推荐 vue vxe-gantt 最好用的甘特图,功能全面的甘特图组件
查看官网:vxeui.com
Github:github.com/x-extends/v…
Gitee:gitee.com/x-extends/v…
npm install vxe-pc-ui@4.8.19 vxe-table@4.16.0 vxe-gantt@4.0.0
// ...
import VxeUIAll from 'vxe-pc-ui'
import 'vxe-pc-ui/es/style.css'
import VxeUITable from 'vxe-table'
import 'vxe-table/es/style.css'
import VxeUIGantt from 'vxe-gantt'
import 'vxe-gantt/lib/style.css'
// ...
createApp(App).use(VxeUIAll).use(VxeUITable).use(VxeUIGantt).mount('#app')
// ...
基础功能

<template>
<div>
<vxe-gantt v-bind="ganttOptions"></vxe-gantt>
</div>
</template>
<script setup>
import { reactive } from 'vue'
const ganttOptions = reactive({
columns: [
{ field: 'name', title: '任务名称' },
{ field: 'start', title: '开始时间', width: 100 },
{ field: 'end', title: '结束时间', width: 100 }
],
data: [
{ id: 10002, name: '城市道路修理进度', start: '2024-03-03', end: '2024-03-08', progress: 10 },
{ id: 10004, name: '超级大工程', start: '2024-03-05', end: '2024-03-11', progress: 15 },
{ id: 10006, name: '一个小目标项目', start: '2024-03-10', end: '2024-03-21', progress: 5 },
{ id: 10007, name: '某某计划', start: '2024-03-15', end: '2024-03-24', progress: 70 },
{ id: 10008, name: '某某科技项目', start: '2024-03-20', end: '2024-03-29', progress: 50 }
]
})
</script>
显示任务进度
通过 task-bar-config.showProgress 显示任务进度

<template>
<div>
<vxe-gantt v-bind="ganttOptions"></vxe-gantt>
</div>
</template>
<script setup>
import { reactive } from 'vue'
const ganttOptions = reactive({
border: true,
columnConfig: {
resizable: true
},
taskBarConfig: {
showProgress: true
},
columns: [
{ field: 'title', title: '任务名称' },
{ field: 'start', title: '开始时间', width: 100 },
{ field: 'end', title: '结束时间', width: 100 }
],
data: [
{ id: 10001, title: 'A项目', start: '2024-03-01', end: '2024-03-04', progress: 3 },
{ id: 10002, title: '城市道路修理进度', start: '2024-03-03', end: '2024-03-08', progress: 10 },
{ id: 10003, title: 'B大工程', start: '2024-03-03', end: '2024-03-11', progress: 90 },
{ id: 10004, title: '超级大工程', start: '2024-03-05', end: '2024-03-11', progress: 15 },
{ id: 10005, title: '地球净化项目', start: '2024-03-08', end: '2024-03-15', progress: 100 },
{ id: 10006, title: '一个小目标项目', start: '2024-03-10', end: '2024-03-21', progress: 5 },
{ id: 10007, title: '某某计划', start: '2024-03-15', end: '2024-03-24', progress: 70 },
{ id: 10008, title: '某某科技项目', start: '2024-03-20', end: '2024-03-29', progress: 50 },
{ id: 10009, title: '地铁建设工程', start: '2024-03-19', end: '2024-03-20', progress: 5 },
{ id: 10010, title: '铁路修建计划', start: '2024-03-12', end: '2024-03-20', progress: 10 },
{ id: 10011, title: '蓝天计划', start: '2024-03-02', end: '2024-03-42', progress: 0 },
{ id: 10012, title: 'C计划', start: '2024-03-05', end: '2024-03-14', progress: 90 }
]
})
</script>
设置颜色

<template>
<div>
<vxe-gantt v-bind="ganttOptions"></vxe-gantt>
</div>
</template>
<script setup>
import { reactive } from 'vue'
const ganttOptions = reactive({
border: true,
taskBarConfig: {
showProgress: true,
barStyle: {
round: true,
bgColor: '#fca60b',
completedBgColor: '#65c16f'
}
},
columns: [
{ field: 'name', title: '任务名称' },
{ field: 'start', title: '开始时间', width: 100 },
{ field: 'end', title: '结束时间', width: 100 }
],
data: [
{ id: 10001, name: 'A项目', start: '2024-03-01', end: '2024-03-04', progress: 3 },
{ id: 10002, name: '城市道路修理进度', start: '2024-03-03', end: '2024-03-08', progress: 10 },
{ id: 10003, name: 'B大工程', start: '2024-03-03', end: '2024-03-11', progress: 90 },
{ id: 10004, name: '超级大工程', start: '2024-03-05', end: '2024-03-11', progress: 15 },
{ id: 10005, name: '地球净化项目', start: '2024-03-08', end: '2024-03-15', progress: 100 },
{ id: 10006, name: '一个小目标项目', start: '2024-03-10', end: '2024-03-21', progress: 5 },
{ id: 10007, name: '某某计划', start: '2024-03-15', end: '2024-03-24', progress: 70 },
{ id: 10008, name: '某某科技项目', start: '2024-03-20', end: '2024-03-29', progress: 50 },
{ id: 10009, name: '地铁建设工程', start: '2024-03-19', end: '2024-03-20', progress: 5 },
{ id: 10010, name: '铁路修建计划', start: '2024-03-12', end: '2024-03-20', progress: 10 }
]
})
</script>
单选框

<template>
<div>
<vxe-gantt v-bind="ganttOptions"></vxe-gantt>
</div>
</template>
<script setup>
import { reactive } from 'vue'
const ganttOptions = reactive({
border: true,
height: 300,
rowConfig: {
isHover: true
},
radioConfig: {
labelField: 'title',
highlight: true
},
taskBarConfig: {
showProgress: true,
showContent: true,
barStyle: {
round: true,
bgColor: '#fca60b',
completedBgColor: '#65c16f'
}
},
taskViewConfig: {
tableStyle: {
width: 480
}
},
columns: [
{ type: 'radio', title: '任务名称' },
{ field: 'start', title: '开始时间', width: 100 },
{ field: 'end', title: '结束时间', width: 100 }
],
data: [
{ id: 10001, title: 'A项目', start: '2024-03-01', end: '2024-03-04', progress: 3 },
{ id: 10002, title: '城市道路修理进度', start: '2024-03-03', end: '2024-03-08', progress: 10 },
{ id: 10003, title: 'B大工程', start: '2024-03-03', end: '2024-03-11', progress: 90 },
{ id: 10004, title: '超级大工程', start: '2024-03-05', end: '2024-03-11', progress: 15 },
{ id: 10005, title: '地球净化项目', start: '2024-03-08', end: '2024-03-15', progress: 100 },
{ id: 10006, title: '一个小目标项目', start: '2024-03-10', end: '2024-03-21', progress: 5 },
{ id: 10007, title: '某某计划', start: '2024-03-15', end: '2024-03-24', progress: 70 },
{ id: 10008, title: '某某科技项目', start: '2024-03-20', end: '2024-03-29', progress: 50 },
{ id: 10009, title: '地铁建设工程', start: '2024-03-19', end: '2024-03-20', progress: 5 },
{ id: 10010, title: '铁路修建计划', start: '2024-03-12', end: '2024-03-20', progress: 10 }
]
})
</script>
复选框
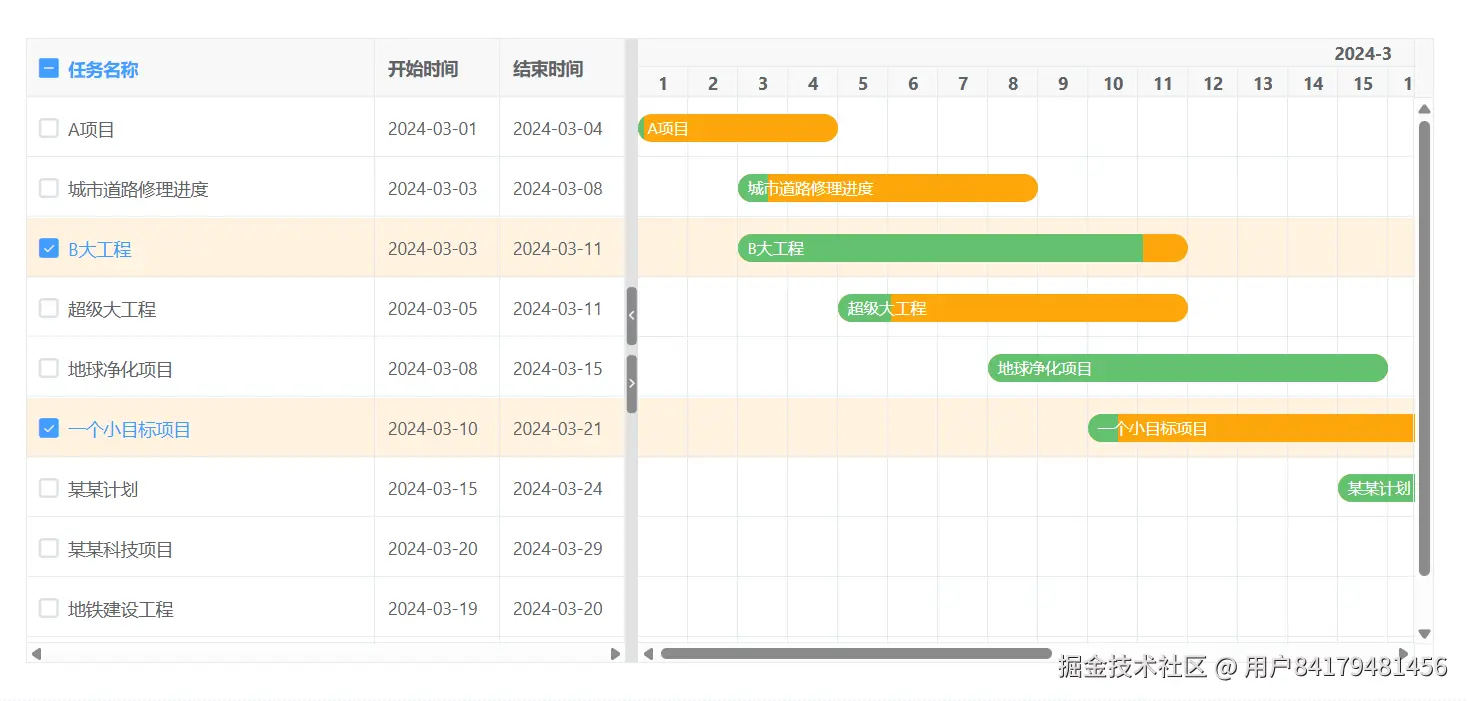
<template>
<div>
<vxe-gantt v-bind="ganttOptions"></vxe-gantt>
</div>
</template>
<script setup>
import { reactive } from 'vue'
const ganttOptions = reactive({
border: true,
height: 500,
rowConfig: {
isHover: true
},
checkboxConfig: {
labelField: 'title',
highlight: true
},
taskBarConfig: {
showProgress: true,
showContent: true,
barStyle: {
round: true,
bgColor: '#fca60b',
completedBgColor: '#65c16f'
}
},
taskViewConfig: {
tableStyle: {
width: 480
}
},
columns: [
{ type: 'checkbox', title: '任务名称' },
{ field: 'start', title: '开始时间', width: 100 },
{ field: 'end', title: '结束时间', width: 100 }
],
data: [
{ id: 10001, title: 'A项目', start: '2024-03-01', end: '2024-03-04', progress: 3 },
{ id: 10002, title: '城市道路修理进度', start: '2024-03-03', end: '2024-03-08', progress: 10 },
{ id: 10003, title: 'B大工程', start: '2024-03-03', end: '2024-03-11', progress: 90 },
{ id: 10004, title: '超级大工程', start: '2024-03-05', end: '2024-03-11', progress: 15 },
{ id: 10005, title: '地球净化项目', start: '2024-03-08', end: '2024-03-15', progress: 100 },
{ id: 10006, title: '一个小目标项目', start: '2024-03-10', end: '2024-03-21', progress: 5 },
{ id: 10007, title: '某某计划', start: '2024-03-15', end: '2024-03-24', progress: 70 },
{ id: 10008, title: '某某科技项目', start: '2024-03-20', end: '2024-03-29', progress: 50 },
{ id: 10009, title: '地铁建设工程', start: '2024-03-19', end: '2024-03-20', progress: 5 },
{ id: 10010, title: '铁路修建计划', start: '2024-03-12', end: '2024-03-20', progress: 10 }
]
})
</script>
子任务
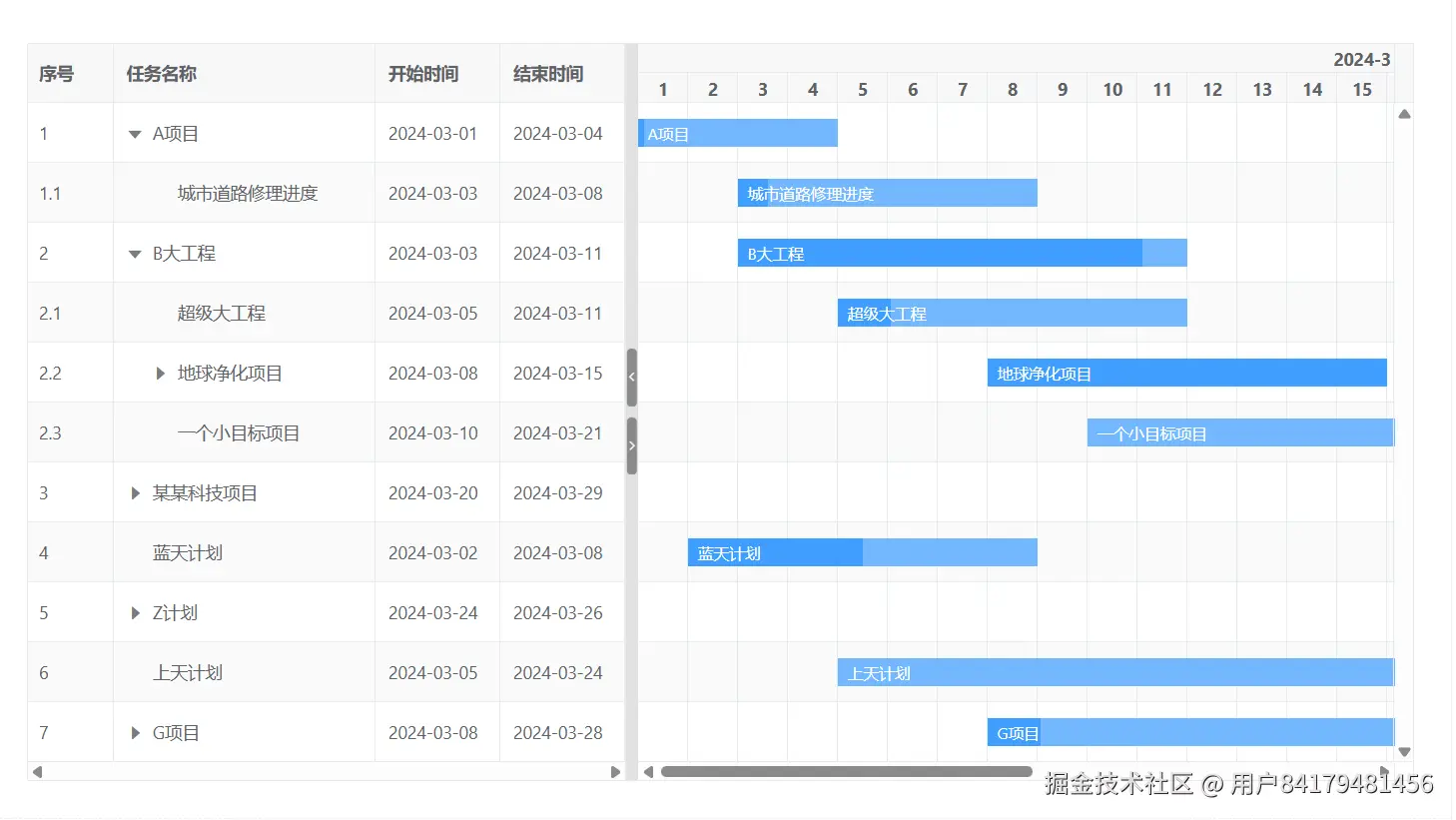
<template>
<div>
<vxe-gantt v-bind="ganttOptions"></vxe-gantt>
</div>
</template>
<script setup>
import { reactive } from 'vue'
const ganttOptions = reactive({
border: true,
stripe: true,
treeConfig: {
transform: true,
rowField: 'id',
parentField: 'parentId'
},
taskBarConfig: {
showProgress: true,
showContent: true
},
taskViewConfig: {
tableStyle: {
width: 480
}
},
columns: [
{ type: 'seq', width: 70 },
{ field: 'title', title: '任务名称', treeNode: true },
{ field: 'start', title: '开始时间', width: 100 },
{ field: 'end', title: '结束时间', width: 100 }
],
data: [
{ id: 10001, parentId: null, title: 'A项目', start: '2024-03-01', end: '2024-03-04', progress: 3 },
{ id: 10002, parentId: 10001, title: '城市道路修理进度', start: '2024-03-03', end: '2024-03-08', progress: 10 },
{ id: 10003, parentId: null, title: 'B大工程', start: '2024-03-03', end: '2024-03-11', progress: 90 },
{ id: 10004, parentId: 10003, title: '超级大工程', start: '2024-03-05', end: '2024-03-11', progress: 15 },
{ id: 10005, parentId: 10003, title: '地球净化项目', start: '2024-03-08', end: '2024-03-15', progress: 100 },
{ id: 10006, parentId: 10003, title: '一个小目标项目', start: '2024-03-10', end: '2024-03-21', progress: 0 },
{ id: 10007, parentId: 10005, title: '某某计划', start: '2024-03-15', end: '2024-03-24', progress: 70 },
{ id: 10008, parentId: null, title: '某某科技项目', start: '2024-03-20', end: '2024-03-29', progress: 50 },
{ id: 10009, parentId: 10008, title: '地铁建设工程', start: '2024-03-19', end: '2024-03-20', progress: 5 },
{ id: 10010, parentId: 10008, title: '公寓装修计划2', start: '2024-03-12', end: '2024-03-20', progress: 30 },
{ id: 10011, parentId: 10008, title: '两个小目标工程', start: '2024-03-01', end: '2024-03-04', progress: 20 },
{ id: 10012, parentId: null, title: '蓝天计划', start: '2024-03-02', end: '2024-03-08', progress: 50 },
{ id: 10013, parentId: 10010, title: 'C大项目', start: '2024-03-08', end: '2024-03-11', progress: 10 },
{ id: 10014, parentId: 10010, title: 'H计划', start: '2024-03-12', end: '2024-03-16', progress: 100 },
{ id: 10015, parentId: 10011, title: '铁路修建计划', start: '2024-03-05', end: '2024-03-06', progress: 0 },
{ id: 10016, parentId: 10011, title: 'D项目', start: '2024-03-06', end: '2024-03-11', progress: 10 },
{ id: 10017, parentId: 10011, title: '海外改造工程', start: '2024-03-08', end: '2024-03-09', progress: 0 },
{ id: 10018, parentId: null, title: 'Z计划', start: '2024-03-24', end: '2024-03-26', progress: 80 },
{ id: 10019, parentId: 10018, title: 'F工程', start: '2024-03-20', end: '2024-03-28', progress: 10 },
{ id: 10020, parentId: 10018, title: '投资大项目', start: '2024-03-23', end: '2024-03-28', progress: 60 },
{ id: 10021, parentId: 10018, title: 'X计划', start: '2024-03-16', end: '2024-03-25', progress: 10 },
{ id: 10022, parentId: null, title: '上天计划', start: '2024-03-05', end: '2024-03-24', progress: 0 },
{ id: 10023, parentId: null, title: 'G项目', start: '2024-03-08', end: '2024-03-28', progress: 5 },
{ id: 10024, parentId: 10023, title: '下地计划', start: '2024-03-09', end: '2024-03-16', progress: 50 }
]
})
</script>
查询表单
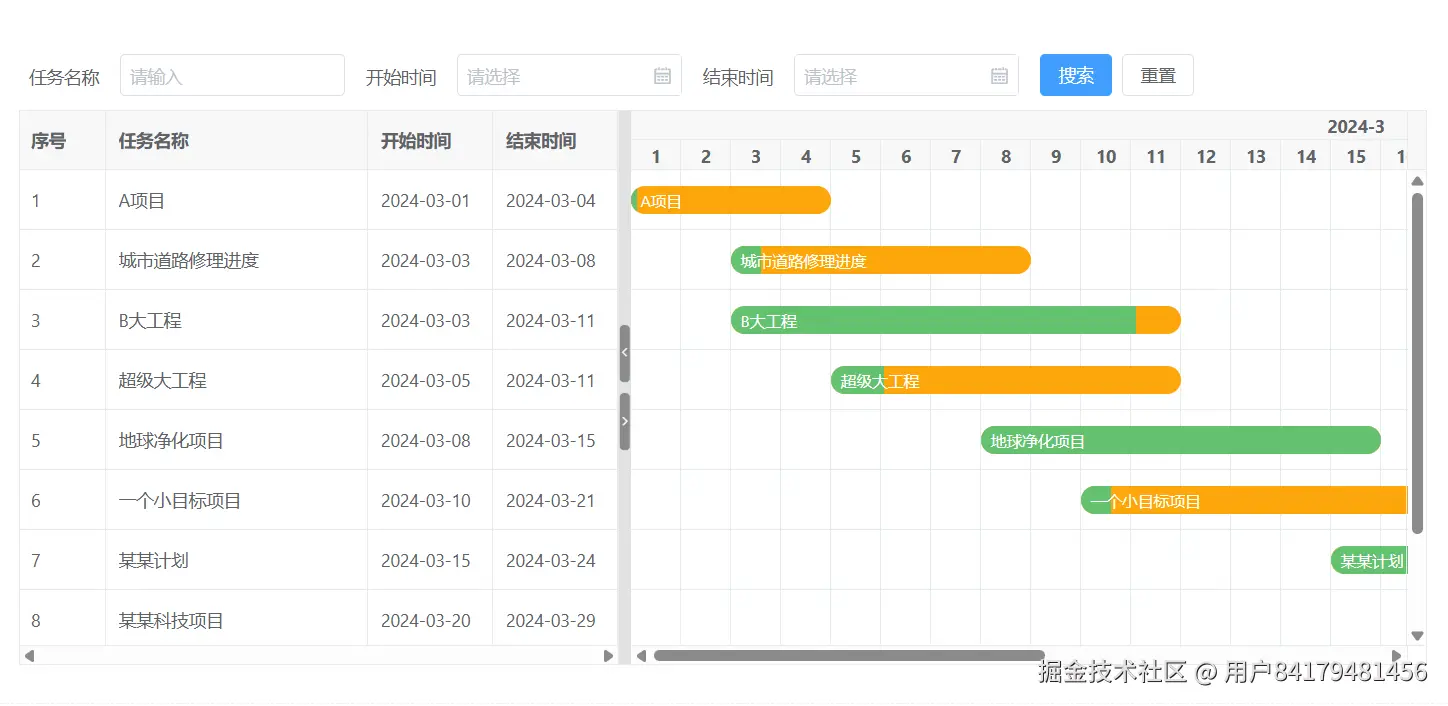
<template>
<div>
<vxe-gantt v-bind="ganttOptions" v-on="ganttEvents"></vxe-gantt>
</div>
</template>
<script setup>
import { reactive } from 'vue'
const ganttOptions = reactive({
showOverflow: true,
border: true,
height: 500,
taskBarConfig: {
showProgress: true,
showContent: true,
barStyle: {
round: true,
bgColor: '#fca60b',
completedBgColor: '#65c16f'
}
},
taskViewConfig: {
tableStyle: {
width: 480
}
},
formConfig: {
data: {
title: '',
start: '',
end: ''
},
items: [
{ field: 'title', title: '任务名称', itemRender: { name: 'VxeInput' } },
{ field: 'start', title: '开始时间', itemRender: { name: 'VxeDatePicker' } },
{ field: 'end', title: '结束时间', itemRender: { name: 'VxeDatePicker' } },
{
itemRender: {
name: 'VxeButtonGroup',
options: [
{ type: 'submit', content: '搜索', status: 'primary' },
{ type: 'reset', content: '重置' }
]
}
}
]
},
columns: [
{ type: 'seq', width: 70 },
{ field: 'title', title: '任务名称' },
{ field: 'start', title: '开始时间', width: 100 },
{ field: 'end', title: '结束时间', width: 100 }
],
data: [
{ id: 10001, title: 'A项目', start: '2024-03-01', end: '2024-03-04', progress: 3 },
{ id: 10002, title: '城市道路修理进度', start: '2024-03-03', end: '2024-03-08', progress: 10 },
{ id: 10003, title: 'B大工程', start: '2024-03-03', end: '2024-03-11', progress: 90 },
{ id: 10004, title: '超级大工程', start: '2024-03-05', end: '2024-03-11', progress: 15 },
{ id: 10005, title: '地球净化项目', start: '2024-03-08', end: '2024-03-15', progress: 100 },
{ id: 10006, title: '一个小目标项目', start: '2024-03-10', end: '2024-03-21', progress: 5 },
{ id: 10007, title: '某某计划', start: '2024-03-15', end: '2024-03-24', progress: 70 },
{ id: 10008, title: '某某科技项目', start: '2024-03-20', end: '2024-03-29', progress: 50 },
{ id: 10009, title: '地铁建设工程', start: '2024-03-19', end: '2024-03-20', progress: 5 },
{ id: 10010, title: '铁路修建计划', start: '2024-03-12', end: '2024-03-20', progress: 10 }
]
})
const ganttEvents = {
formSubmit () {
console.log('form submit')
},
formReset () {
console.log('form reset')
}
}
</script>
数据分页
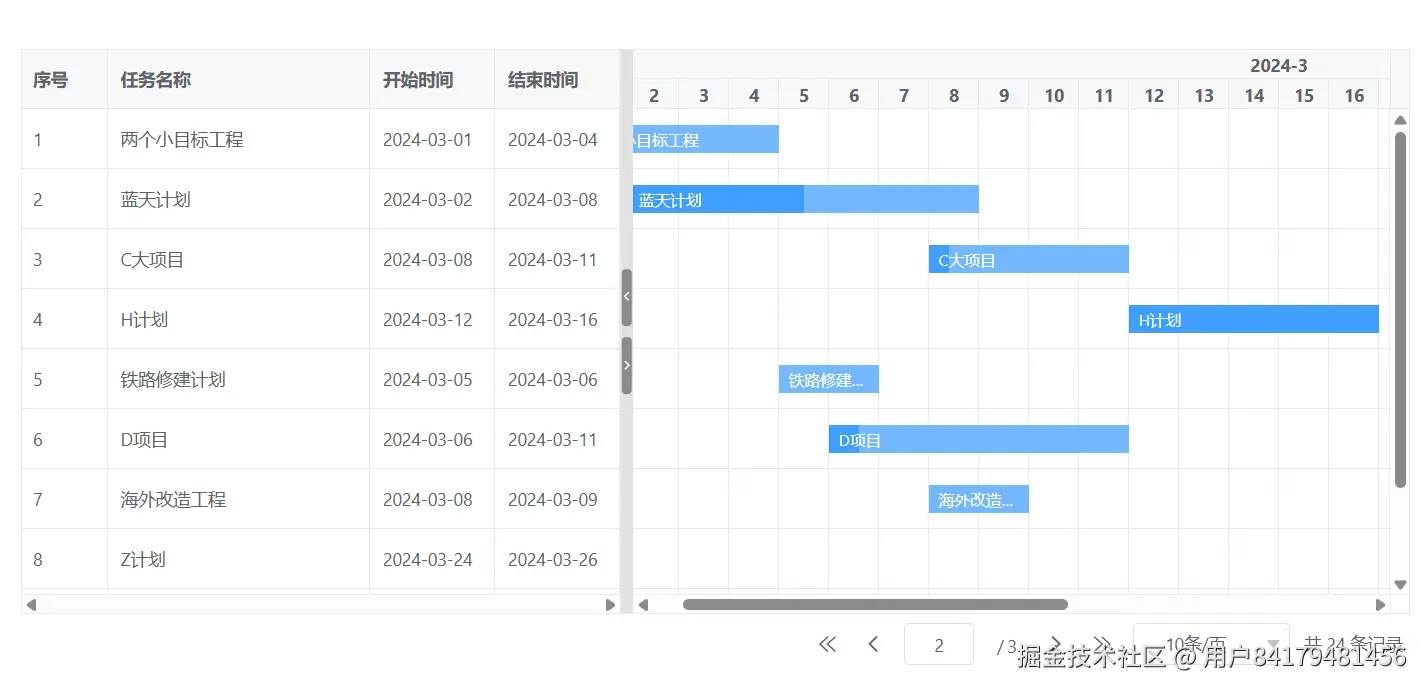
<template>
<div>
<vxe-gantt v-bind="ganttOptions" v-on="ganttEvents"></vxe-gantt>
</div>
</template>
<script setup>
import { reactive } from 'vue'
const allList = [
{ id: 10001, title: 'A项目', start: '2024-03-01', end: '2024-03-04', progress: 3 },
{ id: 10002, title: '城市道路修理进度', start: '2024-03-03', end: '2024-03-08', progress: 10 },
{ id: 10003, title: 'B大工程', start: '2024-03-03', end: '2024-03-11', progress: 90 },
{ id: 10004, title: '超级大工程', start: '2024-03-05', end: '2024-03-11', progress: 15 },
{ id: 10005, title: '地球净化项目', start: '2024-03-08', end: '2024-03-15', progress: 100 },
{ id: 10006, title: '一个小目标项目', start: '2024-03-10', end: '2024-03-21', progress: 0 },
{ id: 10007, title: '某某计划', start: '2024-03-15', end: '2024-03-24', progress: 70 },
{ id: 10008, title: '某某科技项目', start: '2024-03-20', end: '2024-03-29', progress: 50 },
{ id: 10009, title: '地铁建设工程', start: '2024-03-19', end: '2024-03-20', progress: 5 },
{ id: 10010, title: '公寓装修计划2', start: '2024-03-12', end: '2024-03-20', progress: 30 },
{ id: 10011, title: '两个小目标工程', start: '2024-03-01', end: '2024-03-04', progress: 20 },
{ id: 10012, title: '蓝天计划', start: '2024-03-02', end: '2024-03-08', progress: 50 },
{ id: 10013, title: 'C大项目', start: '2024-03-08', end: '2024-03-11', progress: 10 },
{ id: 10014, title: 'H计划', start: '2024-03-12', end: '2024-03-16', progress: 100 },
{ id: 10015, title: '铁路修建计划', start: '2024-03-05', end: '2024-03-06', progress: 0 },
{ id: 10016, title: 'D项目', start: '2024-03-06', end: '2024-03-11', progress: 10 },
{ id: 10017, title: '海外改造工程', start: '2024-03-08', end: '2024-03-09', progress: 0 },
{ id: 10018, title: 'Z计划', start: '2024-03-24', end: '2024-03-26', progress: 80 },
{ id: 10019, title: 'F工程', start: '2024-03-20', end: '2024-03-28', progress: 10 },
{ id: 10020, title: '投资大项目', start: '2024-03-23', end: '2024-03-28', progress: 60 },
{ id: 10021, title: 'X计划', start: '2024-03-16', end: '2024-03-25', progress: 10 },
{ id: 10022, title: '上天计划', start: '2024-03-05', end: '2024-03-24', progress: 0 },
{ id: 10023, title: 'G项目', start: '2024-03-08', end: '2024-03-28', progress: 5 },
{ id: 10024, title: '下地计划', start: '2024-03-09', end: '2024-03-16', progress: 50 }
]
// 模拟前端分页
const handlePageData = () => {
ganttOptions.loading = true
setTimeout(() => {
const { pageSize, currentPage } = pagerVO
pagerVO.total = allList.length
ganttOptions.data = allList.slice((currentPage - 1) * pageSize, currentPage * pageSize)
ganttOptions.loading = false
}, 100)
}
const pagerVO = reactive({
total: 0,
currentPage: 1,
pageSize: 10
})
const ganttOptions = reactive({
showOverflow: true,
border: true,
loading: false,
height: 500,
pagerConfig: pagerVO,
taskBarConfig: {
showProgress: true,
showContent: true
},
taskViewConfig: {
tableStyle: {
width: 480
}
},
columns: [
{ type: 'seq', width: 70 },
{ field: 'title', title: '任务名称' },
{ field: 'start', title: '开始时间', width: 100 },
{ field: 'end', title: '结束时间', width: 100 }
],
data: []
})
const ganttEvents = {
pageChange ({ pageSize, currentPage }) {
pagerVO.currentPage = currentPage
pagerVO.pageSize = pageSize
handlePageData()
}
}
handlePageData()
</script>
gitee.com/x-extends/v…