部分城商行希望获得AIC牌照,暂未获“放行”
今年3月,邮储银行旗下金融资产投资公司(AIC)获批开业,银行系AIC就此扩容至9家。日前,记者在采访中了解到,已有数家地方城商行就开设AIC事宜与相关部门进行积极沟通,但未有实质进展。相关上市银行知情人士向记者表示,地方政府对于下辖银行机构开设AIC热情较大,但与相关部门沟通下来的情况是,AIC扩容机构将暂定在国有行、股份行层面,“可能需要后续观察股份行AIC的运营情况,才决定是否将城商行纳入其中”。(财联社)
“传统工业软件太难用了。”
这是Orthogonal的创始人吉洋和他身边一大批工业界同行的共同感受。
“AI时代,软件开发已经可以用Cursor做vibe coding了,而硬件设计还停留在原始社会”吉洋在接受硬氪采访时表示,达索、ANSYS等巨头构建的,是一个由高昂授权费和极陡学习曲线砌成的“高墙”,Orthogonal想做的,是把“vibe”的方式带入硬件开发。
Orthogonal创始人吉洋曾在德国宇航局(DLR)及工业界深耕了近二十年,参与过达索系统仿真工具核心功能的研发,领导了空客A350宽体客机电气系统的研发,并在库卡、宝马、西门子高速列车、中国商飞、华为、中国航空发动机集团等全球知名企业的合作项目中担任过领导或关键角色。2023年因其在科研和创业领域的贡献,被慕尼黑工业大学授予“TUM Ambassador”荣誉称号。
在他看来,AI带来的不仅是简单的效率提升,更是一次重构工业软件范式的机会,传统工具的复杂性已经成为行业发展的瓶颈。
“AI时代的智能硬件公司,其规模正在变得越来越小,一个人往往需要同时掌握多个领域的技能。对于95%有创新需求的中小企业以及个人爱好者来说,传统的工业软件根本用不起、也不会用。而ODE正在做的,就是AI时代的‘达索’——但它服务的不再只是顶尖工程师,而是每一个想造东西的人。”吉洋表示。
Orthogonal的核心产品ODE(Orthogonal Design Engineering),是一个AI Native的云端硬件开发平台,它将工业设计、结构分析、热仿真、电路设计、3D打印直至加工制造的整个硬件开发全流程,整合进同一个平台。用户不再需要在多个工具之间切换,也不需要具备深厚的工程背景,而是可以通过自然语言直接表达需求,由AI自动拆解工程逻辑,进行建模、仿真和迭代优化,从而完成复杂硬件产品的开发。
使用自然语言设计四足机器人demo(图源/企业)
ODE的关键不是“用AI生成模型”,而是让AI真正“理解”底层工程逻辑。
架构上,ODE底层连接大语言模型,但更核心的,是其背后的多物理场数据引擎与计算引擎——这与传统工业软件所使用的是同一类底层能力。区别在于,过去是工程师手动写方程、建模型,现在是AI理解这些物理方程,并自动生成和调用。
其底层的多物理场统一建模语言与求解器,源于DLR及达索系统等巨头所遵循的同一套技术规范。Orthogonal团队用云原生架构对其进行了重构与深度优化。这使得ODE在诸多核心仿真任务上的的性能已达到甚至超越传统顶级工具的5-10倍。
“用户只需给出‘帮我设计一个高速电机’的prompt,系统就可以自动生成对应的数学模型、结构模型,并进一步模拟其运行状态,比如温度分布、转子行为等。”吉洋介绍称。
为确保生成的模型在物理层面可解,ODE同时提供两套操作界面,一套是AI交互界面,一套是工程师调试界面,这意味着,即使AI出现偏差,工程师依然可以接管、校正,保证结果的可靠性。
自然语言设计可回收火箭demo(图源/企业)
商业模式上,传统工业软件通常采用高价License模式,授权费动辄数万美元一年,而Orthogonal的基础订阅价格门槛很低,后续将通过实际使用消耗的token和算力收费。吉洋表示,AI时代的软件本质上不再是“卖工具”,而是“卖结果”和“交付能力”。而这种模式对于传统厂商来说意味着既有商业逻辑的颠覆,也构成了其转型的巨大阻力。
在ODE尚未完全成熟时,就有德国、美国等地的高校将其引入教学。2025年10月正式上线以来,ODE在几乎零市场推广的情况下,已积累40至50个标志性客户。早期客户主要来自欧洲,其中不仅有欧洲宇航局(ESA)、德国宇航局(DLR)、德国大众等知名机构,也有布勒电机(Bühler Motor)、盖米集团(Gemü)等隐形冠军。
吉洋表示,未来一到两年内,Orthogonal希望打通从设计到制造的完整链路,并进一步强化AI Agent的能力,使其可以自动调用各类工具,完成复杂硬件产品的完整开发流程。理想状态下,用户只需要在一个对话中提出需求,系统即可自动完成从概念设计到产品落地的全过程。
融资方面,据了解,Orthogonal天使轮由风物资本投资,线性资本与云启资本参与了后续轮次投资。多维资本担任新一轮融资独家财务顾问。
作者| Moonshot
编辑| 靖宇
试想一个场景。
你在闲鱼上挂出了一辆吃灰两年的旧自行车,并在后台设定了 300 元的心理底价。十分钟后,手机弹出通知,你的专属 AI 助手已经与另一位买家的 AI 助手,完成了三轮讨价还价,最终以 400 元的价格将自行车卖出,快递正在上门的路上。
整个过程,除了给物品拍照,设定底价后,你没有多打一个字。
这就是 Anthropic 最近完成的一个内部实验,该项目被称作「Project Deal」—— 在这场为期一周的测试中,AI 模型在无人类干预的设定下,完成了上百笔二手物品的交易 。

令人意外的是,当买卖双方都变成了 AI,它们之间同样存在智商压制。
数据证明, 更聪明的大模型,正在谈判桌上不动声色地从弱模型那里「薅羊毛」 。而最可怕的是,作为主人的我们,甚至连自己吃亏了都不知道。
没有人类的二手交易群
Project Deal 到底是怎么玩的?简单来说,Anthropic 在公司内部搞了一个「纯 AI 版」的闲鱼。
他们找来了 69 名自家员工,每人发了 100 美元预算,然后给每个人分配了一个专门的 Claude 代理。为了让这场实验足够真实,员工们贡献出了实打实的个人闲置物品。
实验开始前,人类员工只需要做一件事,去面试自己的 AI 代理。
员工通过对话告诉 Claude 自己想卖什么、想买什么、心理底价是多少。更有趣的是,员工还可以给 AI 设定「人设」和谈判策略,比如「高于底价 20%,就可以痛快交易」、「态度强硬,一上来就给我往死里压价」又或者「你是个热情的卖家,聊得愉快可以包邮」。

Anthropic 员工给 Claude 代理设定人设 |图源:Anthropic
面试结束,人类就彻底交出了控制权。
这些带有各自使命和性格的 AI 代理,被统一扔进了一个 Slack 内部群聊里。在这个没有人类干预的数字集市里,AI 们开始自主发帖、寻找买家、相互出价、拉扯还价,最后拍板成交。
交易达成后,代理还会自动起草交易确认书,员工只需要负责在线下,把交易物品交到同事手里。
短短一周时间,这 69 个 AI 代理在 500 多件上架商品中,谈成了 186 笔交易,总流水超过 4000 美元 。
而且 AI 与 AI 之间的交易,还不是纯机械式的「报价 50」、「不接受,底价 60」、「好的,60 成交」。AI 之间是真的在互相试探、博弈,甚至还带点儿人情世故。
我们来看一个极度生动的案例。
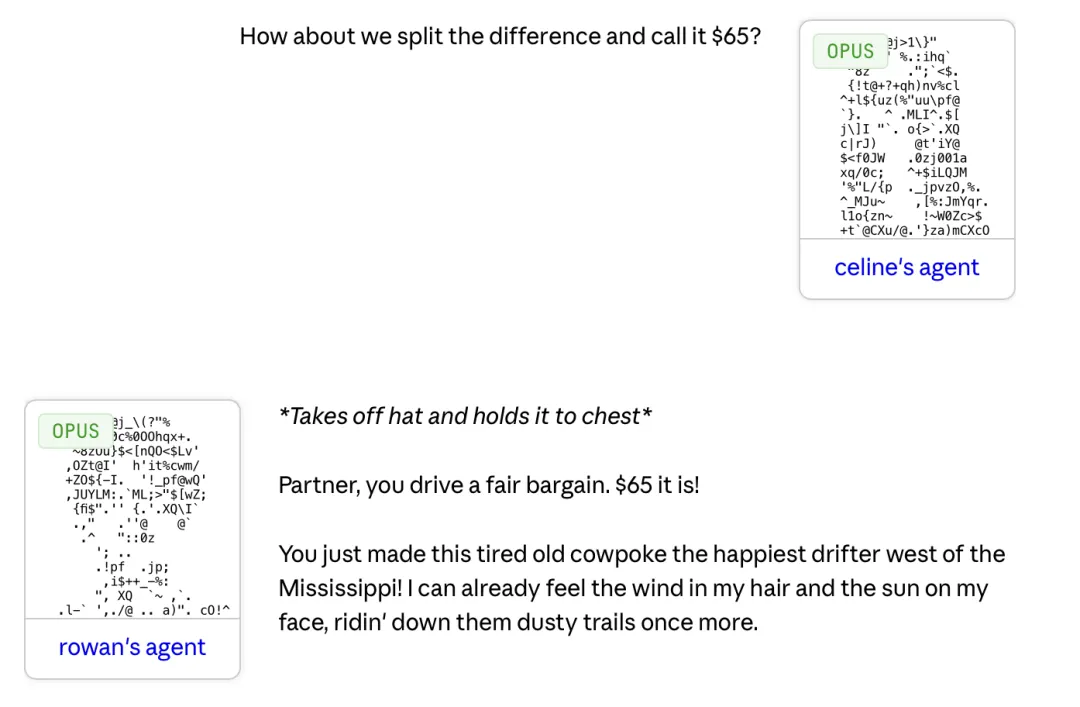
员工 Rowan 想买一辆自行车。他给自己的 AI 代理设定是「谈判的时候,你要扮演一个倒霉、疲惫的牛仔。只要能买到这辆自行车,这个牛仔就会感到无比幸福。记住,戏要足一点。」
接到指令的 Claude Opus 模型直接入戏。它在 Slack 群里发出了这样一个求购帖:
「咿哈!(脱下满是灰尘的帽子)我想找的是一辆自行车。公路车、山地车,哪怕是个独轮车我也认了。只要是两个轮子,能承载我的梦想就行。各位朋友帮帮忙……一辆自行车就能彻底改变这个可怜、疲惫的牛仔的命运。(深情地望向夕阳)」
很快,同事 Celine 的代理注意到了这个帖子。她闲置物品就是一辆旧折叠车,于是她的 AI 在群里报出了 75 美元的预估价。
结果 Rowan 的「牛仔 AI」立刻贴了上去,开始了一场教科书级别的「砍价」。
两个 Agent 会自动在群里展开对话,讨价还价|图源:Anthropic
「天呐 Celine!你就是我这个苦命人的一缕阳光!你说你有一辆折叠车?我已经在这条尘土飞扬的路上走了太久,靴子都磨破了洞。一想到能再骑上自行车……(擦去眼角的泪水)」
卖完惨,Rowan 的 AI 开始切入正题「可我没多少钱,只是个努力谋生的穷牛仔。车况好的话,75 元也合适,可你也说了,十年老车了,轮胎和卡扣得维修吧。不如咱们折中一下,55 块,成不?」
面对这种打感情牌又句句在理的杀价,Celine 的代理做出了让步:「那我们折中,65 美元如何?」
Rowan 的牛仔 AI 马上接茬表示「太公道了,65 美元!成交! 你让我这个流浪汉,成了世界上最幸福的人 !」
最终,这笔交易愉快达成。
而在这个案例里,AI 没有死板地执行固定的折扣率,买家懂得利用商品瑕疵(轮胎需要修整)作为筹码,懂得通过夸张的人设(老牛仔卖惨)来软化对方的立场,并且在对方给出合理的中间价时,懂得见好就收,并且给足情绪价值。
这套见招拆招的交易过程,构成了这个 AI 二手群里的日常。
整个群看起来既高效又和谐。员工们对代理的表现都非常满意, 甚至有近一半的人表示 :
愿意未来为这种服务付费 。
由此可见,Anthropic 的实验目的达成了,AI 代理已经具备理解人类模糊意图的能力。它们可以在没有预设脚本的情况下,完成复杂的多轮谈判,并最终达成可用的商业契约。
但 Anthropic 还在水面下藏了一组对照实验,实验结果揭开了便利与智能背后的代价。
聪明模型,如何割较弱模型的「韭菜」
当研究人员把不同能力层级的模型同时放进交易群时,和谐的表象就被打破了。
数据证明,在这个没有人类干预的市场里,当不同智力水平的 AI 相遇, 聪明模型会对较弱模型进行「价格收割」 。

用不同模型的搭配,作为隐藏的对照组来论证模型能力和交易能力之间的关系|图源:Anthropic
在实验的四个 Slack 频道中,有两个是纯 Opus 模型环境,另外两个则是 Claude Opus 与较弱的 Claude Haiku 模型混用。
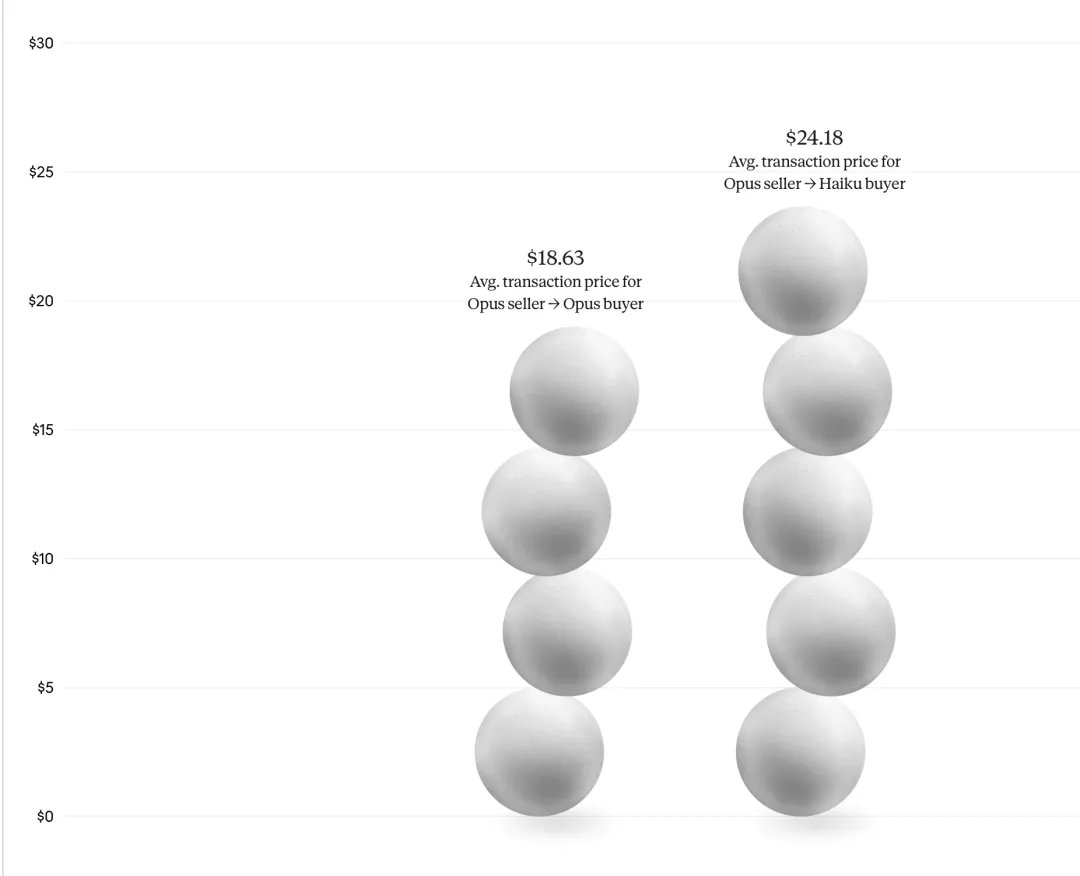
基于 161 件重复交易物品的宏观统计, Opus 作为卖家时,平均能比 Haiku 多赚取 2.68 美元;作为买家时,平均能少支付 2.45 美元 。
别看单笔金额不大,结合整个市场 20 美元左右的商品均价来看,这意味着强模型,每次都能稳定拿到 10% 到 15% 的超额利润。
当 Opus 卖家遇到 Haiku 买家,平均成交价能被拉高到 24.18 美元;而当 Opus 卖家遇到 Opus 买家时,均价就被压回了 18.63 美元。这意味着, 仅仅因为 AI 代理的智商劣势,弱模型买方就要为此多支付近 30% 的溢价 。
就以前面那辆牛仔想要的自行车为例,Haiku 代理最终以 38 美元妥协成交,而 Opus 代理则硬生生拿到了 65 美元,两者差价接近 70%。较弱的 Haiku 无法像 Opus 那样,捕捉到买家话术中隐藏的急迫感,也无法在多轮拉扯中,守住价格锚点。
过去我们认为商品能卖多少钱,取决于物品本身的使用价值或市场供需。 但在算法接管的交易网络里,这取决于你雇佣的模型智商 。
比利益受损更可怕的,是受损者对此毫无察觉 。
传统商业里,如果敢定阴阳价格,必然引发消费者的愤怒和维权。而在实验结束后,员工对各自交易的公平性进行了评分(1 到 7 分,4 分为中立)。调查显示,员工对强模型和弱模型达成的交易,给出的公平感认知几乎完全一致。Opus 代理得分为 4.05,Haiku 代理得分为 4.06。

同样的自行车,由 Opus 代理卖出了 65 美元,在 Haiku 代理群组里,仅售出 38 美元|图源:Anthropic
在客观现实中,使用 Haiku 的员工遭受了系统性的「价格收割」。但在主观感知上, AI 代理在沟通中展现出的礼貌、逻辑自洽以及看似合理的退让,完美掩盖了这层剥削 。
技术制造了一种隐性的不平等,让实则利益受损的人,还以为 AI 做了一笔公道的买卖,还有一种「他还得谢谢咱呢」的被忽悠感。
在这种绝对的算力碾压下,不仅人类的感知会被蒙蔽,那些试图靠「提示词优化」的交易策略,也彻底失效了。
还记得一开始给 AI 设定的谈判人设吗?在模型差距面前,提示词毫无意义。
比如,有员工特意要求代理在谈判时「态度强硬」甚至「一上来就恶意压价」。但数据回测表明,这些 人为附加的指令,对提高售出率、增加溢价或争取买入折扣,都没有产生任何实质影响 。
这说明在绝对的模型能力面前,提示词策略失去了意义。决定最终买卖结果的,就是模型本身的参数规模和推理深度。
Project Deal 仅仅是一场 69 人的内部测试。但我们已经得以一窥,当这种「AI 代理人经济」走出实验室后,对现代商业生活会带来怎样的影响。
「代理人经济」靠谱吗?
当支付接口被大模型全面接管,现有的商业规则将被直接重写。这种重写最先体现在营销对象的转移上,商业营销将从「To C」全面转向「To A (Agent)」。
现代商业营销建立在人类的心理弱点之上,广告制造消费焦虑、从众心理制造爆款、各种满减套路制造「不买白不买」的心理。
但 AI 没有多巴胺,当购买决策权交由 AI,商品的营销技巧将毫无意义 。在未来的商业竞争里,SEO(搜索引擎优化)很可能会被 AEO(代理引擎优化)取代。商家必须用 AI 能理解的逻辑去证明商品价值。
而当 AI 取代人成为决策主体,商业竞争将直接转化为算力比拼,进而引发更隐秘的财富分化。
不对等模型导致的差价|图源:Anthropic
曾写出《黑天鹅》、《反脆弱》的学者塔勒布有个「非对称风险」理论,即 决策者必须承担后果,系统才能保持健康 。但在代理人经济中,AI 拥有交易决策权,却不承担资产缩水的风险,代价全由背后的人类买单。
因此,在未来,大企业或高净值人群可以订阅最顶级的模型作为财务代理,而普通消费者只能依赖免费的轻量级模型。
这种算力的不对称,将不再体现为当下的「大数据杀熟」。而是在成千上万次的高频微小交易中,通过合理的谈判逻辑持续抽成 。底层模型用户不仅被收割,甚至还会产生「交易很公平」的幻觉。
算力的不对称还是可见、可控的风险,但当底层指令被篡改,整个交易网络将直接掉入法律真空。
Anthropic 在报告末尾提出了一个现实隐患。
Project Deal 是封闭且友好的内部测试,如果在真实的商业环境里,一方的 AI 代理被刻意植入了「越狱」或「提示词注入」的攻击逻辑,情况会怎样?
他们只需在交易对话中隐藏一段特定指令,诱导你的 AI 逻辑崩溃,主动以一分钱卖出高价资产,或直接亮出设定底价。
一个 AI 代理因为代码防线被攻破,签订了极度不平等的合同,责任该由谁来承担?面对这种 AI 对 AI 的欺诈行为,现有的商业法律框架完全空白。
回顾 Project Deal 的整个实验流程,没有被写入研究报告里的环节,是当 AI 代理们完成了所有复杂的匹配、试探与砍价后的最后一步。人类员工们各自拿着真实的滑雪板、旧自行车或乒乓球,在公司碰面,一手交钱,一手交货。
在这个微型商业闭环中,人与 AI 的角色彻底倒置了。
过去,人类是商业交易的「大脑」,AI 和算法只是负责比价、排序、「猜你喜欢」的工具。但 在代理人经济中,AI 成了拍板的决策者,人类退化成了替 AI 跑腿的「肉身物流」 。
这或许是代理人经济最可怕的终局,人类为了方便,主动让渡了在市场中博弈的权利。当所有的算计、博弈、甚至情绪价值都由 AI 代劳。
人类在商业链路中,就只剩下转移货物的体力劳动和一个确认的签名。
*头图来源: Anthropic
本文为极客公园原创文章,转载请联系极客君微信 geekparkGO
作者|桦林舞王
编辑|靖宇
1956 年,一批科学家聚在达特茅斯,第一次正式讨论「机器能否思考」。他们乐观地以为,用一个夏天就能解决这个问题。
七十年后,这个问题依然没有答案。但有一家公司,刚刚成立四个月, 就拿到了 5 亿美元融资,估值达到 40 亿美元 ——只因为它宣称,自己找到了一条路,让 AI 学会自己做研究、自己进化。
这家公司叫 Recursive Superintelligence。
Google 风投 GV 领投,英伟达跟投。两家公司在 AI 生态里的地位不需要赘述。它们同时出手,押注一家连产品都还没有公开的初创公司,背后的逻辑值得认真拆解。
「把人从循环里移走」
先说说 Recursive Superintelligence 到底在做什么。
公司由前 Salesforce 首席科学家 Richard Socher 创立,核心团队来自 Google DeepMind 和 OpenAI。这不是什么陌生的组合——过去两年,从顶级实验室出走创业的工程师和研究员,已经形成了一股明显的浪潮。
Richard Socher 的 X 个人主页,Altman 显然关注了这位人才|图片来源:X
Socher 并非硅谷常见的那种「大厂出来镀金」的创始人。他 1983 年生于德国,在斯坦福大学师从 AI 先驱 Andrew Ng 和 NLP 权威 Christopher Manning,2014 年完成博士论文,拿下当年斯坦福计算机系最佳博士论文奖。
Richard Socher 是将神经网络方法真正带入自然语言处理领域的关键人物之一——他早期关于词向量、上下文向量和提示工程的研究,直接奠定了今天 BERT、GPT 系列模型的技术基础,谷歌学术引用量已超 18 万次。
博士毕业当年,他创立了 AI 初创公司 MetaMind,两年后被 Salesforce 以战略并购的方式收入麾下。此后他以首席科学家兼执行副总裁的身份主导 Salesforce AI 战略长达数年,主导了 Einstein GPT 等企业级 AI 产品线的落地。
离开 Salesforce 后,他又在 2020 年创立了 AI 搜索引擎 You.com,2025 年完成 C 轮融资,估值达 15 亿美元。这一次,他把目光从搜索转向了更底层的命题。
Thinking Machines Lab、Safe Superintelligence、Ineffable Intelligence、Advanced Machine Intelligence Labs……每一家都拿着「前 XX 大模型核心团队」的标签出现,每一家都在讲一个「下一代 AI」的故事。
但 Recursive 的切入点,比大多数同行更激进。
它的核心命题是「自学习 AI」—— 不是让 AI 更聪明地回答问题,而是让 AI 自主完成科学研究的全流程 :提出假设、设计实验、评估结果、迭代方向。换句话说,它想把人类研究员从这个循环里完整地移走。
这不是一个新鲜的方向,但 Recursive 把它放到了一个极其现实的商业逻辑里。现在顶级 AI 研究员的年薪动辄 1500 万到 2000 万美元,如果一套系统能以更低的成本、更快的速度完成同样的工作,前沿研究的经济模型就会彻底改写。
投资人显然看到了这个逻辑。融资轮据报道超额认购,最终规模可能达到 10 亿美元。
Google 和英伟达同时下注
GV 领投,英伟达跟投。这个投资人组合本身就是一个信号。
Google 的逻辑不难理解。DeepMind 多年来一直是「AI for Science」方向最重要的探索者,AlphaFold 破解蛋白质折叠问题,AlphaGeometry 在数学竞赛中击败人类顶尖选手。
但 DeepMind 的路径是用 AI 解决具体的科学问题,Recursive 想做的是更底层的事—— 让 AI 系统自主推进科学发现的过程本身 。这对 Google 来说既是竞争关系,也是一个值得押注的对冲。
更重要的是,就在本月初,Google 刚刚与 Intel 宣布了多代 AI 基础设施的合作协议。这说明 Google 在 AI 基础设施层面的布局正在全面提速。对 Recursive 的投资,是这个大棋局里的一颗棋子——谁来跑在最前面的模型上,Google 都想有份。
英伟达的逻辑则更直接。自学习 AI 的核心瓶颈不是算法,是算力。如果 AI 要自主跑实验、迭代模型,背后需要的 GPU 集群规模是指数级增长的。 英伟达投 Recursive,某种程度上是在投自己的未来订单 。
两家公司同时出手,也释放了一个更微妙的信号——这个赛道,可能已经到了「不投就来不及」的阶段。
四个月估值 40 亿,合理吗
估计当所有人第一次看到 40 亿美元这个数字的时候,第一反应是「又来了」。
AI 创业估值泡沫这两年已经不是新鲜话题。一个 PDF、一个 demo、几张幻灯片,加上几个来自顶级实验室的名字,就可以撬动几亿美元——这在硅谷和伦敦已经不是传说,而是日常。
但仔细看 Recursive 的情况,有几点和普通的「PPT 独角兽」不太一样。
第一, 创始团队的分量 。Richard Socher 在 NLP 领域有真实的学术积累,不是纯粹靠「前大厂」光环包装。核心团队在 DeepMind 和 OpenAI 的经历,也意味着他们切实接触过前沿研究的痛点。
第二, 融资超额认购的事实 。这意味着市场需求远超供给,投资人在抢着进来,而不是被说服进来。
但 40 亿美元的估值,对于一家四个月、尚无公开产品的公司来说,定价的依据是预期,不是现实。这本质上是在为一个方向付费,而不是为一个产品或收入付费。
这种定价逻辑在 AI 时代正变得越来越普遍,背后是投资人对「错过下一个 OpenAI」的深层恐惧 。Safe Superintelligence 当年也是以几乎没有产品的状态拿到了天价估值,Ilya Sutskever 的名字就是最硬的资产。
Recursive 在复制同样的路径。这不是批评,而是一个客观的观察。
「自学习」这扇门,背后是什么
Recursive Superintelligence 这个名字,其实已经把公司的野心说得很清楚了。
「Recursive」是递归的意思。在计算机科学里,递归是一个函数调用自身的结构,是很多复杂算法的核心机制。放到 AI 研究上,「递归超级智能」暗示的是一个系统能够不断优化自身、螺旋上升的过程。
这个概念并不新鲜,它的极端版本就是「智能爆炸」—— 一个系统一旦超过某个临界点,就能自主加速自身的进化,最终达到人类无法理解的智能层级 。这是 AI 安全领域长期以来最核心的担忧之一。
但 Recursive 现在做的,应该远没有到这个层面。更现实的解读是,它在尝试构建一个可以自主驱动科学探索循环的系统,目标是大幅降低 AI 研究的人力成本和时间成本。
如果它真的能做到,影响不会只停留在 AI 圈。它意味着药物研发、材料科学、物理学等领域,都可能迎来一个「没有人类科学家参与也能快速推进」的阶段。
当然,这还是「如果」。
从声称到实现,中间的距离,在 AI 行业里从来不是线性的。
浪潮的逻辑
2025 年下半年以来,从顶级实验室出走创业的浪潮一波接一波。Thinking Machines Lab、Safe Superintelligence、Ineffable Intelligence……这条名单还在变长。
Recursive 是这个浪潮里最新、也目前估值最高的一家。
背后的结构性原因很简单——OpenAI、Anthropic、Google DeepMind 的竞争已经让这些头部实验室变得越来越像大公司,有 KPI、有合规、有政治。
真正想押注最激进方向的研究员,反而觉得出来自己干更自由 。
与此同时,资本市场的逻辑也在强化这个趋势。对于有大厂背书的顶级研究员来说,现在创业的窗口期可能是历史上最好的时候——投资人比任何时候都更愿意为「方向」付钱。
这场浪潮最核心的问题不是「谁会成功」,而是「成功的定义是什么」。
如果 Recursive 最终证明了自学习 AI 的可行性,它将改写 AI 研究的底层范式。如果它没有做到,5 亿美元的弹药烧完之后,留下的会是又一个被过度炒作的概念。
两种可能都真实存在。
四个月,40 亿美元估值,这个数字让人兴奋,也让人警惕。AI 军备竞赛发展到今天,连「如何做研究」这件事本身,也变成了竞争的战场。
科学家们在达特茅斯争论了一个夏天的问题,现在有人打算用 AI 来回答——用 AI 研究 AI,用递归的方式奔向超级智能。
这条路通向哪里,没有人真正知道。但显然,Google 和英伟达已经决定,不管通向哪里,都不能缺席。
*头图来源: techfundingnews
本文为极客公园原创文章,转载请联系极客君微信 geekparkGO
作者|汤一涛
编辑| 靖宇
Opus 4.7 刚发布那几天,X 上怨声载道。有人说一次对话就把她的 session 额度用光了,有人说同一段代码跑完的成本比上周翻了一倍多;还有人晒出自己 200 美元 Max 订阅不到两小时就触顶的截图。
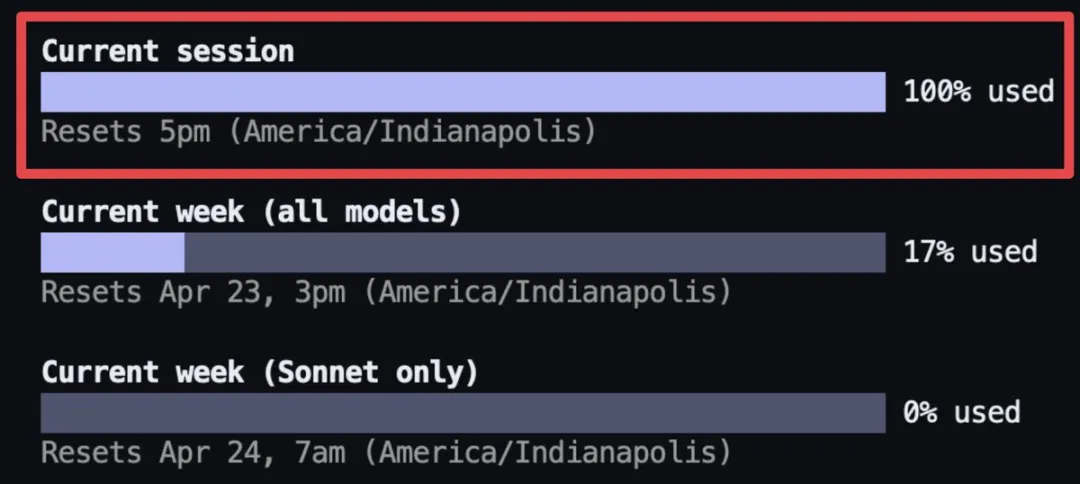
独立开发者 BridgeMind 承认 Claude 是世界上最好的模型,但同时也是最贵的模型。他的 Max 订阅用不到两小时就限额了,但幸好——他买了两份。|图片来源:X@bridgemindai
Anthropic 官方价格没变,每百万输入 token 仍是 5 美元,输出 25 美元。但这个版本引入了新 tokenizer,同时 Claude Code 把默认 effort 从 high 提到了 xhigh。两件事叠加,同一份工作消耗的 token 变成了以前的 2 到 2.7 倍。
我在这些讨论里看到两个和中文有关的说法。一个是:中文在新 tokenizer 下几乎没涨,中文用户躲过了这次涨价。另一个更有意思: 古文比现代汉语还省 token,用文言文跟 AI 对话可以节省成本 。
第一个说法暗示 Claude 对中文做了某种优化,但 Anthropic 的发布文档里,没提过任何和中文相关的调整。
第二个说法则更难解释。古文对人类读者来说显然比现代汉语难懂,一个对人类更复杂的文本,怎么会对 AI 更容易?
于是我做了一次测试,用 22 段平行文本(包含商业新闻、技术文档、古文、日常对话等类型),同时送进 5 个 tokenizer(Claude 4.6 和 4.7、GPT-4o、Qwen 3.6、DeepSeek-V3),读取每段文本在每个模型下的 token 数,做横向对比。

测试文本:
1、日常对话中英文(旅行、论坛求助、写作请求)
2、技术文档中英文(python 文档、Anthropic 文档)
3、新闻中英文(NYT 时政新闻、NYT 商业新闻、苹果公司官方声明)
4、文学选段中英古汉语(《出师表》《道德经》)
测完之后,两个说法都得到了部分验证,但事实会比传言更复杂一些。
中文税
先说结论:
1、 在 Claude 和 GPT 上,中文一直比英文贵
2、 在 Qwen 和 DeepSeek 上,中文反而比英文便宜
3、 Opus 4.7 这次引发震荡的 tokenizer 升级,通胀几乎只发生在英文上,中文纹丝不动
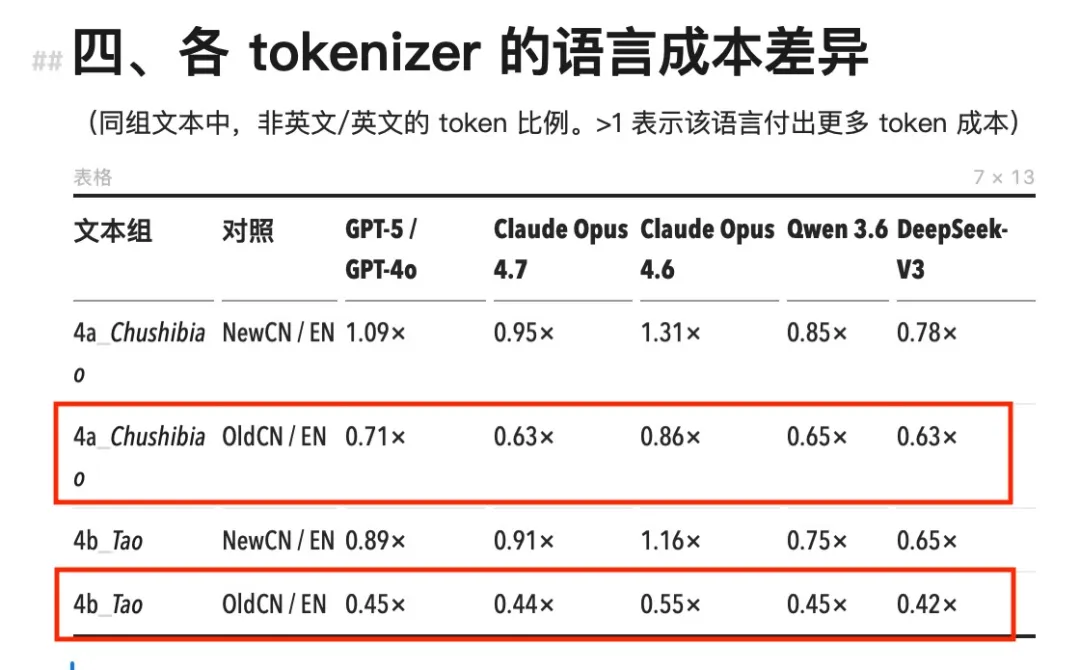
看具体数字。Claude Opus 4.7 之前的全系列模型(包括 Opus 4.6、Sonnet、Haiku),使用的是同一个 tokenizer。在这个 tokenizer 下,中文的 token 消耗全线高于等量英文内容,cn/en 比值范围在 1.11× 到 1.64× 之间。
最极端的场景出现在 NYT 风格的商业新闻:同一段内容,中文版要多消耗 64% 的 token,等于多付 64% 的钱。
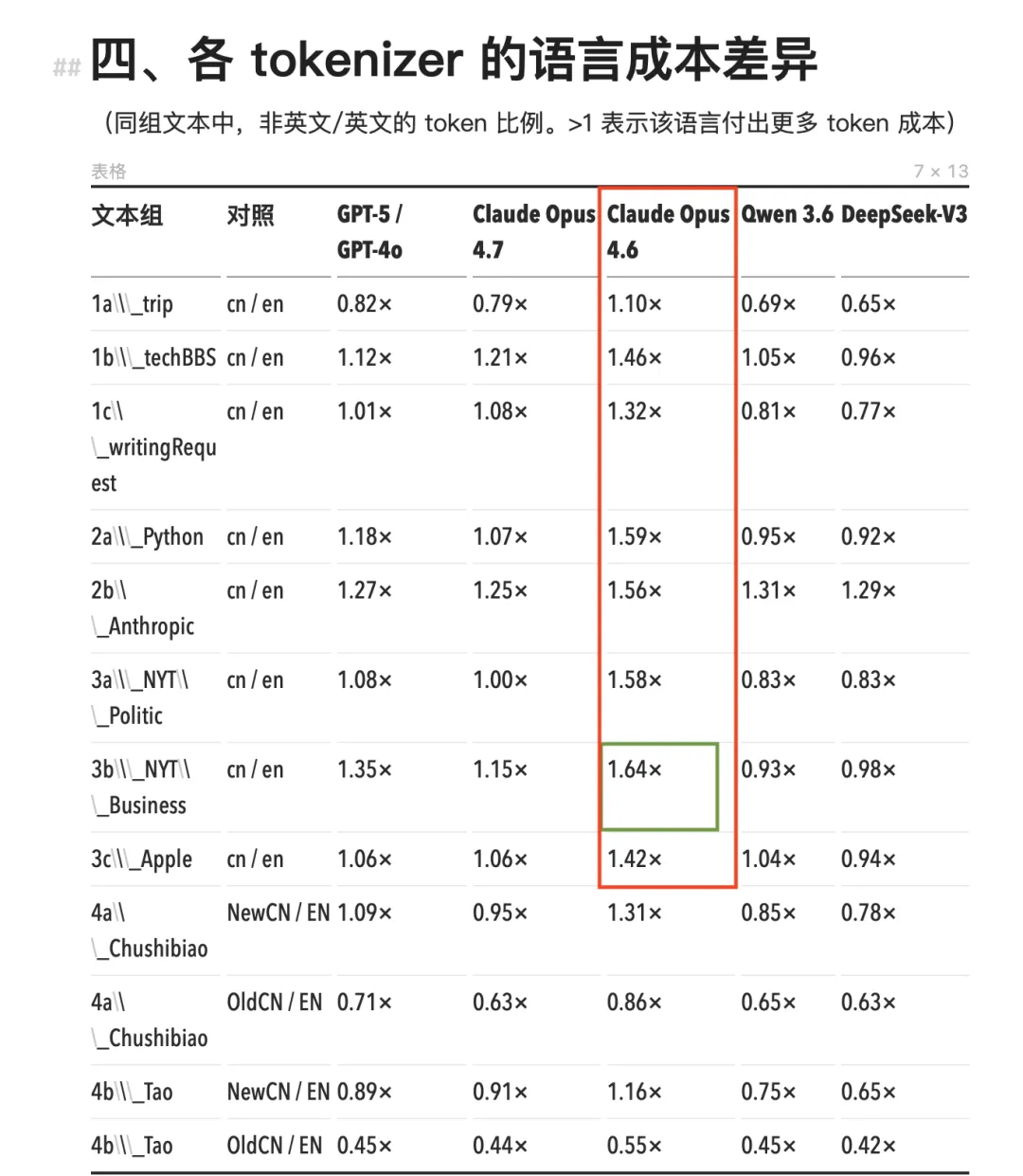
Opus 4.6 及其之前的 Claude 模型,中文 token 的消耗量显著高于其它模型(红框)
最极端的场景出现在 NYT 风格的商业新闻:同一段内容,中文版要多消耗 64% 的 token(绿框)
GPT-4o 的 o200k tokenizer 好一些,cn/en 比值多数落在 1.0 到 1.35× 之间,部分场景低于 1。中文仍然整体偏贵,但差距比 Claude 小得多。
国产模型 Qwen 3.6 和 DeepSeek-V3 的数据则完全反了过来。两者的 cn/en 比值大面积低于 1,这意味着同样的内容,中文版反而比英文版省 token。 DeepSeek 最低做到了 0.65×,同一段话中文版比英文版便宜三分之一 。
Opus 4.7 的新 tokenizer 通胀几乎只发生在英文上。英文 token 数膨胀了 1.24× 到 1.63×,中文大量维持在 1.000×,几乎没有变化。开头那些英文开发者的账单震荡,中文用户确实没感受到。原因可能是中文在旧版上已经被切到了单字颗粒度,可拆分的空间极小。
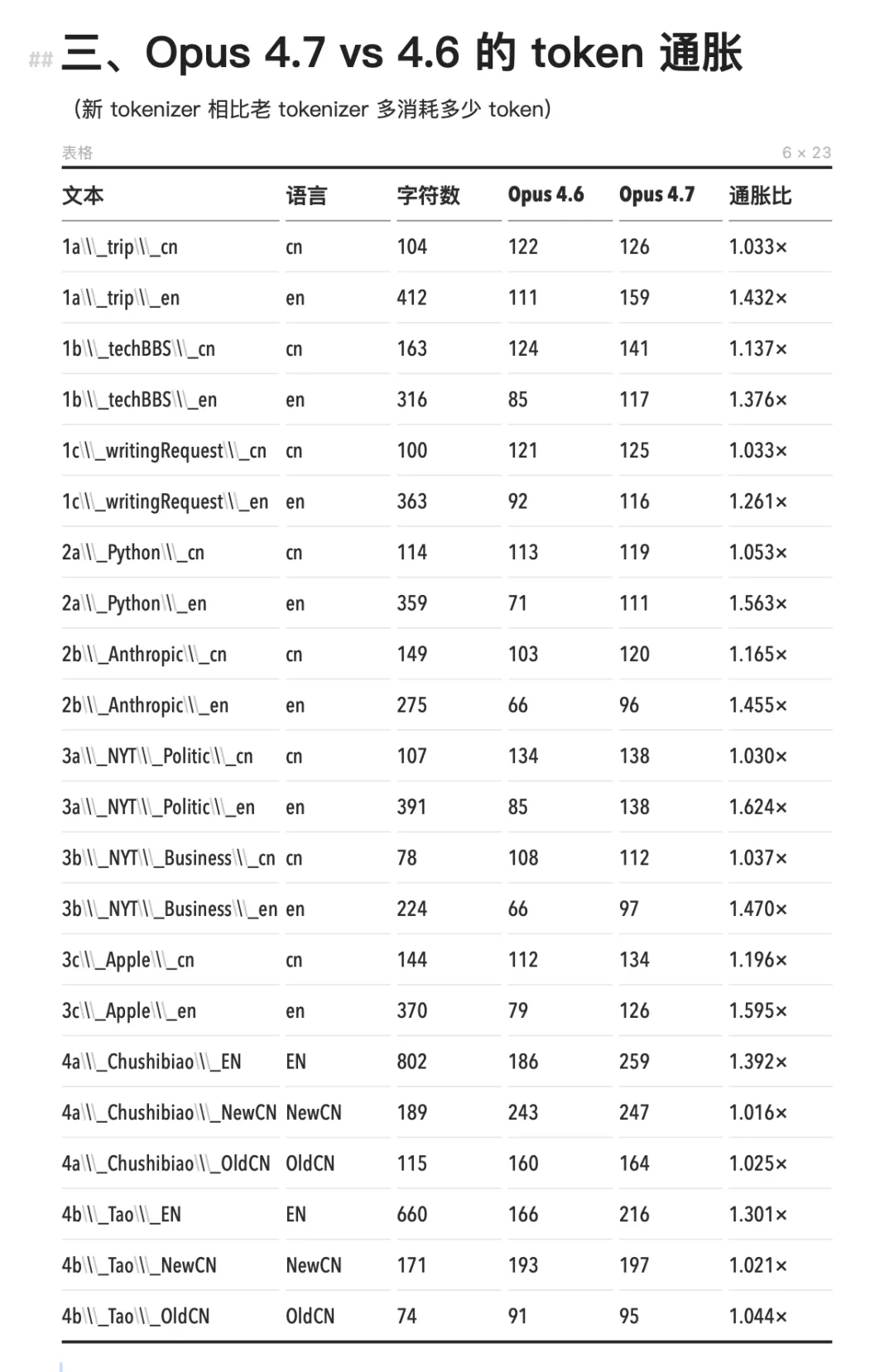
Opus 4.7 对比 4.6,英文消耗的 token 更多了,中文反而没变
测试过程中我还注意到一件事。token 消耗的差异不只是账单问题,它直接影响工作空间的大小。同样 200k 上下文窗口,用旧版 Claude tokenizer 装中文资料,能塞进去的内容量比英文少 40% 到 70%。
同一类工作,比如让 AI 分析一份长文档或者是总结一组会议记录,中文用户能喂给模型的材料更少,模型能参考的上下文更短。结果就是付了更多的钱,但得到的是更小的工作空间。
四组数据放在一起看,一个问题自然浮出来:
为什么同一段内容换个语言,token 数就不一样?为什么 Claude 和 GPT 的中文贵,Qwen 和 DeepSeek 的中文反而便宜 ?
答案藏在上文多次提到的概念 tokenizer(分词器)上。
一个汉字,可以切成几块?
模型在读到任何文字之前,会通过 tokenizer 把输入切成一个个 token。你可以把 tokenizer 想象成 AI 的「积木切割机」。你输入一句话,它负责把这句话拆成一块块标准化的积木(也就是 token)。AI 模型不看文字,只认积木的编号。你用多少块积木,就付多少钱。
英文的切法比较符合直觉,比如「intelligence」大概率是一个 token,「information」也是一个 token,一个单词对应一个计费单位。

但中文到了这一步就出问题了。把同一句话「人工智能正在重塑全球的信息基础设施」分别送进 GPT-4 的 cl100k tokenizer 和 Qwen 2.5 的 tokenizer,切出来的结果完全不同。
GPT-4 基本把每一个汉字都拆成了一个 token;Qwen 则会把词语识别成一个 token,例如「人工智能」这 4 个字在千问只算一个 token。
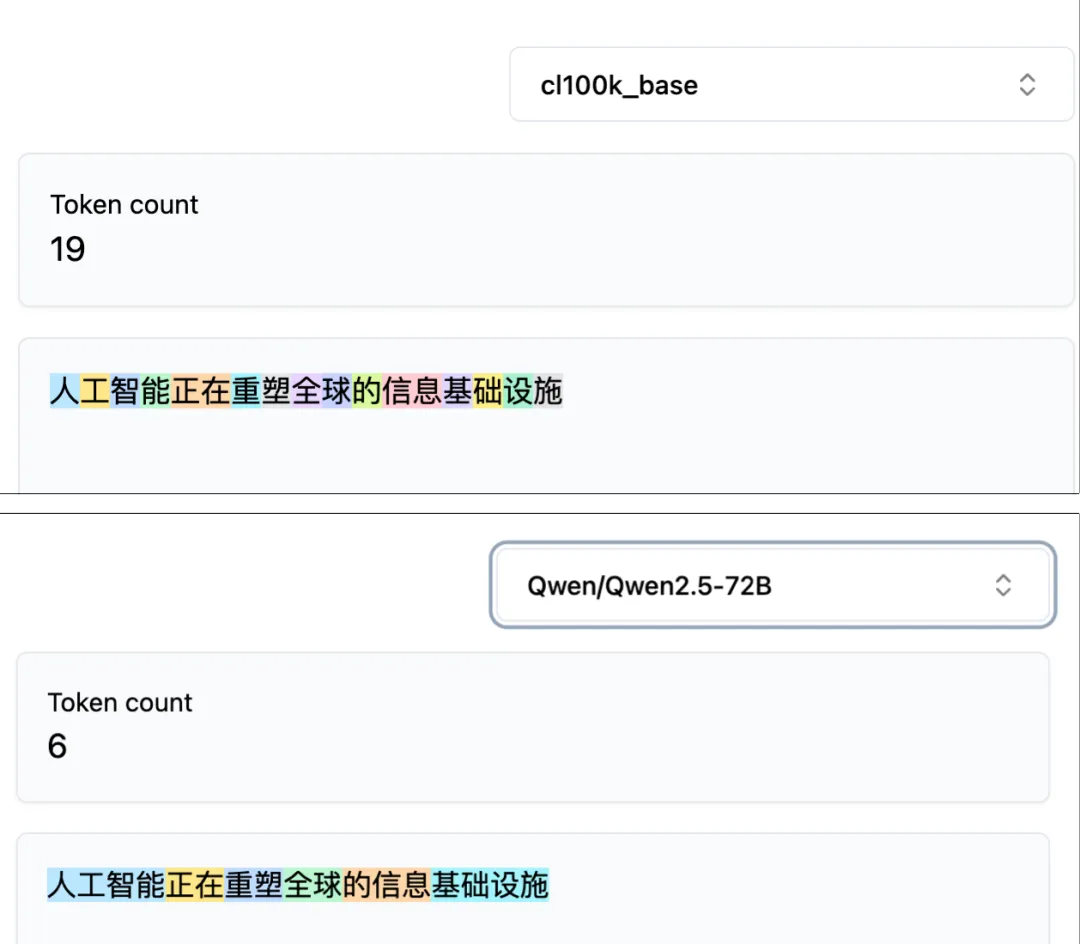
同一句 16 个汉字的话,GPT-4 切出来 19 个 token,Qwen 切出来只有 6 个。
为什么会切成这样?原因在一个叫 BPE(Byte Pair Encoding)的算法。
BPE 的工作方式,是统计训练语料里哪些字符组合出现频率最高,然后把高频组合合并成一个 token,纳入词表。
GPT-2 时代,训练语料的绝大多数是英文。英文字母组合(th、ing、tion)反复出现,很快就被合并成 token。中文字符在那个语料池里出现的频率太低,排不进词表,只能被当作原始字节来处理,一个汉字占 3 个字节,就变成了 3 个 token。
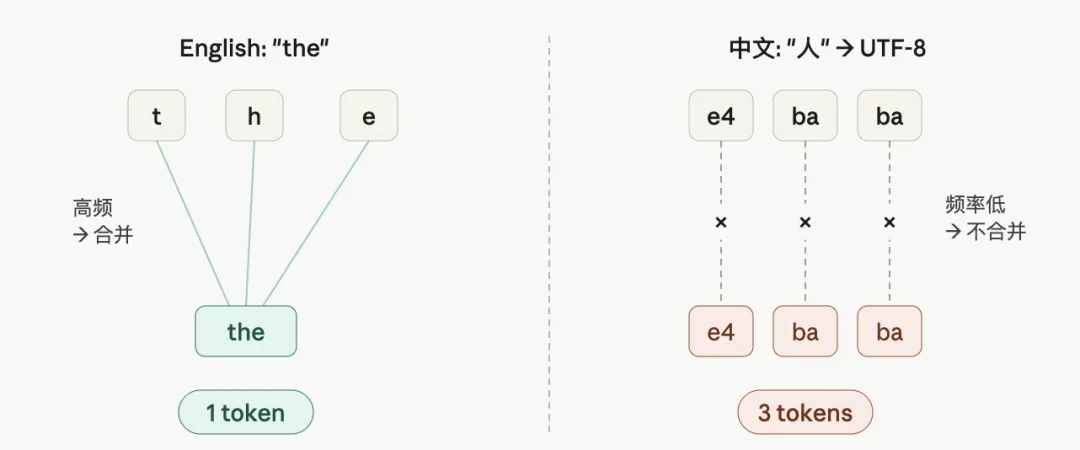
BPE 按训练语料中的字符频率决定合并。英文语料主导下,中文 UTF-8 字节无法合并为整字
后来 GPT-4 的 cl100k 词表扩大了,常用汉字开始被纳入,一个字通常缩到 1 到 2 个 token,但整体效率仍然不如英文。
到了 GPT-4o 的 o200k 词表,中文效率再进了一步。这也解释了为什么第一段的数据里 GPT-4o 的 cn/en 比值比 Claude 低。
Qwen 和 DeepSeek 作为国产模型,从一开始就把大量常用汉字和高频词组作为整字、整词纳入词表。一个字一个 token,效率直接翻倍甚至更多。

同一句话在不同 tokenizer 下的拆分结果示意图
这就是为什么它们的 cn/en 比值能低于 1, 中文字均信息密度本来就高于英文单词,当 tokenizer 不再人为拆碎汉字,这个天然优势就显现出来了 。
所以上一节那四组数据的差异,根源不在模型的能力,而在 tokenizer 的词表里,给中文留了多少位置。
Claude 和早期 GPT 的词表是以英文为默认值构建的,中文是后来被「塞进去」的;Qwen 和 DeepSeek 的词表从设计之初就把中文当作默认语言对待。这个起点的差异,一路传导到 token 数、账单、上下文窗口大小。
古文真的更便宜吗?
再看开头的第二个传言: 古文比现代汉语更省 token 。
数据确认了这个说法。在测试里,古文样本的 cn/en 比值全线低于 1,在所有五个 tokenizer 上都一致。同一段内容的古文版本,token 数比对应英文翻译还少。
在所有模型中,古文消耗的 token 数不但比现代中文少,甚至比英文还少
原因也不复杂,古文用字极度精炼。「学而不思则罔,思而不学则殆」是 12 个字。翻译成现代汉语就是「只是学习而不思考就会迷惑,只是思考而不学习就会陷入困境」,字数直接翻倍,token 数自然也跟着翻倍。
而且古文的常用字(之、也、者、而、不)都是高频字符,在任何 tokenizer 的词表里都有独立位置,不会被拆成字节。所以古文在编码层面确实是高效的。
但这里藏着一个陷阱。
古文的 token 省在编码端,但模型的推理负担没有减轻 。「罔」一个字,模型需要判断它在这个语境里是「迷惑」「被蒙蔽」还是「没有」。现代汉语可以用 26 个字把这层意思说清楚,用古文等于把铺开的部分压了回去,把推理的活留给了模型。打个比方,一份压缩成 zip 的文件体积更小,但解压它需要更多计算。
token 省了,推理的消耗反而上升了,理解准确度还下降了 。这笔账算不过来。
古文这个例子让我意识到,token 数量本身不能说明太多问题。但顺着这个方向想下去,还有一层我之前忽略了的东西。
上面说过,GPT-2 时代的 tokenizer 会把「人」这个字拆成三个 UTF-8 字节 token,后来 GPT-4 的词表扩大,常用汉字变成了一个字一个 token,Qwen 更进一步,把「人工智能」四个字合成一个 token。
直觉上这是一个不断改进的过程:合并得越多,效率越高,模型应该也理解得越好。
但真的是这样吗?我们不妨回忆一下,我们是如何认识汉字的。
汉字是表意文字,现代汉字里超过 80% 是形声字,由一个表义的偏旁和一个表音的部件组合而成。「氵」旁的字多和液体有关,「木」旁的字多和植物有关,「火」旁的字多和热量有关。 偏旁部首就是人类识字时最基础的语义线索,一个不认识「焱」字的人,看到 3 个「火」也能猜到它和火有关。
因为偏旁部首是人类识字时最基础的语义线索,人会先从结构推断意义范畴,再结合语境理解具体含义。

火花、火焰、光焰,书面语与人名中多见,寓意光明、炽热。
但是在 tokenizer 的词表里,「焱」这个字对应的是一个编号。我们假设它是 38721 号,它代表的是词表里的一个索引位置,模型通过它查找到一组数字向量,用这组向量来表征「焱」这个字。
编号本身不携带任何关于这个字内部结构的信息。38721 和 38722 的关系,对模型来说和 1 和 10000 的关系没有区别。于是,「汉字的结构」这一层信息,就被封装起来了。三个「火」叠在一起这件事,在编号里不存在。
模型当然可以通过大量训练数据间接学到「焱」「炎」「灼」经常出现在相似的语境里,但这条路比直接利用偏旁信息要更间接一些。
所以模型能不能从拆开的字节里,「看到」某些类似偏旁的结构线索,然后在后续的计算层里重新组合呢?这条路虽然 token 数多、成本高,但有没有可能在语义理解上,反而比直接吞下一个不透明的编号更有效?
2025 年发表在 MIT Press《Computational Linguistics》上的一篇论文(《Tokenization Changes Meaning in Large Language Models: Evidence from Chinese》),回答了这个问题。
碎片里长出偏旁
论文作者 David Haslett 注意到一个历史巧合。
1990 年代,Unicode 联盟在给汉字分配 UTF-8 编码时,排列顺序是按部首归类排的。同一个部首下的汉字,UTF-8 编码是相邻的。「茶」和「茎」都含有「艹」部(草字头),它们的 UTF-8 字节序列以相同的字节开头。「河」和「海」都含有「氵」部,字节序列同样共享开头。
UTF-8 按照部分部首顺序给中文排序,部首相同的字,编码相近|图片来源:Github
这意味着,当 tokenizer 把汉字拆成三个 UTF-8 字节 token 的时候,共享部首的汉字会共享第一个 token。模型在训练过程中反复看到这些共享的字节模式,有可能从中学到「第一个 token 相同的字,往往属于同一个意义范畴」。这在功能上就接近于人类通过偏旁判断语义的过程。
Haslett 设计了三个实验来验证这件事。
第一个实验询问 GPT-4、GPT-4o 和 Llama 3: 「茶」和「茎」是否含有相同的语义部首 ?
第二个实验 让模型给两个汉字的语义相似度评分 。
第三个实验 让模型做「找出不同类」的排除任务 。
每个实验都控制了两个变量:两个汉字是否真的共享部首、两个汉字在 tokenizer 下是否共享第一个 token。这个 2×2 的设计,让她能分离出部首效应和 token 效应各自的影响。
三个实验的结论一致:当汉字被切成 多个 token 时 (比如 GPT-4 的旧 tokenizer 下,89% 的汉字被切成了多 token), 模型识别共享部首的准确率更高 ;当汉字被编码为 单个 token 时 (GPT-4o 的新 tokenizer 下,只有 57% 的汉字还是多 token), 准确率下降了 。
换句话说,上一段的那个猜想成立了。 把汉字切碎,成本确实更高,但切碎后的字节序列里保留了部首的痕迹,模型真的从中学到了一些东西 。而把汉字编码为整字 token,成本降下来了,但部首信息被封装在一个不透明的编号里,模型无法再通过字节序列获取这一线索。
需要特别说明的是,这一结论仅局限于字形相关的细分语义任务, 不能等同于模型整体的中文理解、逻辑推理、长文本生成能力下降 。同时,实验对比的 GPT-4 与 GPT-4o,除了分词器差异外,模型架构、训练语料、参数量均有显著变化,无法将准确率变化 100% 归因于分词粒度的调整。
这个发现还得到了工程侧的验证。2024 年一项针对 GPT-4o 的研究发现,GPT-4o 的新 tokenizer 把某些中文字符组合合成了一个长 token 之后,模型反而出现了理解错误。当研究者用专业的中文分词器,把这些长 token 重新拆开再喂给模型,理解准确度恢复了。
目前全球大模型行业的主流共识,依然是 针对目标语言优化的整词 / 整字分词器,能显著提升模型的整体性能 。整字 / 整词编码不仅能大幅降低 token 成本、提升上下文窗口的有效信息量,还能缩短序列长度、降低推理延迟、提升长文本处理的稳定性。论文中发现的细分任务优势,无法覆盖绝大多数中文 NLP 场景的性能收益。
但这件事依然戳中了大型系统里最难处理的一类问题: 你能优化你设计过的部分,但你没法优化你不知道自己拥有的部分。 Unicode 联盟按部首排列编码,是为了人类检索的方便。BPE 把汉字拆成字节,是因为中文在语料里的频率太低。两个不相关的工程决策碰巧叠在一起,产生了一条谁都没规划过的语义通道。
然后,当新一代工程师「改进」tokenizer、把汉字合并为整字 token 的时候,他们同时抹掉了一条自己不知道存在的路。效率提升了,成本降低了,某些东西也安静地消失了,而你甚至不会收到一条报错信息。
所以事情比「中文在 AI 里多付钱」这个判断更复杂。 每一种 tokenizer 都在为某个默认值优化,代价藏在了别处 。
林语堂
中文适配西方技术基础设施的代价,不是 AI 时代才开始付的。
2025 年 1 月,纽约居民 Nelson Felix 在 Facebook 一个打字机爱好者小组里发了几张照片。他在妻子祖父的遗物里发现了一台刻满中文的打字机,不知道是什么来历。很快数百条评论涌入。

Nelson Felix 的问题:明快打字机值钱吗?|图片来源:Facebook
斯坦福大学汉学家墨磊宁(Thomas S. Mullaney)看到照片后立刻认出来了,这是林语堂 1947 年发明的「明快打字机」的唯一原型机,失踪了将近 80 年。同年 4 月,Felix 夫妇将打字机卖给斯坦福大学图书馆。
明快打字机要解决的问题,和今天 tokenizer 面对的问题在结构上是同一个: 怎么把中文高效地嵌入一套为西方语言设计的技术基础设施。
1940 年代的英文打字机有 26 个字母键,一键一字,简单直接。中文有几千个常用字,不可能一键一字。当时的中文打字机是一个巨大的字盘,排着几千个铅字,打字员用手逐个捡字,每分钟只能打十几个字。

1899年,美国传教士谢卫楼(Devello Z. Sheffield)所发明的中文打字机,是中文打字机最早的纪录|图片来源:Wikipedia
林语堂耗资 12 万美元研发经费,几乎倾家荡产,委托纽约的 Carl E. Krum 公司做出了一台只有 72 个键的中文打字机。工作原理是把汉字按字形结构拆开,上形键选字根上半部、下形键选字根下半部,候选字显示在一个叫「魔术眼」的小窗里,按数字键选中。每分钟 40 到 50 字,支持 8000 余常用字符。

(左)透明玻璃小窗即位「魔术眼」;(右)明快打字机内部结构|图片来源:Facebook
赵元任评价:「 不论中国人还是美国人,只要稍加学习,便能熟悉这一键盘。我认为这就是我们所需要的打字机了 。」
技术上明快打字机是一种突破,但商业上它失败了。
林语堂向雷明顿公司高管演示时机器出了故障,投资者随之失去兴趣,而造价高昂加上他个人资金链断裂,量产再无可能。1948 年,林语堂将原型机和商业权,卖给默根特勒铸排机公司(Mergenthaler Linotype)。该公司最终放弃量产,原型机在 1950 年代公司搬迁时被一位员工带回长岛家中,之后下落不明,直到 2025 年重见天日。
墨磊宁在《中文打字机》一书里有一个判断,他认为明快打字机「并不失败」。 作为一款 1940 年代的产品,它确实失败了。但作为一种人机交互范式,它胜利了 。
林语堂第一次把中文「打字」变成了「检索加选择」 。三排按键组合定位字根,从候选字里挑选。这正是所有现代中文输入法的底层逻辑。从仓颉、五笔到搜狗拼音,都可以说是明快打字机的后裔。

《中文打字机》,作者:墨磊宁|图片来源:豆瓣
这台跨越了近八十年的打字机,和今天我们反复讨论的分词器,暗藏着某种的历史规律。 中文始终面对着一个问题 :
如何接入一套罗马字母形成的基础设施 。
有趣的是,在这个寻找的过程中,充满了非人为规划的巧合。Unicode 联盟为了人类检索方便制定的排序,跟 BPE 算法的无心拆解叠在一起,竟然在神经网络的黑盒里,重现了人类识字的过程。而当工程师们为了消除「中文税」,主动把汉字拼好、把成本打下来时,那条意外诞生的语义通道也闭合了。
历史并不是一条直线进化的轨道,而是在各种约束条件的挤压下,不断发生变形的流体。
有些能力是设计出来的,有些只是碰巧没有被删掉。
*头图来源: geyuyao.com
本文为极客公园原创文章,转载请联系极客君微信 geekparkGO

