booltest(longlong k){ longlong c1 = a*k; longlong c2 = b*k; if (c1 > n) { longlong r = (c1 - n + d - 1) / d; c1 -= r*d; c2 += r*d; } if (c1 <= n && c2 <=m) returntrue; elsereturnfalse; }
intmain(){ ios::sync_with_stdio(0); cin >> n >> m >> a >> b; if (n < m) swap(n, m); if (a < b) swap(a, b); d = a - b; longlong l = 0; longlong r = n; while (l <= r) { longlong m = (l+r)/2; if (test(m)) { ans = max(ans, m); l = m+1; } else { r = m-1; } } cout << ans << endl; return0; }
int n, m; int tu[55][55]; intmain(){ cin >> n >> m; // 嵌套的 for 循环 for (int i = 1; i <= n; i++) { for (int j = 1; j <= m; j++) { cout << i*j << " "; } cout << endl; } return0; }
intmain(){ int n; int ans = 0; cin >> n; for (int a = 1; a<=n; ++a) { for (int b = a; b<=n; ++b) { if (a*b%2 == 0) ans++; } } cout << ans << endl; return0; }
int t, n, v[10010], tot; intmain(){ ios::sync_with_stdio(false); cin >> t; while (t--) { cin >> n; tot = 0; for (int i = 0; i < n; ++i) { cin >> v[i]; tot += v[i]; } int cnt = 0; bool ans = false; for (int i = 0; i < n && cnt*2<tot; ++i) { cnt += v[i]; if (cnt*2 == tot) { ans = true; } } if (ans) cout << "Yes" << endl; else cout << "No" << endl; } return0; }
此题的思路如下:因为 x 最大是 2025,而如果 y 需要影响 x 的运算,只能与 x 的 bit 位是 1 的位进行操作。所以 y 如果存在,则必定小于 2048。因为 2048 的二进制 1 的 bit 位已经超过 2025 的最高位了。所以直接枚举 1~2048 之间的答案即可。
参考代码:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16
#include<bits/stdc++.h> usingnamespace std;
int ans = -1; int x; intmain(){ cin >> x; for (int i = 1; i < 2048; ++i) { if ((x & i) + (x | i) == 2025) { ans = i; break; } } cout << ans << endl; return0; }
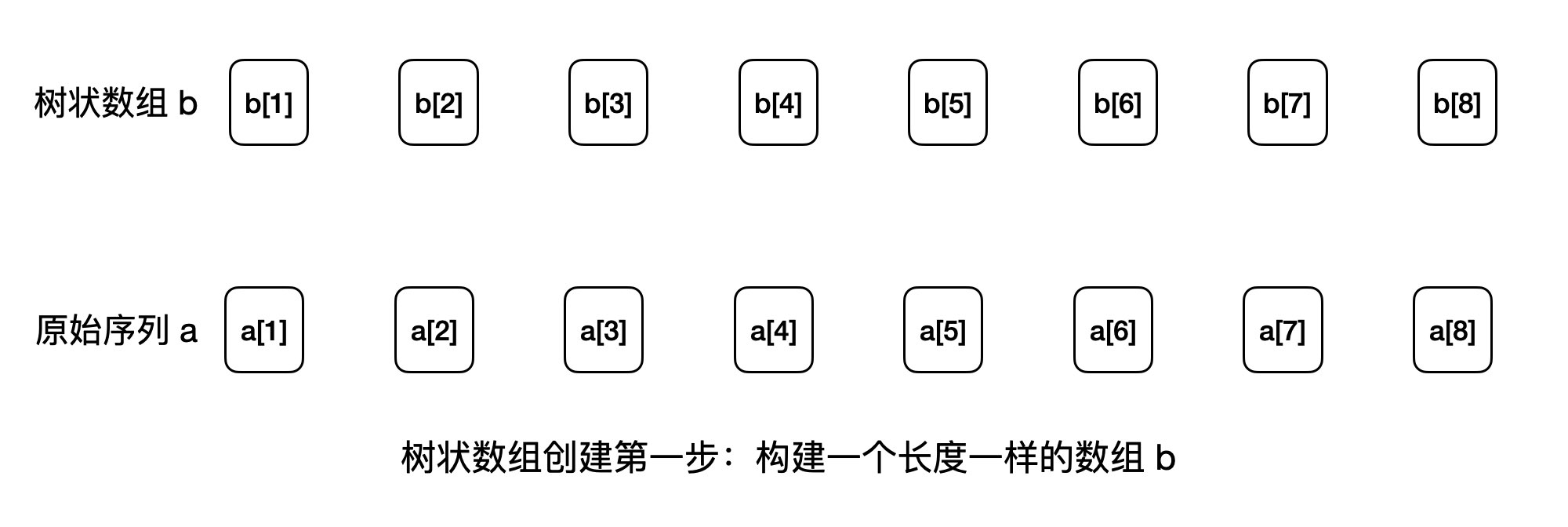
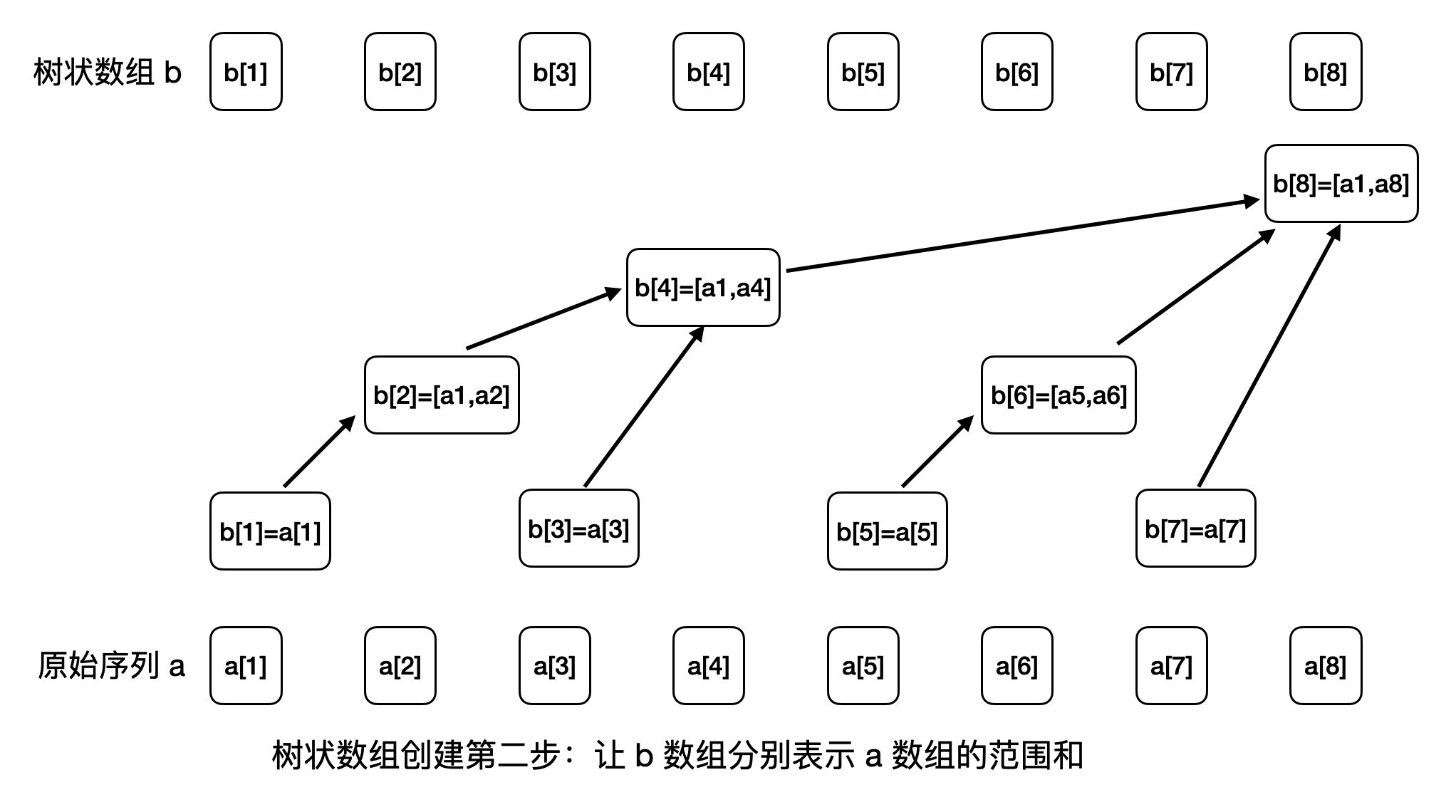
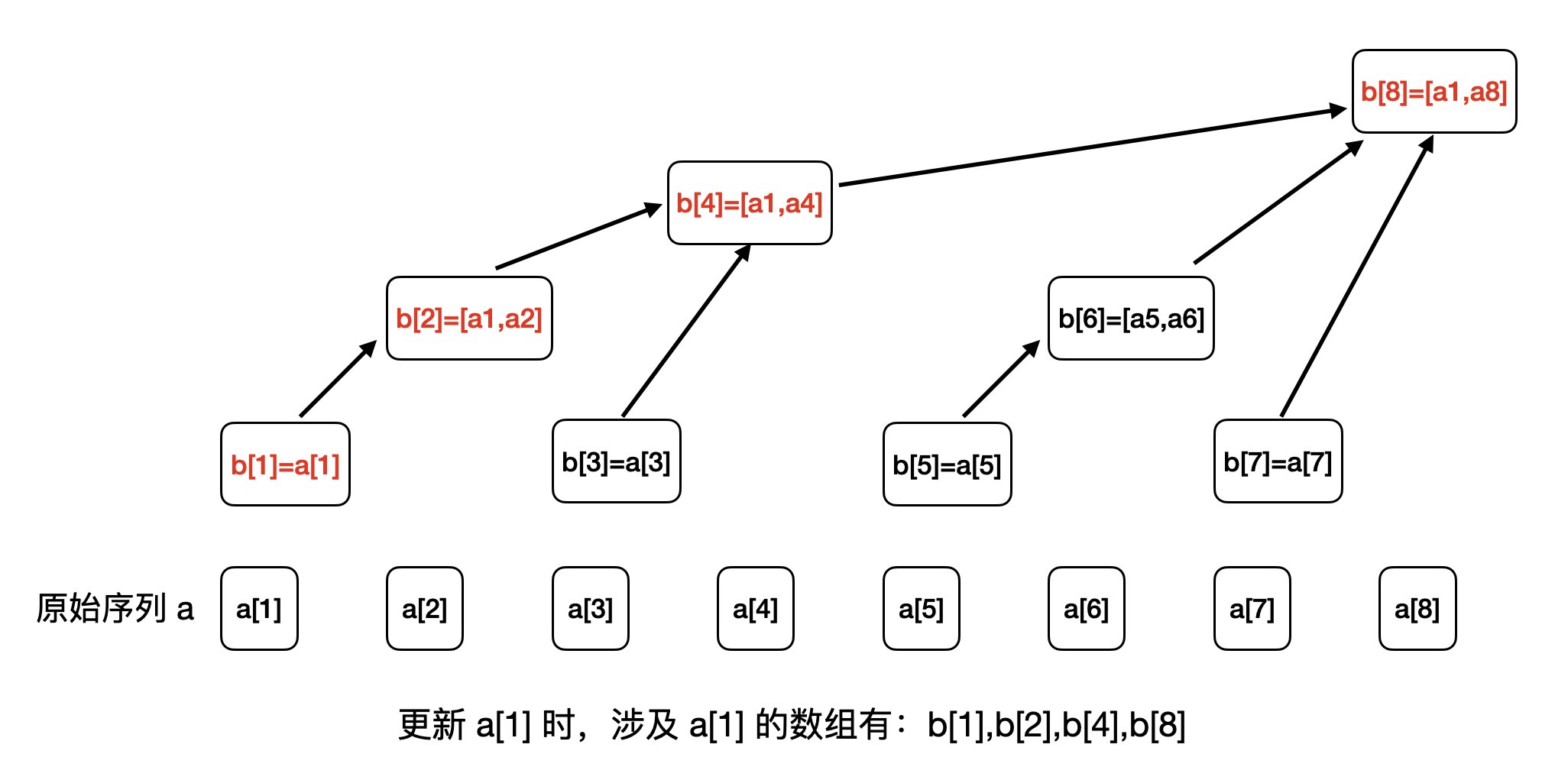
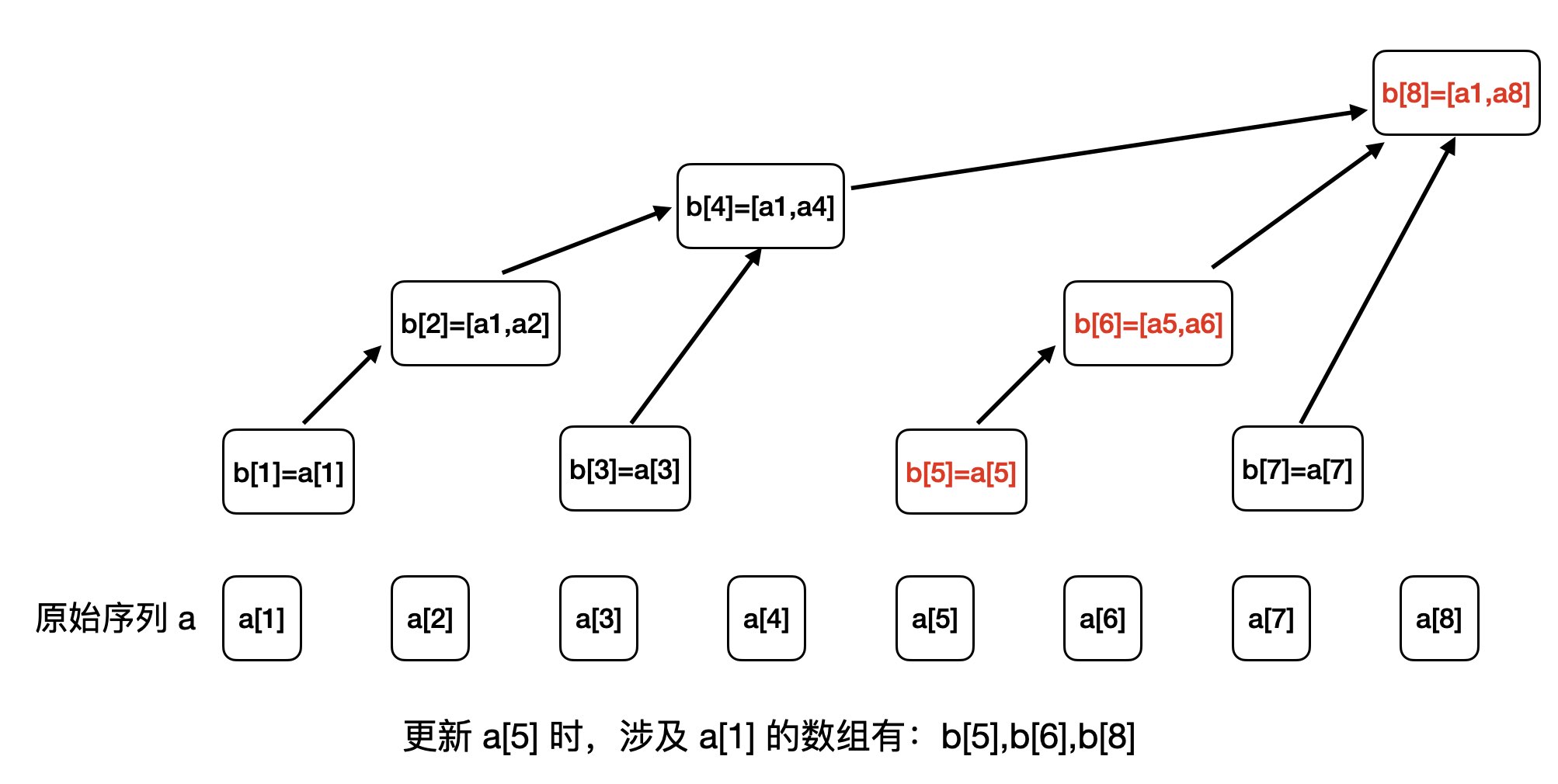
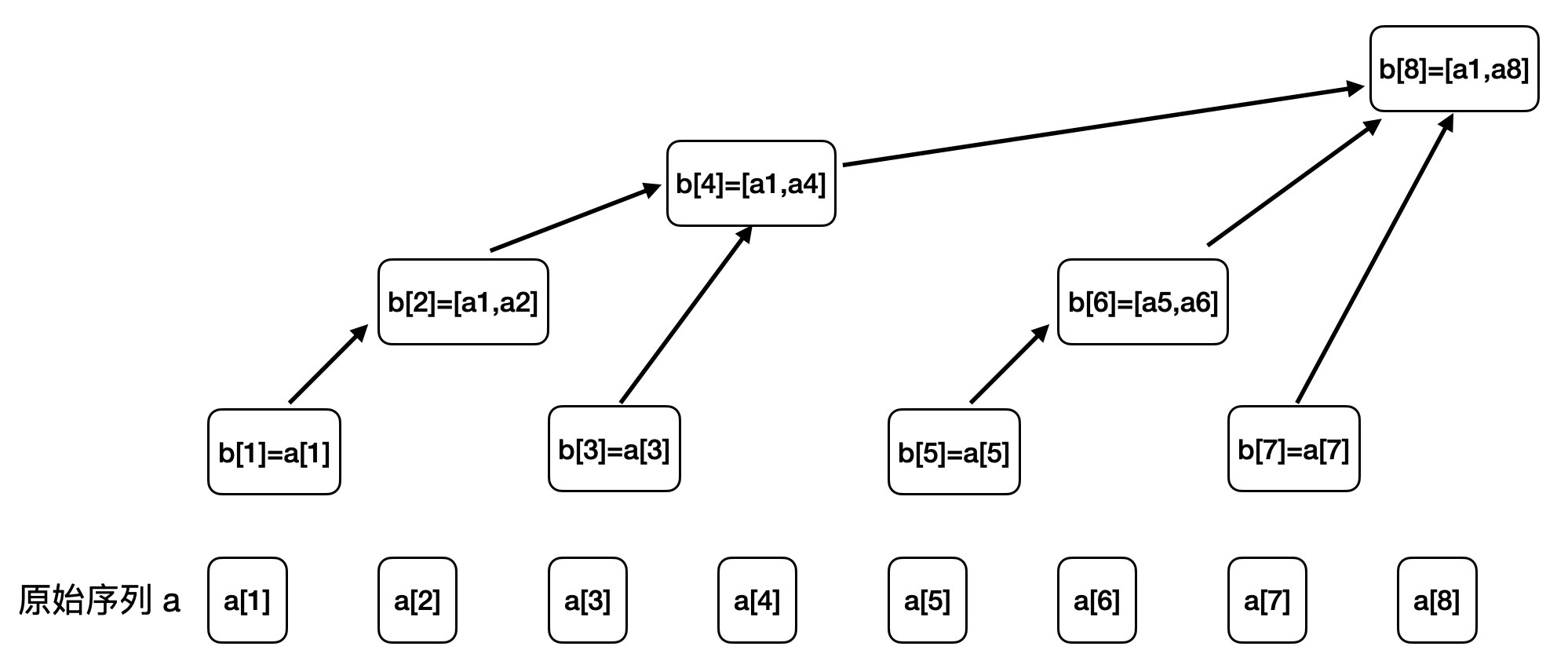
voidadd(int idx, int val){ while (idx <= n) { b[idx] += val; idx += lowbit(idx); } }
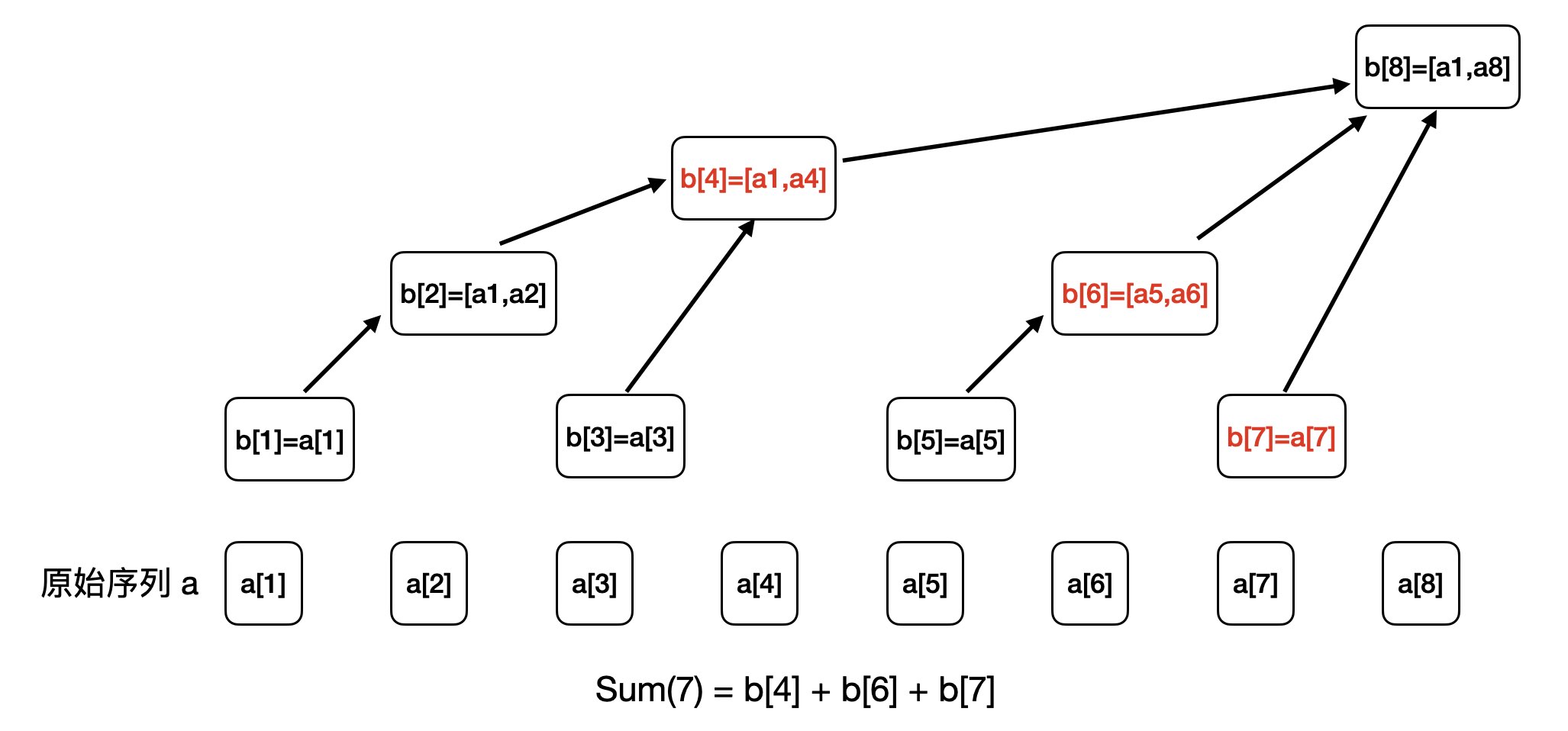
intquery(int range){ int ret = 0; while (range > 0) { ret += b[range]; range -= lowbit(range); } return ret; }
intmain(){ ios::sync_with_stdio(false); cin >> n >> m; for (int i = 1; i <=n; ++i) { cin >> a[i]; add(i, a[i]); } for (int i = 1; i <= m; ++i) { int op, x, y; cin >> op >> x >> y; if (op == 1) { add(x, y); } else { cout << query(y) - query(x-1) << endl; } } return0; }
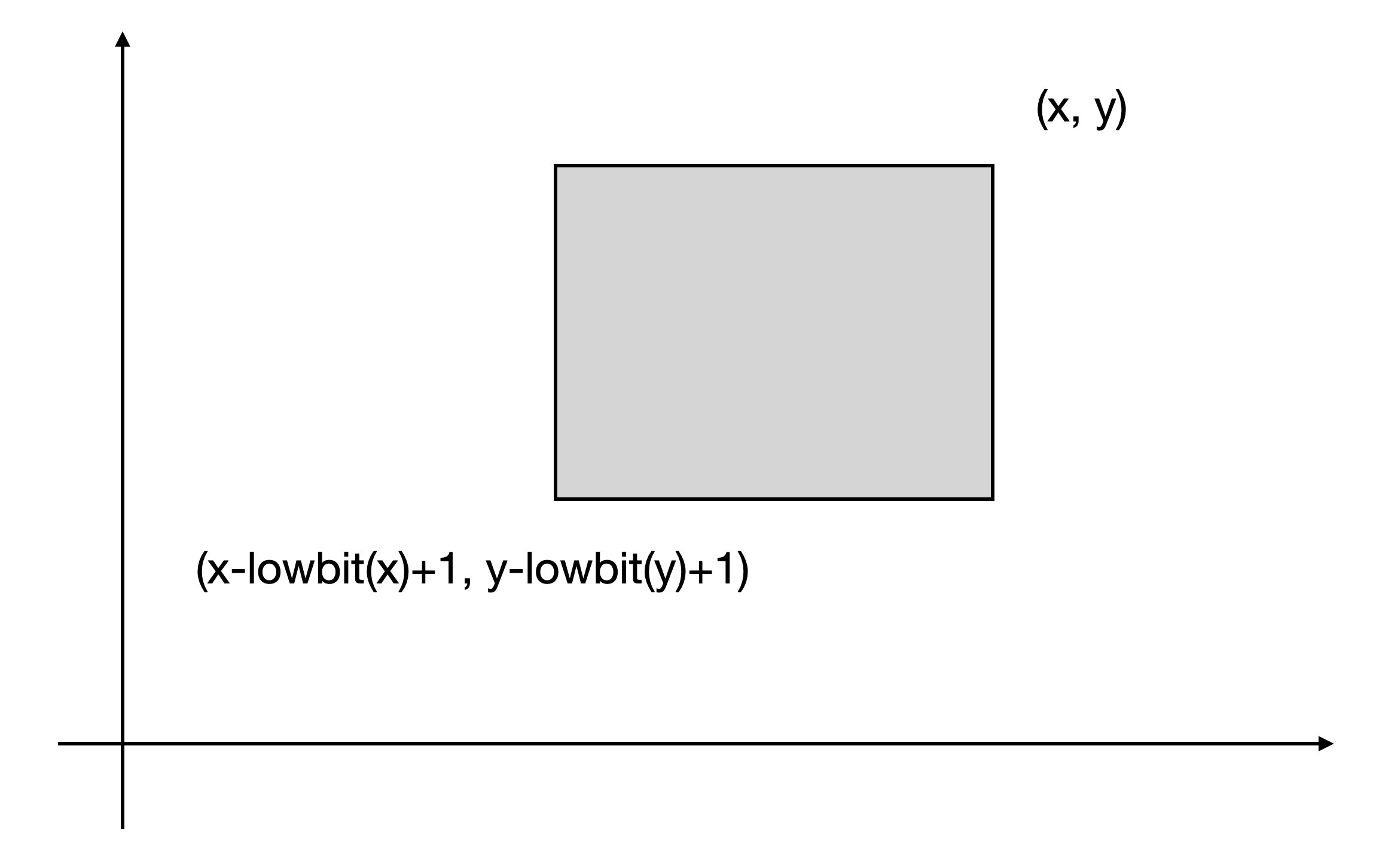
voidadd(int x, int y, int v){ for (int i = x; i <= n; i += lowbit(i)) { for (int j = y; j <= m; j += lowbit(j)) { c[i][j] += v; } } }
查询前缀和同样需要用循环,示例代码如下:
1 2 3 4 5 6 7 8 9
intquery(int x, int y){ int res = 0; for (int i = x; i > 0; i -= lowbit(i)) { for (int j = y; j > 0; j -= lowbit(j)) { res += c[i][j]; } } return res; }
/** * Author: Tang Qiao */ #include<bits/stdc++.h> usingnamespace std; int n, m; char tu[105][105]; int ans; int movex[8] = {0, 0, 1, -1, 1, 1, -1, -1}; int movey[8] = {1, -1, 0, 0, 1, -1, 1, -1};
voiddfs(int x, int y){ tu[x][y] = '.'; for (int i = 0; i < 8; i++) { int nx = x + movex[i]; int ny = y + movey[i]; if (nx < 0 || nx >= n || ny < 0 || ny >= m || tu[nx][ny] != 'W') continue; dfs(nx, ny); } }
intmain(){ cin >> n >> m; for (int i = 0; i < n; i++) { for (int j = 0; j < m; j++) { cin >> tu[i][j]; } } for (int i = 0; i < n; i++) { for (int j = 0; j < m; j++) { if (tu[i][j] == 'W') { dfs(i, j); ans++; } } } cout << ans << endl; return0; }
// 行列唯一性检查 boolfinal_check(){ set<int> row_set, col_set; for (int i = 0; i < 6; i++) { int v = 0; for (int j = 0; j < 6; ++j) { v = v * 10 + (tu[i][j] - '0'); } row_set.insert(v); } if (row_set.size() != 6) returnfalse; for (int j = 0; j < 6; ++j) { int v = 0; for (int i = 0; i < 6; ++i) { v = v * 10 + (tu[i][j] - '0'); } col_set.insert(v); } if (col_set.size() != 6) returnfalse; returntrue; }
voiddfs(int r, int c); voidtry_dfs(int r, int c){ char ch = tu[r][c]; row_cnt[r][ch - '0']++; col_cnt[c][ch - '0']++; if (check(r, c)) { int nr = r; int nc = c + 1; if (nc == 6) { nr++; nc = 0; } dfs(nr, nc); } row_cnt[r][ch - '0']--; col_cnt[c][ch - '0']--; }
voiddfs(int r, int c){ if (r == 6) { if (final_check()) { for (int i = 0; i < 6; i++) { for (int j = 0; j < 6; j++) { cout << tu[i][j]; } } cout << endl; // 因为只有一个合法解,所以找到答案就退出 exit(0); } return; } if (mark[r][c] == 0) { tu[r][c] = '1'; try_dfs(r, c); tu[r][c] = '0'; try_dfs(r, c); } else { tu[r][c] = mark[r][c]; try_dfs(r, c); } }
// 0 - 空地 // 1 - 障碍物 int tu[6][6], n, m, t, sx, sy, ex, ey, ans;
int movex[]={1,-1,0,0}; int movey[]={0,0,-1,1};
voiddfs(int x, int y){ if (x == ex && y == ey) { ans++; return; } for (int i = 0; i < 4; ++i) { int tox = x + movex[i]; int toy = y + movey[i]; if (tox >=1 && tox<=n && toy>=1 && toy<=m && tu[tox][toy]!=1){ tu[tox][toy]=1; dfs(tox, toy); tu[tox][toy]=0; } } }
intmain(){ ios::sync_with_stdio(false); cin >> n >> m >> t; cin >> sx >> sy >> ex >> ey; while (t--) { int x, y; cin >> x >> y; tu[x][y] = 1; } tu[sx][sy] = 1; dfs(sx, sy); cout << ans << endl; return0; }
voiddfs(int pt){ if (tot == n) { cout << v[1]; for (int i = 2; i < pt; ++i) { cout << "+" << v[i]; } cout << endl; return; } for (int i = v[pt-1]; tot + i <=n && i < n ; ++i) { tot += i; v[pt] = i; dfs(pt+1); tot -= i; } }
intmain(){ ios::sync_with_stdio(false); int m, n, t, ans = 0; cin >> m >> n; vector<int> v; while (cin >> t) { if (find(v.begin(), v.end(), t) == v.end()) { // 如果不在内存中 v.push_back(t); ++ans; } if (v.size() > m) v.erase(v.begin()); } cout << ans << endl; }
boolisPrime(int a){ for (int i = 2; i*i <=a; i++) { if (a%i == 0) returnfalse; } returntrue; }
初学者在写的时候,要注意 i*i 与 a 的比较是小于等于。
质因数分解
质因数分解的方法是从 2 开始试商,如果发现能整除,就把被除数中该因数去掉,关键代码是:
1
while (N % i == 0) N /= i;
这样经过几轮下来,N 的值会变得很小,最后 N 如果不为 1,N 就是最后一个质因数。
完整代码如下:
1 2 3 4 5 6 7 8 9 10 11 12 13
vector<int> prime_facs(int N){ vector<int> result; for (int i = 2; i * i <= N; i++) { if (N % i == 0) { while (N % i == 0) N /= i; result.push_back(i); } } if (N != 1) { // 说明再经过操作之后 N 留下了一个素数 result.push_back(N); } return result; }
intgetMaxPrime(int v){ int ret = 0; for (int i = 2; i*i <= v; i++) { if (v%i == 0){ ret = max(ret, i); while (v%i == 0) v/=i; // 把 v 的值缩小 } } ret = max(ret, v); return ret; }
intmain(){ cin >> n >> b; for (int i = 1; i <=n; ++i) { int t = getMaxPrime(i); if (t <= b) ans++; } cout << ans << endl; return0; }
longlongdi(longlong a, longlong L){ if (debug) { // 可用 debug 查看坐标变化过程 cout << "test a = " << a << ", L = " << L << endl; } if (a <= n) { return a; } else { // 如果 a 的位置在右半侧,则调整到左半侧 if (a > L/2) { if (a == L/2 + 1) a = L/2; else a = a - L/2 - 1; } returndi(a, L/2); } }
intmain(){ cin >> s >> a; n = s.length();
// 求出开始往回递归时,字符串拼起来的长度 L longlong L = n; while (L < a) L *= 2;
// 寻找 L 这个长度下,第 a 个字符相当于哪个位置 int ans = di(a, L); cout << s[ans-1] << endl; return0; }
intmain(){ cin >> n; for (int i = 0; i < n; ++i) { v[i] = i+1; } do { for (int i = 0; i < n; ++i) { printf("%5d", v[i]); } printf("\n"); } while (next_permutation(v, v+n)); return0; }
intmain(){ cin >> n >> r; for (int i = r; i < n; ++i) { v[i] = 1; } do { for (int i = 0; i < n; ++i) { if (v[i] == 0) printf("%3d", i+1); } printf("\n"); } while (next_permutation(v, v+n)); return0; }
intmain(){ int n, m; cin >> n >> m; for (int i = 0; i < n; i++) { for (int j = 0; j < m; j++) { char ch; cin >> ch; cnt[i][ch]++; } } int ans = INT_MAX; // 枚举蓝色行的起止 for (int i = 1; i < n; ++i) { for (int j = i; j < n-1; ++j) { int cost = 0; for (int k = 0; k < i; ++k) cost += m - cnt[k]['W']; for (int k = i; k <= j; ++k) cost += m - cnt[k]['B']; for (int k = j+1; k < n; ++k) cost += m - cnt[k]['R']; ans = min(ans, cost); } } cout << ans << endl; return0; }
boolcheck(int x, int y, int dx, int dy){ int nx = x, ny = y; for (int i = 0; i < k; i++) { if (nx >= n || ny >= m) returnfalse; if (tu[nx][ny] == '#') returnfalse; nx += dx; ny += dy; } returntrue; }
intmain(){ ios::sync_with_stdio(false); cin >> n >> m >> k; for (int i = 0; i < n; i++) { for (int j = 0; j < m; j++) { cin >> tu[i][j]; } } for (int i = 0; i < n; i++) { for (int j = 0; j < m; j++) { if (check(i, j, 1, 0)) ans++; if (check(i, j, 0, 1)) ans++; } } if (k == 1) ans /= 2; cout << ans << endl; return0; }
unordered_map<int, int> cnt; int n, x, maxv; longlong ans;
// 从 a 个数中选 2 个数的组合数 longlongC(longlong a){ return a * (a - 1) / 2; }
intmain(){ ios::sync_with_stdio(false); cin >> n; for (int i = 0; i < n; i++) { cin >> x; cnt[x]++; maxv = max(maxv, x); } for (int a = 1; a <= maxv; a++) { for (int b = a; b <= maxv; b++) { if (a == b && cnt[a] < 2) continue; int c = a + b; if (cnt[c] >= 2) { longlong base = C(cnt[c]) % MOD; if (a == b) base = base * C(cnt[a]) % MOD; else base = base * ((cnt[a] * cnt[b]) % MOD) % MOD; ans = (ans + base) % MOD; } } } cout << ans << endl; return0; }
string add(string a, string b){ int len_a = a.length(); int len_b = b.length(); int len_max = max(len_a, len_b); int carry = 0; string ret = ""; for (int i = 0; i < len_max; i++) { int num_a = i < len_a ? a[len_a - i - 1] - '0' : 0; int num_b = i < len_b ? b[len_b - i - 1] - '0' : 0; int sum = num_a + num_b + carry; ret = to_string(sum % 10) + ret; carry = sum / 10; } if (carry > 0) ret = to_string(carry) + ret; return ret; }
string dfs(int n, int m){ if (n > m) return"0"; if (n == m) return"1"; if (record[n][m] != "") return record[n][m]; return record[n][m] = add(dfs(n+1, m), dfs(n+2, m)); }
intmain(){ int n, m; cin >> n >> m; cout << dfs(n, m) << endl; return0; }
int n, m; char tu[110][110]; int movex[] = {-1, -1, -1, 0, 0, 1, 1, 1}; int movey[] = {-1, 0, 1, -1, 1, -1, 0, 1};
intmain(){ cin >> n >> m; for (int i = 1; i <= n; ++i) { for (int j = 1; j <= m; ++j) { cin >> tu[i][j]; } }
for (int i = 1; i <= n; ++i) { for (int j = 1; j <= m; ++j) { if (tu[i][j] == '*') continue; int cnt = 0; for (int k = 0; k < 8; ++k) { int x = i + movex[k]; int y = j + movey[k]; if (tu[x][y] == '*') cnt++; } tu[i][j] = cnt + '0'; } }
for (int i = 1; i <= n; ++i) { for (int j = 1; j <= m; ++j) { cout << tu[i][j]; } cout << endl; } return0; }
boolcheck(int i, int j){ // 检查上方格子 if (i > 1 && a[i-1][j] == y) returntrue; // 检查下方格子 if (i < n && a[i+1][j] == y) returntrue; // 检查左侧格子 if (j > 1 && a[i][j-1] == y) returntrue; // 检查右侧格子 if (j < m && a[i][j+1] == y) returntrue; returnfalse; }
intmain(){ ios::sync_with_stdio(false); cin >> n >> m; for (int i = 1; i <= n; i++) { for (int j = 1; j <= m; j++) { cin >> a[i][j]; } } cin >> x >> y; int count = 0; for (int i = 1; i <= n; i++) { for (int j = 1; j <= m; j++) { if (a[i][j] == x && check(i, j)) { count++; } } } cout << count << endl; return0; }
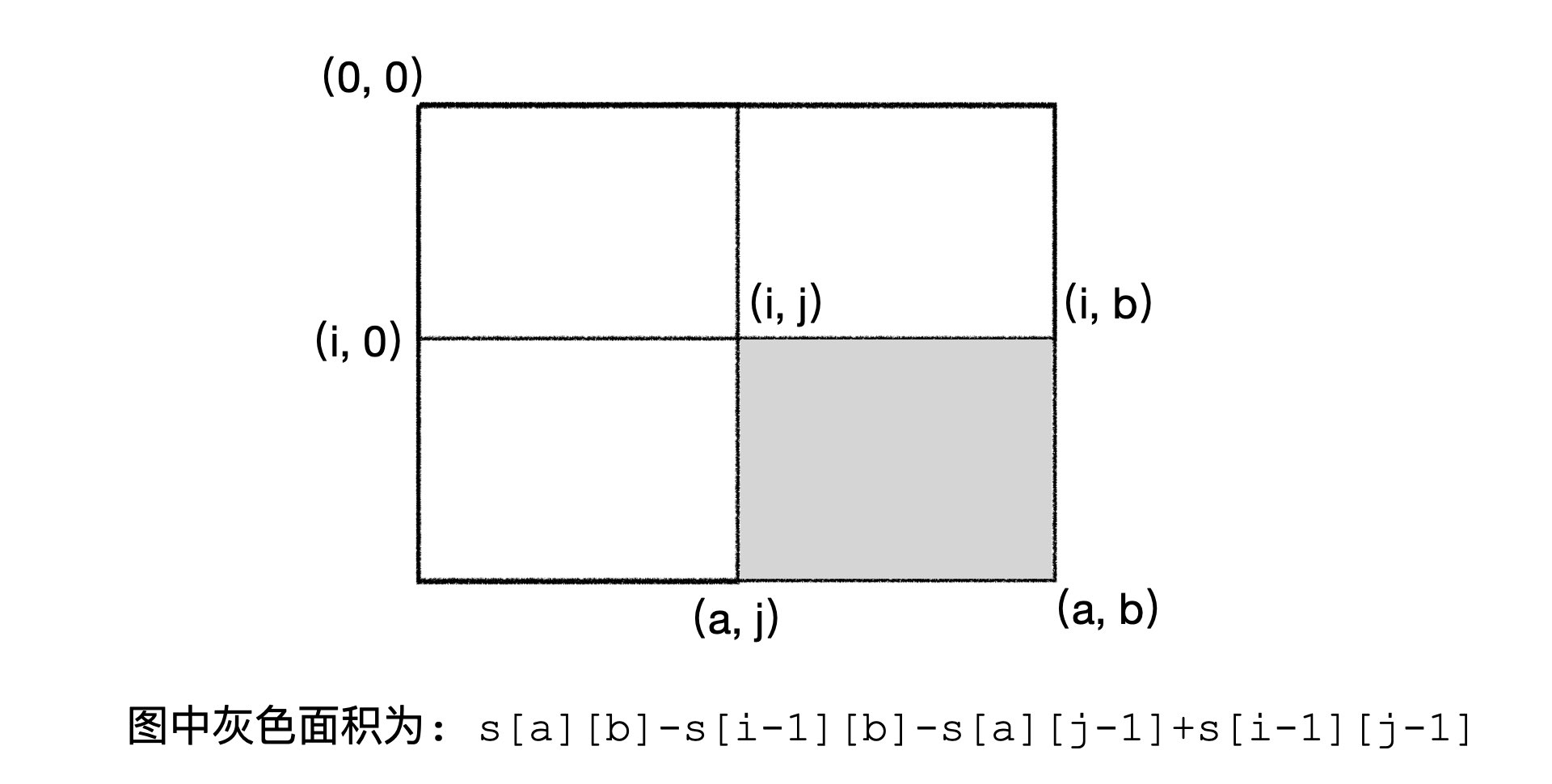
int n, m, k, ans; int s[110][110]; // 表示从(0,0)到(a,b)的 1 的个数 char tu[110][110];
intmain(){ cin >> n >> m >> k; for (int i = 1; i <= n; i++) { cin >> tu[i]+1; } // 从第二行递推 for (int i = 1; i <= n; i++) { int cnt = 0; for (int j = 1; j <= m; j++) { cnt += (tu[i][j] == '1'); s[i][j] = s[i-1][j] + cnt; } } ans = INT_MAX; for (int i = 1; i <= n; i++) { for (int j = 1; j <= m; j++) { for (int a = i; a <= n; a++) { for (int b = j; b <= m; b++) { int cnt = s[a][b] - s[i-1][b] - s[a][j-1] + s[i-1][j-1]; if (cnt >= k) { int tmp = (a-i+1) * (b-j+1); if (tmp < ans) ans = tmp; } } } } } if (ans == INT_MAX) cout << 0 << endl; else cout << ans << endl; return0; }
intmain(){ int n, m; cin >> n >> m; vector<int> a(n); for (int i = 0; i < n; i++) { cin >> a[i]; } int current = 0; for (int i = 0; i < m; i++) { int step = a[current] % n; current = (current - step + n) % n; } cout << current + 1 << endl; return0; }
voidmark(int x, int y, int size){ if (size == 1) return; int half = size/2; for (int i = x; i < x+half; ++i) { for (int j = y; j < y+half; ++j) { v[i][j] = '0'; } } mark(x, y+half, half); mark(x+half, y, half); mark(x+half, y+half, half); }
intmain(){ cin >> n; m = 1<<n; memset(v, '1', sizeof(v)); mark(0, 0, m); for (int i = 0; i < m; ++i) { for (int j = 0; j < m; ++j) { cout << v[i][j] << " "; } cout << endl; } return0; }
int n, x, y, order; int tu[15][15]; int movex[] = {0, 1, 0, -1}; int movey[] = {1, 0, -1, 0}; intmain(){ cin >> n; memset(tu, 0, sizeof(tu)); x = 1; y = 0; order = 0; for (int i = 1; i <= n*n; i++) { int nx = x + movex[order]; int ny = y + movey[order]; if (nx < 1 || nx > n || ny < 1 || ny > n || tu[nx][ny] != 0) { order = (order + 1) % 4; nx = x + movex[order]; ny = y + movey[order]; } x = nx; y = ny; tu[x][y] = i; } for (int i = 1; i <= n; i++) { for (int j = 1; j <= n; j++) { printf("%3d", tu[i][j]); } printf("\n"); } return0; }
#define MAXN 510 int f[MAXN][MAXN], g[MAXN][MAXN]; int n, m; intmain(){ cin >> n >> m; int cnt = 1; for (int i = 1; i <= n; i++) { for (int j = 1; j <= n; j++) { f[i][j] = cnt++; } } for (int i = 1; i <=m; ++i) { int x, y, r, z; cin >> x >> y >> r >> z; if (z == 0) { for (int a = x-r; a <= x+r; ++a) for (int b = y-r; b <= y+r; ++b) g[b-y+x][x-a+y]=f[a][b];
} else { for (int a = x-r; a <= x+r; ++a) for (int b = y-r; b <= y+r; ++b) g[y-b+x][a-x+y]=f[a][b]; } for (int a = x-r; a <= x+r; ++a) for (int b = y-r; b <= y+r; ++b) f[a][b] = g[a][b]; } // end of m for (int i = 1; i <= n; i++) { for (int j = 1; j <= n; j++) { cout << f[i][j] << " "; } cout << endl; } return0; }
boolmatch(char a[12][12], char b[12][12]){ for (int x = 0; x < n; ++x) { for (int y = 0; y < n; ++y) { if (a[x][y] != b[x][y]) returnfalse; } } returntrue; }
voidprint(char a[12][12]){ for (int i = 0; i < n; ++i) { cout << a[i] << endl; } }
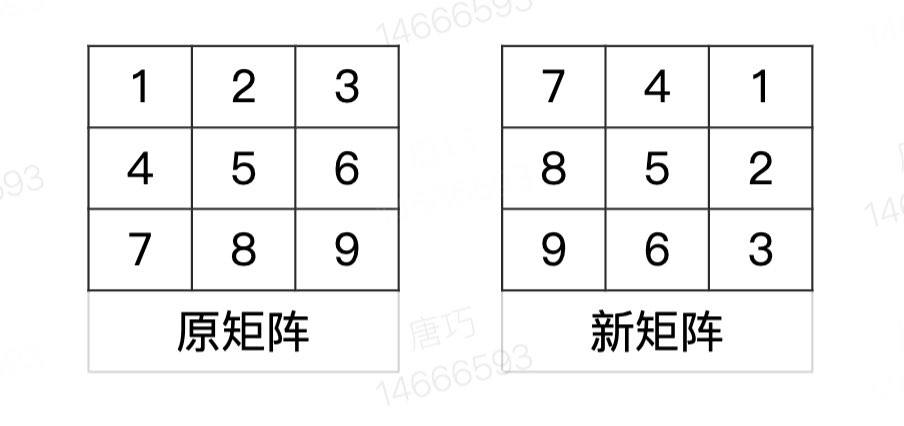
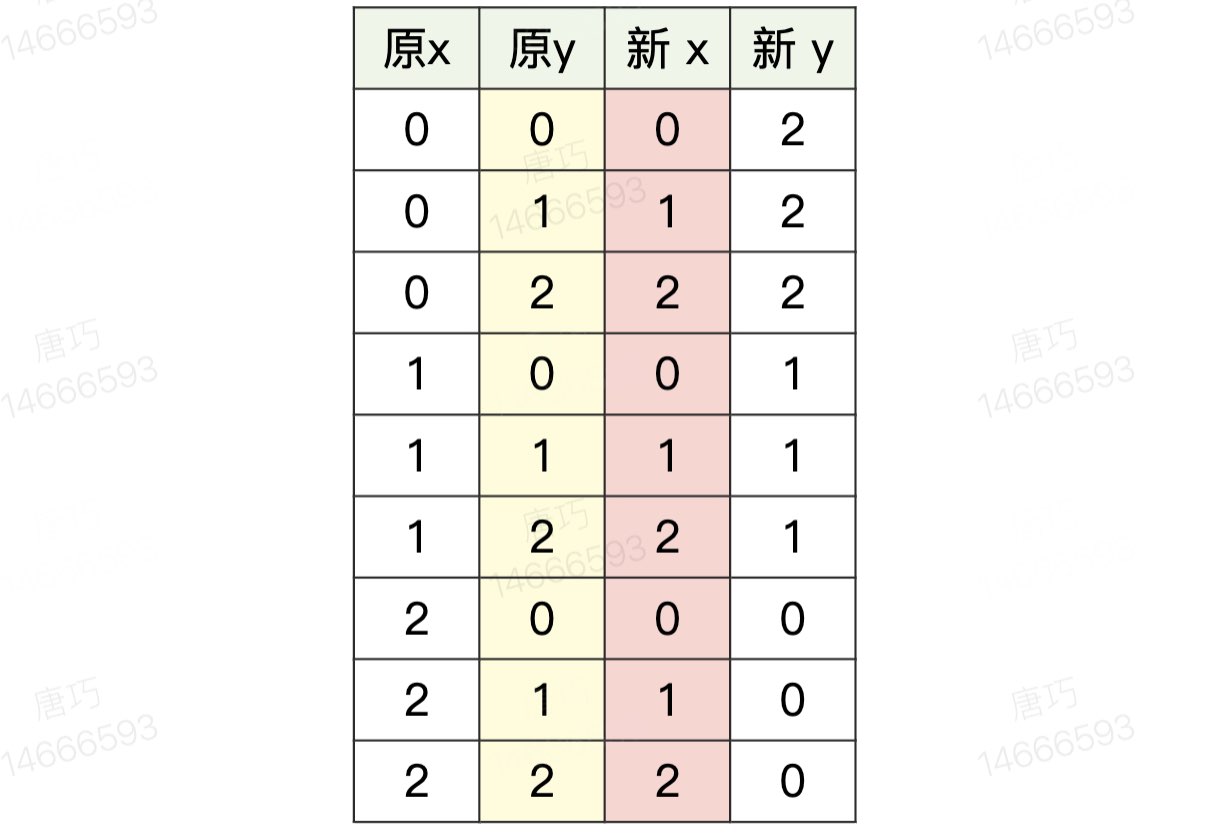
intmain(){ cin >> n; for (int i = 0; i < n; ++i) { cin >> ori[i]; } for (int i = 0; i < n; ++i) { cin >> dest[i]; } // 方案一 for (int x = 0; x < n; ++x) { for (int y = 0; y < n; ++y) { tmp[y][n-x-1] = ori[x][y]; } } if (debug) { cout << "debug 1: " << endl; print(tmp); } if (match(tmp, dest)) { cout << "1" << endl; return0; } // 方案二 for (int x = 0; x < n; ++x) { for (int y = 0; y < n; ++y) { tmp2[y][n-x-1] = tmp[x][y]; } } if (match(tmp2, dest)) { cout << "2" << endl; return0; } // 方案三 for (int x = 0; x < n; ++x) { for (int y = 0; y < n; ++y) { tmp[y][n-x-1] = tmp2[x][y]; } } if (match(tmp, dest)) { cout << "3" << endl; return0; } // 反射 for (int x = 0; x < n; ++x) { for (int y = 0; y < n; ++y) { tmp[x][n-y-1] = ori[x][y]; } } if (match(tmp, dest)) { cout << "4" << endl; return0; } // 反射+旋转90 for (int x = 0; x < n; ++x) { for (int y = 0; y < n; ++y) { tmp2[y][n-x-1] = tmp[x][y]; } } if (debug) { cout << "debug 5-1: " << endl; print(tmp2); } if (match(tmp2, dest)) { cout << "5" << endl; return0; } // 反射+旋转180 for (int x = 0; x < n; ++x) { for (int y = 0; y < n; ++y) { tmp[y][n-x-1] = tmp2[x][y]; } } if (debug) { cout << "debug 5-2: " << endl; print(tmp); } if (match(tmp, dest)) { cout << "5" << endl; return0; } // 反射+旋转270 for (int x = 0; x < n; ++x) { for (int y = 0; y < n; ++y) { tmp2[y][n-x-1] = tmp[x][y]; } } if (debug) { cout << "debug 5-3: " << endl; print(tmp2); } if (match(tmp2, dest)) { cout << "5" << endl; return0; } // 不改变 if (match(ori, dest)) { cout << "6" << endl; return0; } cout << "7" << endl; return0; }
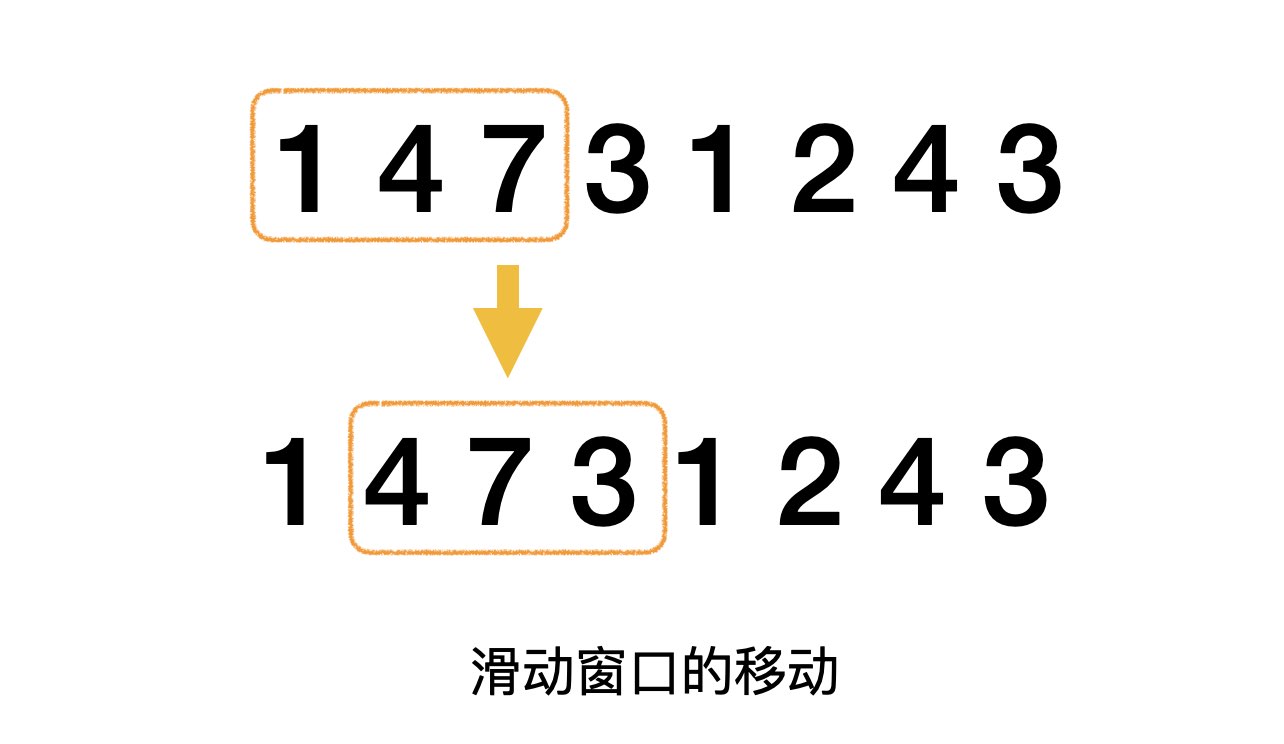
int n, m, tot, ans; int p1, p2; int v[3300]; intmain(){ cin >> n >> m; for (int i = 0; i < n; ++i) { cin >> v[i]; } // 初使化滑动窗口 tot = 0; for (int i = 0; i < m; ++i) { tot += v[i]; } ans = tot; p1 = 0; p2 = m; // 滑动窗口,更新值 while (p2 < n) { tot -= v[p1]; tot += v[p2]; ans = min(ans, tot); p1++; p2++; } cout << ans << endl; return0; }
intfind(int a){ if (p[a] == a) return a; return p[a] = find(p[a]); }
voidmerge(int a, int b){ int pa = find(a); int pb = find(b); p[pa] = pb; }
intmain(){ int a, b; // 初始化 for (int i = 0; i < 5010; ++i) { p[i] = i; } scanf("%d%d%d", &n, &m, &q); for (int i = 0; i < m; ++i) { scanf("%d%d", &a, &b); merge(a, b); } for (int i = 0; i < q; ++i) { scanf("%d%d", &a, &b); if (find(a) == find(b)) printf("Yes\n"); elseprintf("No\n"); } return0; }
intfind(int a){ if (p[a] == a) return a; return p[a] = find(p[a]); }
voidmerge(int a, int b){ int pa = find(a); int pb = find(b); p[pa] = pb; }
voidinit(){ for (int i = 0; i <= n ; ++i) { p[i] = i; } }
intmain(){ while (1) { scanf("%d", &n); if (n == 0) break; init(); scanf("%d", &m); for (int i = 0; i < m; ++i) { int a, b; scanf("%d%d", &a, &b); merge(a, b); } int cnt = 0; for (int i = 1; i <=n ; ++i) { int pa = find(i); if (pa == i) { cnt++; } } printf("%d\n", cnt-1); } return0; }














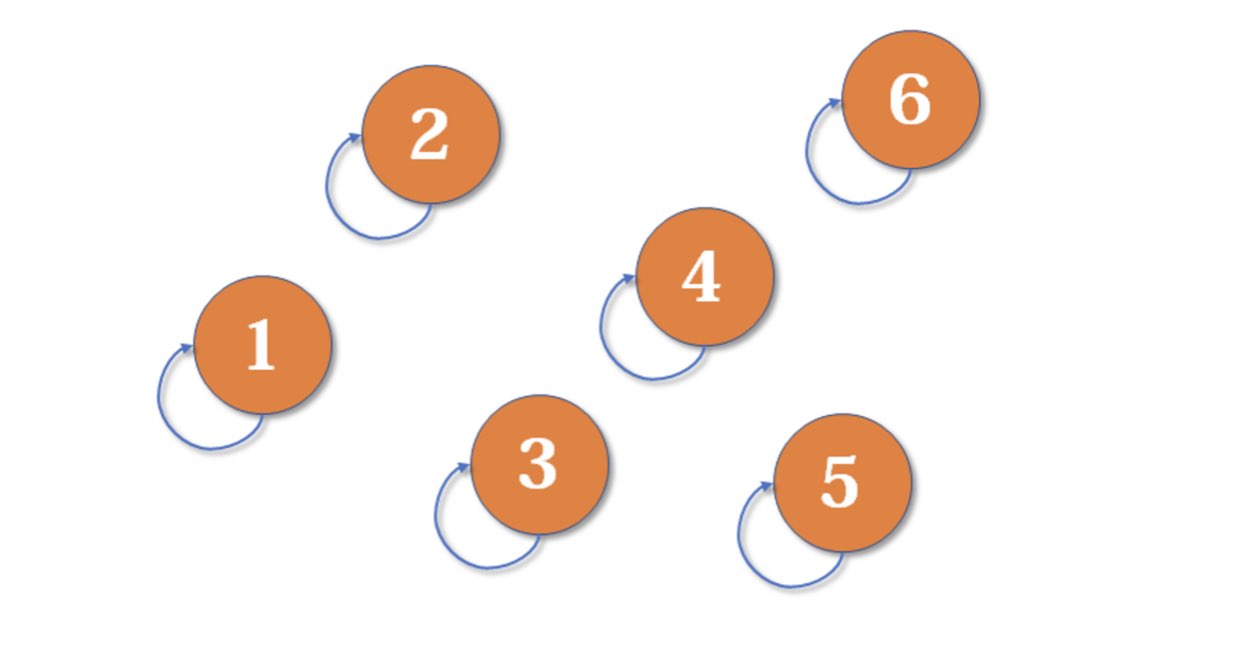
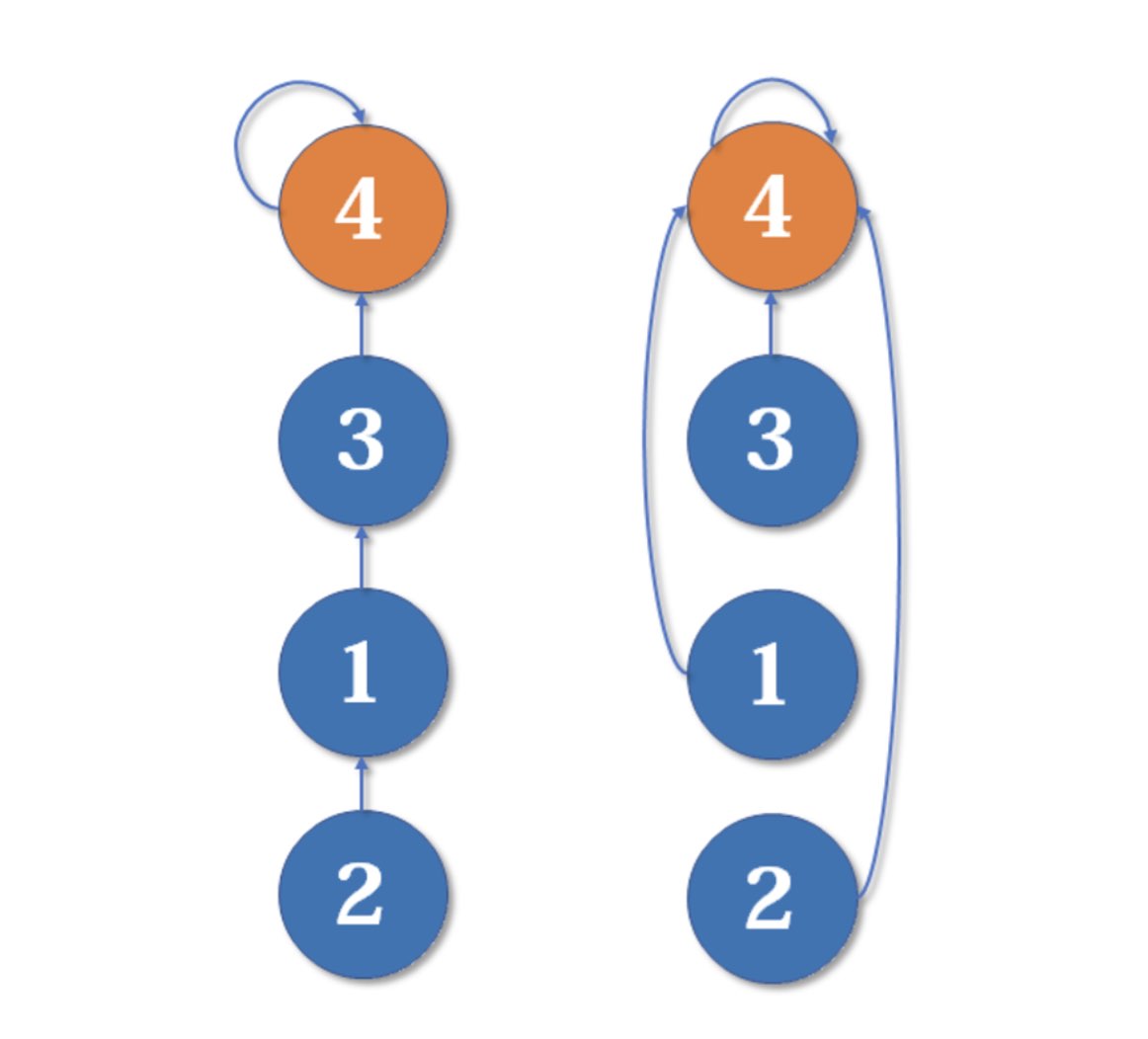
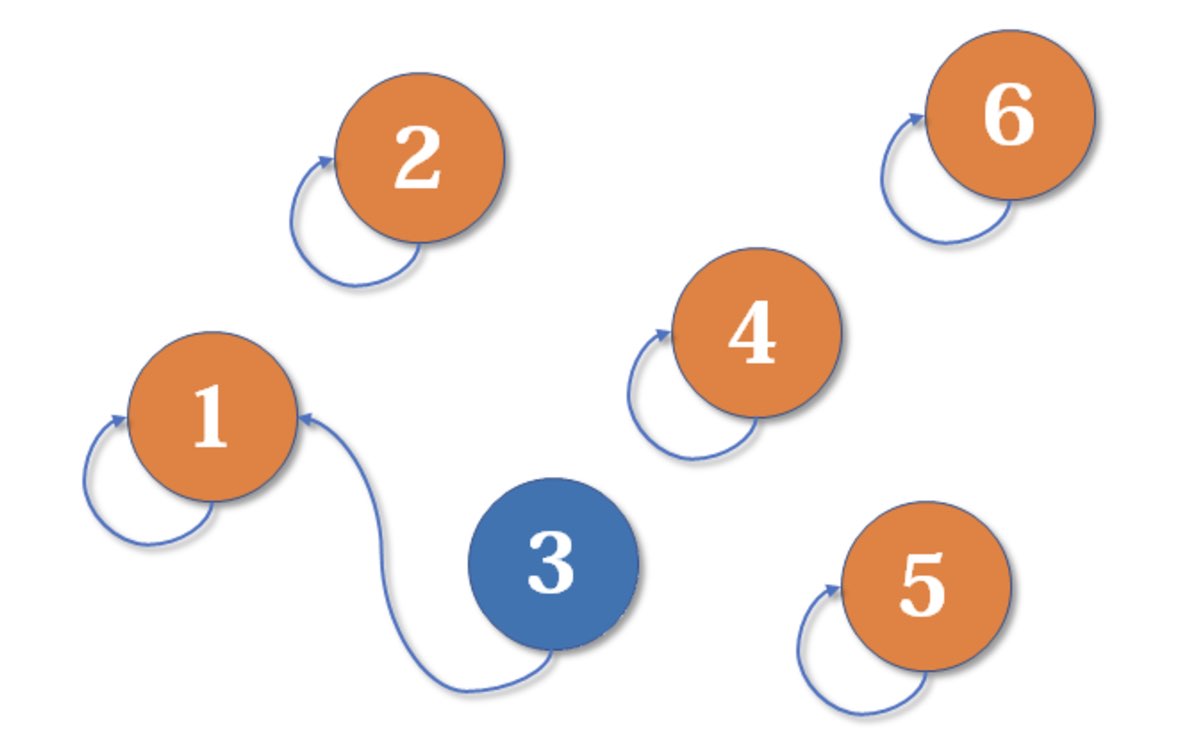
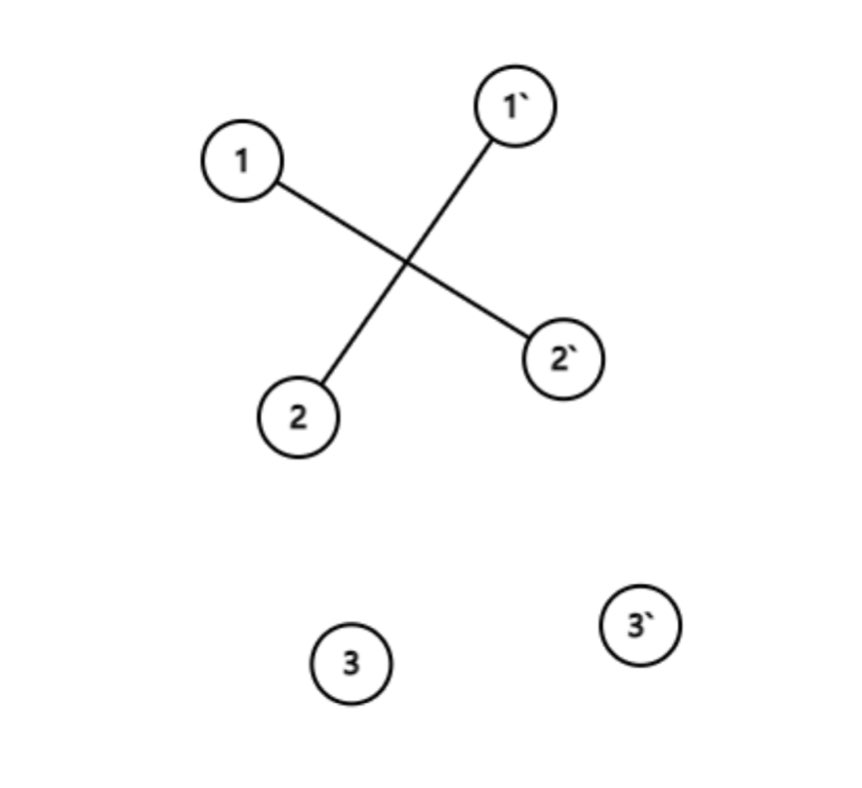
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}