Swift Runtime 符号在动态链接库丢失的排查之路
DanceCC 是字节 Mobile Infra 的一套编译工具链的品牌名,基于 Swift.org 的工具链进行了相关定制,包括调试优化,定制 Clang 插件特性,自研 Pass 做包大小和性能优化等等。在先前的文章中均有介绍。
背景
近期,有人发来反馈,他们在接入 DanceCC 的新版本工具链时,在调整了一些库的工具链选择后(即使用 Apple 工具链还是 DanceCC 工具链),重新编译出包,发生启动 Crash,堆栈如下:
1 |
"Symbol not found: __ZN5swift34swift50override_conformsToProtocolEPKNS_14TargetMetadataINS_9InProcessEEEPKNS_24TargetProtocolDescriptorIS1_EEPFPKNS_18TargetWitnessTableIS1_EES4_S8_E", |
崩溃的核心原因在于:__ZN5swift34swift50override_conformsToProtocolEPKNS_14TargetMetadataINS_9InProcessEEEPKNS_24TargetProtocolDescriptorIS1_EEPFPKNS_18TargetWitnessTableIS1_EES4_S8_E 这个符号找不到,引用发生在 AppStorageCore 动态链接库中,加载发生在 EEAtomic 动态链接库中
符号丢失排查
首先查看 AppStorageCore 的 Load Command,判断其递归加载的动态库(LC_LOAD_DYLIB)包含 EEAtomic 和 LKCommonsLogging,只考虑非系统库(因为该符号必定不在系统库内):
1 |
Load command 11 |
通过 nm 来查看符号分析:
- EEAtomic:在 dSYM 中存在符号,为 local symbol。在二进制中符号消失(被 strip)
1 |
nm EEAtomic.framework.dSYM/Contents/Resources/DWARF/EEAtomic | grep __ZN5swift34swift50override_conformsToProtocolEPKNS_14TargetMetadataINS_9InProcessEEEPKNS_24TargetProtocolDescriptorIS1_EEPFPKNS_18TargetWitnessTableIS1_EES4_S8_E |
- LKCommonsLogging:在 dSYM 中存在符号,为 local symbol。在二进制中符号消失(被 strip)
1 |
nm LKCommonsLogging.framework.dSYM/Contents/Resources/DWARF/LKCommonsLogging | grep |
- AppStorageCore:存在 undefined symbol,需要运行时可见
1 |
nm AppStorageCore.framework/AppStorageCore | grep __ZN5swift34swift50override_conformsToProtocolEPKNS_14TargetMetadataINS_9InProcessEEEPKNS_24TargetProtocolDescriptorIS1_EEPFPKNS_18TargetWitnessTableIS1_EES4_S8_E |
即然符号在 AppStorageCore 中未定义,那么应该在其递归加载的 EEAtomic/LKCommonsLogging 中,以 T(即 global)符号暴露出来,而现在不是。导致运行时找不到该符号 dyld 报错。我们需要进一步探究源头问题。
Swift 编译器符号哪里来?
通过 Demangle 可知,这个符号是
1 |
swift::swift50override_conformsToProtocol(swift::TargetMetadata<swift::InProcess> const*, swift::TargetProtocolDescriptor<swift::InProcess> const*, swift::TargetWitnessTable<swift::InProcess> const* (*)(swift::TargetMetadata<swift::InProcess> const*, swift::TargetProtocolDescriptor<swift::InProcess> const*)) |
其存在于编译器的内置静态库 libswiftCompatibility50.a 中
1 |
nm /Applications/Xcode-15.0.0.app/Contents/Developer/Toolchains/XcodeDefault.xctoolchain/usr/lib/swift/iphoneos/libswiftCompatibility50.a | grep __ZN5swift34swift50override_conformsToProtocolEPKNS_14TargetMetadataINS_9InProcessEEEPKNS_24TargetProtocolDescriptorIS1_EEPFPKNS_18TargetWitnessTableIS1_EES4_S8_E |
什么是 swiftCompatibility50
在 iOS 平台上,Swift Runtime 被内置于操作系统一份(在 /usr/lib/swift/libswiftCore.dylib,以及对应的 dyld shared cache 中),内置的版本取决于操作系统发行时刻。
如,在 iOS 12.4 版本上,内置的 Swift 5.0 的 Runtime,而现在的编译器是 Swift 5.9
由于 Swift 5 确认了“ ABI Stable ”的承诺,因此,Swift 编译器需要实现更新语法的 Backport 能力(比如 Concurrency,Opaque Result Type 等语言能力),有些语法会涉及到 Runtime 的更新,必然,需要对“已有的老版本 Swift Runtime ”打上补丁,提供这些老版本 Runtime 中缺少的符号和功能。
具体补丁根据复杂程度,会拆分多个编译器工具链提供的静态库,最终整体链接到 App 中。
举个例子,如果当前编译单元,用到需要 Swift 5.9+ 的运行时语法,那么编译器就需要打上这些补丁:
- libswiftCompatibility50.a:包含了 Swift 5.0-5.1 的新增 Swfit Runtime API
- libswiftCompatibility51.a:包含了 Swift 5.1-5.6 的新增 Swfit Runtime API
- libswiftCompatibility56.a:包含了 Swift 5.6 到当前版本(写稿时即为 5.9)的新增 Swfit Runtime API
注意几个细节:
- 如果链接了低版本的.a(如50),那么一定会链接高版本的.a(51和56),低版本的.a中可能会直接依赖高版本.a的符号
- 不同版本的.a,如50/51/56,不会重复实现同名符号导致覆盖,每个.a提供的一堆 API 的完整实现,对齐到当前 Swift 版本(即5.9)的行为,即:
-
swift::swift_getTypeName:假设是 Swift 5.0 的新增 API,跳板会访问__DATA,__swift50_hooks,那么它必须通过 libswiftCompatibility50.a 提供 -
swift::swift_getMangledTypeName:假设是 Swift 5.1 的新增 API,跳板会访问__DATA,__swift51_hooks,那么它必须通过 libswiftCompatibility51.a 提供
如果接入了 Concurrency,也需要额外的运行时补丁,即:
- libswiftCompatibilityConcurrency.a:Concurrency Backport
如果接入了 SwiftUI 等依赖@dynamicReplacement 的语法的代码,也需要额外的补丁,即:
- libswiftCompatibilityDynamicReplacements.a:Dynamic replacement Backport
如果接入了 Swift 的 Paramters Pack 语法 each T,也需要额外的补丁,即:
- libswiftCompatibilityPacks.a:Paramters Pack Backport
备注:傻瓜省流,当你 App 用到了 SwiftUI 框架,那么你会全部用到上述所有 6 个补丁,因为 SwiftUI 都涉及到这些😮💨
补丁机制怎么替换实现
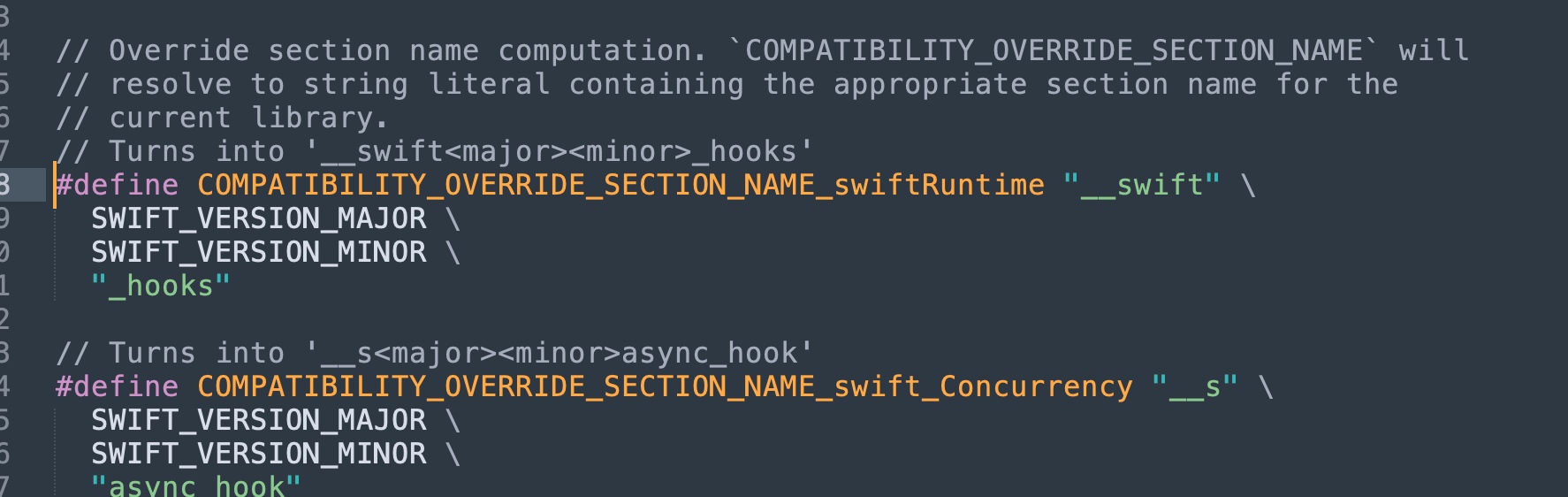
Swift 编译器通过自己在二进制中定义了一个专属的 Section,用动态调用的形式来访问所有 Swift Runtime API
其中,对于 Swift Runtime 的 Hook 存在于 __DATA,__swift50_hooks(假设操作系统内置那份 Swift Runtime 版本是 5.0)
而 Swift Concurrency Backport 的 Hook 存在于 __DATA,__s55async_hook(Concurrency 自身是从 5.5 引入的,也支持补丁)
跳板会检查是否当前运行的 host 环境需要打补丁: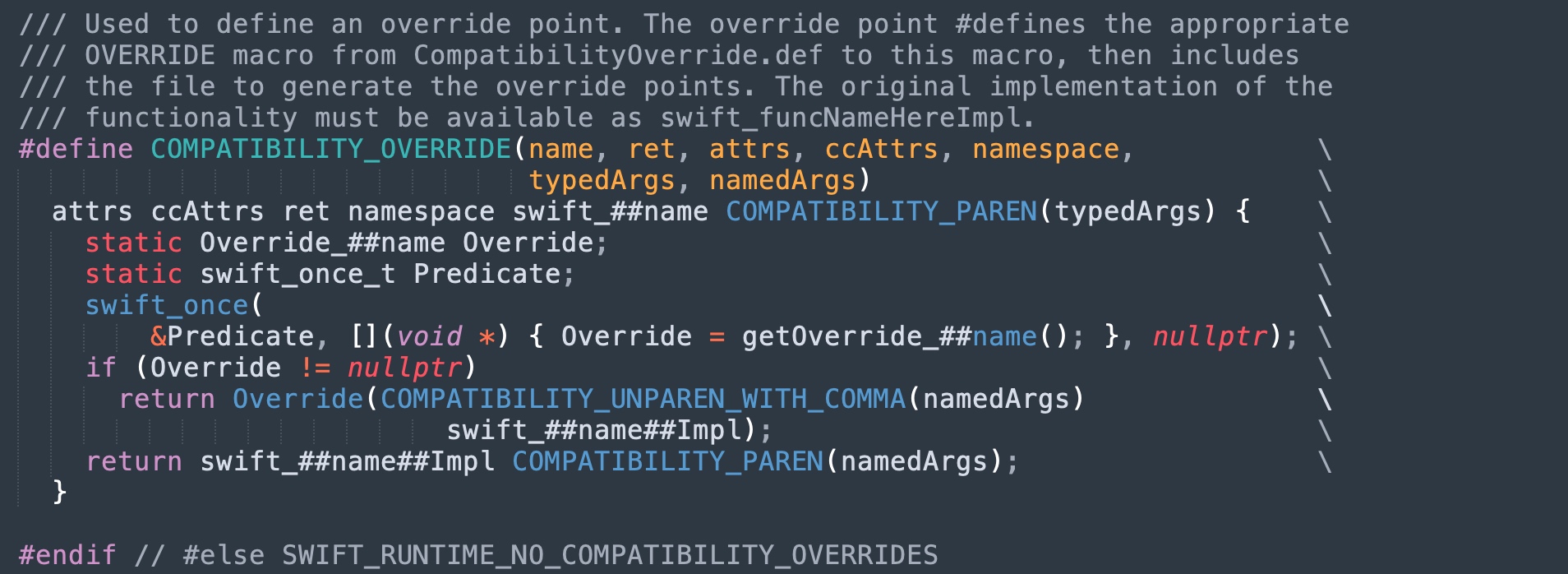
跳板通过 dyld API 去读取 Section 拿到函数指针,随后进行调用: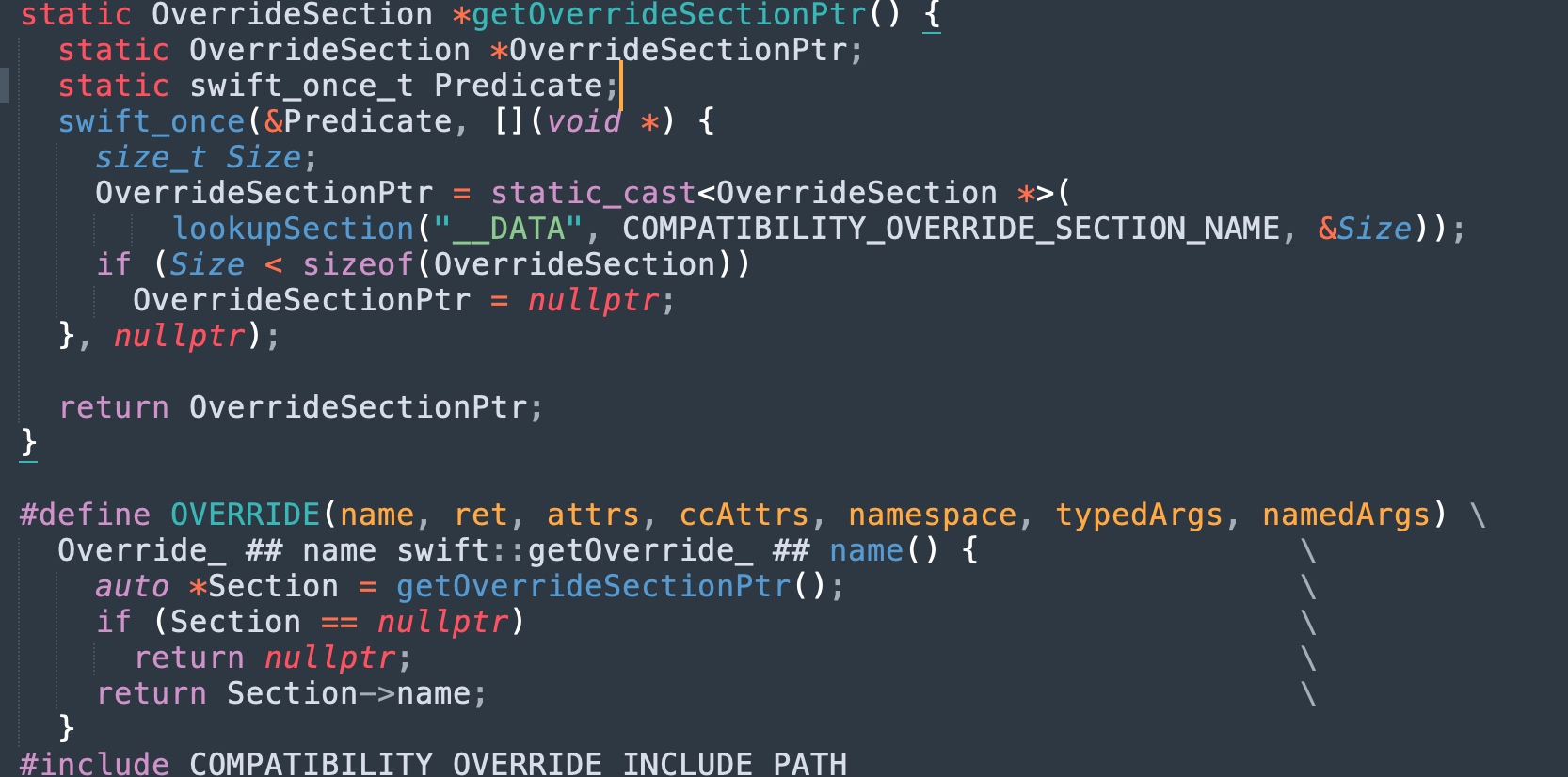
一句话总结,假设调用
swift::swift_getTypeName这个 Swift 5.0 的 Runtime API,会进行以下逻辑(其他情形无非就是 MachO Section 和对应静态库不同罢了):
- 检查
swift::getOverride_swift_getTypeName返回的函数指针-
swift:getOverride_swift_getTypeName会从__DATA,__swift50_hooksMachO Section,找到被链接进去的 libswiftCompatibility50 的符号
-
- 如果返回非空,直接调用
swift::getOverride_swift_getTypeName(App 链接的补丁实现) - 如果返回空,调用
swift::swift_getTypeNameImpl(操作系统的内置实现)
从而实现了上述提到的“补丁机制”。因为通过宏,标记在所有 Swift 的 Runtime API 上,因此在编译时刻都确保支持了运行时支持补丁替换,达成了“向后兼容”。技术上实现其实很原始很简单。
编译器的魔法
那么问题来了,在工具链角度看,编译器,和链接器,是两个不同的独立工作流,在不侵入宿主业务的构建系统的前提下,“ Swift 编译器怎么样告知链接器,需要这些额外的补丁库链接到二进制中呢?”
答案是通过 LC_LINKER_OPTION,即 MachO 的一个 Load Command,允许每个 MachO 提供自己的“额外链接参数”。这个参数原本用于 Clang 社区提倡的 Auto-linking 能力,现在被 Swift 编译器也借过去。参考:深入 iOS 静态链接器(一)— ld64
举个例子,以 SwiftUI 的代码为例子,当你以最低部署版本 -target arm64-apple-ios12.0 进行编译时,编译器给 MachO 写入这些链接参数,告知给链接器:
1 |
Load command 44 |
是没有正确链接补丁吗?
在 DanceCC 的编译器编译下,产出的产物就是上述的 LC_LINKER_OPTION,按理说链接器会正常进行链接,发生了什么?
链接参数对比如图:
通过检查链接参数,看起来似乎没什么问题,这里存在 Library Search Path:-L/path/to/swift-5.9-dancecc.xctoolchain/usr/lib/swift/iphoneos,即指向了工具链内置的 libswiftCompatibility50.a 所在目录,那究竟是什么原因导致符号丢失?
怀疑 libswiftCompatibility50.a 差异
首先进行黑盒对比,观察行为差异
在实际编译机器上进行了如下 4 项测试:
- 使用 Apple Clang + Apple libswiftCompatibility50
- 产生符号为 T(global)
- 使用 DanceCC Clang + DanceCC libswiftCompatibility50
- 产生符号为 t(local)
- 使用 Apple Clang + DanceCC libswiftCompatibility50
- 产生的符号为 t(local)
- 使用 DanceCC Clang + Apple libswiftCompatibility50
- 产生符号为 T(global)
结果如图: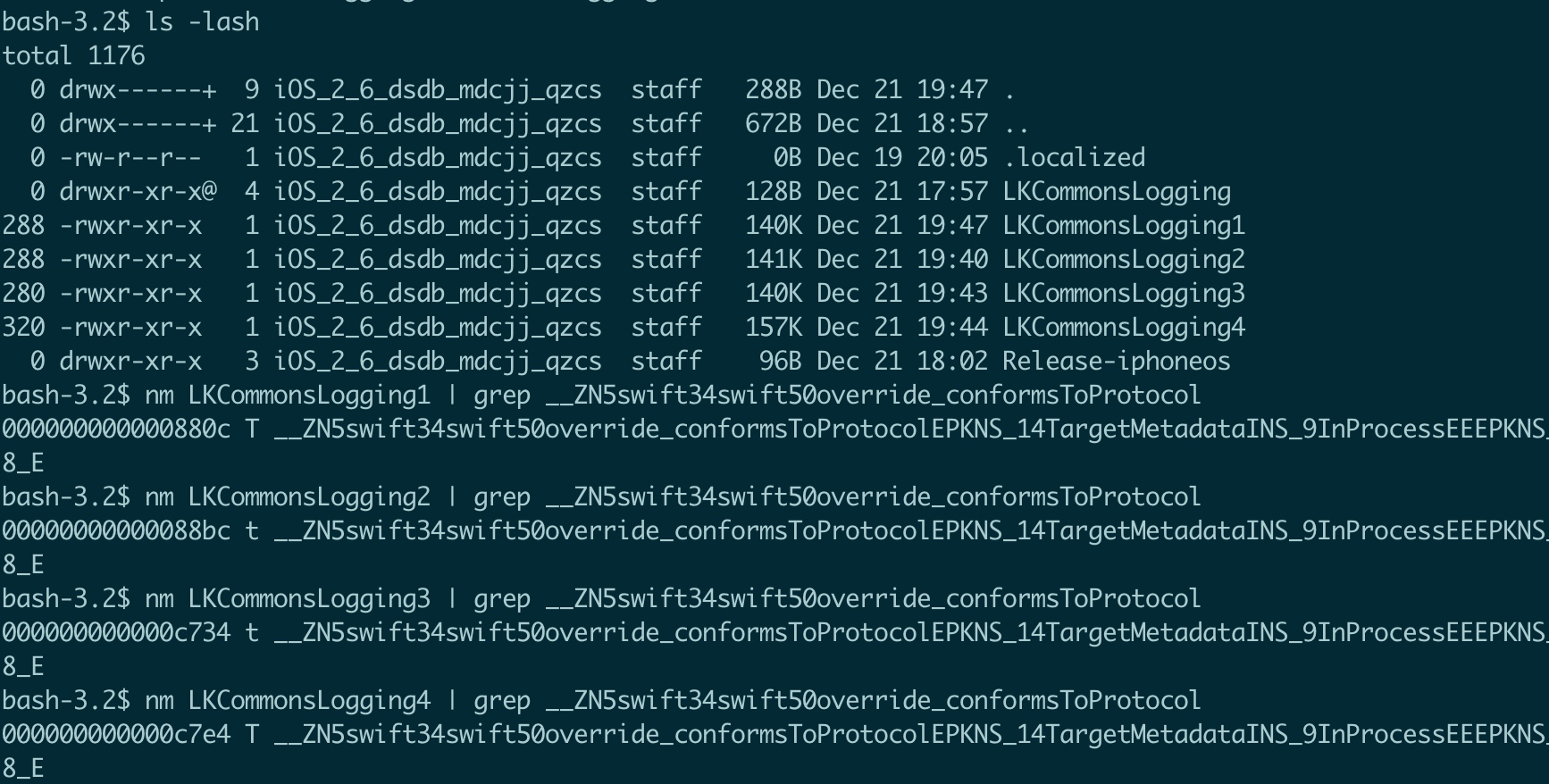
可见,发生问题的地方不在于 linker,不在于 clang 本身,而在于工具链内置的 libswiftCompatibility50.a,其 visibility 有问题!
对比 libswiftCompatibility50.a 差异
我们将 Apple Xcode 15.0 内置的产物和 DanceCC 进行对比
首先一眼从二进制大小来看,DanceCC 的产物未免有些太小,很反常。进一步反汇编查看,发现 Apple 的.a 包含了 -embed-bitcode 的 LLVM Bitcode 内容。我们需要 strip 后再次进行对比
1 |
Section |
我们关注丢失的符号的 visibility,查看(参考:How to know the visibility of a symbol in an object file):
1 |
objdump -Ct libswiftCompatibility50.a |
- Apple:
1 |
0000000000000000 g F __TEXT,__text swift::swift50override_conformsToProtocol(swift::TargetMetadata<swift::InProcess> const*, swift::TargetProtocolDescriptor<swift::InProcess> const*, swift::TargetWitnessTable<swift::InProcess> const* (*)(swift::TargetMetadata<swift::InProcess> const*, swift::TargetProtocolDescriptor<swift::InProcess> const*)) |
- DanceCC:
1 |
0000000000000000 g F __TEXT,__text .hidden swift::swift50override_conformsToProtocol(swift::TargetMetadata<swift::InProcess> const*, swift::TargetProtocolDescriptor<swift::InProcess> const*, swift::TargetWitnessTable<swift::InProcess> const* (*)(swift::TargetMetadata<swift::InProcess> const*, swift::TargetProtocolDescriptor<swift::InProcess> const*)) |
对比直观图: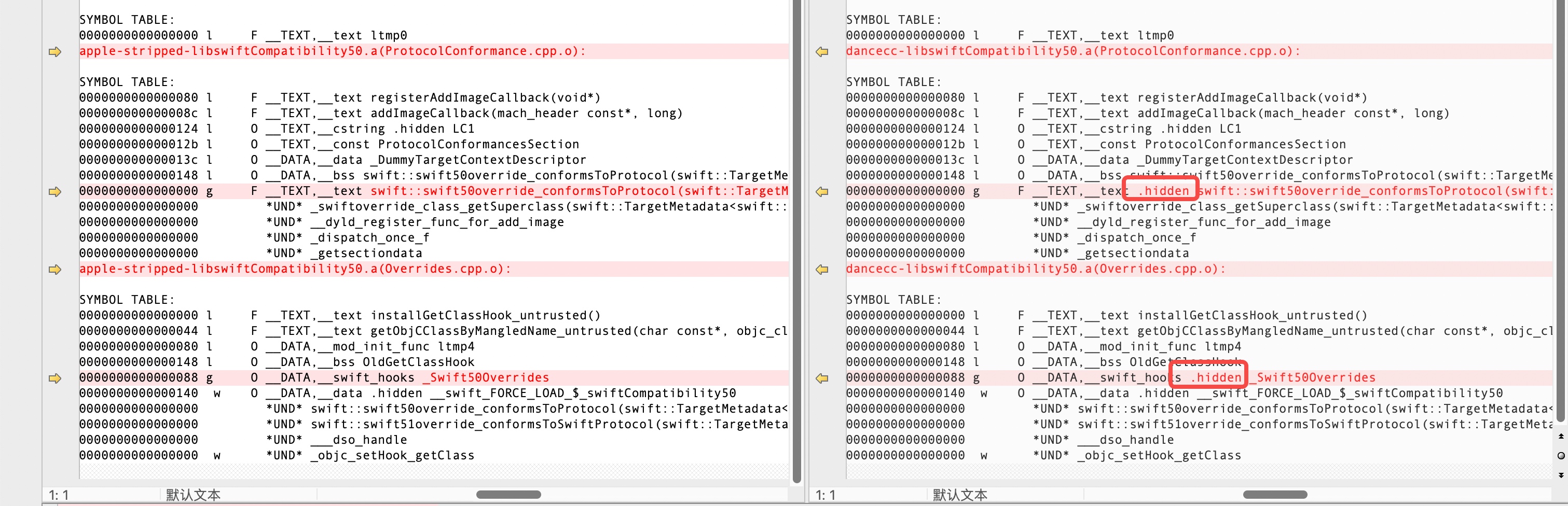
初步结论
DanceCC 在生成该符号时,设置了 visibility=hidden;而苹果的该符号设置为 visibility=default
定位对应的源码
通过直接在源码仓库搜索该符号,定位到来自这里的C++代码:
- 声明:
./stdlib/toolchain/Compatibility50/Overrides.h - 实现:
./stdlib/toolchain/Compatibility50/ProtocolConformance.cpp
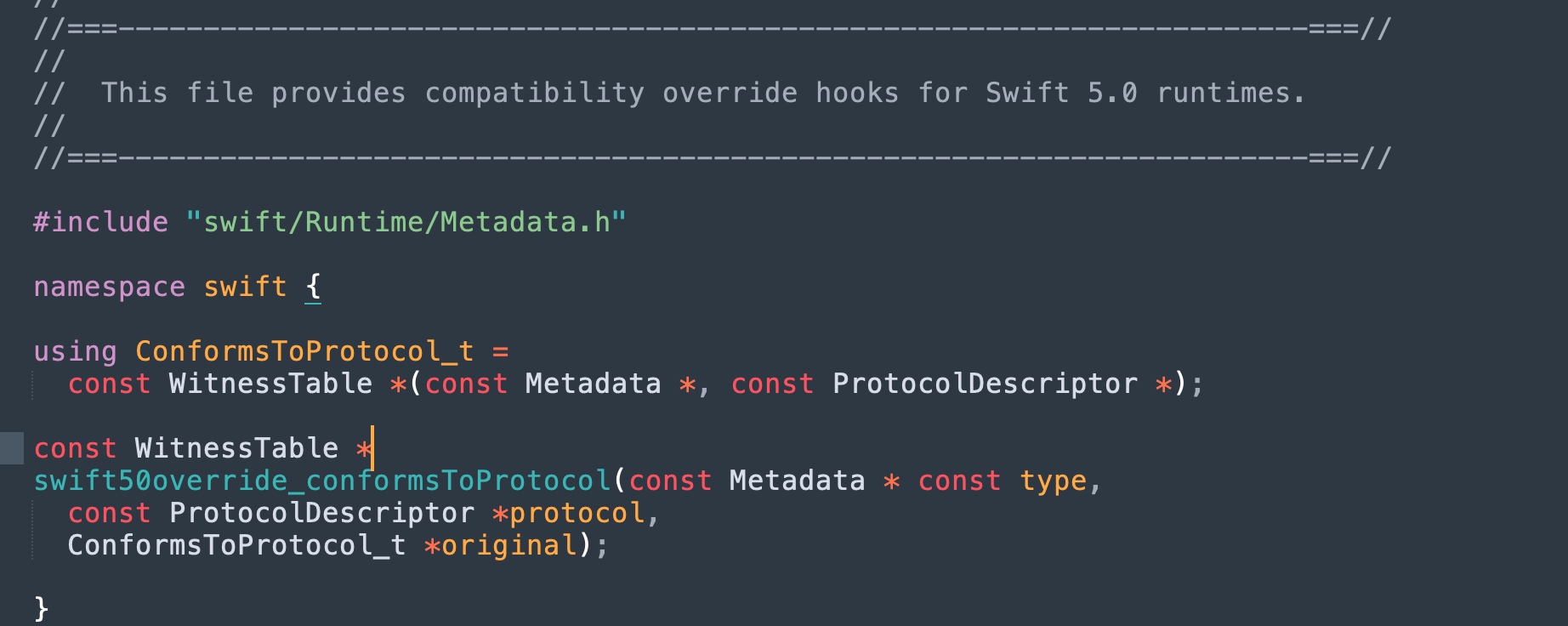
可见,这里没有显式的标记 visibility,由编译器生成。那么编译器为什么“不生成 default 的 visibility 呢?”
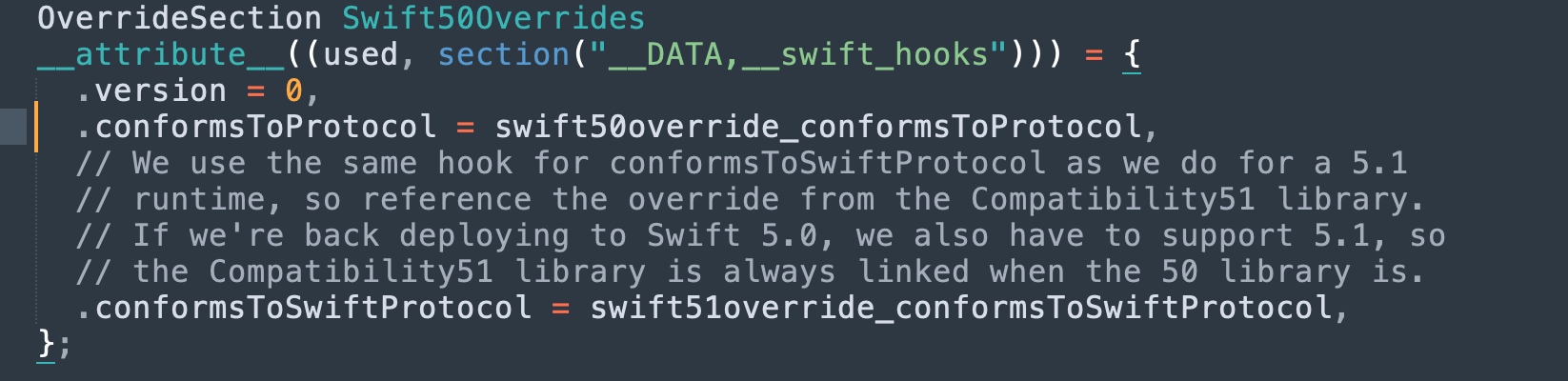
PS:对该符号的引用出现在其插桩的 Hook 实现里(./stdlib/toolchain/Compatibility50/Overrides.cpp)
调查工具链自身的构建参数
注意一个小坑点:Xcode 14(LLVM 14)的 objdump 并不会显示 external hidden symbol,只有 Xcode 15(LLVM 15)的 objdump 会显示,会干扰排查,需要使用同一份二进制进行排查。
定位到原始编译单元产物(Overrides.cpp.o)的 visibility 就是 hidden,和后续流程无关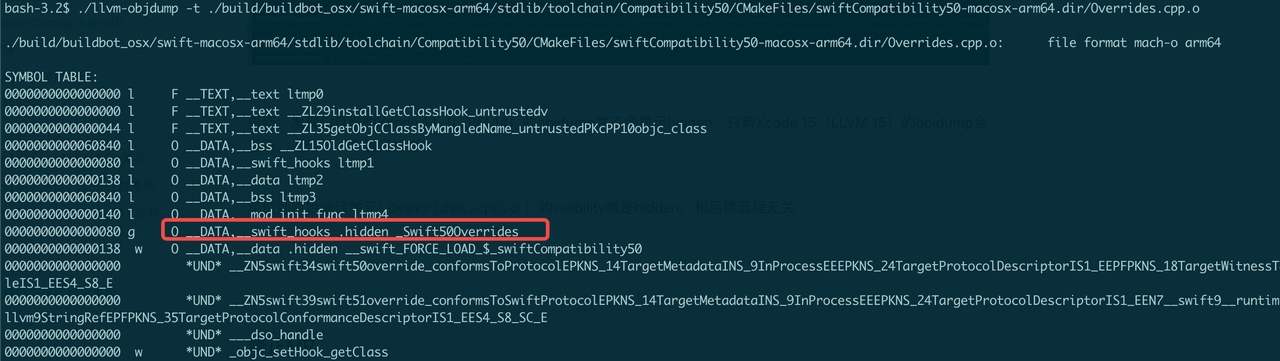
初步怀疑是以下语法存在问题,编译器识别 visibility 时错误设置为 hidden:__attribute__((used, section("__DATA,__swift_hooks")))
当然,更有可能是编译器 clang 传入了全局的 -fvisibility=hidden 覆盖了默认值?需要进一步排查
确认是 CI 编译插入了-fvisibility=hidden
在 CI 加入 verbose 编译后,证明和猜想一致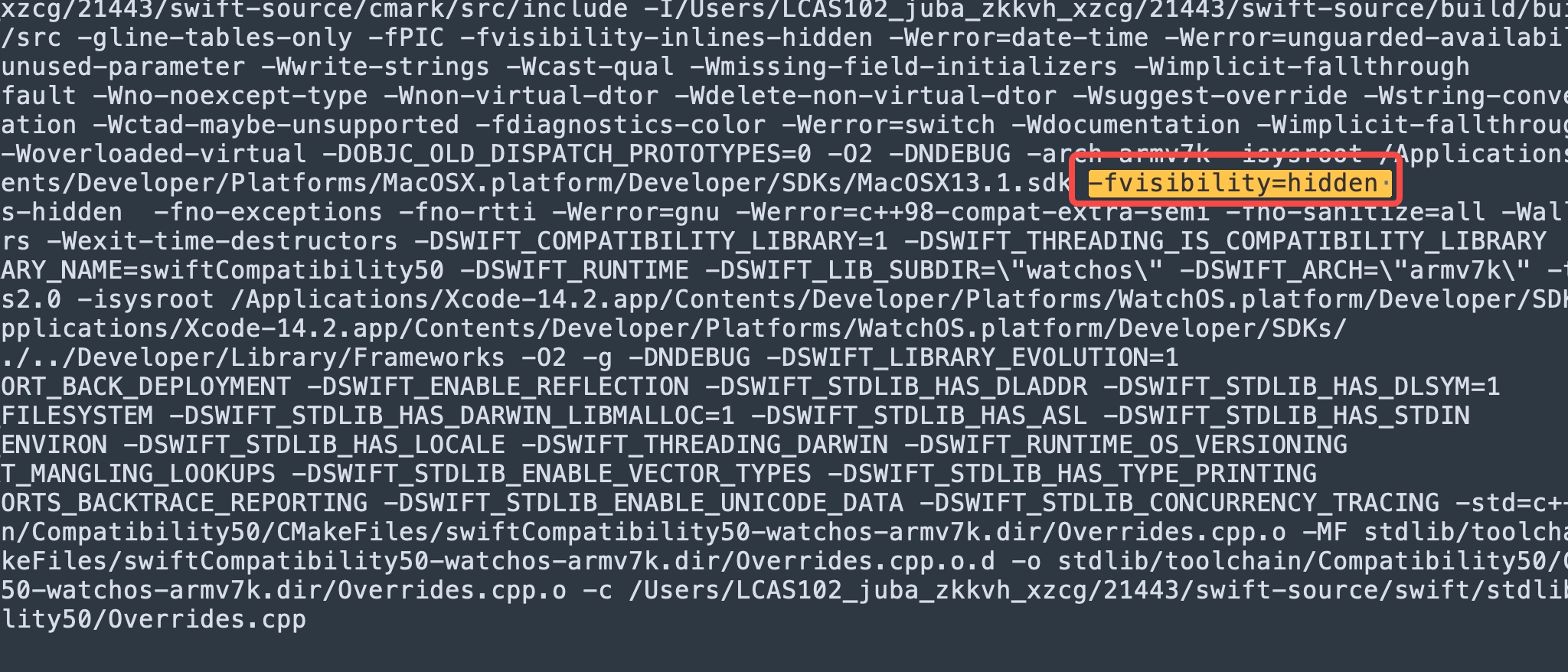
从上述分析可知,当前编译单元(即 swiftCompatibility Target)不应该开启修改默认的 visibility 进行编译,否则就需要源码手动声明 visibility(default)
临时 Workaround
快速绕过改问题,可以对相关库依旧保持 DanceCC 工具链,让链接器以 local symbol 的形式对每个 Swift 库链接了一份 libswiftCompatibility50.a,即 force_load 了一份,使用链接器已有参数 -Wl,-force_load_swift_libs,参考:[lld-macho] Implement -force_load_swift_libs
虽然观察到 Apple 工具链利用了Auto-linking算法,会只对 dylib 被依赖方拷贝该符号,设置为 global symbol(上述问题就是 LKCommonsLogging,nm 显示为 T),dylib 依赖方不拷贝该符号,设置为 undefined symbol(上文就是 AppStorageCore,nm 显示为 U),有点反常(像是一个依赖树,只在树的根节点真正链接了 libswiftCompatibility50.a,兄弟节点不重复静态链接),可以参考下图(Apple 总二进制只 force_load 了 2 份,DanceCC 总二进制 force_load 了 4 份)
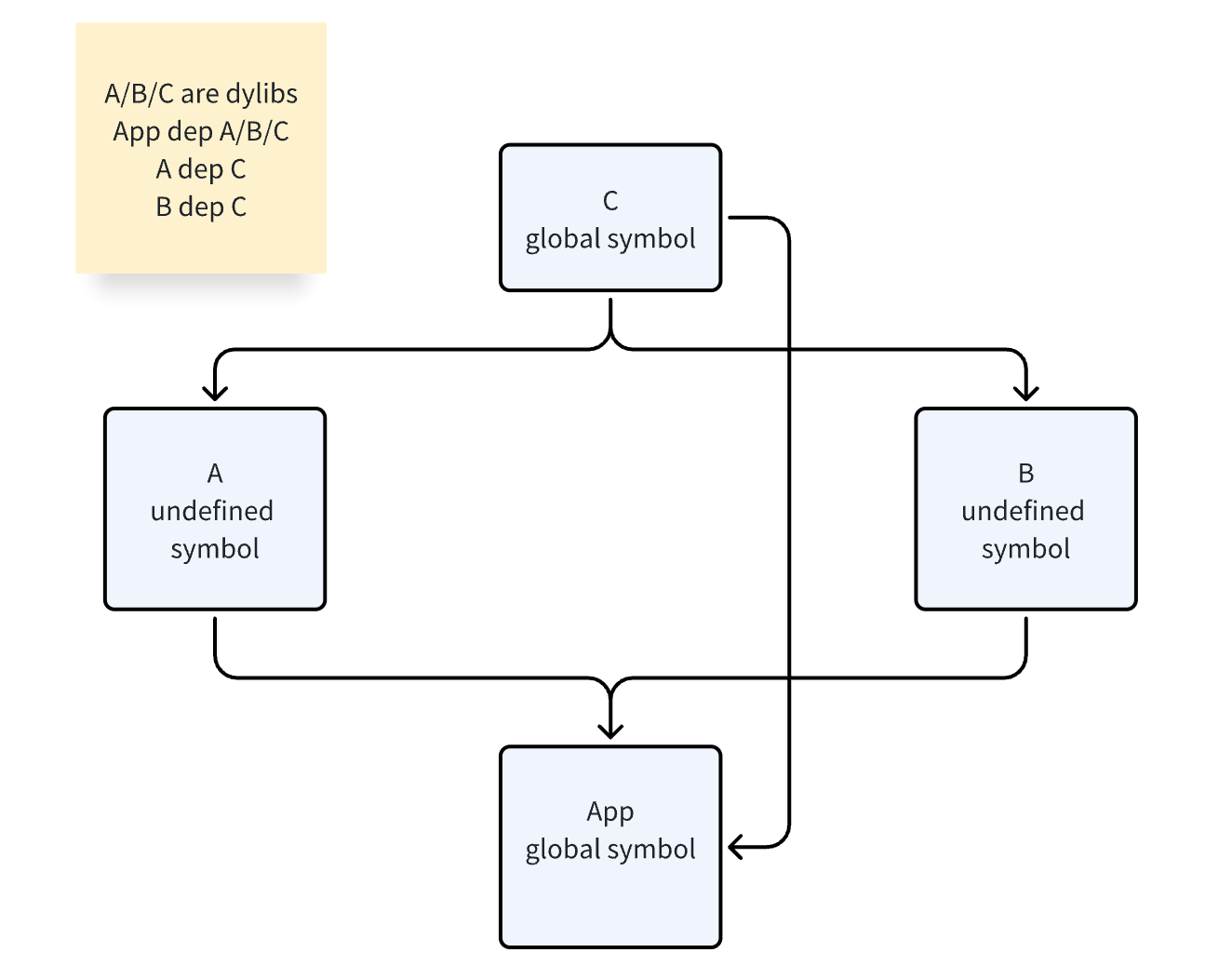
这两种集成仅有小量二进制差异,业务 8 个 dylibs,影响较小(一个 force_load 的 libswiftCompatibility50.a 占据 10KB)
修正方式
根据目前 Apple 内置二进制的解析结果,我们一期考虑直接无脑对齐,通过源码手动标记 visibility(“default”),不影响其他编译单元的构建逻辑:
- libswiftCompatibility50.a:源码标记错误需要更改
0000000000000088 g O __DATA,__swift_hooks _Swift50Overrides - libswiftCompatibility51.a:源码标记错误需要更改
0000000000000000 g O __DATA,__swift51_hooks _Swift51Overrides - libswiftCompatibility56.a:不需要改,源码标记是正确的
0000000000000000 g O __DATA,__s_async_hook .hidden _Swift56ConcurrencyOverrides
总结
这一篇文章不仅仅介绍了具体的一个开源 Swift.org 工具链,和 Apple 闭源工具链的差异,更为重要的是介绍了关于 Swift Runtime Backport 的一些机制流程,并且介绍了一些相关的排查经验,方便工具链开发者用于追查更多类似的行为不一致问题😂。
说起来短短一年期间,DanceCC 工具链已经大大小小修复了数十例子这种行为不对齐的问题,保障了内部业务的可用性。也因此可见 Apple 在其内网维护者庞大的一套自动化验证以及私有分支。如果对这套机制有兴趣的人,可以私聊我,来让这个 Swift.org 工具链能够真正的开源出来有价值,能够在更多的场景产生贡献。














































{kind=link}