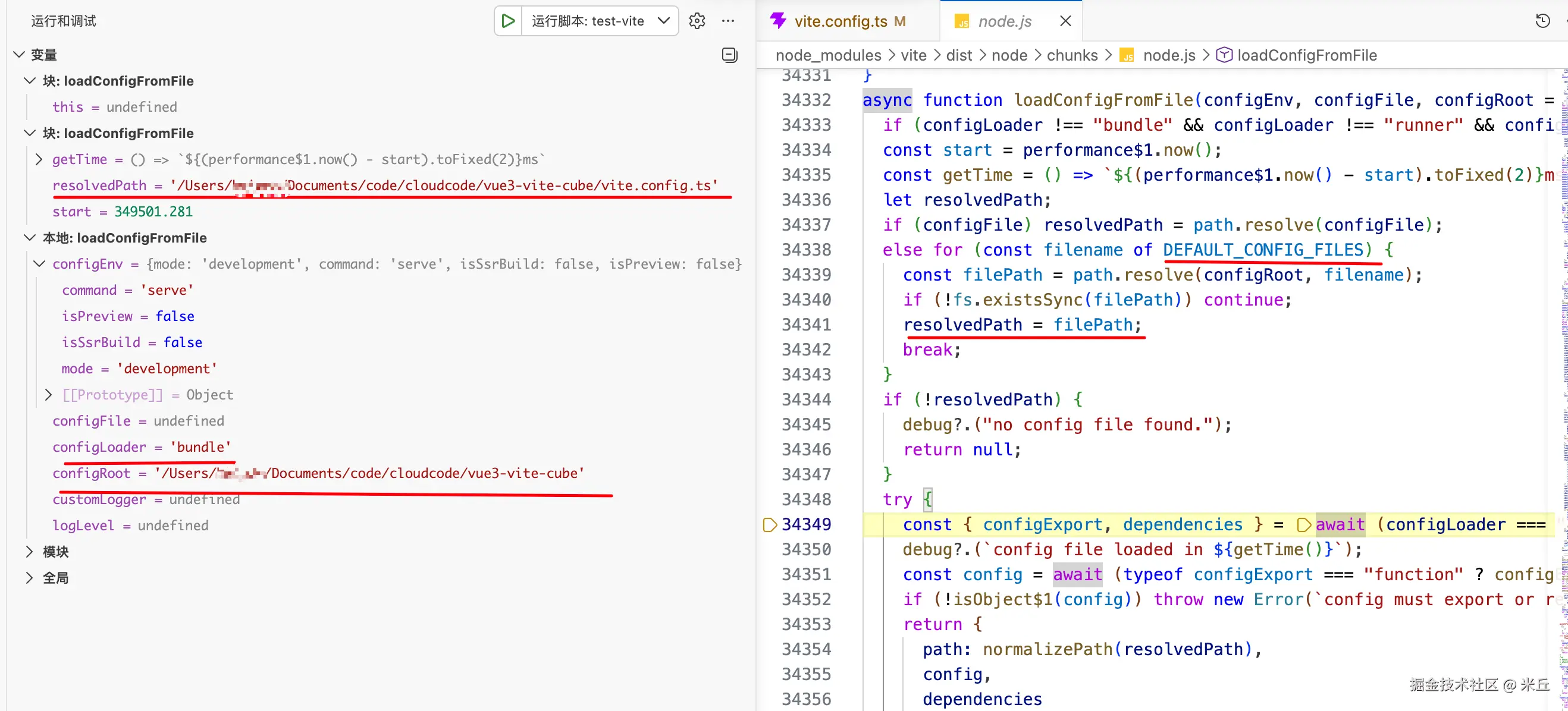
如果在执行 vite dev 时没有使用 --config 参数指定配置文件,Vite 将按照以下顺序自动查找并加载配置文件。
const DEFAULT_CONFIG_FILES: string[] = [
'vite.config.js',
'vite.config.mjs',
'vite.config.ts',
'vite.config.cjs',
'vite.config.mts',
'vite.config.cts',
]
Vite 提供了三种配置加载机制
当配置文件被定位后,Vite 如何读取并执行它的内容?这取决于 configLoader 配置选项。Vite 提供了三种机制来加载配置文件,默认使用 bundle 模式。
const resolver =
configLoader === 'bundle'
? bundleAndLoadConfigFile // 处理配置文件的预构建
: configLoader === 'runner'
? runnerImportConfigFile // 处理配置文件的运行时导入
: nativeImportConfigFile // 处理配置文件的原生导入
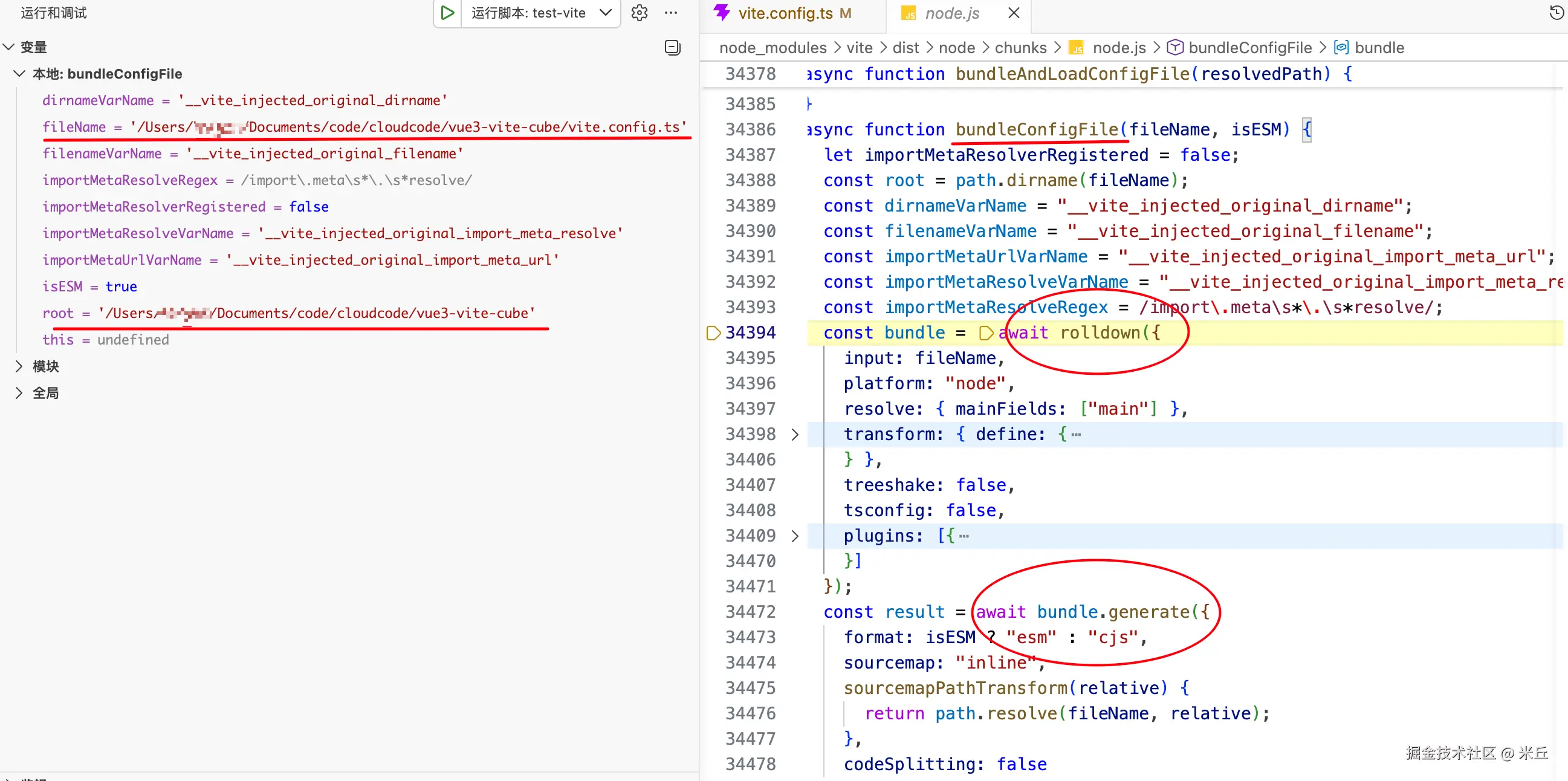
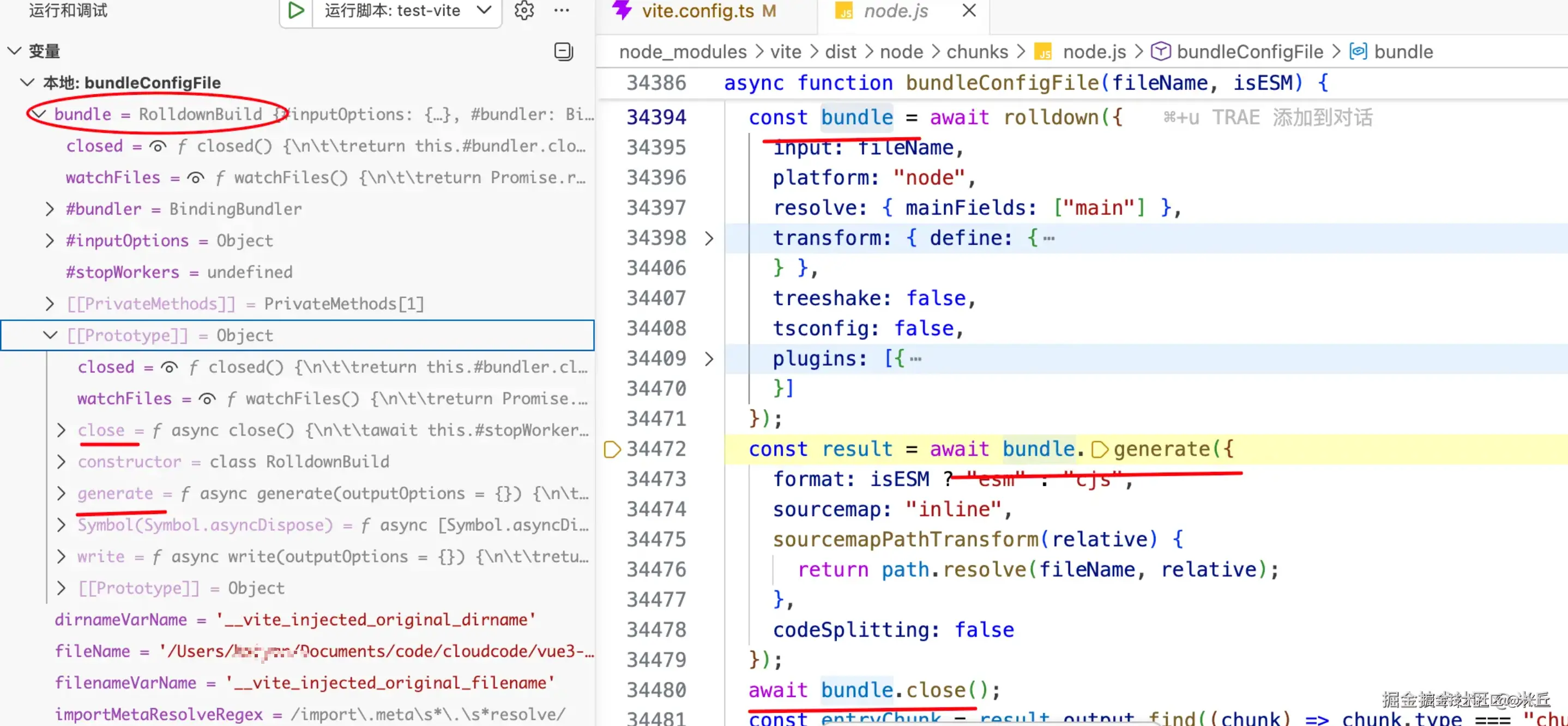
bundle (默认)
使用打包工具(Rolldown)将配置文件及其依赖打包成一个临时文件,再加载执行。
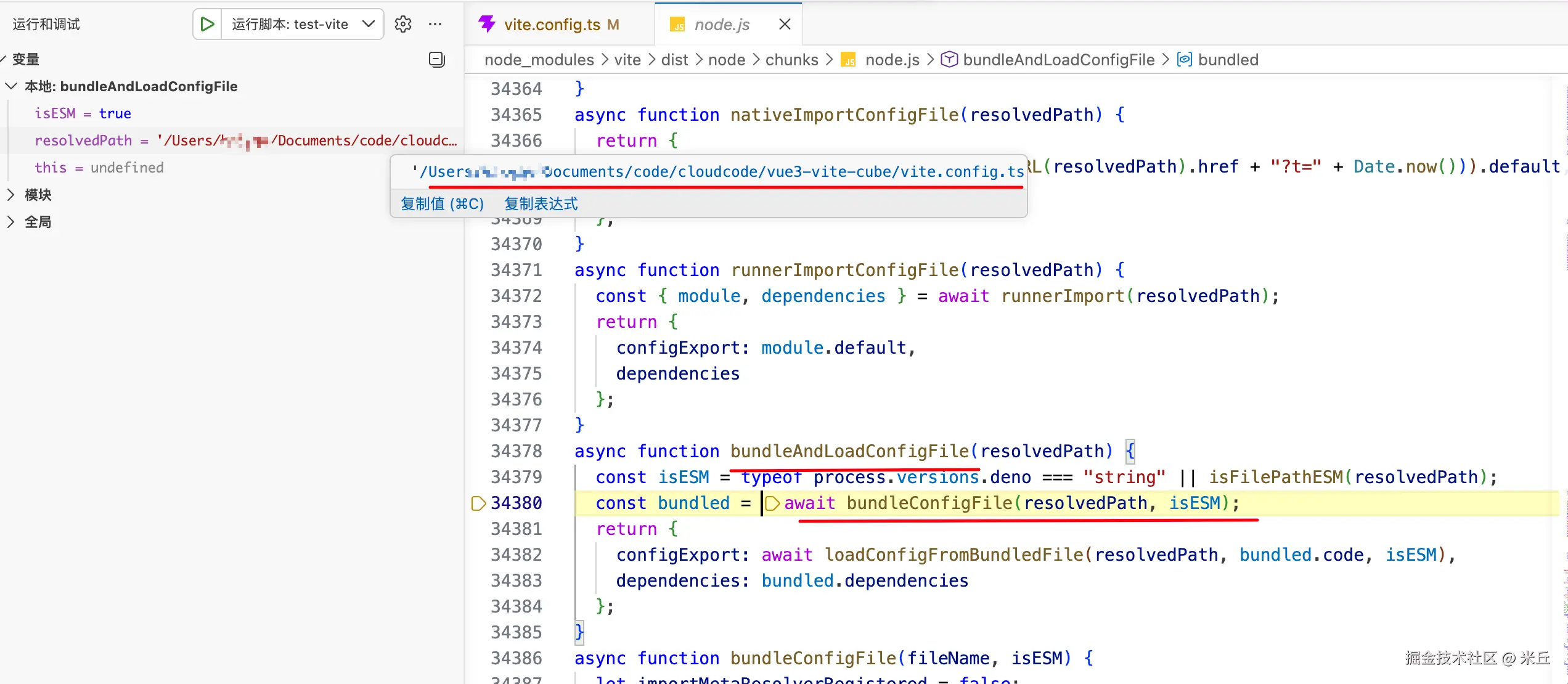
function bundleAndLoadConfigFile(resolvedPath: string) {
// 检查是否为 ESM 模块
const isESM =
// 在 Deno 环境中运行
typeof process.versions.deno === 'string' || isFilePathESM(resolvedPath)
// 配置文件打包
// 打包过程会处理配置文件的依赖,将其转换为可执行的代码
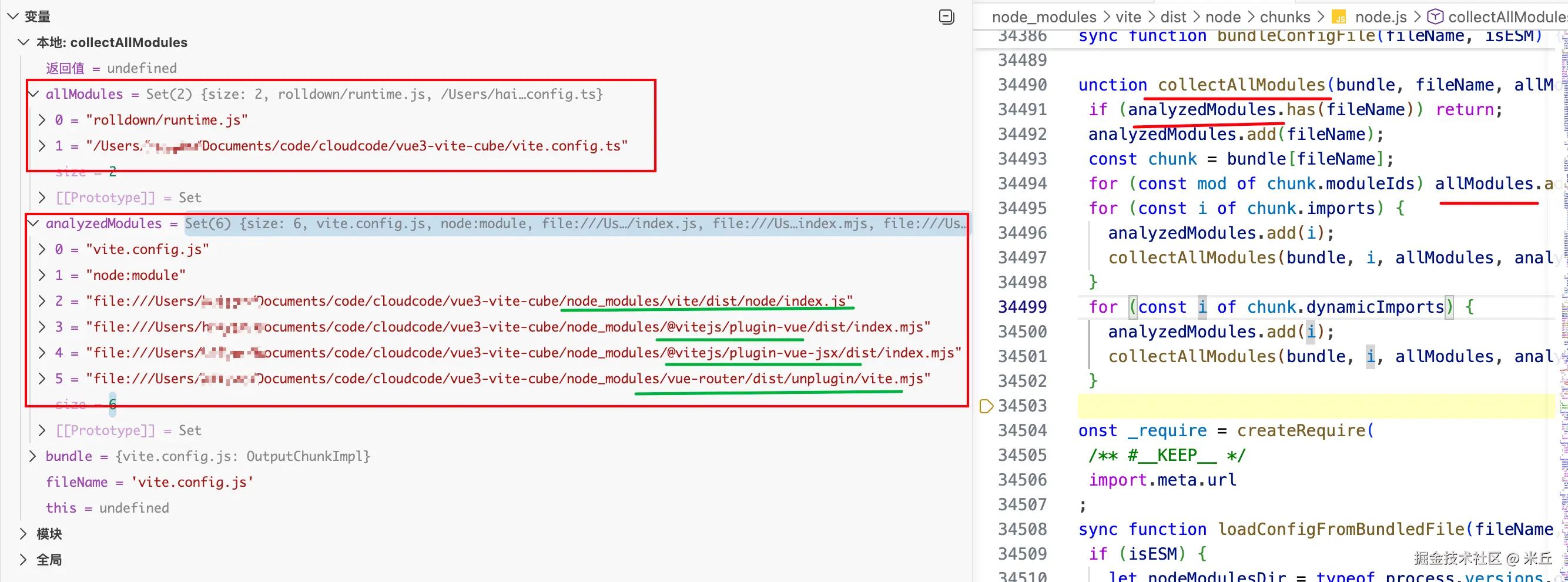
const bundled = await bundleConfigFile(resolvedPath, isESM)
// 配置加载
const userConfig = await loadConfigFromBundledFile(
resolvedPath,
bundled.code,
isESM,
)
return {
// 加载的用户配置
configExport: userConfig,
// 配置文件的依赖项
dependencies: bundled.dependencies,
}
}
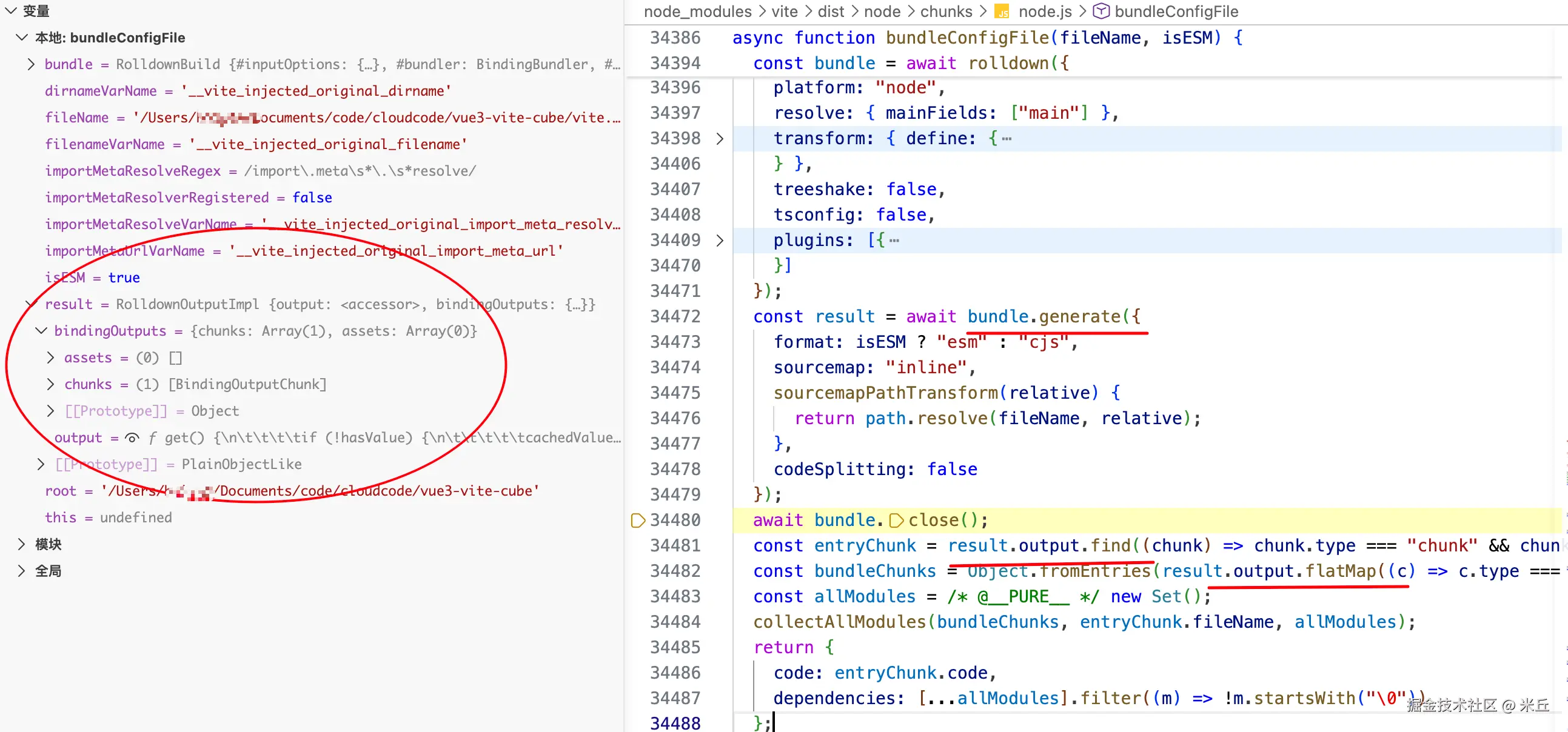
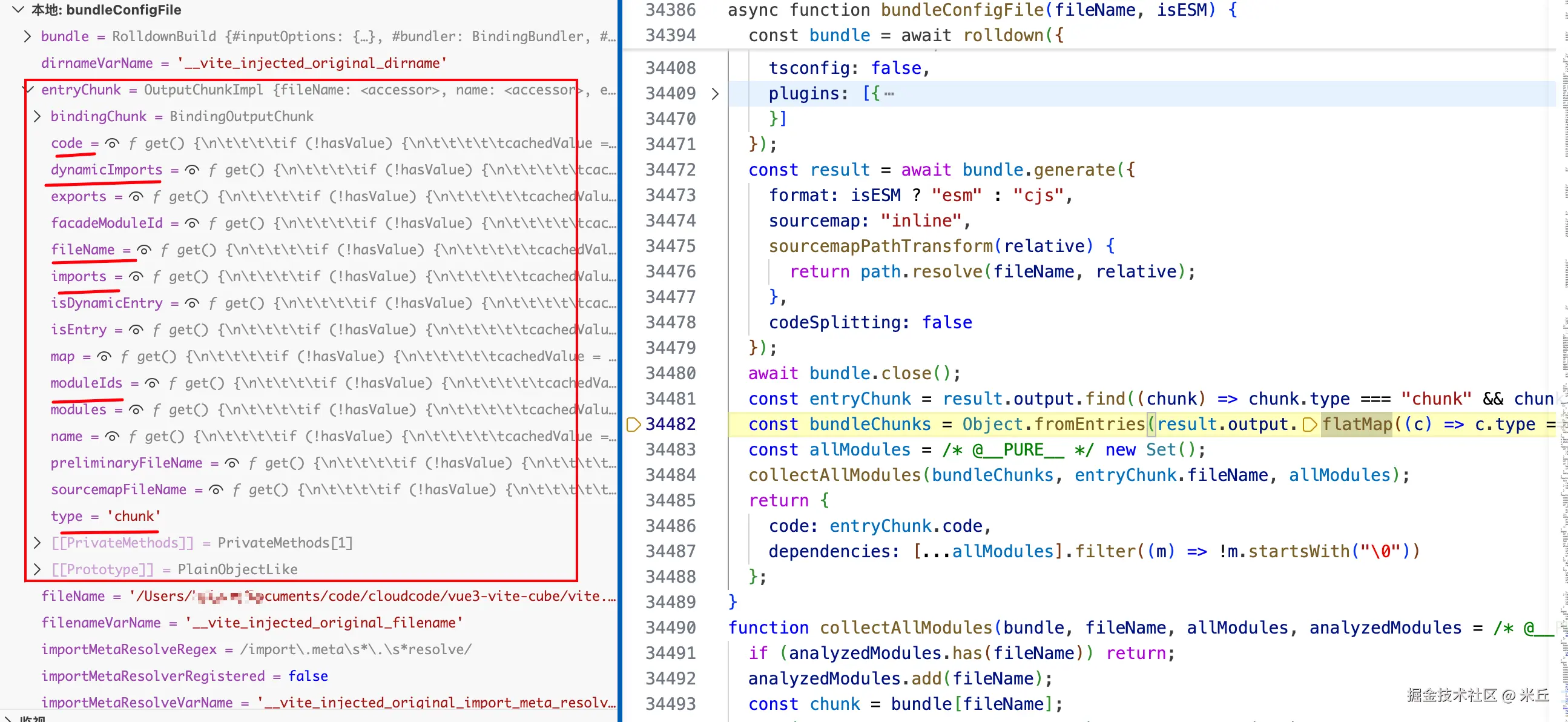
bundle.code 字符串
import "node:module";
import { defineConfig } from "file:///Users/xxxxx/Documents/code/cloudcode/vue3-vite-cube/node_modules/vite/dist/node/index.js";
import vue from "file:///Users/xxxxx/Documents/code/cloudcode/vue3-vite-cube/node_modules/@vitejs/plugin-vue/dist/index.mjs";
import vueJsx from "file:///Users/xxxxx/Documents/code/cloudcode/vue3-vite-cube/node_modules/@vitejs/plugin-vue-jsx/dist/index.mjs";
import VueRouter from "file:///Users/xxxx/Documents/code/cloudcode/vue3-vite-cube/node_modules/vue-router/dist/unplugin/vite.mjs";
Object.create;
Object.defineProperty;
Object.getOwnPropertyDescriptor;
Object.getOwnPropertyNames;
Object.getPrototypeOf;
Object.prototype.hasOwnProperty;
var vite_config_default = defineConfig({
plugins: [
VueRouter({
routesFolder: "src/pages",
extensions: [".vue"],
dts: "src/typed-router.d.ts",
importMode: "async",
root: process.cwd(),
watch: true
}),
vue(),
vueJsx()
],
resolve: { alias: { "@": "/src" } },
css: { preprocessorOptions: { less: {
additionalData: \`@import "@/styles/variables.less";\`,
javascriptEnabled: true
} } },
mode: "development"
});
//#endregion
export { vite_config_default as default };
//# sourceMappingURL=data:application/json;charset=utf-8;base64,eyJ2ZXJzaW9uIjozLCJmaWxlIjoidml0ZS5jb25maWcuanMiLCJuYW1lcyI6W10sInNvdXJjZXMiOlsiL1VzZXJzL2hhaXlhbi9Eb2N1bWVudHMvY29kZS9jbG91ZGNvZGUvdnVlMy12aXRlLWN1YmUvdml0ZS5jb25maWcudHMiXSwic291cmNlc0NvbnRlbnQiOlsiLy8gaW1wb3J0IHsgZmlsZVVSTFRvUGF0aCwgVVJMIH0gZnJvbSAnbm9kZTp1cmwnXG5pbXBvcnQgeyBkZWZpbmVDb25maWcgfSBmcm9tICd2aXRlJ1xuaW1wb3J0IHZ1ZSBmcm9tICdAdml0ZWpzL3BsdWdpbi12dWUnXG5pbXBvcnQgdnVlSnN4IGZyb20gJ0B2aXRlanMvcGx1Z2luLXZ1ZS1qc3gnXG5pbXBvcnQgdnVlRGV2VG9vbHMgZnJvbSAndml0ZS1wbHVnaW4tdnVlLWRldnRvb2xzJ1xuaW1wb3J0IFZ1ZVJvdXRlciBmcm9tICd2dWUtcm91dGVyL3ZpdGUnXG5cblxuLy8gaHR0cHM6Ly92aXRlLmRldi9jb25maWcvXG5leHBvcnQgZGVmYXVsdCBkZWZpbmVDb25maWcoe1xuICBwbHVnaW5zOiBbXG4gICAgLy8g5b+F6aG76KaB5ZyoIHZ1ZSDmj5Lku7bkuYvliY1cbiAgICBWdWVSb3V0ZXIoe1xuICAgICAgcm91dGVzRm9sZGVyOiAnc3JjL3BhZ2VzJywgLy8g6buY6K6kIHBhZ2VzXG4gICAgICBleHRlbnNpb25zOiBbJy52dWUnXSwgLy8g5Yy56YWN5paH5Lu25ZCO57yAXG4gICAgICBkdHM6ICdzcmMvdHlwZWQtcm91dGVyLmQudHMnLCAvLyDnlJ/miJDnsbvlnovmlofku7ZcbiAgICAgIC8vIOWHuueOsCBSYW5nZUVycm9yOiBNYXhpbXVtIGNhbGwgc3RhY2sgc2l6ZSBleGNlZWRlZFxuICAgICAgLy8gZ2V0Um91dGVOYW1lOiAocm91dGUpID0+IHtcbiAgICAgIC8vICAgY29uc29sZS5sb2coJ2dldFJvdXRlTmFtZScscm91dGUpXG4gICAgICAvLyAgIHJldHVybiByb3V0ZS5uYW1lIHx8IHJvdXRlLnBhdGhcbiAgICAgIC8vIH0sXG5cbiAgICAgICAvLyDmt7vliqDosIPor5XpgInpoblcbiAgICAgIC8vIGxvZ3M6IHRydWUsXG5cbiAgICAgIC8vIHJvdXRlQmxvY2tMYW5nOiAnanNvbjUnLCAvLyDot6/nlLHlnZfor63oqIDvvIzpu5jorqQganNvblxuICAgICAgaW1wb3J0TW9kZTogJ2FzeW5jJyxcbiAgICAgIHJvb3Q6IHByb2Nlc3MuY3dkKCksXG5cbiAgICAgIC8vIOWcqOmFjee9ruaWh+S7tuWGmeWFpeWJje+8jOaJi+WKqOS/ruaUuei3r+eUsemFjee9ru+8iOWmgua3u+WKoOWFqOWxgOi3r+eUseWuiOWNq+OAgeiwg+aVtOi3r+eUseWFg+S/oeaBr+OAgei/h+a7pOi3r+eUseetie+8iVxuICAgICAgLy8gYmVmb3JlV3JpdGVGaWxlczogKGVkaXRlZFJvdXRlcykgPT4ge1xuICAgICAgLy8gICBjb25zb2xlLmxvZygnYmVmb3JlV3JpdGVGaWxlcycsIGVkaXRlZFJvdXRlcylcbiAgICAgIC8vIH0sXG4gICAgICB3YXRjaDogdHJ1ZSwgLy8g5byA5ZCv6Lev55Sx5Z2X5paH5Lu255uR5ZCsXG4gICAgICAvLyDlvIDlkK/lrp7pqozmgKflip/og71cbiAgICAgIC8vIGV4cGVyaW1lbnRhbDoge1xuICAgICAgIFxuICAgICAgLy8gfSxcbiAgICB9KSxcbiAgICB2dWUoKSxcbiAgICB2dWVKc3goKSxcbiAgICAvLyB2dWVEZXZUb29scygpLFxuICBdLFxuICByZXNvbHZlOiB7XG4gICAgLy8gYWxpYXM6IHtcbiAgICAvLyAgICdAJzogZmlsZVVSTFRvUGF0aChuZXcgVVJMKCcuL3NyYycsIGltcG9ydC5tZXRhLnVybCkpXG4gICAgLy8gfSxcbiAgICBhbGlhczoge1xuICAgICAgJ0AnOiAnL3NyYycsXG4gICAgfSxcbiAgICAvLyB0c2NvbmZpZ1BhdGhzOiB0cnVlLCAgLy8g6Ieq5Yqo6K+75Y+WIHRzY29uZmlnIHBhdGhzXG4gIH0sXG4gIGNzczoge1xuICAgIHByZXByb2Nlc3Nvck9wdGlvbnM6IHtcbiAgICAgIGxlc3M6IHtcbiAgICAgICAgYWRkaXRpb25hbERhdGE6IGBAaW1wb3J0IFwiQC9zdHlsZXMvdmFyaWFibGVzLmxlc3NcIjtgLFxuICAgICAgICBqYXZhc2NyaXB0RW5hYmxlZDogdHJ1ZVxuICAgICAgfVxuICAgIH1cbiAgfSxcbiAgbW9kZTogJ2RldmVsb3BtZW50JyxcbiAgLy8gc2VydmVyOiB7XG4gIC8vICAgd3M6IGZhbHNlLFxuICAvLyB9LFxuICAvLyBvcHRpbWl6ZURlcHM6IHtcbiAgLy8gICBpbmNsdWRlOiBbJ3ZpcnR1YWw6dnVlLWluc3BlY3Rvci1wYXRoOmxvYWQuanMnXSxcbiAgLy8gfSxcblxufSkiXSwibWFwcGluZ3MiOiI7Ozs7Ozs7Ozs7O0FBU0EsSUFBQSxzQkFBZSxhQUFhO0NBQzFCLFNBQVM7RUFFUCxVQUFVO0dBQ1IsY0FBYztHQUNkLFlBQVksQ0FBQyxPQUFPO0dBQ3BCLEtBQUs7R0FXTCxZQUFZO0dBQ1osTUFBTSxRQUFRLEtBQUs7R0FNbkIsT0FBTztHQUtSLENBQUM7RUFDRixLQUFLO0VBQ0wsUUFBUTtFQUVUO0NBQ0QsU0FBUyxFQUlQLE9BQU8sRUFDTCxLQUFLLFFBQ04sRUFFRjtDQUNELEtBQUssRUFDSCxxQkFBcUIsRUFDbkIsTUFBTTtFQUNKLGdCQUFnQjtFQUNoQixtQkFBbUI7RUFDckIsRUFDRixFQUNEO0NBQ0QsTUFBTTtDQVFQLENBQUEifQ==
dependencies
[
"/Users/xxxx/Documents/code/cloudcode/vue3-vite-cube/vite.config.ts",
]
临时文件
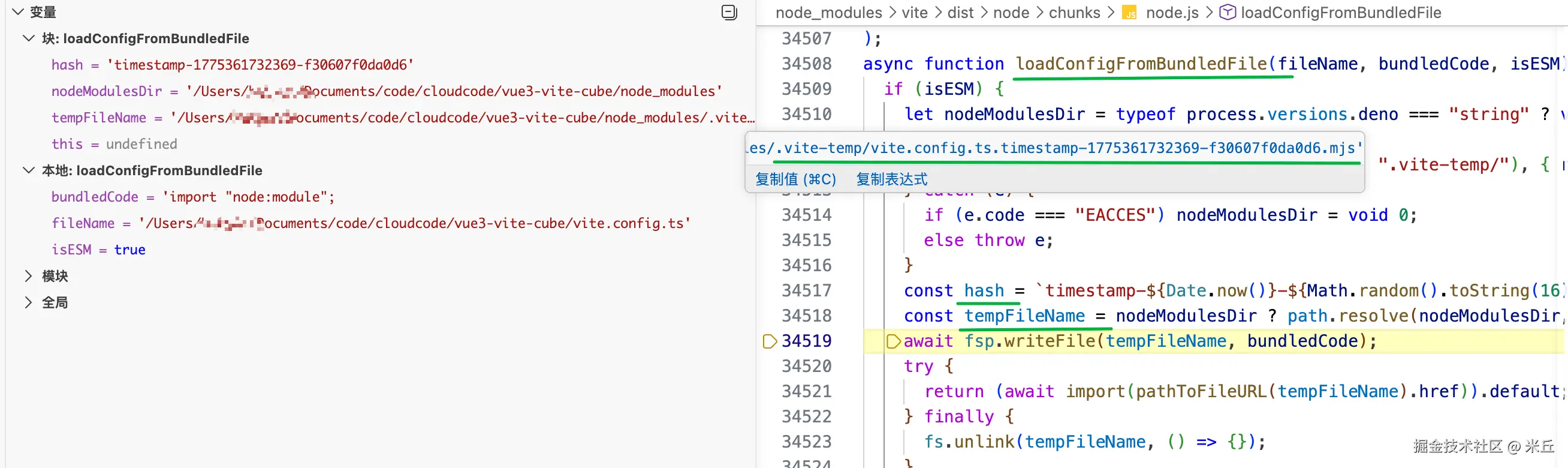
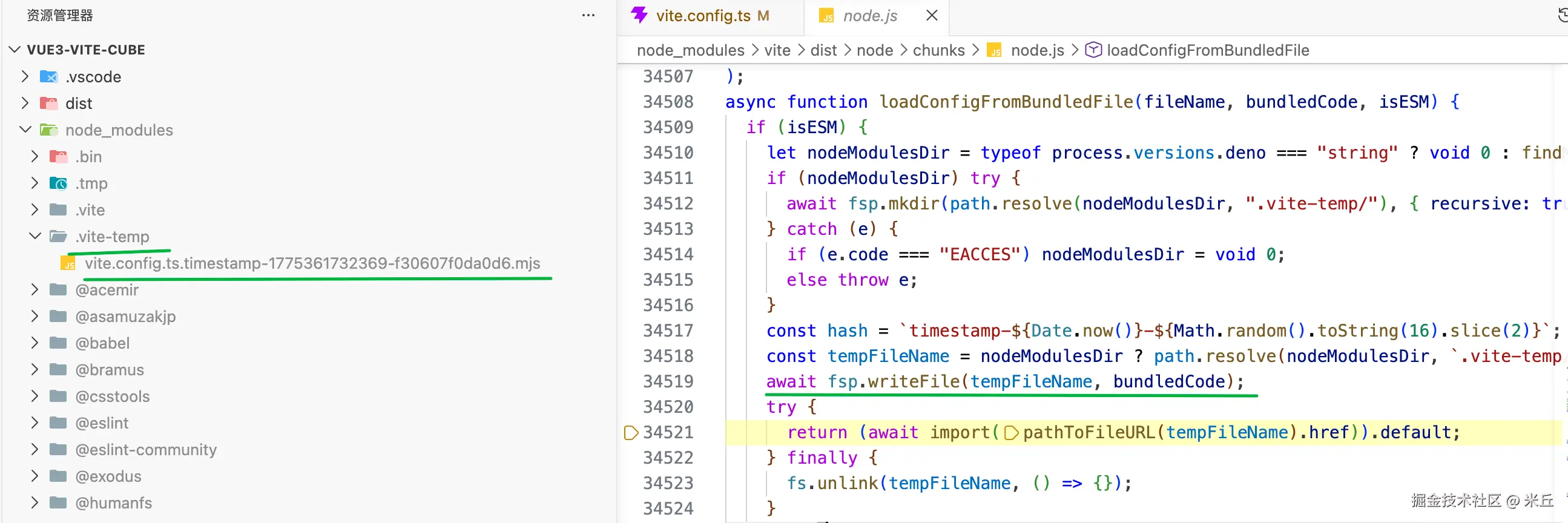
vue3-vite-cube/node_modules/.vite-temp/vite.config.ts.timestamp-1775361732369-f30607f0da0d6.mjs 文件内容如下:
import "node:module";
import { defineConfig } from "file:///Users/xxxx/Documents/code/cloudcode/vue3-vite-cube/node_modules/vite/dist/node/index.js";
import vue from "file:///Users/xxxx/Documents/code/cloudcode/vue3-vite-cube/node_modules/@vitejs/plugin-vue/dist/index.mjs";
import vueJsx from "file:///Users/xxxx/Documents/code/cloudcode/vue3-vite-cube/node_modules/@vitejs/plugin-vue-jsx/dist/index.mjs";
import VueRouter from "file:///Users/xxxx/Documents/code/cloudcode/vue3-vite-cube/node_modules/vue-router/dist/unplugin/vite.mjs";
Object.create;
Object.defineProperty;
Object.getOwnPropertyDescriptor;
Object.getOwnPropertyNames;
Object.getPrototypeOf;
Object.prototype.hasOwnProperty;
var vite_config_default = defineConfig({
plugins: [
VueRouter({
routesFolder: "src/pages",
extensions: [".vue"],
dts: "src/typed-router.d.ts",
importMode: "async",
root: process.cwd(),
watch: true
}),
vue(),
vueJsx()
],
resolve: { alias: { "@": "/src" } },
css: { preprocessorOptions: { less: {
additionalData: `@import "@/styles/variables.less";`,
javascriptEnabled: true
} } },
mode: "development"
});
//#endregion
export { vite_config_default as default };
//# sourceMappingURL=data:application/json;charset=utf-8;base64,eyJ2ZXJzaW9uIjozLCJmaWxlIjoidml0ZS5jb25maWcuanMiLCJuYW1lcyI6W10sInNvdXJjZXMiOlsiL1VzZXJzL2hhaXlhbi9Eb2N1bWVudHMvY29kZS9jbG91ZGNvZGUvdnVlMy12aXRlLWN1YmUvdml0ZS5jb25maWcudHMiXSwic291cmNlc0NvbnRlbnQiOlsiLy8gaW1wb3J0IHsgZmlsZVVSTFRvUGF0aCwgVVJMIH0gZnJvbSAnbm9kZTp1cmwnXG5pbXBvcnQgeyBkZWZpbmVDb25maWcgfSBmcm9tICd2aXRlJ1xuaW1wb3J0IHZ1ZSBmcm9tICdAdml0ZWpzL3BsdWdpbi12dWUnXG5pbXBvcnQgdnVlSnN4IGZyb20gJ0B2aXRlanMvcGx1Z2luLXZ1ZS1qc3gnXG5pbXBvcnQgdnVlRGV2VG9vbHMgZnJvbSAndml0ZS1wbHVnaW4tdnVlLWRldnRvb2xzJ1xuaW1wb3J0IFZ1ZVJvdXRlciBmcm9tICd2dWUtcm91dGVyL3ZpdGUnXG5cblxuLy8gaHR0cHM6Ly92aXRlLmRldi9jb25maWcvXG5leHBvcnQgZGVmYXVsdCBkZWZpbmVDb25maWcoe1xuICBwbHVnaW5zOiBbXG4gICAgLy8g5b+F6aG76KaB5ZyoIHZ1ZSDmj5Lku7bkuYvliY1cbiAgICBWdWVSb3V0ZXIoe1xuICAgICAgcm91dGVzRm9sZGVyOiAnc3JjL3BhZ2VzJywgLy8g6buY6K6kIHBhZ2VzXG4gICAgICBleHRlbnNpb25zOiBbJy52dWUnXSwgLy8g5Yy56YWN5paH5Lu25ZCO57yAXG4gICAgICBkdHM6ICdzcmMvdHlwZWQtcm91dGVyLmQudHMnLCAvLyDnlJ/miJDnsbvlnovmlofku7ZcbiAgICAgIC8vIOWHuueOsCBSYW5nZUVycm9yOiBNYXhpbXVtIGNhbGwgc3RhY2sgc2l6ZSBleGNlZWRlZFxuICAgICAgLy8gZ2V0Um91dGVOYW1lOiAocm91dGUpID0+IHtcbiAgICAgIC8vICAgY29uc29sZS5sb2coJ2dldFJvdXRlTmFtZScscm91dGUpXG4gICAgICAvLyAgIHJldHVybiByb3V0ZS5uYW1lIHx8IHJvdXRlLnBhdGhcbiAgICAgIC8vIH0sXG5cbiAgICAgICAvLyDmt7vliqDosIPor5XpgInpoblcbiAgICAgIC8vIGxvZ3M6IHRydWUsXG5cbiAgICAgIC8vIHJvdXRlQmxvY2tMYW5nOiAnanNvbjUnLCAvLyDot6/nlLHlnZfor63oqIDvvIzpu5jorqQganNvblxuICAgICAgaW1wb3J0TW9kZTogJ2FzeW5jJyxcbiAgICAgIHJvb3Q6IHByb2Nlc3MuY3dkKCksXG5cbiAgICAgIC8vIOWcqOmFjee9ruaWh+S7tuWGmeWFpeWJje+8jOaJi+WKqOS/ruaUuei3r+eUsemFjee9ru+8iOWmgua3u+WKoOWFqOWxgOi3r+eUseWuiOWNq+OAgeiwg+aVtOi3r+eUseWFg+S/oeaBr+OAgei/h+a7pOi3r+eUseetie+8iVxuICAgICAgLy8gYmVmb3JlV3JpdGVGaWxlczogKGVkaXRlZFJvdXRlcykgPT4ge1xuICAgICAgLy8gICBjb25zb2xlLmxvZygnYmVmb3JlV3JpdGVGaWxlcycsIGVkaXRlZFJvdXRlcylcbiAgICAgIC8vIH0sXG4gICAgICB3YXRjaDogdHJ1ZSwgLy8g5byA5ZCv6Lev55Sx5Z2X5paH5Lu255uR5ZCsXG4gICAgICAvLyDlvIDlkK/lrp7pqozmgKflip/og71cbiAgICAgIC8vIGV4cGVyaW1lbnRhbDoge1xuICAgICAgIFxuICAgICAgLy8gfSxcbiAgICB9KSxcbiAgICB2dWUoKSxcbiAgICB2dWVKc3goKSxcbiAgICAvLyB2dWVEZXZUb29scygpLFxuICBdLFxuICByZXNvbHZlOiB7XG4gICAgLy8gYWxpYXM6IHtcbiAgICAvLyAgICdAJzogZmlsZVVSTFRvUGF0aChuZXcgVVJMKCcuL3NyYycsIGltcG9ydC5tZXRhLnVybCkpXG4gICAgLy8gfSxcbiAgICBhbGlhczoge1xuICAgICAgJ0AnOiAnL3NyYycsXG4gICAgfSxcbiAgICAvLyB0c2NvbmZpZ1BhdGhzOiB0cnVlLCAgLy8g6Ieq5Yqo6K+75Y+WIHRzY29uZmlnIHBhdGhzXG4gIH0sXG4gIGNzczoge1xuICAgIHByZXByb2Nlc3Nvck9wdGlvbnM6IHtcbiAgICAgIGxlc3M6IHtcbiAgICAgICAgYWRkaXRpb25hbERhdGE6IGBAaW1wb3J0IFwiQC9zdHlsZXMvdmFyaWFibGVzLmxlc3NcIjtgLFxuICAgICAgICBqYXZhc2NyaXB0RW5hYmxlZDogdHJ1ZVxuICAgICAgfVxuICAgIH1cbiAgfSxcbiAgbW9kZTogJ2RldmVsb3BtZW50JyxcbiAgLy8gc2VydmVyOiB7XG4gIC8vICAgd3M6IGZhbHNlLFxuICAvLyB9LFxuICAvLyBvcHRpbWl6ZURlcHM6IHtcbiAgLy8gICBpbmNsdWRlOiBbJ3ZpcnR1YWw6dnVlLWluc3BlY3Rvci1wYXRoOmxvYWQuanMnXSxcbiAgLy8gfSxcblxufSkiXSwibWFwcGluZ3MiOiI7Ozs7Ozs7Ozs7O0FBU0EsSUFBQSxzQkFBZSxhQUFhO0NBQzFCLFNBQVM7RUFFUCxVQUFVO0dBQ1IsY0FBYztHQUNkLFlBQVksQ0FBQyxPQUFPO0dBQ3BCLEtBQUs7R0FXTCxZQUFZO0dBQ1osTUFBTSxRQUFRLEtBQUs7R0FNbkIsT0FBTztHQUtSLENBQUM7RUFDRixLQUFLO0VBQ0wsUUFBUTtFQUVUO0NBQ0QsU0FBUyxFQUlQLE9BQU8sRUFDTCxLQUFLLFFBQ04sRUFFRjtDQUNELEtBQUssRUFDSCxxQkFBcUIsRUFDbkIsTUFBTTtFQUNKLGdCQUFnQjtFQUNoQixtQkFBbUI7RUFDckIsRUFDRixFQUNEO0NBQ0QsTUFBTTtDQVFQLENBQUEifQ==
/**
* 用于从打包后的代码加载 Vite 配置。
* 它根据模块类型(ESM 或 CommonJS)采用不同的加载策略,确保配置文件能够被正确执行并返回配置对象
* @param fileName 文件路径
* @param bundledCode 打包转换后代码
* @param isESM 是否为 ESM 格式
* @returns
*/
async function loadConfigFromBundledFile(
fileName: string,
bundledCode: string,
isESM: boolean,
): Promise<UserConfigExport> {
// for esm, before we can register loaders without requiring users to run node
// with --experimental-loader themselves, we have to do a hack here:
// write it to disk, load it with native Node ESM, then delete the file.
if (isESM) {
// Storing the bundled file in node_modules/ is avoided for Deno
// because Deno only supports Node.js style modules under node_modules/
// and configs with `npm:` import statements will fail when executed.
// 查找最近的 node_modules 目录
let nodeModulesDir =
typeof process.versions.deno === 'string'
? undefined
: findNearestNodeModules(path.dirname(fileName))
if (nodeModulesDir) {
try {
// 创建临时目录
// node_modules/.vite-temp/
await fsp.mkdir(path.resolve(nodeModulesDir, '.vite-temp/'), {
recursive: true,
})
} catch (e) {
if (e.code === 'EACCES') {
// If there is no access permission, a temporary configuration file is created by default.
nodeModulesDir = undefined
} else {
throw e
}
}
}
// 生成 hash 值
const hash = `timestamp-${Date.now()}-${Math.random().toString(16).slice(2)}`
// 生成临时文件名
const tempFileName = nodeModulesDir
? path.resolve(
nodeModulesDir,
`.vite-temp/${path.basename(fileName)}.${hash}.mjs`,
)
: `${fileName}.${hash}.mjs`
// 写入临时文件
await fsp.writeFile(tempFileName, bundledCode)
try {
// 将文件系统路径转换为 file:// 协议的 URL 对象
// 原因:ESM 的 import() 语法要求模块标识符为 URL 格式(对于本地文件),不能直接使用文件系统路径
// 动态加载 ESM 格式配置文件
// 执行过程:
// 1、Node.js 读取并执行 tempFileName 指向的文件
// 2、执行文件中的代码,构建模块的导出
// 3、生成包含所有导出的模块命名空间对象
// 4、Promise 解析为该命名空间对象
return (await import(pathToFileURL(tempFileName).href)).default
} finally {
fs.unlink(tempFileName, () => {}) // Ignore errors
}
}
// for cjs, we can register a custom loader via `_require.extensions`
else {
// 获取文件扩展名
const extension = path.extname(fileName)
// We don't use fsp.realpath() here because it has the same behaviour as
// fs.realpath.native. On some Windows systems, it returns uppercase volume
// letters (e.g. "C:\") while the Node.js loader uses lowercase volume letters.
// See https://github.com/vitejs/vite/issues/12923
// 获取文件的真实路径
// 避免 Windows 系统上的路径大小写问题
const realFileName = await promisifiedRealpath(fileName)
// 确定加载器扩展名
// require.extensions 标记已废弃
const loaderExt = extension in _require.extensions ? extension : '.js'
const defaultLoader = _require.extensions[loaderExt]!
// 注册自定义加载器
_require.extensions[loaderExt] = (module: NodeModule, filename: string) => {
if (filename === realFileName) {
// 执行打包后的代码
;(module as NodeModuleWithCompile)._compile(bundledCode, filename)
} else {
// 使用默认加载器
defaultLoader(module, filename)
}
}
// clear cache in case of server restart
// 清除缓存
delete _require.cache[_require.resolve(fileName)]
// 加载配置文件
const raw = _require(fileName)
// 恢复默认加载器
_require.extensions[loaderExt] = defaultLoader
return raw.__esModule ? raw.default : raw
}
}
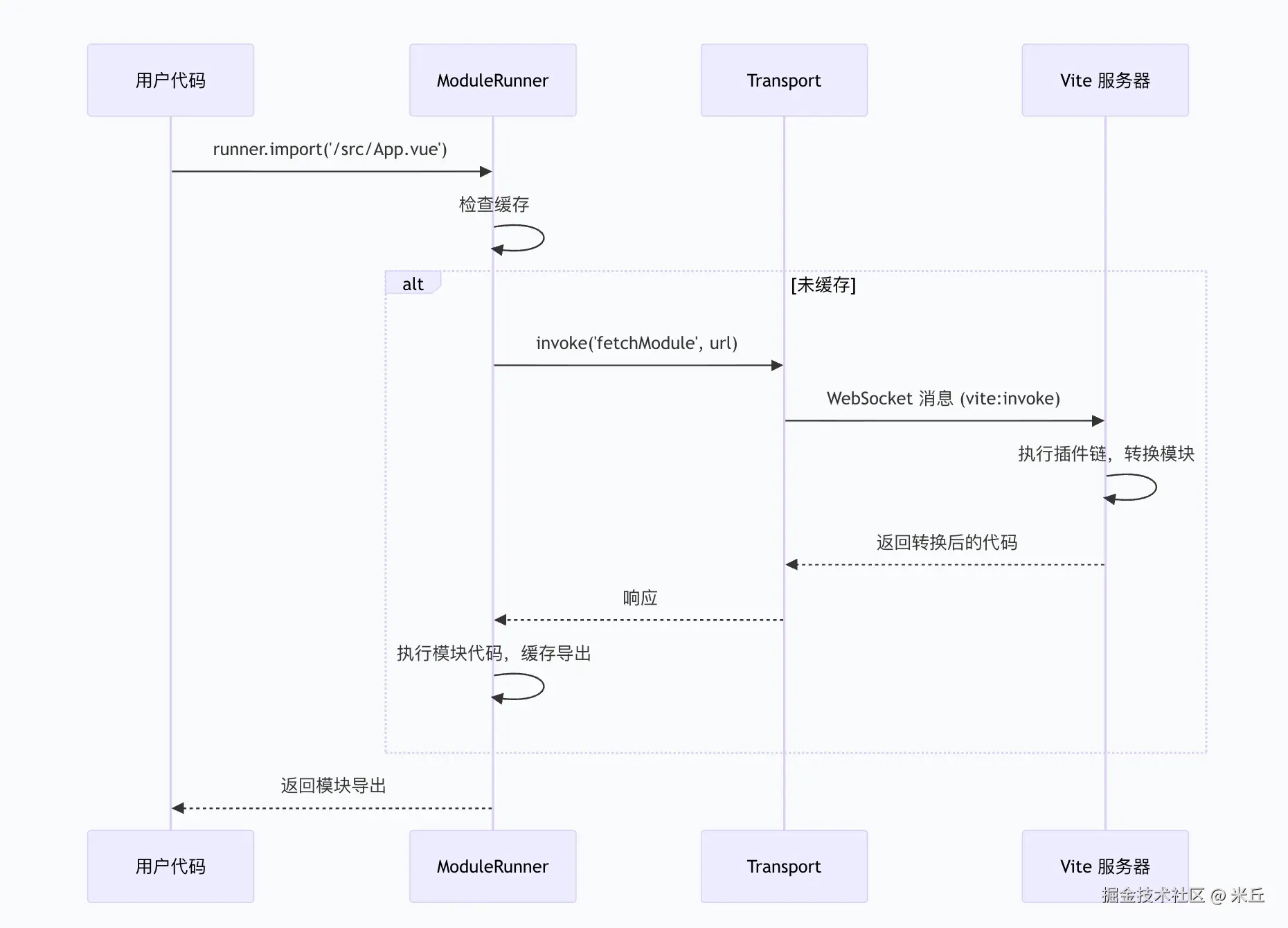
runner (实验性)
runner 模式不会创建临时配置文件,而是使用 Vite 的 ModuleRunner 动态转换任何文件。它的核心机制是利用 RunnableDevEnvironment 提供的 runner.import 函数,在独立的执行环境中加载并运行模块。
{
"start": "vite --configLoader=runner",
}
/**
* 用于通过 runner 方式导入配置文件。
* 它使用 runnerImport 函数动态加载配置文件,提取默认导出作为配置对象,并返回配置对象及其依赖项。
* @param resolvedPath 配置文件路径
* @returns
*/
async function runnerImportConfigFile(resolvedPath: string) {
const { module, dependencies } = await runnerImport<{
default: UserConfigExport
}>(resolvedPath)
return {
configExport: module.default,
dependencies,
}
}
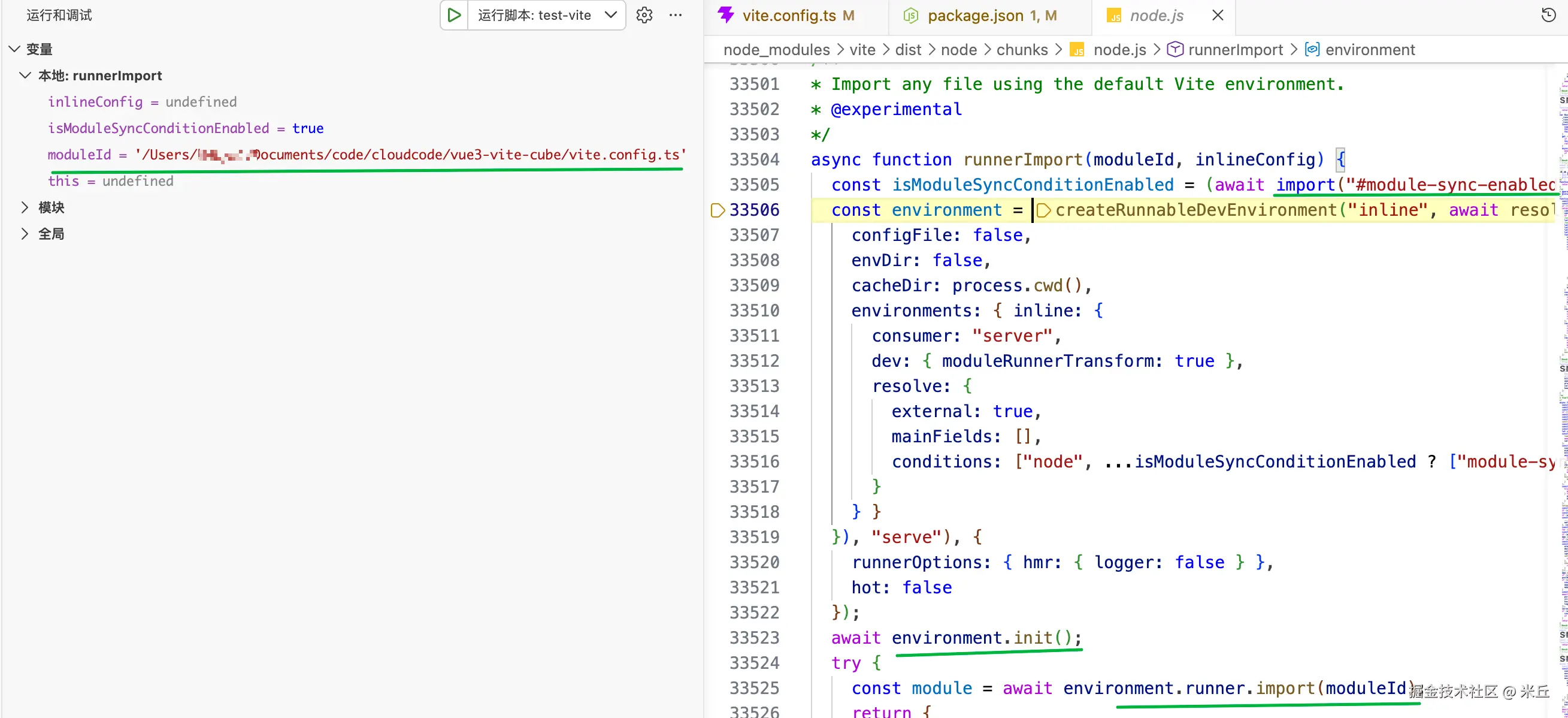
async function runnerImport<T>(
moduleId: string,
inlineConfig?: InlineConfig,
): Promise<RunnerImportResult<T>> {
// 模块同步条件检查
const isModuleSyncConditionEnabled = (await import('#module-sync-enabled'))
.default
// 配置解析
const config = await resolveConfig(
// 合并配置
mergeConfig(inlineConfig || {}, {
configFile: false, // 禁用配置文件解析
envDir: false, // 禁用环境变量目录解析
cacheDir: process.cwd(), // 缓存目录设置为当前工作目录
environments: {
inline: {
// 指定环境的消费方为服务器端
consumer: 'server',
dev: {
// 启用模块运行器转换
moduleRunnerTransform: true,
},
// 模块解析配置
resolve: {
// 启用外部模块解析,将依赖视为外部模块,不进行打包
// 影响:减少打包体积,提高模块加载速度
external: true,
// 清空主字段数组
// 不使用 package.json 中的主字段进行模块解析
// 避免因主字段优先级导致的解析问题,确保一致性
mainFields: [],
// 指定模块解析条件
conditions: [
'node',
...(isModuleSyncConditionEnabled ? ['module-sync'] : []),
],
},
},
},
} satisfies InlineConfig),
'serve', // 确保是 serve 命令
)
// 创建可运行的开发环境
const environment = createRunnableDevEnvironment('inline', config, {
runnerOptions: {
hmr: {
logger: false, // 禁用 HMR 日志记录
},
},
hot: false, // 禁用 HMR
})
// 初始化环境
// 准备模块运行器,确保能够正确加载模块
await environment.init()
try {
// 使用环境的运行器导入模块
// 模块加载与执行:
// 1、ModuleRunner 解析 moduleId,处理路径解析
// 2、加载模块文件内容
// 3、应用必要的转换(如 ESM 到 CommonJS 的转换)
// 4、执行模块代码
// 5、收集模块的依赖项
const module = await environment.runner.import(moduleId)
// 获取所有评估过的模块
const modules = [
...environment.runner.evaluatedModules.urlToIdModuleMap.values(),
]
// 过滤出所有外部化模块和当前模块
// 这些模块不是依赖项,因为它们是 Vite 内部使用的模块
const dependencies = modules
.filter((m) => {
// ignore all externalized modules
// 忽略没有meta的模块 或者标记为外部化的模块
if (!m.meta || 'externalize' in m.meta) {
return false
}
// ignore the current module
// 忽略当前模块,因为它不是依赖项
return m.exports !== module
})
.map((m) => m.file)
return {
module,
dependencies,
}
} finally {
// 关闭环境
// 释放所有资源,避免内存泄漏等问题
await environment.close()
}
}
module
{
default: {
plugins: [
{
name: "vue-router",
enforce: "pre",
resolveId: {
filter: {
id: {
include: [
{
},
{
},
{
},
],
},
},
handler: function(...args) {
const [id] = args;
if (!supportNativeFilter(this, key) && !filter(id)) return;
return handler.apply(this, args);
},
},
buildStart: async buildStart() {
await ctx.scanPages(options.watch);
},
buildEnd: function() {
ctx.stopWatcher();
},
transform: {
filter: {
id: {
include: [
"/Users/xxxx/Documents/code/cloudcode/vue3-vite-cube/src/pages/**/*.vue",
{
},
],
exclude: [
],
},
},
handler: function(...args) {
const [code, id] = args;
if (plugin.transformInclude && !plugin.transformInclude(id)) return;
if (!supportNativeFilter(this, key) && !filter(id, code)) return;
return handler.apply(this, args);
},
},
load: {
filter: {
id: {
include: [
{
},
{
},
{
},
],
},
},
handler: function(...args) {
const [id] = args;
if (plugin.loadInclude && !plugin.loadInclude(id)) return;
if (!supportNativeFilter(this, key) && !filter(id)) return;
return handler.apply(this, args);
},
},
vite: {
configureServer: function(server) {
ctx.setServerContext(createViteContext(server));
},
},
configureServer: function(server) {
ctx.setServerContext(createViteContext(server));
},
},
{
name: "vite:vue",
api: {
options: {
isProduction: false,
compiler: null,
customElement: {
},
root: "/Users/xxxx/Documents/code/cloudcode/vue3-vite-cube",
sourceMap: true,
cssDevSourcemap: false,
},
include: {
},
exclude: undefined,
version: "6.0.5",
},
handleHotUpdate: function(ctx) {
ctx.server.ws.send({
type: "custom",
event: "file-changed",
data: { file: normalizePath(ctx.file) }
});
if (options.value.compiler.invalidateTypeCache) options.value.compiler.invalidateTypeCache(ctx.file);
let typeDepModules;
const matchesFilter = filter.value(ctx.file);
if (typeDepToSFCMap.has(ctx.file)) {
typeDepModules = handleTypeDepChange(typeDepToSFCMap.get(ctx.file), ctx);
if (!matchesFilter) return typeDepModules;
}
if (matchesFilter) return handleHotUpdate(ctx, options.value, customElementFilter.value(ctx.file), typeDepModules);
},
config: function(config) {
const parseDefine = (v) => {
try {
return typeof v === "string" ? JSON.parse(v) : v;
} catch (err) {
return v;
}
};
return {
resolve: { dedupe: config.build?.ssr ? [] : ["vue"] },
define: {
__VUE_OPTIONS_API__: options.value.features?.optionsAPI ?? parseDefine(config.define?.__VUE_OPTIONS_API__) ?? true,
__VUE_PROD_DEVTOOLS__: (options.value.features?.prodDevtools || parseDefine(config.define?.__VUE_PROD_DEVTOOLS__)) ?? false,
__VUE_PROD_HYDRATION_MISMATCH_DETAILS__: (options.value.features?.prodHydrationMismatchDetails || parseDefine(config.define?.__VUE_PROD_HYDRATION_MISMATCH_DETAILS__)) ?? false
},
ssr: { external: config.legacy?.buildSsrCjsExternalHeuristics ? ["vue", "@vue/server-renderer"] : [] }
};
},
configResolved: function(config) {
options.value = {
...options.value,
root: config.root,
sourceMap: config.command === "build" ? !!config.build.sourcemap : true,
cssDevSourcemap: config.css?.devSourcemap ?? false,
isProduction: config.isProduction,
devToolsEnabled: !!(options.value.features?.prodDevtools || config.define.__VUE_PROD_DEVTOOLS__ || !config.isProduction)
};
const _warn = config.logger.warn;
config.logger.warn = (...args) => {
if (args[0].match(/\[lightningcss\] '(deep|slotted|global)' is not recognized as a valid pseudo-/)) return;
_warn(...args);
};
transformCachedModule = config.command === "build" && options.value.sourceMap && config.build.watch != null;
},
options: function() {
optionsHookIsCalled = true;
plugin.transform.filter = { id: {
include: [...makeIdFiltersToMatchWithQuery(ensureArray(include.value)), /[?&]vue\b/],
exclude: exclude.value
} };
},
shouldTransformCachedModule: function({ id }) {
if (transformCachedModule && parseVueRequest(id).query.vue) return true;
return false;
},
configureServer: function(server) {
options.value.devServer = server;
},
buildStart: function() {
const compiler = options.value.compiler = options.value.compiler || resolveCompiler(options.value.root);
if (compiler.invalidateTypeCache) options.value.devServer?.watcher.on("unlink", (file) => {
compiler.invalidateTypeCache(file);
});
},
resolveId: {
filter: {
id: [
{
},
{
},
],
},
handler: function(id) {
if (id === EXPORT_HELPER_ID) return id;
if (parseVueRequest(id).query.vue) return id;
},
},
load: {
filter: {
id: [
{
},
{
},
],
},
handler: function(id, opt) {
if (id === EXPORT_HELPER_ID) return helperCode;
const ssr = opt?.ssr === true;
const { filename, query } = parseVueRequest(id);
if (query.vue) {
if (query.src) return fs.readFileSync(filename, "utf-8");
const descriptor = getDescriptor(filename, options.value);
let block;
if (query.type === "script") block = resolveScript(descriptor, options.value, ssr, customElementFilter.value(filename));
else if (query.type === "template") block = descriptor.template;
else if (query.type === "style") block = descriptor.styles[query.index];
else if (query.index != null) block = descriptor.customBlocks[query.index];
if (block) return {
code: block.content,
map: block.map
};
}
},
},
transform: {
handler: function(code, id, opt) {
const ssr = opt?.ssr === true;
const { filename, query } = parseVueRequest(id);
if (query.raw || query.url) return;
if (!filter.value(filename) && !query.vue) return;
if (!query.vue) return transformMain(code, filename, options.value, this, ssr, customElementFilter.value(filename));
else {
const descriptor = query.src ? getSrcDescriptor(filename, query) || getTempSrcDescriptor(filename, query) : getDescriptor(filename, options.value);
if (query.src) this.addWatchFile(filename);
if (query.type === "template") return transformTemplateAsModule(code, filename, descriptor, options.value, this, ssr, customElementFilter.value(filename));
else if (query.type === "style") return transformStyle(code, descriptor, Number(query.index || 0), options.value, this, filename);
}
},
},
},
{
name: "vite:vue-jsx",
config: function(config) {
const parseDefine = (v) => {
try {
return typeof v === "string" ? JSON.parse(v) : v;
} catch (err) {
return v;
}
};
const isRolldownVite = this && "rolldownVersion" in this.meta;
return {
[isRolldownVite ? "oxc" : "esbuild"]: tsTransform === "built-in" ? { exclude: /\.jsx?$/ } : { include: /\.ts$/ },
define: {
__VUE_OPTIONS_API__: parseDefine(config.define?.__VUE_OPTIONS_API__) ?? true,
__VUE_PROD_DEVTOOLS__: parseDefine(config.define?.__VUE_PROD_DEVTOOLS__) ?? false,
__VUE_PROD_HYDRATION_MISMATCH_DETAILS__: parseDefine(config.define?.__VUE_PROD_HYDRATION_MISMATCH_DETAILS__) ?? false
},
optimizeDeps: isRolldownVite ? { rolldownOptions: { transform: { jsx: "preserve" } } } : {}
};
},
configResolved: function(config) {
needHmr = config.command === "serve" && !config.isProduction;
needSourceMap = config.command === "serve" || !!config.build.sourcemap;
root = config.root;
},
resolveId: {
filter: {
id: {
},
},
handler: function(id) {
if (id === ssrRegisterHelperId) return id;
},
},
load: {
filter: {
id: {
},
},
handler: function(id) {
if (id === ssrRegisterHelperId) return ssrRegisterHelperCode;
},
},
transform: {
order: undefined,
filter: {
id: {
include: {
},
exclude: undefined,
},
},
handler: async handler(code, id, opt) {
const ssr = opt?.ssr === true;
const [filepath] = id.split("?");
if (filter(id) || filter(filepath)) {
const plugins = [[jsx, babelPluginOptions], ...babelPlugins];
if (id.endsWith(".tsx") || filepath.endsWith(".tsx")) if (tsTransform === "built-in") plugins.push([await import("@babel/plugin-syntax-typescript").then((r) => r.default), { isTSX: true }]);
else plugins.push([await import("@babel/plugin-transform-typescript").then((r) => r.default), {
...tsPluginOptions,
isTSX: true,
allowExtensions: true
}]);
if (!ssr && !needHmr) plugins.push(() => {
return { visitor: { CallExpression: { enter(_path) {
if (isDefineComponentCall(_path.node, defineComponentName)) {
const callee = _path.node.callee;
callee.name = `/* @__PURE__ */ ${callee.name}`;
}
} } } };
});
else plugins.push(() => {
return { visitor: { ExportDefaultDeclaration: { enter(_path) {
const unwrappedDeclaration = unwrapTypeAssertion(_path.node.declaration);
if (isDefineComponentCall(unwrappedDeclaration, defineComponentName)) {
const declaration = unwrappedDeclaration;
const nodesPath = _path.replaceWithMultiple([types.variableDeclaration("const", [types.variableDeclarator(types.identifier("__default__"), types.callExpression(declaration.callee, declaration.arguments))]), types.exportDefaultDeclaration(types.identifier("__default__"))]);
_path.scope.registerDeclaration(nodesPath[0]);
}
} } } };
});
const result = babel.transformSync(code, {
babelrc: false,
ast: true,
plugins,
sourceMaps: needSourceMap,
sourceFileName: id,
configFile: false
});
if (!ssr && !needHmr) {
if (!result.code) return;
return {
code: result.code,
map: result.map
};
}
const declaredComponents = [];
const hotComponents = [];
for (const node of result.ast.program.body) {
if (node.type === "VariableDeclaration") {
const names = parseComponentDecls(node, defineComponentName);
if (names.length) declaredComponents.push(...names);
}
if (node.type === "ExportNamedDeclaration") {
if (node.declaration && node.declaration.type === "VariableDeclaration") hotComponents.push(...parseComponentDecls(node.declaration, defineComponentName).map((name) => ({
local: name,
exported: name,
id: getHash(id + name)
})));
else if (node.specifiers.length) {
for (const spec of node.specifiers) if (spec.type === "ExportSpecifier" && spec.exported.type === "Identifier") {
if (declaredComponents.find((name) => name === spec.local.name)) hotComponents.push({
local: spec.local.name,
exported: spec.exported.name,
id: getHash(id + spec.exported.name)
});
}
}
}
if (node.type === "ExportDefaultDeclaration") {
if (node.declaration.type === "Identifier") {
const _name = node.declaration.name;
if (declaredComponents.find((name) => name === _name)) hotComponents.push({
local: _name,
exported: "default",
id: getHash(id + "default")
});
} else if (isDefineComponentCall(unwrapTypeAssertion(node.declaration), defineComponentName)) hotComponents.push({
local: "__default__",
exported: "default",
id: getHash(id + "default")
});
}
}
if (hotComponents.length) {
if (needHmr && !ssr && !/\?vue&type=script/.test(id)) {
let code = result.code;
let callbackCode = ``;
for (const { local, exported, id } of hotComponents) {
code += `\n${local}.__hmrId = "${id}"\n__VUE_HMR_RUNTIME__.createRecord("${id}", ${local})`;
callbackCode += `\n__VUE_HMR_RUNTIME__.reload("${id}", __${exported})`;
}
const newCompNames = hotComponents.map((c) => `${c.exported}: __${c.exported}`).join(",");
code += `\nimport.meta.hot.accept(({${newCompNames}}) => {${callbackCode}\n})`;
result.code = code;
}
if (ssr) {
const normalizedId = normalizePath(path.relative(root, id));
let ssrInjectCode = `\nimport { ssrRegisterHelper } from "${ssrRegisterHelperId}"\nconst __moduleId = ${JSON.stringify(normalizedId)}`;
for (const { local } of hotComponents) ssrInjectCode += `\nssrRegisterHelper(${local}, __moduleId)`;
result.code += ssrInjectCode;
}
}
if (!result.code) return;
return {
code: result.code,
map: result.map
};
}
},
},
},
],
resolve: {
alias: {
"@": "/src",
},
},
css: {
preprocessorOptions: {
less: {
additionalData: "@import \"@/styles/variables.less\";",
javascriptEnabled: true,
},
},
},
mode: "development",
},
}
导出的内容就是 vite.config.js 中配置信息
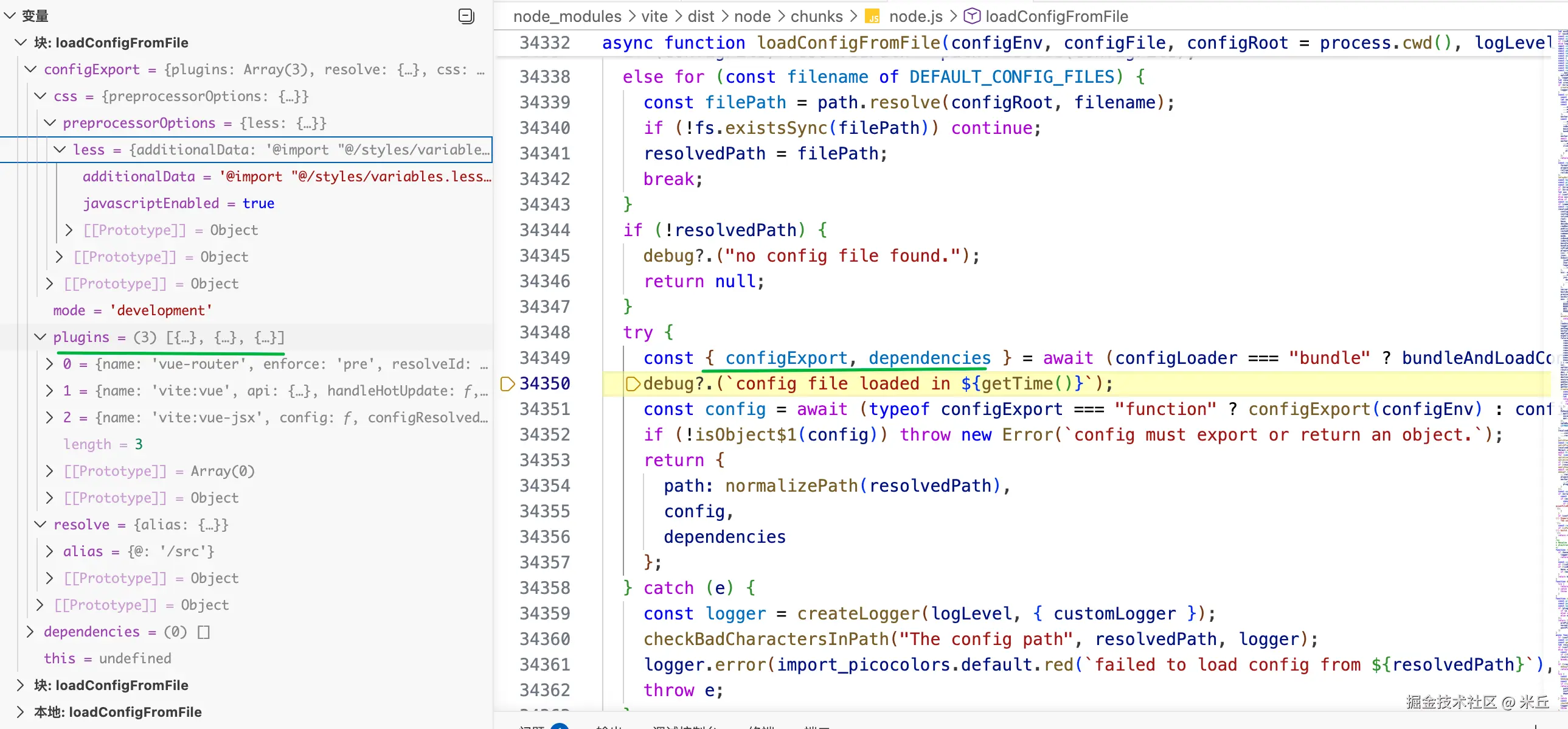
ModuleRunner模块运行器
public async import<T = any>(url: string): Promise<T> {
// 获取缓存模块
const fetchedModule = await this.cachedModule(url)
// 执行模块请求
return await this.cachedRequest(url, fetchedModule)
}
native (实验性)
native 模式直接通过 Node.js 原生的动态 import() 加载配置文件,不经过任何打包步骤。
只能编写纯 JavaScript,可以指定 --configLoader native 来使用环境的原生运行时加载配置文件。
{
"start": "vite --configLoader=native",
}
- 它的优点是简单快速,调试时断点可以直接定位到源码,不受临时文件干扰。
- 但这种模式有一个重要限制:配置文件导入的模块的更新不会被检测到,因此不会自动重启 Vite 服务器。
async function nativeImportConfigFile(resolvedPath: string) {
const module = await import(
pathToFileURL(resolvedPath).href + '?t=' + Date.now()
)
return {
configExport: module.default,
dependencies: [],
}
}
在 native 模式下,由于没有经过打包工具分析依赖,Vite 无法知道配置文件引入了哪些本地模块。因此依赖列表被硬编码为空数组,意味着当配置文件导入的其他本地文件(如 ./utils.js)发生变化时,Vite 不会自动重启服务器。这是 native 模式的重要限制。
三者的区别
