全网最全面的web性能优化详解
文中用到的工具方法性能工具方法库
免费的面试合集 - cookguo.github.io/learn/brows… 整理不易,给个免费的star就行了,兄弟们。
目录
- 第一章:为什么性能优化很重要
- 第二章:Web 性能指标全景
- 第三章:Chrome DevTools 性能分析工具实战
- 第四章:LCP 优化深度指南
- 第五章:INP 优化深度指南
- 第六章:CLS 优化深度指南
- 第七章:TTFB 与网络优化
- 第八章:代码层面的通用优化
- 第九章:综合实战——完整性能排查流程
- 第十章:性能监控与持续改进
第一章:为什么性能优化很重要
1.1 用数据说话:性能与业务的直接关联
很多初学者会问:页面慢一点,用户忍一忍不就好了吗?事实并非如此。性能问题直接影响用户留存和业务收入,这不是假设,而是有大量真实数据支撑的结论。
根据 2025 年的行业数据:
- 性能优化不达标可能导致 8% 到 35% 的转化率、排名和收入损失
- Google 的研究显示,页面加载时间从 1s 增加到 3s,跳出率增加 32%;增加到 5s,跳出率增加 90%
- Pinterest 将感知等待时间减少 40%,搜索引擎流量和注册量增加了 15%
- BBC 发现每增加一秒的加载时间,额外损失 10% 的用户
对于 Web3 钱包等金融类应用,用户的容忍度更低。当用户在进行交易操作时,一个卡顿的交互体验不仅影响用户留存,更会直接影响用户对产品安全性的信任感。
1.2 搜索引擎排名的硬性要求
2021 年,Google 正式将 Core Web Vitals(核心网页指标)纳入搜索排名算法。这意味着:
- 如果你的页面 LCP 超过 4 秒,搜索排名会受到明显的负面影响
- Core Web Vitals 包括 LCP(最大内容绘制)、INP(与下一次绘制的交互)、CLS(累积布局偏移)
- 目前全球只有 48% 的移动页面和 56% 的桌面页面通过全部三项 Core Web Vitals
这一数据意味着,做好性能优化本身就是竞争优势。
1.3 用户体验的心理学
人类对时间的感知并不是线性的:
-
0-100ms:用户感觉是"即时"的,操作如丝般顺滑
-
100-300ms:用户感觉是"流畅"的,可以接受
-
300-1000ms:用户感觉有"延迟",开始不耐烦
-
1000ms 以上:用户的注意力开始转移,心流被打断
-
10s 以上:用户往往直接放弃
因此,性能目标不仅仅是"能用",而是要达到让用户感觉"快"的心理阈值。
1.4 前端性能的三个维度
理解性能优化,需要从三个维度思考:
-
加载性能:页面从开始加载到用户能看到内容需要多长时间(LCP、FCP、TTFB)
-
交互性能:用户操作页面时的响应速度(INP、FID)
-
视觉稳定性:页面内容是否会在加载过程中发生意外移动(CLS)
这三个维度互相独立,需要分别进行诊断和优化。
第二章:Web 性能指标全景
2.1 Core Web Vitals:最重要的三个指标
Core Web Vitals 是 Google 定义的三个核心用户体验指标,是性能优化的重中之重。
LCP(Largest Contentful Paint,最大内容绘制)
定义:从页面开始加载到视口中最大的图片或文本块完成渲染的时间。
阈值标准:
- 良好:< 2.5 秒
- 需改进:2.5 秒 ~ 4 秒
- 差:> 4 秒
哪些元素会被计为 LCP 元素?
-
<img> 元素
-
<image> SVG 内的元素
-
<video> 元素(使用海报图像时)
- 通过
url() 函数加载了背景图片的元素
- 包含文本节点或其他内联文本元素子级的块级元素
需要特别注意的是,浏览器会排除"无意义"的内容,例如透明度为 0 的元素、尺寸为 0 的元素等,不会将其计为 LCP 候选元素。
INP(Interaction to Next Paint,与下一次绘制的交互)
定义:衡量用户与页面的每次离散交互(点击、键盘按键、触摸)从交互发生到下一帧绘制的延迟时间。INP 取的是页面整个生命周期内所有交互延迟的最大值(排除一些异常值)。
INP 的三个阶段:
-
Input Delay(输入延迟) :从用户操作到事件处理程序开始执行的时间,受主线程上正在执行的长任务影响
-
Processing Time(处理时间) :事件处理程序本身的执行时间
-
Presentation Delay(呈现延迟) :从事件处理完成到浏览器绘制下一帧的时间,包括样式计算、布局、绘制
阈值标准:
- 良好:< 200 毫秒
- 需改进:200 ~ 500 毫秒
- 差:> 500 毫秒
注意:INP 于 2024 年 3 月正式替代 FID(First Input Delay,首次输入延迟)成为 Core Web Vitals 的一部分。INP 比 FID 更严格,因为它衡量的是整个页面生命周期内的交互响应,而不仅仅是首次交互。
CLS(Cumulative Layout Shift,累积布局偏移)
定义:衡量页面在加载过程中元素发生意外移动的程度。当一个可见元素从一帧到下一帧改变位置时,就会发生布局偏移。
计算方式:
布局偏移分数 = 影响分数 × 距离分数
影响分数 = 受影响的视口比例
距离分数 = 元素移动的最大距离 / 视口高度
阈值标准:
- 良好:< 0.1
- 需改进:0.1 ~ 0.25
- 差:> 0.25
2.2 其他重要性能指标
FCP(First Contentful Paint,首次内容绘制)
定义:浏览器第一次渲染任何文本、图像、非白色 canvas 或 SVG 的时间。
阈值:良好 < 1.8 秒
FCP 是用户感知到"页面开始加载"的时间点,是 LCP 的前置指标。如果 FCP 就很慢,LCP 一定不会快。
TTFB(Time to First Byte,首字节时间)
定义:从浏览器发出 HTTP 请求到接收到第一个字节响应的时间。
阈值:良好 < 200 毫秒
TTFB 是所有加载指标的基础,它反映的是服务器响应速度和网络延迟。如果 TTFB 很高,无论前端如何优化,LCP 都很难达标。
TTI(Time to Interactive,可交互时间)
定义:页面从加载开始到能够可靠地响应用户输入所需的时间。
TTI 要求满足:
- 页面显示了有用内容(FCP 之后)
- 大多数可见元素的事件处理程序已注册
- 页面在 50ms 内响应用户交互
TBT(Total Blocking Time,总阻塞时间)
定义:FCP 和 TTI 之间所有长任务(执行时间超过 50ms 的任务)的阻塞时间之和。一个长任务的阻塞时间 = 任务时长 - 50ms。
阈值:良好 < 200 毫秒
TBT 是衡量 JavaScript 执行对主线程占用程度的关键指标。在真实案例中,我们曾发现一个页面的 TBT 高达 69,747ms,有 506 个长任务,最长单个任务达 4,771ms。这种情况下,页面几乎完全无法交互。
2.3 指标之间的关联关系
网络请求开始
│
▼
TTFB(服务器响应速度)
│
▼
FCP(首次内容出现)
│
├──► LCP(最大内容出现)← 加载性能核心
│
├──► TTI(页面可交互)
│ │
│ ▼
│ TBT(阻塞时间)← JS 执行质量
│
└──► INP(交互响应速度)← 交互性能核心
CLS(布局稳定性)─── 贯穿整个加载过程
理解这个关系图对于排查性能问题至关重要:如果 TTFB 就慢,要从服务器和网络层面解决;如果 FCP 慢但 TTFB 正常,要看 CSS 和关键资源阻塞;如果 LCP 慢,要看最大元素的渲染和加载;如果 INP 差,要看 JavaScript 长任务。
第三章:Chrome DevTools 性能分析工具实战
3.1 工具概览
Chrome DevTools 提供了多个用于性能分析的面板,每个面板有不同的侧重点:
| 面板 |
用途 |
适合分析 |
| Performance |
录制运行时性能 |
长任务、帧率、CPU 占用 |
| Lighthouse |
综合性能审计 |
所有 Core Web Vitals |
| Network |
网络请求分析 |
资源加载、TTFB、优先级 |
| Memory |
内存分析 |
内存泄漏、堆快照 |
| Coverage |
代码覆盖率 |
未使用的 JS/CSS |
3.2 Lighthouse 面板实战
Lighthouse 是最适合初学者入手的性能分析工具,它能一键给出综合评分和改进建议。
使用步骤:
- 打开 Chrome DevTools(F12 或右键 → 检查)
- 切换到 Lighthouse 标签页
- 选择要分析的类别(勾选 Performance)
- 选择设备类型(推荐先选 Mobile 模拟移动端,因为移动端更严格)
- 点击 Analyze page load 按钮
- 等待约 30 秒,查看报告
📸 Lighthouse 面板配置界面(设备类型、分析类别、清除缓存选项):
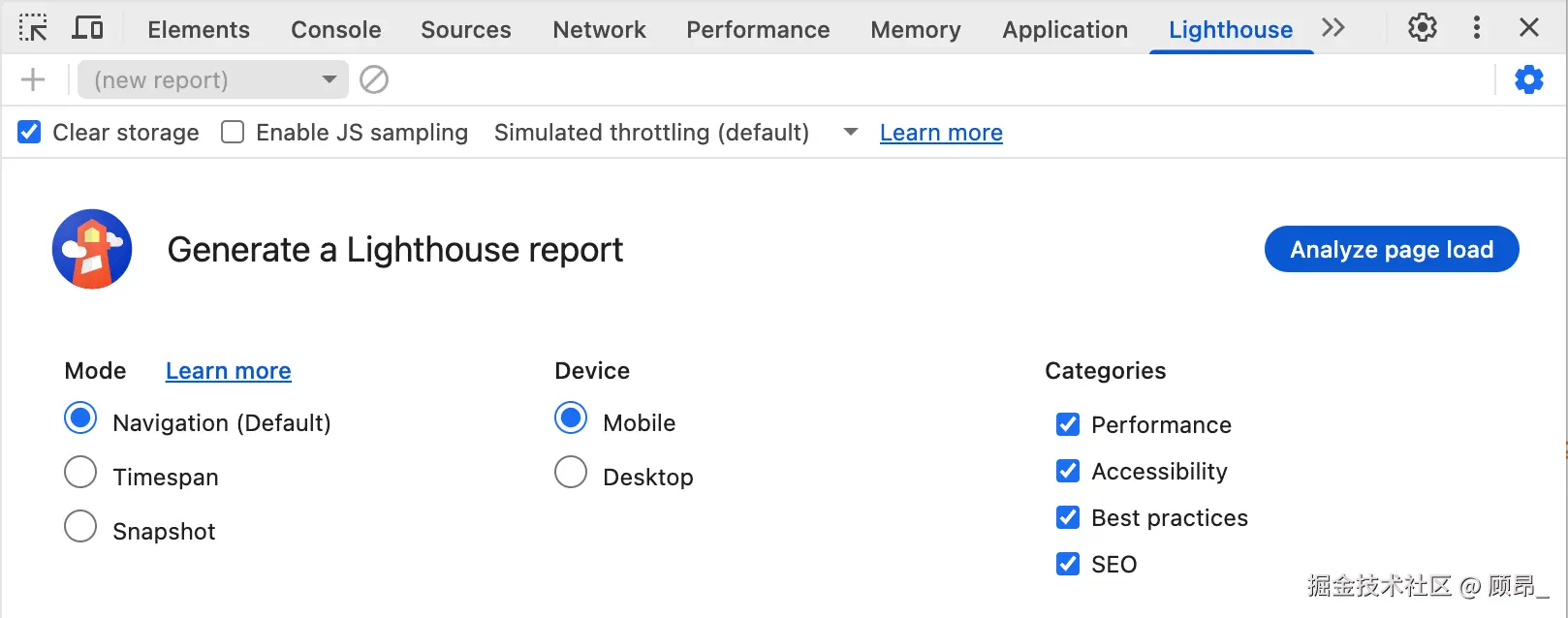
面板上方可以选择:Mode(Navigation / Timespan / Snapshot)、Device(Mobile / Desktop)、Categories(Performance 必须勾选)。建议勾选 Clear storage 模拟新用户首次访问。
读懂 Lighthouse 报告:
Lighthouse 会给出 0-100 的综合评分,并列出 Metrics 和 Opportunities 两部分:
-
Metrics 部分:显示各项核心指标的具体数值和评级(绿色良好、橙色需改进、红色差)
-
Opportunities 部分:列出具体的优化建议,每条建议都会估算优化后能节省的时间
-
Diagnostics 部分:列出可能影响性能的问题,例如"避免过大的 DOM 节点"
重要提示:Lighthouse 的测试结果会受到本地网络状况、CPU 性能等因素影响。建议:
- 在隐身模式下运行,避免浏览器扩展干扰
- 多次运行取平均值
- 关闭其他占用资源的程序
3.3 Performance 面板深度使用
Performance 面板是最强大也最复杂的性能分析工具,它能录制页面运行时的每一帧,让你看到 JavaScript 执行、样式计算、布局绘制的完整时间线。
录制性能分析:
- 打开 Performance 面板
- 点击左上角的 录制按钮(圆圈图标) 开始录制
- 在页面上执行你想分析的操作(如点击按钮、滚动页面)
- 点击 停止 按钮
- 等待分析完成,查看时间线
📸 录制控制按钮位置(左上角圆形录制键,右下角也有一个快捷键):
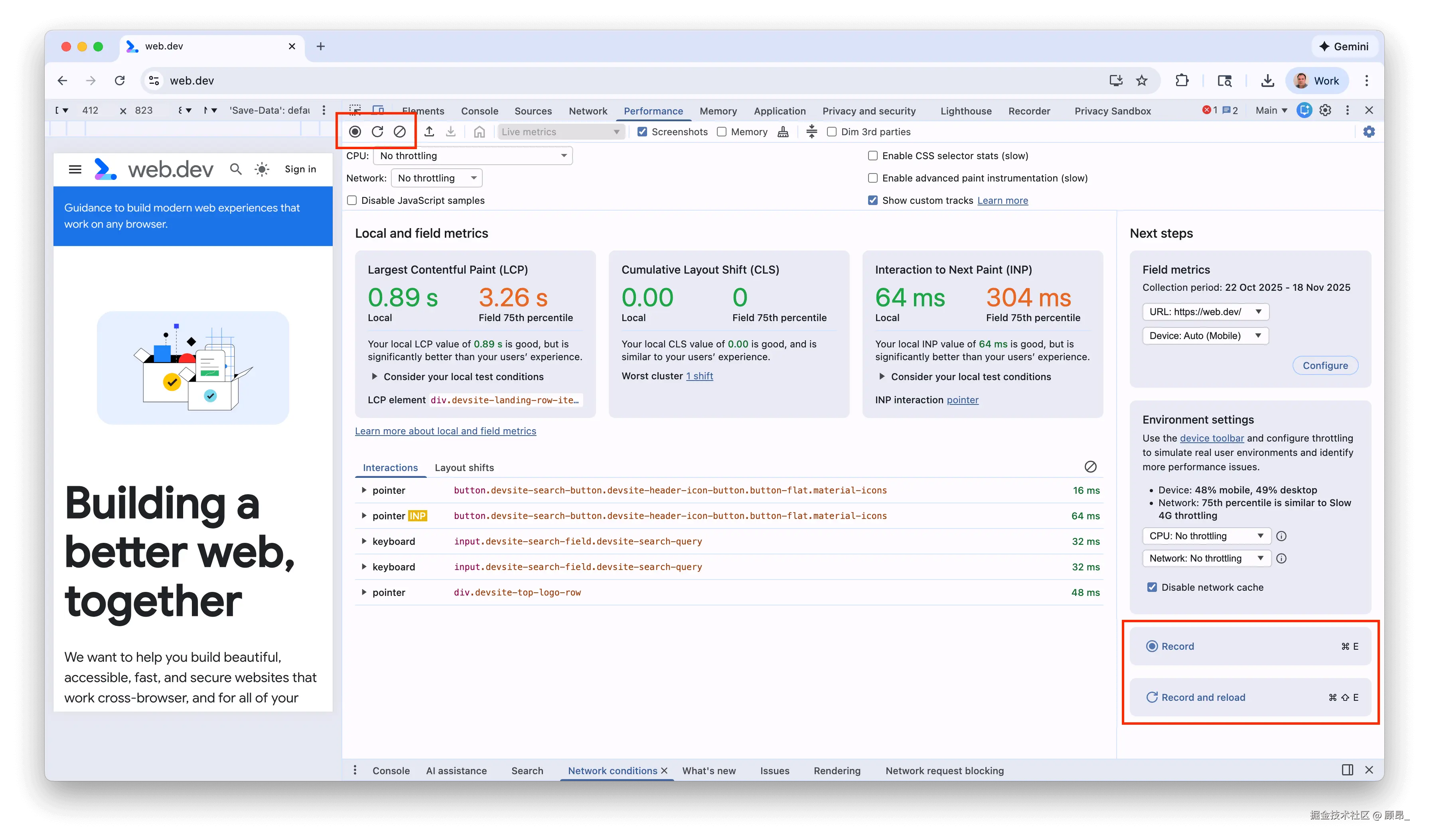
读懂 Performance 面板:
Performance 面板分为几个区域,从上到下依次是:
① 概览区域(Overview) :
- 顶部的彩色条带展示 FPS(帧率)、CPU 占用、网络请求的整体情况
- 绿色区域表示帧率正常(60fps),红色区域表示帧率下降
- CPU 区域颜色越深表示 CPU 越繁忙:黄色是 JavaScript,紫色是渲染,绿色是绘制
📸 Overview 概览区域(上方 CPU/NET 条带 + 下方时间线选区):
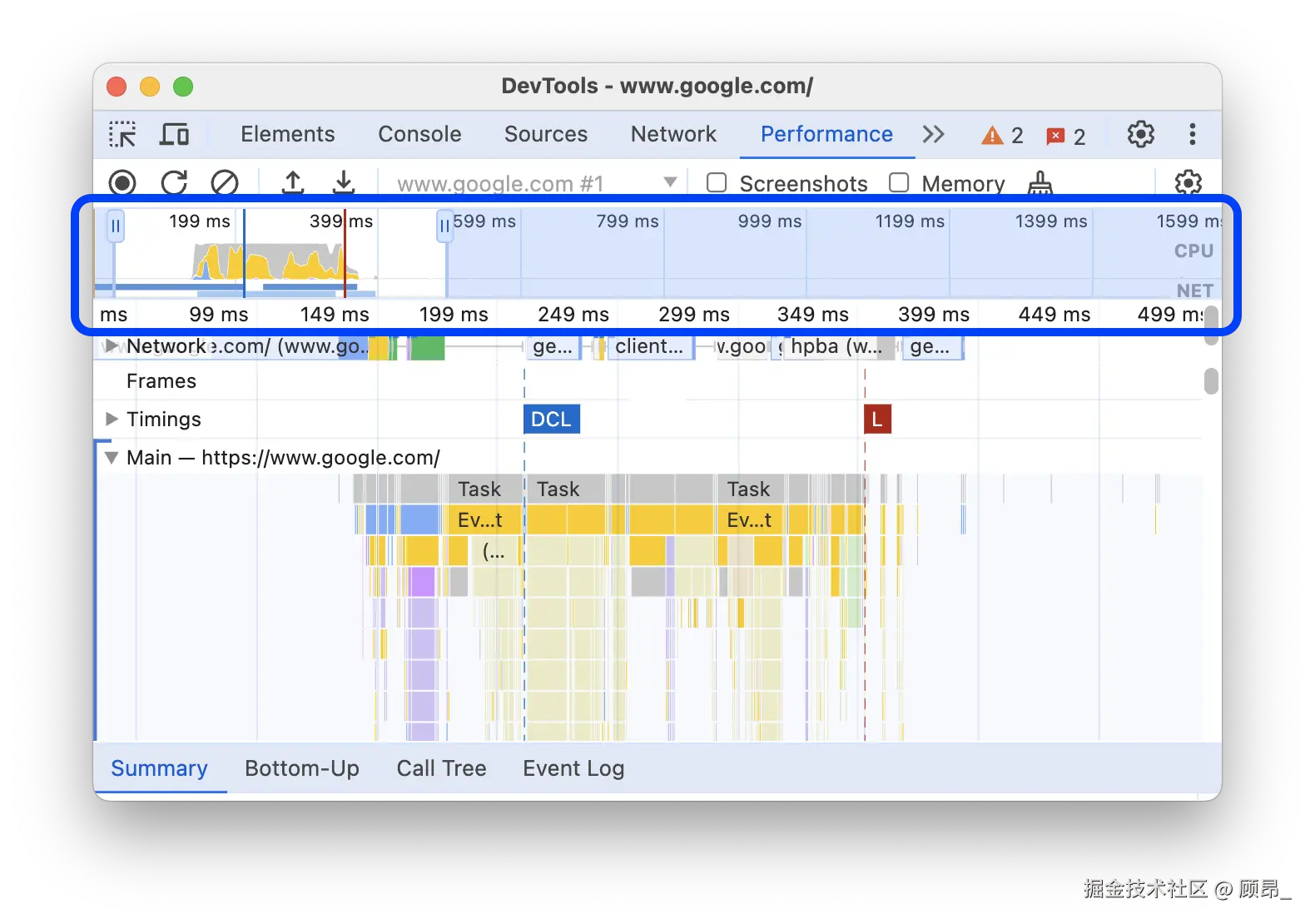
拖动下方的灰色选区可以放大特定时间段,方便精细分析。
② 主线程区域(Main) :
- 这是最关键的区域,展示主线程上发生的所有活动
- 每个彩色块代表一个任务,高度表示任务的调用深度
-
长任务(Long Task)会被标记为红色三角形 ← 这是你需要重点关注的地方
- 点击任何一个色块,可以在底部看到该任务的详细信息
📸 Main 主线程区域(每个色块是一个任务,底部是 Summary 详情):
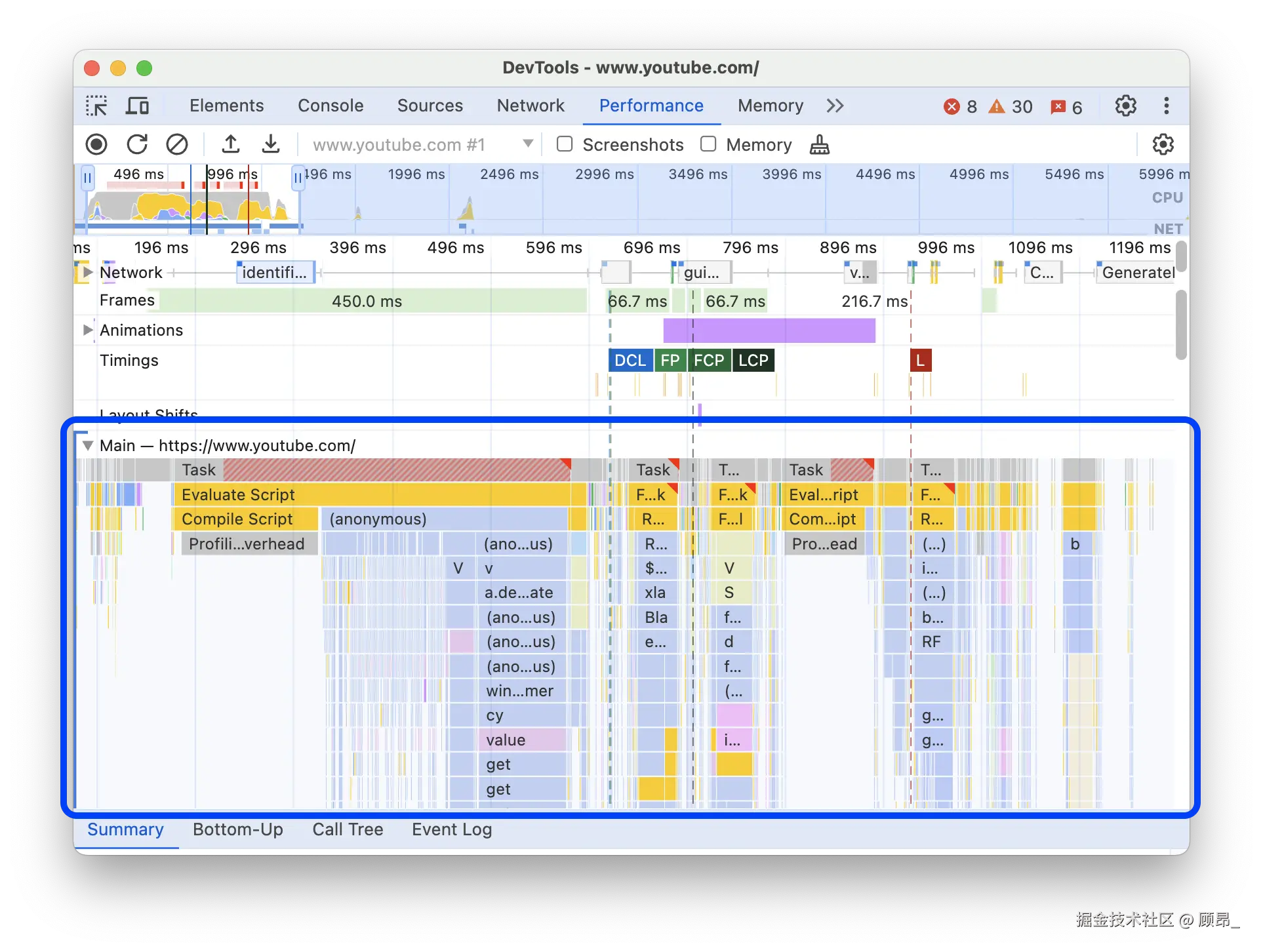
点击任意色块后,底部 Summary 标签页 会显示该任务的耗时分解(Scripting / Rendering / Painting)。
③ 识别长任务(最重要) :
在 Main 区域,找到顶部有 红色三角形 的任务块,这些就是超过 50ms 的长任务。展开这个任务块,可以看到:
- 哪个函数占用了最多时间
- 调用栈的完整链路
- 每个函数的自身时间(Self Time)和总时间(Total Time)
📸 Long Task 标记(红色三角形 + 超出 50ms 部分用红色斜线标注):
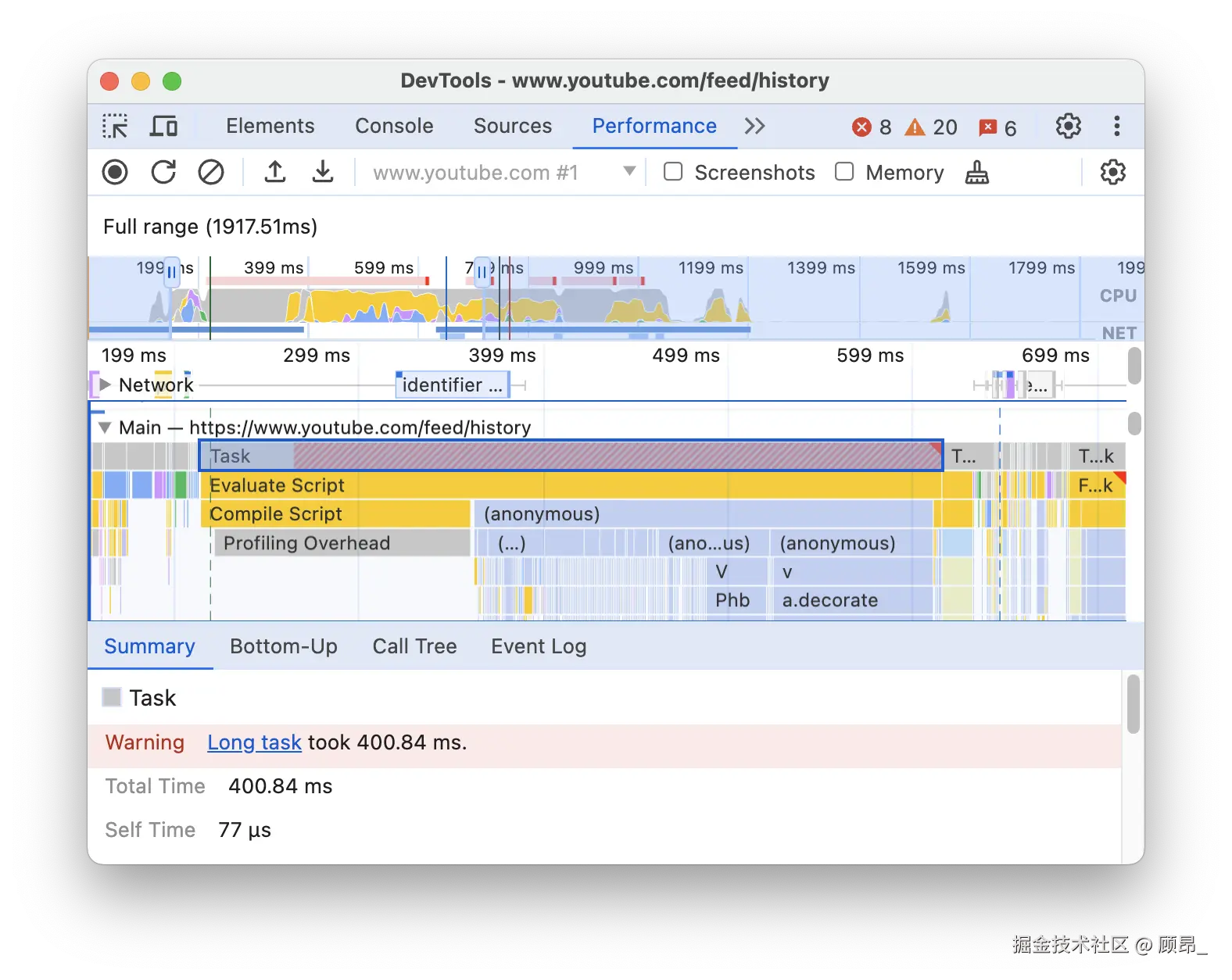
如何读这个图:任务块顶部出现红色三角旗标,任务超出 50ms 的部分会用红色斜线填充。任务越宽表示执行时间越长,越高表示调用层级越深。
④ 火焰图(Flame Chart)——找到最耗时函数:
点击长任务块并放大后,可以看到火焰图。火焰图是从上到下的函数调用栈:最顶层是入口函数,往下每一层是被调用的子函数。
📸 火焰图详情(点击 click 事件后可看到完整调用链):
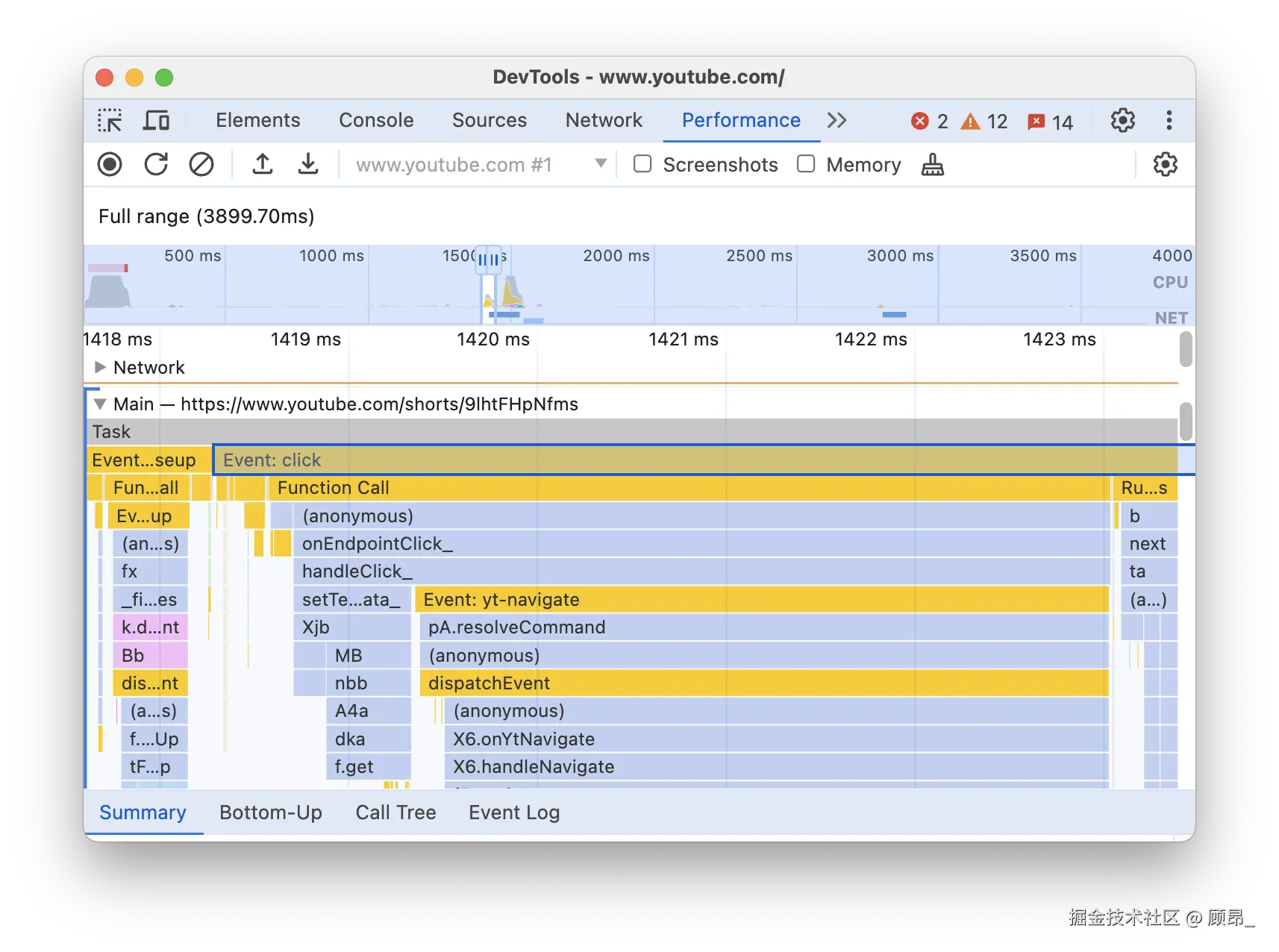
技巧:找到"宽度最大"且"位于底层"的色块,那就是最耗时的叶子函数(Self Time 最高的函数),优先优化它。
⑤ 性能时间点标记(FCP / LCP / DCL / Load) :
时间线上会有几条垂直的彩色线,对应关键时间点:
📸 关键时间点标记线(FCP 绿线、LCP 绿线、DCL 蓝线、Load 红线):
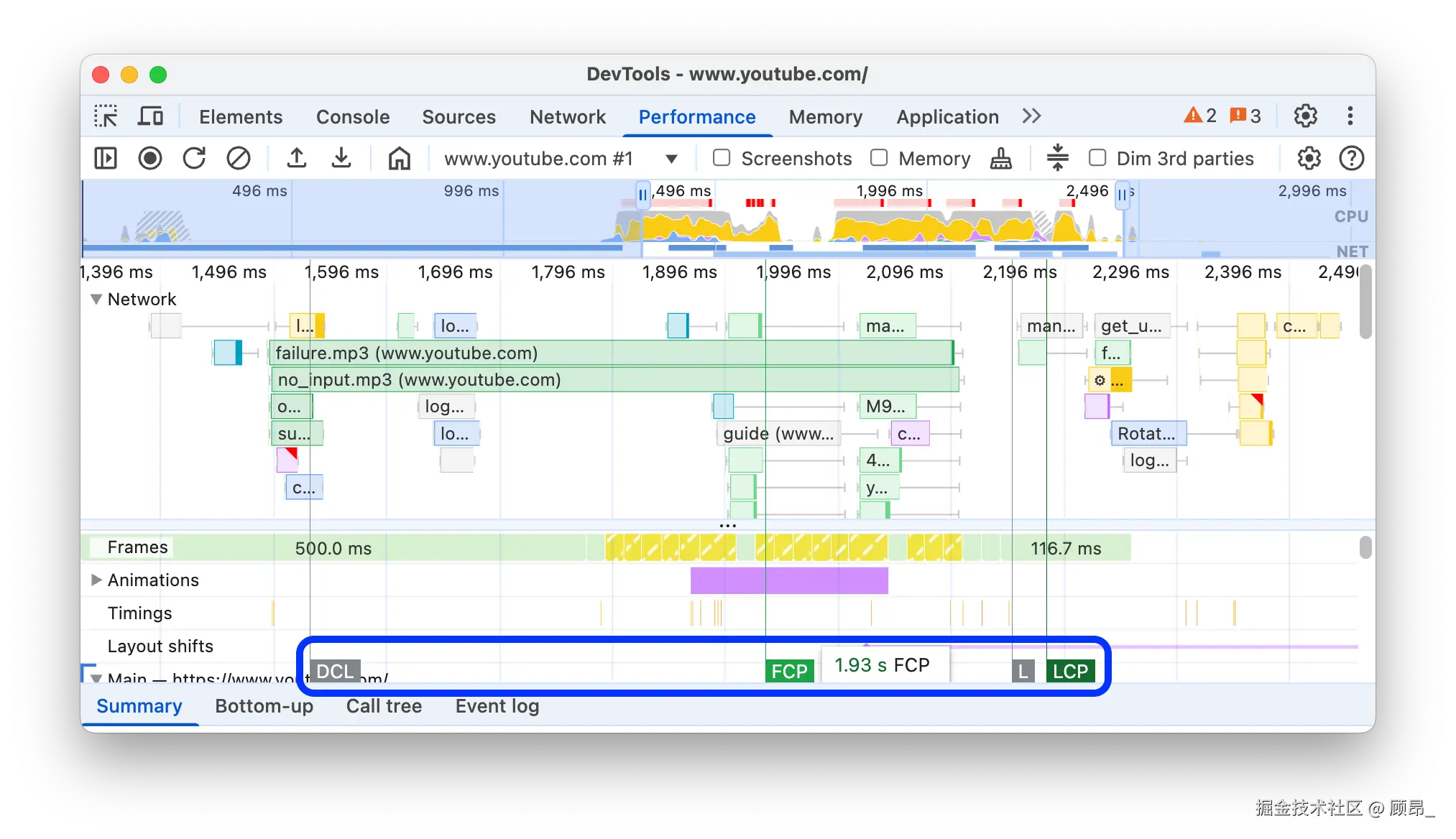
-
FCP(绿色) :第一块内容出现的时间
-
LCP(绿色,更靠后) :最大内容出现的时间
-
DCL(蓝色) :HTML 解析完成
-
Load(红色) :所有资源加载完成
实际案例:在我们的内部性能分析中,发现某页面存在以下问题:
- Long Tasks 总数:506 个
- TBT:69,747ms
- 最长 Long Task:4,771ms
-
querySelectorAll 是最大瓶颈(合计 4,176ms)
- Web3 加密库占 CPU 42.3%
- DOM/Native API 占 CPU 29.5%
- React DOM 占 CPU 13.8%
从这个数据可以得出结论:需要优化 DOM 查询(将 querySelectorAll 结果缓存),并考虑将加密库运算移入 Web Worker。
3.4 Chrome DevTools 2025 新特性
Live Metrics 实时指标面板:
在 Performance 面板中,Chrome 现在提供了 Live Metrics 功能,可以在你正常使用页面的同时,实时显示 LCP、INP、CLS 的当前数值。
使用方法:
- 打开 Performance 面板
- 找到 Live Metrics 区域(在面板右侧)
- 正常操作页面,观察指标变化
- 当某个指标变红时,说明触发了一次不良的交互或渲染
📸 Live Metrics 实时面板(左侧本地实测值 + 右侧 CrUX 字段真实用户数据):
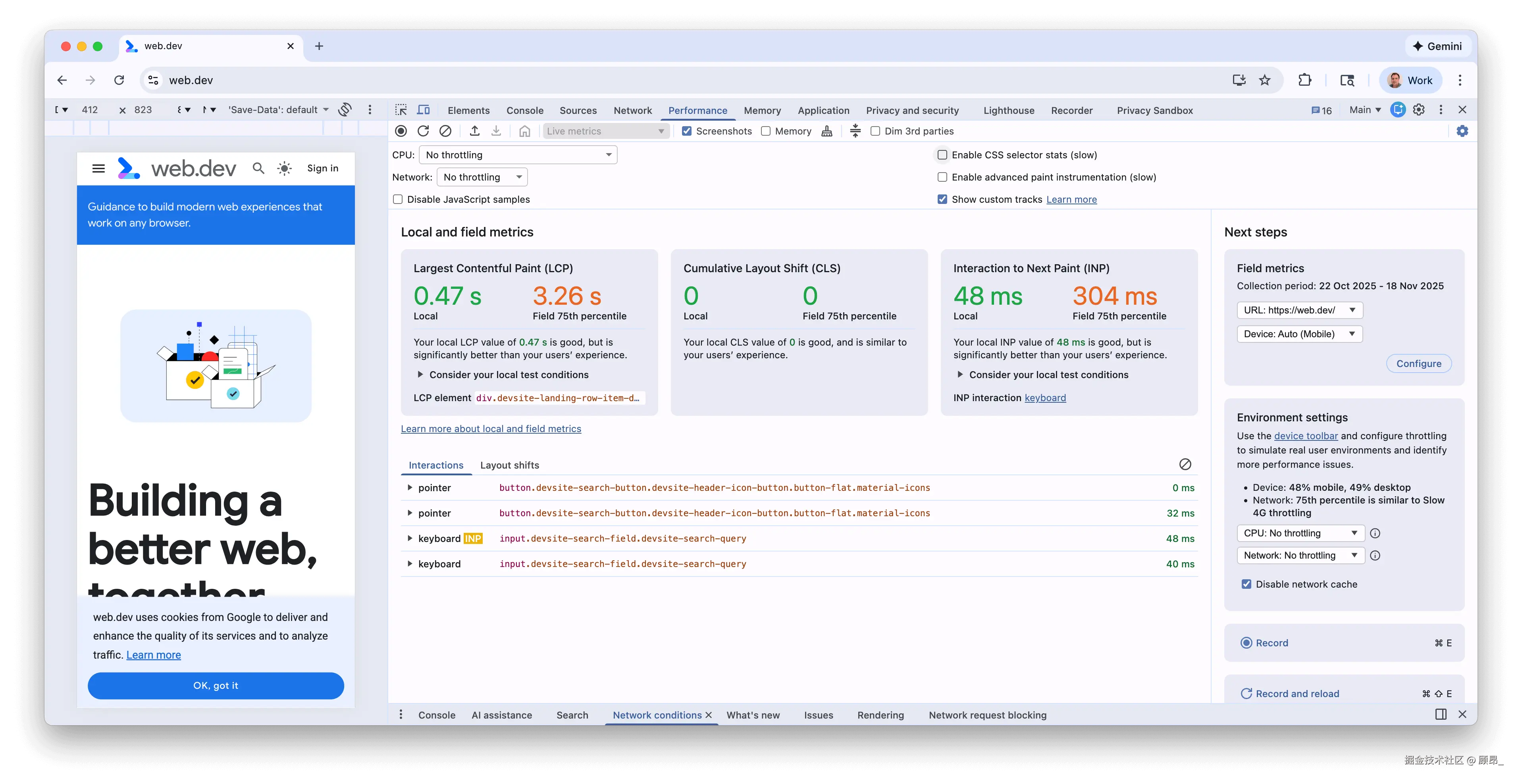
面板分两列:本地(Local) 是你当前浏览器实测值,字段数据(Field) 是来自 CrUX 的真实用户数据。悬停指标数值可以展开该指标的各阶段细分(如 LCP 的 TTFB / Load Delay / Load Time / Render Delay)。
这个功能特别适合快速定位是哪个操作导致了 INP 变差。
INP 交互日志(Interactions Track) :
录制结束后,Performance 面板中有一条 Interactions 轨道,记录了所有被计入 INP 的用户交互:
📸 Interactions 轨道(每次交互显示 Input Delay + Processing + Presentation 三段时间条):
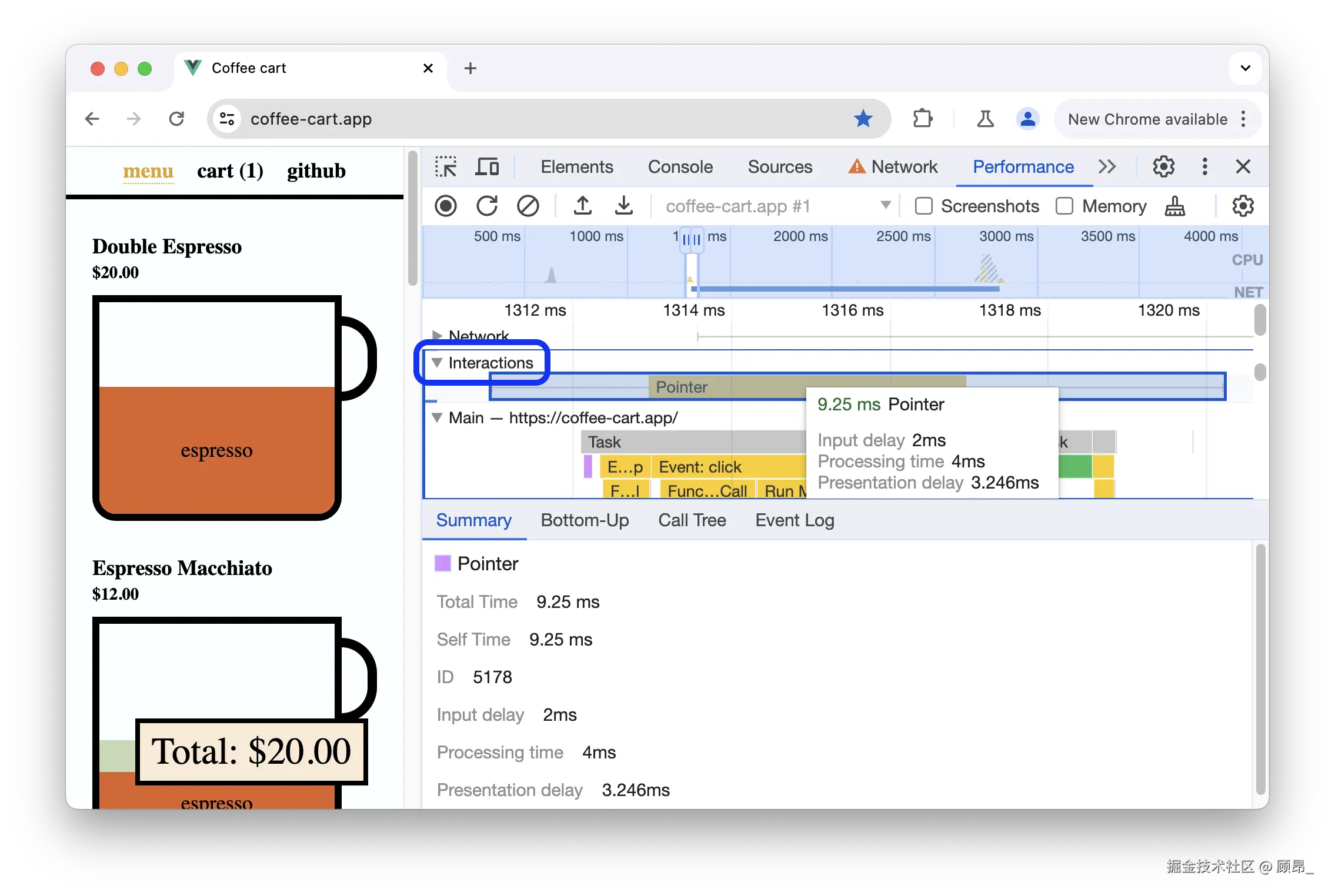
点击某条交互记录,可以展开看三个阶段的耗时:
-
Input Delay(灰色) :点击到事件处理开始,越短越好
-
Processing(黄色) :事件处理函数执行时间,这里优化 → 用 taskSplitPoint/asyncExecuteTask
-
Presentation(紫色) :渲染到下一帧,这里优化 → 减少重排/重绘
AI 驱动的性能 Insights:
Chrome DevTools 现在内置了 AI 性能分析功能,在 Performance 录制结束后,可以点击 Insights 面板,AI 会自动识别关键瓶颈并给出优化建议。
校准节流(Calibrated Throttling) :
在 Performance 面板的节流设置中,Chrome 现在支持根据你当前机器的性能自动校准节流比例,使模拟的移动端性能更准确。
3.5 Network 面板分析资源加载
找到 LCP 图片的加载时间:
- 打开 Network 面板
- 刷新页面
- 在请求列表中找到你认为的 LCP 图片
- 点击该请求,查看 Timing 标签页
Timing 标签页会显示:
-
Queued at:请求在哪个时间点被排队
-
Stalled:等待发送的时间(通常是连接复用等待)
-
Waiting (TTFB) :首字节时间
-
Content Download:下载时间
📸 Network 面板选中某个请求后的 Timing 详情:
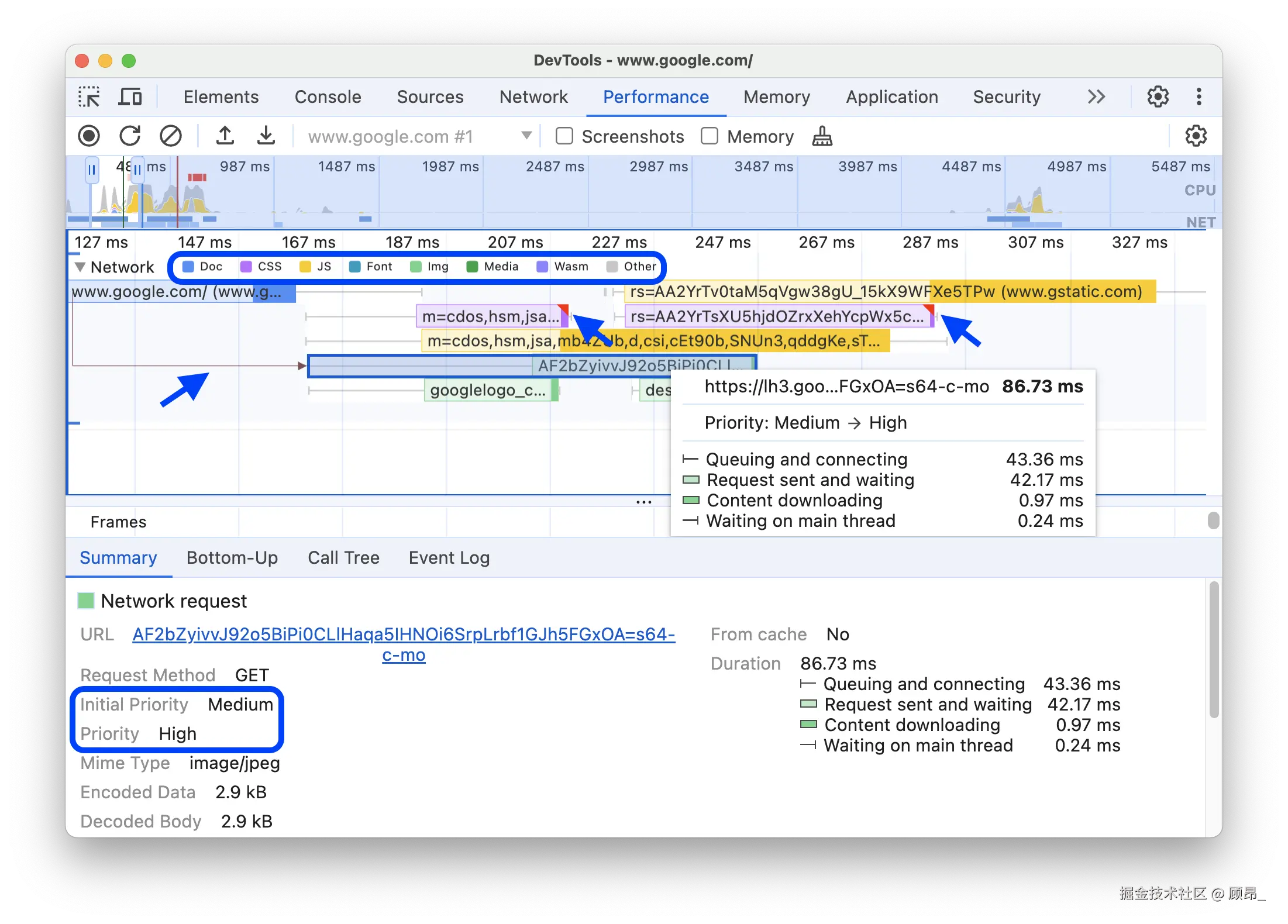
如何判断问题所在:
-
Waiting (TTFB) 时间长 → 服务器响应慢,考虑 CDN 或服务器优化
-
Content Download 时间长 → 文件太大,考虑压缩或格式转换(WebP)
-
Stalled 时间长 → 连接数限制导致排队,考虑 HTTP/2 或 preconnect
查看资源加载优先级:
在 Network 面板的请求列表中,右键任意列标题,勾选 Priority 列,可以看到每个资源的加载优先级。
LCP 图片的优先级应该是 Highest,如果显示为 Low 或 Medium,就需要使用 fetchpriority="high" 属性来提升它。
💡 快速定位 LCP 图片的技巧:在 Network 面板按 Img 类型过滤,然后看哪张图片的开始时间最晚且体积最大,大概率就是 LCP 元素。
3.6 Coverage 面板:找到未使用的代码
- 打开 Coverage 面板(可以通过 Ctrl+Shift+P 搜索 "Coverage" 打开)
- 点击录制按钮
- 刷新页面并操作
- 停止录制,查看结果
Coverage 面板会列出每个 JS/CSS 文件,并显示有多少百分比的代码在本次操作中被执行。如果一个文件 90% 的代码都是红色(未使用),说明代码分割可以带来很大的性能提升。
3.7 一图总结:Chrome DevTools 性能分析全流程
第一步:快速体检 第二步:精细录制 第三步:定位问题
┌──────────────────┐ ┌──────────────────┐ ┌──────────────────┐
│ Lighthouse │ │ Performance 面板 │ │ Network 面板 │
│ │ │ │ │ │
│ 一键生成评分 │──→ │ 录制交互操作 │──→ │ 找 LCP 图片 │
│ 找到 LCP/INP/ │ │ 找 Long Task │ │ 查 Priority 列 │
│ CLS 的问题点 │ │ 看火焰图 │ │ 看 Timing 详情 │
│ │ │ 看 Interactions │ │ │
└──────────────────┘ └──────────────────┘ └──────────────────┘
↓ ↓ ↓
确认哪个指标差 找到是哪个函数慢 找到资源加载瓶颈
↓ ↓ ↓
对应第四/五/六章 用 taskSplitPoint 等 加 fetchpriority
优化方案 工具优化 或 preload 优化
第四章:LCP 优化深度指南
4.1 LCP 的计算原理
理解 LCP 的计算方式,是优化的基础。
LCP 的候选元素在整个页面加载过程中是动态更新的。浏览器每渲染一帧,都会检查是否有比当前候选元素更大的元素出现。最终的 LCP 值是页面上出现的最大可见元素完成渲染的时间点。
LCP 计算会排除的元素:
- 透明度为 0(
opacity: 0)的元素
- 尺寸为 0x0 的元素
-
visibility: hidden 的元素
- 覆盖整个视口的元素(被认为是背景)
这个排除规则非常关键,后面的优化技巧会用到它。
4.2 诊断 LCP 慢的原因
LCP 慢通常有以下几种原因:
-
服务器响应慢(TTFB 高) :在第一个字节到达之前,什么都无法开始渲染
-
渲染阻塞资源:
<head> 中的同步 CSS 和 JS 会阻塞渲染
-
资源加载慢:LCP 图片文件太大,或加载优先级低
-
客户端渲染延迟:LCP 元素由 JavaScript 动态生成,需要等待 JS 执行完成
诊断步骤:
打开 Lighthouse,在 LCP 的详情中,Chrome 会告诉你 LCP 的四个阶段各占了多少时间:
-
TTFB:服务器响应
-
Load Delay:从 TTFB 到开始加载 LCP 资源
-
Load Time:LCP 资源的加载时间
-
Render Delay:从资源加载完成到实际渲染
针对不同的瓶颈阶段,采取不同的优化策略。
4.3 LCP 图片优化技术
技术一:使用 fetchpriority="high" 提升图片优先级
这是最简单有效的优化手段之一。浏览器默认会给 LCP 图片分配较低的加载优先级,通过 fetchpriority 属性可以显式提升:
<!-- 优化前:浏览器可能将图片优先级设为 Low -->
<img src="hero-image.webp" alt="主图" />
<!-- 优化后:显式告知浏览器这是高优先级资源 -->
<img src="hero-image.webp" alt="主图" fetchpriority="high" />
注意:fetchpriority="high" 只应该用于真正的 LCP 元素,不要滥用,否则会适得其反。
技术二:使用 <link rel="preload"> 预加载
对于通过 CSS background-image 或 JavaScript 动态加载的图片,浏览器无法在解析 HTML 时就发现并预加载,需要通过 preload 主动告知浏览器:
<head>
<!-- 预加载 LCP 图片,让浏览器尽早开始加载 -->
<link rel="preload" as="image" href="hero-image.webp" />
<!-- 对于 srcset 图片,需要指定 imagesrcset -->
<link
rel="preload"
as="image"
href="hero-image.webp"
imagesrcset="hero-small.webp 400w, hero-large.webp 800w"
imagesizes="100vw"
/>
</head>
在构建系统中,可以通过配置自动注入 preload 标签:
{
"links": [{
"url": "hero-image.webp",
"attrs": {
"rel": "preload",
"as": "image"
}
}]
}
技术三:使用 WebP 格式减小图片体积
WebP 相比 PNG 和 JPEG,在相同视觉质量下通常能减小 25%-50% 的文件体积:
<!-- 使用 picture 元素,兼容不支持 WebP 的浏览器 -->
<picture>
<source srcset="hero.webp" type="image/webp" />
<source srcset="hero.jpg" type="image/jpeg" />
<img src="hero.jpg" alt="主图" fetchpriority="high" />
</picture>
实际数据:一张 500KB 的 PNG 图片,转换为 WebP 后通常在 100-200KB,加载时间可以缩短 60%-80%。
技术四:GIF 首帧优化
对于大尺寸 GIF 动图,可以先加载轻量级的首帧图片(通常是静态 PNG),待 GIF 加载完成后再切换:
// hooks/useGifImg.ts
import { useState, useMemo } from 'react';
import { useAsyncEffect } from 'ahooks';
/**
* 加载指定图片,返回 Promise
*/
const loadImg = ({ src }: { src: string }): Promise<boolean> => {
return new Promise((resolve) => {
const img = new Image();
img.onload = () => resolve(true);
img.onerror = () => resolve(false);
img.src = src;
});
};
/**
* GIF 图片优化 Hook
* 策略:先展示首帧静态图(thumbnailUrl),GIF 加载完成后切换
*/
export const useGifImg = ({
src,
thumbnailUrl,
}: {
src: string;
thumbnailUrl?: string;
}) => {
// 初始展示首帧(如果有的话),否则直接展示原图
const [displayUrl, setDisplayUrl] = useState(thumbnailUrl || src);
const isGif = useMemo(() => src.toLowerCase().endsWith('.gif'), [src]);
useAsyncEffect(async () => {
if (isGif && thumbnailUrl) {
// 异步加载 GIF,加载完成后切换
const isSuccess = await loadImg({ src });
if (isSuccess) {
setDisplayUrl(src);
}
}
}, [src]);
return { isGif, displayUrl };
};
// 使用示例
function HeroImage({ gifSrc, thumbnailSrc }) {
const { displayUrl } = useGifImg({ src: gifSrc, thumbnailUrl: thumbnailSrc });
return (
<img
src={displayUrl}
alt="动态主图"
fetchpriority="high"
/>
);
}
技术五:背景图 Base64 占位优化
当 LCP 元素是一张需要通过网络加载的背景图时,可以用一张极小的 base64 内联图片作为占位符。这样 LCP 元素在页面 HTML 加载完成时就已经"出现"了,LCP 时间会大幅提前:
// 一个很小的纯色 base64 图片(约 100 字节)
// 颜色可以和实际背景图的主色调匹配,减少视觉突变
const DEFAULT_BG_BASE64 = 'data:image/png;base64,iVBORw0KGgoAAAANSUhEUgAAAAEAAAABCAYAAAAfFcSJAAAADUlEQVR42mNk+M9QDwADhgGAWjR9awAAAABJRU5ErkJggg==';
/**
* 带 LCP 优化的背景图组件
* 策略:
* 1. 立即展示 base64 小图(作为 LCP 元素上报)
* 2. 实际背景图加载完成后覆盖
*/
const OptimizedBgImage = ({ src, alt, children }) => {
return (
<div style={{ position: 'relative', overflow: 'hidden' }}>
{/* LCP 占位图:base64,立即渲染,作为 LCP 元素 */}
<img
src={DEFAULT_BG_BASE64}
alt={alt}
style={{
position: 'absolute',
top: 0,
left: 0,
width: '100%',
height: '100%',
zIndex: 0,
// 注意:不能设置 opacity: 0,否则会被 LCP 排除
}}
/>
{/* 实际背景图:通过 CSS 加载,不影响 LCP 计算 */}
<div
style={{
position: 'absolute',
top: 0,
left: 0,
width: '100%',
height: '100%',
backgroundImage: `url(${src})`,
backgroundSize: 'cover',
zIndex: 1,
}}
/>
{/* 内容层 */}
<div style={{ position: 'relative', zIndex: 2 }}>
{children}
</div>
</div>
);
};
4.4 LCP 优化的终极技巧:主动"指定" LCP 元素
这是一个来自实战的进阶技巧。
背景:在某个项目中,页面真正有意义的 LCP 元素是一张很快就加载完成的小图。但页面还有一个用户引导弹层,弹层里有一张更大的图片。由于弹层是通过 JavaScript 渲染的,要等 JS 执行完才显示,而且弹层图片的尺寸更大,导致浏览器将弹层图片判定为 LCP 元素,LCP 时间被拉到了 5 秒以上。
解决方案:在页面首屏 HTML 中放置一个尺寸更大的占位图,让浏览器优先将它识别为 LCP 元素:
// 在页面根组件中放置这个"LCP 锚点"元素
function LCPAnchor() {
return (
<img
// 使用一张加载极快的小图(如 base64 内联或 1px 透明图)
src={getNoConnectionIcon()}
// 关键:尺寸必须比其他竞争元素更大
width={375}
height={260}
alt="LCP_hide_placeholder"
style={{
// 将元素隐藏,但不能使用 opacity: 0(会被 LCP 排除)
// 使用 position: absolute 和 zIndex: -2 让它在内容层后面
height: 260,
left: 0,
pointerEvents: 'none', // 不响应鼠标事件
position: 'absolute',
zIndex: -2, // 层叠在最底层,用户不可见
top: 0,
userSelect: 'none', // 不可选中
width: '100%',
}}
/>
);
}
原理:
- 这个元素在 HTML 中是可见的(不是
opacity: 0,不是 visibility: hidden),所以浏览器会将它纳入 LCP 候选
- 它的渲染尺寸(375×260)比弹层图片更大,所以会被选为 LCP 元素
- 它使用的是 base64 图片,随 HTML 一起内联,加载时间极短
- 通过
zIndex: -2 将它隐藏在内容层后面,用户看不到它
效果:LCP 时间从 5 秒以上降至 1 秒以内。
关键限制:以下方式会导致元素被 LCP 排除:
-
opacity: 0 - 完全透明,被认为无意义
-
visibility: hidden - 不可见
- 尺寸为 0×0
- 完全覆盖视口(被视为背景)
第五章:INP 优化深度指南
5.1 INP 慢的根本原因
INP 差的根本原因是主线程被长任务阻塞。当用户点击按钮时,如果主线程正在执行一个耗时 500ms 的 JavaScript 任务,浏览器就无法立即处理这个点击事件,INP 就会很差。
主线程阻塞的常见来源:
-
大量 DOM 操作:
querySelectorAll、大规模 DOM 读写
-
复杂计算:加密运算、数据处理、排序过滤
-
大量 React 重渲染:不必要的 re-render、大列表渲染
-
同步的大文件加载:阻塞解析的
<script> 标签
5.2 使用 Chrome DevTools 定位 INP 问题
步骤一:使用 Live Metrics 确认 INP 问题
- 打开 Performance 面板的 Live Metrics
- 在页面上进行各种交互(点击、输入、滚动)
- 观察 INP 数值,找到使数值变大的操作
步骤二:录制性能分析
- 点击录制
- 执行刚才导致 INP 变大的操作
- 停止录制
- 在时间线上找到该交互对应的区域
步骤三:分析交互的三个阶段
在 Performance 面板中,点击一个交互事件,底部会显示该交互的三个阶段时间分布:
- Input Delay:如果这个值很大,说明点击时主线程正在执行其他任务
- Processing Time:如果这个值很大,说明事件处理函数本身太耗时
- Presentation Delay:如果这个值很大,说明渲染过程太复杂
5.3 三种核心优化技术
技术一:asyncExecuteTask - 异步化处理时间
这个技术适合解决 Processing Time 过长的问题。原理是将耗时操作从当前的同步执行中剥离,放到下一个任务(Task)中执行。这样当前交互的 INP 就只计算到任务切换点,而不包含后续耗时操作。
// ── 底层调度器 ──────────────────────────────────────────────
/**
* 封装 requestIdleCallback,兼容不支持的浏览器(降级为 setTimeout)
* timeout 超时后强制执行,保证任务不会被无限期推迟
*/
function runRequestIdleCallback(fn, timeout = 300) {
if (typeof requestIdleCallback !== 'undefined') {
requestIdleCallback(fn, { timeout });
} else {
setTimeout(fn, 1); // 降级兼容
}
}
/**
* 封装 queueMicrotask,兼容不支持的浏览器
*/
function runQueueMicrotask(fn) {
if (typeof queueMicrotask !== 'undefined') {
queueMicrotask(fn);
} else {
Promise.resolve().then(fn);
}
}
// ── asyncExecuteTask 实际源码 ────────────────────────────────
/**
* @param fn 要异步执行的函数
* @param option.highPriority true → queueMicrotask(微任务)
* false(默认)→ requestIdleCallback(空闲宏任务)
* @param option.runTimeout requestIdleCallback 的超时保底时间,默认 300ms
* @param option.mustSplit true → 强制 setTimeout(fn, 1),确保产生新的宏任务边界
*/
const asyncExecuteTask = (fn, option) => {
const {
highPriority = false,
runTimeout = 300,
mustSplit = false,
} = option || {};
return new Promise((resolve) => {
const wrappedFn = () => resolve(fn());
if (mustSplit) {
// 强制切分:通过 setTimeout 产生硬性宏任务边界
return setTimeout(wrappedFn, 1);
}
if (highPriority) {
// 高优先级:queueMicrotask,在当前宏任务末尾、下一宏任务前执行
// 注意:微任务不会真正"让出主线程",仅推迟到当前调用栈清空后
return runQueueMicrotask(wrappedFn);
}
// 默认(低优先级):requestIdleCallback,在浏览器空闲帧执行
// 这是 INP 优化的核心:把耗时操作放到浏览器认为"当前帧已完成"之后
return runRequestIdleCallback(wrappedFn, runTimeout);
});
};
// ── asyncExecuteTaskHoc 实际源码 ─────────────────────────────
/**
* HOC 版本:将一个函数包装成"调用时自动异步执行"的版本
* 适合直接作为事件处理函数赋值,无需在调用处写 async/await
*/
const asyncExecuteTaskHoc = (fn, option) => {
return (...params) => asyncExecuteTask(() => fn(...params), option);
};
三种调度策略对比
| 参数 |
调度机制 |
执行时机 |
适用场景 |
| 默认(低优先级) |
requestIdleCallback |
浏览器空闲帧 |
MobX store 更新、非紧急副作用 |
highPriority: true |
queueMicrotask |
当前调用栈清空后(微任务队列) |
需要"稍后但尽快"执行的任务 |
mustSplit: true |
setTimeout(fn, 1) |
下一个宏任务(强制切分) |
必须产生宏任务边界的场景 |
关键理解:requestIdleCallback 才是默认路径,不是 setTimeout。浏览器在完成当前帧的渲染后,如果还有剩余时间,才会执行 idle callback。这意味着 INP 的 Processing Time 几乎为 0——点击事件响应完成、画面更新后,耗时操作才开始跑。
// ============= 使用示例 =============
// 优化前:所有操作在一个同步任务中完成
// INP = Input Delay + (A耗时 + B耗时 + C耗时) + Presentation Delay
const handleClick_before = () => {
doExpensiveOperationA(); // 耗时 100ms
doExpensiveOperationB(); // 耗时 100ms
setState({ ... }); // 触发重渲染
doExpensiveOperationC(); // 耗时 100ms
// INP Processing Time ≈ 300ms,差
};
// 优化后:耗时操作异步化
// INP = Input Delay + (setState耗时) + Presentation Delay
const handleClick_after = async () => {
// 先执行 A,但立即让出控制权
await asyncExecuteTask(() => {
doExpensiveOperationA();
doExpensiveOperationB();
});
// 这行代码决定了 INP 的 Processing Time
setState({ ... });
// 后续操作不影响当前 INP
await asyncExecuteTask(() => {
doExpensiveOperationC();
});
};
实测数据:原始代码 INP = 340ms,使用 asyncExecuteTaskHoc 异步化后 INP = 9.19ms,几乎完全消除了交互延迟。
使用 performance-utils SDK:
import { asyncExecuteTask, asyncExecuteTaskHoc } from "performance-utils";
// 方式一:asyncExecuteTask(适合需要 await 的场景)
const handleClick = async () => {
await asyncExecuteTask(() => {
doExpensiveOperationA();
doExpensiveOperationB();
});
setShowContent(!showContent); // 状态更新
await asyncExecuteTask(() => {
doExpensiveOperationC();
doExpensiveOperationD();
});
};
// 方式二:asyncExecuteTaskHoc(适合整个函数都需要异步化的场景)
const handleClick = asyncExecuteTaskHoc(
() => {
doExpensiveOperationA();
doExpensiveOperationB();
setShowContent(!showContent);
doExpensiveOperationC();
doExpensiveOperationD();
}
);
技术二:taskSplitPoint - 长任务切片
这个技术适合解决一个函数内有多段耗时代码、需要在任务之间让出主线程的场景。
// ── taskSplitPoint 实际源码 ──────────────────────────────────
/**
* 注意:使用的是 setTimeout(resolve, 1) 而非 setTimeout(resolve, 0)
*
* 为什么是 1ms 而不是 0ms?
* - setTimeout(fn, 0) 在不同浏览器/场景下实际延迟可能被折叠到 0-4ms
* - 使用 1ms 可以更可靠地保证产生一个真正的宏任务边界
* - 浏览器有 4ms 的最小定时器间隔(嵌套 setTimeout 时),1ms 足以触发边界
*/
const taskSplitPoint = () => {
return new Promise((resolve) => {
setTimeout(resolve, 1);
});
};
// ── runTasks 实际源码(async generator 模式)────────────────
/**
* 顺序执行任务队列,每个任务之间自动插入 taskSplitPoint
* 使用 for...of 循环 + yield,逐个执行并收集结果
*/
const runTasks = async (taskList) => {
const results = [];
for (const task of taskList) {
results.push(await task());
await taskSplitPoint(); // 每个任务完成后让出主线程
}
return results;
};
// ── runTasksParallel 实际源码 ────────────────────────────────
/**
* 并行执行所有任务
* 使用 Promise.allSettled 而非 Promise.all:
* - Promise.all:任意一个任务失败就立即 reject,其他任务被放弃
* - Promise.allSettled:等待所有任务完成,无论成功或失败,结果中包含每个任务的状态
* 选用 allSettled 是为了容错——某个任务失败不应影响其他任务执行
*/
const runTasksParallel = (taskList) => {
return Promise.allSettled(taskList.map((task) => task()));
};
// ── runArrayIterationTask 实际源码 ───────────────────────────
/**
* @param array 要遍历的数组
* @param fun 遍历回调,参数与 Array.map 一致:(value, index, array)
* @param splitPointNum 插入几个切分点(默认 2)
*
* 切分逻辑:按数组长度均分,每隔 length/splitPointNum 个元素插一个切分点
* 特殊处理:splitPointNum=1 时按 length/2 计算,避免只插一个点在中间
*/
const runArrayIterationTask = async (array, fun, splitPointNum = 2) => {
const result = [];
const batchSize = array.length / (splitPointNum === 1 ? 2 : splitPointNum);
for (let i = 0; i < array.length; i++) {
result.push(fun(array[i], i, array));
if (Math.floor(i % batchSize) === 0) {
await taskSplitPoint();
}
}
return result;
};
// ============= 使用示例 =============
// 优化前:一个巨大的长任务
const processData = async () => {
// 这整个函数是一个 500ms 的长任务
parseAndValidateData(rawData); // 100ms
transformData(parsedData); // 150ms
calculateStatistics(transformed); // 120ms
renderChart(statistics); // 130ms
};
// 优化后:通过 taskSplitPoint 切分为多个小任务
const processData_optimized = async () => {
parseAndValidateData(rawData); // 100ms 任务一
await taskSplitPoint(); // ← 切分点,让出主线程
transformData(parsedData); // 150ms 任务二
await taskSplitPoint(); // ← 切分点
calculateStatistics(transformed); // 120ms 任务三
await taskSplitPoint(); // ← 切分点
renderChart(statistics); // 130ms 任务四
// 现在是 4 个 ≤ 150ms 的任务,而不是 1 个 500ms 的长任务
};
使用 SDK:
import { taskSplitPoint, runTasks, runTasksParallel } from "performance-utils";
// taskSplitPoint 基础用法
const handleClick = async () => {
doStep1();
await taskSplitPoint(); // 切分点一
doStep2();
await taskSplitPoint(); // 切分点二
doStep3();
};
// runTasks:将任务数组按顺序切片执行
// 实测 INP = 90.63ms(原始 340ms)
const handleClick = async () => {
await runTasks([
() => doExpensiveOperationA(),
() => doExpensiveOperationB(),
]);
setShowContent(!showContent);
await runTasks([
() => doExpensiveOperationC(),
() => doExpensiveOperationD(),
]);
};
// runTasksParallel:并行执行多个任务(不保证执行顺序)
const handleClick = async () => {
// A 和 B 会并行执行,总时间 ≈ max(A耗时, B耗时)
await runTasksParallel([
() => doIndependentTaskA(),
() => doIndependentTaskB(),
]);
setShowContent(!showContent);
};
// runArrayIterationTask:对数组进行切片遍历
// 参数:数组, 回调函数, 每批处理数量
const processItems = async () => {
const items = [1, 2, 3, ..., 10000]; // 大数组
await runArrayIterationTask(
items,
(value, index, array) => {
processItem(value); // 处理每个元素
},
50 // 每批处理 50 个,处理完一批后让出主线程
);
setProcessed(true);
};
实测对比数据:
| 优化方案 |
INP 值 |
说明 |
| 原始代码 |
340ms |
所有操作在单个长任务中执行 |
| taskSplitPoint 切片 |
130ms |
任务被分为四段 |
| runTasks 队列切片 |
90.63ms |
通过任务队列管理 |
| asyncExecuteTaskHoc 异步化 |
9.19ms |
几乎完全消除延迟 |
技术三:useTransition - React 18 并发优化
这个技术专门针对 React 应用中的渲染引起的 INP 问题。
原理:React 18 的 useTransition 可以将某个状态更新标记为"非紧急",React 会将对应的渲染工作切分为小的可中断单元(Fiber 调度),当检测到用户有新的输入时,可以暂停非紧急渲染,先处理用户输入,再恢复渲染。
import { useState, useTransition } from 'react';
/**
* 场景:搜索输入框 + 大列表过滤
* 问题:输入时更新列表(10000条数据),导致输入卡顿
* 优化:将列表更新标记为非紧急,确保输入框始终流畅
*/
function SearchWithTransition() {
const [inputValue, setInputValue] = useState('');
const [filteredList, setFilteredList] = useState(allItems);
const [isPending, startTransition] = useTransition();
const handleInput = (e) => {
const value = e.target.value;
// 输入框更新是紧急操作,直接更新,不会被中断
setInputValue(value);
// 列表过滤是非紧急操作,包裹在 startTransition 中
// React 会在空闲时处理,用户输入会打断并重新开始
startTransition(() => {
const newList = allItems.filter(item =>
item.name.toLowerCase().includes(value.toLowerCase())
);
setFilteredList(newList);
});
};
return (
<div>
<input
value={inputValue}
onChange={handleInput}
placeholder="搜索..."
/>
{/* isPending 为 true 时说明列表还在更新中 */}
{isPending && <span style={{ opacity: 0.5 }}>更新中...</span>}
<ul>
{filteredList.map(item => (
<li key={item.id}>{item.name}</li>
))}
</ul>
</div>
);
}
使用场景总结:
| 场景 |
推荐方案 |
原因 |
| 处理函数中有多段耗时操作 |
taskSplitPoint |
在关键位置插入切分点 |
| MobX store 属性更改 |
asyncExecuteTask |
将 MobX 更新异步化 |
| React setState 触发大量重渲染 |
useTransition |
利用 React 并发特性 |
| 大数组批量处理 |
runArrayIterationTask |
分批处理,避免长任务 |
| 多个独立任务并行 |
runTasksParallel |
充分利用浏览器调度 |
5.4 优化 Input Delay
如果 INP 的瓶颈是 Input Delay(用户点击到事件处理开始的延迟),说明点击时主线程正在执行其他代码,通常是:
-
定时器轮询:大量
setInterval 短期轮询
-
动画帧占用:
requestAnimationFrame 中执行了太多工作
-
后台任务:没有被用户触发的定时任务占用主线程
解决方案:
- 用
requestIdleCallback 执行后台任务,在主线程空闲时运行
- 减少
setInterval 的频率
- 将复杂计算移入 Web Worker(详见第八章)
第六章:CLS 优化深度指南
6.1 CLS 的计算原理
CLS(累积布局偏移)计算的是页面整个生命周期内所有意外布局偏移的累积分数。
单次布局偏移分数 = 影响分数 × 距离分数
影响分数 = 偏移前后合并区域占视口的比例
距离分数 = 元素移动的最大距离 / 视口尺寸
例如:一个按钮从视口中间移动到顶部,移动了视口高度的 25%,影响了视口 50% 的区域:
- 距离分数 = 0.25
- 影响分数 = 0.5
- 单次 CLS = 0.25 × 0.5 = 0.125(已超过良好阈值)
注意:由用户操作(点击、键盘输入)触发的布局变化不计入 CLS,只有页面自发的变化才会被计算。
6.2 CLS 的常见原因与修复
原因一:图片无尺寸
问题:图片没有指定 width 和 height 属性,浏览器不知道要为图片预留多大的空间,图片加载后会把下面的内容往下推。
<!-- ❌ 错误:没有尺寸,会导致 CLS -->
<img src="product.jpg" alt="产品图" />
<!-- ✅ 正确:指定宽高,浏览器预留空间 -->
<img src="product.jpg" alt="产品图" width="400" height="300" />
对于响应式图片,使用 aspect-ratio CSS 属性:
/* 使用 aspect-ratio 预留空间 */
.product-image {
width: 100%;
aspect-ratio: 4 / 3; /* 宽高比 */
}
原因二:动态注入的内容
问题:广告、通知横幅、Cookie 提示等内容在加载后才动态插入到页面顶部,把下面的内容往下推。
// ❌ 错误:动态插入横幅会导致 CLS
function Page() {
const [showBanner, setShowBanner] = useState(false);
useEffect(() => {
// 1秒后显示广告横幅,把页面内容往下推
setTimeout(() => setShowBanner(true), 1000);
}, []);
return (
<div>
{showBanner && <AdBanner />} {/* 这里会导致 CLS */}
<MainContent />
</div>
);
}
// ✅ 正确方案一:预留空间
function Page() {
const [showBanner, setShowBanner] = useState(false);
useEffect(() => {
setTimeout(() => setShowBanner(true), 1000);
}, []);
return (
<div>
{/* 预留固定高度的容器,无论横幅是否显示都占据这个空间 */}
<div style={{ height: '60px', minHeight: '60px' }}>
{showBanner && <AdBanner />}
</div>
<MainContent />
</div>
);
}
// ✅ 正确方案二:使用 position: fixed/sticky,不占文档流空间
function Page() {
return (
<div>
<MainContent />
{/* 使用固定定位,不影响文档流 */}
<CookieBanner style={{ position: 'fixed', bottom: 0 }} />
</div>
);
}
原因三:Web 字体导致的文本偏移(FOUT/FOIT)
问题:页面先用系统字体渲染文本,Web 字体加载完成后切换,导致文本大小变化、布局偏移。
/* ✅ 使用 font-display: optional */
/* optional 策略:如果字体在极短时间内没有加载完,就放弃使用自定义字体 */
@font-face {
font-family: 'MyFont';
src: url('my-font.woff2') format('woff2');
font-display: optional; /* 减少 FOUT */
}
/* ✅ 使用 size-adjust 减少字体切换时的布局变化 */
@font-face {
font-family: 'FallbackFont';
src: local('Arial');
size-adjust: 105%; /* 调整备用字体大小,使其更接近自定义字体 */
ascent-override: 95%;
}
原因四:后期加载的骨架屏尺寸不准确
骨架屏(Skeleton)的尺寸应该尽量与实际内容保持一致,否则内容加载后的替换会导致布局偏移:
// ❌ 错误:骨架屏高度和实际内容高度不一致
function UserCard({ user }) {
if (!user) {
return <div style={{ height: '50px' }}>加载中...</div>; // 高度不准确
}
return (
<div style={{ height: '80px' }}> {/* 实际高度是 80px,骨架是 50px */}
<img src={user.avatar} width="40" height="40" />
<span>{user.name}</span>
<span>{user.bio}</span>
</div>
);
}
// ✅ 正确:骨架屏与实际内容尺寸一致
function UserCard({ user }) {
if (!user) {
return (
<div style={{ height: '80px', display: 'flex', alignItems: 'center' }}>
{/* 骨架屏的布局和实际内容保持一致 */}
<div style={{ width: 40, height: 40, borderRadius: '50%', background: '#eee' }} />
<div style={{ marginLeft: 12 }}>
<div style={{ width: 100, height: 16, background: '#eee' }} />
<div style={{ width: 200, height: 12, background: '#eee', marginTop: 8 }} />
</div>
</div>
);
}
return (
<div style={{ height: '80px', display: 'flex', alignItems: 'center' }}>
<img src={user.avatar} width="40" height="40" style={{ borderRadius: '50%' }} />
<div style={{ marginLeft: 12 }}>
<div style={{ fontSize: '16px', lineHeight: '16px' }}>{user.name}</div>
<div style={{ fontSize: '12px', marginTop: 8 }}>{user.bio}</div>
</div>
</div>
);
}
6.3 用 Chrome DevTools 诊断 CLS
- 在 Lighthouse 报告中,找到 CLS 指标,点击展开
- 查看哪些元素发生了偏移(Lighthouse 会列出偏移元素的选择器)
- 在 Performance 面板中录制,找到 Layout Shift 事件(紫色标记)
- 点击 Layout Shift 事件,查看哪个元素发生了偏移以及偏移量
第七章:TTFB 与网络优化
7.1 TTFB 慢的诊断
TTFB(首字节时间)是所有性能指标的起点。如果 TTFB 超过 200ms,即使其他所有优化都做得完美,LCP 也很难达到良好水平。
在 Chrome DevTools Network 面板中,点击 HTML 文档请求,查看 Timing 标签:
Queued at 0ms ← 请求被排入队列
Stalled for Xms ← 等待发送(连接限制、缓存检查等)
DNS Lookup: Xms ← DNS 解析时间
Initial connection: Xms ← TCP 连接时间
SSL: Xms ← TLS 握手时间(HTTPS)
Request sent: Xms ← 请求发送时间
Waiting (TTFB): Xms ← ← 这里是服务器处理时间,是核心指标
Content Download: Xms ← HTML 下载时间
7.2 CDN 优化
CDN(内容分发网络)通过将静态资源分发到全球多个节点,减少用户到服务器的物理距离,是降低 TTFB 最有效的手段之一。
配置 CDN 的关键点:
# Nginx 配置:为静态资源设置长效缓存
location ~* .(js|css|png|jpg|gif|ico|woff2)$ {
# 静态资源缓存 1 年
expires 365d;
add_header Cache-Control "public, max-age=31536000, immutable";
# immutable 告诉浏览器在缓存期内不要重新验证
}
location /api/ {
# API 接口不缓存
add_header Cache-Control "no-store";
proxy_pass http://backend;
}
前端资源的内容哈希:
现代构建工具(Webpack、Vite)会在文件名中加入内容哈希,当文件内容变化时哈希也变化,确保用户始终获取最新版本:
// webpack.config.js
module.exports = {
output: {
// [contenthash] 会根据文件内容生成哈希
filename: 'js/[name].[contenthash:8].js',
chunkFilename: 'js/[name].[contenthash:8].chunk.js',
},
};
7.3 HTTP/2 和 HTTP/3
HTTP/2 的优势:
-
多路复用:一个连接可以同时处理多个请求,解决了 HTTP/1.1 的队头阻塞问题
-
头部压缩:使用 HPACK 压缩请求头,减少重复头部的传输开销
-
服务器推送:服务器可以在客户端请求之前主动推送资源
验证是否使用 HTTP/2:
在 Chrome DevTools Network 面板中,右键列标题,勾选 Protocol 列,如果看到 h2 就是 HTTP/2。
7.4 资源预连接
对于需要从第三方域名加载的关键资源,可以使用 preconnect 提前建立连接:
<head>
<!-- 提前与 CDN 建立连接(DNS解析 + TCP连接 + TLS握手) -->
<link rel="preconnect" href="https://cdn.example.com" crossorigin />
<!-- 仅提前做 DNS 解析,不建立连接(适合不确定是否会用到的域名) -->
<link rel="dns-prefetch" href="https://analytics.example.com" />
</head>
第八章:代码层面的通用优化
8.1 代码分割(Code Splitting)
代码分割是减少首屏 JavaScript 体积最有效的手段。核心思想是:首屏只加载必要的代码,其他代码按需加载。
// webpack.config.js - 配置代码分割
module.exports = {
optimization: {
splitChunks: {
chunks: 'all',
cacheGroups: {
// 将 node_modules 中的代码单独打包
vendors: {
test: /[\/]node_modules[\/]/,
name: 'vendors',
chunks: 'all',
priority: 10,
},
// 将 React 相关库单独打包(变化少,可以长期缓存)
react: {
test: /[\/]node_modules[\/](react|react-dom|react-router)[\/]/,
name: 'react-vendor',
chunks: 'all',
priority: 20,
},
},
},
},
};
8.2 路由级别的懒加载
在 React 应用中,每个路由页面都应该懒加载:
// router.tsx - 路由级懒加载
import { lazy, Suspense } from 'react';
// lazy() 会在组件首次被渲染时才加载对应的 JS 文件
const HomePage = lazy(() => import('./pages/HomePage'));
const TradePage = lazy(() => import('./pages/TradePage'));
const SettingsPage = lazy(() => import('./pages/SettingsPage'));
function App() {
return (
// Suspense 提供加载状态
<Suspense fallback={<PageLoading />}>
<Routes>
<Route path="/" element={<HomePage />} />
<Route path="/trade" element={<TradePage />} />
<Route path="/settings" element={<SettingsPage />} />
</Routes>
</Suspense>
);
}
效果:假设每个页面有 50KB 的 JS,有 10 个页面,不做懒加载首屏需要加载 500KB,做了懒加载首屏只需要加载当前页面的 50KB,减少 90%。
8.3 组件级别的懒加载
对于非关键的弹层、标签页内容等,可以延迟加载:
import { lazy, Suspense, useState } from 'react';
// 交易详情弹层:用户点击时才加载
const TxDetailModal = lazy(() => import('./TxDetailModal'));
function TxList() {
const [selectedTx, setSelectedTx] = useState(null);
return (
<div>
{transactions.map(tx => (
<div key={tx.id} onClick={() => setSelectedTx(tx)}>
{tx.hash}
</div>
))}
{/* 只在需要时才渲染(并加载)弹层组件 */}
{selectedTx && (
<Suspense fallback={<Spinner />}>
<TxDetailModal tx={selectedTx} onClose={() => setSelectedTx(null)} />
</Suspense>
)}
</div>
);
}
8.4 Tree Shaking
Tree Shaking 是构建工具在打包时自动移除未使用代码的优化。要让 Tree Shaking 正常工作,需要注意:
// ❌ 全量引入:会打包整个 lodash(几百 KB)
import _ from 'lodash';
const result = _.debounce(fn, 300);
// ✅ 按需引入:只打包 debounce(几 KB)
import debounce from 'lodash/debounce';
const result = debounce(fn, 300);
// ✅ 更好的方案:使用支持 Tree Shaking 的 ES Module 版本
import { debounce } from 'lodash-es';
const result = debounce(fn, 300);
对于 UI 组件库:
// ❌ 错误:引入整个组件库
import { Button, Input } from 'some-ui-library';
// ✅ 正确:使用 babel-plugin-import 按需引入
// 配置 .babelrc:
{
"plugins": [
["import", {
"libraryName": "some-ui-library",
"style": true // 同时按需引入样式
}]
]
}
8.5 Web Workers
将 CPU 密集型计算移入 Web Worker,避免阻塞主线程:
// crypto.worker.js - Web Worker 文件
self.onmessage = function(e) {
const { type, data } = e.data;
if (type === 'HASH') {
// 在 Worker 中执行加密运算,不阻塞主线程
const result = expensiveCryptoOperation(data);
self.postMessage({ type: 'HASH_RESULT', result });
}
};
// main.js - 主线程
const cryptoWorker = new Worker('./crypto.worker.js');
async function hashData(data) {
return new Promise((resolve) => {
cryptoWorker.postMessage({ type: 'HASH', data });
cryptoWorker.onmessage = (e) => {
if (e.data.type === 'HASH_RESULT') {
resolve(e.data.result);
}
};
});
}
// 主线程调用:加密运算在 Worker 中执行,不阻塞 UI
const hash = await hashData(rawData);
实际案例:在前面提到的性能分析中,Web3 加密库占 CPU 42.3%,将其移入 Web Worker 可以基本消除主线程阻塞。
8.6 虚拟列表
当列表数据量很大(数百到数万条)时,不应该渲染所有 DOM 节点,而应该使用虚拟列表:
import { FixedSizeList as List } from 'react-window';
// ❌ 错误:渲染 10000 个真实 DOM 节点
function BigList({ items }) {
return (
<ul>
{items.map(item => (
<li key={item.id} style={{ height: 50 }}>
{item.name}
</li>
))}
</ul>
);
}
// ✅ 正确:虚拟列表,只渲染视口内的节点(通常约 20 个)
function VirtualBigList({ items }) {
const Row = ({ index, style }) => (
// style 包含 position、top、height 等虚拟列表所需样式
<div style={style}>
{items[index].name}
</div>
);
return (
<List
height={600} // 列表容器高度
itemCount={items.length} // 总条目数
itemSize={50} // 每行高度(固定)
width="100%"
>
{Row}
</List>
);
}
8.7 React 性能优化
import { memo, useMemo, useCallback } from 'react';
// ✅ React.memo:避免不必要的组件重渲染
const TxItem = memo(function TxItem({ tx, onSelect }) {
return (
<div onClick={() => onSelect(tx)}>
{tx.hash} - {tx.amount}
</div>
);
});
// ✅ useMemo:缓存计算结果
function TxList({ transactions, filter }) {
// 只有 transactions 或 filter 变化时才重新计算
const filteredTxs = useMemo(
() => transactions.filter(tx => tx.type === filter),
[transactions, filter]
);
// ✅ useCallback:缓存函数引用,避免子组件重渲染
const handleSelect = useCallback((tx) => {
console.log('Selected:', tx.hash);
}, []); // 依赖为空,函数引用永远不变
return (
<ul>
{filteredTxs.map(tx => (
<TxItem key={tx.id} tx={tx} onSelect={handleSelect} />
))}
</ul>
);
}
第九章:综合实战——完整性能排查流程
9.1 场景描述
假设你接手了一个新页面,用户反映"这个页面很慢,点了没反应"。下面是完整的排查和优化流程。
9.2 第一步:建立基准数据
在优化之前,先测量现状,建立基准:
-
使用 Lighthouse 获取综合评分:在隐身模式下,对目标页面运行 Lighthouse,记录所有指标数值
-
记录用户场景:明确用户说"慢"是哪个场景——是页面加载慢、还是点击某个按钮后没反应
-
确认设备环境:移动端还是桌面端,网络速度如何
假设 Lighthouse 报告如下:
Performance Score: 32
LCP: 5.8s (差)
INP: 420ms (需改进)
CLS: 0.18 (需改进)
TTFB: 850ms
TBT: 3200ms
9.3 第二步:定位 TTFB 瓶颈
TTFB 850ms 远超 200ms 的良好阈值,先排查这个:
- 打开 Network 面板,找到 HTML 文档请求
- 查看 Timing:
Waiting (TTFB): 750ms
- 750ms 都在等待服务器响应,说明是服务端问题(API 慢、数据库慢、没有 CDN 等)
解决方案:
- 联系后端优化 API 响应速度
- 确认 HTML 是否经过 CDN 分发
- 对于 SSG/SSR 内容,确认是否有适当的缓存
9.4 第三步:分析 LCP 问题
TTFB 处理后,关注 LCP:
-
在 Lighthouse 报告中找到 LCP 截图,查看被识别为 LCP 的元素
-
假设 LCP 元素是一张 600KB 的 PNG 主图
-
在 Network 面板中找到该图片的请求,查看:
- Priority:
Low(加载优先级低!)
- Content-Encoding:
(none)(没有压缩)
- 下载时间:
1.8s(文件太大)
优化方案:
<!-- 原来 -->
<img src="hero.png" alt="主图" />
<!-- 优化后 -->
<link rel="preload" as="image" href="hero.webp" />
<img src="hero.webp" alt="主图" fetchpriority="high" width="1200" height="600" />
同时将图片转换为 WebP 格式,体积从 600KB 减小到约 150KB。
9.5 第四步:分析 INP 和长任务
TBT 3200ms 说明有大量长任务,这是 INP 差的根本原因:
- 录制 Performance,找到页面加载和用户交互的时间线
- 在 Main 区域识别红色三角形标记的长任务
- 展开最长的任务,查看调用栈
假设发现:
-
filterTransactions() 函数执行了 800ms
- 原因是每次都重新遍历 10000 条交易记录
优化方案:
// 优化前:每次点击都同步过滤 10000 条数据
const handleFilterChange = (filter) => {
const filtered = allTransactions.filter(tx => matchFilter(tx, filter)); // 800ms
setFilteredTxs(filtered);
};
// 优化后:使用 taskSplitPoint 拆分任务
import { taskSplitPoint } from 'performance-utils';
const handleFilterChange = async (filter) => {
// 先更新 UI 状态(让用户感觉立即响应)
setIsFiltering(true);
await taskSplitPoint(); // 让出主线程
// 分批过滤
const BATCH_SIZE = 500;
const results = [];
for (let i = 0; i < allTransactions.length; i += BATCH_SIZE) {
const batch = allTransactions.slice(i, i + BATCH_SIZE);
results.push(...batch.filter(tx => matchFilter(tx, filter)));
await taskSplitPoint(); // 每处理500条让出一次主线程
}
setFilteredTxs(results);
setIsFiltering(false);
};
9.6 第五步:修复 CLS 问题
CLS 0.18 超过了 0.1 的良好阈值:
- 在 Performance 面板中录制页面加载
- 找到紫色的
Layout Shift 事件
- 点击后查看是哪个元素发生了偏移
假设发现是顶部的 banner 图片加载后把下面内容推下去了:
// 优化前
<img src="banner.webp" alt="banner" />
// 优化后:指定宽高,预留空间
<img
src="banner.webp"
alt="banner"
width="1200"
height="300"
style={{ width: '100%', height: 'auto' }}
/>
9.7 第六步:验证优化效果
再次运行 Lighthouse,对比数据:
优化前:
Performance Score: 32
LCP: 5.8s → 优化后: 1.9s ✅
INP: 420ms → 优化后: 180ms ✅
CLS: 0.18 → 优化后: 0.05 ✅
TTFB: 850ms → 优化后: 180ms ✅
TBT: 3200ms → 优化后: 380ms (仍需改进)
Performance Score: 32 → 78
对于仍然偏高的 TBT,继续分析剩余的长任务,逐步优化。
9.8 优化的优先级原则
当面对多个需要优化的问题时,按照以下优先级处理:
-
首先解决 TTFB:这是所有指标的基础
-
然后解决 LCP:影响用户对页面加载速度的第一印象
-
然后解决 INP:影响用户与页面的交互体验
-
最后解决 CLS:减少用户困惑和误操作
第十章:性能监控与持续改进
10.1 真实用户监控(RUM)与实验室测试的区别
Lighthouse 和 Performance 面板是"实验室测试"——在受控环境下测量的数据。真实用户的体验可能因为网络状况、设备性能、地理位置等因素有很大差异。
真实用户监控(RUM, Real User Monitoring) :
- 在真实用户的浏览器中收集性能数据
- 数据更真实,但需要用户量才有统计意义
- Google Search Console 中的 Core Web Vitals 报告就是基于真实用户数据
10.2 使用 web-vitals 库收集性能数据
// performance-monitor.ts
import { onLCP, onINP, onCLS, onFCP, onTTFB } from 'web-vitals';
// 将性能数据发送到分析服务
function sendToAnalytics(metric) {
const { name, value, rating, id } = metric;
// rating 是 'good' | 'needs-improvement' | 'poor'
console.log(`${name}: ${value}ms (${rating})`);
// 发送到你的分析服务
fetch('/api/analytics/performance', {
method: 'POST',
body: JSON.stringify({
metricName: name,
value: Math.round(value),
rating,
id,
url: window.location.href,
timestamp: Date.now(),
}),
});
}
// 注册所有 Core Web Vitals 监听
onLCP(sendToAnalytics);
onINP(sendToAnalytics);
onCLS(sendToAnalytics);
onFCP(sendToAnalytics);
onTTFB(sendToAnalytics);
10.3 性能预算
性能预算是指为关键性能指标设置上限,当预算被超出时触发告警或构建失败:
// webpack.config.js - 配置性能预算
module.exports = {
performance: {
// 资源超出大小限制时发出警告
hints: 'warning',
// 单个文件最大 250KB
maxAssetSize: 250 * 1024,
// 入口文件总大小最大 500KB(包含所有同步依赖)
maxEntrypointSize: 500 * 1024,
// 只对 JS 和 CSS 文件执行检查
assetFilter: (assetFilename) => {
return /.(js|css)$/.test(assetFilename);
},
},
};
在 CI/CD 流程中集成性能测试:
# .gitlab-ci.yml
performance_test:
stage: test
script:
# 使用 Lighthouse CI 进行性能测试
- npx lhci autorun
rules:
- if: $CI_PIPELINE_SOURCE == "merge_request_event"
// lighthouserc.js
module.exports = {
ci: {
assert: {
preset: 'lighthouse:recommended',
assertions: {
// LCP 必须低于 2500ms,否则 CI 失败
'largest-contentful-paint': ['error', { maxNumericValue: 2500 }],
// INP 必须低于 200ms
'experimental-interaction-to-next-paint': ['warn', { maxNumericValue: 200 }],
// TBT 必须低于 300ms
'total-blocking-time': ['error', { maxNumericValue: 300 }],
},
},
upload: {
target: 'temporary-public-storage',
},
},
};
10.4 建立性能优化文化
性能优化不是一次性的工作,而是需要持续维护的过程。建立良好的性能优化文化需要:
-
可见性:将性能指标加入团队的监控大盘,让所有人都能看到
-
责任制:每次新功能上线,开发者需要提供性能测试数据
-
自动化:在 CI/CD 中集成性能测试,防止性能退化
-
教育:定期分享性能优化案例,提升团队意识
10.5 性能优化 Checklist
在每个新功能上线前,使用以下检查清单自检:
加载性能:
- LCP 元素是否添加了 fetchpriority="high" 或
- 图片是否指定了 width 和 height 属性(防止 CLS)
- 图片是否使用了 WebP 格式
- 大图是否已经压缩到合理大小(通常移动端 < 200KB)
- 新增的第三方域名是否添加了 preconnect
代码质量:
- 新增的路由/弹层是否使用了懒加载(React.lazy)
- 是否引入了新的大型依赖库(通过 Bundle Analyzer 检查)
- 是否有不必要的全量引入(如 import _ from 'lodash')
交互性能:
- 点击事件处理函数是否有超过 50ms 的同步操作
- 是否有大数组遍历在事件处理函数中
- 大列表是否使用了虚拟列表
布局稳定性:
- 动态插入的内容是否预留了空间
- 是否有可能导致页面内容重排的操作
10.6 总结:性能优化的核心思想
经过十章的学习,我们可以总结出性能优化的几个核心思想:
1. 测量优先:永远先测量,再优化。没有数据支撑的优化可能是无效甚至有害的。
2. 用户感知优先:性能优化的目标是改善用户感知,不是追求技术数字。有时候"感觉快"比实际数字更重要(如添加骨架屏)。
3. 关键路径优先:页面加载是一条关键路径(TTFB → FCP → LCP),优化要从瓶颈处入手,不要优化不在关键路径上的内容。
4. 主线程保护:所有交互性能问题的根源都是主线程被阻塞。保持主线程畅通,是 INP 优化的核心策略。
5. 渐进增强:先呈现核心内容,再逐步加载增强功能。首屏只加载必要资源,其他内容懒加载。
6. 持续监控:性能是一个会随着业务发展而退化的指标,需要通过 RUM 和 CI/CD 持续监控和保护。
附录:工具资源
在线分析工具
npm 包
-
web-vitals(
npm i web-vitals):Google 官方的 Core Web Vitals 收集库
-
performance-utils(
npm i performance-utils):性能优化工具集
-
react-window(
npm i react-window):虚拟列表
-
react-virtualized(
npm i react-virtualized):更完整的虚拟化方案
学习资源
-
web.dev/performance:Google 官方性能优化文档,是最权威的学习资源
-
Chrome Developers YouTube 频道:有大量 Performance 面板的使用教程
