解法
思路和算法
矩阵 $\textit{grid}$ 的大小是 $m \times n$。用 $\textit{total}$ 表示矩阵 $\textit{grid}$ 的所有元素之和。
如果不移除单元格,则判断方法与「3546. 等和矩阵分割 I」相同。
对于移除一个单元格的情况,需要计算两部分的元素和之差 $\textit{diff}$,然后考虑如下两个方面。
-
判断元素较大的一部分是否包含等于 $\textit{diff}$ 的元素。
-
判断是否可以从元素较大的一部分移除一个元素 $\textit{diff}$,使得该部分的剩余元素保持连通。
以下说明判断是否存在符合要求的按行分割,判断过程中需要依次遍历矩阵 $\textit{grid}$ 的每一行。
首先考虑只满足最多移除一个单元格的限制,不考虑连通性限制。
使用两个哈希表分别记录矩阵 $\textit{grid}$ 的上边部分和下边部分的每个元素的出现次数,将两个哈希表分别记为 $\textit{partOne}$ 和 $\textit{partTwo}$。初始时,计算矩阵 $\textit{grid}$ 中的所有元素的出现次数并存入哈希表 $\textit{partTwo}$。
从上到下遍历矩阵 $\textit{grid}$ 的每一行,将遍历到的每个元素在哈希表 $\textit{partOne}$ 中将出现次数增加 $1$ 并在哈希表 $\textit{partTwo}$ 中将出现次数减少 $1$,将哈希表 $\textit{partTwo}$ 中的出现次数变成 $0$ 的元素移除,遍历过程中维护遍历到的所有元素之和 $\textit{partOneSum}$,即上边部分的元素之和。每一行遍历结束之后,执行如下操作。
-
如果 $\textit{partOneSum} \times 2 = \textit{total}$,则将当前行作为上边部分的最后一行,即可满足在不移除元素的情况下将矩阵水平分割成元素和相等的两个非空部分。
-
如果 $\textit{partOneSum} \times 2 > \textit{total}$,记 $\textit{diff} = \textit{partOneSum} \times 2 - \textit{total}$,则当哈希表 $\textit{partOne}$ 中存在元素 $\textit{diff}$ 时,将当前行作为上边部分的最后一行,即可满足在从上边部分移除一个元素的情况下将矩阵水平分割成元素和相等的两个非空部分。
-
如果 $\textit{partOneSum} \times 2 < \textit{total}$,记 $\textit{diff} = \textit{total} - \textit{partOneSum} \times 2$,则当哈希表 $\textit{partTwo}$ 中存在元素 $\textit{diff}$ 时,将当前行作为上边部分的最后一行,即可满足在从下边部分移除一个元素的情况下将矩阵水平分割成元素和相等的两个非空部分。
然后考虑连通性限制。如果从一部分移除一个单元格之后导致该部分的剩余元素不连通,则有如下两种情况。
为了实现连通性限制,需要做如下调整。
-
当遍历到行下标 $i = 0$ 时,只将 $\textit{grid}[0][0]$ 和 $\textit{grid}[0][n - 1]$ 在哈希表 $\textit{partOne}$ 中的出现次数增加 $1$,列下标范围 $[1, n - 2]$ 的元素都不更新哈希表 $\textit{partOne}$。行下标 $i = 0$ 的判断结束之后,将列下标范围 $[1, n - 2]$ 的所有元素在哈希表 $\textit{partOne}$ 中的出现次数增加 $1$。
-
当遍历到行下标 $i = m - 2$ 时,将行下标 $m - 1$ 的列下标范围 $[1, n - 2]$ 的所有元素在哈希表 $\textit{partTwo}$ 中的出现次数减少 $1$,并移除出现次数变成 $0$ 的元素。
-
当 $n = 1$ 时,对于遍历到的每个行下标 $i$,应做额外判断。如果需要从上边部分移除一个元素 $\textit{diff}$,则必须满足 $\textit{diff} = \textit{grid}[0][0]$ 或 $\textit{diff} = \textit{grid}[i][0]$;如果需要从下边部分移除一个元素 $\textit{diff}$,则必须满足 $\textit{diff} = \textit{grid}[i + 1][0]$ 或 $\textit{diff} = \textit{grid}[m - 1][0]$。
根据上述操作,即可判断是否存在符合要求的按行分割。
使用同样的方法可以判断是否存在符合要求的按列分割,判断过程中需要依次遍历矩阵 $\textit{grid}$ 的每一列。
代码
###Java
class Solution {
public boolean canPartitionGrid(int[][] grid) {
long total = 0;
int m = grid.length, n = grid[0].length;
for (int i = 0; i < m; i++) {
for (int j = 0; j < n; j++) {
total += grid[i][j];
}
}
return canPartition(grid, m, n, total, true) || canPartition(grid, m, n, total, false);
}
public boolean canPartition(int[][] grid, int m, int n, long total, boolean horizontal) {
Map<Long, Integer> partOne = new HashMap<Long, Integer>();
Map<Long, Integer> partTwo = getCounts(grid, m, n, horizontal);
long partOneSum = 0;
if (horizontal) {
for (int i = 0; i < m - 1; i++) {
for (int j = 0; j < n; j++) {
partOneSum += grid[i][j];
update(grid[i][j], i, j, m, n, horizontal, partOne, partTwo);
}
if (i == m - 2) {
for (int j = 1; j < n - 1; j++) {
long num = grid[m - 1][j];
partTwo.put(num, partTwo.get(num) - 1);
if (partTwo.get(num) == 0) {
partTwo.remove(num);
}
}
}
if (existsPartition(partOneSum, total, partOne, partTwo, n, grid, new int[]{0, 0}, new int[]{i, 0}, new int[]{i + 1, 0}, new int[]{m - 1, 0})) {
return true;
}
if (i == 0) {
for (int j = 1; j < n - 1; j++) {
long num = grid[0][j];
partOne.put(num, partOne.getOrDefault(num, 0) + 1);
}
}
}
} else {
for (int j = 0; j < n - 1; j++) {
for (int i = 0; i < m; i++) {
partOneSum += grid[i][j];
update(grid[i][j], i, j, m, n, horizontal, partOne, partTwo);
}
if (j == n - 2) {
for (int i = 1; i < m - 1; i++) {
long num = grid[i][n - 1];
partTwo.put(num, partTwo.get(num) - 1);
if (partTwo.get(num) == 0) {
partTwo.remove(num);
}
}
}
if (existsPartition(partOneSum, total, partOne, partTwo, m, grid, new int[]{0, 0}, new int[]{0, j}, new int[]{0, j + 1}, new int[]{0, n - 1})) {
return true;
}
if (j == 0) {
for (int i = 1; i < m - 1; i++) {
long num = grid[i][0];
partOne.put(num, partOne.getOrDefault(num, 0) + 1);
}
}
}
}
return false;
}
public Map<Long, Integer> getCounts(int[][] grid, int m, int n, boolean horizontal) {
Map<Long, Integer> counts = new HashMap<Long, Integer>();
for (int i = 0; i < m; i++) {
for (int j = 0; j < n; j++) {
long num = grid[i][j];
counts.put(num, counts.getOrDefault(num, 0) + 1);
}
}
return counts;
}
public void update(long num, int row, int col, int m, int n, boolean horizontal, Map<Long, Integer> partOne, Map<Long, Integer> partTwo) {
if (remainConnected(row, col, m, n, horizontal)) {
partOne.put(num, partOne.getOrDefault(num, 0) + 1);
partTwo.put(num, partTwo.get(num) - 1);
if (partTwo.get(num) == 0) {
partTwo.remove(num);
}
}
}
public boolean existsPartition(long partOneSum, long total, Map<Long, Integer> partOne, Map<Long, Integer> partTwo, int length, int[][] grid, int[] pos0, int[] pos1, int[] pos2, int[] pos3) {
if (partOneSum * 2 == total) {
return true;
} else if (partOneSum * 2 > total) {
long diff = partOneSum * 2 - total;
if (partOne.containsKey(diff)) {
if (length > 1 || (grid[pos0[0]][pos0[1]] == diff || grid[pos1[0]][pos1[1]] == diff)) {
return true;
}
}
} else {
long diff = total - partOneSum * 2;
if (partTwo.containsKey(diff)) {
if (length > 1 || (grid[pos2[0]][pos2[1]] == diff || grid[pos3[0]][pos3[1]] == diff)) {
return true;
}
}
}
return false;
}
public boolean remainConnected(int row, int col, int m, int n, boolean horizontal) {
if (horizontal) {
return row > 0 || (col == 0 || col == n - 1);
} else {
return col > 0 || (row == 0 || row == m - 1);
}
}
}
###C#
public class Solution {
public bool CanPartitionGrid(int[][] grid) {
long total = 0;
int m = grid.Length, n = grid[0].Length;
for (int i = 0; i < m; i++) {
for (int j = 0; j < n; j++) {
total += grid[i][j];
}
}
return CanPartition(grid, m, n, total, true) || CanPartition(grid, m, n, total, false);
}
public bool CanPartition(int[][] grid, int m, int n, long total, bool horizontal) {
IDictionary<long, int> partOne = new Dictionary<long, int>();
IDictionary<long, int> partTwo = GetCounts(grid, m, n, horizontal);
long partOneSum = 0;
if (horizontal) {
for (int i = 0; i < m - 1; i++) {
for (int j = 0; j < n; j++) {
partOneSum += grid[i][j];
Update(grid[i][j], i, j, m, n, horizontal, partOne, partTwo);
}
if (i == m - 2) {
for (int j = 1; j < n - 1; j++) {
long num = grid[m - 1][j];
partTwo[num]--;
if (partTwo[num] == 0) {
partTwo.Remove(num);
}
}
}
if (ExistsPartition(partOneSum, total, partOne, partTwo, n, grid, new int[]{0, 0}, new int[]{i, 0}, new int[]{i + 1, 0}, new int[]{m - 1, 0})) {
return true;
}
if (i == 0) {
for (int j = 1; j < n - 1; j++) {
long num = grid[0][j];
partOne.TryAdd(num, 0);
partOne[num]++;
}
}
}
} else {
for (int j = 0; j < n - 1; j++) {
for (int i = 0; i < m; i++) {
partOneSum += grid[i][j];
Update(grid[i][j], i, j, m, n, horizontal, partOne, partTwo);
}
if (j == n - 2) {
for (int i = 1; i < m - 1; i++) {
long num = grid[i][n - 1];
partTwo[num]--;
if (partTwo[num] == 0) {
partTwo.Remove(num);
}
}
}
if (ExistsPartition(partOneSum, total, partOne, partTwo, m, grid, new int[]{0, 0}, new int[]{0, j}, new int[]{0, j + 1}, new int[]{0, n - 1})) {
return true;
}
if (j == 0) {
for (int i = 1; i < m - 1; i++) {
long num = grid[i][0];
partOne.TryAdd(num, 0);
partOne[num]++;
}
}
}
}
return false;
}
public IDictionary<long, int> GetCounts(int[][] grid, int m, int n, bool horizontal) {
IDictionary<long, int> counts = new Dictionary<long, int>();
for (int i = 0; i < m; i++) {
for (int j = 0; j < n; j++) {
long num = grid[i][j];
if (RemainConnected(i, j, m, n, horizontal)) {
counts.TryAdd(num, 0);
counts[num]++;
}
}
}
return counts;
}
public void Update(long num, int row, int col, int m, int n, bool horizontal, IDictionary<long, int> partOne, IDictionary<long, int> partTwo) {
if (RemainConnected(row, col, m, n, horizontal)) {
partOne.TryAdd(num, 0);
partOne[num]++;
partTwo[num]--;
if (partTwo[num] == 0) {
partTwo.Remove(num);
}
}
}
public bool ExistsPartition(long partOneSum, long total, IDictionary<long, int> partOne, IDictionary<long, int> partTwo, int length, int[][] grid, int[] pos0, int[] pos1, int[] pos2, int[] pos3) {
if (partOneSum * 2 == total) {
return true;
} else if (partOneSum * 2 > total) {
long diff = partOneSum * 2 - total;
if (partOne.ContainsKey(diff)) {
if (length > 1 || (grid[pos0[0]][pos0[1]] == diff || grid[pos1[0]][pos1[1]] == diff)) {
return true;
}
}
} else {
long diff = total - partOneSum * 2;
if (partTwo.ContainsKey(diff)) {
if (length > 1 || (grid[pos2[0]][pos2[1]] == diff || grid[pos3[0]][pos3[1]] == diff)) {
return true;
}
}
}
return false;
}
public bool RemainConnected(int row, int col, int m, int n, bool horizontal) {
if (horizontal) {
return row > 0 || (col == 0 || col == n - 1);
} else {
return col > 0 || (row == 0 || row == m - 1);
}
}
}
复杂度分析


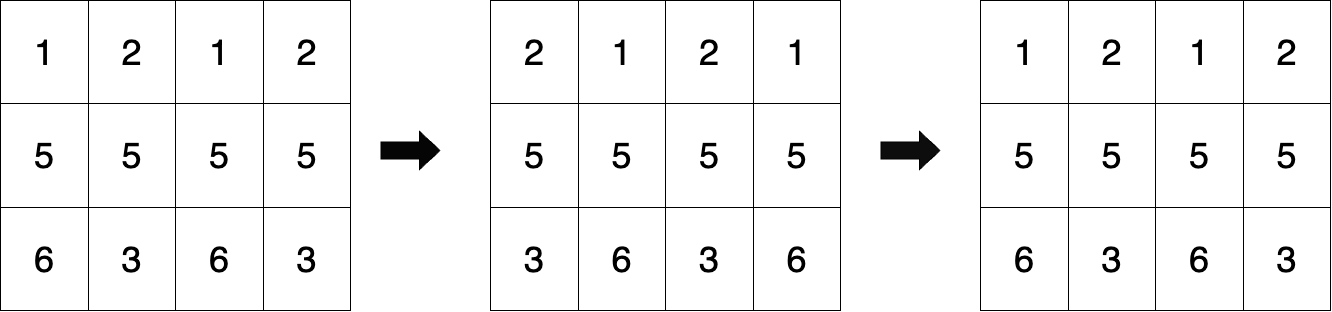 初始矩阵如图一所示。
图二表示对奇数行右移一次且对偶数行左移一次后的矩阵状态。
图三是经过两次循环移位后的最终矩阵状态,与初始矩阵相同。
因此,返回 true 。
初始矩阵如图一所示。
图二表示对奇数行右移一次且对偶数行左移一次后的矩阵状态。
图三是经过两次循环移位后的最终矩阵状态,与初始矩阵相同。
因此,返回 true 。


