
前言
vue-plugin-hiprint是作者基于hiprint二次开发的打印插件,虽然带着vue,但是插件为单纯的JavaScript【工具库】。hiprint是未开源的打印插件,可以在官方地址查看部分api的用法和实例项目操作。
vue-plugin-hiprint相关教程可以查看,不简说 的个人主页 - 文章的主页-文章中,最初的文章里包含了教程和常见问题的解答,vue-plugin-hiprint-start项目中有具体的使用实例
本教程整理了自己的使用过程经验和接触到的教程文档,旨在为初次接触到vue-plugin-hiprint开发的人,提供初步的了解和自定义开发的方向
概述
首先对整个插件有一个大概了解,整个打印插件分为三个部分,组件元素面板、设计器和属性面板(此处截图使用的为vue-plugin-hiprint-start示例项目)
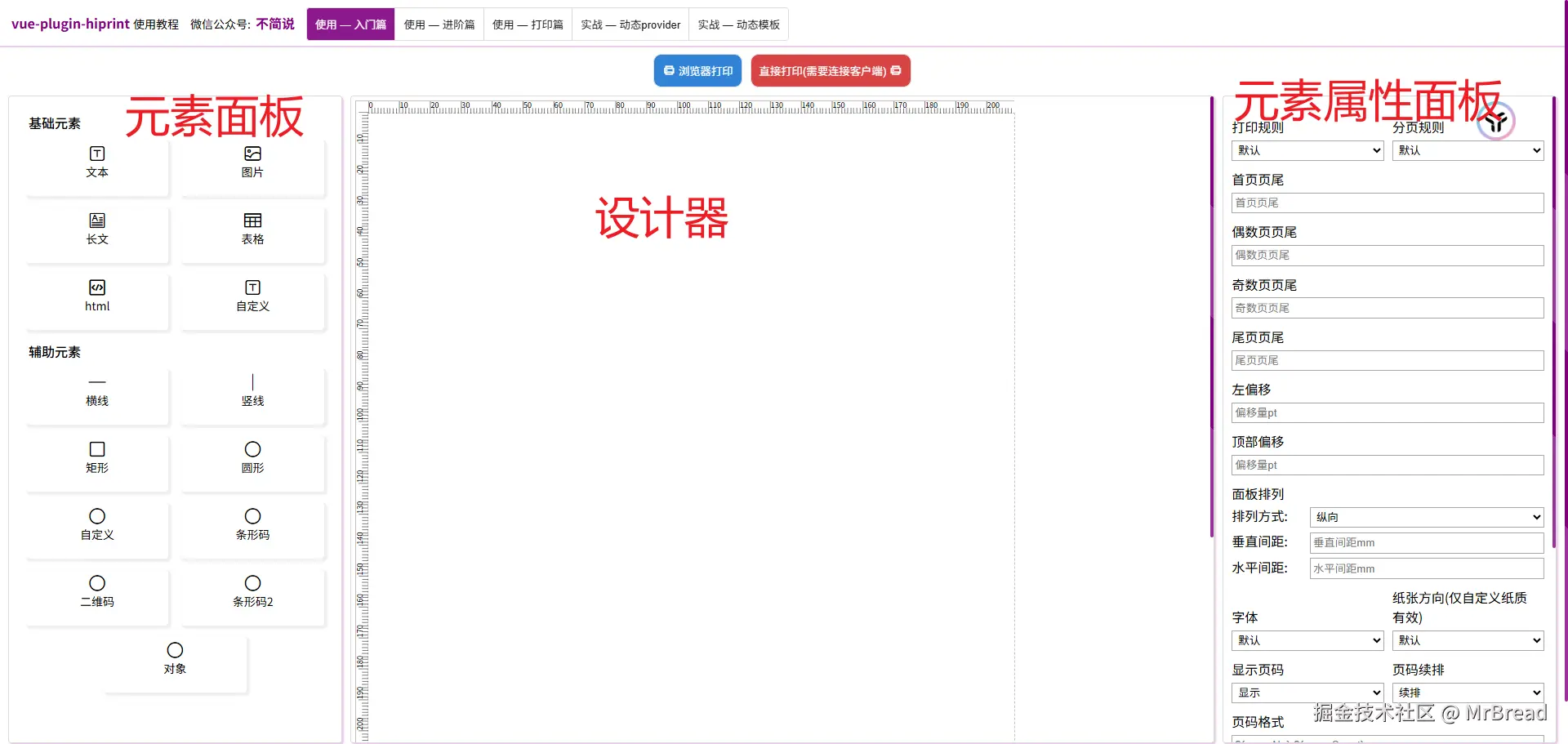
组件元素面板中,已经注册的元素可以直接拖拽的到设计器中,调节大小。可以按住ctrl键进行多选,但打印属性只会显示最后选择的元素。
以下是一个简单的完整代码示例,需要注意几点:1.元素面板的结构是完全自定义的,只需要保证每个元素tid正确和dom可以传递给构建函数 2.hiprint.PrintTemplate和design时,页面中已经渲染了DOM
<div class="flex-row">
<div class="flex-2 left">
<!-- 元素容器,每一个元素是单独的容器,以数组形式传递给buildByHtml -->
<div class="ep-draggable-item item" tid="defaultModule.text">
<i class="iconfont sv-text" />
<span>文本</span>
</div>
</div>
<div class="flex-5 center">
<!-- 设计器的 容器 -->
<div id="hiprint-printTemplate"></div>
</div>
<div class="flex-2 right">
<!-- 元素属性的 容器 -->
<div id="PrintElementOptionSetting"></div>
</div>
</div>
import { hiprint, defaultElementTypeProvider } from 'vue-plugin-hiprint';
/* 左侧元素面板 */
hiprint.init({ providers: [defaultElementTypeProvider()] }); // providers是一个数组,接受组件元素,Provider提供的组件元素,defaultElementTypeProvider是内置Provider。
const items = $('.ep-draggable-item');
hiprint.PrintElementTypeManager.buildByHtml(items);
// 属性面板配置
hiprint.setConfig();
// 自定义配置
// hiprint.setConfig(defaultPanelConfig);
/* 设计器 */
$("#hiprint-printTemplate").empty(); // 先清空, 避免重复构建
hiprintTemplate = new hiprint.PrintTemplate({
settingContainer: "#PrintElementOptionSetting", // 属性面板容器
});
hiprintTemplate.design("#hiprint-printTemplate");
// 打印与预览
hiprintTemplate.print()
hiprintTemplate.getHtml()
左侧组件元素面板构建
组件元素的构建分成两部分,一是provider,用来给hiprint提供组件元素;二是dom构建与绑定。
简单构建
内置组件Provider为hiprint提供元素
import { hiprint, defaultElementTypeProvider } from "vue-plugin-hiprint";
// defaultElementTypeProvider是内置的provider,其中的元素具有tid的属性(具体可以参考自定义provider),比如text的tid属性就是defaultModule.text,这与dom中的tid对应
hiprint.init({ providers: [defaultElementTypeProvider()] })
dom构建与绑定
<!-- DOM的构建是完全自定义,只要保证 1.能够获取到dom 2.dom上存在tid属性 -->
<!--
1.class="ep-draggable-item",使用该类名获取真实dom,在buildByHtml绑定
2.tid的值与defaultElementTypeProvider()中元素的tid值对应
-->
<div class="ep-draggable-item item" tid="defaultModule.text">
<span>文本</span>
</div>
hiprint.PrintElementTypeManager.buildByHtml($(".ep-draggable-item")); // 绑定页面中的dom。($(".ep-draggable-item"),jquery获取dom的写法)
内置元素类型
插件有以下内置类型
text 文本
image 图片
longText 长文本
table 表格
html
hline 横线
vline 竖线
rect 矩形
oval 圆形
barcode 条形码
qrcode 二维码
defaultElementTypeProvider中的tid属性即为 defaultModule.属性类型。比如defaultModule.text
自定义provider
provider的结构为provider = { addElementTypes },所以只需要关注 addElementTypes 的实现
addElementTypes
const addElementTypes = (context: any) => { // context是hiprint调用时传入的参数
context.removePrintElementTypes('providerModule'); // providerModule自定义元素模组名称
context.addPrintElementTypes('providerModule', [ // 添加元素类型的方法
new hiprint.PrintElementTypeGroup('', [ // 创建元素类型
{
tid: 'providerModule.text', // 需要与html上对应的dom上的自定义属性tid对应,即
title: '文本', // 拖拽时出现的文本
type: 'text', // 元素类型,此处的text为内置元素类型
options: {}, // 定义打印设计器上元素的样式、名称等等,这些属性可以在右侧的属性面板上显示,进行在线编辑
},
])
])
}
options
对于大多数的类型可以参考,hiprint的官方-中文文档-左侧菜单从文本到长文。有几个注意点
1.简单说明一下field和fields属性。两个属性填充的都是在预览(getHtml)和打印(print)的获取具体数据字段名,testData在设计的时候显示的测试数据
{
field: 'name',
fields: [{field:'name' ,text:'姓名' },{ field: 'sex', text: '性别' }]
}
const printData = {
name: "123",
sex: "男",
object: {
name: '456'
}
}
hiprint.print(printData)// 对于打印函数,详情看打印模块
1.field属性的值用来填写数据(printData)中的字段名。fields提供可选择的字段名,会将属性面板中对应的字段的输入框变成选择框。
2.print和getHtml可以接受单一数据和数据数组。print([printData])
3.两者可以接受属性访问的方式,field: 'object.name'
2.二维码与条纹码,会根据测试数据或者实际的数据对应生成,二维码在无数据的时候会生成失败。
3.更多的属性
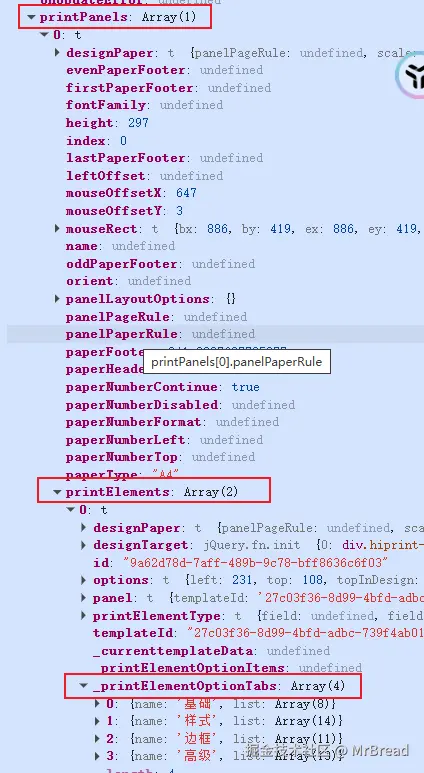
官网的html类型页面是打不开的,或者其他元素有一些属性文档中没有写,可以在设计器中添加该元素然后在console里打印模板的实例,按照printPanels-printElements-_printElementOptionTabs路径,可以在此处查看对应的属性。
(ps:元素的属性值全是默认的情况时,元素上没有printElementOptionTabs)
4.图片
图片元素,在它的属性面板中有一个图片地址的属性,对应options中的src字段,这个属性是在设计时模板上显示的图片地址。在属性面板上有一个选择按钮,点击选择按钮调用的是挂载在模板实例上的onImageChooseClick按钮,其中的参数为target,target.refresh(src)可以更新这个属性;
5.HTML
html实际上使用的options里formatter,返回具体html结构
formatter: "function(t,e,printData){return'<div style=\"height:50pt;width:50pt;background:red;border-radius: 50%;\"></div>';}"
ps:
1.html类型在打印和预览时会有一些出入,比如打印时背景色会被忽略,需要自行调整
@media print {
div {
-webkit-print-color-adjust: exact;
print-color-adjust: exact;
}
}
2.html的formatter与图片的formatter参数相同,与其他元素类型的formatter有一些区别
设计器
基础
$("#hiprint-printTemplate").empty(); // 先清空, 避免重复构建
hiprintTemplate = new hiprint.PrintTemplate({
template: template
settingContainer: "#PrintElementOptionSetting", // 属性面板容器
});
hiprintTemplate.design("#hiprint-printTemplate");
相关概念解释:
模板,模板是由hiprint.PrintTemplate创建的实例,即为页面所展示的包括刻度尺在内的设计器,官网hiprint模板中有相关初始化的参数
面板,一个模板中可以包含多个面板,可以理解为新的一页纸张,但是同一个模板下同时只能展示一个面板。官网hiprint.io面板中有面板的相关参数。页面中的元素是存储在面板中,hiprint.io的demo页面下有一个生成json到textarea按钮。
可以看到template实际上就是一个包含panels字段的json数据,而panels是一个数组。打印模板实例,在原型上可以看到操作面板的方法addPrintPanel、selectPanel、deletePanel
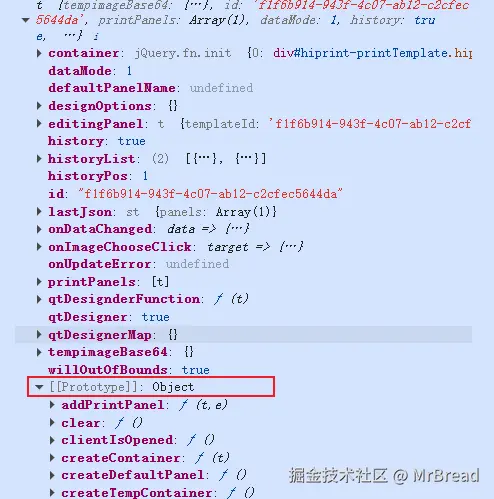
selectPanel(index) 接受的是面板的索引
addPrintPanel(options) 接受的面板参数
deletePanel(index) 接受的是面板的索引
我们可以通过hiprintTemplate.printPanels查看到当前的模版,然后通过上述函数管理面板。也可以通过数组来管理panel,然后通过整体重复构建的,避免使用不清楚的函数,当然这样重复构建的性能可能比较差。
多模版
页面可以同时展示多个模板,只需要多创建一个模板实例,示例参见下方代码。模板容器需要多个,但是属性面板容器可以复用一个,并且元素都是共享的。
$("#hiprint-printTemplate").empty(); // 先清空, 避免重复构建
hiprintTemplate = new hiprint.PrintTemplate({
template: template, // 模板json(object)
settingContainer: "#PrintElementOptionSetting", // 元素参数容器
});
// 构建 并填充到 容器中
hiprintTemplate.design("#hiprint-printTemplate", { grid: true }); // 0.0.46版本新增, 是否显示网格
// ------ 构建多个设计器 ------
// eslint-disable-next-line no-undef
$("#hiprint-printTemplate2").empty(); // 先清空, 避免重复构建
hiprintTemplate2 = new hiprint.PrintTemplate({
template: template2, // 模板json(object)
settingContainer: "#PrintElementOptionSetting", // 元素参数容器
});
// 构建 并填充到 容器中
hiprintTemplate2.design("#hiprint-printTemplate2");
API补充
官方的文档中只有一部分API的文档,对于其它API在使用的过程中,需要自己去查看实例、原型和对应的源码。可以在console中打印模板实例或者hiprint,找到对应的方法(比如selectPanel),在[[FunctionLocation]]找到对应的方法。
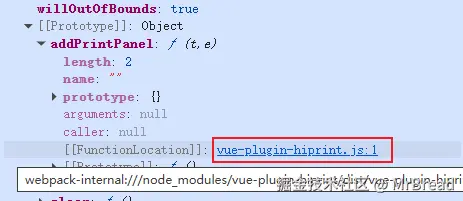
ps:如果源码没有格式化,在控制台底部有格式化的功能
举一个例子来说,setPaper设置纸张大小,setPaper(width, height)
// A4纸张大小
{
width: 210,
height: 297,
},
但是,setPaper方法只能设置当前的展示的面板的纸张大小,不会影响其它面板。查看它的源码发现它只调用了editPanel.resize,只改变了当前编辑的panel,所以如果需要统一修改可以获取hiprintTemplate.printPanels,对所有的panel执行resize方法。
部分API补充简述
| 名称 |
参数 |
说明 |
| setElsAlign |
type: left|right|vertical|top|horizontal|
bottom|distributeHor|distributeVer |
对齐函数,在面板上选中元素时,调用此函数可以进行对齐操作。 |
| zoom |
number: float |
放大缩小当前面板 |
| selectPanel |
number: int |
切换当前显示的面板,入参是面板在printPanels中的索引 |
| update |
template |
更新模板,入参为满足template格式的json |
| getSelectEls |
|
返回选中的元素,按住ctrl可以多选 |
属性面板
属性面板的各种配置都是在setConfig函数完成,不传参数则会使用默认参数。config中有两种字段:
1.optionItems,可以理解为属性组件库,为属性配置对应样式和dom
2.元素类型字段,在此处配置该元素选中是属性面板的显示
hiprint.setConfig(config);
config = { // 除了optionItems外,其它的字段名都是模板上显示的各种元素的类型(包括面板),
optionItems: [], // 详情见下
text: {
tabs: [ // 属性面板具体每一个tab下的属性,按照printElementOptionTabs中的顺序
{ options: [] },
{ options: [] },
{ options: [] },
{
name: '基础',
replace: true, // 可以替换掉原来的标签
options: [// 属性面板上每一项的显示,默认可以在printElementOptionTabs中查找,自定义的name与optionItems中对应
{ name: 'textType', hidden: true },
{ name: 'tableTextType', hidden: true },
{ name: 'barcodeMode', hidden: true },
{ name: 'barWidth', hidden: true },
{ name: 'barAutoWidth', hidden: true },
{ name: 'qrCodeLevel', hidden: true },
],
},
],
},
panel: {// 控制panel的属性在属性面板的显示,supportOptions下配置
supportOptions: [
{ name: 'firstPaperFooter', hidden: true },
{ name: 'evenPaperFooter', hidden: true },
{ name: 'oddPaperFooter', hidden: true },
{ name: 'lastPaperFooter', hidden: true },
{ name: 'panelLayoutOptions', hidden: true },
]
}
}
optionItems,以name做区分与被引用。如果与内置的name相同,则会替换掉原来的属性组件;自定义的name可以在tabs的options中引入使用。
其内部通过class="auto-submit"绑定事件,执行getValue或者setValue。
// optionItems
export default (function () {
function t() {
this.name = 'paperNumberDisabled';
}
return (
(t.prototype.createTarget = function (_t, i) { // i可以访问元素的options
this.target = $(
`<div class="hiprint-option-item">\n <div class="hiprint-option-item-label">\n 显示页码\n </div>\n <div class="hiprint-option-item-field">\n <select class="auto-submit">\n <option value="" >显示</option>\n <option value="true" >隐藏</option>\n </select>\n </div>\n </div>`,
)
return this.target;
}),
(t.prototype.getValue = function () { // getValue在每次赋值属性面板的时候,会被调用
if ('true' == this.target.find('select').val()) return !0;
}),
(t.prototype.setValue = function (t) { // setValue每次展示属性绑定的元素的属性面板时,会执行一次
this.target.find('select').val((null == t ? '' : t).toString());
}),
(t.prototype.destroy = function () {
this.target.remove();
}),
t
);
})();
打印与预览
单模板
单模板可以直接通过模板实例调用打印函数。打印数据,可以传递单一数据hiprintTemplate.print(printData),也可以像示例一样传递数组
// 打印数据,key 对应 元素的 字段名
let printData = { name: "CcSimple", src: "/favicon.ico", object: { name: "对象字段值" } };
// 参数: 打印时设置 左偏移量,上偏移量
let options = { leftOffset: -1, topOffset: -1 };
// 扩展
let ext = {
callback: () => {
console.log("浏览器打印窗口已打开");
},
styleHandler: () => {
// 重写 文本 打印样式
return `
<link rel="stylesheet" href="/print-lock.css" />
<style>
@media print {
div {
-webkit-print-color-adjust: exact;
print-color-adjust: exact;
}
}
</style>
`;
},
};
hiprintTemplate.print([printData], options, ext);
需要注意的是,打印的时候可能出现元素都重叠在第一页上,这个时候需要引入print-lock.css文件,这个文件可以在node_modules/vue-plugin-hiprint/dist中找到
多模板
hiprint也是可以实现多模板打印的,创建两个模板实例,对应绑定不同的容器即可(元素属性面板可以绑定同一个)。
hiprint.print({
templates: [
{ template: hiprintTemplate, data: printData, options: { topOffset: 100 } },
{ template: hiprintTemplate2, data: [printData2, printData3] },
],
});
多模版引入print-lock.css文件,需要在html中静态引入。
其它注意点
1.使用浏览器打印的时候,可能会出现浏览器自动添加的页脚与页眉。1.这说明内容没有填满整张纸,使用@page { margin: 0cm; }可以不展示自动的页脚与页眉。 2.panel中的纸张大小与浏览器打印设置中的纸张大小不匹配,不传递panel纸张大小或者让两者匹配,即可消除掉。
ps:panel中的纸张大小会被渲染为 @page { size: width height },实际上就是size与打印设置纸张的匹配
2.关于其它打印时的样式问题,在实际调用一次print后,浏览器会渲染一个id为hiwprint_iframe的iframe元素,这就是实际被打印的页面。可以拷贝出来寻找样式问题。
总结
核心价值:
- 🖨️ 可视化拖拽设计
- 🎨 高度可定制,从元素到属性面板都能自由扩展
- 🔧 多模板支持,应对复杂打印场景
使用建议:
- 初次使用建议从内置元素开始,逐步深入自定义
- 遇到样式问题优先检查
print-lock.css 和打印媒体查询
- 当前文档和官网文档中的API应该足够满足大多数的需求,但是还是需要善用浏览器控制台探索未文档化的 API
👍创作不易,如有错误请指正,感谢观看!记得点个赞哦!👍
 这款《火柴人:终极爆裂 (Stickman: Ultimate Burst)》目前已经具备了相当完整且爽快的 Roguelite 射击与平台跳跃体验。以下是当前版本的功能总结:
这款《火柴人:终极爆裂 (Stickman: Ultimate Burst)》目前已经具备了相当完整且爽快的 Roguelite 射击与平台跳跃体验。以下是当前版本的功能总结: