国家药监局:2025年我国药品申报和审结数量双创新高
国家药监局今天发布《2025年度药品审评报告》,报告显示,2025年我国药品注册申报和审结数量,双双创历史新高。2025年国家药监局药品审评中心全年受理各类药品注册申请20149件,同比增加3%,创历史新高;据介绍,药品注册申请,包括新药临床试验申请、新药上市申请、仿制药上市申请和补充申请等。(央视新闻)
如果几年前有人告诉我,AI 不仅能写代码、生成论文摘要,还能像一个真正的工程师那样,在实验室里反复寻找可行的策略、持续优化一个方案——我大概会觉得这个人科幻片看多了。
但最近读到一篇论文的时候,我的想法变了。
过去两年,大模型的能力突飞猛进,从写诗到写代码,从做数学题到跑实验流程,AI 擅长的事情越来越多。但真正做过科研和工程的人都清楚,最耗人的部分,往往不是提出第一个可行方案,而是后面那段漫长的「长期优化」——一个实验跑通了,但指标还差一点;一个算法能用了,但速度还不够快;一个电池快充策略成立了,但温度、寿命和析锂之间还需要反复平衡。
现实中的高价值成果,很多都不是「做出来」的,而是被持续优化出来的。而这,恰恰是过去大多数 AI Agent 系统最缺失的一环。
最近,Einsia AI 旗下 Navers Lab 发布了一个叫 Frontier-Eng Bench 的新基准测试,正试图衡量这种能力。它没有再把 AI 放进「一问一答」的选择题里,而是直接把 Agent 扔进真实工程优化环境——Agent 必须不断提出方案、运行仿真器、读取反馈、修改策略,在长期迭代中持续逼近更优解。

论文题目:Frontier-Eng: Benchmarking Self-Evolving Agents on Real-World Engineering Tasks with Generative Optimization
Arxiv: https://arxiv.org/abs/2604.12290
Github: https://github.com/EinsiaLab/Frontier-Engineering
这让我想到一个历史参照:AlphaGo 之所以强大,并不在于它每一步棋都能算对,而在于它能在数百万次自我对弈中持续进化。某种程度上,Frontier-Eng 试图回答的,也是同一个问题——当 AI 开始进入真实世界的长期反馈循环后,智能的本质,究竟该怎么衡量?
从「一次性答对」到「持续优化」,
范式正在切换
要理解 Frontier-Eng Bench 的意义,得先看清楚它在反对什么。
过去几年,大模型领域的 benchmark 越来越多,但本质上都在评估同一件事:模型能不能「一次性生成正确答案」。无论是代码生成、数学推理,还是任务执行,大多数测试的逻辑仍然是——答案对,或者错;任务完成,或者失败。
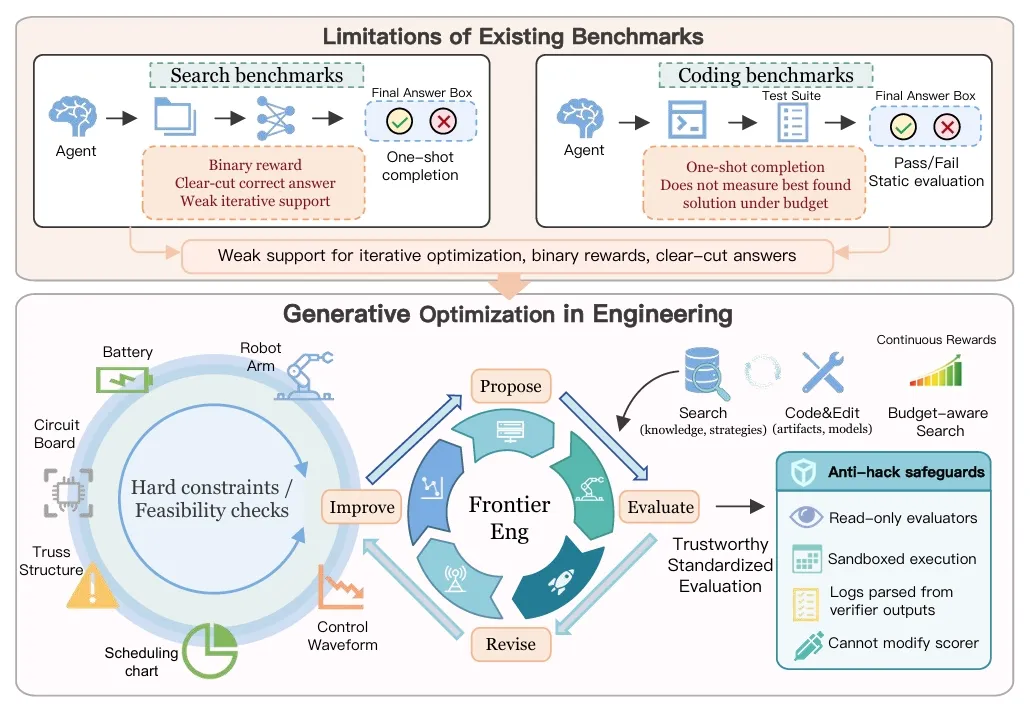
Frontier-Eng Bench 总览
但这里有一个被忽视的问题:真实的科研与工程,从来不是一个「对或错」的过程。
一个量子线路已经正确了,但保真度还能不能再往上抠一点?一个 GPU kernel 已经可用了,但速度还不够快?这些问题没有「标准答案」,只有「更优解」。而找到更优解的过程,往往需要成百上千次的迭代、试错和微调。
事实上,这正是 Frontier-Eng Bench 提出的核心命题——论文将其定义为「Generative Optimization」(生成式优化)。它认为,下一代 Agent 的核心能力,不应该只是「一次性给出看起来合理的答案」,而是能否在环境反馈里持续修正自己的轨迹,并在有限预算下不断优化结果。
换句话说,真正的 intelligence,可能本质上是一种长期反馈闭环中的持续优化能力。
这个判断并不只是理论推演。Frontier-Eng 设计了 47 个横跨五大领域的实验任务——量子计算与信息、运筹与决策科学、机器人与控制系统、光学与通信、物理科学与工程设计。在每一个任务中,Agent 都不是简单地「回答问题」,而是需要提出优化方案、运行仿真器、获取真实反馈、修改代码与策略,并在固定的计算预算里持续迭代。
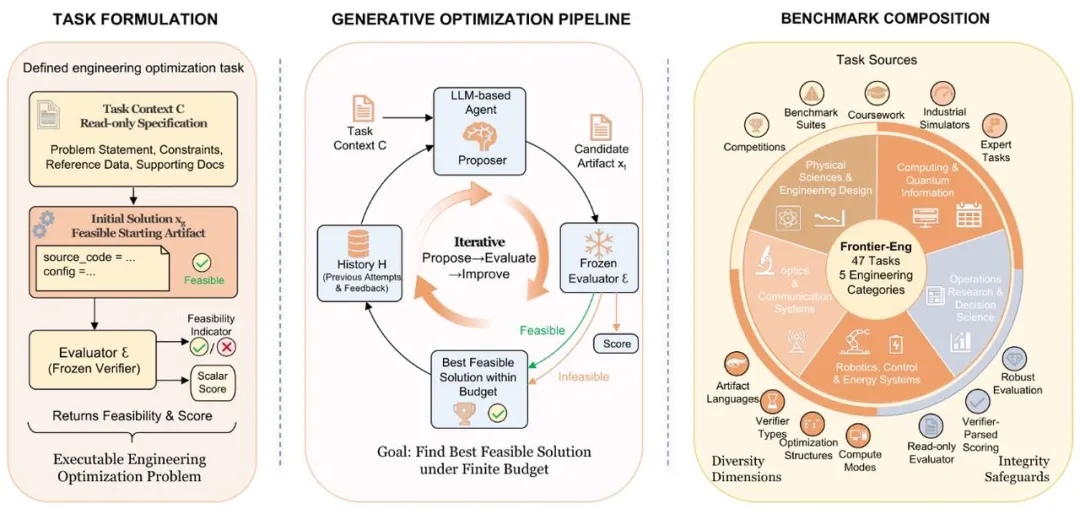
Frontier-Eng Bench 体系概览
不只有「答对题」的聪明,更有「不断变好」的韧性。这可能才是真正长程智能的起点。
深度 vs 宽度:Agent 架构的关键抉择
在 Frontier-Eng 揭示的所有发现中,有一个结论让我印象最深:关于「推理算力分配」的讨论。
论文通过大量实验发现,Agent 的性能提升遵循一套双重幂律衰减规律——随着任务进入「深水区」,获得显著性能提升的难度呈指数级上升。这是一个残酷但真实的规律:越往后优化,每一个百分点的进步都越来越贵。
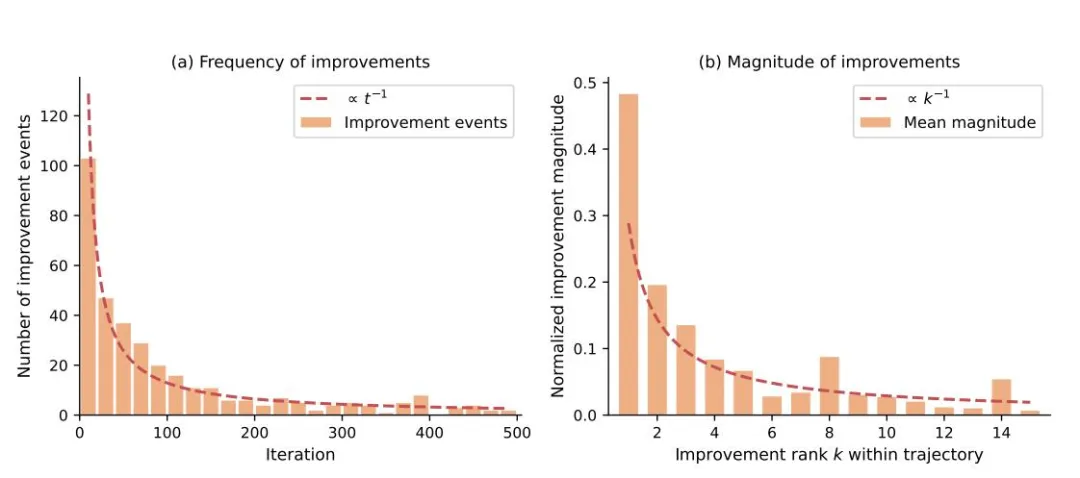
工程优化的双重幂律衰减
但更有意思的发现在于一个架构层面的核心争议:到底是让 Agent 并行尝试 100 种可能性(宽度),还是让它在 1 个路径上通过「反思—修正」递归 100 次(深度)?
Frontier-Eng 给出了一个非常清晰的信号:深度才是那个能撬动真正突破的杠杆。
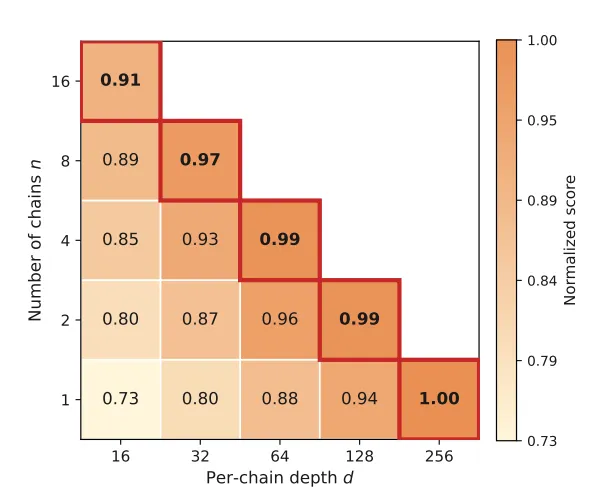
深度 vs 宽度
这让我想到一个日常的类比。面对一道难题,是同时翻开十本参考书碰运气更有效,还是沿着一条思路反复推敲、不断修正更容易找到答案?大多数有经验的工程师和科学家都会选后者。Frontier-Eng 的数据,某种程度上用实验验证了这种直觉。
论文将这种能力称为「Deep Iterative Reasoning」(深度迭代推理)。在这背后,其实指向了一个更大的趋势:下一代 Agent 的核心竞争力,可能正在从「知道多少知识」转向「能不能在长期反馈中持续自我修正」。
一个有趣的现象是,这个结论和人类专家解决复杂问题的方式高度一致。顶级的工程师和科学家,几乎从来不靠「灵光一闪」解决核心难题,而是在漫长的试错循环中一步步逼近最优解。某种程度上,Frontier-Eng 证明了:AI 要变得真正聪明,也得学会这种「慢功夫」。
更重要的是,这个发现正在直接改变 Agent 架构设计的方向。过去,开发者们的注意力大多放在 prompt engineering 上——怎么写出更好的提示词,让模型一次就给出好答案。但如果深度迭代推理才是关键,那么未来真正重要的可能是 reasoning architecture——如何构建更强的推理侧架构,让模型能够像人类专家一样进行「慢思考」。
推理侧的算力红利,才刚刚开始
从产业角度看,Frontier-Eng 释放出的信号其实非常强烈。
过去几年,大模型行业的核心护城河主要来自三件事:参数规模、训练算力、高质量数据。谁的模型更大、训练数据更多、GPU 集群更强,谁就占据优势。
但 Frontier-Eng 的实验结果暗示,护城河可能正在发生转移——从训练侧转向推理侧。
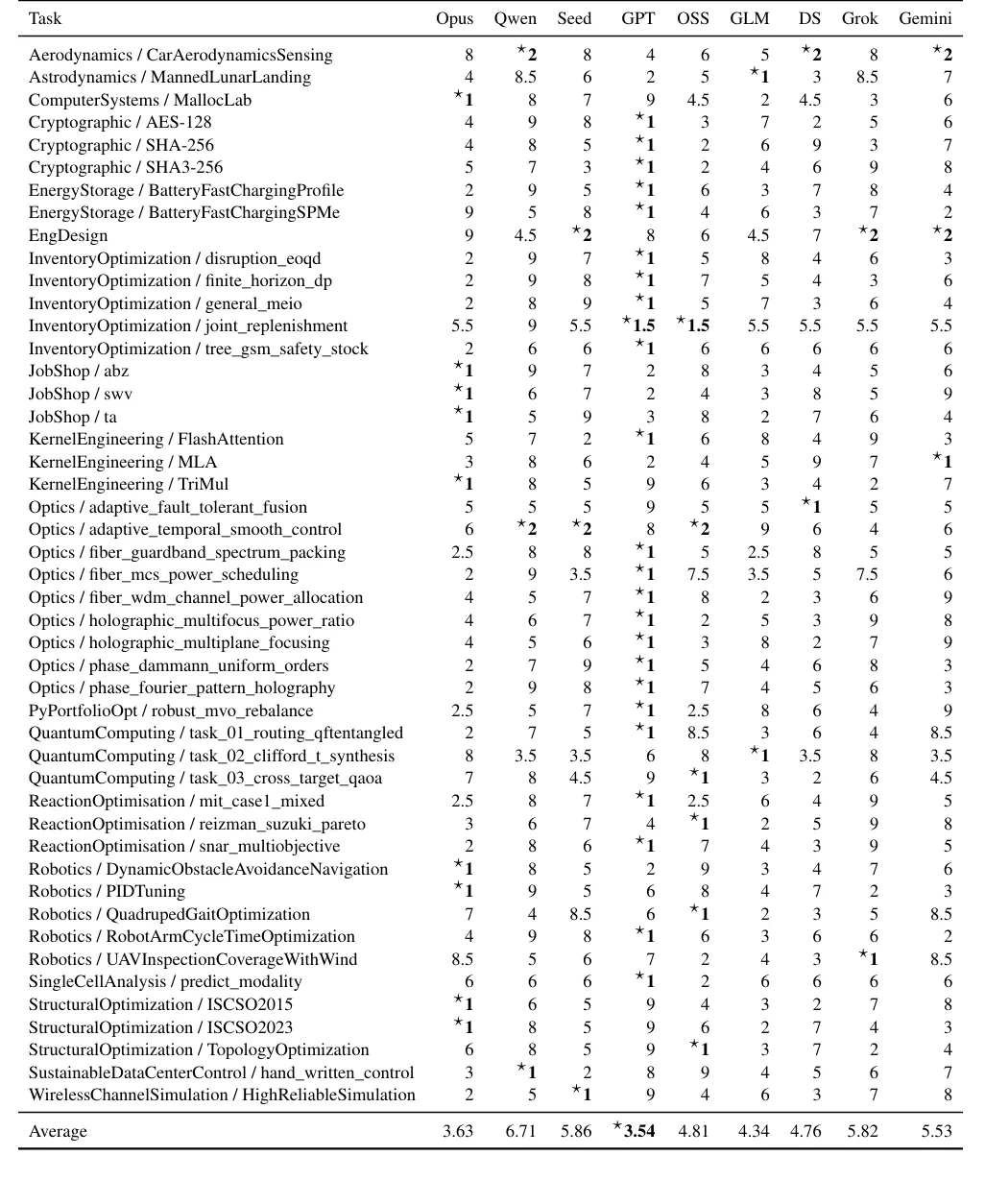
不同模型的详细评测结果
换句话说,未来真正重要的,可能不只是模型「知道什么」,而是它能否在长期环境反馈中持续优化、在复杂搜索空间里稳定收敛、在有限算力下完成递归推理、在真实仿真器中不断自我修正。
这会直接改变整个 Agent 基础设施的竞争方向。因为一旦智能开始更多地来自 inference-time optimization(推理时优化),而不是一次性的预训练,那么几件事将同时发生:
首先,AI for Science 可能将迎来真正的爆发。科学研究本身就是最完美的「生成式优化」场景——提出假设、实验验证、修正假设、再验证,这个循环和 Frontier-Eng 测试的过程几乎完全一致。
其次,Agent 的开发范式会从 prompt engineering 转向 reasoning architecture。开发者将不再仅仅盯着提示词的措辞,而是去思考如何构建更强的推理链、更高效的搜索策略、更智能的反思机制。
此外,长程记忆、工具调用、搜索和反思能力将变得越来越关键,而算力分配本身也会成为一种新的基础设施能力。
从这个角度看,Frontier-Eng 不只是一个学术 benchmark,它更像是一张路线图——告诉整个行业,下一阶段的竞争焦点在哪里。
尾声
回到开头那个问题:AI 做科研,最难替代人类的是哪个环节?
在读 Frontier-Eng 这篇论文之前,我的回答可能是「直觉」和「创造力」。但现在我觉得,答案可能正在被改写。
Frontier-Eng 告诉我们,Agent 正在走出文字游戏的「温室」,进入物理规律的「竞技场」。它们开始学习的,不再只是如何给出一个漂亮的答案,而是如何在成千上万次失败中,一点一点地抠出那 1% 的性能突破。
而身处其中,我们往往后知后觉。但把时间维度拉长,也许多年后回看,2025 年前后这段时间,正是 AI 从「聪明的回答者」变成「执着的优化者」的转折点。
不只有聚光灯下的 OpenAI、Google DeepMind 们在推动这个进程,更有像 Einsia AI 这样的团队,在用严谨的实验框架丈量智能的真实边界。
而下一代 Agent 真正比拼的,可能不再是谁「知道得多」,而是谁能在长期环境反馈中,持续逼近最优解。这场关于「深度」与「反馈」的竞赛,才刚刚鸣枪。
*头图来源: Frontier-Eng Bench
作者|Cynthia
编辑| 郑玄
商汤最近做了一件大多数大模型公司都不舍得做的事。
每 5 小时 1500 次免费调用,Token 消耗比同行低 60%,三款新产品同步上线,还把核心模型 U1 以 Apache 2.0 协议全面开源——在大模型公司普遍在想怎么收费的当下,商汤在反向操作。
免费从来不是目的。问题是,它图什么?答案,是一套从模型、工具链到生态锁定的三层护城河。
如果要给过去三年的大模型行业挑个刺,人肉胶水一定排得上号。
一方面,模型能力越来越强,编程、问答、推理、绘画,单点拿出来都是专家水平。但问题也跟着来了,这些 SOTA 级的能力,本质上还是一座座互不相通的孤岛。
在内容创作、设计创意、编程等工作中,AI 负责了最有创意的环节,却把图文整合、校对、排版、内容搬运这些脏活,留给了人类。技术提升带来的效率红利,有相当一部分被胶水成本吃掉了。
那么,能不能把完整方案生成变成模型内置能力?商汤的回答是:不光能,而且免费。
就在前几天,商汤一举推出了三个具备完整交付能力的产品与模型:
SenseNova 6.7 Flash-Lite :新一代多模态智能体模型,具备顶尖的 Agent 能力,为复杂数据分析与任务规划而生,能很好适配高频、高并发的生产级办公需求。
SenseNova U1 :基于自研的 NEO-unify 原生理解生成统一架构,首创连续图文创作输出,实现复杂信息图生成。
全线办公技能 SenseNova-Skills :支持海量数据分析、自动化办公等实战场景。
而伴随着产品上线,商汤还推出了 SenseNova Token Plan,赠送首月每 5 小时 1500 次免费调用额度 ,不可谓不豪横。
要理解这套打法背后的逻辑,先从护城河的第一层说起。
第一层护城河:做别人做不到的事
SeneNova U1:从「会画画」到「会思考再画画」,差距在哪里?
先聊几个数字。
U1 于 4 月 28 日正式发布,两个版本的模型权重(SenseNova-U1-8B-MoT 和 SenseNova-U1-A3B-MoT)均采用 Apache 2.0 协议开源,支持商业使用和本地部署。发布后迅速在 Hugging Face 收获大量开发者关注,成功冲进 Trending 榜前列。这个热度,在最近扎堆发布的开源多模态模型里,实属少见。
它凭什么?答案在架构里。
商汤 SenseNova U1 技术报告认为,多模态智能不应只是把视觉编码器、语言模型和图像生成器拼接起来,而应在同一表示空间中同时完成"看、读、想、画"。 这是 U1 系列模型的核心技术理念,也是 NEO-Unify 架构的出发点。
传统多模态模型的架构,是视觉编码器 (VE) + 变分自编码器 (VAE) 的组合——用 VE 做理解、用 VAE/扩散潜空间做生成。看图和画画是两套独立系统,模态转换过程会带来信息丢失,表示空间也是割裂的。
NEO-Unify 的做法截然不同:直接在像素 patch 与文本 token 上端到端建模,统一支持视觉理解、图像生成、图像编辑、交错图文生成等任务。理解和生成不再是上下游模块,而是同一上下文中的两种推理视角。
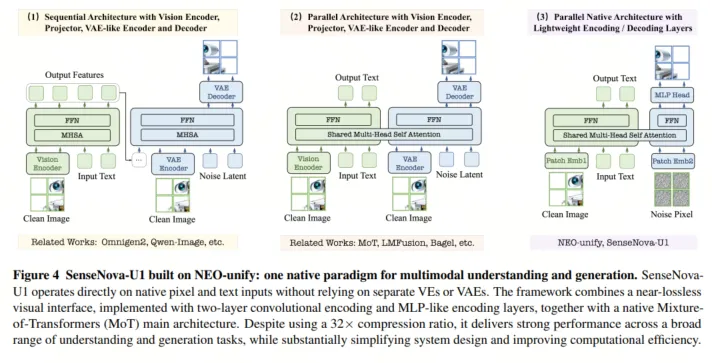
具体到架构设计上,NEO-Unify 同时解决了三组长期存在的矛盾:
第一,近无损视觉接口。 输入端不用 CLIP、SigLIP 等预训练视觉编码器,而用两层卷积加 GELU 将图像转为 token;输出端不用 VAE decoder,而用两层 MLP 直接预测原始像素 patch。表示空间由模型自身学习,既能承载高层语义,也保留生成所需的局部纹理、文字边缘和结构细节。
第二,分辨率自适应 flow matching。 动态分辨率会导致固定噪声先验在不同尺度下信噪比不一致,U1 引入分辨率自适应噪声尺度,使 256 到 2048 等不同分辨率下的像素空间生成更稳定。
第三,原生 Mixture-of-Transformers(MoT)。 理解流与生成流共享 self-attention 上下文,但 Q/K/V/O、LayerNorm、MLP 等参数解耦;文本、理解图像 token、生成图像 token 在每层交互,却保留各自表征专长。同时,三维 RoPE 把 token 放入时间、高度、宽度三轴坐标,从位置编码层面统一了语言顺序与二维结构。
这套机制的关键价值在于:MoT 的参数解耦加共享注意力上下文,能降低理解与生成之间的内在冲突。消融实验也证实了这一点——即使生成数据和理解数据共同训练,理解能力仍保持稳定,生成能力反而收敛更快。统一架构不是折中,而是带来了真正的跨能力协同。
这不只是架构描述, 有数据为证: 即便是 2B 参数量的 NEO-Unify 模型,在图像重建基准 MS COCO 2017 上,也达到了 31.56 PSNR、0.85 SSIM 的成绩,与公认的业界标杆 Flux VAE(32.65 PSNR、0.91 SSIM)差距不足 1 个百分点——而 Flux VAE 是一个专门为生成优化的独立组件,U1 是用一个统一架构顺带完成的。更值得关注的是,与同类统一模型 BAGEL 相比,NEO-Unify 在更少的训练 token 下取得了更好的表现,数据效率的优势相当显著。
实测效果如何?
技术报告显示,在基准测试中 SenseNova U1 展现出均衡且出色的能力谱系。多模态理解上,A3B-MoT 在 MMMU 达 80.55、MMMU-Pro 达 72.83,OCRBench 达 91.90,说明文本密集图像和通用视觉理解没有因统一生成而削弱。生成方面,GenEval 总分约 0.91-0.92,组合、计数、颜色、位置和属性绑定稳定;OneIG 英/中文文本维度最高达 0.969/0.977,LongText-Bench 英/中文达 0.979/0.962,长文本渲染能力尤为突出。
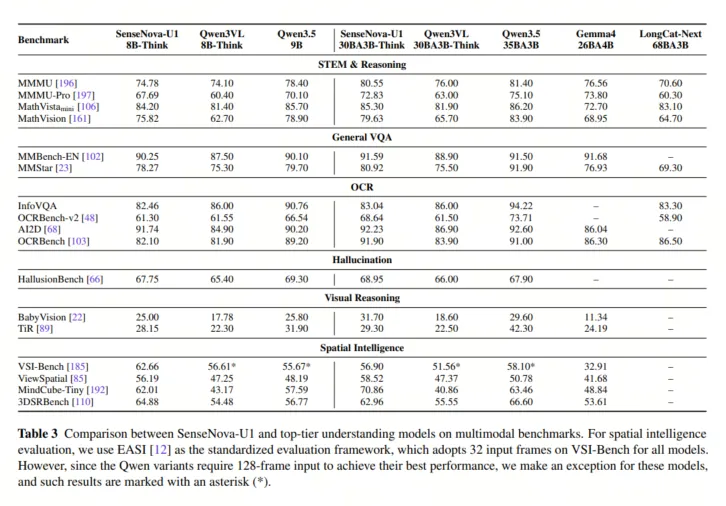
SenseNova-U1 与其他顶级多模态理解模型在多模态基准测试(Benchmarks)
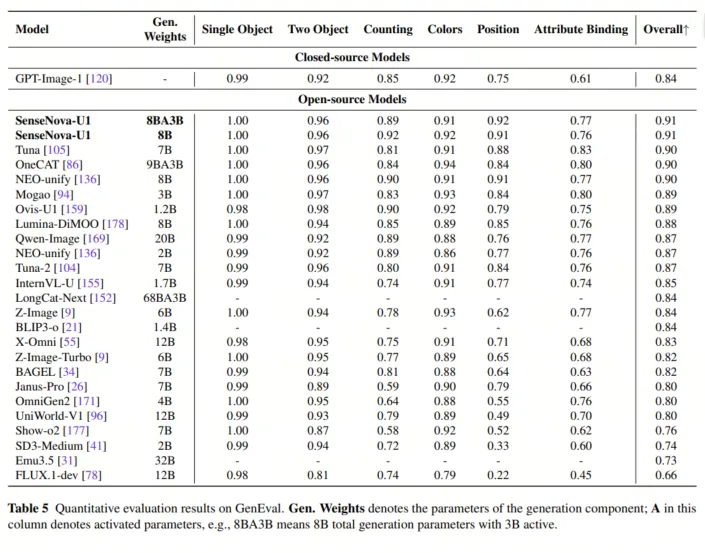
GenEval 上的定量评估结果
在图文交错生成(OneIG 中英文、LongText 中英文、CVTG)和信息图专项(BizGenEval Easy/Hard、IGenBench)的延迟-性能综合对比里,U1 在同等延迟区间内综合表现领先 Nano-Banana、Gemma-4 等主流开源模型,是目前开源模型里的 SOTA 水平。在与商业闭源模型的横向对比中,U1 Lite 在通用图像生成上的输出质量已与 Qwen-Image 2.0 Pro、Seedream 4.5 持平;在信息图这个历来是开源模型"滑铁卢"的领域,同样达到了商业级水准。
举个例子,输入「帮我生成一道做炒野生菌的教程」。完整的图文混排内容,就在十几秒时间里完整处理好了。它能在多轮推理过程中,边进行逻辑推导,写文字并输出食材、数量、配料、火候,动作对应的草图,再利用这些自行生成的视觉内容继续辅助后续推理,生成图文并茂的完整教程。

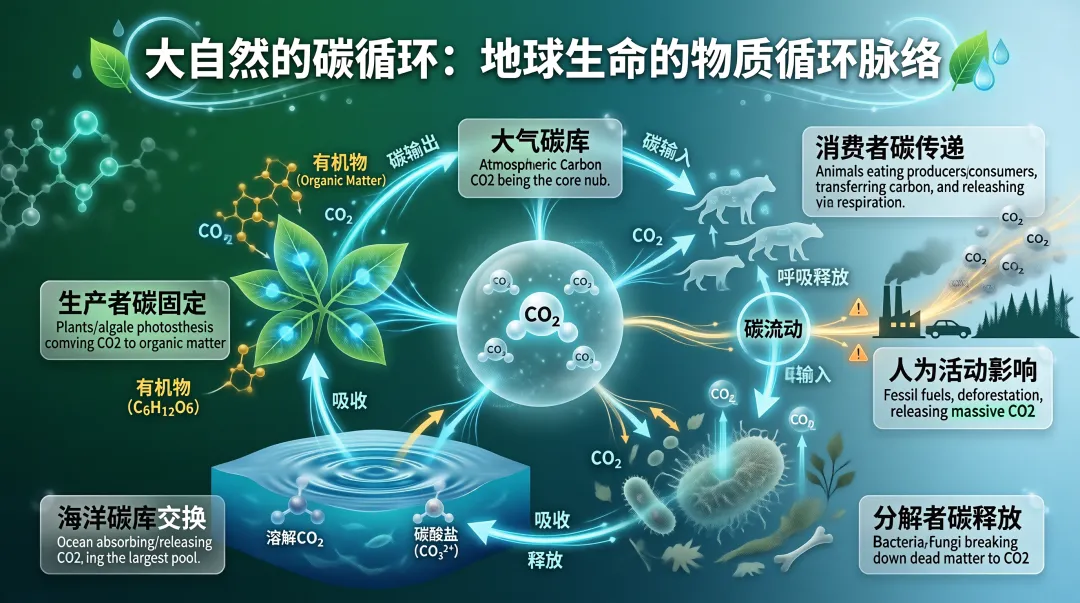
生成信息图也是一句话的事。比如,让它生成极简风的大自然碳循环图。整张图里的自然界碳循环逻辑完全正确,没有信息遗漏。在信息呈现上,以模块化区分不同功能模块,用符号化的视觉元素替代纯文字表述,既保留了有机物化学式、碳酸盐等专业细节,又通过自然系配色与具象化场景降低了大众认知门槛。从信息准确度、视觉层级、专业细节保留三个维度来看,是一张相当成熟的科普可视化作品。
过去,AI 无法做到的根本原因在于,类似的内容产出不仅是画得好,更需要排版美、信息准确、逻辑清晰、字体统一,是多个能力的综合考验。传统的分步生成再拼接模式,一个环节做到 90 分,连续经过五个环节,生成的就是一个只有 59 分的残次品。
U1 系列模型,通过将理解、推理、生成统一为一个整体,首次让 AI 交付一个及格线上的完整结果成为了可能。这正是去掉了创意端最厚的那层人肉胶水。
第二层护城河:低成本把人留住
SenseNova 6.7 Flash-Lite:当 AI 能真正看懂文档,工作流效率翻几倍?
U1 更像一个多才多艺的创作者,而 SenseNova 6.7 Flash-Lite 更像一个能管理全局的项目经理。
如果说 U1 解决的是创意端的闭环问题,那 SenseNova 6.7 Flash-Lite 解决的则是完整工作流的问题。它专门为真实世界工作流而生,能稳定支撑数据分析、深度调研、复杂图片理解、PPT 生成这些长链路办公任务。能力上,它原生支持 OpenClaw、Hermes Agent 等智能体框架,配合 SenseNova-Skills,可以一键开启全自动办公
传统智能体模型采用语言+视觉拼接设计,视觉只是文本的补充,无法深度参与核心决策与推理循环。信息在转译过程中受损,也会导致 Token 消耗虚高。
6.7 Flash-Lite 不一样。它能直接看懂复杂的网页布局、文档结构、财务图表,实现看、想、做一体化。借助这种真正的「看懂」,6.7 Flash-Lite 也做到了 Token 消耗直降 60%——在信息搜索等场景,对比纯文本智能体,这个节省幅度相当可观。
这正是第二层护城河的核心: 让用户用得更便宜,便宜到不值得换一个平台。
一个案例。给它一段 36 个月、近 90 万行销售记录的数据,让它完成完整的企业运营分析报告。
模型没有直接跳入统计,而是先进行数据审计,敏锐地察觉到单价中的异常离群值,判断这些极值对应了促销或高端单品场景,予以保留以反映真实市场波动。 这是模型主动发现的问题,而非用户指定分析方向——这才是真正的亮点所在。
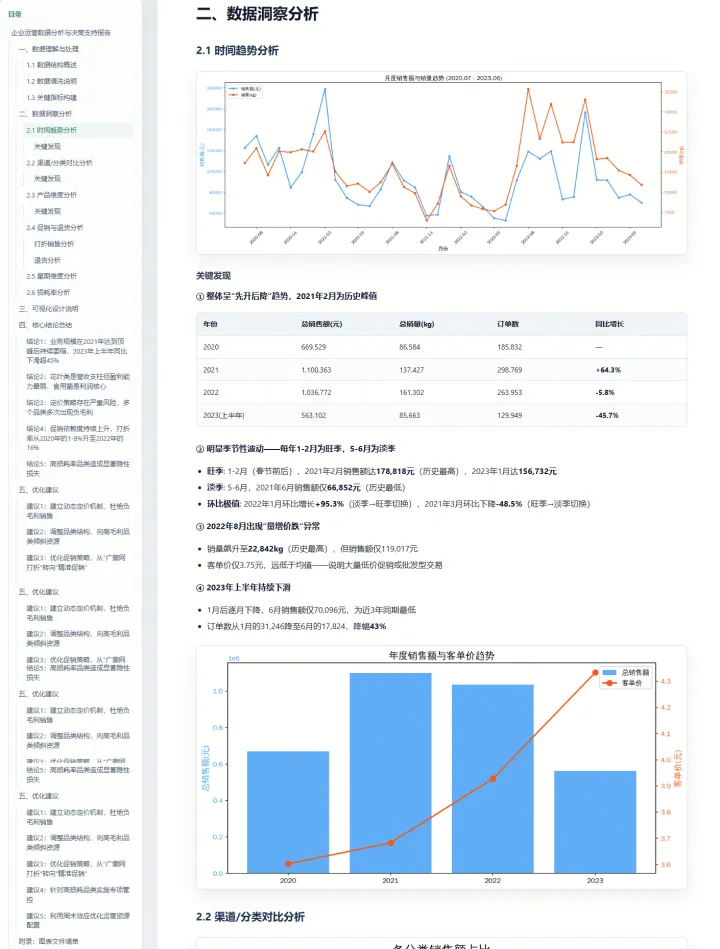
分析毛利时发现辣椒类 2022 年 5 月出现严重负毛利,进一步探寻供应链环节,诊断出采购成本控制与零售定价间缺乏联动机制的问题,并主动提出了五项精准建议:建立动态定价机制、调整品类结构等,直接辅助管理层决策。

当然,6.7 Flash-Lite 的能力远远不止是分析数据。
数据分析之外,6.7 Flash-Lite 还能直接生成 PPT。从叙事逻辑到版面设计全自动产出,风格统一、元素对齐,生成即交付。从数据分析到内容呈现,中间不再需要人来搬运——这正是去掉了交付端最后一层人肉胶水。
第三层护城河:工具链让人走不掉
大模型公司的竞争,已经从模型能力蔓延到了生态与场景。
当 GPT 和 Claude 的能力差距已经从代际碾压变成各有千秋,开源模型的能力已经不断逼近闭源 SOTA 水平,单靠模型性能已经很难形成持续的竞争优势。这时候,谁能让用户用得更省心、更便宜、更完整,谁就能在激烈的竞争中脱颖而出。
商汤的 SenseNova 体系,正是新规则下的代表性玩家。
要理解这套生态的锁定逻辑,可以借用一个经典的商业模型:剃须刀与刀片。
免费或低价提供剃须刀(模型和调用额度),通过持续消耗刀片(工具链使用量和规模化付费)来盈利。商汤的三层护城河,本质上都是在服务这一个飞轮。
模型差异化, 是让人愿意第一次进来。NEO-Unify 架构让 U1 在信息图生成、图文交错、多步推理上做出了真正的差异——技术报告中的消融实验也证实,这种统一不是能力折中,而是带来了理解与生成的双向协同增益,是竞争对手短期内难以复制的技术壁垒。
低成本 Token 输出, 是让人不舍得走。首月每 5 小时 1500 次的免费额度,加上长期比同行低 60% 的 Token 消耗,把试错成本压到最低。Apache 2.0 的开源协议,进一步消除了开发者进入的心理门槛。
值得一提的是,U1 的推理系统并非停留在论文结构:LightLLM 负责多模态理解与请求调度,LightX2V 负责图像生成,两者通过共享内存和优化传输 kernel 交换状态,FlashAttention3 后端在统一多模态 prefill 中相比 Triton 有约 2.3 到 3.2 倍的加速——正是这套可服务、可扩展的基础设施,才撑起了低成本大规模商用的底气。
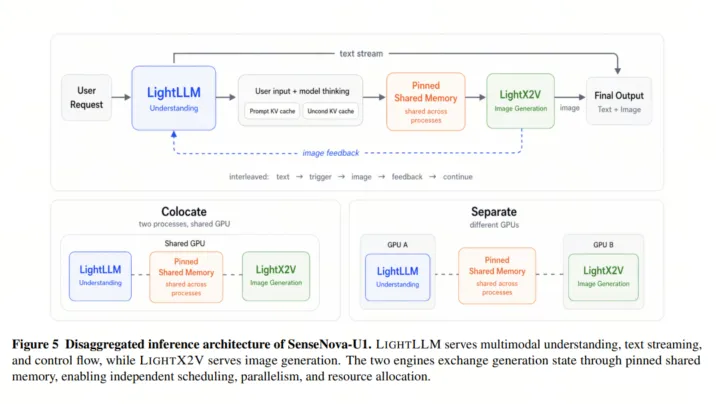
工具链的完整性, 是让人真的走不掉。商汤的生态不只有模型,还包括:
SenseNova-Skills:覆盖信息图生成、PPT 创作、数据分析、深度调研等高频办公场景
Agent Pack:集成了 Hermes Agent 和 OpenClaw 框架的一键部署包
结合起来,当开发者因为低成本开始尝试商汤的工具链,会逐渐被工具链以及交付产品的完整性所吸引;当他们习惯了整套工作流的协作效率,换平台的迁移成本就会变得极高;当这种使用习惯扩散到整个团队,商汤就拥有了用户粘性带来的持续付费。
这套闭环一旦形成,就会在开发者生态中产生网络效应:用的人越多,贡献的反馈和案例越多,模型迭代的方向就越精准,工具链的打磨就越完善,Token Plan 的成本摊薄效应就越明显。
当然,这一飞轮要真正转起来,前提是商汤能在竞争激烈的窗口期内迅速积累足够的用户基数。DeepSeek、Qwen、InternVL 们都在同一条赛道上全力冲刺,这场仗远没有结束。
但至少眼下,商汤给出了一个值得认真对待的答案:用一套从架构创新(NEO-Unify)到工具闭环(SenseNova-Skills)再到成本优势(Token Plan)的完整体系,把"去人肉胶水"从一句口号,变成了可交付的产品。
技术报告的结论说得直接: 多模态智能的未来突破,并不只是简单的规模扩大,更重要的是朝着深度融合进化的内核架构创新。这句话,也许正是商汤这盘棋真正的谜底。
对于开发者和企业来说,现在正是低成本进入这套生态、验证其价值的最佳窗口期。
大模型的竞争里,技术领先只是起点,生态锁定才是终点。
SenseNova U1:
https://github.com/OpenSenseNova/SenseNova-U1/
SenseNova-Skills:
https://github.com/OpenSenseNova/SenseNova-Skills
TokenPlan 免费领取:
https://sensenova.sensetime.com/
*头图来源:商汤科技
本文为极客公园原创文章,转载请联系极客君微信 geekparkGO
作者|Cynthia
编辑| 郑玄
有没有发现,去韩国玩的人,不管是旅游还是留学还是出差,只要待的时间稍微一长,几乎都会被朋友拉着去做一个叫色彩测试的东西。
就是你排队两个月,有人拿着色卡在你脸上比划半天,然后告诉你,你是春、夏、秋、冬里的哪一型,你的肤色适合什么色系,你的五官适合什么饱和度,你的日常穿搭应该避开什么材质。
然后,温暖的色彩,就会化身冰冷的几千元,转账到商家的账户,而你回家后打开衣柜,才发现原来自己过去这么多年前,其实从来不会买衣服。
这个生意为什么会爆火?
本质在于购物这件事,其实是一个需要专业技能的技术活。哪怕网上商品有千万种 SKU,哪怕算法推荐越来越精准,但找到适合自己的那一件的门槛,比大多数人的想象要高得多。
就像健身需要私教、学习需要老师,而购物需要「李佳琦」。
而当万物皆可 skill 的时代到来,AI 当然也能把「购物」这个专业技能封装,供所有「想买但说不清楚买什么」的消费者随时调用。
昨天 淘宝与千问的 打通 , 本质上就是完成了这件事。打通后, 用户可以直接在千问 App 里逛淘宝、选商品、下单 。
这是 AI 购物第一次完成闭环, 这场迁徙背后的逻辑,远比换个地方下单要深刻的多。
买对东西,为什么这么难?
对一个选择困难症来说,每次买东西,都是一场精神与钱包的双重折磨:
打开购物平台搜索 「 黑色连衣裙 」 ,能跳出超过两万件商品;搜索 「 保湿面霜 」 ,超过 200 个品牌至少 2000 个产品排队等待翻牌。
但万里挑一之后,为什么买到一个最合适的东西,依然很难?
原因很简单,当我们在购物的时候,我们只部分知道自己要什么,却不知道自己不知道什么,这几乎是人类购物史上永恒的困境。
对女生买衣服来说。绝大多数消费者并不具备专业的服装知识。不知道韩版和欧美版的版型差异意味着什么,不了解天丝和莫代尔的手感区别,不清楚自己到底是什么体型、适合什么剪裁。
而对男生来说,520 即将到来,想送一件让女朋友感动哭了的礼物,在电商平台直接搜索,得到的结果,大概是送命题。

这就是不知道自己不知道的典型场景。
类似的困境其实弥漫在消费世界的每一个角落:
书籍领域:想买本哲学入门,到底该选《苏菲的世界》还是《大问题》?电子产品:想买一台相机,面对 「 全画幅 」 「 APS-C 」 「 M43 」 各种规格,到底哪个适合自己?护肤品:同样是保湿,精华液、乳液、面霜到底该怎么搭配?
因此,过去消费者想要选到最合适自己的那一款,就得反复在线上挑选、退货、加购物车。
线下商业部分的解决了这一问题。我们不难发现那些活得 最好的实体店,无一例外,全都活成了精品商品+专家级导购的样子 ,顶级美妆店配备经验丰富的彩妆师,帮用户选到最合适的美妆,风靡一时的色彩测试,本质上也是在帮助用户搞清楚我想要什么、适合什么。
那么问题来了, 这对社恐,以及没空去实体店逛街的人来说,难度实在过于地狱;线下的导购也非全知全能,再专业的导购,也记不清品牌推出过的所有商品。
这也是为什么,我相信 AI 一定会成为全新的购物入口。
实测千问购物:24 小时在线的专家导购
治好了我们全家的购物无能
之所以尝试在千问中买东西,是因为直到最近,我才意识到,购物是一件需要天赋的事情,而多数人(包括我)在这方面堪比绝望的文盲。
人类永远无法直视自己半年前的淘宝购物历史,就像 90 后永远不会当众朗读自己初中在 qq 空间写下的火星文。
我的朋友,曾在淘宝直播间冲动购物买过一罐来自大草原的空气;而我,也曾蹲在暗无天日的出租屋,一口气买下三盆太阳花后,疯狂搜索教程,太阳花没有太阳怎么开花?
所以, 深度体验了千问的购物功能并把它推荐给身边所有人后,我最深的感受就是,这和把审美最好、懂我喜好、最懂性价比、脾气最好的购物小天才朋友 24 小时带在身边有什么区别?
还是以买一个黑色显瘦连衣裙为例。过去搜索完黑色显瘦连衣裙,网页会跳出上万个链接,每一个模特图都足够精美,但买回来到底适不适合我,全靠运气。
而在千问,AI 会这样工作:
首先,它会主动了解你的基本信息:你的体型是什么?(梨形、苹果型、H 型……)你的肤色如何?平时的穿着偏好?如果是梨形身材,上衣应该选择领口有设计感、下摆略微收紧的款式,来平衡视觉重心。如果是苹果型身材,应该选择 V 领或大圆领、腰部有适当余量的上衣,避免紧身款勒出腹部线条。如果是 H 型身材,可以尝试有收腰设计或腰带装饰的款式,制造曲线感。
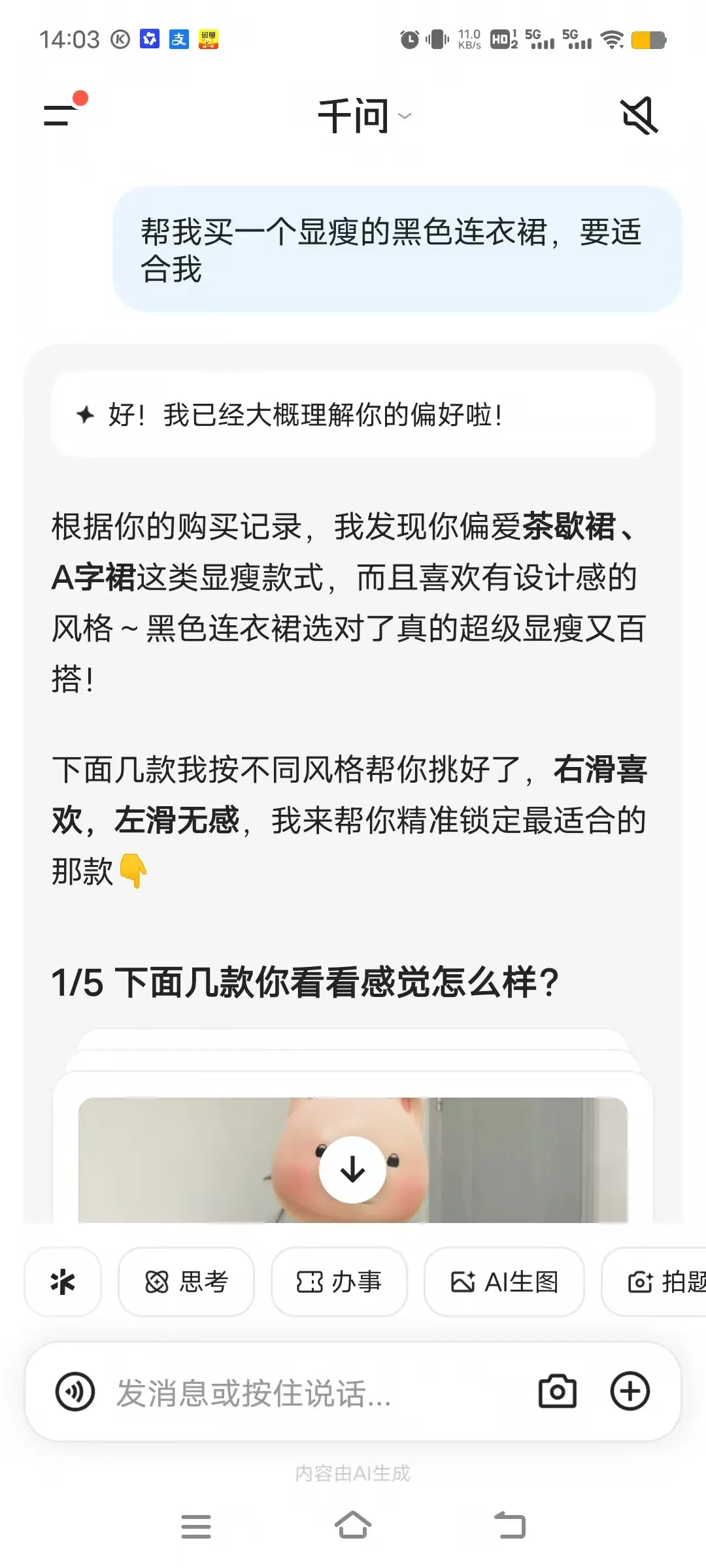
最后,在综合我的历史购物偏好、浏览记录后,千问还会先通过几次问答彻底了解了我的审美以及个人特点后,才给出精准推荐,并且每款都附带为什么适合的详细解释。整个过程,就像在线下店遇到了一位既专业又有耐心的导购。
除了买衣服,买书籍这样的专业产品也是同理。前段时间我突然对荷马史诗很感兴趣,但这本书的阅读难度着实不低。诸多版本怎么选择,要读原版还是译本?朱生豪和杨宪益的译本有什么区别?入门读者选哪个版本更容易上手?想深入研究,哪个版本的注释更详尽?
这些信息在传统电商平台上碎片化地散落着,过去需要翻阅大量书评、对比不同版本、甚至多次踩坑才能拼凑出答案。

但在千问,它会告诉我:如果你英文水平较好,AI 推荐你尝试英文原版(推荐 Penguin Classics 或 Oxford World's Classics 版本)如果你英文阅读有挑战,初学者推荐杨宪益译本(语言流畅、结构清晰),进阶读者可以选朱生豪译本(文学性强、注释详尽)。
当然,周围一圈人中,用千问购物受益的,其实是老家被村口送鸡蛋神医忽悠,差点上头买了治高血压枕头的外公。
在千问中输入「买治高血压枕头」后,他得到的反馈是这样的:

是的, 一个好的购物应用,不只会告诉用户你适合什么,还应该能提醒用户,什么是不合适的。 千问不仅拒绝了老年人买治高血压的枕头的要求,还给出了科普:枕头不治高血压,但选择合适的枕头确实可以改善睡眠质量、间接有助于血压管理。
而且,千问中购物,除了能帮助我们选择商品,还能通过对话直接领券下单、匹配国补、推荐有运费险的商品;想知道物流进度,也能直接对话查询;AI 甚至还能基于历史订单给我们做复购推荐。
过去, 查物流、领券这些看似简单的查询,对年轻人来说虽然繁琐,但尚在接受范围之内;但对很多不熟悉操作的老年人来说,这种极简化操作,几乎是打开了他们电商购物的大门。
AI 为什么一定会成为新的购物入口
其实,把视野拉大到整个商业史, 我们不难发现购物入口的变迁,一直都遵循着一条清晰的脉络:每一次技术革命,都在重新定义效率的含义。
最早,我们在集市、百货、超市购物,用双脚丈量商品。 逛街是一种身体行为,你必须亲临现场,信息获取的效率,取决于你能走多远的路、逛多长的时间 。而在这个过程中,怎么比价、怎么谈价,都需要耗费大量的时间与精力成本。
在此之后,搜索引擎入口出现,我们可以用手动搜索输入替代脚步丈量。信息获取的效率随之大幅提升,但前提是你知道买什么, 搜索引擎只能处理明确需求,面对模糊需求,它束手无策 。
针对这个困难,算法推荐随之登场,借助短视频电商、内容种草,我们看了一条短视频,下单了一件同款;读了一篇种草笔记,冲动购入了一件爆品。这是一种先有需求、再刺激需求的模式,本质上是把购物变成了一种娱乐体验。但 商品到底买的对不对,适不适合,依然只是基于简单标签的匹配,无法解决根源问题。
对话式 AI 入口的出现,解决了以上的所有瑕疵。人类开始回归自然语言定义需求的模式: 「 我下周要参加一个正式商务晚宴,需要一套低调但有质感的穿搭,预算 2000 以内 」 这些包含了大量的隐性信息,搜索引擎、标签推荐根本无法处理的问题,通过 AI 可以理解、分析、转化,并给出精准推荐。
在这个过程中, 我们收获的是线下式的专业服务、搜索引擎式的海量选择、推荐算法式匹配以及一站式服务。
而更长期来看,当越来越多人开始用 AI 购物,当数据积累越来越丰富,这个体验也会越来越好, 而我们这代人,或许从现在起,又要学会一套新的购物方式了。
*头图来源:视觉中国
本文为极客公园原创文章,转载请联系极客君微信 geekparkGO
副标题:韧性全球化,AI向未来|EqualOcean2026出海全球化百人论坛(GGF2026)将于6月11日在上海举行
出海这件事,已经变了。
如果今天还把出海理解为“寻找增量市场”,大概率已经慢了一步。
如今,中国企业出海已经进入一个全新的阶段。真正拉开差距的,早已不是“是否出海”,而是:
· 下一阶段最值得重仓的区域市场在哪里?
· AI应该优先进入哪些关键环节,才能形成真正差异化?
· 在资本趋于理性、增长更重质量的背景下,什么样的公司还具备穿越周期的可能性?
· 对于具身智能、自动驾驶、AI硬件等新技术企业而言,如何跨越从技术验证到场景落地、从产品展示到规模商业化的关键门槛?
这些问题,没有标准答案,但每一家出海企业都必须面对。
也正因此,由出海全球化智库EqualOcean主办的2026出海全球化百人论坛(2026 GoGlobal Forum of 100,GGF2026)将于2026年6月11日在上海举行。
论坛将以“韧性全球化 AI向未来”为主题,希望把这场论坛做成一个真正面向现实问题的对话现场:既不回避全球化的新难题,也不空谈技术风口;既讨论趋势判断,也讨论落地路径;既交流“怎么看出海”,也探讨“怎么做出海”。
1. 为什么是“韧性全球化,AI向未来”
本届论坛将主题定为“韧性全球化 AI向未来”,是因为今天中国企业全球化的核心命题,正在发生明显变化。
一方面,全球化正在从“寻找增量”走向“深度经营”。真正决定企业能否走得远的,已经不只是进入市场的速度,而是能否在区域分化、供应链重组、合规门槛提高的环境中,保持经营稳定、组织协同和长期投入。“韧性全球化”强调的,正是企业在复杂环境中的持续经营能力。
另一方面,AI对企业全球化的影响,也正在从局部提效走向系统重构。它不仅改变产品、营销、组织和供应链,也正在从数字世界延伸到物理世界。以人形机器人、自动驾驶为代表的具身智能,正在推动全球化竞争从“效率提升”走向“技术能力、场景落地与商业化能力”的综合比拼。
也正因此,GGF2026想讨论的,不只是企业“有没有用AI”,而是:AI能否成为下一代全球化企业的核心能力?在市场分化与红利变化之下,企业又该如何重构品牌、组织与本地经营体系?
“韧性全球化”讨论的是企业如何在复杂世界中稳住经营、穿越周期;“AI向未来”讨论的,则是企业如何借助新技术建立下一阶段的全球竞争力。把这两个关键词放在一起,正是因为它们共同指向了2026年中国企业全球化最真实的命题。
1. GGF2026议程前瞻
GGF2026将于6月11日在上海举行,论坛为期一天,围绕趋势判断、区域机会、AI应用、品牌建设、组织能力、硬科技出海与内容创新等核心话题展开。具体议程以最终发布版本为准。
上午场:研判全局・解码全球化底层趋势
论坛的上午场将从宏观环境与趋势判断切入,讨论在全球竞争新周期下,中国企业应该如何重新理解出海。主办方EqualOcean将带来题为《未来全球竞争的核心:AI能力、韧性布局与长期主义》的致辞,系统回应本届论坛主题,并提出对下一阶段全球化竞争格局的判断。
随后,多场主题演讲将围绕以下议题展开:
· 《AI原生企业的全球化加速度》探讨AI原生企业如何借助技术优势、组织效率与产品迭代能力,更快进入全球市场。
· 《红利消失后,谁还能留在全球市场》回到企业最现实的挑战:当粗放扩张失效,什么样的企业还能持续经营、持续增长、持续建立全球竞争力。
· 《寻找增量:新兴市场韧性与AI驱动》从新兴市场视角出发,讨论区域增长的新变量,以及AI如何帮助企业提升进入效率与经营质量。
上午的主题演讲后,还将设置一场主题为《未来已来:AI时代的出海新范式》的圆桌讨论,届时,来自企业、投资、服务生态等不同背景的嘉宾将围绕 AI、组织、本地化、品牌和区域布局等关键议题展开碰撞。
圆桌讨论结束后,现场还将设置面向观众的“快问快答”互动交流环节,圆桌嘉宾将会预留5-10分钟面向观众开放提问。无论是围绕嘉宾发言观点的追问、还是来自一线实践中的真实困惑,都有机会在这一环节中与大佬讨论、交流,让现场讨论更具参与感与启发性。
GGF2025活动现场
特别环节:AI出海创业项目路演
除主题讨论外,GGF2026还将设置AI出海创业项目路演特别环节,面向全球征集优质AI出海创新项目。经评审筛选后,入围项目将在现场进行路演展示,并获得投资人点评与精准投融资对接机会。
我们希望通过这一环节,让更多具备技术潜力、产品想象力与全球化野心的新一代创业项目,在真实产业语境中被看见、被连接、被验证,也让创新者、投资人和产业资源在同一个现场形成更高效的互动。
AI路演项目申报通道现已开启,欢迎专初创AI企业扫描下方二维码填写申报表:
下午场:落地实操・拆解出海全链路打法
如果说上午场更多回答的是“方向在哪里”,那么下午场将更进一步,聚焦企业“到底该怎么做”。下午议程将从区域布局、全链路效率、AI基础设施、品牌与组织建设、硬科技出海以及内容创新等多个层面,拆解企业全球化的落地路径。
重点议题包括:
· 《2026重点出海区域:欧美、中东与新兴市场的机会分化》
· 《从工具到生态:AI如何重构出海全链路》
· 《AI+x:中国企业全球化的新基础设施》
· 《AI出海的长期主义:技术壁垒、品牌建设与本地化运营》
· 《破局“硬”科技出海:具身智能与AI硬件的场景商业化与供应链韧性》
· 《AI漫剧:下一波出海爆款从哪来》
下午压轴圆桌的主题为《AI时代的全球化核心竞争力》。讨论将围绕几个极具现实意义的问题展开:
· AI是降本工具,还是战略基础设施?
· 从“卖产品”到“做品牌”,AI如何重塑全球品牌能力?
· 在资本理性期,什么样的全球化公司具备穿越周期的韧性?
· 组织、人才与本土化能力,如何成为企业真正的护城河?
1. GGF2026,不只是一场论坛
今天的企业参加一场论坛,已经不只是为了“获取信息”。大家更关心的是,能不能在这里听到足够新的判断,碰到足够关键的人,找到真正有价值的合作机会,看到值得参考的全球化样本。GGF2026希望提供的,正是这样一个兼具趋势判断、产业链接与合作触发的现场。
这里会有对全球市场变化的研究视角,会有对AI如何进入企业出海全链路的实战拆解,会有来自品牌、科技、硬件、内容、服务生态等不同角色的经验碰撞,也会有项目路演、榜单发布与更多高质量交流场景,共同构成一次更完整的全球化行业会面。
对于正在全球化路上的企业而言,这不仅是一场会,更可能是一次重新识别方向、更新认知、链接合作的关键节点。
GGF2025颁奖晚宴
1. 晚间重磅:年度榜单发布
在晚宴环节,将举行EqualOcean出海全球化系列年度榜单发布环节。
我们希望通过榜单,识别这个时代最具代表性的全球化参与者:那些真正理解区域差异、具备本地经营能力、能够将AI转化为新竞争力,并在复杂环境中保持长期投入与韧性的企业和机构。
榜单既是对优秀样本的阶段性呈现,也是对中国企业全球化新趋势的一次集中观察。相关征集通道也将同步开启,欢迎企业与机构积极参与。
榜单申报通道现已开启,欢迎专注于出海全球化的企业/机构扫描下方二维码填写申报表:
拟发布年度榜单(以活动现场发布为准):
EqualOcean出海全球化品牌榜单
2026中国AI应用全球化品牌TOP10
2026中国出行科技全球化品牌TOP10
2026中国智能设备全球化品牌TOP10
2026中国数字内容与娱乐全球化品牌TOP10
2026中国医疗科技全球化品牌TOP10
2026中国智能家居全球化品牌TOP10
2026中国实体零售全球化品牌TOP10
EqualOcean出海全球化服务商榜单
2026出海全球化金融科技机构TOP10
2026出海全球化品牌营销机构TOP10
2026出海全球化人才服务机构TOP10
2026出海全球化合规服务机构TOP10
EqualOcean出海全球化投资机构榜单
2026出海全球化投资机构TOP20
EqualOcean出海ESG典范企业榜单
2026中国出海ESG典范企业TOP20
2. GGF2026大会报名通道
如果你正在重新判断企业的全球化路径;如果你关心AI将如何改变出海的产品、品牌与组织逻辑;如果你希望与更多企业家、投资人、服务生态和创新项目建立连接;如果你相信下一个阶段的全球化竞争,比的已经不只是速度,而是韧性、系统能力与长期主义——欢迎来到 GGF2026。
GGF2026大会报名通道现已开启,欢迎扫描下方二维码报名。
3. GGF合作&咨询
关于我们
EqualOcean是一家专注于服务中国企业出海全球化、帮助海外公司或机构把握中国发展机遇的新型智库与核心资源链接者。
以"连接中国与世界为使命",我们的核心优势是拥有业内最强的团队、连接官方和民间、打通科技互联网和"传统行业"、具有全球化视野和全球资源网络。








