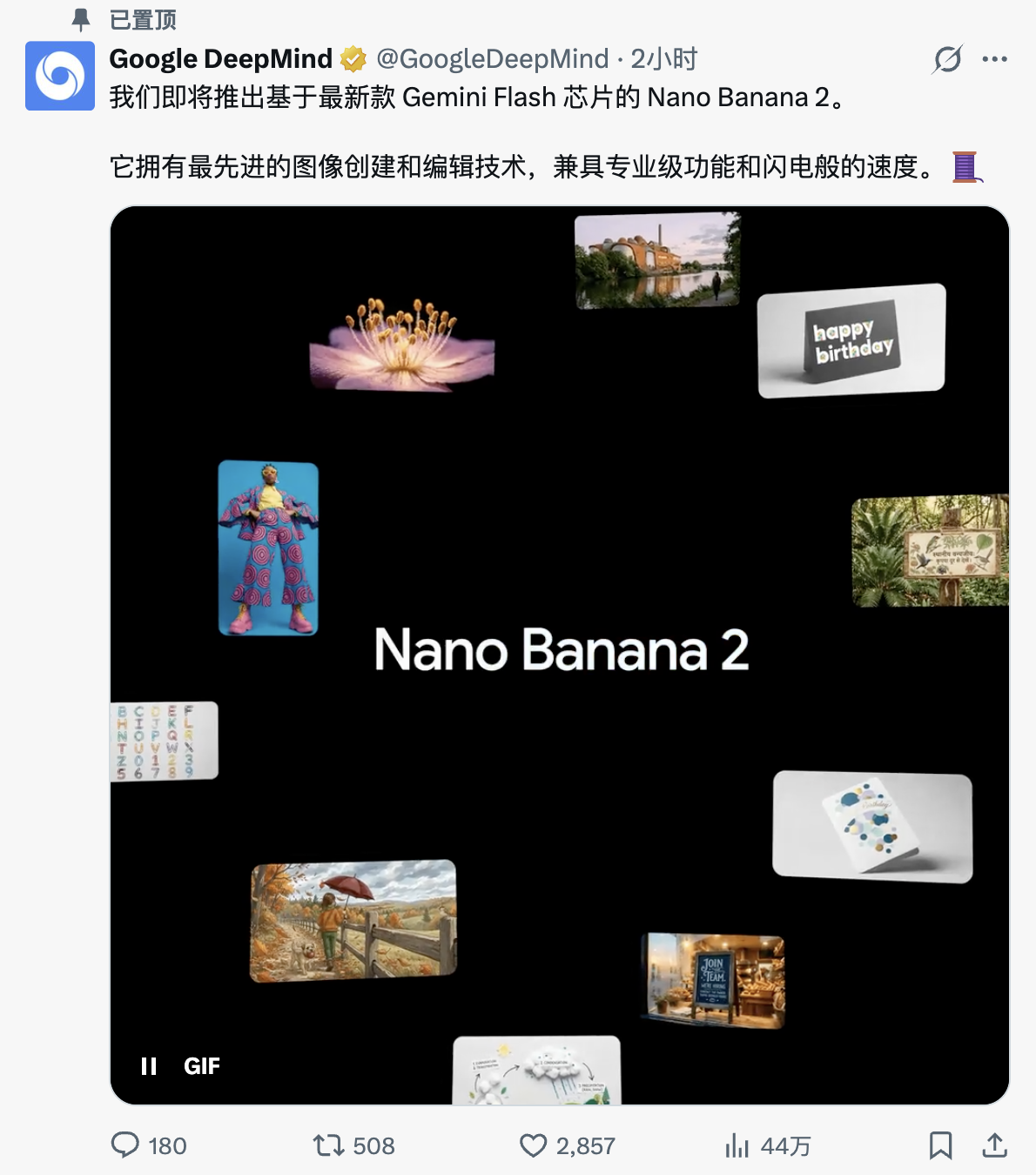
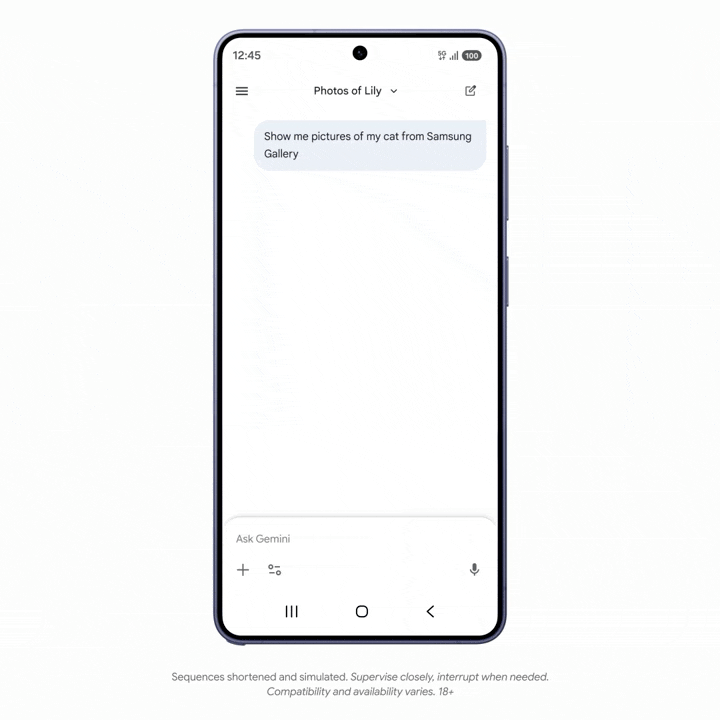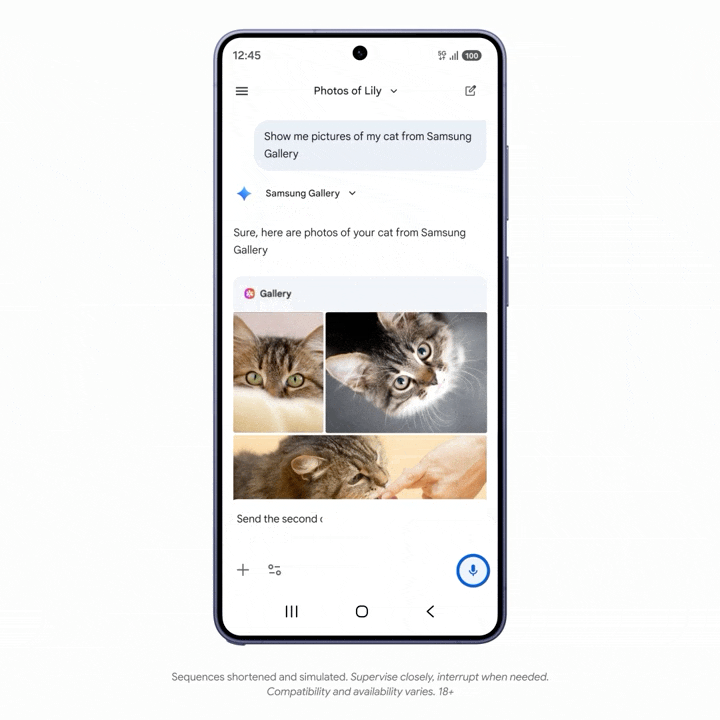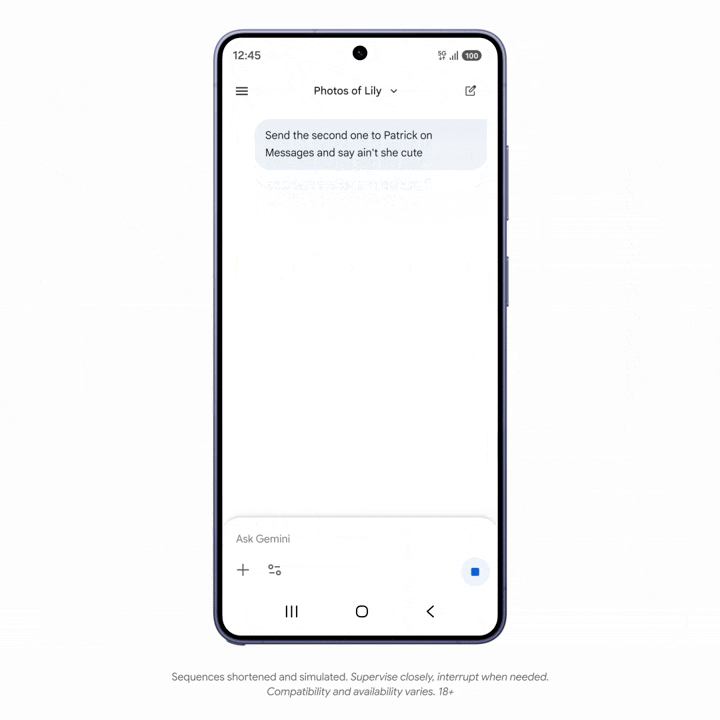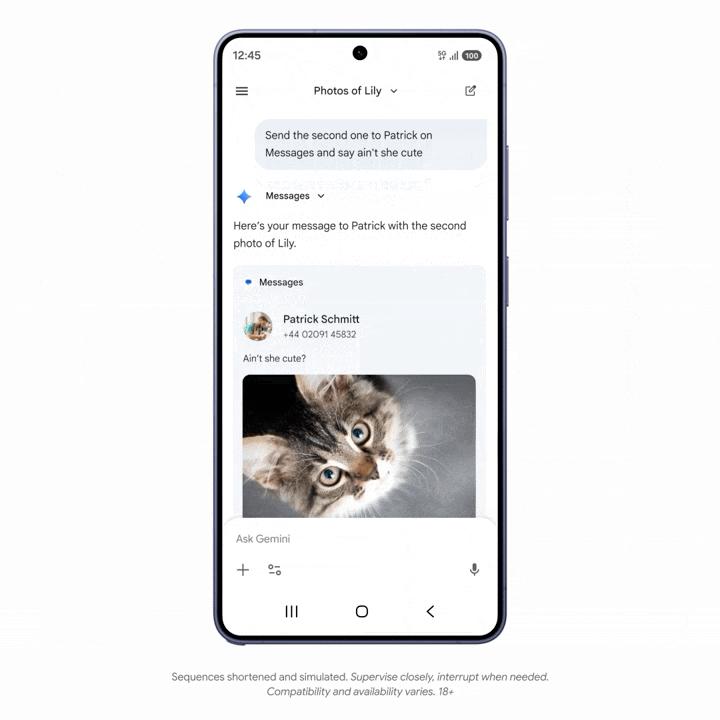
创新“新特区”,AWE2026上海新国际博览中心W3馆创新科技展区正式亮相
在中国家电与消费电子产业规模优势持续巩固的背景下,行业正站在向结构升级和技术跃迁转变的关键节点。AWE2026选择在上海新国际博览中心这一高度成熟、产业密度最高的核心展区内,开辟一个全新的“特区型”板块——创新科技展区,以此响应产业新增长动能的需求。

创新科技展区落地于上海新国际博览中心W3馆内,展示面积达到半个馆约5000余平方米。创新科技展区是在传统优势品类云集、头部品牌集中的产业平台上,为具备高成长潜力的新技术、新产品、新企业,划出一块聚焦未来创新科技的展示空间。
创新科技展区并非对现有展区的简单补充,而是与AWE既有板块形成清晰分工与有机协同,共同构成了AWE智慧生活生态。相较于以智能白电、家庭场景化解决方案为核心的智能家电展区,以消费电子、软硬件融合为重点的智能科技展区,以及厨电、卫浴和健康电器所组成的智慧健康展区,创新科技展区将重点覆盖具身智能与机器人、AI硬件、新型人机交互、前沿视听与智能娱乐等方向,重点展示正在快速走向应用化与商业化的先进技术形态与产品,呈现当前全球消费电子与智能产业竞争中最具变量和想象空间的关键赛道。
AWE2026创新科技展区将由宇树科技、魔法原子、乐享科技(元点智能)、智身科技、它石智航等具身智能与机器人企业,九号、首驱等智能出行企业,绿联、千问AI眼镜、艾德未来等AI硬件企业,以及幻陆、炉石、恩雅音乐等“科技×文化”创新型企业,Realtek、奕斯伟、移远、聆思、庆科等芯片方案商共同组成。
新物种集结:具身智能从实验室走向真实生活
在创新科技展区中,具身智能无疑是最具标志性的技术方向之一。随着大模型、多模态感知与运动控制技术的持续突破,机器人开始真正进入工业生产场景与开放环境。近日,魔法原子与宇树科技相继官宣成为2026年春晚机器人合作伙伴,更预示着机器人产业正迎来从技术验证走向大众视野的关键时刻。
宇树科技(Unitree):世界知名的民用机器人公司
宇树科技是世界知名的民用机器人公司,也是全球率先公开零售高性能四足机器人的企业。公司高度重视自主研发,全自研电机、减速器、激光雷达等关键零部件及高性能运动控制算法,拥有国内外授权专利180余项。凭借卓越的技术实力,宇树产品多次受邀亮相2022冬奥会开幕式、2023亚运会及2025蛇年央视春晚等顶级舞台。在去年举办的AWE2025上,宇树科技就曾以“新晋顶流”之姿惊艳亮相,其Go2四足机器人与G1人形机器人的灵动表现引发展台人声鼎沸,成为去年展会最具人气的打卡点之一。

人形智能体Unitree G1身高约132厘米,全身拥有23-43个关节电机,具备超大运动角度空间,可完成动态站起、舞棍等高难度动作,并能通过深度强化学习持续进化。具身智能新物种Unitree Go2则配备自研4D超广角激光雷达,在大模型赋能下大幅提升环境理解与决策能力;其关节峰值扭矩达45N.m,支持跳跃、倒立等丰富姿态。
作为行业创新的引领者,宇树科技近期推出了全球首个人形机器人专属APP Store,首次将“应用生态”模式引入机器人领域,推动行业从单纯的硬件比拼转向“硬件+软件+生态”的综合竞争。此外,宇树携手京东开设的全球首家线下品牌店已在北京开业,标志着机器人零售正迈向线下零距离体验的新阶段。
魔法原子(MagicLab):全栈自研驱动的具身智能全球化先锋
魔法原子(MagicLab)成立于2024年1月,是一家专注于通用人形机器人和具身智能技术研发与落地应用的全球化公司。公司核心成员汇聚清华、上海交大、密西根大学等国内外顶尖高校,研发人员占比超70%,拥有全栈自研的软硬件技术体系。其核心硬件自研比例超90%,覆盖关节模组、灵巧手等关键零部件,并自研VLA大模型“原子万象”,采取VLM+MoE分层架构,已采集约36万条真机数据,实现了多模态感知与具身操作的算法领先。

本届展会上,魔法原子带来了旗下机器人家族的明星成员。全尺寸通用人形机器人MagicBot Gen1全身42个主动自由度,能有效在工商业场景中执行长序列操作任务。荣获2025福布斯中国“人形机器人未来奖”的高动态双足人形机器人MagicBot Z1,搭载自研高性能关节模组,最大扭矩超130N·m,支持“大扰动冲击恢复”、“连续倒地起身”等高爆发运动,并在世界人形机器人运动会上斩获铜牌。此外,全球首款“头尾联动”四足机器人MagicDog融合音视触多模态交互,实现了真正的情感化陪伴。
魔法原子跑通产品从销售至交付的闭环,自2025年5月启动商业化以来,短短半年已获5亿元意向订单,海外收入占比超60%,广泛覆盖家庭、工业、商业场景。目前,公司所有产品均已实现小规模量产。
乐享科技(元点智能Zeroth):全球消费级具身智能商业化领跑者
乐享科技成立于2024年,是全球消费级具身智能商业化领跑者。不同于其他企业聚焦工业场景,乐享科技从创立之初便将目光锁定在家庭、养老、教育、宠物等消费场景,致力于打造真正具备理解能力的“镜像伙伴”。公司核心团队深耕机器人大小脑研发、算法优化及运动控制等关键领域,在2025年率先斩获消费级具身智能首个亿元级订单并实现千万元收入,打破了行业“重资本运作、轻技术落地”的固有印象,标注出行业从技术验证迈向规模商业化的关键拐点。2025年底,乐享科技发布具身智能全新品牌“元点智能”(Zeroth)。
本届AWE上,元点智能携全线产品亮相。全尺寸人形机器人Jupiter作为技术旗舰,搭载了专属训练环境Zeroth World,摆脱了对第三方环境地图的依赖,能依托过往经验与感知直觉深度学习现实世界的物理法则,在杂乱居家等复杂场景中自主适配、灵活作业。

针对消费级市场,元点智能推出了两款核心产品。家庭具身智能机器人M1是全球首款采用强化学习控制的伺服驱动机器人,融合全屋视觉语言导航技术,并配备全球首创的机器人平衡车底座,可自主切换运动模式。M1植入了自研Zeroth Soul交互模型,具备跌倒检测、双向音视频通话及定制化模块,精准覆盖养老、教育、宠物监护等刚需场景。户外履带式机器人W1则专为户外生活而生,28公斤自重可承载超50公斤负重,集成储能、安防、影像采集等全能功能,既是户外爱好者的装备搬运助手,也是家庭聚会的娱乐中枢与临时电源。
除此之外,本届AWE上,乐享科技将带来其灵动可爱的具身智能熊猫,以及全球首次对外的家庭服务机器人N1.
智身科技:自主研发驱动的具身智能全产业链技术服务商
智身科技成立于2023年,是行业领先的具身智能全产业链技术服务商,构建了从核心部件研发、整机制造到场景化落地的完整技术闭环。公司核心团队由顶尖科研人才组成,研发人员占比高达70%,在强化学习运控算法、VLN大模型及高功率密度关节模组等领域具备全栈研发能力与量产经验。目前,智身科技已拥有超60项核心专利,深度参与国家级重点课题,并推动产品在安防巡逻、电力巡检及应急救援等领域实现规模化应用。在AWE2025现场,智身科技曾展示灵动型四足机器人,呈现其在运动控制与场景化落地方面的技术突破。

本届展会上,智身科技将带来多款专为特种和行业应用打造的硬核产品。仿生四足机器人“钢镚ZSL-1”,搭载AI强化学习运控算法,是同类中唯一能实现“720°后空翻”特技的产品,最高速度3.7m/s,支持40°爬坡与IP54防护,堪称“最抗造”的机器狗。其轮足版本ZSL-1W则兼具5m/s高速巡航与低噪音优势,适用于安防、巡检、导盲等多场景智能移动任务。此外,高端轮足一体化产品“铜锤M1”以1:1的极致负载自重比(自重30kg/负载30kg)惊艳亮相,具备8m/s奔跑速度与80cm越障能力,是户外复杂作业场景当之无愧的“全能选手”。
AI硬件与视听娱乐:重新定义人与科技的互动方式
除机器人之外,AI硬件与视听娱乐是创新科技展区的另一条重要主线,探索AI如何以更自然、更直观、更具沉浸感的方式,重塑人与技术之间的交互关系。
千问AI眼镜:阿里巴巴千问-最强模型最佳对话助手加持的超级智能终端
千问C端事业群隶属于阿里巴巴集团,聚焦打造“AI时代用户的第一入口”,专注于研发和落地以千问大模型为核心的智能AI终端设备。
本届展会中,搭载最新千问大模型的千问AI眼镜将在本届AWE上全系列亮相并可以上头体验。作为千问(Qwen)品牌在智能硬件领域的首款统一命名产品,它深度集成最新一代千问大模型,以“软件定义体验”为核心,打造真正“会聊天、能办事”的随身AI助手——语音交互自然流畅,多模态感知精准智能,覆盖翻译、办公、生活等全场景需求。

未来智能:深耕智能办公领域的软硬件一体化AI科技公司
未来智能是深耕智能办公领域的软硬件一体化AI科技公司,其讯飞AI会议耳机系列已连续三年销量第一。未来智能在语音语义识别领域拥有深厚积淀,致力于打造具有情感和个性化、多模态混合交互的智能AI助理。

本届展会上,未来智能将带来两大旗舰新品。讯飞AI会议耳机Pro3搭载viaim大脑,不仅支持32种语言实时互译与98%转写准确率,更具备智能摘要、任务提取及“语音嘴替”等革命性功能,仅需10秒录音即可生成个人声纹进行跨语言表达。声学方面,Pro3联合中国爱乐乐团定制调音,获Hi-Res金标认证,并通过AI智能降噪系统实现48dB深度降噪。
讯飞AI会议耳机Air2则主打开放式舒适体验,采用0.8mm航天级钛丝骨架与智能防漏音技术,单耳仅10克,支持53小时超长续航与离线闪录功能,完美兼顾了长时间佩戴的舒适性与突发会议的高效记录需求。未来智能正以AI助理与极致声学的双轮驱动,重构职场办公效率边界。
恩雅音乐(ENYA MUSIC):创新型科技音乐公司
恩雅音乐是一家集乐器研发、智能音频与音乐教育于一体的创新型科技音乐公司,秉承“技术驱动进步”理念,致力于通过数字化精准制造与音频算法技术降低音乐演奏门槛,其尤克里里与民谣吉他热销全球40多个国家。

本届展会上,恩雅带来了赛博吉他Cyber G。这款集高品质蓝牙音箱、智能伴奏鼓机、贝斯及8种乐器音色于一体的电子乐器,彻底颠覆了传统乐器的学习门槛。通过开创性的发光键盘设计与恩雅音乐APP联动,用户无需乐理基础,“哪里亮灯点哪里”即可轻松实现高水平弹唱,甚至一人掌控全场,化身赛博乐队。
Cyber G搭载专业级Remote DAW采样合成算法与强劲BSR技术音腔,不仅能惊艳还原原声乐器音色,还支持近百种律动风格的自由切换。其模块化设计更具未来感,键盘与琴柄可更换为真琴弦模块,变身专业MIDI吉他。产品支持5小时续航与多种音频接口,无论是耳机练习还是舞台演出,Cyber G都能让用户随时随地释放音乐想象。
整体来看,AWE2026创新科技展区所呈现的具身智能图景,清晰指向真实应用与商业可持续的下一阶段发展;同时,AI硬件与视听娱乐产品正在成为连接技术创新与大众消费的重要桥梁,为未来智能终端与数字娱乐的演进提供了极具想象力的发展方向。

在AWE2026的整体版图中,创新科技展区将成为最具科技浓度、最具生命力、最具未来感的区域之一。这里,或许正孕育着下一个改变消费与生活方式的新物种。
3月12-15日,上海新国际博览中心,AWE2026见!