基于 Lexical 实现变量输入编辑器
我们是袋鼠云数栈 UED 团队,致力于打造优秀的一站式数据中台产品。我们始终保持工匠精神,探索前端道路,为社区积累并传播经验价值。
本文作者:霁明
1. 引言
1.1 背景与动机
在 AIWorks 的工作流和 Agent 编排系统中,有一个核心需求:支持在节点配置面板的配置项中引用上游节点的输出变量。例如,一个 LLM 节点需要引用“开始节点”的用户输入或自定义变量,或者引用上一个“HTTP 请求节点”的返回结果。
最直接的方案是使用传统的 Input 或 Textarea 组件,配合变量占位符语法如 {{nodeId.variableName}}。但这种方案存在明显的用户体验问题:
- 可读性差:原始的变量语法对用户不友好,难以快速识别变量来源
- 输入效率低:用户需要记忆变量名称和语法格式
- 缺乏上下文:无法直观展示变量所属节点和类型
- 易出错:手动输入变量语法容易出现拼写错误
我们期望的用户体验是:
- 用户输入
/字符时,自动弹出变量选择菜单 - 菜单按节点分组展示所有可用变量,支持搜索过滤
- 选择变量后,以可视化标签的形式展示(显示节点图标、节点名称、变量名)
- 底层数据仍保持
{{#nodeId.variableName#}}格式,便于后端解析
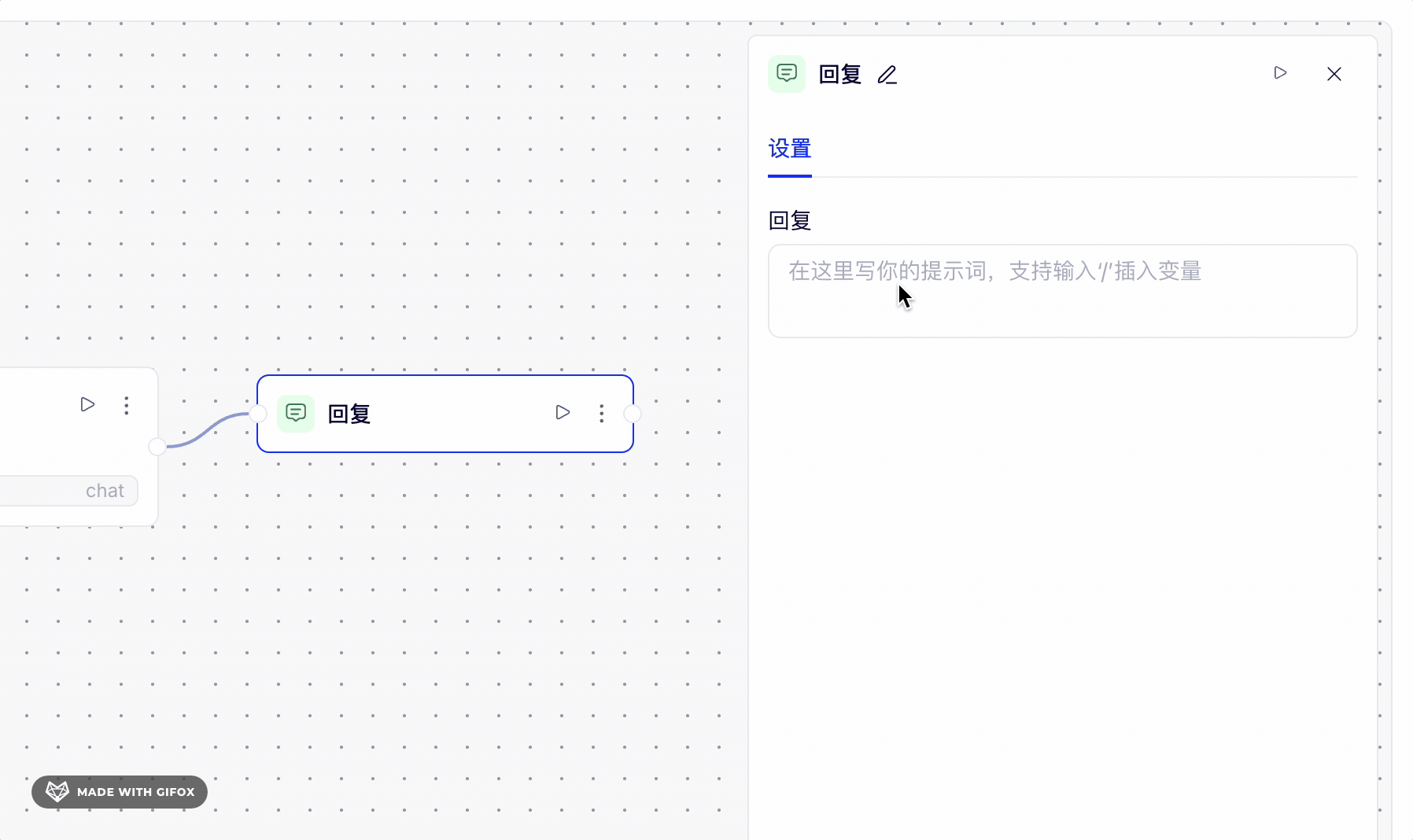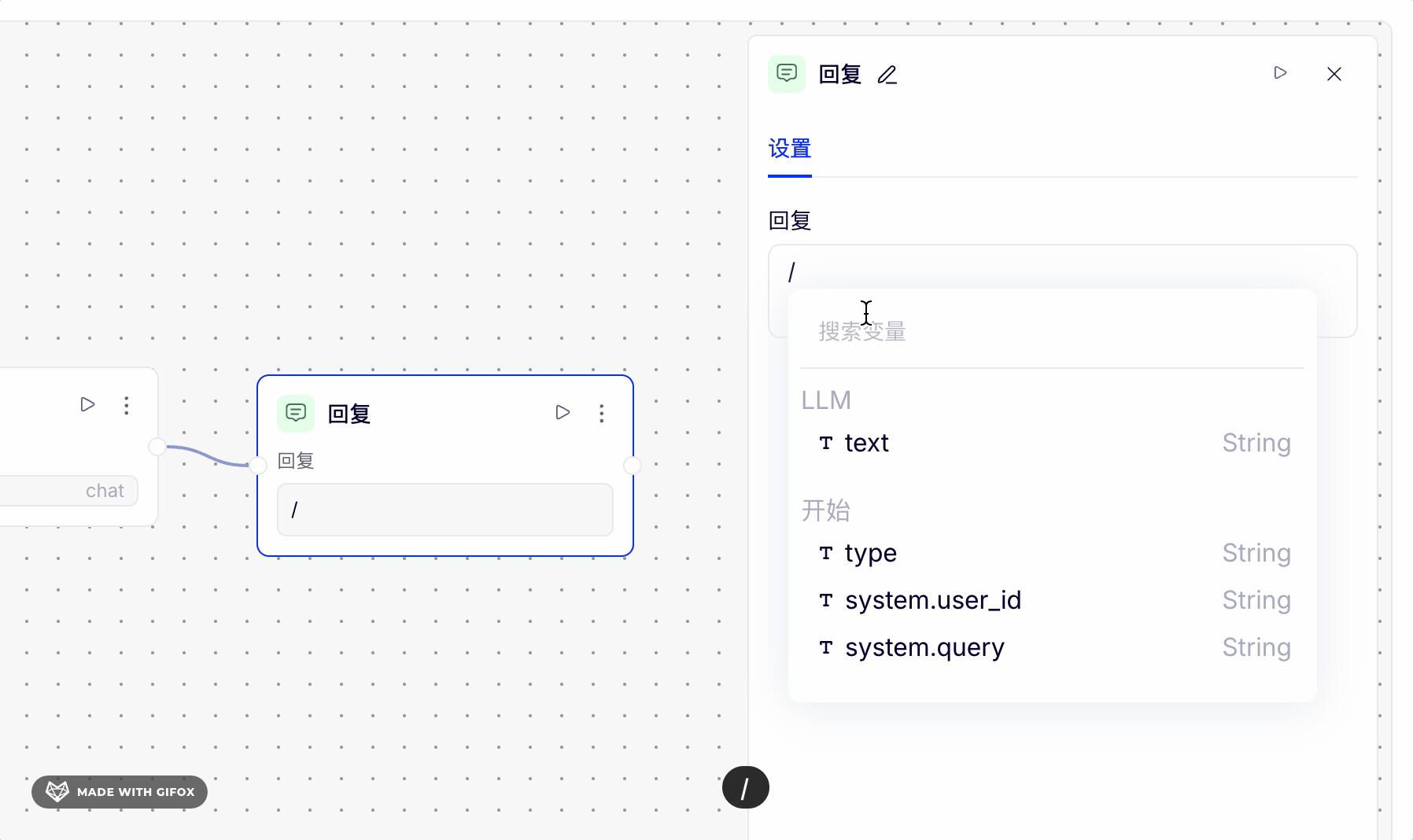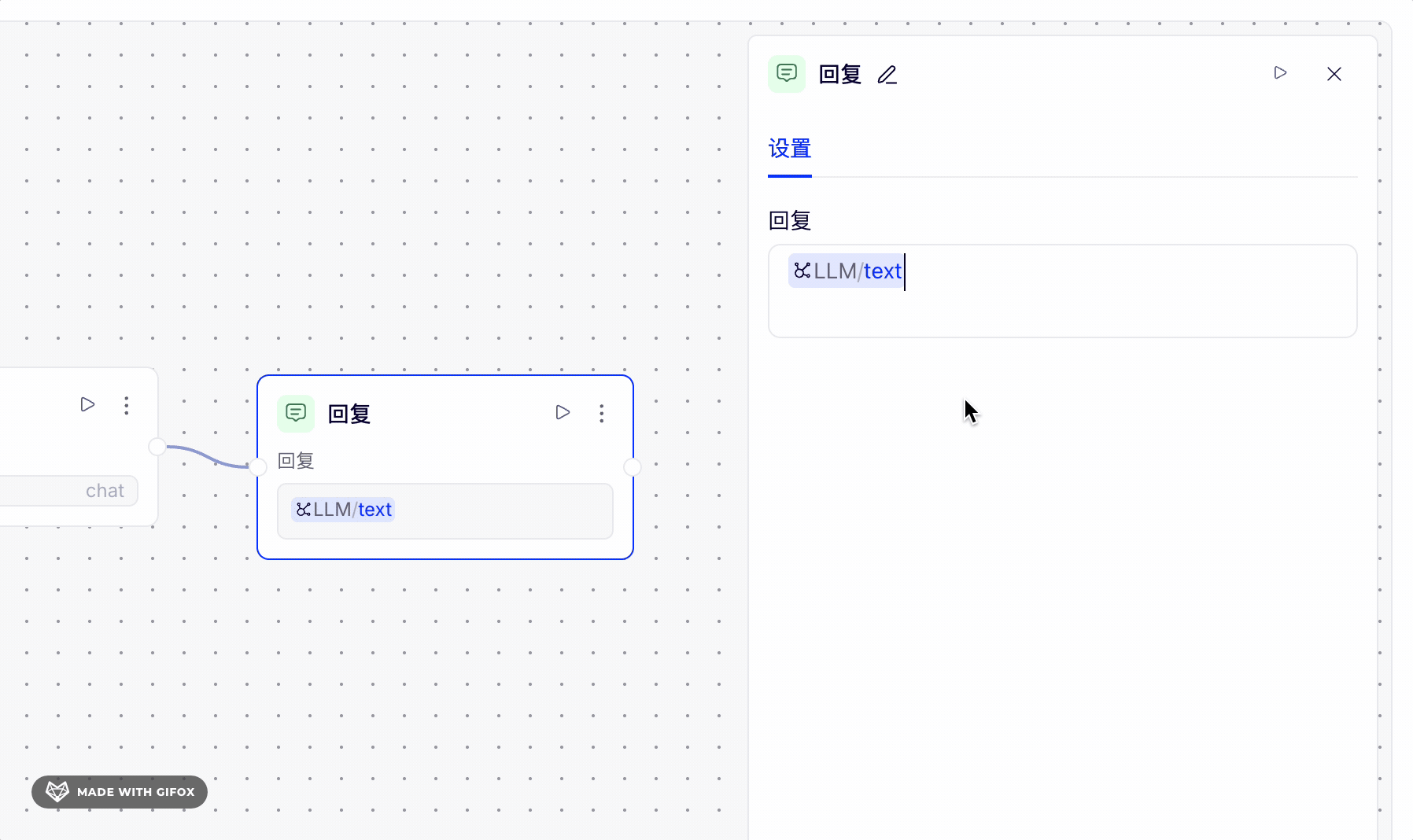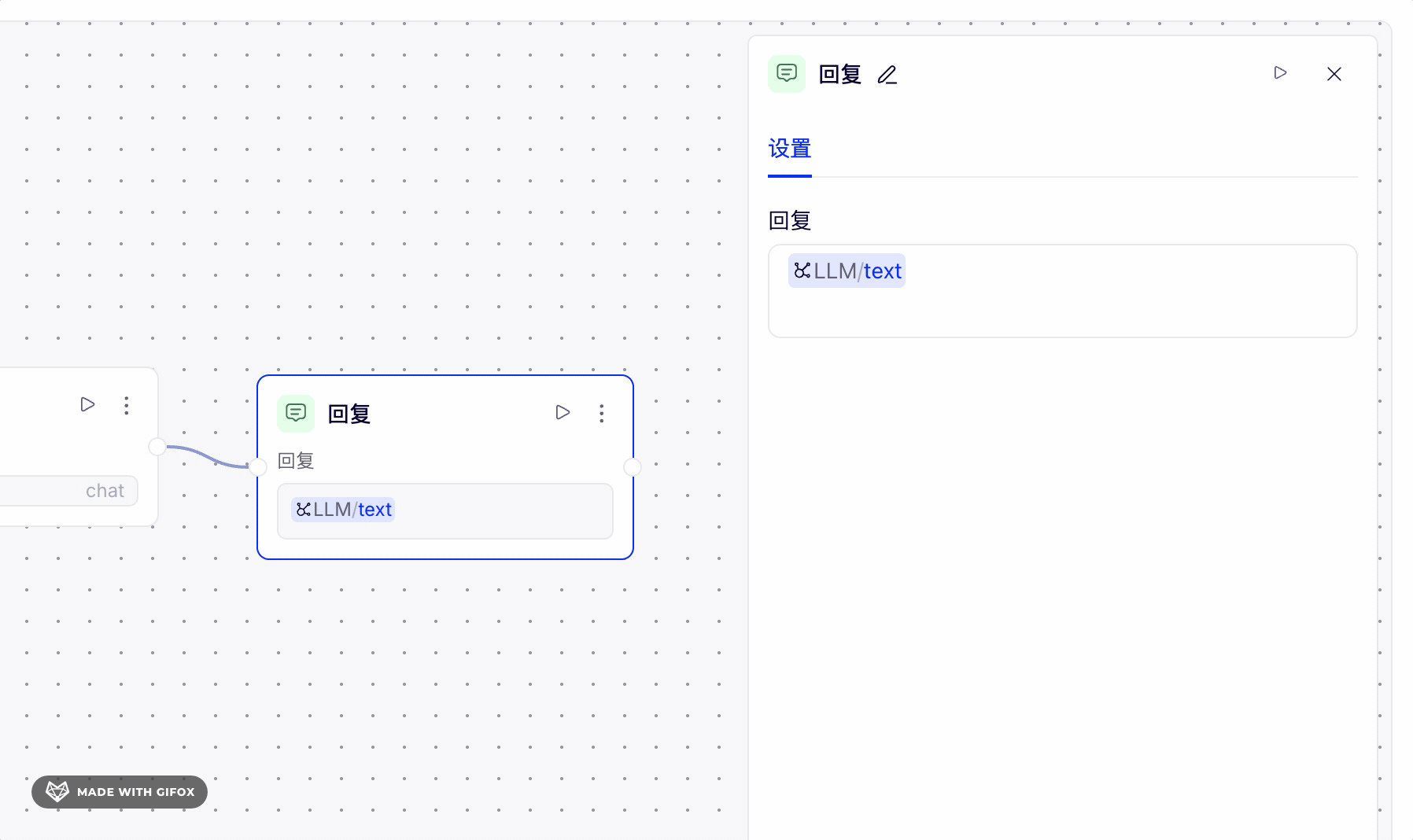
1.2 最终效果
实现后的效果如下:
-
触发菜单:在编辑器中任意位置输入
/,即刻弹出变量选择悬浮菜单 - 变量搜索:支持按变量名进行搜索
- 可视化标签:选中的变量渲染为带有节点图标和样式的标签
- 无缝编辑:标签与普通文本混排,支持 Input 组件中的常规操作,例如复制、删除、撤销等
2. 技术选型:为什么选择 Lexical?
2.1 Lexical 简介
Lexical 是 Meta(Facebook)于 2022 年开源的一个可扩展的可扩展富文本编辑器框架,它专注于提供高可靠性、出色的可访问性和高性能,让开发者能构建出从简单文本到复杂富文本协作编辑器的应用。它核心是一个轻量、无依赖的编辑器,通过模块化的插件机制支持自定义功能,支持与 React 等前端框架进行绑定,旨在简化富文本编辑器的开发和维护。
2.2 主流富文本框架对比
| 维度 | Lexical | Slate | Tiptap | ProseMirror | Editor.js | Quill |
|---|---|---|---|---|---|---|
| 维护方 | Meta | 社区 | Tiptap 团队 | 社区 | CodeX 团队 | 社区 |
| 是否开源 | 是 (MIT) | 是 (MIT) | 是 (MIT) | 是 (MIT) | 是 (Apache 2.0) | 是 (BSD) |
| React 支持 | 原生 | 原生 | 支持 | 需适配层 | 支持 | 支持 |
| 学习曲线 | 中等 | 中等偏高 | 中等偏低 | 陡峭 | 低 | 低 |
| 社区生态 | 增长迅速 | 稳定 | 繁荣 | 稳定 | 稳定 | 稳定 |
| TS 支持 | 完善 | 完善 | 完善 | 支持 | 支持 | 支持 |
| 核心优势 | 高可靠性、高性能、Meta 背书,适合现代 web 应用 | 灵活性极高、符合 React 直觉 | 兼顾易用与强大、UI 无头 | 协同编辑天花板、极其严谨 | 块级结构、天然适合 CMS | 简单易用、稳定 |
| 主要劣势 | 文档仍可优化 | 升级可能断层 | 协作/高级功能需付费订阅 | 开发门槛极高 | 跨行选择等体验有限 | 定制复杂功能较难 |
| 适用场景 | 现代高性能 React 应用 | 需要极度定制 UI 的 React 项目 | 快速交付的产品 | 复杂协同办公 (Google Docs 类) | 新闻发布、类 Notion 编辑器 | 评论区、简单博客、CMS |
2.3 选择 Lexical 的理由
- 轻量级:核心库约 42KB(gzip 后),对 bundle size 友好
- 现代架构:基于不可变状态,与 React 理念一致
- 高性能:优化的内部机制使得能够处理大规模的文本编辑任务而不牺牲响应速度
- 强扩展性:插件化设计,自定义节点类型简单直观
- React 深度集成:虽然并不仅限于 React,但它提供了与 React 深度集成的能力
- 官方维护:Meta 活跃维护,稳定可靠
- TypeScript 原生:完整的类型支持,开发体验好
- 同类主流产品验证:Dify、FastGPT 等都采用 Lexical 实现变量输入功能
2.4 AIWorks 使用的依赖
{
"lexical": "^0.35.0",
"@lexical/react": "^0.35.0",
"@lexical/text": "^0.35.0",
"@lexical/utils": "^0.35.0"
}
-
lexical:核心库,提供编辑器状态管理、节点系统、命令系统 -
@lexical/react:React 绑定,提供 Composer、插件等组件 -
@lexical/text:文本处理工具,包含文本实体(Text Entity)相关功能 -
@lexical/utils:工具函数,如mergeRegister用于批量注册/注销
3. Lexical 核心概念速览
在深入实现之前,我们需要理解 Lexical 的几个核心概念。
3.1 编辑器状态
Lexical 采用不可变状态设计。编辑器的所有内容都存储在 EditorState 中,任何修改都会产生新的状态对象。
// 读取状态(只读操作)
editor.getEditorState().read(() => {
const root = $getRoot();
const text = root.getTextContent();
});
// 更新状态(写操作)
editor.update(() => {
const selection = $getSelection();
if ($isRangeSelection(selection)) {
selection.insertText('Hello');
}
});
关键点:
-
read()内只能读取,不能修改 -
update()内可以读取和修改 - 所有
$开头的函数(如$getRoot、$getSelection)只能在这两个回调中调用
3.2 节点体系
Lexical 的内容由树状节点结构组成:
RootNode
└── ParagraphNode (ElementNode)
├── TextNode ("普通文本")
├── VariableLabelNode (DecoratorNode)
└── TextNode ("更多文本")
核心节点类型:
| 类型 | 说明 | 示例 |
|---|---|---|
RootNode |
根节点,每个编辑器有且仅有一个 | - |
ElementNode |
容器节点,可包含子节点 | ParagraphNode, ListNode |
TextNode |
文本叶子节点 | 普通文本内容 |
DecoratorNode |
装饰器节点,可渲染自定义 React 组件 | 变量标签、提及、表情 |
DecoratorNode 是实现自定义可视化元素的关键,后文会详细讲解。
3.3 命令系统
Lexical 使用命令模式处理用户输入和操作:
// 创建自定义命令
const HELLO_WORLD_COMMAND: LexicalCommand<string> = createCommand();
// 注册自定义命令行为
editor.registerCommand(
HELLO_WORLD_COMMAND,
(payload: string) => {
console.log(payload);
return false;
},
COMMAND_PRIORITY_LOW,
);
// 触发对应命令
editor.dispatchCommand(HELLO_WORLD_COMMAND, 'Hello World!');
Lexical 内置了许多命令,例如:KEY_DOWN_COMMAND、UNDO_COMMAND、INSERT_TAB_COMMAND 等,具体可查看LexicalCommands.ts
命令优先级从高到低:
-
COMMAND_PRIORITY_CRITICAL(4) -
COMMAND_PRIORITY_HIGH(3) -
COMMAND_PRIORITY_NORMAL(2) -
COMMAND_PRIORITY_LOW(1) -
COMMAND_PRIORITY_EDITOR(0)
3.4 节点转换
节点转换是 Lexical 的强大特性,允许监听特定类型节点的变化并自动处理:
editor.registerNodeTransform(TextNode, (textNode) => {
// 每当 TextNode 发生变化时触发
const text = textNode.getTextContent();
// 检测特定模式并转换
if (isVariablePattern(text)) {
const variableNode = $createVariableLabelNode(...);
textNode.replace(variableNode);
}
});
这是实现“输入特定文本自动转换为自定义节点”的核心机制。
3.5 插件架构
Lexical 采用组合式插件设计:
<LexicalComposer initialConfig={config}>
{/* 核心编辑插件 */}
<RichTextPlugin contentEditable={...} placeholder={...} />
{/* 功能插件 */}
<HistoryPlugin /> {/* 撤销/重做 */}
<OnChangePlugin /> {/* 内容变化监听 */}
<VariableLabelPlugin /> {/* 自定义:变量渲染 */}
<VariableLabelPickerPlugin />{/* 自定义:变量选择 */}
</LexicalComposer>
插件通过 useLexicalComposerContext() 获取编辑器实例:
const MyPlugin = () => {
const [editor] = useLexicalComposerContext();
useEffect(() => {
// 使用 editor 注册命令、转换等
}, [editor]);
return null; // 无 UI 的纯逻辑插件
};
4. 整体架构设计
4.1 架构图
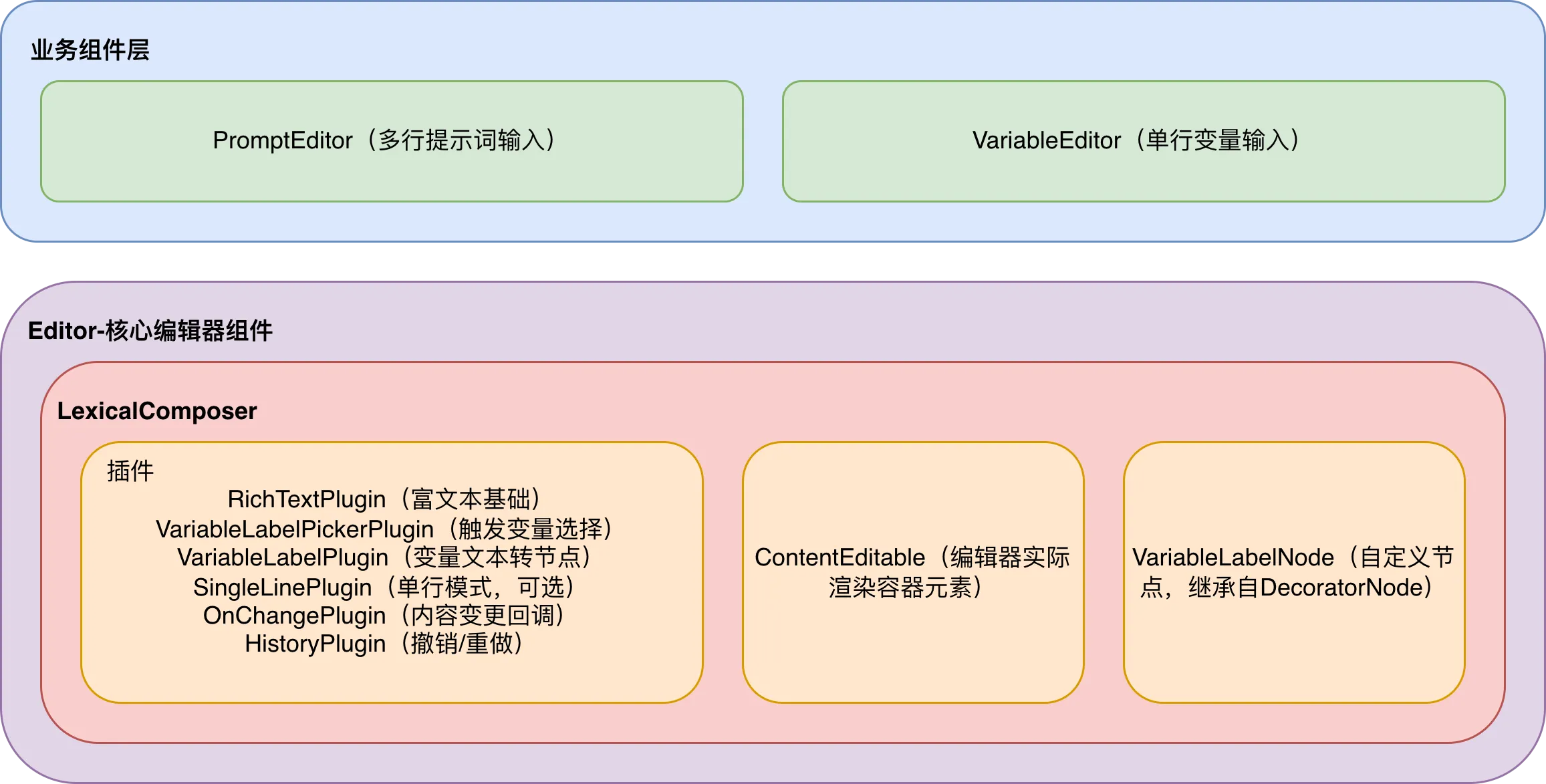
4.2 组件职责划分
| 组件/模块 | 职责 |
|---|---|
PromptEditor |
业务组件,连接 workflow store,处理多行提示词场景 |
VariableEditor |
业务组件,处理单行变量输入场景 |
Editor |
核心组件,封装 Lexical 编辑器和所有插件 |
VariableLabelNode |
自定义节点,渲染为 React 组件,用于反显变量标签 |
VariableLabelPlugin |
自定义插件,监听文本变化,将变量语法转换为变量标签 |
VariableLabelPickerPlugin |
自定义插件,处理 / 触发和变量选择 |
SingleLinePlugin |
自定义插件,限制单行输入 |
4.3 数据流及渲染过程
flowchart TD
Start([开始]) --> Input["用户输入 '/'"]
Input --> Detect["VariableLabelPickerPlugin 检测到 '/'"]
Detect --> Menu["弹出 VariableMenu 菜单"]
Menu --> Select["用户选择变量"]
Select --> Insert["插入文本 '{{#nodeId.varName#}}'"]
Insert --> Transform["VariableLabelPlugin 的 TextNode Transform 检测到变量语法"]
Transform --> CreateNode["创建 VariableLabelNode 替换文本"]
CreateNode --> Render["VariableLabelNode 渲染 VariableLabel 组件"]
Render --> Sync["OnChangePlugin 的 onChange 方法触发,同步文本内容到外部状态"]
Sync --> End([结束])
5. 核心实现详解
5.1 自定义 VariableLabelNode
这是整个方案的核心。我们通过继承 DecoratorNode 来创建一个可以渲染 React 组件的自定义节点:
export class VariableLabelNode extends DecoratorNode<JSX.Element> {
__variableKey: string; // 变量的完整标识,如 {{#nodeId.name#}}
__variableLabel: string; // 显示用的标签
__isSystemVariable: boolean; // 是否为系统变量
static getType(): string {
return "variableLabel";
}
// 返回 React 组件作为节点的渲染内容
decorate(): JSX.Element {
return (
<VariableLabel
variableLabel={this.__variableLabel}
isSystemVariable={this.__isSystemVariable}
/>
);
}
// ... 其他方法
}
关键设计点:
- 继承 DecoratorNode:这使得节点可以渲染任意 React 组件
- **getTextContent()**:返回变量的原始格式文本,确保序列化时能正确还原
- **decorate()**:返回
VariableLabel组件,实现可视化展示
5.2 触发器:/ 唤起变量选择菜单
当用户输入 / 时,我们需要弹出一个变量选择菜单。这里使用 Lexical 官方提供的 LexicalTypeaheadMenuPlugin:
const VariableLabelPickerPlugin = ({ variableGroups }) => {
const [editor] = useLexicalComposerContext();
// 自定义触发匹配:检测用户输入 /
const checkForTriggerMatch = useBasicTypeaheadTriggerMatch("/", {
minLength: 0,
});
// 用户选择变量后的处理逻辑
const onSelectOption = useCallback((selectedOption, nodeToRemove, closeMenu) => {
editor.update(() => {
// 删除触发字符 /
if (nodeToRemove) nodeToRemove.remove();
// 插入变量文本,格式为 {{#nodeId.variableName#}}
selection.insertNodes([
$createTextNode(`{{#${selectedOption.nodeId}.${selectedOption.name}#}}`),
]);
closeMenu();
});
}, [editor]);
// ...
};
工作流程:
- 用户输入
/→checkForTriggerMatch返回匹配结果 - 弹出
VariableMenu组件,显示可用变量列表 - 用户点击选择 →
onSelectOption插入格式化的变量文本 -
VariableLabelPlugin监测到文本变化,自动转换为节点
注意这里我们并不直接插入 VariableLabelNode,而是插入格式化的文本字符串。这是为了解耦选择逻辑和渲染逻辑——文本到节点的转换由下一个插件统一处理。
5.3 文本实体识别与自动转换
VariableLabelPlugin 负责监听文本变化,当发现符合变量格式的文本时,自动将其转换为 VariableLabelNode:
const VariableLabelPlugin = () => {
const [editor] = useLexicalComposerContext();
// 创建变量节点的工厂函数
const createVariableLabelPlugin = useCallback((textNode: TextNode) => {
const text = textNode.getTextContent();
const info = parseVariableTokenInfo(text);
return $createVariableLabelNode(
text,
info?.variableName ?? "",
info?.isSystemVariable ?? false,
);
}, []);
useEffect(() => {
// 注册文本实体转换器
registerLexicalTextEntity(
editor,
getVariableMatchInText, // 正则匹配函数
VariableLabelNode,
createVariableLabelPlugin,
);
}, [editor]);
// ...
};
变量格式通过正则表达式定义:
// 用户变量格式:{{#uuid.variableName#}}
export const USER_VARIABLE_REGEX = new RegExp(
"(\\{\\{)(#)([a-fA-F0-9-]{36}\\.[a-zA-Z0-9_]+)(#)(\\}\\})",
);
// 系统变量格式:{{#system.xxx#}}
export const SYSTEM_VARIABLE_REGEX = new RegExp(
"(\\{\\{)(#)(system\\.[a-zA-Z0-9_]+)(#)(\\}\\})",
);
registerLexicalTextEntity 是核心的转换逻辑,它注册了两个 Transform:
export function registerLexicalTextEntity(editor, getMatch, targetNode, createNode) {
// 1. TextNode → VariableLabelNode 的转换
const textNodeTransform = (node: TextNode) => {
const text = node.getTextContent();
const match = getMatch(text);
if (match === null) return;
// 分割文本节点,将匹配部分替换为目标节点
const [nodeToReplace, remainingNode] = node.splitText(match.start, match.end);
const replacementNode = createNode(nodeToReplace);
nodeToReplace.replace(replacementNode);
// 递归处理剩余文本(可能包含多个变量)
if (remainingNode) textNodeTransform(remainingNode);
};
// 2. 反向转换:当节点内容不再匹配时还原为文本
const reverseNodeTransform = (node) => {
const match = getMatch(node.getTextContent());
if (match === null) {
replaceWithSimpleText(node); // 还原为普通文本
}
};
return [
editor.registerNodeTransform(TextNode, textNodeTransform),
editor.registerNodeTransform(targetNode, reverseNodeTransform),
];
}
5.4 变量标签的可视化渲染
VariableLabel 组件负责将变量以友好的方式呈现给用户:
const VariableLabel = ({ variableLabel, isSystemVariable }) => {
const { Icon, nodeLabel, displayLabel } = useVariableLabelInfo(
variableLabel,
isSystemVariable,
);
return (
<div className="inline-flex items-center rounded-sm bg-bg-primary-4 px-[2px]">
<Icon className="flex-shrink-0" />
<span className="text-text-2-icon">{nodeLabel}</span>
<span className="text-text-4-description">/</span>
<span className="text-primary-default">{displayLabel}</span>
</div>
);
};
会渲染一个可视化变量标签,包含节点图标、节点名称和变量名,效果如下:
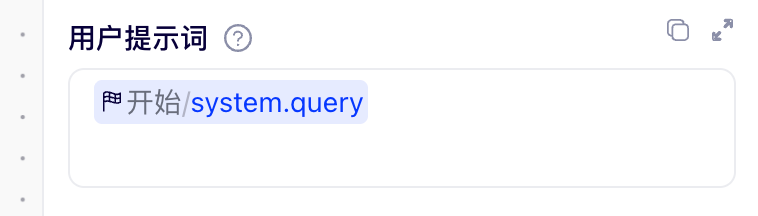
5.5 编辑器单行模式
在某些场景(如 HTTP 节点的 URL 输入、条件节点的表达式输入),我们需要限制编辑器为单行模式:
const SingleLinePlugin = ({ onEnter }) => {
const [editor] = useLexicalComposerContext();
useEffect(() => {
mergeRegister(
// 1. 限制 RootNode 只保留一个段落
editor.registerNodeTransform(RootNode, (rootNode) => {
if (rootNode.getChildrenSize() <= 1) return;
const children = rootNode.getChildren();
const firstChild = children[0];
// 将后续段落的内容合并到第一个段落
for (let i = 1; i < children.length; i++) {
const paragraph = children[i];
paragraph.getChildren().forEach(child => firstChild.append(child));
paragraph.remove();
}
}),
// 2. 拦截 Enter 键
editor.registerCommand(KEY_ENTER_COMMAND, (event) => {
event?.preventDefault();
onEnter?.(); // 可以触发外部回调,如提交表单
return true;
}, COMMAND_PRIORITY_HIGH),
);
}, [editor, onEnter]);
return null;
};
这个插件通过两种机制实现单行限制:
- RootNode Transform:当检测到多个段落时,自动合并为一个
- Command 拦截:阻止 Enter 键创建新段落
5.6 编辑器状态初始化与同步
编辑器内容需要与后端数据同步,我们采用纯文本格式存储。
编辑器状态初始化:
export const textToEditorState = (text = "") => {
const lines = text.split("\n");
const paragraph = lines.map((p) => ({
children: [{ text: p, type: "text", ... }],
type: "paragraph",
//...
}));
return JSON.stringify({
root: { children: paragraph, type: "root", ... },
});
};
编辑器状态同步:
const handleEditorChange = (editorState: EditorState) => {
const text = editorState.read(() => {
return $getRoot()
.getChildren()
.map((p) => p.getTextContent())
.join("\n");
});
onChange(text);
};
由于 VariableLabelNode.getTextContent() 返回原始变量格式({{#nodeId.name#}}),导出的文本可以直接存储,再次加载时会自动转换回节点形式。
6. 总结
本文介绍了基于 Lexical 实现工作流变量输入编辑器的完整方案:
- VariableLabelNode:继承 DecoratorNode 实现渲染自定义变量标签节点
-
VariableLabelPickerPlugin:使用 LexicalTypeaheadMenuPlugin 实现
/触发展示变量选择菜单 - VariableLabelPlugin:通过 Transform 自动识别和转换变量文本
- SingleLinePlugin:可选的单行模式支持
- 插件化架构:功能解耦,各插件职责单一,方便维护和扩展
这套方案适用于:
- 工作流中的变量引用
- 类似评论区的 Mention 功能
- 模板引擎的可视化编辑
- 任何需要“触发字符 + 选择菜单 + 自定义渲染”的场景
最后
欢迎关注【袋鼠云数栈 UED 团队】~ 袋鼠云数栈 UED 团队持续为广大开发者分享技术成果,相继参与开源了欢迎 star
