我是东厂:Skill管不了的,我Hooks管
AI Coding 系列第 05d 篇 · 自动化体系
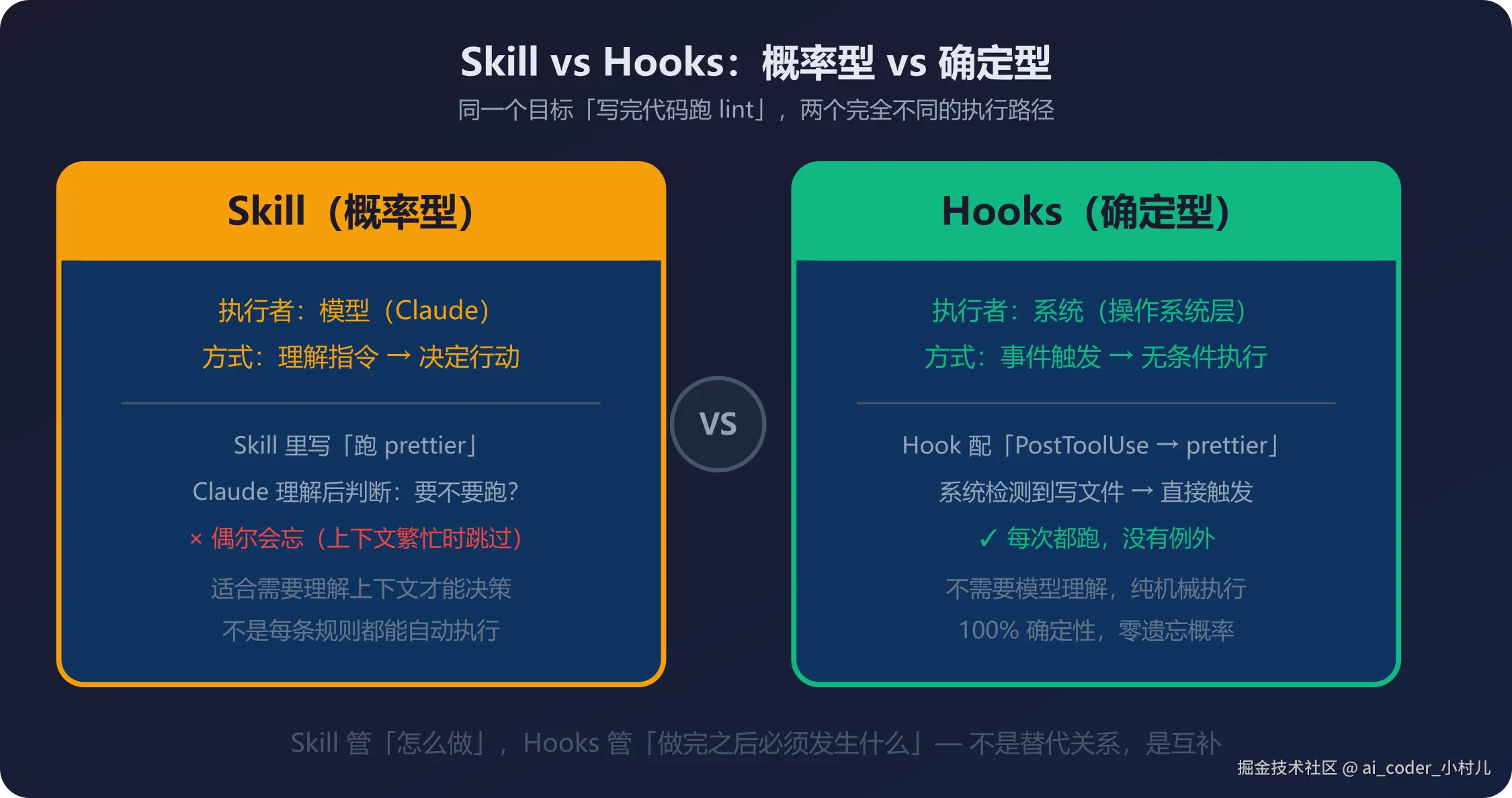
上一篇讲 Skill 的时候,我提过一个判断:Skill 的本质是固化默认动作。
这话没问题,但有一个场景它盖不住。
你写了一个 code review Skill,步骤里写得清清楚楚:"改完代码后跑 prettier --write,确保格式统一。" Claude 大部分时候会照做,但偶尔它就是忘了。不是因为 Skill 写得不好,而是因为这一步对它来说只是"一段建议"——它理解了,但在上下文繁忙的时候,它可能觉得"格式化不是最紧急的",于是跳过了。
你把这行加粗,加感叹号,甚至在 Skill 里写"这一步绝对不能跳过"。大部分时候管用,但你永远没法保证 100%。
因为 Skill 的执行本质上是概率型的——它靠模型理解指令来行动,而理解本身就带不确定性。
Hooks 做的是完全不同的事:它不经过模型,不需要理解,不存在"忘了"的可能。 你配好一条规则"每次 Write 工具执行完毕后跑 prettier --write",它就是每次都跑,没有例外。
这就是 Hooks 的定位:Skill 管"怎么做",Hooks 管"做完之后必须发生什么"。 一个靠理解,一个靠规则。一个是概率型的,一个是确定型的。
理解了这个区分,后面所有内容都会顺下来。

这篇文章对谁有用
- 你已经用 Skill 约束过 Claude 的行为,但发现有些步骤它偶尔还是会漏
- 你希望 Claude 改完代码自动跑 lint / 格式化 / 类型检查,不需要每次提醒
- 你想在 Claude 调用危险命令之前自动拦截,而不是事后补救
- 你想把 Claude 的工作流和团队的 CI / 通知 / 日志系统打通
- 你好奇 Hooks 除了"跑 shell 命令"还能做什么(剧透:远不止这些)
先说结论
- Hooks 是事件驱动的确定性自动化,不经过模型推理,100% 执行
- 它和 Skill 不是替代关系,而是互补:Skill 管任务流程,Hooks 管质量保障和安全边界
- Hooks 有五种类型:command(跑脚本)、http(调接口)、mcp_tool(调 MCP 工具)、prompt(让 Claude 做一次性判断)、agent(起子 Agent 评估)
- 事件分三层:Session 级(启动/结束)、Turn 级(用户输入/Claude 回复完成)、Tool 级(工具调用前后)
- PreToolUse 是最强大的事件——它可以拦截、放行、修改 Claude 即将执行的操作
- Hook 的退出码和 JSON 输出决定了它如何反馈给 Claude,这不是 shell 技巧,是通信协议
- Hooks 可以写在 Skill 的 frontmatter 里,和 Skill 的生命周期绑定
一、Hooks 是什么,不是什么
先把边界画清楚。
Hooks 是事件驱动的自动化层。当 Claude Code 执行到某个特定节点——比如它刚用 Write 工具写了一个文件,或者它准备调用 Bash 执行一条命令——你预先配好的动作就会被触发。
它的思路和 Git hooks 几乎一样:pre-commit 在提交前跑检查,post-merge 在合并后跑脚本。只不过 Claude Code 的 hooks 绑定的不是 Git 操作,而是 Claude 的工具调用和会话生命周期。
但 Hooks 不是:
- 不是 AI 行为规则——那是 CLAUDE.md 和 Skill 的事
- 不是修改 Claude 思考方式的机制——它不碰模型推理
- 不是万能拦截器——它能拦截工具调用,但拦不住 Claude 的思考过程
一句话定位:Hooks 是 Claude Code 工作流里的"系统级回调"。 你定义条件和动作,系统在满足条件时无条件执行。
1.1 从源码看类型系统:Hooks 的精确定义
理解 Hooks 的最好方式,是看源码里它如何被类型系统精确定义。Claude Code 用 Zod 构建了完整的 Hook 类型体系,这份严谨是整个 Hook 系统可靠性的基石。
关于 Zod:TypeScript 的类型检查只在编译时生效——代码一跑起来,类型就"消失"了。Zod 做的事是在运行时校验数据——它定义一套 schema(数据结构规则),然后在你拿到任何数据(用户配置、Hook 输出、API 响应)时,当场检查这数据是否符合规则。你可以把它理解为"运行时类型警察":编译期 TypeScript 保证代码逻辑类型正确,运行时 Zod 保证外部数据格式正确。Claude Code 为什么依赖它?因为 Hook 的配置和输出都来自外部——用户写的 JSON、shell 脚本的 stdout——这些在编译期完全不可知,只有 Zod 能在程序跑起来之后拦住格式错误。
关于源码:本文引用的源码路径(如 src/schemas/hooks.ts)来自 Claude Code 的开源参考实现 claude-code-cli。这些文件不在你本地安装的 Claude Code 目录里——需要 clone 仓库才能看到完整实现。如果你对某个机制的细节感兴趣,沿着路径翻源码会比读任何二手解释都更透彻。
从源码可以知道:Hook 的四种类型(command/prompt/agent/http)通过 Zod 的 discriminatedUnion 严格定义,返回值结构根据事件类型展开 15 种分支。输出格式之所以必须精确,不是系统挑剔,而是 Zod 在运行时强制校验——多一个字段或少一个字段都会产生错误。
🔬 展开查看源码详情
src/schemas/hooks.ts:176-189 定义了四种可持久化的 Hook 类型,用 Zod 的 discriminatedUnion 模式——也就是用 type 字段做标签,区分布局的四种具体形态:
// 实际源码中的四种 Hook 类型定义
z.discriminatedUnion('type', [
BashCommandHookSchema, // { type: 'command', command: '...' }
PromptHookSchema, // { type: 'prompt', prompt: '...' }
AgentHookSchema, // { type: 'agent', prompt: '...' }
HttpHookSchema, // { type: 'http', url: '...' }
])
这个设计意味着:你的配置 JSON 里 type 字段写错一个字,Zod 会在启动时直接报解析错误,不会等到运行时才发现。这就是"确定性"的第一层体现——类型系统保证配置是正确的,否则不让通过。
src/types/hooks.ts:50-166 定义了 Hook 返回值的完整类型——syncHookResponseSchema。这不是一个简单的 {ok: true} 结构,而是一个联合类型(union),根据 hookSpecificOutput.hookEventName 的不同值,展开不同的字段结构:
// hookSpecificOutput 是一个 discriminator union
// hookEventName 的值决定了能用哪些字段
z.union([
{ hookEventName: 'PreToolUse', → updatedInput, permissionDecision
{ hookEventName: 'PostToolUse', → updatedMCPToolOutput, additionalContext
{ hookEventName: 'SessionStart', → additionalContext, initialUserMessage, watchPaths
{ hookEventName: 'PermissionRequest' → decision: { behavior, updatedInput } | { behavior, message }
{ hookEventName: 'Elicitation', → action: 'accept' | 'decline' | 'cancel'
// ... 共 15 种 discriminator
])
这意味着:你的 PostToolUse Hook 返回了 updatedInput 字段?Zod 校验会拒绝它,因为 PostToolUse 的 hookSpecificOutput 里根本没定义这个字段。Hook 返回正确的 JSON 不只是"建议",而是被 Zod 运行时强制校验的。
src/types/hooks.ts:169-176 还有一个关键设计——同步和异步响应的区分。hookJSONOutputSchema 是一个 union([asyncHookResponseSchema, syncHookResponseSchema])。Hook 输出的第一行如果是 {"async": true},系统就知道这不是同步结果,而是"我已经在后台运行了"的信号。这个协议在 execCommandHook 里通过实时解析 stdout 的第一行来实现,后面会展开讲。
这对你有什么用:理解了这个类型体系,你就知道为什么 Hook 输出格式必须精确——不是系统"挑剔",而是 Zod 在运行时执行严格校验(src/utils/hooks.ts:382-397 的 validateHookJson)。如果你的 JSON 里多了一个不该有的字段,或者少了一个必需的字段,Hook 不会静默失败,而是会产生一条带详细错误信息的 non_blocking_error 消息。
二、配置放在哪,决定谁受影响
和 Skill 的存放位置逻辑一样,Hooks 的配置位置决定了它的作用域。
用户级(所有项目都生效):
~/.claude/settings.json
项目级(仅当前项目,可以提交到仓库):
.claude/settings.json
项目级本地(仅当前项目,不提交):
.claude/settings.local.json
插件级(插件启用时生效):
<plugin>/hooks/hooks.json
Skill / Agent 级(Skill 激活期间生效):
写在 SKILL.md 的 YAML frontmatter 里,后面会展开讲。
判断标准很简单:这个 Hook 换个项目还适用吗?"写文件后自动 prettier"大概率适用所有项目,放用户级。"改了 .prisma 文件后自动跑 prisma generate"只在用 Prisma 的项目里有意义,放项目级。
2.1 源码级:配置合并引擎如何工作
你把 Hook 配置在这五个层级,系统怎么决定最终生效哪些?从源码可以知道:合并走五层优先级链,managed(企业策略)层拥有最高控制权——用户级 disableAllHooks 关不掉 managed 层的东西。去重用 seenFiles 防止同一文件被读两次,Session hooks 存在内存 Map 里不落盘。
🔬 展开查看源码详情
src/utils/hooks/hooksConfigSnapshot.ts:18-53 的 getHooksFromAllowedSources() 是合并逻辑的入口。它按以下优先级链依次决策:
1. policySettings.disableAllHooks == true?
→ 返回 {}(所有 Hook 禁用,包括 managed hooks)
2. policySettings.allowManagedHooksOnly == true?
→ 只返回 policySettings 里的 hooks(企业策略模式)
3. isRestrictedToPluginOnly('hooks') == true?
→ 只返回 policySettings 里的 hooks(插件限制模式)
4. 用户级 settings.disableAllHooks == true?
→ 只返回 policySettings 里的 hooks(用户禁用但 managed 不受影响)
5. 正常模式:getSettings_DEPRECATED() 合并 user + project + local
这个链表设计体现了安全分层思想:managed(企业策略)层可以在第1步就关掉所有 Hook,但用户层(第4步)不能关掉 managed 层的 Hook——因为 disableAllHooks 在用户级只是"关掉非 managed 的 Hook",不影响 policySettings。
src/utils/hooks/hooksSettings.ts:92-161 的 getAllHooks() 进一步合并来自 editable 源(userSettings / projectSettings / localSettings)和 session hooks。注意它用 seenFiles 做了去重——当用户主目录就是项目目录时,~/.claude/settings.json 和 .claude/settings.json 是同一个文件,不去重就会导致同一条配置执行两次。
Session hooks 是另一个维度的配置——它们存在内存中(src/utils/hooks/sessionHooks.ts:62 的 SessionHooksState = Map<string, SessionStore>),不落盘。Session hooks 来自三个渠道:
- Skill frontmatter 里的
hooks 字段
- Agent 定义里的
hooks 字段
- 内部系统注册的 function hooks(比如 structured output enforcement)
src/utils/hooks.ts:1492-1566 的 getHooksConfig() 把所有来源合并成最终要执行的 Hook 列表。合并顺序是:snapshot hooks → registered hooks(SDK/plugin)→ session hooks → session function hooks。
这对你有什么用:如果你发现某个 Hook 总是被覆盖,用 /hooks 命令查看当前生效列表,对照上面的合并链就能定位是哪个源覆盖了它。也意味着你不能在用户级 disableAllHooks 来关掉企业策略层的 Hook——这是故意的安全设计。
配置的基本 JSON 结构长这样:
{
"hooks": {
"事件名": [
{
"matcher": "匹配模式",
"hooks": [
{
"type": "command",
"command": "你要执行的命令"
}
]
}
]
}
}
三层嵌套:事件名 → 匹配规则 → 具体动作。看起来层级多,但逻辑很清晰:什么时候触发(事件)→ 在什么条件下触发(matcher)→ 触发后做什么(hooks 数组)。
三、事件分三个层级,从粗到细
Hooks 能绑定的事件不只是"工具调用前后"。它覆盖了 Claude Code 会话的整个生命周期,按粒度分三层。
Session 级:会话生命周期节点触发
SessionStart — 会话启动时。适合加载开发环境上下文、设置环境变量、打印项目状态。
它有四种子场景,通过 matcher 区分:
-
startup:全新会话启动
-
resume:恢复之前的会话
-
clear:清空对话后重新开始
-
compact:上下文压缩后重新加载
{
"hooks": {
"SessionStart": [
{
"matcher": "startup",
"hooks": [
{
"type": "command",
"command": "echo '当前分支:'$(git branch --show-current) '| 未提交文件:'$(git status --short | wc -l | tr -d ' ')"
}
]
}
]
}
}
这样每次新会话启动,Claude 第一眼就能看到当前分支和未提交文件数。不需要它自己去查,上下文一开始就对了。
SessionEnd — 会话结束时。适合做清理、统计、日志归档。
Turn 级:每轮对话触发
UserPromptSubmit — 用户发送消息后、Claude 开始处理之前。可以用来做输入校验、自动注入上下文。
Stop — Claude 完成一轮回复时。适合做收尾检查、发通知。
这里有个特别实用的用法:如果你的 Stop Hook 返回 { "continue": false, "stopReason": "请先跑完测试再结束" },Claude 会看到这个消息并继续工作,而不是直接结束。这等于给了你一个"拦截 Claude 过早收手"的能力。
StopFailure — Claude 非正常停止时(比如限流、认证失败、账单错误)。matcher 可以区分具体原因:rate_limit、authentication_failed、billing_error 等。
Tool 级:每次工具调用触发
PreToolUse — Claude 即将调用某个工具之前。这是最强大的事件,因为它能拦截、放行、甚至修改即将执行的操作。后面单独展开。
PostToolUse — 工具调用成功之后。最常用的事件——写文件后跑格式化、编辑后跑 lint、执行命令后记日志。
PostToolUseFailure — 工具调用失败后。适合做错误收集和诊断。
PermissionRequest — 权限弹窗出现时。可以用来自动批准或拒绝特定操作。
还有一些更细粒度的事件,比如 FileChanged(文件变更时)、CwdChanged(工作目录切换时)、PreCompact / PostCompact(上下文压缩前后)、WorktreeCreate / WorktreeRemove(git worktree 操作时)。不是每个都常用,但知道它们存在很重要——当你遇到"我想在某个时机自动做某件事"的需求时,很可能已经有对应的事件。

四、matcher:决定什么条件下才触发
配了事件之后,matcher 决定"在这个事件里,我只关心哪些情况"。
对于 Tool 级事件(PreToolUse、PostToolUse 等),matcher 匹配的是工具名称。
| 写法 |
含义 |
例子 |
省略 / "" / "*"
|
匹配所有工具 |
任何工具调用都触发 |
| 纯字母数字 |
精确匹配 |
"Write" 只在写文件时触发 |
用 | 分隔 |
匹配多个工具 |
"Edit|Write" 写或编辑文件时触发 |
| 其他字符 |
当作正则表达式 |
"^Notebook" 匹配所有笔记本工具 |
MCP 工具的匹配格式是 mcp__<server>__<tool>,比如 mcp__memory__.* 匹配 memory 服务器的所有工具。
还有一个更精细的过滤:if 字段。它用权限规则语法做二次筛选。
{
"matcher": "Bash",
"if": "Bash(git *)",
"hooks": [{ "type": "command", "command": "echo 'Git 操作被执行'" }]
}
这个 Hook 只在 Claude 用 Bash 执行 git 开头的命令时才触发——不是所有 Bash 调用,只是 git 相关的。if 和 matcher 配合,能做到非常精准的条件筛选,不会误触发。
4.1 源码级:matcher 匹配引擎的三层判断
你写的 matcher 字符串是怎么被解析和匹配的?从源码可以知道:matcher 经历三层判断——空值/* 全部放行 → 纯字母数字做精确或管道匹配 → 含特殊字符走正则。if 条件二次筛选用的是权限规则引擎的 AST 匹配,不是正则。
🔬 展开查看源码详情
src/utils/hooks.ts:1346-1381 的 matchesPattern() 函数执行了三层判断:
第一层:空值和通配符(matchesPattern:1347-1349)
if (!matcher || matcher === '*') {
return true // 匹配所有
}
省略 matcher、写空字符串、写 "*",三者等效——全部放行。
第二层:纯字母数字模式(matchesPattern:1351-1361)
if (/^[a-zA-Z0-9_|]+$/.test(matcher)) {
// 精确匹配或管道分隔的多个精确匹配
if (matcher.includes('|')) {
const patterns = matcher.split('|').map(p => normalizeLegacyToolName(p.trim()))
return patterns.includes(matchQuery)
}
return matchQuery === normalizeLegacyToolName(matcher)
}
关键细节:normalizeLegacyToolName 会把旧版工具名映射到新名。也就是说你写 "Write" 或 "WriteFile"(旧名)都能正确匹配。管道符 | 会被拆成数组逐一比对——不是正则的或运算符,是精确匹配的或逻辑。
第三层:正则表达式模式(matchesPattern:1363-1380)
// 包含任何非字母数字下划线管道符的字符 → 当作正则
const regex = new RegExp(matcher)
if (regex.test(matchQuery)) return true
// 也对旧版工具名做正则匹配,兼容 legacy 名称
for (const legacyName of getLegacyToolNames(matchQuery)) {
if (regex.test(legacyName)) return true
}
如果你在 matcher 里写了 ^、.、*、(、) 等任何特殊字符,系统会自动切换到正则模式。这就是为什么 "^Notebook" 能用、".*" 也能用——因为在 [a-zA-Z0-9_|] 之外就进入正则分支。
if 条件的二次筛选用的是权限规则引擎。src/utils/hooks.ts:1390-1421 的 prepareIfConditionMatcher() 针对不同工具类型调用各自的 preparePermissionMatcher 方法。比如 Bash 工具的 matcher 会解析你的命令字符串("rm -rf *"),生成一个 AST 节点,然后用 tree-sitter 做真正的命令模式匹配——不是正则,是 AST。
一个常见坑:你在 matcher 里写 "Bash"(希望匹配 Bash 工具名),它确实全由字母数字组成——满足 [a-zA-Z0-9_|]+ 检测,所以它被当作精确匹配,不会进正则分支。这和有些人的直觉不同——他们认为 "Bash" 混合大小写、看起来像正则。实际上只有包含 ^、.、$、( 等特殊字符的字符串才会进正则分支。
五、不只是跑 shell 命令:Hook 的五种类型
很多人以为 Hooks 就是"跑 shell 命令",其实远不止。Claude Code 支持五种 Hook 类型,覆盖了从本地脚本到远程服务到 AI 判断的完整谱系。
1. command — 执行 shell 命令
最常用的类型。Claude 的操作信息以 JSON 格式通过 stdin 传给你的命令。
{
"type": "command",
"command": "npx prettier --write $(cat /dev/stdin | jq -r '.tool_input.file_path')",
"timeout": 30
}
支持 async: true 让命令在后台执行不阻塞 Claude,还有 asyncRewake: true 可以在异步命令完成后唤醒 Claude 继续处理。
2. http — 调用外部 HTTP 接口
把事件信息发到外部服务。非常适合做日志收集、团队通知、审计系统对接。
{
"type": "http",
"url": "https://your-team-webhook.com/claude-events",
"headers": {
"Authorization": "Bearer ${API_TOKEN}"
}
}
请求体是 JSON POST,包含完整的事件信息。headers 里支持 ${ENV_VAR} 语法引用环境变量,通过 allowedEnvVars 字段控制哪些环境变量可以被引用。非 2xx 响应不会阻断 Claude,只记录错误。
3. mcp_tool — 调用已连接的 MCP 工具
直接调用当前会话里已经连接的 MCP 服务器工具。输入支持模板变量。
{
"type": "mcp_tool",
"server": "memory",
"tool": "add_memory",
"input": {
"content": "Claude edited file: ${tool_input.file_path}"
}
}
这个例子在每次文件编辑后,自动把操作记录写进 MCP memory 服务器。不需要写 shell 脚本,不需要 HTTP 请求,直接用已有的 MCP 连接。
4. prompt — 让 Claude 做一次性判断
这是一个很有意思的类型:它在 Hook 触发时起一个轻量的 Claude 实例,做一次 yes/no 判断。
{
"type": "prompt",
"prompt": "以下 Bash 命令是否可能造成数据丢失或不可逆操作?只回答 yes 或 no。命令:${tool_input.command}",
"model": "haiku",
"timeout": 30
}
prompt 类型的 Hook 适合做那些不好用规则硬写、但又需要快速判断的场景。比如"这条命令是不是危险的"这个问题,用正则匹配只能覆盖已知的危险模式,用 prompt Hook 可以做更灵活的语义判断。
不过要注意:它每次触发都会消耗 token,而且有延迟。只在 PreToolUse 这类需要做决策的事件上用才划算,别挂在 PostToolUse 这种高频事件上。
5. agent — 起子 Agent 做深度评估
最重量级的类型。它会起一个有 Read、Grep、Glob 工具的子 Agent,做更复杂的评估。
{
"type": "agent",
"prompt": "检查当前工作目录下是否有未提交的敏感文件(.env, credentials, private keys)。如果发现,返回 block 决策。",
"timeout": 60
}
agent 类型目前还是实验性的,但它代表了一个很有意思的方向:用 AI 来守护 AI 的操作边界。 主 Agent 准备执行某个操作,另一个独立的 Agent 先跑一轮检查,觉得安全才放行。

5.1 源码级:execCommandHook — 命令执行引擎的内部运作
整个 Hooks 系统最核心的函数是近600行的 execCommandHook()。从源码可以知道:Windows bash 模式自动做 Cygwin 路径转换,PowerShell 模式走原生路径;异步检测协议通过实时解析 stdout 第一行 JSON 实现;asyncRewake 让后台任务完成后能唤醒 Claude。
🔬 展开查看源码详情
src/utils/hooks.ts:747-1335 是执行引擎,处理 shell 选择、路径转换、环境变量注入、stdin/stdout/stderr 生命周期、异步检测、超时控制。
Windows 路径的 Cygwin 转换陷阱。 execCommandHook:808-810 对 Windows bash 模式下的所有路径做 POSIX 转换:C:\Users\foo → /c/Users/foo。这是因为 Git Bash 底层是 Cygwin,不认识 Windows 路径。PowerShell Hook(shell: "powershell")走的是原生路径,不做此转换。这意味着:如果你在 Windows 上写 bash Hook,环境变量 CLAUDE_PROJECT_DIR 的值是 /c/Users/... 格式,不是 C:\Users\...。
环境变量注入清单(execCommandHook:882-926)。 每个 Hook 进程获得 CLAUDE_PROJECT_DIR(repo root,不是 worktree 路径)、CLAUDE_PLUGIN_ROOT(plugin/skill 的根目录)、CLAUDE_PLUGIN_DATA(plugin 数据目录)、CLAUDE_PLUGIN_OPTION_*(plugin 的用户配置项)。SessionStart/Setup/CwdChanged/FileChanged 事件还额外获得 CLAUDE_ENV_FILE——Hook 把 export VAR=value 写进这个 .sh 文件,系统随后把所有 .sh 文件拼接注入后续 Bash 命令。PowerShell Hook 不会获得此变量(PS 写的是 $env:FOO = 'bar',bash 无法解析)。
异步检测协议(execCommandHook:1117-1164)。 系统不需要等 Hook 执行完才判断它是同步还是异步——它实时解析 stdout 的第一行:如果第一行是 {"async": true},进程立刻被转入后台执行,主逻辑不等待。这个协议的精妙之处在于:Hook 的脚本可以先 echo 一行 JSON 告知"我要异步了",然后慢慢做耗时操作。配置级的 "async": true(第 995-1030 行)则更早——spawn 之后直接 stdin 写入、直接后台化,不等第一行。
asyncRewake 机制(execCommandHook:206-245)。 当 asyncRewake: true 的后台进程以 exit code 2 结束时,stderr 内容会通过消息队列注入 Claude 的上下文,让它"醒来"处理阻断信息。典型场景:写文件后异步跑测试套件,测试失败(exit 2)时 Claude 自动看到失败信息并修复。
六、退出码和 JSON 输出:Hook 如何和 Claude 通信
这是很多人忽略的关键细节。Hook 不是"跑完就完了"——它的退出码和标准输出决定了后续 Claude 的行为。
退出码
-
exit 0:成功。如果 stdout 有内容,尝试解析为 JSON
-
exit 2:阻断错误。Claude 会看到 stderr 里的信息,当前操作被中止
-
其他:非阻断错误。stderr 信息记录到日志,但 Claude 继续工作
exit 2 是一个特别设计的"强制刹车"。比如你的 PreToolUse Hook 检测到 Claude 要删一个关键文件,exit 2 + stderr 写上"禁止删除 production.env",这个操作就会被直接拦住。
JSON 输出格式
如果 Hook 以 exit 0 退出,stdout 输出的 JSON 可以精确控制 Claude 的后续行为:
{
"continue": true,
"systemMessage": "lint 发现 3 个警告,已自动修复 2 个",
"decision": "allow",
"reason": "操作安全,已通过检查",
"hookSpecificOutput": {
"additionalContext": "修复了 import 排序和尾部逗号"
}
}
几个关键字段:
continue — 设为 false 时 Claude 停止当前任务,stopReason 会显示给用户。
systemMessage — 以系统消息的形式显示给用户,适合传达重要但不阻断的信息。
decision — 只在 PreToolUse 和 PermissionRequest 事件中有效。可选值:
-
allow:放行,不再弹权限确认
-
deny(或 block):拒绝执行,Claude 会看到拒绝原因并尝试其他方案
-
ask:交给用户决定
-
defer:这个 Hook 不做判断,留给后续 Hook 或默认逻辑
hookSpecificOutput.updatedInput — 这个最有意思:它可以修改 Claude 即将执行的工具输入。比如 Claude 要写文件到 /tmp/test.js,你的 Hook 可以把路径改成 /tmp/sandbox/test.js。Claude 不知道路径被改了,但实际操作发生在你指定的安全位置。
理解了这套通信协议,你对 Hooks 能做什么的认知会完全不一样。它不只是"跑个脚本",它是一个双向通信通道——Claude 告诉 Hook "我要做什么",Hook 告诉 Claude "可以做 / 不可以做 / 改一下再做"。
6.1 源码级:退出码和 JSON 输出的处理管线
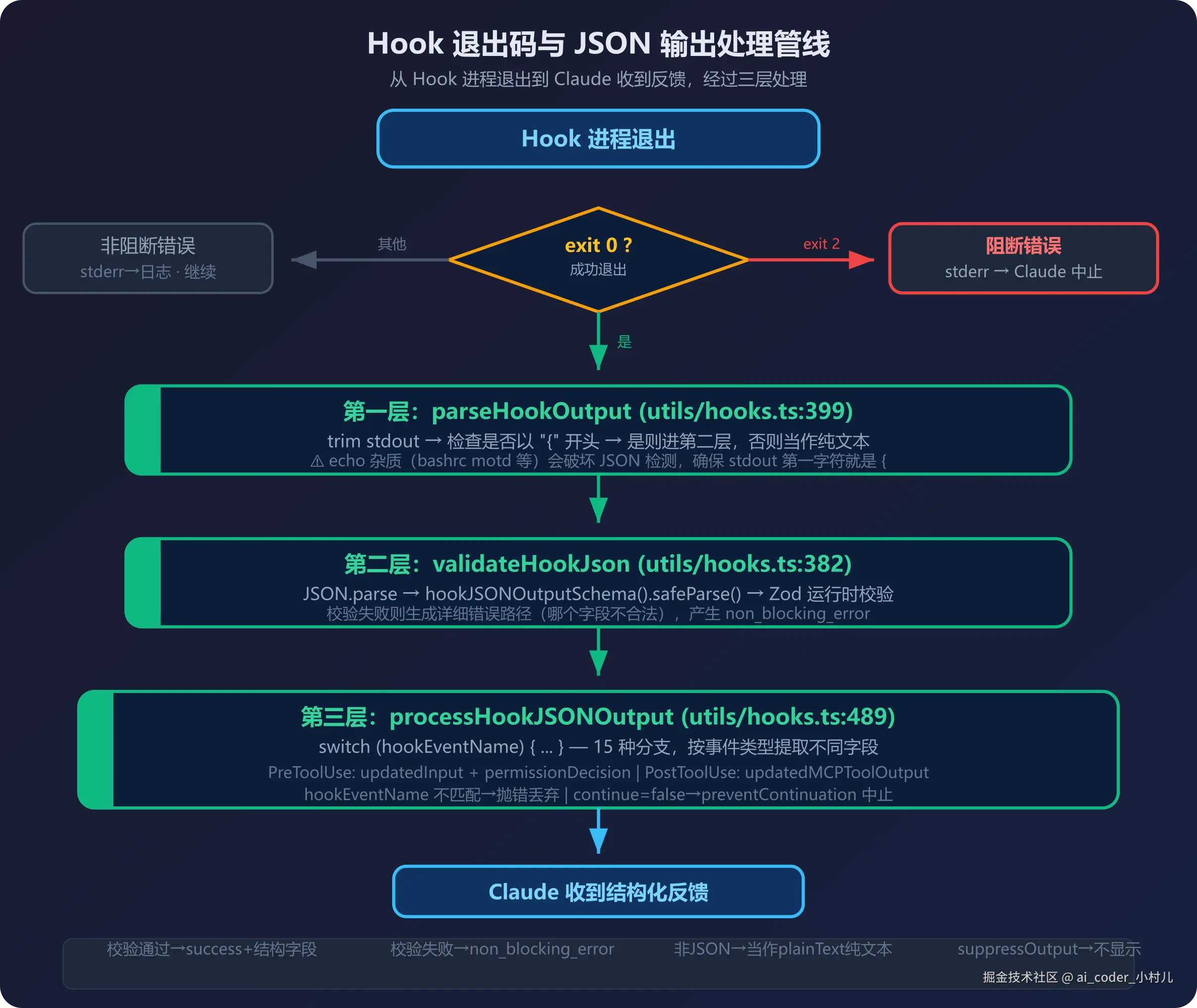
从 Hook 进程退出到 Claude 感受到反馈,中间经过三层处理管线。从源码可以知道:stdout 第一字符必须是 { 才能进 JSON 解析;Zod 校验失败会生成精确的错误路径;hookEventName 与实际事件不匹配会被直接抛错丢弃。
🔬 展开查看源码详情
第一层:parseHookOutput(src/utils/hooks.ts:399-451)
function parseHookOutput(stdout: string) {
const trimmed = stdout.trim()
if (!trimmed.startsWith('{')) {
return { plainText: stdout } // 非 JSON → 当作纯文本
}
// 尝试用 Zod 校验这个 JSON
const result = validateHookJson(trimmed)
...
}
这里有一个关键点:stdout 不是以 { 开头的,系统就直接把它当纯文本输出。所以如果你的 Hook 在 JSON 之前 echo 了任何东西(比如 bashrc 的 motd),JSON 解析会失败。这也是为什么 || true 不能放在 stdout 输出 JSON 的命令里——|| true 不解决问题,echo 的杂质字面量才是问题。
第二层:validateHookJson(src/utils/hooks.ts:382-397)
function validateHookJson(jsonString: string) {
const parsed = jsonParse(jsonString)
const validation = hookJSONOutputSchema().safeParse(parsed)
if (validation.success) {
return { json: validation.data }
}
// 构造详细的错误信息
const errors = validation.error.issues
.map(err => ` - ${err.path.join('.')}: ${err.message}`)
.join('\n')
return { validationError: `Hook JSON output validation failed:\n${errors}\n...` }
}
Zod 在这里做运行时校验。你的 JSON 结构如果不对——比如 PostToolUse Hook 的 hookSpecificOutput 里写了 updatedInput(这是 PreToolUse 才有的字段)——Zod 会生成一条具体的错误路径,告诉你是哪个字段不合法。
第三层:processHookJSONOutput(src/utils/hooks.ts:489-737)
这是最长的处理函数。它根据 hookSpecificOutput.hookEventName 的值,走不同的 switch 分支提取相应字段。例如:
case 'PreToolUse':
result.updatedInput = json.hookSpecificOutput.updatedInput
result.additionalContext = json.hookSpecificOutput.additionalContext
// 权限决策覆盖
if (json.hookSpecificOutput.permissionDecision === 'allow') {
result.permissionBehavior = 'allow'
} else if (...) { ... }
break
case 'PostToolUse':
result.updatedMCPToolOutput = json.hookSpecificOutput.updatedMCPToolOutput
result.additionalContext = json.hookSpecificOutput.additionalContext
break
注意第 583-590 行——如果 hookSpecificOutput.hookEventName 和实际触发的事件名不匹配(比如你在 PostToolUse Hook 里返回了 hookEventName: 'PreToolUse'),系统会直接抛错。这是一个常见的坑:你需要保证返回的 hookEventName 和实际事件一致,否则整个 Hook 结果会被丢弃。
退出码的实际处理流程(src/utils/hooks.ts:2617-2696):
exit 0 且 stdout 是 JSON → processHookJSONOutput → 结构化处理
exit 0 且 stdout 不是 JSON → 创建 hook_success 消息,stdout 作为纯文本内容
exit 2 → 创建 hook_blocking_error 消息,stderr 作为阻断原因
其他 exit code → 创建 hook_non_blocking_error 消息,记录错误但不阻断
这里有两个容易被忽略的细节:
-
exit 2 的 stderr 内容会被包装成 [hookCommand]: ${stderr} 格式传给 Claude。所以你的 stderr 文字应该直接是 Claude 能理解的说明,不需要额外格式。
-
exit 0 但 stdout 是 JSON 且 suppressOutput: true 时,即使 JSON 校验通过,stdout 也不会出现在对话记录里——只处理结构化字段。这在你只想修改 updatedInput 而不想污染上下文时很有用。
七、PreToolUse 深入:拦截、放行、修改
PreToolUse 值得单独拉出来讲,因为它是整个 Hooks 体系里最强大、也最需要谨慎使用的事件。
拦截危险操作
最直接的用法:阻止 Claude 执行你不想让它碰的命令。
{
"hooks": {
"PreToolUse": [
{
"matcher": "Bash",
"if": "Bash(rm -rf *)",
"hooks": [
{
"type": "command",
"command": "echo '{\"decision\": \"deny\", \"reason\": \"禁止执行 rm -rf,请使用更安全的删除方式\"}'"
}
]
}
]
}
}
Claude 会看到拒绝原因,然后尝试用其他方式完成任务——比如逐个删除,或者用 trash 命令。它不会傻等,也不会崩溃,而是理解了约束之后调整策略。
自动放行可信操作
反过来,你也可以让某些操作自动通过,不再弹权限确认框。
{
"hooks": {
"PreToolUse": [
{
"matcher": "Bash",
"if": "Bash(npm test *)",
"hooks": [
{
"type": "command",
"command": "echo '{\"decision\": \"allow\"}'"
}
]
}
]
}
}
每次 Claude 要跑 npm test,不再问你"确认执行吗?",直接跑。这在你信任测试命令的安全性时很有用——减少人工确认的打断,让 Claude 的工作流更顺畅。
修改工具输入
最高级的用法:在 Claude 不知情的情况下,修改它即将执行的操作。
{
"hooks": {
"PreToolUse": [
{
"matcher": "Write",
"hooks": [
{
"type": "command",
"command": "python3 -c \"import sys,json; d=json.load(sys.stdin); d['hookSpecificOutput']={'updatedInput':{'file_path': d['tool_input']['file_path'].replace('/src/','/src/sandbox/')}}; print(json.dumps(d))\""
}
]
}
]
}
}
这个 Hook 把所有写入 /src/ 的文件重定向到 /src/sandbox/。Claude 以为自己在正常写文件,实际上所有改动都进了沙箱。等你确认没问题,再合并回去。
这种能力在高风险场景下特别有价值——你不需要告诉 Claude "先写到沙箱里"(它可能忘),而是从系统层面保证它的所有写操作都是安全的。
八、Hooks 和 Skills 的联动:frontmatter 里的 hooks 字段
前面说了 Hooks 的配置放在 settings.json 里。但还有一种更精细的用法:把 Hooks 写在 Skill 的 frontmatter 里,让它只在这个 Skill 激活期间生效。
---
name: secure-deploy
description: Deploy with security checks. Manual trigger only.
disable-model-invocation: true
context: fork
hooks:
PreToolUse:
- matcher: "Bash"
hooks:
- type: command
command: "./scripts/deploy-security-check.sh"
statusMessage: "Running security scan..."
Stop:
- hooks:
- type: command
command: "./scripts/notify-deploy-complete.sh"
once: true
---
执行部署流程...
这里有几个值得注意的点。
hooks 字段的格式和 settings.json 里的一模一样,只是写成了 YAML。当这个 Skill 被触发时,这些 Hooks 才生效;Skill 结束后,Hooks 自动失效。
statusMessage 字段可以自定义 Hook 执行时的等待提示,用户会在界面上看到"Running security scan..."而不是默认的等待动画。
once: true 表示这个 Hook 在当前会话里只执行一次。比如部署完成通知,你只想收到一次,不想每次 Claude 说完话都发一遍。这个字段只在 Skill / Agent 的 frontmatter hooks 里有效。
这个组合的威力在于:Skill 定义了"做什么",Hooks 保证了"做的过程中,哪些安全检查绝对不能跳过"。 Skill 是概率型的任务流程,Hooks 是确定型的安全护栏。两者绑在一起,一个能力包就同时有了灵活性和可靠性。
8.1 源码级:Hook 的并行执行与权限优先级仲裁
当同一个事件上挂了多个 Hook,它们并行执行而非串行。从源码可以知道:权限优先级为 deny > ask > allow(安全优先),仅 allow/ask 的 Hook 可修改工具输入,去重用 \0 分隔符确保不同 plugin 的同名 Hook 不被误合并。
🔬 展开查看源码详情
src/utils/hooks.ts:2142-2972 的 executeHooks() 用 all(hookPromises) 将同一个事件的所有匹配 Hook 并行启动。每个 Hook 在自己的 Promise 里独立运行,有自己的超时和 abort signal。
但并行执行带来了一个问题:多个 Hook 可能返回不一致的权限决策。比如 Hook A 说 allow,Hook B 说 deny,应该听谁的?
权限优先级规则在 src/utils/hooks.ts:2820-2847:
deny > ask > allow
一个 deny 会覆盖所有 allow 和 ask;一个 ask 会覆盖 allow;allow 只是最后的 fallback。这个顺序不是随意的——它体现了安全优先的原则:任何 Hook 的拒绝都能推翻其他 Hook 的放行,但任何一个 Hook 的放行不能推翻其他 Hook 的拒绝。
updatedInput 的合并也值得注意(src/utils/hooks.ts:2850-2880):只有标记了 allow 或 ask 的 Hook 才能修改工具输入。标记为 deny 的 Hook 的 updatedInput 会被忽略——既然都拒绝执行了,修改输入就没有意义。
去重机制(src/utils/hooks.ts:1453-1455):
function hookDedupKey(m: MatchedHook, payload: string): string {
return `${m.pluginRoot ?? m.skillRoot ?? ''}\0${payload}`
}
同一个 Hook 命令可能同时出现在用户级和项目级配置中,去重机制用 \0 分隔符 + plugin/skill 命名空间确保:同一个来源内的重复只执行一次,但不同 plugin 的同名 Hook 不会相互覆盖。去重键包含 command/prompt/url 内容、shell 类型、和 if 条件——也就是说,{command: "echo x", shell: "bash"} 和 {command: "echo x", shell: "powershell"} 被视为不同的 Hook。
内部 callback hook 的性能优化(src/utils/hooks.ts:2036-2067):当所有匹配的 Hook 都是 callback 类型(内部 Hook,如 sessionFileAccessHooks、attributionHooks)时,系统跳过 span/tracing/progress/resultLoop 等全套开销,直接同步调用。实测这个 fast-path 将 PostToolUse 的每次命中从 6µs 降到 ~1.8µs。这对理解系统设计很重要——内部 Hook 和用户 Hook 是两条不同的执行路径。
九、Hook 的输入:Claude 告诉你它在做什么
每个 Hook 触发时,都会收到一个 JSON 输入(对 command 类型是 stdin,对 http 类型是请求体)。这个输入包含了当前事件的完整上下文。
所有事件都有的公共字段:
{
"session_id": "abc123",
"transcript_path": "/path/to/transcript.jsonl",
"cwd": "/your/project/root",
"hook_event_name": "PostToolUse"
}
Tool 级事件额外包含:
{
"tool_name": "Write",
"tool_input": {
"file_path": "/src/index.ts",
"content": "..."
},
"tool_output": "File written successfully" // 只在 PostToolUse 里有
}
SessionStart 事件有一个特殊能力:通过 CLAUDE_ENV_FILE 环境变量,你可以把 Hook 设置的环境变量持久化到整个会话。
#!/bin/bash
if [ -n "$CLAUDE_ENV_FILE" ]; then
echo "export PROJECT_VERSION=$(cat package.json | jq -r '.version')" >> "$CLAUDE_ENV_FILE"
echo "export GIT_BRANCH=$(git branch --show-current)" >> "$CLAUDE_ENV_FILE"
fi
这样 Claude 在整个会话里都能访问到 $PROJECT_VERSION 和 $GIT_BRANCH,不需要每次重新查。
十、实战:一个项目级配置的完整例子
把前面讲的这些组合成一个真实可用的项目配置。这个配置覆盖了日常开发最常用的五个自动化场景。
{
"hooks": {
"SessionStart": [
{
"matcher": "startup",
"hooks": [
{
"type": "command",
"command": "echo \"分支: $(git branch --show-current) | 待提交: $(git status --short | wc -l | tr -d ' ') 个文件\""
}
]
}
],
"PreToolUse": [
{
"matcher": "Bash",
"if": "Bash(rm -rf *)",
"hooks": [
{
"type": "command",
"command": "echo '{\"decision\": \"deny\", \"reason\": \"rm -rf 被禁止,请用更安全的删除方式\"}'"
}
]
}
],
"PostToolUse": [
{
"matcher": "Write|Edit",
"hooks": [
{
"type": "command",
"command": "npx prettier --write $(cat /dev/stdin | jq -r '.tool_input.file_path') 2>/dev/null || true"
}
]
},
{
"matcher": "Write|Edit",
"if": "Write(*.ts)|Write(*.tsx)|Edit(*.ts)|Edit(*.tsx)",
"hooks": [
{
"type": "command",
"command": "npx tsc --noEmit 2>&1 | head -15 || true"
}
]
},
{
"matcher": "Write|Edit",
"hooks": [
{
"type": "command",
"command": "echo \"$(date '+%H:%M:%S') $(cat /dev/stdin | jq -r '.tool_name'): $(cat /dev/stdin | jq -r '.tool_input.file_path')\" >> .claude-activity.log"
}
]
}
],
"Stop": [
{
"matcher": "*",
"hooks": [
{
"type": "command",
"command": "osascript -e 'display notification \"任务完成\" with title \"Claude Code\"' 2>/dev/null || notify-send 'Claude Code' '任务完成' 2>/dev/null || true"
}
]
}
]
}
}
这个配置做了五件事:
-
新会话启动时,显示当前分支和未提交文件数——Claude 从第一步就有正确的上下文
-
拦截
rm -rf——不管 Claude 出于什么理由想执行这个命令,直接拒绝
-
写 / 编辑文件后自动格式化——
|| true 确保不支持的文件类型不会阻断流程
-
TypeScript 文件改动后自动类型检查——Claude 立刻看到类型错误,下一步就能修复
-
任务完成后桌面通知——macOS 和 Linux 都覆盖,你可以安心去做别的事
10.1 源码级:信任检查——为什么所有 Hook 都要过一道安全闸
从源码可以知道:shouldSkipHookDueToTrust() 是所有 Hook 执行前的统一守门人——交互模式下未通过信任对话框则所有 Hook 跳过。这个集中检查源于两个历史漏洞(SessionEnd 和 SubagentStop 绕过信任),修复后成为唯一的安全入口。
🔬 展开查看源码详情
src/utils/hooks.ts:286-296 的 shouldSkipHookDueToTrust() 是 Hook 执行的第一道守门人,在 executeHooks() 的第 1994 行被调用。它强制执行一条简单但重要的规则:
export function shouldSkipHookDueToTrust(): boolean {
const isInteractive = !getIsNonInteractiveSession()
if (!isInteractive) {
return false // SDK/CI 模式:隐式信任,直接执行
}
const hasTrust = checkHasTrustDialogAccepted()
return !hasTrust // 交互模式下:没通过信任对话框 → 跳过
}
所有 Hook——无一例外——都需要 workspace trust。 这不是针对某个具体事件的检查,而是对所有事件的集中拦截。源码注释里明确写了两条历史漏洞:SessionEnd Hook 在用户拒绝信任对话框时仍执行了;SubagentStop Hook 在子代理完成时绕过了信任检查。这两个漏洞促使团队把信任检查集中到一个地方——executeHooks() 入口处——而不是分散在每个事件调用点。
与之配套的是 hooksConfigSnapshot.ts:18-53 的快照机制:信任对话框弹出之前,系统就通过 captureHooksConfigSnapshot() 拍了一张 Hook 配置的快照。即使用户拒绝信任,后来 Hook 配置也不会被动态加载和解析。先截屏、再弹窗、再执行——用一个时间顺序保证了"拒绝信任后,没有新的 Hook 能被注入"。
在企业策略层面,shouldDisableAllHooksIncludingManaged() (hooksConfigSnapshot.ts:83-88)和 isEnvTruthy(CLAUDE_CODE_SIMPLE) (hooks.ts:1982)提供了两个额外的全局开关:前者由企业策略层的 manage settings 控制,后者是一个环境变量级别的紧急熔断。
十一、避坑指南
Hook 命令要快。 Hook 在 Claude 工作流里同步执行(除非你用了 async: true)。一个跑 5 秒的 Hook,每次写文件都阻塞 5 秒。全量测试套件不适合放在 PostToolUse 里——只跑相关测试或做快速检查。
用 || true 处理非关键 Hook 的失败。 Prettier 不支持的文件类型会报错,这不应该影响 Claude 继续工作。非关键的 Hook 加上 || true,让失败静默通过。
stdout 不要有杂质。 如果你的 Hook 返回 JSON,确保 stdout 里只有 JSON。shell 的 .bashrc / .zshrc 里的 echo、motd、conda 提示等都会污染输出,导致 JSON 解析失败。
PreToolUse 的 deny 不是终点。 Claude 收到 deny 后不会崩溃,它会理解拒绝原因并尝试其他方案。所以 reason 字段尽量写清楚"为什么不行"和"建议怎么做",这样 Claude 的调整方向会更准。
多个 Hook 的执行顺序。 同一个事件上挂了多个 Hook,它们并行执行(源码中用 all(hookPromises) 并发调度)。返回的权限决策按 deny > ask > allow 的优先级仲裁。需要注意的是:并不是配得越靠前 Hook 就越先生效——安全优先的仲裁规则才是决定最终行为的机制。
用 /hooks 命令调试。 在 Claude Code 里输入 /hooks,可以查看当前生效的所有 Hook 配置。配完之后先确认它们真的被加载了,再去测试效果。
十二、什么该用 Skill,什么该用 Hooks
到这里,一个自然的问题是:同样是"让 Claude 写完文件后跑 lint",我到底该写在 Skill 里还是配成 Hook?
判断标准只有一个:
这件事需不需要模型理解?
- 需要理解上下文才能决定怎么做 → Skill
- 不需要理解,每次都一样执行 → Hook
"代码审查时按固定顺序检查数据库、异步和错误处理" → 这需要 Claude 理解代码逻辑,Skill。
"每次写文件后跑 prettier" → 不需要理解,纯机械执行,Hook。
"检测到 Claude 要执行危险命令时阻止" → 不需要理解(或者用 prompt 类型做轻量判断),Hook。
"根据 PR 的改动范围决定需要跑哪些测试套件" → 需要理解改动语义,Skill。
更精确地说:Skill 是你给 Claude 的任务书,Hooks 是你给系统的执行规则。 Skill 的执行者是模型,Hooks 的执行者是系统。当你发现自己在 Skill 里写的某一步"每次都一样、不需要判断",那一步就该提取成 Hook。
最强的组合是两者配合:Skill 定义任务流程和判断逻辑,Hooks(尤其是 Skill frontmatter 里的 hooks)保证流程中的确定性步骤不会被跳过。
本篇实践任务
任务一(5 分钟,马上做): 在你的 ~/.claude/settings.json 里加一个 Stop Hook,任务结束后发桌面通知。做完之后,开一个新会话让 Claude 帮你改一个文件,然后去泡杯茶——等通知弹出来再回来看结果。
任务二(有 TypeScript 项目必做): 加上 PostToolUse Hook,Write 和 Edit 之后自动跑 prettier --write + tsc --noEmit。观察 Claude 的行为变化:当它看到类型错误时,会不会主动去修?
任务三(想做安全防护的): 配一个 PreToolUse Hook,拦截 rm -rf 命令。然后故意让 Claude 执行一个可能触发 rm -rf 的任务,观察它收到 deny 后的调整策略。
下篇预告
第 05b 篇:Plugins 打包与分发——把 Skill + Hooks + CLAUDE.md 封装成团队可复用的能力包
上一篇讲了 Skill(任务模板),这一篇讲了 Hooks(确定性守卫),加上第 04 篇的 CLAUDE.md(行为约束)——这三者刚好是 Plugin 的三块核心砖。下一篇聚焦怎么把它们打包成一个可安装、可共享的 Plugin,让你把个人的最佳实践变成团队的基础设施。
AI Coding 系列持续更新。Skill 管"怎么做",Hooks 管"做完之后必须发生什么"——把概率型和确定型的控制手段分清楚,你对 Claude 的掌控感会提升一个量级。