在现有工程中实施基于CTMediator的组件化方案
前述
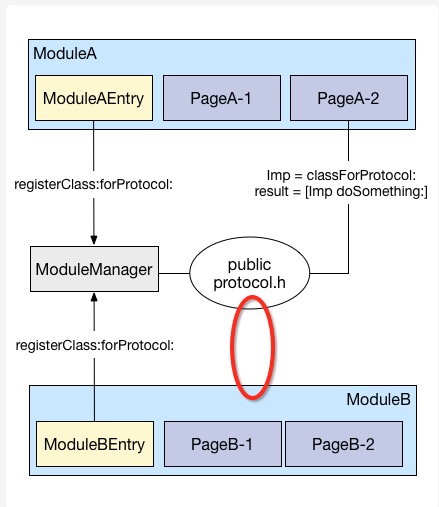
国内业界大家对组件化的讨论从今年年初开始到年尾,不外乎两个方案:URL/protocol注册调度,runtime调度。
我之前批评过URL注册调度是错误的组件化实施方案,在所有的基于URL注册调度的方案中,存在两个普遍问题:
- 命名域渗透
- 因注册是不必要的,而带来同样不必要的注册列表维护成本
其它各家的基于URL注册的不同方案在这两个普遍问题上还有各种各样的其他问题,例如FRDIntent库中的FRDIntent对象其本质是鸡肋对象、原属于响应者的业务被渗透到调用者的业务中、组件化实施方案的过程中会产生对原有代码的侵入式修改等问题。
另外,我也发现还是有人在都没有理解清楚的前提下就做出了自己的解读,流毒甚广。我之前写过关于CTMediator比较理论的描述,也有Demo,但惟独没有写实践方面的描述。我本来以为Demo就足够了,可现在看来还是要给一篇实践的文章的。
在更早之前,卓同学的swift老司机群里也有人提出因为自己并没有理解透彻CTMediator方案,所以不敢贸然直接在项目中应用。所以这篇文章的另一个目的也是希望能够让大家明白,基于CTMediator的组件化方案实施其实非常简单,而且也是有章法可循的。这篇文章可能会去讨论一些理论的东西,但主要还会是以实践为主。争取做到能够让大家看完文章之后就可以直接在自己的项目中顺利实施组件化。
最后,我希望这篇文章能够终结业界持续近一年的关于组件化方案的无谓讨论和错误讨论。
准备工作
我在github上开了一个orgnization,里面有一个主工程:MainProject,我们要针对这个工程来做组件化。组件化实施完毕之后的主工程就是ModulizedMainProject了。抽出来的独立Pod、私有Pod源也都会放在这个orgnization中去。
在一个项目实施组件化方案之前,我们需要做一个准备工作,建立自己的私有Pod源和快手工具脚本的配置:
- 先去开一个repo,这个repo就是我们私有Pod源仓库
pod repo add [私有Pod源仓库名字] [私有Pod源的repo地址]- 创立一个文件夹,例如Project。把我们的主工程文件夹放到Project下:
~/Project/MainProject - 在~/Project下clone快速配置私有源的脚本repo:
git clone git@github.com:casatwy/ConfigPrivatePod.git - 将ConfigPrivatePod的template文件夹下Podfile中
source 'https://github.com/ModulizationDemo/PrivatePods.git'改成第一步里面你自己的私有Pod源仓库的repo地址 - 将ConfigPrivatePod的template文件夹下upload.sh中
PrivatePods改成第二步里面你自己的私有Pod源仓库的名字
最后你的文件目录结构应该是这样:
Project
├── ConfigPrivatePod
└── MainProject
到此为止,准备工作就做好了。
实施组件化方案第一步:创建私有Pod工程和Category工程
MainProject是一个非常简单的应用,一共就三个页面。首页push了AViewController,AViewController里又push了BViewController。我们可以理解成这个工程由三个业务组成:首页、A业务、B业务。
我们这一次组件化的实施目标就是把A业务组件化出来,首页和B业务都还放在主工程。
因为在实际情况中,组件化是需要循序渐进地实施的。尤其是一些已经比较成熟的项目,业务会非常多,一时半会儿是不可能完全组件化的。CTMediator方案在实施过程中,对主工程业务的影响程度极小,而且是能够支持循序渐进地改造方式的。这个我会在文章结尾做总结的时候提到。
既然要把A业务抽出来作为组件,那么我们需要为此做两个私有Pod:A业务Pod(以后简称A Pod)、方便其他人调用A业务的CTMediator category的Pod(以后简称A_Category Pod)。这里多解释一句:A_Category Pod本质上只是一个方便方法,它对A Pod不存在任何依赖。
我们先创建A Pod
- 新建Xcode工程,命名为A,放到Projects下
- 新建Repo,命名也为A,新建好了之后网页不要关掉
此时你的文件目录结构应该是这样:
Project
├── ConfigPrivatePod
├── MainProject
└── A
然后cd到ConfigPrivatePod下,执行./config.sh脚本来配置A这个私有Pod。脚本会问你要一些信息,Project Name就是A,要跟你的A工程的目录名一致。HTTPS Repo、SSH Repo网页上都有,Home Page URL就填你A Repo网页的URL就好了。
这个脚本是我写来方便配置私有库的脚本,pod lib create也可以用,但是它会直接从github上拉一个完整的模版工程下来,只是国内访问github其实会比较慢,会影响效率。而且这个配置工作其实也不复杂,我就索性自己写了个脚本。
这个脚本要求私有Pod的文件目录要跟脚本所在目录平级,也会在XCode工程的代码目录下新建一个跟项目同名的目录。放在这个目录下的代码就会随着Pod的发版而发出去,这个目录以外的代码就不会跟随Pod的版本发布而发布,这样子写用于测试的代码就比较方便。
然后我们在主工程中,把属于A业务的代码拎出来,放到新建好的A工程的A文件夹里去,然后拖放到A工程中。原来主工程里面A业务的代码直接删掉,此时主工程和A工程编译不过都是正常的,我们会在第二步中解决主工程的编译问题,第三步中解决A工程的编译问题。
此时你的主工程应该就没有A业务的代码了,然后你的A工程应该是这样:
A
├── A
| ├── A
| │ ├── AViewController.h
| │ └── AViewController.m
| ├── AppDelegate.h
| ├── AppDelegate.m
| ├── ViewController.h
| ├── ViewController.m
| └── main.m
└── A.xcodeproj
我们再创建A_Category Pod
同样的,我们再创建A_Category,因为它也是个私有Pod,所以也照样子跑一下config.sh脚本去配置一下就好了。最后你的目录结构应该是这样的:
Project
├── A
│ ├── A
│ │ ├── A
│ │ ├── AppDelegate.h
│ │ ├── AppDelegate.m
│ │ ├── Assets.xcassets
│ │ ├── Info.plist
│ │ ├── ViewController.h
│ │ ├── ViewController.m
│ │ └── main.m
│ ├── A.podspec
│ ├── A.xcodeproj
│ ├── FILE_LICENSE
│ ├── Podfile
│ ├── readme.md
│ └── upload.sh
├── A_Category
│ ├── A_Category
│ │ ├── A_Category
│ │ ├── AppDelegate.h
│ │ ├── AppDelegate.m
│ │ ├── Info.plist
│ │ ├── ViewController.h
│ │ ├── ViewController.m
│ │ └── main.m
│ ├── A_Category.podspec
│ ├── A_Category.xcodeproj
│ ├── FILE_LICENSE
│ ├── Podfile
│ ├── readme.md
│ └── upload.sh
├── ConfigPrivatePod
│ ├── config.sh
│ └── templates
└── MainProject
├── FILE_LICENSE
├── MainProject
├── MainProject.xcodeproj
├── MainProject.xcworkspace
├── Podfile
├── Podfile.lock
├── Pods
└── readme.md
然后去A_Category下,在Podfile中添加一行pod "CTMediator",在podspec文件的后面添加s.dependency "CTMediator",然后执行pod install --verbose。
接下来打开A_Category.xcworkspace,把脚本生成的名为A_Category的空目录拖放到Xcode对应的位置下,然后在这里新建基于CTMediator的Category:CTMediator+A。最后你的A_Category工程应该是这样的:
A_Category
├── A_Category
| ├── A_Category
| │ ├── CTMediator+A.h
| │ └── CTMediator+A.m
| ├── AppDelegate.h
| ├── AppDelegate.m
| ├── ViewController.h
| └── ViewController.m
└── A_Category.xcodeproj
到这里为止,A工程和A_Category工程就准备好了。
实施组件化方案第二步:在主工程中引入A_Category工程,并让主工程编译通过
去主工程的Podfile下添加pod "A_Category", :path => "../A_Category"来本地引用A_Category。
然后编译一下,说找不到AViewController的头文件。此时我们把头文件引用改成#import <A_Category/CTMediator+A.h>。
然后继续编译,说找不到AViewController这个类型。看一下这里是使用了AViewController的地方,于是我们在Development Pods下找到CTMediator+A.h,在里面添加一个方法:
- (UIViewController *)A_aViewController;
再去CTMediator+A.m中,补上这个方法的实现,把主工程中调用的语句作为注释放进去,将来写Target-Action要用:
- (UIViewController *)A_aViewController
{
/*
AViewController *viewController = [[AViewController alloc] init];
*/
return [self performTarget:@"A" action:@"viewController" params:nil shouldCacheTarget:NO];
}
补充说明一下,performTarget:@"A"中给到的@"A"其实是Target对象的名字。一般来说,一个业务Pod只需要有一个Target就够了,但一个Target下可以有很多个Action。Action的名字也是可以随意命名的,只要到时候Target对象中能够给到对应的Action就可以了。
关于Target-Action我们会在第三步中去实现,现在不实现Target-Action是不影响主工程编译的。
category里面这么写就已经结束了,后面的实施过程中就不会再改动到它了。
然后我们把主工程调用AViewController的地方改为基于CTMediator Category的实现:
UIViewController *viewController = [[CTMediator sharedInstance] A_aViewController];
[self.navigationController pushViewController:viewController animated:YES];
再编译一下,编译通过。
到此为止主工程就改完了,现在跑主工程点击这个按钮跳不到A页面是正常的,因为我们还没有在A工程中实现Target-Action。
而且此时主工程中关于A业务的改动就全部结束了,后面的组件化实施过程中,就不会再有针对A业务线对主工程的改动了。
实施组件化方案第三步:添加Target-Action,并让A工程编译通过
此时我们关掉所有XCode窗口。然后打开两个工程:A_Category工程和A工程。
我们在A工程中创建一个文件夹:Targets,然后看到A_Category里面有performTarget:@"A",所以我们新建一个对象,叫做Target_A。
然后又看到对应的Action是viewController,于是在Target_A中新建一个方法:Action_viewController。这个Target对象是这样的:
头文件:
#import <UIKit/UIKit.h>
@interface Target_A : NSObject
- (UIViewController *)Action_viewController:(NSDictionary *)params;
@end
实现文件:
#import "Target_A.h"
#import "AViewController.h"
@implementation Target_A
- (UIViewController *)Action_viewController:(NSDictionary *)params
{
AViewController *viewController = [[AViewController alloc] init];
return viewController;
}
@end
这里写实现文件的时候,对照着之前在A_Category里面的注释去写就可以了。
因为Target对象处于A的命名域中,所以Target对象中可以随意import A业务线中的任何头文件。
另外补充一点,Target对象的Action设计出来也不是仅仅用于返回ViewController实例的,它可以用来执行各种属于业务线本身的任务。例如上传文件,转码等等各种任务其实都可以作为一个Action来给外部调用,Action完成这些任务的时候,业务逻辑是可以写在Action方法里面的。
换个角度说就是:Action具备调度业务线提供的任何对象和方法来完成自己的任务的能力。它的本质就是对外业务的一层服务化封装。
现在我们这个Action要完成的任务只是实例化一个ViewController并返回出去而已,根据上面的描述,Action可以完成的任务其实可以更加复杂。
然后我们再继续编译A工程,发现找不到BViewController。由于我们这次组件化实施的目的仅仅是将A业务线抽出来,BViewController是属于B业务线的,所以我们没必要把B业务也从主工程里面抽出来。但为了能够让A工程编译通过,我们需要提供一个B_Category来使得A工程可以调度到B,同时也能够编译通过。
B_Category的创建步骤跟A_Category是一样的,不外乎就是这几步:新建Xcode工程、网页新建Repo、跑脚本配置Repo、添加Category代码。
B_Category添加好后,我们同样在A工程的Podfile中本地指过去,然后跟在主工程的时候一样。
所以B_Category是这样的:
头文件:
#import <CTMediator/CTMediator.h>
#import <UIKit/UIKit.h>
@interface CTMediator (B)
- (UIViewController *)B_viewControllerWithContentText:(NSString *)contentText;
@end
实现文件:
#import "CTMediator+B.h"
@implementation CTMediator (B)
- (UIViewController *)B_viewControllerWithContentText:(NSString *)contentText
{
/*
BViewController *viewController = [[BViewController alloc] initWithContentText:@"hello, world!"];
*/
NSMutableDictionary *params = [[NSMutableDictionary alloc] init];
params[@"contentText"] = contentText;
return [self performTarget:@"B" action:@"viewController" params:params shouldCacheTarget:NO];
}
@end
然后我们对应地在A工程中修改头文件引用为#import <B_Category/CTMediator+B.h>,并且把调用的代码改为:
UIViewController *viewController = [[CTMediator sharedInstance] B_viewControllerWithContentText:@"hello, world!"];
[self.navigationController pushViewController:viewController animated:YES];
此时再编译一下,编译通过了。注意哦,这里A业务线跟B业务线就已经完全解耦了,跟主工程就也已经完全解耦了。
实施组件化方案最后一步:收尾工作、组件发版
此时还有一个收尾工作是我们给B业务线创建了Category,但没有创建Target-Action。所以我们要去主工程创建一个B业务线的Target-Action。创建的时候其实完全不需要动到B业务线的代码,只需要新增Target_B对象即可:
Target_B头文件:
#import <UIKit/UIKit.h>
@interface Target_B : NSObject
- (UIViewController *)Action_viewController:(NSDictionary *)params;
@end
Target_B实现文件:
#import "Target_B.h"
#import "BViewController.h"
@implementation Target_B
- (UIViewController *)Action_viewController:(NSDictionary *)params
{
NSString *contentText = params[@"contentText"];
BViewController *viewController = [[BViewController alloc] initWithContentText:contentText];
return viewController;
}
@end
这个Target对象在主工程内不存在任何侵入性,将来如果B要独立成一个组件的话,把这个Target对象带上就可以了。
收尾工作就到此结束,我们创建了三个私有Pod:A、A_Category、B_Category。
接下来我们要做的事情就是给这三个私有Pod发版,发版之前去podspec里面确认一下版本号和dependency。
Category的dependency是不需要填写对应的业务线的,它应该是只依赖一个CTMediator就可以了。其它业务线的dependency也是不需要依赖业务线的,只需要依赖业务线的Category。例如A业务线只需要依赖B_Category,而不需要依赖B业务线或主工程。
发版过程就是几行命令:
git add .
git commit -m "版本号"
git tag 版本号
git push origin master --tags
./upload.sh
命令行cd进入到对应的项目中,然后执行以上命令就可以了。
要注意的是,这里的版本号要和podspec文件中的s.version给到的版本号一致。upload.sh是配置私有Pod的脚本生成的,如果你这边没有upload.sh这个文件,说明这个私有Pod你还没用脚本配置过。
最后,所有的Pod发完版之后,我们再把Podfile里原来的本地引用改回正常引用,也就是把:path...那一段从Podfile里面去掉就好了,改动之后记得commit并push。
组件化实施就这么三步,到此结束。
总结
hard code
这个组件化方案的hard code仅存在于Target对象和Category方法中,影响面极小,并不会泄漏到主工程的业务代码中,也不会泄漏到业务线的业务代码中。
而且在实际组件化的实施中,也是依据category去做业务线的组件化的。所以先写category里的target名字,action名字,param参数,到后面在业务线组件中创建Target的时候,照着category里面已经写好的内容直接copy到Target对象中就肯定不会出错(仅Target对象,并不会牵扯到业务线本身原有的对象)。
如果要消除这一层hard code,那么势必就要引入一个第三方pod,然后target对象所在的业务线和category都要依赖这个pod。为了消除这种影响面极小的hard code,而且只要按照章法来就不会出错。为此引入一个新的依赖,其实是不划算的。
命名域问题
在这个实践中,响应者的命名域并没有泄漏到除了响应者以外的任何地方,这就带来一个好处,迁移非常方便。
比如我们的响应者是一个上传组件。这个上传组件如果要替换的话,只需要在它外面包一个Target-Action,就可以直接拿来用了。而且包Target-Action的过程中,不会产生任何侵入性的影响。
例如原来是你自己基于AFNetworking写的上传组件,现在用了七牛SDK上传,那么整个过程你只需要提供一个Target-Action封装一下七牛的上传操作即可。不需要改动七牛SDK的代码,也不需要改动调用方的代码。倘若是基于URL注册的调度,做这个事情就很蛋疼。
服务管理问题
由于Target对象处于响应者的命名域中,Target对象就可以对外提供除了页面实例以外的各种Action。
而且,由于其本质就是针对响应者对外业务逻辑的Action化封装(其实就是服务化封装),这就能够使得一个响应者对外提供了哪些Action(服务),Action(服务)的实现逻辑是什么得到了非常好的管理,能够大大降低将来工程的维护成本。然后Category解决了服务应该怎么调用的问题。
但在基于URL注册机制和Protocol共享机制的组件化方案中,由于服务散落在响应者各处,服务管理就显得十分困难。如果还是执念于这样的方案,大家只要拿上面提到的三个问题,对照着URL注册机制和Protocol共享机制的组件化方案比对一下,就能明白了。
另外,如果这种方案把所有的服务归拢到一个对象中来达到方便管理的目的的话,其本质就已经变成了Target-Action模式,Protocol共享机制其实就已经没有存在意义了。
高内聚
基于protocol共享机制的组件化方案导致响应者业务逻辑泄漏到了调用者业务逻辑中,并没有做到高内聚。
如果这部分业务在其他地方也要使用,那么代码就要重新写一遍。虽然它可以提供一个业务高内聚的对象来符合这个protocol,但事实上这就又变成了Target-Action模式,protocol的存在意义就也没有了。
侵入性问题
正如你所见,CTMediator组件化方案的实施非常安全。因为它并不存在任何侵入性的代码修改。
对于响应者来说,什么代码都不用改,只需要包一层Target-Action即可。例如本例中的B业务线作为A业务的响应者时,不需要修改B业务的任何代码。
对于调用者来说,只需要把调用方式换成CTMediator调用即可,其改动也不涉及原有的业务逻辑,所以是十分安全的。
另外一个非侵入性的特征体现在,基于CTMediator的组件化方案是可以循序渐进地实施的。这个方案的实施并不要求所有业务线都要被独立出来成为组件,实施过程也并不会修改未组件化的业务的代码。
在独立A业务线的过程中如果涉及其它业务线(B业务线)的调用,就只需要给到Target对象即可,Target对象本身并不会对未组件化的业务线(B业务线)产生任何的修改。而且将来如果对应业务线需要被独立出去的时候,也仅需要把Target对象一起复制过去就可以了。
但在基于URL注册和protocol共享的组件化方案中,都必须要在未组件化的业务线中写入注册代码和protocol声明,并分配对应的URL和protocol到具体的业务对象上。这些其实都是不必要的,无端多出了额外维护成本。
注册问题
CTMediator没有任何注册逻辑的代码,避免了注册文件的维护和管理。Category给到的方法很明确地告知了调用者应该如何调用。
例如B_Category给到的- (UIViewController *)B_viewControllerWithContentText:(NSString *)contentText;方法。这能够让工程师一眼就能够明白使用方式,而不必抓瞎拿着URL再去翻文档。
这可以很大程度提高工作效率,同时降低维护成本。
实施组件化方案的时机
MVP阶段过后,越早实施越好。
这里说的MVP不是一种设计模式,而是最小价值产品的意思,它是产品演进的第一个阶段。
一般来说天使轮就是用于MVP验证的,在这个阶段产品闭环尚未确定,因此产品本身的逻辑就会各种变化。但是过了天使轮之后,产品闭环已经确定,此时就应当实施组件化,以应对A轮之后的产品拓张。
有的人说我现在项目很小,人也很少,所以没必要实施组件化。确实,把一个小项目组件化之后,跟之前相比并没有多大程度的改善,因为本来小项目就不复杂,改成组件化之后,也不会更简单。
但这其实是一种很短视的认知。
组件化对于一个小项目而言,真正发挥优势的地方是在未来的半年甚至一年之后。
因为趁着人少项目小,实施组件化的成本就也很小,三四天就可以实施完毕。于是等将来一年之后业务拓张到更大规模时,就不会束手束脚了。
但如果等到项目大了,人手多了再去实施组件化,那时候实施组件化的复杂度肯定比现在规模还很小的时候的复杂度要大得多,三四天肯定搞不定,而且实施过程还会非常艰辛。到那时你就后悔为什么当初没有早早实施组件化了。
Swift工程怎么办?
其实只要Target对象继承自NSObject就好了,然后带上@objc(className)。action的参数名永远只有一个,且名字需要固定为params,其它照旧。具体swift工程中target的写法参见A_swift
因为Target对象是游离于业务实现的,所以它去继承NSObject完全没有任何问题。完整的SwiftDemo在这里。
本文Demo