1. 示例与调试环境
示例代码(Vue@2.6.14)
<body>
<div id="app">
<h1>组件化机制</h1>
<p>{{msg}}</p>
<comp />
</div>
<script src="../../dist/vue.js"></script>
<script>
Vue.component('comp', {
template: '<div>I am a component</div>'
})
const app = new Vue({
el: '#app',
data:{
msg: 'hello vue'
}
})
</script>
</body>
源码调试环境搭建
-
获取Vue.js源码,v2.6.14
-
安装项目依赖
npm install(安装phantom.js时可终止)
-
安装构建工具rollup
npm i -g rollup
-
配置构建脚本
修改package.json中的dev脚本,添加--sourcemap,在开发模式下生成sourcemap
"scripts": {
"dev": "rollup -w -c scripts/config.js --sourcemap --environment TARGET:web-full-dev"
}
-
构建Vue.js
运行行开发命令npm run dev,构建完成后,会在dist目录下生成带源码映射的vue.js文件
-
创建测试页面并引入构建好的vue.js
-
调试Vue.js源码
在浏览器中打开测试页面,然后打开开发者工具进行调试
2. 从构建配置寻找源码入口
2.1. 构建命令分析
"dev": "rollup -w -c scripts/config.js --sourcemap --environment TARGET:web-full-dev"
-
-c scripts/config.js=> 指定Rollup配置文件路径
-
--environment TARGET:web-full-dev=> 设置环境变量TARGET为web-full-dev
2.2. 查看Rollup配置文件
-
打开scripts/config.js
-
找到web-full-dev相关配置
const builds = {
...
// Runtime+compiler development build (Browser)
'web-full-dev': {
entry: resolve('web/entry-runtime-with-compiler.js'),
dest: resolve('dist/vue.js'),
format: 'umd',
env: 'development',
alias: { he: './entity-decoder' },
banner
},
...
}
2.3. 定位入口文件
从配置中可以看出入口文件为:
entry: resolve('web/entry-runtime-with-compiler.js')
-
先看resolve函数的定义:
const aliases = require('./alias')
const resolve = p => {
// 将传入的web/entry-runtime-with-compiler.js通过/分割成数组
// 然后取第一个元素设置为base,即web
const base = p.split('/')[0]
if (aliases[base]) {
return path.resolve(aliases[base], p.slice(base.length + 1))
} else {
return path.resolve(__dirname, '../', p)
}
}
2. 接着来到scripts/alias.js
module.exports = {
...
web: resolve('src/platforms/web'),// 找到web对应的真实路径
...
}
3. 于是便得到入口文件的真实路径
src/platforms/web/entry-runtime-with-compiler.js
2.4. 通过追踪入口文件依赖关系找到核心入口
💡 主线不要乱,粗略地看细节,先理清调用链
打开代码文件后,先把方法都折叠起来,了解大致结构
🚂 src/platforms/web/entry-runtime-with-compiler.js
⬇️ import Vue from './runtime/index'
🚂 src/platforms/web/runtime/index.js
⬇️ import Vue from 'core/index'
🚂 /src/core/index.js
⬇️ import Vue from './instance/index'
🚂 src/core/instance/index.js
➡️ function Vue () { ... } 找到Vue构造函数
3. Vue的渐进式构建
Vue并非一次性定义完成,而是通过多个模块逐步增强功能
3.1. 原型方法混入
🚂 src/core/instance/index.js
先定义一个空函数,只是定义,还没执行
function Vue (options) {
...
this._init(options)// 初始化入口
}
这里只是一个空函数,还没有原型方法:
按顺序混入原型上的方法和属性
initMixin(Vue) ➡️ 添加_init方法
stateMixin(Vue) ➡️ 添加 $data``$props属性 & $set``$delete``$watch方法
eventsMixin(Vue) ➡️ 添加 $on``$once``$off``$emit方法
lifecycleMixin(Vue) ➡️ 添加 _update``$forceUpdate``$destroy方法
renderMixin(Vue)
- 添加
$nextTick方法
installRenderHelpers(Vue.prototype)
-
- 为Vue实例添加渲染相关的工具方法(_s _l _v等,注意,此时还没有添加_c)
- 🚂
src/core/instance/render-helpers/index.js
导出基础Vue
此时只有原型方法
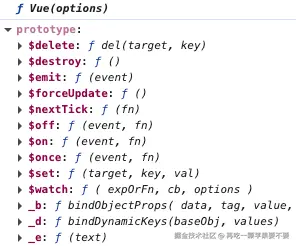
3.2. 静态方法添加
🚂 src/core/index.js
import Vue from './instance/index'// 导入上一步导出的基础Vue类
initGlobalAPI(Vue);// 全局静态API初始化入口
🚂 src/core/global-api/index.js
-
初始化全局配置对象Vue.config
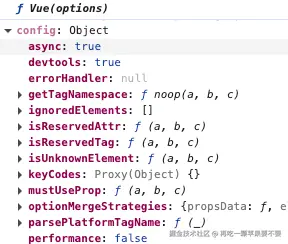
-
添加内部使用的工具函数
Vue.util = {
warn,
extend,
mergeOptions,
defineReactive
}
-
添加Vue.set Vue.delete Vue.nextTick
-
初始化选项对象
Vue.options = Object.create(null)
-
初始化组件、指令、过滤器的存储结构
// ['component', 'directive', 'filter']
ASSET_TYPES.forEach(type => {
Vue.options[type + 's'] = Object.create(null)
})
-
内置组件 <keep-alive>

-
初始化全局API
initUse(Vue)=>Vue.use
initMixin(Vue)=>Vue.mixin
initExtend(Vue)=>Vue.extend
-
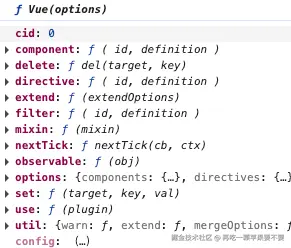
资源注册
initAssetRegisters(Vue)
最后,导出完整的Vue类:
3.3. 平台适配完善
🚂src/platforms/web/runtime/index.js
导入上一步导出的Vue类
-
添加web平台特定配置
Vue.config.mustUseProp = mustUseProp
Vue.config.isReservedTag = isReservedTag
Vue.config.isReservedAttr = isReservedAttr
Vue.config.getTagNamespace = getTagNamespace
Vue.config.isUnknownElement = isUnknownElement
-
安装web平台相关指令和组件
// model,show
extend(Vue.options.directives, platformDirectives)
// Transition,TransitionGroup
extend(Vue.options.components, platformComponents)
-
安装 __patch__ 函数 ❗
-
安装 $mount方法❗
-
导出Web平台适配后的Vue
3.4. 编译器集成
🚂 src/platforms/web/entry-runtime-with-compiler.js
导入上一步平台适配后的Vue
-
缓存原始的$mount方法 const mount = Vue.prototype.$mount
-
重写$mount方法,支持模板编译
const mount = Vue.prototype.$mount // 缓存原始方法
Vue.prototype.$mount = function (el, hydrating) {
// 处理模板编译逻辑
if (!options.render) {
let template = options.template
if (!template && el) {
template = getOuterHTML(el) // 将 DOM 转为模板字符串
}
if (template) {
// 编译模板得到 render 函数
const { render, staticRenderFns } = compileToFunctions(template, {
delimiters: options.delimiters,
comments: options.comments
}, this)
options.render = render
}
}
// 调用原始 mount 方法
return mount.call(this, el, hydrating)
}
最终导出给用户使用的Vue
4. 从new Vue()到挂载
4.1. 全局组件注册
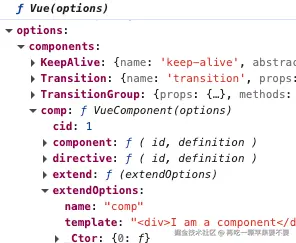
Vue.component('comp', { // 🚂 调用initGlobalAPI中定义的Vue.component
template: '<div>I am a component</div>'
})
4.1.1. 执行过程
- 调用
initGlobalAPI中定义的Vue.component方法
- 将组件配置存入
Vue.options.components
- ⚠️ 此时只是注册定义,尚未创建组件构造函数
4.1.2. 相关代码
🚂src/core/global-api/assets.js
// src/core/global-api/assets.js
function initAssetRegisters(Vue) {
ASSET_TYPES.forEach(type => {
Vue[type] = function(id, definition) {
if (!definition) {
return this.options[type + 's'][id]
}
// 注册组件
if (type === 'component' && isPlainObject(definition)) {
definition.name = definition.name || id
definition = this.options._base.extend(definition)
}
this.options[type + 's'][id] = definition
return definition
}
})
}
执行完后
4.2. Vue实例化入口
const app = new Vue({
el: '#app',
data: {
msg: 'hello vue'
}
})
当执行new Vue(options)时,Vue内部会立即调用_init
🚂core/instance/index.js
const app = new Vue({
el: '#app',
data: {
msg: 'hello vue'
}
})
4.3. _init方法
❗初始化流程开始
🚂src/core/instance/init.js
4.3.1. 选项合并
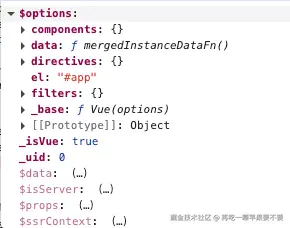
目的: 将用户传入的实例配置与Vue构造函数自身的全局配置(🌰全局组件/混入/指令/...)进行合并,生成最终的实例属性vm.$options
vm.$options = mergeOptions(
resolveConstructorOptions(vm.constructor),// 解析Vue全局配置
options || {},// 用户实例配置
vm// 当前Vue实例
)
合并后: vm.$options包含了所有可用于当前实例的选项
4.3.2. 核心功能初始化
此阶段按特定顺序初始化实例的核心功能模块,确保后续模块能访问先初始化的内容
initLifecycle(vm)
-
- 初始化组件实例的生命周期相关属性
- 建立父子组件关系链(
$parent $children ...)等
initEvents(vm)
-
- 初始化事件系统
- 处理父组件传递的自定义事件(
vm.$listeners),为后续的$on $emit等方法提供支持
-
initRender(vm)⚠️ 关键步骤
-
- 初始化与渲染相关的属性和方法
- 挂载
vm._createElement vm._c
initRender(vm) {
// 供内部模板编译生成的render函数使用
vm._c = (a, b, c, d) => createElement(vm, a, b, c, d, false)
// 供用户手写render函数时使用
vm.$createElement = (a, b, c, d) => createElement(vm, a, b, c, d, true)
}
// 两者的区别
// vm._c:会对子节点进行简单的规范化处理,因为模板编译时已经处理过大部分情况
// vm.$createElement:会进行更全面的规范化处理,确保用户编写的VNode结构正确
⚠️ 此时安装了_c
4.3.3. 调用beforeCreate钩子
callHook(vm, 'beforeCreate')
此时状态:事件、渲染函数已就绪,但数据响应式尚未建立,即无法访问到data、computed等数据
4.3.4. 初始化inject
initInjections(vm)
解析并建立inject选项,使得当前实例可以注入来自祖先组件提供的数据
4.3.5. 初始化状态
initState(vm) ❗️响应式系统核心
目的: 建立Vue的响应式数据系统
初始化顺序:props => methods => data => computed => watch
取出options选项,按照以上顺序,如果存在,则初始化之
❓ 为什么是按这个顺序
确保后初始化的数据能访问先初始化的数据
- props - 接收父组件传递的数据(最先,供其他选项使用)
- methods - 定义方法,供data中方法调用
- data - 整个响应式系统的起点,将数据对象转为响应式,建立getter/setter =>
observe(data)
- computed - 定义计算属性,创建惰性求值的Watcher
- watch - 监听器,依赖前面所有数据,为每个处理函数创建watcher =>
createWatcher
4.3.6. 初始化provide
initProvide(vm)
解析provide选项,为后代组件提供数据
4.3.7. 调用created钩子
callHook(vm, 'created')
此时状态:数据响应式系统已完全建立,实例已准备就绪,但尚未开始DOM的挂载和渲染
4.3.8. 自动挂载判断
if (vm.$options.el) {// 如果设置了el选项,直接挂载
vm.$mount(vm.$options.el)// 启动挂载流程
}
4.4. 渲染&挂载阶段
4.4.1. $mount的扩展
4.4.1.1. 回到入口文件
🚂src/platforms/web/entry-runtime-with-compiler.js
可以看到
const mount = Vue.prototype.$mount
Vue.prototype.$mount = function () {
...
return mount.call(this, el, hydrating)
}
❓ 这里做了什么? => 扩展$mount方法
- 缓存原始
$mount
- 重定定义
$mount => 扩展
- 调用原始
$mount,执行默认挂载
❓ 为什么这样设计?
✅ 功能分离:编译逻辑与挂载逻辑解耦
✅ 向后兼容:确保核心功能不受破坏
✅ 灵活配置:运行时版本可以直接使用原始方法
4.4.1.2. 模板处理链与优先级
Vue.prototype.$mount = function () {
// 1.处理el
el = el && query(el)
const options = this.$options
// 2. 模板处理链: el -> template -> render
if (!options.render) {
let template = options.template
if (template) {
// 处理各种template(字符串/DOM元素/...)
} else if (el) {
// 没有template,从el获取模版 (🌰 id="app"的div内容)
template = getOuterHTML(el)
}
// 3.如果存在template,则编译它,获取render函数
if (template) {
const { render, staticRenderFns } = compileToFunctions(template, {
// 编译选项...
}, this)
// 4.将结果保存到选项中,供后续使用
options.render = render
options.staticRenderFns = staticRenderFns
}
}
// 5.调用原始$mount 执行默认挂载
return mount.call(this, el, hydrating)
}
优先级说明:
- render函数(最高)-> 直接使用
- template选项 -> 编译为render函数
- el选项(最低)-> 提取对应DOM的HTML并编译
4.4.2. 模板编译过程
4.4.2.1. 编译流程概览
➡️ compileToFunctions 🚂 src/platforms/web/compiler/index.js
const { compile, compileToFunctions } = createCompiler(baseOptions)
➡️ createCompiler 🚂 src/compiler/index.js
4.4.2.2. 核心编译函数
import { createCompilerCreator } from './create-compiler'
export const createCompiler = createCompilerCreator(function baseCompile(
template: string, // 要编译的模版字符串
options: CompilerOptions // 编译选项,可以配置一些编译时的行为
): CompiledResult {
// 1.解析 template=>AST
const ast = parse(template.trim(), options)
// 2.优化 标记静态节点
if (options.optimize !== false) {
optimize(ast, options)
}
// 3.生成render函数 AST=>render函数
const code = generate(ast, options)
// 返回一个CompiledResult对象,包含:
// ast 生成的抽象语法树,可以用于服务端渲染或其他分析
// render 主渲染函数的代码字符串
// staticRenderFns 一个数组,包含静态子树的渲染函数代码字符串,结果恒定,缓存
return {
ast,
render: code.render,
staticRenderFns: code.staticRenderFns
}
})
4.4.2.3. 编译结果示例
function render() {
with(this) {
return _c('div',
{ attrs: { "id": "app" } },
[
_c('h1', [_v("组件化机制")]),
_c('p', [_v(_s(msg))]),
_c('comp')
],
1 // 规范化类型标识
)
}
}
工具函数说明:
-
_c:createElement,创建VNode
-
_v:createTextVNode,创建文本VNode
-
_s:toString,值转换为字符串
4.4.3. 运行时挂载:mountComponent
4.4.3.1. 调用原始$mount方法
🚂 src/platforms/web/runtime/index.js
Vue.prototype.$mount = function (el, hydrating) {
el = el && inBrowser ? query(el) : undefined
// 调用核心挂载方法, Vue实例真正开始挂载的地方
return mountComponent(this, el, hydrating)
}
4.4.3.2. 核心挂载逻辑
🚂 src/core/instance/lifecycle.js
function mountComponent (vm, el, hydrating) {
// 1.保存DOM引用
vm.$el = el
// 2.正式挂载前,触发beforeMount钩子
callHook(vm, 'beforeMount')
// 3.定义组件更新函数 updateComponent(❗️核心)
const updateComponent = () => {
// 首先执行_render => vdom
vm._update(vm._render(), hydrating)
}
// 4.创建Watcher实例,触发首次渲染(响应式系统的关键连接点)
// 对于子组件,它们的mounted钩子会在其自身的vnode被插入到父DOM树时才触发
new Watcher(vm, updateComponent, noop, ...)
// 5.触发mounted钩子,仅根实例
if (vm.$vnode == null) {
vm._isMounted = true
callHook(vm, 'mounted')
}
// 6.返回实例本身,支持链式调用
return vm
}
关于updateComponent的两个关键步骤
vm._render()
调用实例的_render方法,执行定义的render函数或模板编译得到的render函数,返回一个vnode
vm._update(vm._render(), hydrating)
调用实例的_update方法,接收_render产生的vnode,进行patch算法,将vnode转为真实DOM并挂载或更新到页面
4.4.3.3. 挂载执行时序
mountComponent()
↓
new Watcher(vm, updateComponent) // 创建渲染Watcher
↓
Watcher.get() → pushTarget(this) // 开始依赖收集
↓
updateComponent() // 执行更新函数
↓
vm._render() // 生成VNode树
↓
vm._update() // DOM更新
↓
vm.__patch__() // 创建/更新真实DOM
↓
popTarget() // 结束依赖收集
↓
callHook(vm, 'mounted') // 挂载完成
4.4.4. 渲染Watcher
4.4.4.1. Watcher的核心职责
- 解析表达式:处理计算属性和监听器
- 收集依赖:建立视图与数据的关联
- 触发回调:数据变化时执行更新
4.4.4.2. 首次渲染的执行流程
4.4.4.2.1. 触发时机
在mountComponent时创建Watcher时,Watcher.get()会同步执行,立即触发首次渲染
function mountComponent (vm, el, hydrating)
...
new Watcher(vm, updateComponent, noop, {
before () {
if (vm._isMounted && !vm._isDestroyed) {
callHook(vm, 'beforeUpdate')
}
}
}, true /* isRenderWatcher */)
...
}
4.4.4.2.2. 执行流程
🚂 src/core/observer/watcher.js
// 💡 Watcher构造函数中的关键逻辑
constructor(vm, expOrFn, ...){
this.vm = vm // 保存组件引用
// 如果是render watcher,记录到vm上
if (isRenderWatcher) {
vm._watcher = this// 便于实例管理和调试
}
...
// 处理getter 保存更新函数
if (typeof expOrFn === 'function') {
// 如果传入的参数2=>expOrFn是函数,则表示它是组件的更新函数
// 即updateComponent
this.getter = expOrFn
}else{
...
}
this.value = this.get()// 立即执行首次渲染
}
// 💡 依赖收集核心
get() {
// 设置当前Watcher实例为全局的依赖收集目标
pushTarget(this) // 即Dep.target = this(当前Watcher),在后续的属性访问中,相关的Dep就知道要收集哪个Watcher
let value
const vm = this.vm
try{
// 触发getter,即updateComponent
value = this.getter.call(vm, vm)
} finally {
popTarget() // 恢复上一个 Watcher
this.cleanupDeps() // 清理依赖
}
return value
}
4.4.5. 虚拟DOM的创建与处理
4.4.5.1. 虚拟DOM的生成
核心方法: _render() 执行render函数并返回对应的vnode
🚂 src/core/instance/render.js
Vue.prototype._render = function (): VNode {
// 保存当前Vue实例的引用
const vm: Component = this
// 从实例配置中获取render方法和父组件的vnode(父组件创建的,代表当前组件的占位符vnode)
const { render, _parentVnode } = vm.$options
// 设置父vnode,根实例为null
vm.$vnode = _parentVnode
// 🔥 核心调用:执行渲染函数,生成当前组件的 VNode 树
let vnode
try {
vnode = render.call(vm._renderProxy, vm.$createElement)
} ...
// 设置父级关系,将当前VNode的parent指向_parentVnode,完善vnode树结构
vnode.parent = _parentVnode
// 返回最终生成的虚拟DOM节点
return vnode
}
关键参数:
-
vm._renderProxy执行上下文,开发环境有代理检查,生产环境即vm
vm.$createElement
-
- 创建vnode的函数
-
initRender()时已经挂载到实例上的
4.4.5.2. createElement的设计
设计模式:外层包装+内层实现
🚂 src/core/vdom/create-element.js
- 外层:参数标准化和重载处理
export function createElement(context, tag, data, children, ...) {
// 参数重载:支持多种调用方式
if (Array.isArray(data) || isPrimitive(data)) {
// h('div', ['hello']) → h('div', undefined, ['hello'])
normalizationType = children
children = data
data = undefined
}
// 调用核心实现
return _createElement(context, tag, data, children, normalizationType)
}
2. 内层:vnode创建核心逻辑
// 真正返回vnode的函数
export function _createElement (context, tag, data, children, normalizationType) {
// 1. 子节点标准化
if (normalizationType === ALWAYS_NORMALIZE) {
children = normalizeChildren(children)
}
// 2. 根据tag类型创建对应DOM
let vnode, ns
if (typeof tag === 'string') {
// 处理字符串标签(HTML 元素、组件、...)
if (config.isReservedTag(tag)) {
// 平台内置元素 div/p/...
vnode = new VNode(config.parsePlatformTagName(tag), data, children,undefined, undefined, context)
} else if ((!data || !data.pre) && isDef(Ctor = resolveAsset(context.$options, 'components', tag))) {
// 已注册的组件,创建组件占位符vnode
vnode = createComponent(Ctor, data, context, children, tag)
} else {
// 未知标签或命名空间元素
vnode = new VNode(tag, data, children,undefined, undefined, context)
}
} else {
// 组件选项/构造函数
vnode = createComponent(tag, data, context, children)
}
return vnode
}
4.4.5.3. createComponent:组件占位符的创建
在执行_createElement的过程中,当识别到一个组件时(已注册的组件名或直接传入的组件选项/构造函数),会调用createComponent创建组件占位符vnode。
❗️注意:createComponent只负责创建一个代表该组件的占位符vnode,而不是立即实例化组件本身。
4.4.5.3.1. 设计思想
延迟渲染&性能优化
-
懒加载:组件占位符vnode只包含元数据(构造函数/Props/...)。真正的组件实例化、渲染还有挂载被延迟到后续的patch阶段才执行
-
性能优化: 这种组件级懒渲染方式带了巨大的性能优势,🌰 对于
v-if="false"的组件,Vue在首次渲染的时候只需创建一个轻量的占位符vnode,完全跳过内部复杂的实例化、渲染和DOM操作流程
- 支持异步组件
4.4.5.3.2. 主要逻辑
🚂 src/core/vdom/create-component.js
export function createComponent(Ctor, data, context, children, tag) {
// 确保Ctor是构造函数
const baseCtor = context.$options._base // 获取Vue构造函数
if (isObject(Ctor)) {
// 如果传入的是组件选项对象,则转换为构造函数
Ctor = baseCtor.extend(Ctor)
}
...
// 将组件的生命周期逻辑(init, prepatch等)以钩子函数的形式挂载到 vnode.data.hook上
// 在后续的 patch过程中,当处理到这个组件 VNode 时,会调用相应的钩子(如 init)来真正创建组件实例
installComponentHooks(data)
// 创建组件占位符vnode
const vnode = new VNode(...)
return vnode
}
4.4.5.3.3. 组件占位符vnode结构
{
// 基本 VNode 属性
tag: 'vue-component-1-comp', // Vue 内部生成的唯一标识符
data: {
hook: { // 🔥 核心!存放组件生命周期的钩子函数,将在 patch 阶段被触发
init: function(vnode) { ... }, // 初始化组件实例
prepatch: function(oldVnode, vnode) { ... }, // 更新前
insert: function(vnode) { ... }, // 插入 DOM 后
destroy: function(vnode) { ... } // 销毁时
}
},
children: undefined, // ❗ 注意:子节点(元素内容)不在这里
elm: null, // 对应的真实 DOM 元素(此时尚未创建)
// 组件特有属性
componentOptions: { // 🔥 组件的“配置包”,包含了实例化所需的一切信息
Ctor: function VueComponent(options) { ... }, // 组件构造函数
propsData: { msg: 'hello' }, // 从 data 中提取出的 props 值
listeners: { 'custom-event': handler }, // 父组件监听的事件
tag: 'comp', // 原始标签名
children: [/* 插槽内容的 VNode 数组 */] // ❗ 子节点(插槽内容)在这里
},
componentInstance: undefined // ❗ 关键:此时组件实例还不存在!
}
关键点说明:
-
componentOptions对象: 一个信息聚合包,包含了创建和配置组件实例所需要的全部数据,方便在patch阶段一次性使用
-
children的存放位置: 对于组件vnode,其模板内的子内容(即默认插槽内容)不是作为vnode的直接子节点(vnode.children),而是放在
vnode.componentOptions.children中
4.4.5.4. vnode的创建顺序
深度优先
执行render函数时的调用栈推进过程:
调用栈深度:
anonymous() 开始
↓
准备执行 _c('div', ...)
↓ 需要先计算子节点数组
计算第一个数组元素:_c('h1', ...)
↓ 需要先计算h1的子节点
计算 _v("组件化机制") ← 最先执行完成!
↓
_c('h1', ...) 执行完成
↓
计算第二个数组元素:_c('comp')
↓
_c('comp') 执行完成
↓
现在所有子节点就绪,执行 _c('div', ...)
↓
anonymous() 返回结果
4.4.5.5. 生成的vnode的大致结构:
{
tag: 'div',
data: { attrs: { id: 'app' } },
children: [
{
tag: 'h1',
children: [
{ tag: undefined, text: '组件化机制', isComment: false }
],
elm: undefined,
context: vm
},
{ tag: undefined, text: ' ', isComment: false },
{
tag: 'p',
children: [
{ tag: undefined, text: "hello vue", isComment: false }
],
elm: undefined,
context: vm
},
{ tag: undefined, text: ' ', isComment: false },
{
tag: 'vue-component-1-comp',
componentOptions: {
Ctor: CompConstructor,
propsData: undefined,
tag: 'comp'
},
data: {
hook: { /* 组件生命周期钩子 */ }
},
elm: undefined,
context: vm
}
],
elm: undefined,
context: vm,
parent: undefined
}
4.4.6. Patch过程:从虚拟DOM到真实DOM
4.4.6.1. Patch的触发
在_update中,会根据是否首次渲染,选择不同的patch策略
🚂 src/core/instance/lifecycle.js
Vue.prototype._update = function (vnode, hydrating) {
const vm = this
const prevVnode = vm._vnode// 之前渲染的vnode
if (!prevVnode) {
// 首次渲染
vm.$el = vm.__patch__(vm.$el, vnode, hydrating, false)
} else {
// 更新渲染(diff算法)
vm.$el = vm.__patch__(prevVnode, vnode)
}
}
4.4.6.2. Patch函数的创建
🚂 src/platforms/web/runtime/patch.js
// 工厂模式,创建平台专用的 patch 函数
export const patch: Function = createPatchFunction({ nodeOps, modules })
createPatchFunction一个工厂函数
-
- nodeOps:封装了平台对应的各种原生DOM的基础操作方法
- modules:处理属性、样式、事件等平台相关逻辑
💡 核心算法复用,平台特性隔离
4.4.6.3. Patch核心流程
🚂 src/core/vdom/patch.js
主要处理三个场景:
-
新节点不存在 => 销毁旧节点(组件被条件渲染移除 v-if="false")
if (isUndef(vnode)) {
if (isDef(oldVnode)) invokeDestroyHook(oldVnode)
return
}
-
旧节点不存在 => 全新挂载(动态组件首次渲染/服务端渲染激活)
if (isUndef(oldVnode)) {
isInitialPatch = true
createElm(vnode, insertedVnodeQueue) // 直接创建新DOM树
}
-
新旧都存在 => 精细化更新
在首次渲染根节点时,走的就是这里
// 检查是否是真实DOM元素(首次挂载时 oldVnode 是真实的 div#app)
const isRealElement = isDef(oldVnode.nodeType)
if (!isRealElement && sameVnode(oldVnode, vnode)) {
// 可复用的虚拟节点 → 精细化diff
patchVnode(oldVnode, vnode, insertedVnodeQueue, null, null, removeOnly)
} else {
// 真实DOM或不可复用 → 替换操作
if (isRealElement) {// 根组件挂载
// 首次挂载,标准化为vnode
oldVnode = emptyNodeAt(oldVnode)
}
const oldElm = oldVnode.elm // 获取宿主元素
const parentElm = nodeOps.parentNode(oldElm) // 获取宿主元素父元素 🌰body
// 关键:创建新DOM树,将它追加到parentElm里面,oldElm旁边
createElm(
vnode, // 新虚拟节点
insertedVnodeQueue, // 插入回调队列
parentElm, // 父容器(body)
nodeOps.nextSibling(oldElm) // 参考位置:旧节点的下一个兄弟节点前
)
// 销毁旧节点
if (isDef(parentElm)) {
removeVnodes(parentElm, [oldVnode], 0, 0)
}
}
4.4.6.4. createElm() :DOM创建的核心
从虚拟DOM到真实DOM的转换器
4.4.6.4.1. 核心逻辑
function createElm(vnode, insertedVnodeQueue, parentElm, refElm, nested) {
// 优先尝试作为组件创建
if (createComponent(vnode, insertedVnodeQueue, parentElm, refElm)) {
return// 如果是组件,创建成功直接返回,不是组件则继续普通元素创建流程
}
const data = vnode.data
const children = vnode.children
const tag = vnode.tag
// 按元素类型分派处理
if (isDef(tag)) {
// 1. 元素节点:创建对应HTML标签
vnode.elm = vnode.ns
? nodeOps.createElementNS(vnode.ns, tag) // 命名空间元素
: nodeOps.createElement(tag, vnode) // 普通元素
// 递归创建子节点(深度优先)
createChildren(vnode, children, insertedVnodeQueue)
// 处理属性、样式、事件等
if (isDef(data)) {
invokeCreateHooks(vnode, insertedVnodeQueue)
}
// 插入到DOM
insert(parentElm, vnode.elm, refElm)
} else if (isTrue(vnode.isComment)) {
// 2. 注释节点
vnode.elm = nodeOps.createComment(vnode.text)
insert(parentElm, vnode.elm, refElm)
} else {
// 3. 文本节点
vnode.elm = nodeOps.createTextNode(vnode.text)
insert(parentElm, vnode.elm, refElm)
}
}
4.4.6.4.2. createChildren
递归创建子节点,深度优先遍历
function createChildren(vnode, children, insertedVnodeQueue) {
if (Array.isArray(children)) {
for (let i = 0; i < children.length; ++i) {
// 对每个子节点递归调用 createElm
createElm(children[i], insertedVnodeQueue, vnode.elm, null, true)
}
} else if (isPrimitive(vnode.text)) {
// 文本内容直接创建文本节点
nodeOps.appendChild(vnode.elm, nodeOps.createTextNode(String(vnode.text)))
}
}
4.4.6.4.3. 当前示例的执行顺序
createElm(div#app)
↓
createChildren → 遍历5个子节点
↓
createElm(h1) → 创建h1元素 → createChildren → 创建文本节点"组件化机制"
↓
createElm(文本节点 "\n ")
↓
createElm(p) → 创建p元素 → createChildren → 创建动态文本节点
↓
createElm(文本节点 "\n ")
↓
createElm(comp组件) → 触发组件创建逻辑
4.4.6.5. createComponent()组件创建的特殊处理
createElm中,会调用createComponent,将vnode优先尝试作为组件创建
function createComponent(vnode, insertedVnodeQueue, parentElm, refElm) {
let i = vnode.data
if (isDef(i)) {
// 检查是否有init钩子(组件标识,只有组件节点的data属性中会有hook属性)
if (isDef(i = i.hook) && isDef(i = i.init)) {
// 执行组件初始化钩子
i(vnode, false /* hydrating */)
}
// 如果组件实例创建成功 => 调用组件的init钩子后,vnode中才会有组件实例,所以可以用vnode.componentInstance来判断组件实例是否创建成功
if (isDef(vnode.componentInstance)) {
// 初始化组件DOM
initComponent(vnode, insertedVnodeQueue)
// 插入到父容器
insert(parentElm, vnode.elm, refElm)
return true // 返回true,表示已作为组件处理
}
}
return false
}
4.4.6.5.1. 组件init钩子的作用
🚂 src/core/vdom/create-component.js
init(vnode, hydrating) {
if (vnode.componentInstance && vnode.data.keepAlive) {
// keep-alive组件复用逻辑
} else {
// 创建组件实例
const child = vnode.componentInstance = createComponentInstanceForVnode(
vnode,
activeInstance // 当前激活的组件实例
)
// 子组件递归挂载(重要!)
child.$mount(hydrating ? vnode.elm : undefined, hydrating)
}
}
4.4.6.5.2. 组件从render到patch的完整过程
1. 渲染阶段 (_render)
父组件 _render()
↓
遇到 <comp></comp>,调用 _createElement('comp', ...)
↓
识别为组件,调用 createComponent(...)
↓
返回一个轻量的【组件占位符 VNode】(包含 Ctor, props, hooks 等元数据)
↓
父组件 VNode 树生成完毕
2. 补丁阶段 (patch)
patch 过程遍历到组件占位符 VNode
↓
调用 vnode.data.hook.init(vnode) 钩子
↓
在 init 钩子中:const child = vnode.componentInstance = new Ctor(...)
↓
子组件开始自己的生命周期:child.$mount() -> _init() -> _render() -> patch()
↓
此时才真正创建子组件的实例和 DOM 树
4.4.6.6. Diff算法核心
4.4.6.6.1. patchVnode() 中的Diff入口
在Patch的过程中,当判断到新旧vnode可复用时,会调用patchVnode()方法,进行精细化更新
核心逻辑: 首先进行树级别比较
三种情况:
- 新vnode不存在 => 删
- 旧vnode不存在 => 增
- 都存在 => diff
具体规则:
- 新老节点均有children,则对子节点diff,调用updateChildern
- 新节点有children而老节点没有,先清空老节点文本,再新增子节点
- 新节点没有children而老节点有,移除该节点的所有子节点
- 新老节点都没有children,文本替换
// 获取双方子元素
const oldCh = oldVnode.children
const ch = vnode.children
if (isUndef(vnode.text)) {
// 非文本节点
if (isDef(oldCh) && isDef(ch)) {
// 新旧节点都有子节点
// 触发updateChildren进行对比
if (oldCh !== ch) updateChildren(elm, oldCh, ch, insertedVnodeQueue, removeOnly)
} else if (isDef(ch)) {
// 只有新节点有子节点
// 如果旧节点有文本则清空
if (isDef(oldVnode.text)) nodeOps.setTextContent(elm, '')
// 添加新节点
addVnodes(elm, null, ch, 0, ch.length - 1, insertedVnodeQueue)
} else if (isDef(oldCh)) {
// 只有旧节点有子节点,直接移除
removeVnodes(oldCh, 0, oldCh.length - 1)
} else if (isDef(oldVnode.text)) {
// 旧节点有文本内容,直接清空
nodeOps.setTextContent(elm, '')
}
} else if (oldVnode.text !== vnode.text) {
// 文本节点,直接更新文本
nodeOps.setTextContent(elm, vnode.text)
}
if (isDef(data)) {
// 触发postpatch钩子
if (isDef(i = data.hook) && isDef(i = i.postpatch)) i(oldVnode, vnode)
}
4.4.6.6.2. updateChildren() :Diff算法的核心实现
4.4.6.6.2.1. 核心逻辑:
双指针&同层比较

新老两组VNode节点的左右头尾两侧都有一个变量标记,在遍历过程中这几个变量都会向中间靠拢,oldStartIdx > oldEndIdx或newStartIdx > newEndIdx时结束循环
function updateChildren(parentElm, oldCh, newCh, insertedVnodeQueue, removeOnly) {
// 初始化指针
let oldStartIdx = 0
let newStartIdx = 0
let oldEndIdx = oldCh.length - 1
let oldStartVnode = oldCh[0]
let oldEndVnode = oldCh[oldEndIdx]
let newEndIdx = newCh.length - 1
let newStartVnode = newCh[0]
let newEndVnode = newCh[newEndIdx]
let oldKeyToIdx, idxInOld, vnodeToMove, refElm
// 双端比较循环
while (oldStartIdx <= oldEndIdx && newStartIdx <= newEndIdx) {
if (isUndef(oldStartVnode)) {
// 旧开始节点为空,跳过
oldStartVnode = oldCh[++oldStartIdx]
} else if (isUndef(oldEndVnode)) {
// 旧结束节点为空,跳过
oldEndVnode = oldCh[--oldEndIdx]
}
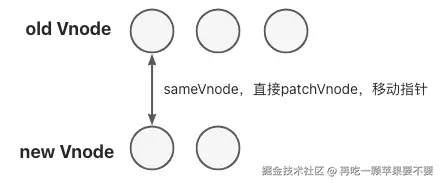
// 1. 头头相同 - 直接 patch
else if (sameVnode(oldStartVnode, newStartVnode)) {
patchVnode(oldStartVnode, newStartVnode, insertedVnodeQueue)
oldStartVnode = oldCh[++oldStartIdx]
newStartVnode = newCh[++newStartIdx]
}
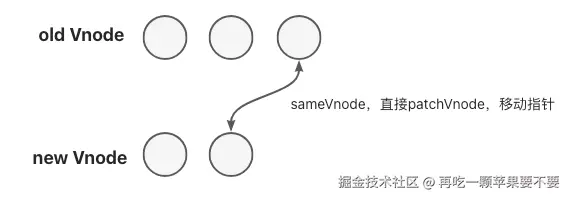
// 2. 尾尾相同 - 直接 patch
else if (sameVnode(oldEndVnode, newEndVnode)) {
patchVnode(oldEndVnode, newEndVnode, insertedVnodeQueue)
oldEndVnode = oldCh[--oldEndIdx]
newEndVnode = newCh[--newEndIdx]
}
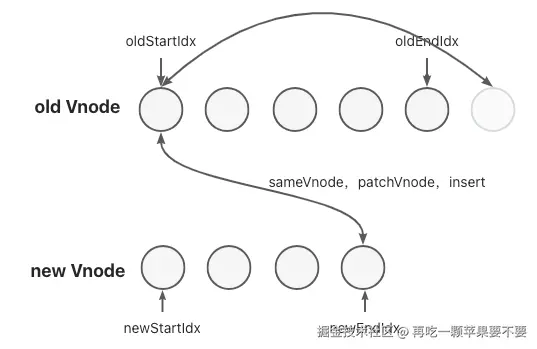
// 3. 头尾相同 - patch 后移动到末尾
else if (sameVnode(oldStartVnode, newEndVnode)) {
patchVnode(oldStartVnode, newEndVnode, insertedVnodeQueue)
// 将节点移动到旧列表末尾之后
nodeOps.insertBefore(parentElm, oldStartVnode.elm, nodeOps.nextSibling(oldEndVnode.elm))
oldStartVnode = oldCh[++oldStartIdx]
newEndVnode = newCh[--newEndIdx]
}
// 4. 尾头相同 - patch 后移动到开头
else if (sameVnode(oldEndVnode, newStartVnode)) {
patchVnode(oldEndVnode, newStartVnode, insertedVnodeQueue)
// 将节点移动到旧列表开头之前
nodeOps.insertBefore(parentElm, oldEndVnode.elm, oldStartVnode.elm)
oldEndVnode = oldCh[--oldEndIdx]
newStartVnode = newCh[++newStartIdx]
}
// 5. 四种情况都不匹配 - 使用 key 映射查找
else {
// 创建旧节点的 key 到 index 的映射
if (isUndef(oldKeyToIdx)) {
oldKeyToIdx = createKeyToOldIdx(oldCh, oldStartIdx, oldEndIdx)
}
// 根据新节点的 key 查找在旧列表中的位置
idxInOld = isDef(newStartVnode.key)
? oldKeyToIdx[newStartVnode.key]
: findIdxInOld(newStartVnode, oldCh, oldStartIdx, oldEndIdx)
if (isUndef(idxInOld)) {
// 新节点 - 创建并插入
createElm(newStartVnode, insertedVnodeQueue, parentElm, oldStartVnode.elm)
} else {
// 找到可复用的节点
vnodeToMove = oldCh[idxInOld]
if (sameVnode(vnodeToMove, newStartVnode)) {
patchVnode(vnodeToMove, newStartVnode, insertedVnodeQueue)
oldCh[idxInOld] = undefined // 标记为已处理
// 移动到当前位置
nodeOps.insertBefore(parentElm, vnodeToMove.elm, oldStartVnode.elm)
} else {
// 相同 key 但不同元素 - 创建新节点
createElm(newStartVnode, insertedVnodeQueue, parentElm, oldStartVnode.elm)
}
}
newStartVnode = newCh[++newStartIdx]
}
}
// 处理剩余节点
if (oldStartIdx > oldEndIdx) {
// 旧节点遍历完 - 添加剩余的新节点
addVnodes(parentElm, refElm, newCh, newStartIdx, newEndIdx, insertedVnodeQueue)
} else if (newStartIdx > newEndIdx) {
// 新节点遍历完 - 移除剩余的旧节点
removeVnodes(parentElm, oldCh, oldStartIdx, oldEndIdx)
}
}
4.4.6.6.2.2. Diff算法的四种比较策略
- 头头
- 尾尾
- 头尾(节点移动)
- 尾头(节点移动)
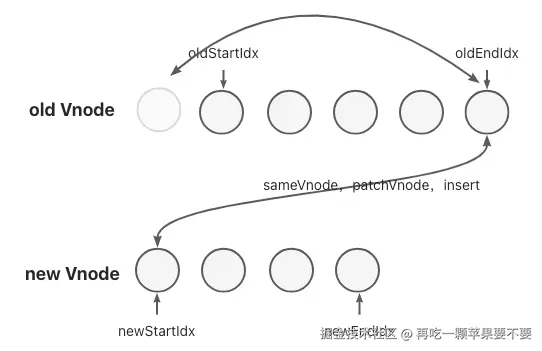
4.4.6.6.2.3. key的重要性
有key的情况:
// 旧列表
[{key: 'a', text: 'A'}, {key: 'b', text: 'B'}, {key: 'c', text: 'C'}]
// 新列表
[{key: 'c', text: 'C'}, {key: 'a', text: 'A'}, {key: 'b', text: 'B'}]
// Diff 过程:通过 key 快速定位,只需移动节点,无需重新创建
无key的情况:
// 旧列表
[{text: 'A'}, {text: 'B'}, {text: 'C'}]
// 新列表
[{text: 'C'}, {text: 'A'}, {text: 'B'}]
// Diff 过程:只能按位置比较,误判为不同节点,导致不必要的重新创建
key是Vue中用于优化diff算法的特殊属性,核心作用是为vnode提供一个唯一标识,帮助Vue更高效地识别哪些节点可以复用,从而最小化DOM操作,提升性能。
从源码层面来看:
首先key是用来判断是否相同节点的第一条件,只有当两个vnode的key和tag都相同时,vue才会认为它们是可复用节点,继而进行精细化的属性更新,否则,Vue会直接销毁并重新创建节点。
其次,在diff算法的核心,updateChildren函数中,当前面的头头、尾尾、头尾、尾头,四种快捷对比都失败后,Vue会为旧的节点数组创建一个key到index的映射表,通过这个映射表,Vue可以直接用新节点的key快速判断是否有可复用节点,然后通过移动DOM来完成更新。没有key的情况下,Vue只能按索引顺序对比。这在对列表进行排序、过滤等非末尾增删操作时,会误判为是节点内容发生了更改,而非节点位置发生了移动。结果就是导致大量不必要的DOM操作和组件重新渲染,而非高效的移动。
因此,在实际开发中,尤其是包含状态的组件列表或复杂DOM结构的v-for循环中,必须为每一项提供一个唯一且稳定的key(通常为id)。
5. 关键流程回顾
new Vue() → _init() → $mount() → mountComponent() → new Watcher()
↓
Watcher.get() → updateComponent() → _render() → createElement()
↓
生成 VNode 树 → _update() → patch() → createElm()
↓
递归处理组件 → 创建真实 DOM → 触发 mounted 钩子