vxe-gantt vue table 甘特图子任务多层级自定义模板用法
vxe-gantt vue table 甘特图子任务多层级自定义模板用法,通过树结构来渲染多层级的子任务,将数据带有父子层级的数组进行渲染
查看官网:gantt.vxeui.com/
gitbub:github.com/x-extends/v…
gitee:gitee.com/x-extends/v…
安装
npm install xe-utils@3.8.0 vxe-pc-ui@4.10.45 vxe-table@4.17.26 vxe-gantt@4.1.2
// ...
import VxeUIBase from 'vxe-pc-ui'
import 'vxe-pc-ui/es/style.css'
import VxeUITable from 'vxe-table'
import 'vxe-table/es/style.css'
import VxeUIGantt from 'vxe-gantt'
import 'vxe-gantt/lib/style.css'
// ...
createApp(App).use(VxeUIBase).use(VxeUITable).use(VxeUIGantt).mount('#app')
// ...
效果
代码
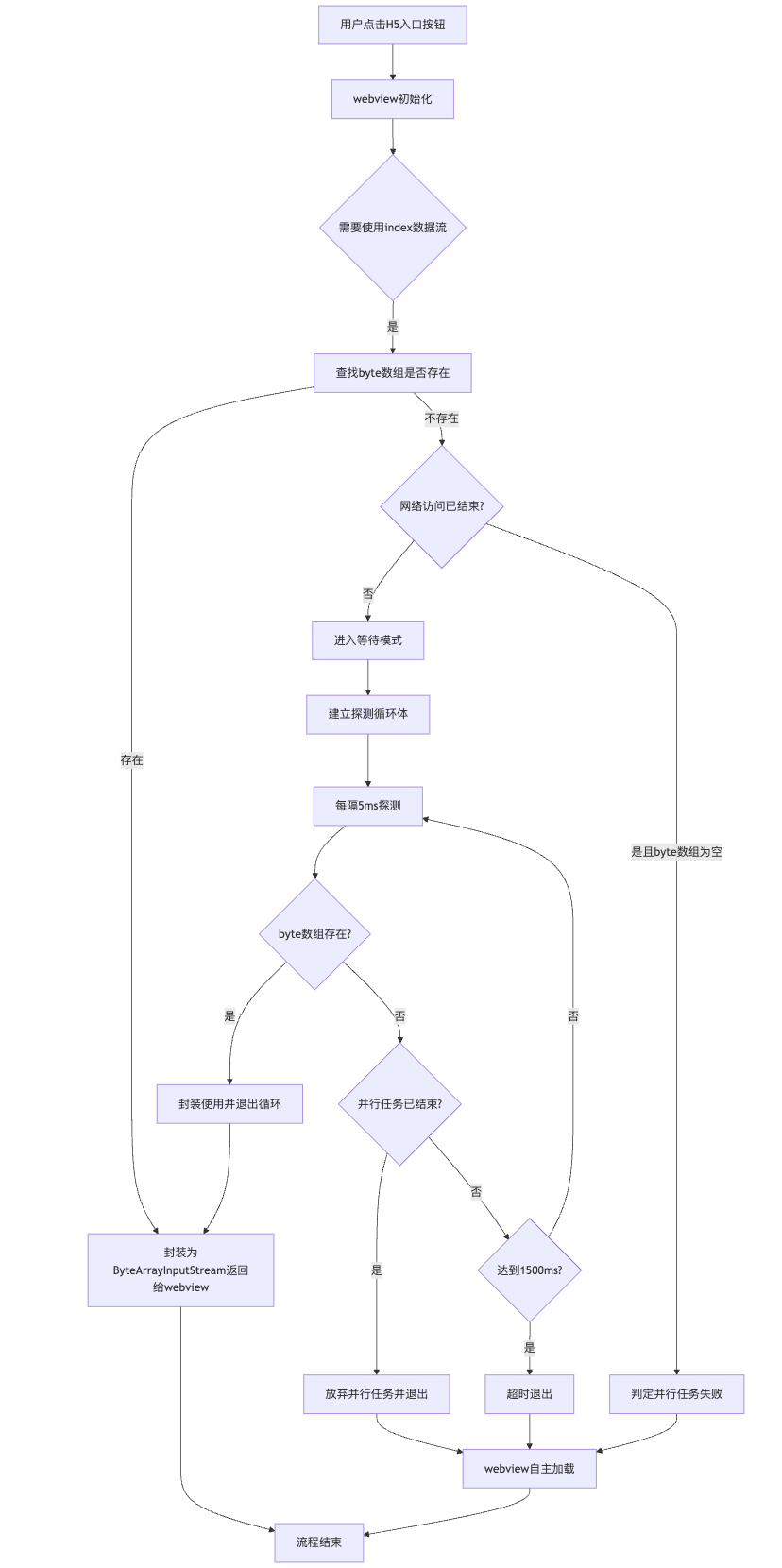
树结构由 tree-config 和 column.tree-node 参数开启,支持自动转换带有父子层级字段的平级列表数据,例如 { id: 'xx', parentId: 'xx' }。只需要设置 tree-config.transform 就可以开启自动转换,通过 task-view-config.scales.headerCellStyle 自定义列头样式
<template>
<div>
<vxe-gantt v-bind="ganttOptions">
<template #task-bar="{ row }">
<div class="custom-task-bar" :style="{ backgroundColor: row.bgColor }">
<div class="custom-task-bar-img">
<vxe-image :src="row.imgUrl" width="60" height="60"></vxe-image>
</div>
<div>
<div>{{ row.title }}</div>
<div>开始日期:{{ row.start }}</div>
<div>结束日期:{{ row.end }}</div>
<div>进度:{{ row.progress }}%</div>
</div>
</div>
</template>
<template #task-bar-tooltip="{ row }">
<div>
<div>任务名称:{{ row.title }}</div>
<div>开始时间:{{ row.start }}</div>
<div>结束时间:{{ row.end }}</div>
<div>进度:{{ row.progress }}%</div>
</div>
</template>
</vxe-gantt>
</div>
</template>
<script setup>
import { reactive } from 'vue'
const ganttOptions = reactive({
border: true,
height: 600,
cellConfig: {
height: 100
},
treeConfig: {
transform: true,
rowField: 'id',
parentField: 'parentId'
},
taskViewConfig: {
tableStyle: {
width: 380
},
showNowLine: true,
scales: [
{ type: 'month' },
{
type: 'day',
headerCellStyle ({ dateObj }) {
// 周日高亮
if (dateObj.e === 0) {
return {
backgroundColor: '#f9f0f0'
}
}
return {}
}
},
{
type: 'date',
headerCellStyle ({ dateObj }) {
// 周日高亮
if (dateObj.e === 0) {
return {
backgroundColor: '#f9f0f0'
}
}
return {}
}
}
],
viewStyle: {
cellStyle ({ dateObj }) {
// 周日高亮
if (dateObj.e === 0) {
return {
backgroundColor: '#f9f0f0'
}
}
return {}
}
}
},
taskBarConfig: {
showTooltip: true,
barStyle: {
round: true
}
},
columns: [
{ field: 'title', title: '任务名称', treeNode: true },
{ field: 'start', title: '开始时间', width: 100 },
{ field: 'end', title: '结束时间', width: 100 }
],
data: [
{ id: 10001, parentId: null, title: '任务1', start: '2024-03-03', end: '2024-03-10', progress: 20, bgColor: '#c1c452', imgUrl: 'https://vxeui.com/resource/productImg/product9.png' },
{ id: 10002, parentId: 10001, title: '任务2', start: '2024-03-05', end: '2024-03-12', progress: 15, bgColor: '#fd9393', imgUrl: 'https://vxeui.com/resource/productImg/product8.png' },
{ id: 10003, parentId: 10001, title: '任务3', start: '2024-03-10', end: '2024-03-21', progress: 25, bgColor: '#92c1f1', imgUrl: 'https://vxeui.com/resource/productImg/product1.png' },
{ id: 10004, parentId: 10002, title: '任务4', start: '2024-03-15', end: '2024-03-24', progress: 70, bgColor: '#fad06c', imgUrl: 'https://vxeui.com/resource/productImg/product3.png' },
{ id: 10005, parentId: 10003, title: '任务5', start: '2024-03-20', end: '2024-04-05', progress: 50, bgColor: '#e78dd2', imgUrl: 'https://vxeui.com/resource/productImg/product11.png' },
{ id: 10006, parentId: null, title: '任务6', start: '2024-03-22', end: '2024-03-29', progress: 38, bgColor: '#8be1e6', imgUrl: 'https://vxeui.com/resource/productImg/product7.png' },
{ id: 10007, parentId: null, title: '任务7', start: '2024-03-28', end: '2024-04-04', progress: 24, bgColor: '#78e6d1', imgUrl: 'https://vxeui.com/resource/productImg/product5.png' },
{ id: 10008, parentId: 10007, title: '任务8', start: '2024-05-18', end: '2024-05-28', progress: 65, bgColor: '#edb695', imgUrl: 'https://vxeui.com/resource/productImg/product4.png' },
{ id: 10009, parentId: 10008, title: '任务9', start: '2024-05-05', end: '2024-05-28', progress: 78, bgColor: '#92c1f1', imgUrl: 'https://vxeui.com/resource/productImg/product6.png' },
{ id: 10010, parentId: 10008, title: '任务10', start: '2024-04-28', end: '2024-05-17', progress: 19, bgColor: '#92c1f1', imgUrl: 'https://vxeui.com/resource/productImg/product5.png' },
{ id: 10011, parentId: 10009, title: '任务11', start: '2024-04-01', end: '2024-05-01', progress: 100, bgColor: '#fd9393', imgUrl: 'https://vxeui.com/resource/productImg/product4.png' },
{ id: 10012, parentId: 10009, title: '任务12', start: '2024-04-09', end: '2024-04-22', progress: 90, bgColor: '#fd9393', imgUrl: 'https://vxeui.com/resource/productImg/product8.png' },
{ id: 10013, parentId: 10010, title: '任务13', start: '2024-03-22', end: '2024-04-05', progress: 86, bgColor: '#fad06c', imgUrl: 'https://vxeui.com/resource/productImg/product11.png' },
{ id: 10014, parentId: null, title: '任务14', start: '2024-04-05', end: '2024-04-18', progress: 65, bgColor: '#8be1e6', imgUrl: 'https://vxeui.com/resource/productImg/product6.png' },
{ id: 10015, parentId: 10014, title: '任务15', start: '2024-03-05', end: '2024-03-18', progress: 48, bgColor: '#edb695', imgUrl: 'https://vxeui.com/resource/productImg/product11.png' },
{ id: 10016, parentId: null, title: '任务16', start: '2024-03-01', end: '2024-03-28', progress: 28, bgColor: '#e78dd2', imgUrl: 'https://vxeui.com/resource/productImg/product12.png' },
{ id: 10017, parentId: null, title: '任务17', start: '2024-03-19', end: '2024-04-02', progress: 36, bgColor: '#c1c452', imgUrl: 'https://vxeui.com/resource/productImg/product5.png' }
]
})
</script>
<style lang="scss" scoped>
.custom-task-bar {
display: flex;
flex-direction: row;
padding: 8px 16px;
width: 100%;
font-size: 12px;
}
.custom-task-bar-img {
display: flex;
flex-direction: row;
align-items: center;
justify-content: center;
width: 70px;
height: 70px;
}
</style>