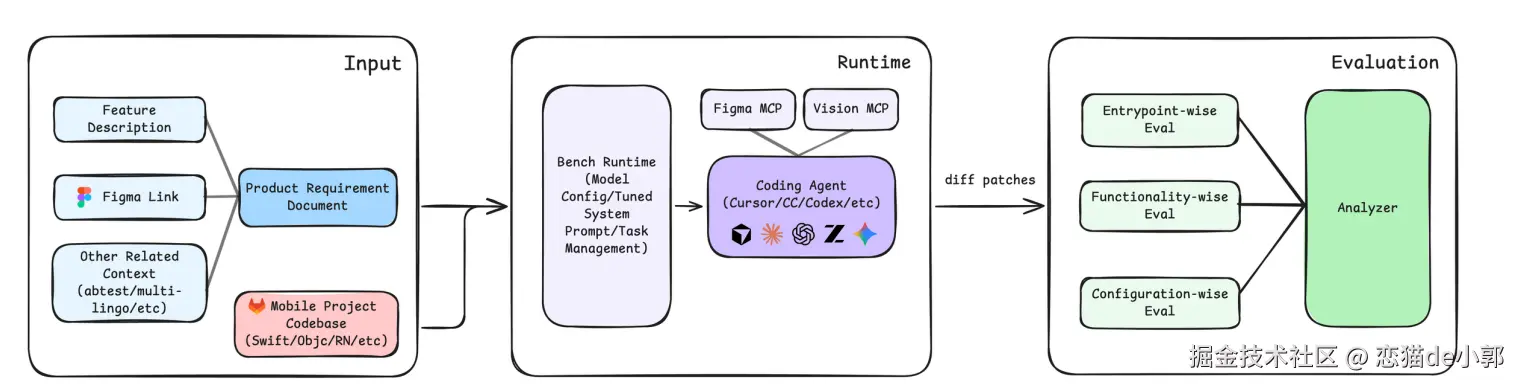
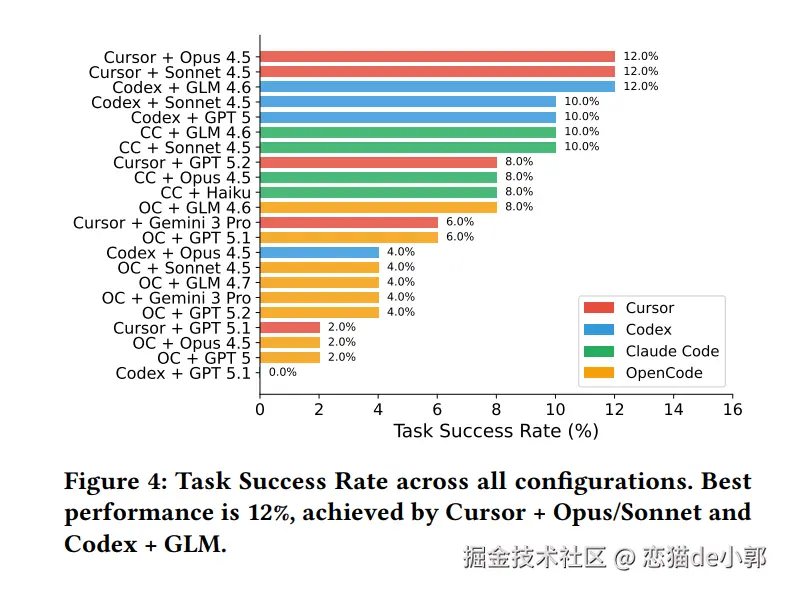
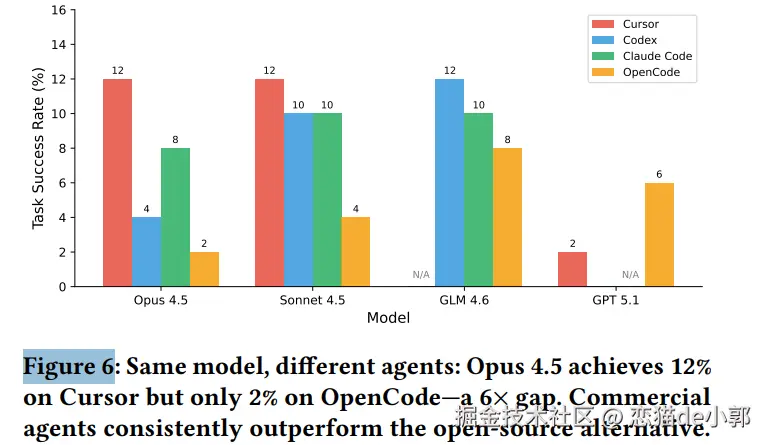
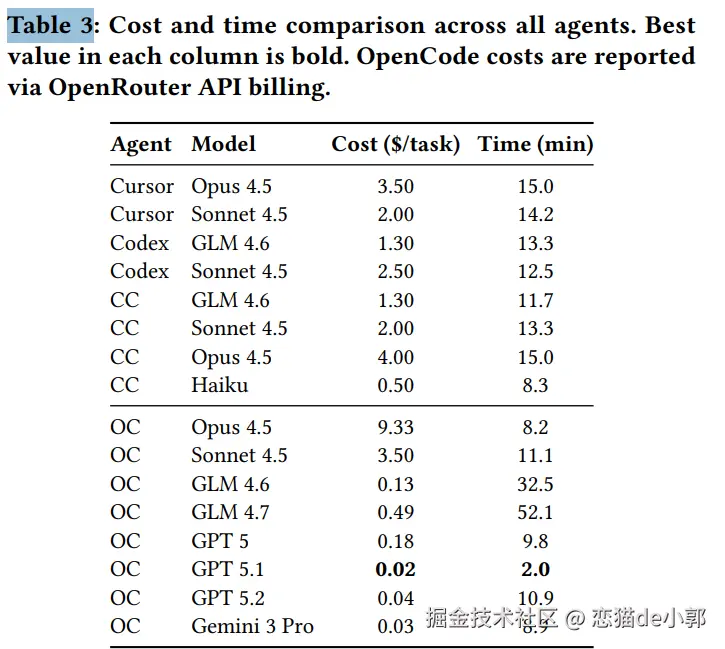
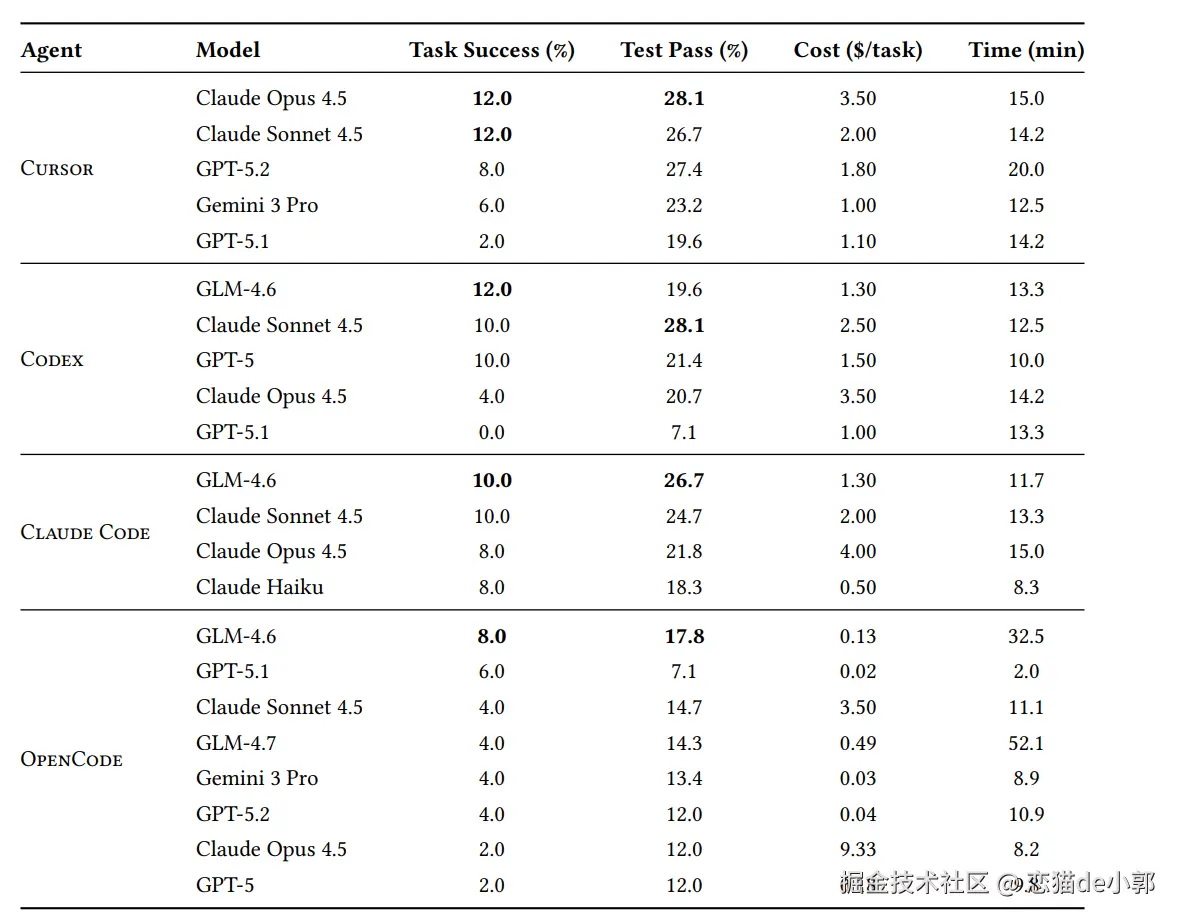
iOS Bug AutoFix 是一个基于 AI 的 iOS 代码 Bug 自动定位工具。它从自然语言 Bug 描述出发,通过三步流水线 (信息提取 → 粗筛定位 → 精确定位)自动定位到问题代码的具体文件和行号。本次分析以两条实际命令的运行为例。
index — 构建代码索引
1 npx ts-node src/index.ts index
入口文件 index.ts 的 main() 函数首先调用 loadConfig() 读取配置文件:
配置路径 : tool/config/autofix.config.json
读取结果 :
repoRoot → /Users/wyan/Develop/Code/branch/Bugfix
openai.model → deepseek-chat
index.includeDirs → ["Classes/Modules"]
同时在构造 BugAutoFixer 时,基于 repoRoot 设置了运行时目录:
.autofix/ 根目录
.autofix/index.db — SQLite 索引数据库
.autofix/results/ — 定位结果目录
.autofix/logs/ — 日志目录(预留)
BugAutoFixer 构造函数中创建 FileLocator,而 FileLocator 构造时会创建 PageMapper。 page-mapper.ts 会按优先级搜索 page-mapping.json 文件:
1 ✓ 已加载页面映射表: .../page-mapping.json (14 个页面)
映射表内容示例(来自 page-mapping.example.json):
1 2 3 4 5 { "个人主页" : [ "QMPersonalInfoViewController" , "QMGeneralUserHeaderView" , "QMGeneralUserV2TabVC" ] , "播放页" : [ "QMAudioPlayerVC" , "QMPlayingSongPage" , ...] , ... }
页面映射表同时构建了反向映射(类名 → 页面名),共 14 个页面。
code-indexer.ts 的 buildFullIndex() 方法执行以下步骤:
创建 SQLite 数据库(WAL 模式),包含:
表
用途
file_index文件级索引(类名、方法名、协议、UI 类、无障碍标记等)
class_hierarchy类继承关系
file_fts (FTS5)
全文搜索虚拟表,通过触发器自动同步
使用 find 命令扫描仓库,由于配置了 includeDirs: ["Classes/Modules"],实际执行的命令相当于:
1 find "/Users/wyan/Develop/Code/branch/Bugfix" -type f \( -name "*.swift" -o -name "*.m" -o -name "*.h" \) -and \( -path "*/Classes/Modules/*" \)
1 Found 17522 source files to index
在一个 SQLite 事务中,对每个文件进行解析。根据文件扩展名分别调用:
.swift 文件parseSwiftFile(): 用正则提取 class/struct/enum/extension 声明、func 方法名、协议、UI* 类使用、accessibility* 属性、@IBOutlet
.m / .h 文件parseObjCFile(): 用正则提取 @interface/@implementation(含 Category)、方法名(-/+ (type)methodName)、<Protocol> 协议、UI* 类指针声明、accessibility* 属性
每个文件还会:
生成 raw_summary :取前 30 行 + 所有关键声明行(class/func/@interface/@implementation/accessibility 等),控制在 2000 字符以内
推断 pod_name :从路径中匹配 Pods/ModuleName/ 或 Modules/ModuleName/ 模式
提取类继承关系 :存入 class_hierarchy 表
FTS5 是 Full-Text Search version 5 的缩写,即 SQLite 内置的第 5 版全文搜索引擎。
通过 SQLite 触发器,file_index 表的 INSERT/UPDATE/DELETE 操作会自动同步到 file_fts 全文搜索虚拟表,支持后续的 MATCH 全文搜索。
1 2 Indexed: 17522, Skipped: 0 Index built successfully!
17522 个源文件全部成功索引。
locate — 定位 Bug
1 npx ts-node src/index.ts locate "个人主页导航栏更多按钮无障碍响应错误"
整个 locate 流程分为三个 Step,总耗时 73.7 秒 。
执行者 : bug-info-extractor.ts
将 bug 描述嵌入一个结构化 prompt 中,要求 LLM 以 JSON 格式输出提取结果。Prompt 关键指令:
“keywords 要包含各种可能的命名变体,比如中文’播放页’对应可能的类名 PlayerViewController, PlayViewController, PlayerVC…”
使用 OpenAI SDK 的 chat.completions.create:
模型 : deepseek-chat
温度 : 0.1(低温度确保输出稳定)
响应格式 : json_object(强制 JSON 输出)
重试机制 : 最多 3 次,指数退避(1s → 2s → 4s)
1 2 3 4 5 6 7 8 9 10 11 Type: accessibility Summary: 个人主页导航栏更多按钮的无障碍响应功能存在错误 Keywords: ProfileViewController, ProfileVC, PersonalHomeViewController, HomeViewController, NavigationBar, NavBar, MoreButton, MoreBtn, RightBarButtonItem, UIBarButtonItem, accessibilityLabel, accessibilityHint, accessibilityTraits, isAccessibilityElement, ProfileModule, UserProfile, PersonalCenter Module: 个人主页/用户资料 Page: 个人主页 VCs: ProfileViewController, PersonalHomeViewController, UserProfileViewController, HomeViewController
关键观察 :LLM 从简短的中文描述中猜测了大量可能的英文类名/属性名变体,这些关键词将在 Step 2 中被用于多策略搜索。
执行者 : file-locator.ts
6 种策略全部并行执行 (Promise.allSettled),互不影响:
逻辑 :检查 bugInfo.codeScanIssue?.filePath 是否存在
本次结果 :无(bug 描述中没有直接给出文件路径)
权重 :100 分(未触发)
逻辑 :对 keywords 中长度 ≥ 3 的关键词,逐个并行执行 ripgrep:
1 rg -l --type swift --type objc "ProfileViewController" "/Users/wyan/Develop/Code/branch/Bugfix" 2>/dev/null | head -50
本次匹配到的关键词 (从结果中可以看到):
NavBar → 匹配到 QMPersonalInfoViewController.m, QMGeneralUserHeaderView.m
MoreButton → 匹配到 QMPersonTitleView.m, QMPersonHeaderCell.m, QMPersonalInfoViewController.m
MoreBtn → 匹配到多个文件
accessibilityHint → 匹配到 QMPersonalInfoViewController.m
accessibilityTraits → 匹配到 QMPersonTitleView.m, QMPersonHeaderCell.m, QMPersonalInfoViewController.m
ProfileViewController → 匹配到 ProfileViewController_V3Pad.m, ProfileViewController_V3+Follow.m 等
ProfileVC → 匹配到多个 Profile 相关文件
UserProfile → 匹配到 QMPersonalInfoViewController.m, QMPersonalInfoViewController+JumpAction.m
每个匹配得 6 分
页面映射匹配 (最高权重 40 分):
bugInfo.pageName = "个人主页"查映射表 → ["QMPersonalInfoViewController", "QMGeneralUserHeaderView", "QMGeneralUserV2TabVC"]
SQL: SELECT file_path FROM file_index WHERE class_names LIKE '%QMPersonalInfoViewController%'
匹配到所有 QMPersonalInfoViewController 的 .m/.h 及 Category 文件,每个 40 分
类名 FTS5 匹配 (30 分):
对 viewControllers 列表(ProfileViewController, PersonalHomeViewController 等)执行全文搜索
SQL: SELECT file_path FROM file_fts WHERE class_names MATCH 'ProfileViewController' LIMIT 30
匹配到 ProfileViewController_V3Pad.m 等文件,每个 30 分
关键词 FTS5 匹配 (8 分):
对长度 ≥ 4 的关键词(如 MoreBtn, accessibilityLabel, accessibilityTraits, isAccessibilityElement)执行全文搜索
匹配到 QMPersonTitleView.m, QMPersonHeaderCell.m 等
逻辑 :对 pageName(”个人主页”)和 moduleName(”个人主页/用户资料”)执行 find 命令搜索匹配的目录
由于中文名和目录命名不匹配,本次可能未产生有效结果
逻辑 :
1 git log --since="2 weeks ago" --name-only --pretty=format: | sort | uniq -c | sort -rn | head -100
获取最近 2 周频繁修改的文件,每个 2 分
低权重兜底策略
bugType = “accessibility” → 调用 searchAccessibilityIssues()
逻辑 :在索引中查找包含特定 UI 元素但缺少无障碍属性 的文件
1 SELECT file_path FROM file_index WHERE has_accessibility = 0 AND ui_classes LIKE '%UIButton%' LIMIT 30
每个匹配 15 分
所有策略结果通过 candidateMap 合并。同一文件多次命中的分数会叠加 。
关键的交叉验证加分机制 :
1 2 // 命中策略数 > 1 时,每多一种策略额外加 5 分 const bonus = extraStrategies * 5 ;
例如 QMPersonalInfoViewController.m:
策略 2 (ripgrep): 匹配了 NavBar, MoreButton, MoreBtn, accessibilityHint, accessibilityTraits, UserProfile → 6×6 = 36 分
策略 3 (索引): 页面映射 40 分
交叉验证加分: 2 种策略命中 → +5 分
总分: 81 分(排名第 1)
结果按 score 降序排序,取前 MAX_CANDIDATES = 20 个文件:
排名
分数
文件
主要得分来源
1
81
QMPersonalInfoViewController.mripgrep(6项) + 页面映射 + 交叉验证
2
57
QMPersonalInfoViewController+JumpAction.mripgrep(ProfileVC,UserProfile) + 页面映射 + 交叉验证
3
55
ProfileViewController_V3Pad.mripgrep + 索引类名 + 索引关键词 + 交叉验证
4
55
ProfileViewController_V3+Follow.m同上
5
55
QMPersonTitleView.mripgrep(MoreButton,MoreBtn,accessibilityTraits) + 索引关键词(多个) + 交叉验证
6
55
QMPersonHeaderCell.m同上
…
…
…
…
执行者 : precise-locator.ts
这是整个流程中消耗 token 最多的阶段,通过漏斗式两轮筛选 来控制成本。
对 Top 10(MAX_SCREENING_FILES = 10)候选文件,调用 loadFileSummaries():
读取完整文件内容 :fs.readFileSync(filePath, "utf-8")
生成摘要 :extractSummary(content) — 取前 30 行 + 所有关键声明行(class/func/@interface/@implementation/accessibility 等),约控制在 ~500 token/文件
1 2 3 4 5 6 7 8 private extractSummary (content : string ): string { const importantLines = lines.filter (line => return /^(class |struct |func |@interface|@implementation|@IBOutlet|@IBAction|import |#import)/ .test (trimmed) || /accessibility/i .test (trimmed); }); const header = lines.slice (0 , 30 ).join ("\n" ); return `${header} \n\n// === Key declarations ===\n${keyDeclarations} ` ; }
目的 :用低 token 成本快速排除无关文件。
构建 Prompt :将 bug 描述 + 10 个文件的摘要和匹配原因拼接成一个 prompt:
1 2 3 4 5 6 7 8 9 10 11 12 13 你是 iOS 开发专家。以下是一个 bug 的描述和几个候选文件的摘要。 请判断哪些文件最可能包含问题代码,返回文件路径列表(按可能性从高到低排序)。 Bug 描述:个人主页导航栏更多按钮无障碍响应错误 候选文件: --- /path/to/QMPersonalInfoViewController.m --- 匹配原因: ripgrep 匹配关键词: NavBar, MoreButton, ... 摘要: [前30行 + 关键声明] --- /path/to/QMPersonTitleView.m --- ...
LLM 返回 :JSON 格式的相关文件列表
1 { "relevantFiles" : [ "path1" , "path2" , "path3" , "path4" , "path5" ] }
结果 :从 10 个文件筛选到 5 个 真正相关的文件。
1 2 Round 1: Screening with file summaries... Screened to 5 relevant files
在这个工具中,**”关键声明”(Key Declarations)** 是指源代码中以特定模式开头的、具有结构性意义 的代码行。具体来说,就是通过正则表达式匹配出的以下内容:
在 precise-locator.ts 的 extractSummary 方法(第 371 行)中:
1 2 3 4 5 6 7 const importantLines = lines.filter ((line ) => { const trimmed = line.trim (); return ( /^(class |struct |enum |extension |func |@interface|@implementation|@IBOutlet|@IBAction|import |#import)/ .test (trimmed) || /accessibility/i .test (trimmed) ); });
也就是说,关键声明行 = 匹配以下任一模式的代码行:
模式
含义
示例
class Swift 类声明
class MyViewController: UIViewController
struct Swift 结构体声明
struct Config { ... }
enum 枚举声明
enum State { ... }
extension Swift 扩展声明
extension UIView { ... }
func Swift 函数声明
func viewDidLoad() { ... }
@interfaceObjC 类/分类声明
@interface QMPersonalInfoViewController
@implementationObjC 实现声明
@implementation QMPersonTitleView
@IBOutletStoryboard 关联
@IBOutlet weak var moreBtn: UIButton!
@IBActionStoryboard 事件
@IBAction func didClickMore()
import / #import
导入语句
#import "QMPersonalInfoViewController.h"
/accessibility/i任何包含 accessibility 的行
moreBtn.accessibilityLabel = @"更多";
最终生成的摘要格式为:
1 2 3 4 [文件前 30 行原文] // === Key declarations === [所有关键声明行]
用一个具体例子来说明,对于 QMPersonTitleView.m,摘要大概长这样:
1 2 3 4 5 6 7 8 9 10 11 12 // 前 30 行(包含 #import、文件注释等) #import "QMPersonTitleView.h" #import "UIView+Frame.h" ... // === Key declarations === @implementation QMPersonTitleView - (void )addMoreBtnWithTitle:... // ← func/method 声明 @IBOutlet ... // ← IBOutlet moreBtn.accessibilityLabel = moreBtnTitle; // ← accessibility 相关 moreBtn.accessibilityTraits &= ~UIAccessibilityTraitSelected ; moreBtn.accessibilityLabel = @"更多" ;
这个设计的目的是用极少的 token (约 500 token/文件)让 AI 快速理解一个文件的”骨架”:
前 30 行 → 了解文件是什么(import 了什么、类名是什么)
关键声明行 → 了解文件做了什么(有哪些类、方法、UI 关联)
accessibility 行 → 专门针对无障碍类 Bug,直接暴露相关代码
这样 Round 1 用 20 个文件 × 500 token ≈ 10,000 token 就能完成初筛,而不需要发送 20 个完整文件(可能要 200,000+ token)。
这里的漏斗设计是整个工具的核心性能优化:
1 2 3 4 5 Step 2: 20个候选文件(纯本地,0 token) ↓ Round 1: 20个文件的摘要(~500 token/文件 = ~5000 token)→ 筛选到 5 个 ↓ Round 2: 5个文件的完整内容(每个独立调用)
如果直接对 20 个文件都发送完整内容,token 消耗将极其巨大(一个 ObjC 文件可能有数千行)。
对筛选出的 Top 5(MAX_PRECISE_FILES = 5)文件,逐个调用 locateInFile():
大文件智能截取 :对超过 500 行的文件(ObjC 文件通常非常长),不是简单截断前 500 行,而是使用 smartExtract() 进行智能截取:
保留头部 50 行 (imports、类声明)
从 bug 描述中提取搜索关键词 :extractKeywordsFromDescription()
提取英文标识符:accessibility, button, more, navigation 等
提取中文关键词:导航栏, 更多, 按钮, 无障碍 等
搜索关键词在文件中的出现位置 ,取前后各 15 行上下文
合并重叠区间 ,避免重复
如果关键词匹配不到,回退为均匀采样关键声明行
最终生成带行号的截取内容:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 1: #import "QMPersonalInfoViewController.h" 2: ... ... 50: ... ... (skipped to line 5660) ... 5660: // 导航栏更多按钮 5661: ... 5667: UIButton *button = [ComHelper createCustomButtonByImageName:@"personal_info_header_more" ... 5673: button.accessibilityLabel = QMLocalizedString(@"SVCC_SHOW_MORE", nil); ... (total 6000 lines, showing 350 relevant lines)
构建 Prompt :
1 2 3 4 5 6 7 你是 iOS 开发专家。请在以下代码中精确定位 bug 所在位置。 Bug 描述:个人主页导航栏更多按钮无障碍响应错误 文件:/path/to/QMPersonTitleView.m ```code [带行号的文件内容/智能截取内容]
1 2 3 4 5 6 7 请返回 JSON: { "lineStart": 问题代码起始行号, "lineEnd": 问题代码结束行号, "confidence": 0到1之间的置信度数值, "explanation": "定位原因的详细说明" }
5 个文件的 LLM 返回结果 :
文件
行号
置信度
核心发现
QMPersonTitleView.m189-195
90%
accessibilityLabel 被设置后又被硬编码为 @"更多" 覆盖
QMPersonHeaderCell.m70-70
90%
accessibilityLabel = moreBtnTitle 但缺少完整的无障碍配置
QMPersonalInfoViewController.m5667-5673
85%
导航栏更多按钮创建处,可能存在本地化字符串问题
ProfileViewController_V3Pad.m1010-1013
85%
accessibilityLabel:atIndex: 方法始终返回空字符串 @""
ProfileViewController_V3+Follow.m176-200
85%
关注按钮点击处理缺少无障碍属性更新
所有定位结果按 confidence(置信度)降序排序:
1 return results.sort ((a, b ) => b.confidence - a.confidence );
90% 的两个结果排在前面,85% 的三个排在后面。
对每个定位结果,根据 lineStart 和 lineEnd 从完整文件内容中截取代码:
1 2 const contentLines = content.split ("\n" );const codeSnippet = contentLines.slice (lineStart - 1 , lineEnd).join ("\n" );
定位结果同时输出到终端和 JSON 文件:
1 2 const timestamp = new Date ().toISOString ().replace (/[:.]/g , "-" );const resultFile = path.join (RESULTS_DIR , `result-${timestamp} .json` );
1 Results saved to: .../result-2026-03-06T14-04-42-624Z.json
本次 locate 命令总共进行了 7 次 LLM API 调用 :
次序
阶段
输入
输出
预估 Token
1
Step 1: 信息提取
bug 描述 + prompt模板
BugInfo JSON
~500
2
Step 3 Round 1: 摘要筛选
10个文件摘要
5个相关文件路径
~6000
3-7
Step 3 Round 2: 精确定位
每个文件的内容(智能截取)
行号 + 置信度 + 解释
~3000-8000/次
Step 2 完全在本地执行(ripgrep + SQLite + find + git),无 API 调用,0 token 消耗。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 graph TD A[Bug 描述] --> B[Step 1: LLM 提取 BugInfo] B --> C1[策略1: 直接路径] B --> C2[策略2: ripgrep 搜索] B --> C3[策略3: 索引查询+页面映射] B --> C4[策略4: 目录推断] B --> C5[策略5: Git 热点] B --> C6[策略6: 类型专项] C1 --> D[分数合并 + 交叉验证加分] C2 --> D C3 --> D C4 --> D C5 --> D C6 --> D D --> E[Top 20 候选文件] E --> F[Round 1: 摘要筛选 → Top 5] F --> G[Round 2: 逐文件精确定位] G --> H[按置信度排序输出]
来源
分值
设计意图
直接路径
100
代码扫描报告给出的路径几乎必中
页面映射
40
人工维护的映射最可靠
索引类名匹配
30
FTS5 匹配到类名,可信度高
Bug 类型专项
15
有针对性的搜索
索引关键词匹配
8
关键词范围更广,可能有噪声
目录推断
8
目录名和模块名可能不完全对应
ripgrep
6
全文搜索覆盖广但噪声多
Git 热点
2
纯统计信息,低权重兜底
交叉验证加分
+5/策略
多策略命中说明文件高度相关
1 2 3 4 5 6 7 17,522 源文件 ↓ 本地 6 策略并行筛选(0 token) 20 候选文件 ↓ 读取 Top 10 文件摘要(~500 token/文件 × 10) 10 → 5 文件(Round 1 筛选,~6000 token) ↓ 逐文件精确定位,大文件智能截取 5 个定位结果(Round 2,~5000 token/文件 × 5)
总 token 消耗约: 30,000-40,000 token ,相比直接将 20 个大文件发给 AI(可能 500,000+ token),节省了 90% 以上 。
简单截断前 500 行的问题:ObjC 文件头部通常是 #import 和属性声明,真正有 bug 的代码可能在第 5000+ 行。智能截取通过关键词搜索 + 上下文窗口(前后各 15 行)确保问题代码被覆盖。
本次案例中 QMPersonalInfoViewController.m 的问题代码在第 5667 行,如果简单截断前 500 行将完全漏掉。
对于 bug 描述 **”个人主页导航栏更多按钮无障碍响应错误”**:
Step 1 准确识别为 accessibility 类型,正确推断了 个人主页 页面名,关键词覆盖了 MoreButton/MoreBtn/accessibilityLabel/accessibilityTraits 等关键变体
Step 2 的 Top 1 就是主文件 QMPersonalInfoViewController.m(81 分),得益于页面映射(40分)+ ripgrep 多关键词命中(36分)+ 交叉验证加分(5分)
Step 3 最终输出了 5 个定位结果,最高置信度 90% 的两个结果精确指向了 accessibilityLabel 被错误覆盖和不完整设置的代码行