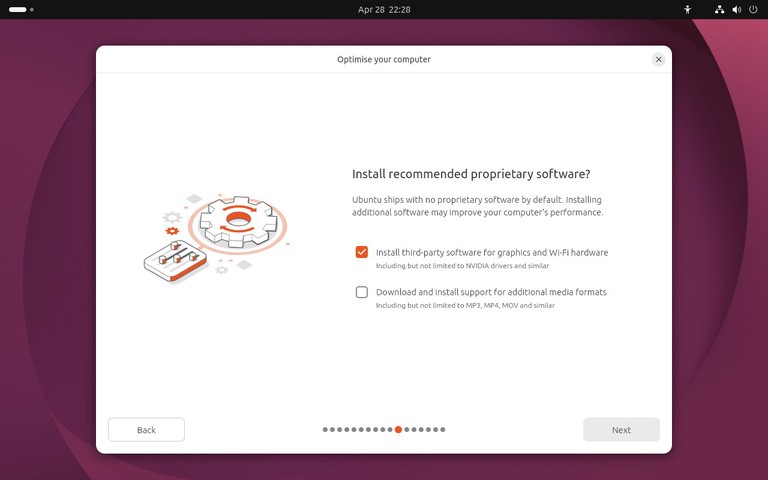
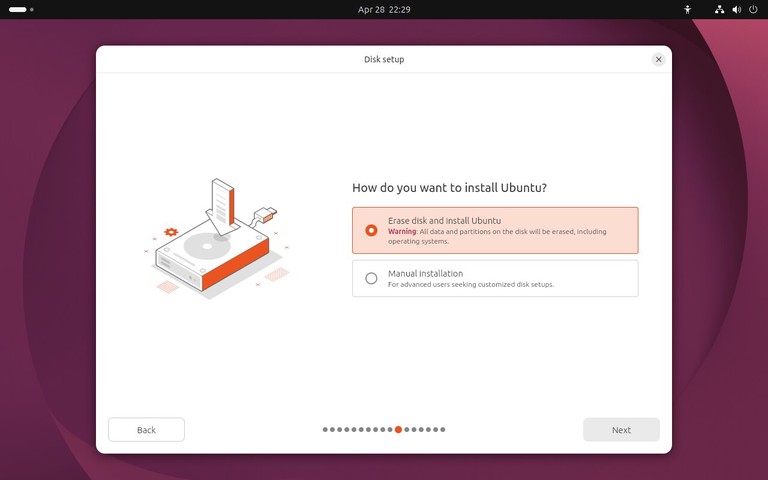
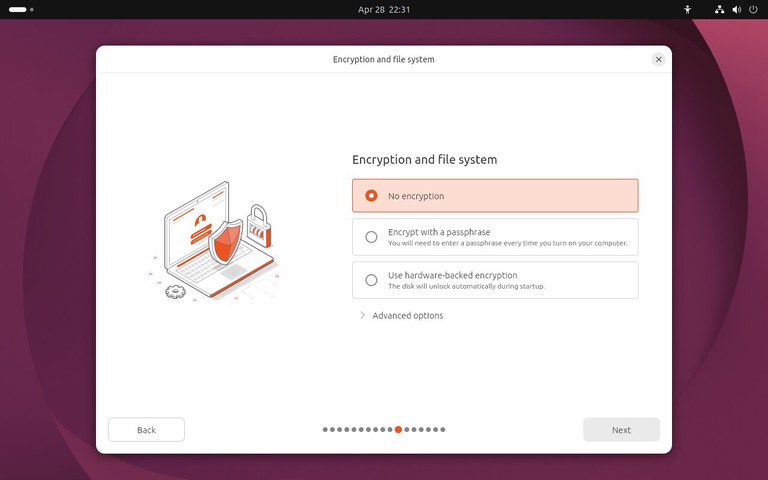
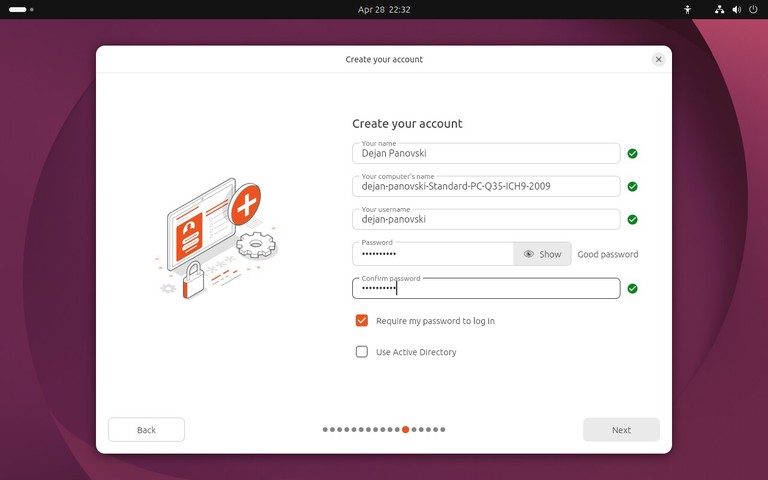
为什么要写这样一篇文章?
一个普通的甚至不太够看的后台图书管理系统,能够正常运行、实现基础业务功能就足够了,为什么还要花费大量时间,去从头到尾梳理一遍甚至写成文章呢?
写这个文章之前我也去思考了这件事的必要性,得出了下面这四条
有四个层次的意义
第一层:工具层面:更加熟练、通透地理解 Vue 整套开发工具链,明白工具的用法、适用场景与设计逻辑,学会去使用现在掌握和学习的工具。
第二层:项目理解层面:跳出单一语法与页面开发,站在项目整体角度去思考架构分层、代码封装、业务逻辑、工程设计,理解一个完整项目究竟该如何搭建,学习完之后尝试去自己设计项目。
第三层:个人层面:通过完整复盘沉淀,慢慢尝试搭建属于自己的,清晰、完整、闭环的前端开发体系,为之后更好地使用工具、开发项目打下扎实基础,同时也是对于以后拓展工具完善体系有一个参照。
第四层:也是这篇文章的意义:希望把自己的思路完整分享出来。对于入门学习者,可能是一种不一样的思考角度;同时也期待行业里有经验的开发者能够阅读点评,指出我理解不到位、思考有偏差的地方,让我从自己没有注意的视角查漏补缺,修正自己的错误,提升自己的认知。
所以接下来,我将从零开始,正向完整梳理这个简单项目从构思、搭建到开发落地的全部过程。
前置认知:浅谈项目开发思路、学习逻辑与技术选型
在正式进入项目开发之前,先浅浅的聊聊我理解的项目开发思路。
框架和各类开发工具,本身就是为落地项目而诞生的,本质上属于项目驱动学习
正常完整的开发逻辑,应当是先拿到业务需求,对项目整体进行完整分析,确定业务场景、功能需求,再根据项目体量去挑选合适的技术栈与开发工具。
(这一步整体规划分析,其实也是开发里难度很高、很考验思维的一环。)
本次项目是以学习理解为主,没有严格的业务要求与上线标准,因此我并没有按照标准项目流程先需求后选型。而是以现阶段需要学习掌握的技术为核心,反向完成技术选型。
最终选用 Vue3 + Vite+ Element Plus + VueRouter + Pinia + Axios 技术栈
整体页面包含登录页、系统布局首页、图书管理模块、个人中心页面这么几个内容模块。
用完整项目载体,反过来带动工具理解、框架熟悉与工程思维落地。
(所以具体这个技术选型和原因这里就不细说,不是因为它不重要,反而是太重要(对于我目前现阶段的认知和能力,还不足以完整、专业地讲出来底层选型逻辑),但是必须要清楚,这个项目的选型的方式只是学习阶段的方式,真正正规的项目开发顺序,绝对不能本末倒置。)
聊一下项目最核心第一步:项目基础工程构建
有句老话讲“万事开头难”,一点不错。咱们就来看看这个开头难在哪
整个项目构建的核心第一步,其实整体可以分为两大环节。
第一环节相对简单
以咱们的这个项目为例,在明确整体业务需求、确定好本次项目所用技术栈之后,利用 Vite 快速初始化,创建出一个干净、基础的 Vue3 项目文件。
(这一步更多是环境搭建,依赖安装,只需要把项目基础可用环境跑通即可。)
真正核心、最考验开发思维的,是第二个环节:
依托我们已经梳理拆分好的业务需求,去精细化设计、完善项目内部完整的根目录体系。
简单一句话:业务是皮肉,工程架构才是骨架。
骨架歪了,后面功能写再多,项目也是松散、混乱、没有章法的。
骨架搭建清晰合理,后面所有业务开发都会顺水推舟,条理清晰,思路顺畅。
(可以说业务代码是下限,工程思维与项目架构构造能力,才是一个开发者的上限。特别是现在AI越来越厉害,不断在冲击下限,我们更需要去锻炼构造能力和工程思维 ,守住自己下限的同时,去提高自己的上限。)
所以我们没有一上来就写页面、写功能。
而是在业务分析完毕、技术选型确定之后,优先沉下心构建整套基础工程。
从目录划分、路由设计、状态管理、请求封装、全局配置全部提前规划,用搭建工程的过程,慢慢建立自己整体的项目开发思维。
理清这一层,我们再正式开始实操完成从零初始化结构,再到完善整个后台图书管理系统项目。
后台图书管理系统
正式开工:构建项目雏形
首先,我们使用 Vite 创建一个最纯净、无多余配置的 JS 版本 Vue3 模板,同时安装好本项目全部所需核心依赖:路由、状态管理、网络请求、UI组件库等。得到一个极简干净的项目初始环境。
环境准备完成后,我们不再急着编写页面代码,正式进入根据业务需求搭建项目目录结构阶段。
简易后台图书管理项目结构较为简单,可以拆分成权限登录、全局布局、图书业务管理、个人中心四大核心模块,也明确了:工程化目录,绝不是一次性把所有文件夹建好,而是跟着业务模块、代码职责,逐一对号入座、逐个新建,每建一个目录,都清楚它对应哪块业务、承担什么功能。
接下来,我们就从零开始,不列最终框架,拆一个模块、建一个目录、讲清一层逻辑,一步步搭起整个项目的目录骨架。
第一步:新建项目基础核心——src根目录
Vite初始化完成后,默认只有基础的 src 文件夹,这是我们所有业务代码的唯一容器,所有模块、目录、文件,全部都在 src 内部搭建,不向外扩散。
这是最基础的规则:所有开发代码,只在src内编写,从根源避免文件散乱。
第二步:对应【页面业务模块】——新建views目录
我们最先拆分的,就是项目的页面级业务,登录、首页、图书管理、个人中心,都是独立的页面业务模块,所以第一步先新建承载所有页面的目录:
src/
├── views/ # 核心:所有业务页面容器
新建逻辑&业务对应
1. 对应前文拆分的权限登录、全局首页、图书管理、个人中心四大页面业务,所有页面都归属于此
2. 拒绝把所有 .vue 页面直接堆在 src 下,按业务模块划分子目录,后续新增页面、查找页面很清晰
3. 按照业务优先级,继续在 views 下新建子目录(按开发顺序新建,不一次性建完):
src/
├── views/
├── login/ # 对应【权限登录模块】:登录页面
├── home/ # 对应【全局布局首页模块】:系统工作台
├── books/ # 对应【核心图书管理模块】:图书增删改查业务
├── profile/ # 对应【个人中心模块】:用户信息管理
每建一个子文件夹,都对应我们拆分好的一个业务模块,完全做到业务拆分到哪,目录建到哪,没有多余目录,也没有遗漏业务。
第三步:对应【全局布局模块】——新建layout目录
后台管理系统有统一的页面外壳(侧边栏+顶部导航+内容区域),这是独立于具体业务页面的全局公共布局,不属于任何一个业务页面,所以单独新建目录:
src/
├── views/ # 业务页面
├── layout/ # 核心:全局布局容器,对应【全局布局模块】
└── index.vue # 布局主组件,承载所有业务页面展示
新建逻辑&业务对应
1. 独立拆分公共布局,和业务页面解耦,不用在每个页面重复写布局代码
2. 后续所有 views 下的业务页面,都作为子页面嵌入 layout ,实现布局复用
3. 只做布局渲染、菜单切换、路由承载,不写具体业务逻辑
第四步:对应【页面跳转&权限控制】——新建router目录
业务页面、全局布局都有了,页面之间需要跳转、需要控制访问权限(未登录不能进后台),这部分路由逻辑是独立的,不属于任何页面,因此新建路由专属目录:
src/
├── views/
├── layout/
├── router/ # 核心:路由管理,负责页面跳转、权限校验
└── index.js # 路由配置主文件
新建逻辑&业务对应
1. 对应所有页面的跳转规则,把 login/home/books/profile 页面路由统一配置
2. 承载登录权限校验逻辑,实现未登录跳转登录页的权限控制
3. 路由逻辑集中管理,不分散在各个页面中,方便后期维护修改
第五步:对应【全局数据共享】——新建store目录
后台系统存在跨页面共享数据:用户登录信息、token、用户权限等,这些数据在登录页、首页、个人中心、图书管理页都会用到,需要独立的全局状态管理,因此新建Pinia状态管理目录:
src/
├── views/
├── layout/
├── router/
├── store/ # 核心:全局状态管理,存储跨页面共享数据
├── modules/ # 按业务拆分状态模块
└── user.js # 用户状态:对应登录模块、个人中心模块数据
└── index.js # Pinia入口配置文件
新建逻辑&业务对应
1. 对应权限登录、个人中心模块的共享数据,专门管理用户信息、登录状态
2. 按业务模块拆分状态文件,后续如果需要图书相关全局状态,直接在 modules 下新建 book.js 即可
3. 状态与页面分离,避免组件间层层传值,降低代码耦合
第六步:对应【后端接口交互】——新建api目录
所有业务页面都需要和后端对接接口(登录校验、图书增删改查、用户信息修改),如果把接口代码写在页面里,后期接口修改要逐个页面改,极其混乱,因此单独新建接口管理目录:
src/
├── views/
├── layout/
├── router/
├── store/
├── api/ # 核心:所有后端接口请求容器
新建逻辑&业务对应
1. 对应所有业务模块的接口请求,后续按业务新建接口文件: user.js (登录/个人中心接口)、 book.js (图书管理接口)
2. 接口与页面业务分离,统一管理请求地址、请求参数、响应数据
3. 接口修改只改当前文件,不影响页面业务代码
第七步:对应【通用工具封装】——新建utils目录
项目中有很多和业务无关、可复用的工具逻辑(最核心的就是接口请求封装),不需要在每个页面重复编写,因此新建工具函数目录:
src/
├── views/
├── layout/
├── router/
├── store/
├── api/
├── utils/ # 核心:通用工具函数封装
└── request.js # 核心:axios请求封装
新建逻辑&业务对应
1. 承载全局通用工具代码, request.js 专门封装axios,统一处理请求头、响应报错、token携带
2. 后续可新增格式化、校验类工具,所有业务页面均可复用
3. 通用逻辑抽离,让业务页面只关注业务实现
第八步:对应【公共组件&静态资源】——补全剩余目录
最后,把项目中会用到的公共组件、静态资源补充完整,完成整个目录搭建,整体看一下:
src/
├── views/ # 业务页面
├── layout/ # 全局布局
├── router/ # 路由
├── store/ # 状态管理
├── api/ # 接口请求
├── utils/ # 工具函数
├── components/ # 全局公共组件(表格、弹窗、搜索框等)
├── assets/ # 静态资源(图片、全局样式、图标)
├── App.vue # 项目根组件
├── main.js # 项目入口文件
└── style.css # 全局样式
逐模块建目录的核心意义
拆分一个业务模块,新建一个对应目录,这样搭建的目录结构,核心优势在于:
1. 每一个目录都有明确业务归属,没有无意义的文件夹,清晰看懂每个目录的作用
2. 完全贴合业务拆分逻辑,业务和目录一一对应,后期新增、修改、删除业务,只需要操作对应目录
3. 代码职责完全分离,页面、路由、状态、接口、工具各司其职,项目再大也不会混乱
4. 循序渐进搭建,符合学习和开发逻辑,不会一上来被复杂目录劝退,每一步都知道自己在做什么、为什么这么做
项目目录骨架已经按照业务需求完整搭建完毕,文件夹层级清晰、职责划分明确,整个项目的基础框架已然成型。但此时我们还不能急于动手编写路由、接口封装、全局状态这些功能模块代码,在正式开启所有功能手写工作前,有一个至关重要、必须优先完成的环节——项目全局配置。
全局配置落地:vite.config.js 核心工程环境搭建
我们所说的配置文件,就是项目根目录下的vite.config.js,它是整个Vue3+Vite项目的核心工程配置文件,不涉及任何业务逻辑,却掌管着项目的编译规则、插件调用、路径映射、代码导入规范等所有底层运行逻辑。
之所以要提前做这项配置,核心原因有两点:
一:提前规范项目开发规则,统一路径别名、自动导入API与组件,省去后续重复手写引入代码的繁琐,提升开发效率;
二:提前配置好项目打包、运行的基础环境,规避后续开发中路径报错、组件无法识别、打包部署失败等问题,为所有功能代码编写筑牢底层环境基础,让后续开发更顺畅、代码更规范。
接下来我们就一步步完成本项目vite.config.js的完整配置
1. 导入所有需要用到的配置依赖
import { defineConfig } from 'vite'
import vue from '@vitejs/plugin-vue'
import AutoImport from 'unplugin-auto-import/vite'
import Components from 'unplugin-vue-components/vite'
import {ElementPlusResolver} from 'unplugin-vue-components/resolvers'
import { fileURLToPath,URL } from 'node:url'
这一部分主要是引入我们接下来要使用的各类插件和工具:
- defineConfig :Vite 官方配置方法,用来规范配置格式,拥有更好的代码提示
- vue :Vue编译插件,让项目可以识别并解析 .vue 文件
- AutoImport :自动导入工具
- Components :组件自动按需导入工具
- 最后两个Node 自带方法,专门用来处理文件路径
2. 插件功能配置
plugins: [
vue(),
AutoImport({
imports:['vue','vue-router','pinia'],
dts:true
}),
Components({
resolvers:[ElementPlusResolver()],
dts:true
})
]
这是配置文件里最核心的功能区域
1. 注册vue插件,保证项目正常运行Vue语法
2. AutoImport 自动导入
自动帮我们引入 vue、vue-router、pinia 里的常用API。
后续开发不用每次手动 import,直接使用语法即可,代码更加简洁干净。
3. Components 组件自动引入
配合 ElementPlus 解析器,实现UI组件按需自动引入。
不需要全局引入整个组件库,用到什么加载什么,项目体积更小。
dts:true 开启类型提示,避免代码爆红报错。
3. 打包路径配置
base:'./'
专门配置项目打包之后的资源访问路径。
使用相对路径,可以避免项目打包部署后出现页面空白、样式丢失、资源加载失败,是后台管理系统必备配置。
4. 路径别名配置
resolve:{
alias:{
'@': fileURLToPath(new URL('./src', import.meta.url))
}
}
将符号 @ 直接映射指向我们的 src 源代码根目录。
(适配我们前面规划好的整套目录结构,之后引入文件可以直接简写
@/router @/utils @/views
路径直观、优雅,不会出现复杂冗长的层级跳转。)
整合配置代码
// 引入Vite配置方法,提供类型提示
import { defineConfig } from 'vite'
// 引入Vue编译插件,让Vite支持.vue文件
import vue from '@vitejs/plugin-vue'
// 引入API自动导入插件
import AutoImport from 'unplugin-auto-import/vite'
// 引入组件自动导入插件
import Components from 'unplugin-vue-components/vite'
// 引入ElementPlus组件解析器,实现按需自动引入
import { ElementPlusResolver } from 'unplugin-vue-components/resolvers'
// 引入Node路径处理方法,用于配置路径别名
import { fileURLToPath, URL } from 'node:url'
// Vite配置导出
export default defineConfig({
// 项目插件配置
plugins: [
// 启用Vue编译功能
vue(),
// API自动导入配置
AutoImport({
// 自动导入Vue、VueRouter、Pinia的核心API,无需手动import
imports: ['vue', 'vue-router', 'pinia'],
// 自动生成类型声明文件,避免代码报错
dts: true
}),
// 组件自动导入配置
Components({
// 自动解析并导入ElementPlus组件
resolvers: [ElementPlusResolver],
// 自动生成组件类型声明文件
dts: true
})
],
// 打包资源使用相对路径,防止部署后资源加载失败
base: './',
// 路径别名配置
resolve: {
alias: {
// 将@映射为src根目录,简化文件引入路径
'@': fileURLToPath(new URL('./src', import.meta.url))
}
}
})
到这里,项目根配置文件基本完成。工程环境全部搭建就绪,接下来我们就可以依次开始搭建项目底层三件套:路由基础配置、Axios请求封装、Pinia全局状态雏形。
项目底层基础架构三件套
在项目全局配置完成之后,我们正式搭建项目三大底层基础模块:路由 Router、网络请求 Axios、全局状态 Pinia。
这三个模块是整个后台管理系统的运行根基。路由负责页面跳转,Axios负责后端接口请求,Pinia负责全局数据共享。底层架构搭建完成,方便后续所有页面业务更好开发。
同时绝大多数 Vue3 后台管理项目,这三份初始化基础代码写法基本固定,属于通用架构模板。我们目前只搭建最简雏形结构,不写入业务逻辑,后续开发页面再逐步扩充。
1. 路由配置
文件路径: src/router/index.js
// 引入创建路由、路由模式核心方法
import { createRouter, createWebHistory } from 'vue-router'
// 路由配置数组,存放所有页面路由信息
const routes = []
// 创建路由实例
const router = createRouter({
history: createWebHistory(),
routes
})
export default router
关键词解释
- createRouter :用于创建路由实例,是路由功能的核心方法
- createWebHistory :开启 history 路由模式,地址不带 # 号
- routes :路由规则数组,所有页面路径与组件都配置在这里
(整体说明:路由结构简单单层文件,一个文件完成所有路由初始化,结构直观清晰。)
2. Axios 请求封装
文件路径: src/utils/request.js
// 引入axios请求库
import axios from 'axios'
// 创建独立axios实例
const service = axios.create({
baseURL: '',
timeout: 10000
})
// 请求拦截器
service.interceptors.request.use(config => {
return config
})
// 响应拦截器
service.interceptors.response.use(
res => res.data,
err => Promise.reject(err)
)
export default service
关键词解释
- axios.create :创建独立请求实例,统一管理接口配置
- baseURL :接口公共基础地址
- interceptors :拦截器,统一处理请求头、返回数据、错误信息
(整体说明:同样为单文件结构,一个文件完成请求封装,所有接口统一走当前实例,方便统一维护。)
3. Pinia 全局状态管理
文件目录结构
stores
├─ index.js // pinia 总入口
└─ modules
└─ user.js // 具体业务状态模块
① Pinia 根实例
***路径: src/stores/index.js ***
// 引入创建pinia大仓库方法
import { createPinia } from "pinia";
// 创建全局唯一状态管理容器
const pinia = createPinia()
export default pinia
② 用户状态模块
路径: src/stores/modules/user.js
// 定义单独业务仓库
import { defineStore } from 'pinia'
export const useUserStore = defineStore('user', {
state: () => ({
token: '',
userInfo: {}
}),
actions: {}
})
这个项目里Pinia 和路由、Axios结构区别
1. 路由、Axios 都是单层单文件结构
一个文件夹内只有一个 index.js,功能集中、结构简单。
2. Pinia 采用双层模块化结构
- index.js :只创建全局根仓库,做统一入口
- modules :拆分不同业务状态仓库,用户、权限、菜单分开管理
(这种分包方式扩展性更强,项目变大后不会代码臃肿)
入口文件(main.js)全局插件挂载
三大底层基础模块已全部搭建完成,路由、请求、全局状态的核心架构已然成型,但这些独立的配置和工具,还无法直接在Vue项目中全局生效。
我们需要通过项目唯一入口文件main.js,将路由、Pinia以及项目用到的ElementPlus组件库、全局样式,统一挂载到Vue根实例上,完成最后一步全局注册,让所有底层配置和第三方插件贯穿整个项目,至此整套项目基础架构才算彻底闭环。
main.js全局挂载配置
文件路径: src/main.js
import { createApp } from 'vue'
import App from './App.vue'
// 引入路由实例
import router from './router'
// 引入Pinia全局根仓库
import pinia from './store'
// 引入ElementPlus组件库
import ElementPlus from 'element-plus'
// 引入ElementPlus默认样式
import 'element-plus/dist/index.css'
// 引入项目全局自定义样式
import '@/assets/styles/global.scss'
// 创建Vue根应用实例
const app = createApp(App)
// 全局挂载路由
app.use(router)
// 全局挂载Pinia状态管理
app.use(pinia)
// 全局挂载ElementPlus组件库
app.use(ElementPlus)
// 将Vue实例挂载到页面DOM节点,启动项目
app.mount('#app')
代码说明
-
依次引入路由、Pinia、ElementPlus及全局样式,将独立模块统一汇总到入口文件
-
通过 app.use() 完成全局挂载,挂载后整个项目所有页面都能直接使用对应功能
-
最后 app.mount('#app') 是项目渲染的关键,将Vue应用挂载到页面指定节点,项目正式运行
至此,从Vite工程化配置,到三大底层模块搭建,再到入口文件全局挂载,Vue3后台管理系统全套基础架构全部搭建完成,没有遗漏任何核心配置,后续可以毫无阻碍地进入页面开发、业务逻辑编写阶段。
项目业务逻辑代码编写与逐步完善
在完成项目目录搭建、工程基础配置、网络请求封装、路由配置、Pinia状态管理、全局组件库挂载等底层基础工程代码后,项目已具备正常启动运行条件。
底层通用基建全部落地完毕,正式进入页面业务代码开发阶段。
整体业务开发也要遵循由大框架到页面、由基础交互到完整业务、由单一功能到整体闭环的前端工程开发思路,不会一次性完成所有业务代码编写,按照开发顺序分步书写、迭代优化、逐步补全逻辑。
结合当前项目真实目录结构与代码文件,整体业务代码编写顺序以及对应文件大致思路如下:
1. 搭建后台管理系统整体布局骨架
对应文件: src/layout/index.vue
2. 开发登录页面结构、表单校验、登录请求业务逻辑
对应文件: src/views/login/index.vue
3. 完善路由守卫,实现登录权限控制与页面访问拦截
对应文件: src/router/index.js
4. 维护用户登录状态,完善全局用户状态管理
对应文件: src/store/modules/user.js
5. 在布局页面内部完成侧边菜单渲染,实现菜单与路由联动
对应文件: src/layout/index.vue
6. 依次开发各个核心业务页面
- 图书管理页面: src/views/books/index.vue
- 首页数据统计: src/views/home/index.vue
- 个人中心页面: src/views/profile/index.vue
7. 整体功能调试、业务逻辑补全、页面交互完善
大致就是这个由大及小,由外及内的编写顺序,现在直接开始
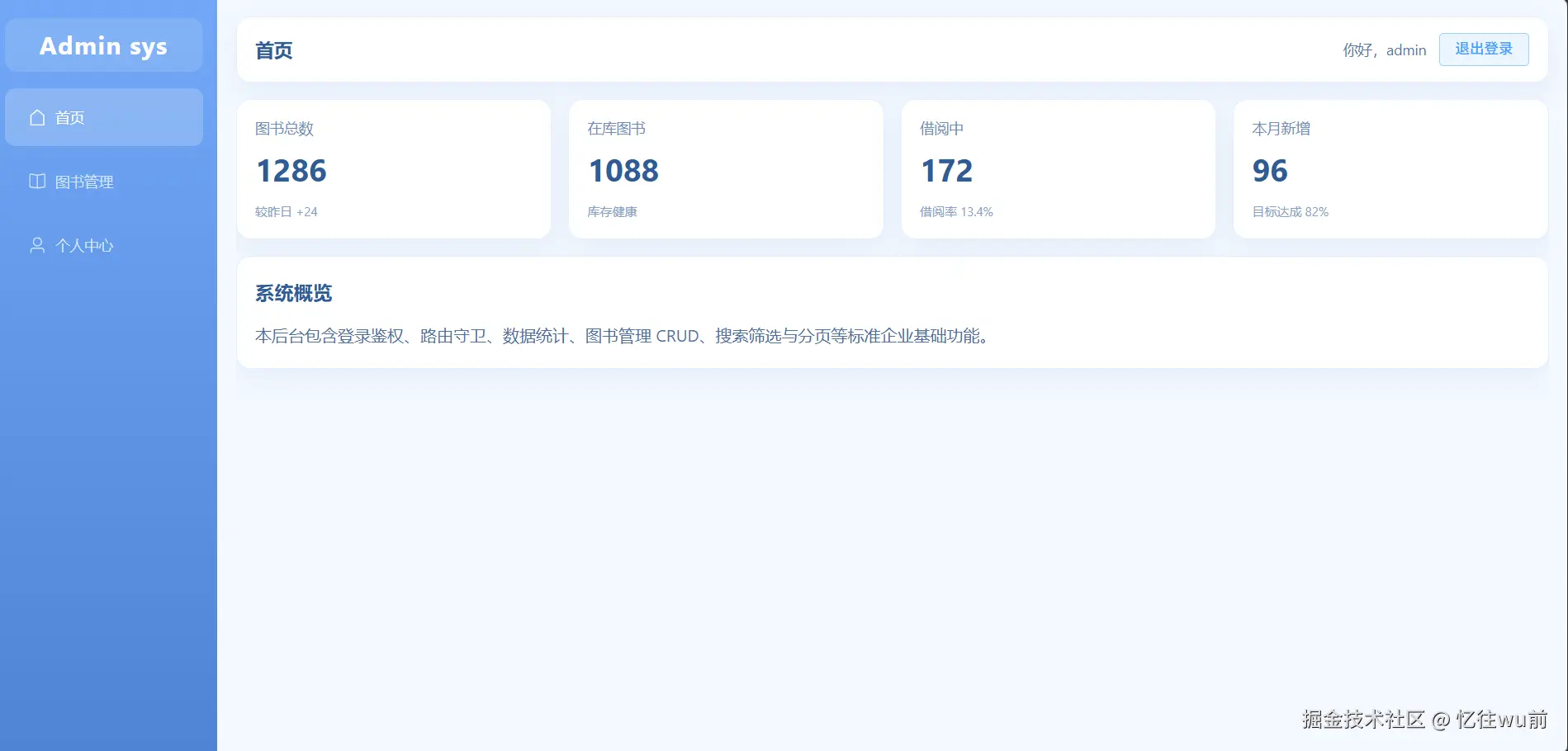
整体布局页面(src/layout/index.vue)
首先展示本页面最终视觉完成效果进行对照(只看布局)
一、现阶段编写
遵循结构样式先行、依赖逻辑后置的开发思路,本阶段优先完成页面可视化架构与样式美化,所有依赖其他业务模块、暂无法独立实现的功能逻辑,全部预留位置,后续补齐业务闭环后再添加。
二、本阶段可完整实现的内容
1. 页面整体架构搭建
直接确定后台管理系统经典布局,划分左侧侧边栏、顶部头部、主体内容区三大核心板块,搭建完整DOM结构,引入Element Plus菜单组件,配置菜单路由跳转、菜单图标,完成基础导航框架搭建。
2. 页面样式完善
一次性完成所有样式代码编写,包括侧边栏渐变背景、logo样式、菜单圆角与选中效果、顶部头部排版、内容区布局等,实现页面完整视觉效果,无需后续反复修改样式。
三、本阶段暂不实现、后续补充的功能逻辑
以下功能均依赖其他业务模块,当前无对应支撑逻辑,无法独立完成,待后续对应模块开发完毕后,再回补到布局页面中:
1. 菜单自动高亮(activeMenu):依赖路由路径匹配,需路由完整配置后实现
2. 页面标题展示(currentTitle):依赖路由meta元信息配置,需完善路由后添加
3. 用户信息展示:依赖Pinia用户状态仓库、登录业务逻辑,需完成登录模块后接入
4. 退出登录功能(handleLogout):依赖用户状态清空、路由跳转,需登录状态逻辑完善后实现
四、本阶段编写代码
<template>
<div class="layout">
<aside class="sidebar">
<div class="logo">Admin sys</div>
<!-- 菜单基础结构+路由+图标,本阶段直接完成 -->
<el-menu
router
background-color="transparent"
text-color="#cfe3ff"
active-text-color="#ffffff"
>
<el-menu-item index="/home">
<el-icon><House /></el-icon>
<span>首页</span>
</el-menu-item>
<el-menu-item index="/books">
<el-icon><Reading /></el-icon>
<span>图书管理</span>
</el-menu-item>
<el-menu-item index="/profile">
<el-icon><User /></el-icon>
<span>个人中心</span>
</el-menu-item>
</el-menu>
</aside>
<section class="main">
<!-- 头部仅搭建结构,用户信息、退出按钮暂不写逻辑 -->
<header class="header page-card">
<div class="crumb"></div>
<div class="header-right"></div>
</header>
<!-- 路由容器,本阶段直接完成 -->
<main class="content">
<router-view />
</main>
</section>
</div>
</template>
<script setup>
// 仅引入当前阶段必需的图标
import { House, Reading, User } from '@element-plus/icons-vue'
</script>
<!-- 所有样式本阶段一次性完善 -->
<style scoped lang="scss">
.layout {
display: flex;
width: 100%;
height: 100%;
}
.sidebar {
width: 220px;
padding: 20px 14px;
background: linear-gradient(180deg, #72a8f7 0%, #4f84d4 100%);
}
.logo {
height: 52px;
margin-bottom: 16px;
color: #fff;
font-size: 24px;
font-weight: 700;
line-height: 52px;
text-align: center;
letter-spacing: 1px;
background: rgba(255, 255, 255, 0.12);
border-radius: 12px;
}
.menu {
border-right: none;
}
:deep(.el-menu-item) {
margin: 6px 0;
border-radius: 10px;
}
:deep(.el-menu-item.is-active) {
background: rgba(255, 255, 255, 0.2);
}
.main {
display: flex;
flex: 1;
flex-direction: column;
padding: 18px 18px 16px;
}
.header {
display: flex;
align-items: center;
justify-content: space-between;
height: 64px;
padding: 0 18px;
}
.crumb {
color: #2f5b96;
font-size: 18px;
font-weight: 700;
}
.header-right {
display: flex;
gap: 12px;
align-items: center;
}
.content {
flex: 1;
padding-top: 16px;
overflow: auto;
}
</style>
当前代码已大致实现布局页面完整结构与视觉样式
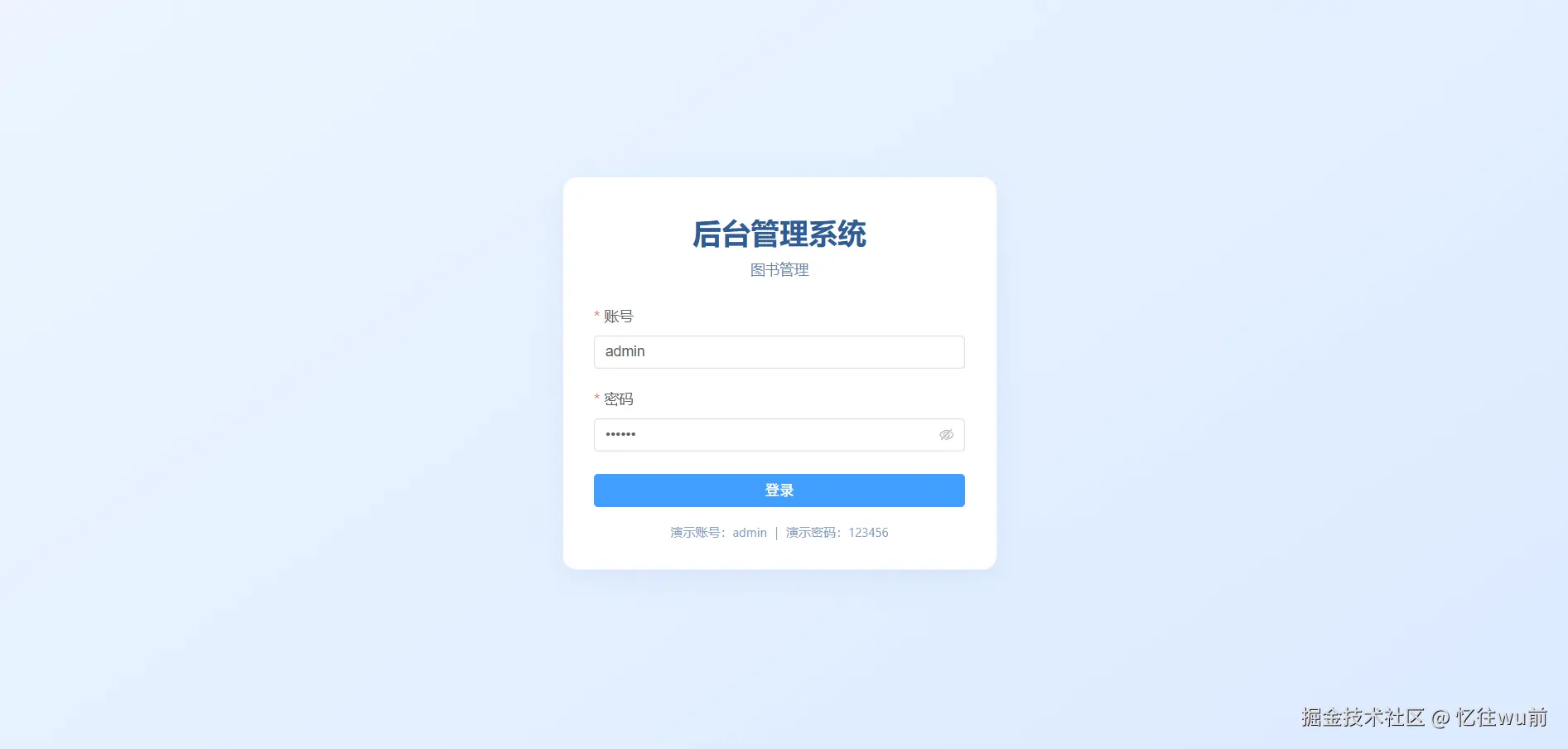
登录页面(src/views/login/index.vue)
首先展示本页面最终完成效果图,直观呈现页面整体样式与布局结构。
一、现阶段编写
延续结构样式先行、依赖逻辑后置的开发思路,本阶段优先完成页面整体布局结构与全部样式代码。凡是依赖全局状态、路由跳转、登录业务交互的逻辑代码全部暂时移除,等待后续模块开发完毕后统一补充完善。
二、本阶段可完整实现的内容
1. 页面整体架构搭建
根据最终页面结构,搭建登录容器、登录卡片、表单整体结构,引入对应图标与表单组件,完成页面基础DOM结构搭建。
2. 页面样式完善
直接沿用项目完整样式代码,保留全部背景、卡片圆角、配色、排版布局,页面视觉效果和最终成品完全一致,无需二次修改美化。
三、本阶段暂不实现、后续补充的功能逻辑
当前阶段路由、用户仓库、登录业务还未开发完成,以下交互逻辑暂时不编写:
1. 表单双向数据绑定
2. 表单校验规则
3. 登录点击事件、账号判断逻辑
4. 登录成功保存用户信息
5. 登录完成页面跳转
四、本阶段代码
<template>
<div class="login-box">
<div class="login-card">
<h2>图书后台管理系统</h2>
<p class="sub-title">图书管理</p>
<el-form>
<el-form-item label="用户名">
<el-input placeholder="请输入用户名"></el-input>
</el-form-item>
<el-form-item label="密码">
<el-input type="password" placeholder="请输入密码"></el-input>
</el-form-item>
<el-form-item>
<el-button type="primary" class="login-btn">登录</el-button>
</el-form-item>
</el-form>
</div>
</div>
</template>
<script setup>
</script>
<style scoped lang="scss">
.login-box {
width: 100vw;
height: 100vh;
background: linear-gradient(120deg, #74a9f8, #5287d8);
display: flex;
justify-content: center;
align-items: center;
}
.login-card {
width: 420px;
padding: 40px 36px;
background: #fff;
border-radius: 14px;
box-shadow: 0 6px 22px rgba(0,0,0,0.12);
h2 {
text-align: center;
margin-bottom: 30px;
color: #335894;
font-weight: bold;
}
}
.login-btn {
width: 100%;
}
</style>
当前已经完整实现登录页面布局结构与全部外观样式
路由配置文件(src/router/index.js)
先搭建基础路由骨架、页面路径配置、布局嵌套关系。
本阶段可完整实现的内容
1. 路由基础环境搭建
导入vue-router相关方法,创建路由实例,配置路由模式。
2. 页面路由映射
把已经写完的登录页、布局主页、首页、图书管理、个人中心全部配置对应访问路径。
3. 嵌套路由结构搭建
配置layout布局嵌套子路由结构,实现后台系统标准页面层级关系。
后续补充的功能逻辑
1. 全局路由守卫 beforeEach 登录权限判断
2. 未登录拦截、强制跳转登录页逻辑
3. 登录后放行访问内部页面逻辑
4. 路由重定向细节优化
本阶段代码
import { createRouter, createWebHistory } from 'vue-router'
// 引入页面组件
import Login from '@/views/login/index.vue'
import Layout from '@/layout/index.vue'
const routes = [
{
path: '/login',
component: Login
},
{
path: '/',
component: Layout,
redirect: '/home',
children: [
{
path: '/home',
name: 'home',
component: () => import('@/views/home/index.vue')
},
{
path: '/books',
name: 'books',
component: () => import('@/views/books/index.vue')
},
{
path: '/profile',
name: 'profile',
component: () => import('@/views/profile/index.vue')
}
]
}
]
const router = createRouter({
history: createWebHistory(),
routes
})
export default router
当前完成项目全部页面路由地址配置与嵌套结构
用户状态管理仓库(src/store/modules/user.js)
现阶段只搭建Pinia仓库基础结构、定义存储数据字段、创建仓库实例。登录信息存取、状态持久化、退出清空数据等交互逻辑暂时不实现,等待前面登录页面业务完善后再补充写入。
本阶段可完整实现的内容
1. 导入Pinia核心方法,创建独立用户仓库
2. 定义仓库内部state状态数据,预留用户名、登录状态等字段
3. 规范仓库导出结构,保证可以在任意页面引入使用
后续补充的功能逻辑
1. 登录后保存用户信息方法
2. 退出登录清空用户数据
3. 本地存储持久化用户登录状态
4. 和登录页面、路由守卫联动调用
本阶段代码
import { defineStore } from 'pinia'
export const useUserStore = defineStore('user', {
state: () => {
return {
username: '',
isLogin: false
}
},
actions: {}
})
目前完成用户仓库整体架构搭建,基础数据字段齐全,仓库可以正常引入使用。
首页页面(src/views/home/index.vue)
首先展示本页面最终完成效果图,直观呈现页面整体样式与布局结构。
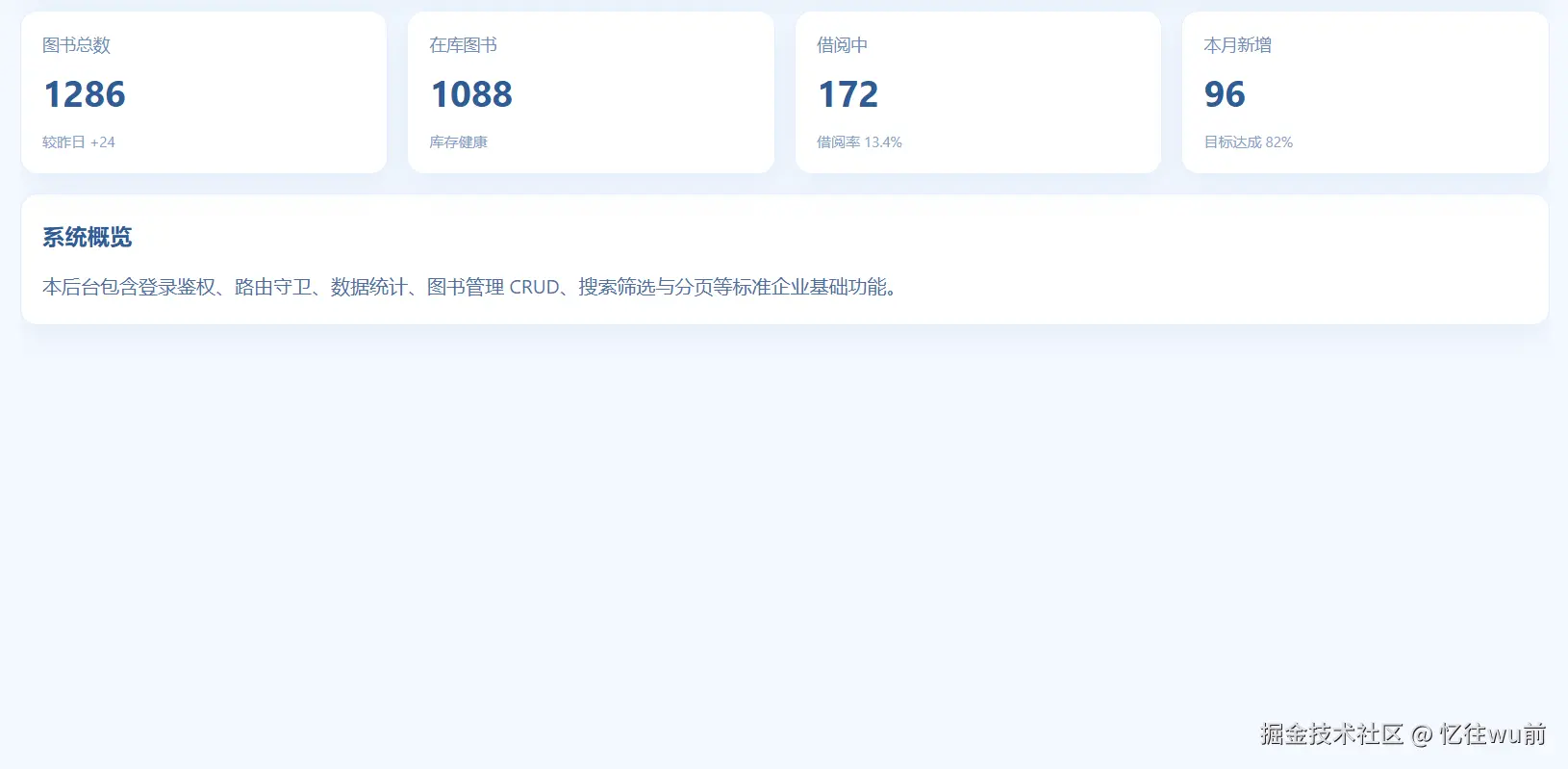
首页页面结构简单,无复杂业务逻辑与交互功能,仅展示基础数据统计卡片与系统文字介绍,整体以静态页面展示为主所以可以直接完善写出来。
<template>
<div class="home-page">
<div class="card-grid">
<div v-for="item in statCards" :key="item.title" class="stat-card page-card">
<div class="stat-title">{{ item.title }}</div>
<div class="stat-value">{{ item.value }}</div>
<div class="stat-foot">{{ item.tip }}</div>
</div>
</div>
<div class="welcome page-card">
<h3>系统概览</h3>
<p>本后台包含登录鉴权、路由守卫、数据统计、图书管理 CRUD、搜索筛选与分页等标准企业基础功能。</p >
</div>
</div>
</template>
<script setup>
const statCards = [
{ title: '图书总数', value: 1286, tip: '较昨日 +24' },
{ title: '在库图书', value: 1088, tip: '库存健康' },
{ title: '借阅中', value: 172, tip: '借阅率 13.4%' },
{ title: '本月新增', value: 96, tip: '目标达成 82%' }
]
</script>
<style scoped lang="scss">
.card-grid {
display: grid;
grid-template-columns: repeat(4, minmax(220px, 1fr));
gap: 16px;
}
.stat-card {
padding: 18px;
}
.stat-title {
color: #6f8eb8;
font-size: 14px;
}
.stat-value {
margin-top: 10px;
color: #2f5b96;
font-size: 30px;
font-weight: 700;
}
.stat-foot {
margin-top: 14px;
color: #87a2c7;
font-size: 12px;
}
.welcome {
margin-top: 16px;
padding: 18px;
color: #4f6f9d;
line-height: 1.8;
}
.welcome h3 {
margin: 0 0 10px;
color: #2f5b96;
}
.welcome p {
margin: 0;
}
.welcome p + p {
margin-top: 8px;
}
</style>
该页面只做页面渲染展示,不存在数据修改、接口请求、业务处理逻辑,页面简洁直观,完成首页基础展示效果。
图书管理页面(src/views/books/index.vue)
首先展示本页面最终完成效果图,直观呈现页面整体样式与布局结构。
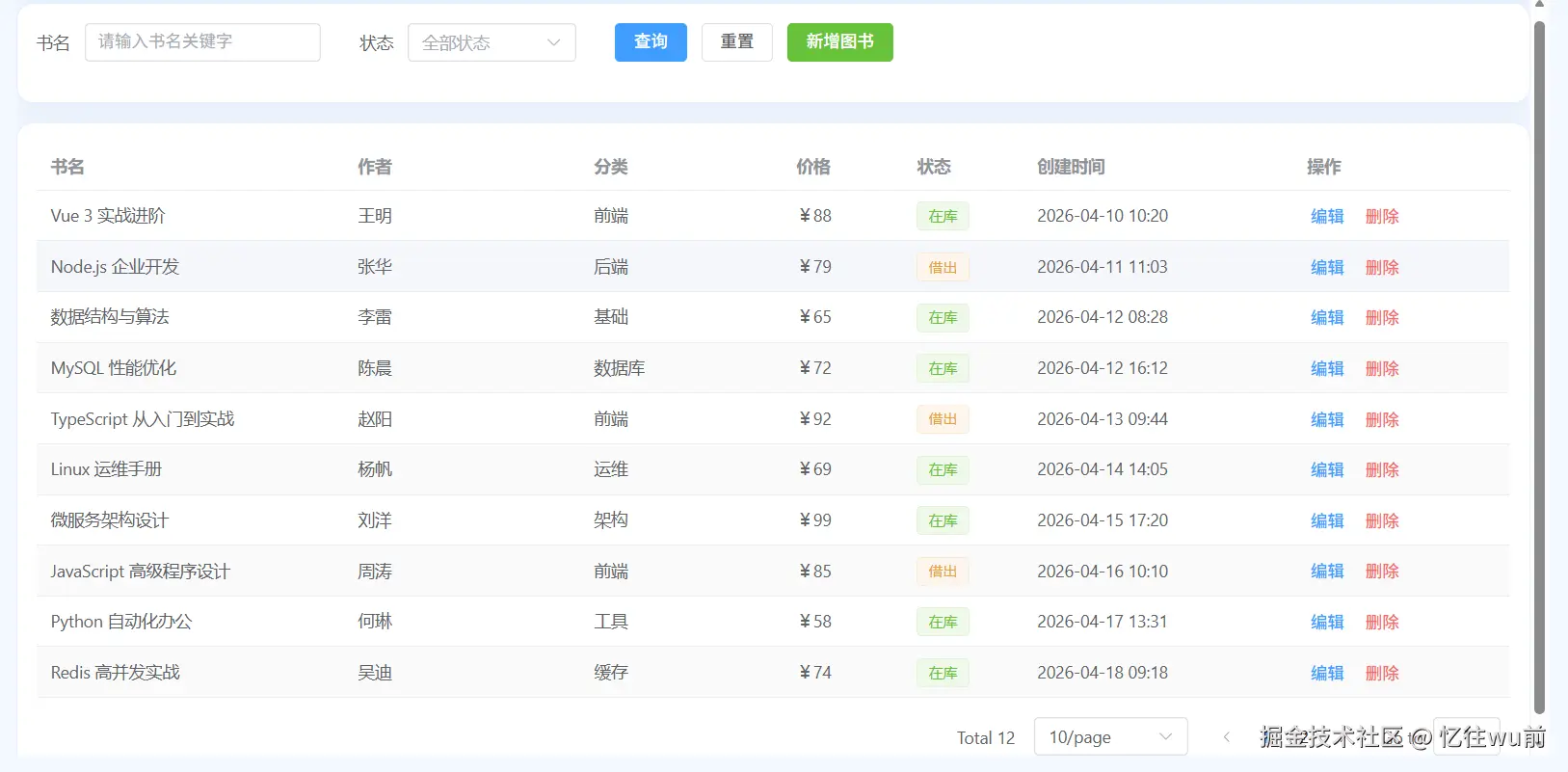
依旧遵循页面结构与样式优先,业务逻辑后置补齐的开发方式。
只搭建表格整体结构、页面布局、完整美化样式。表格增删改查、数据渲染、接口请求、操作事件全部暂时不编写。
本阶段可完整实现的内容
1. 搭建图书管理页面整体布局,顶部操作栏、表格主体结构
2. 引入表格、按钮等组件,完成页面完整DOM结构
3. 保留项目原版全部样式,页面外观和最终成品保持一致
后续补充的功能逻辑
1. 图书列表数据获取、表格数据渲染
2. 新增、编辑、删除图书操作事件
3. 搜索筛选功能
4. 所有表格业务交互逻辑
本阶段代码
<template>
<div class="books-page">
<!-- 顶部搜索区域 -->
<div class="search-panel page-card">
<el-form :inline="true">
<el-form-item label="书名">
<el-input />
</el-form-item>
<el-form-item label="状态">
<el-select>
<el-option label="在库" />
<el-option label="借出" />
</el-select>
</el-form-item>
<el-form-item>
<el-button type="primary">查询</el-button>
<el-button>重置</el-button>
<el-button type="success">新增图书</el-button>
</el-form-item>
</el-form>
</div>
<!-- 表格区域 -->
<div class="table-panel page-card">
<el-table stripe>
<el-table-column label="书名" />
<el-table-column label="作者" />
<el-table-column label="分类" />
<el-table-column label="价格" />
<el-table-column label="状态" />
<el-table-column label="创建时间" />
<el-table-column label="操作" fixed="right">
<template #default>
<el-button link type="primary">编辑</el-button>
<el-button link type="danger">删除</el-button>
</template>
</el-table-column>
</el-table>
<div class="pager">
<el-pagination />
</div>
</div>
<!-- 新增编辑弹窗 -->
<el-dialog title="图书信息" width="520px">
<el-form label-width="80px">
<el-form-item label="书名">
<el-input />
</el-form-item>
<el-form-item label="作者">
<el-input />
</el-form-item>
<el-form-item label="分类">
<el-input />
</el-form-item>
<el-form-item label="价格">
<el-input-number />
</el-form-item>
<el-form-item label="状态">
<el-radio-group>
<el-radio label="在库" />
<el-radio label="借出" />
</el-radio-group>
</el-form-item>
</el-form>
<template #footer>
<el-button>取消</el-button>
<el-button type="primary">确认</el-button>
</template>
</el-dialog>
</div>
</template>
<script setup>
// 本阶段只搭建页面结构,暂不编写任何业务逻辑、数据、方法
</script>
<style scoped lang="scss">
.books-page {
display: flex;
flex-direction: column;
gap: 16px;
}
.search-panel,
.table-panel {
padding: 16px;
}
.pager {
display: flex;
justify-content: flex-end;
margin-top: 16px;
}
</style>
图书管理页面整体布局、组件结构、页面样式已有。
个人中心页面(src/views/profile/index.vue)
首先展示本页面最终完成效果图,直观呈现页面整体样式与布局结构。
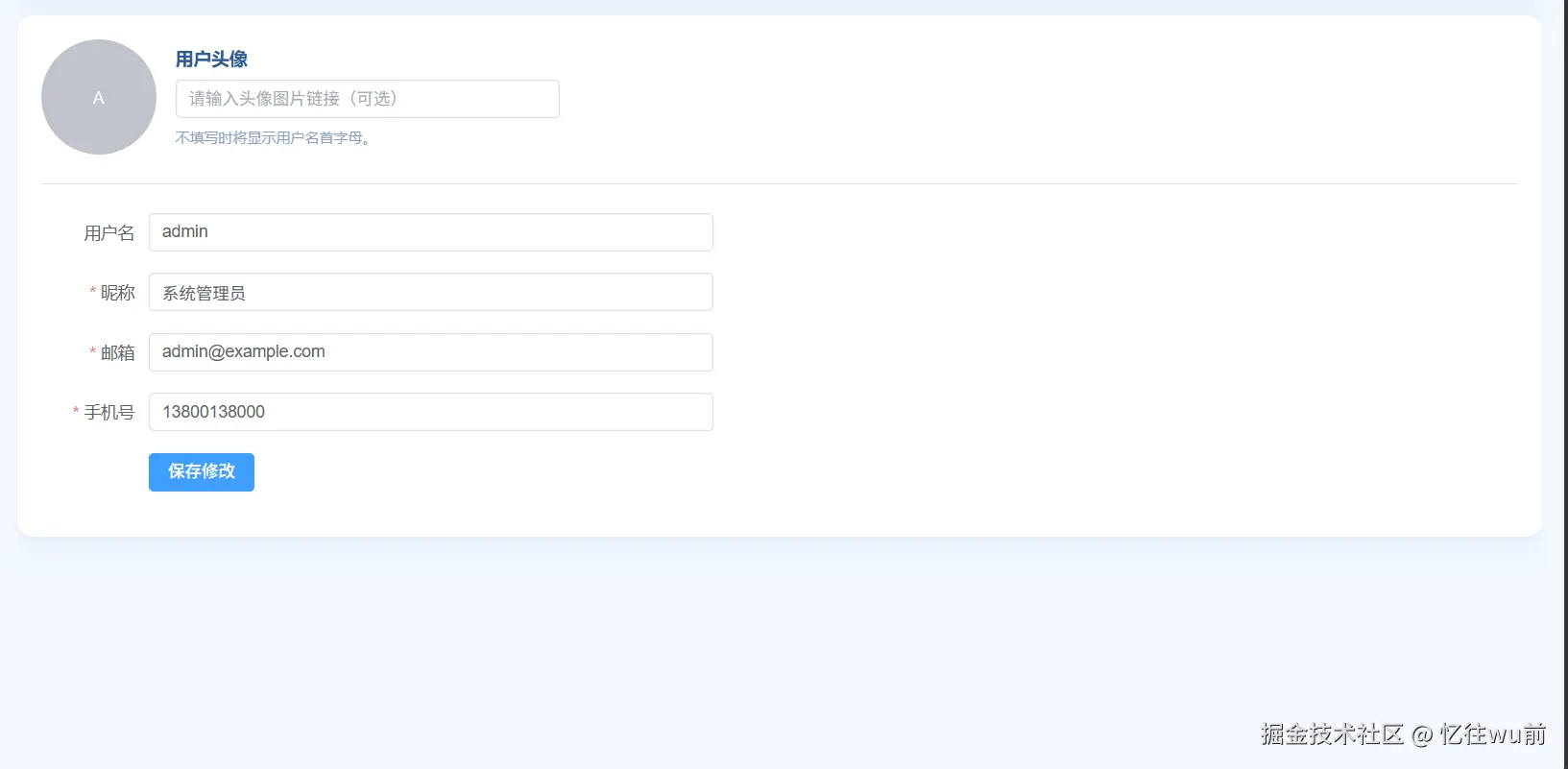
继续沿用整体开发思路,优先完成页面整体结构搭建与全部样式美化,只完成静态页面展示。
用户信息回显、信息修改、数据提交、个人资料业务逻辑全部后置,后续统一集中补充。
本阶段实现的内容
1. 搭建个人中心页面布局结构,卡片排版、信息展示区域
2. 完成表单结构、页面整体布局
3. 保留原版全部样式代码,页面视觉效果和最终成品一致
后续补充的功能逻辑
1. 用户信息数据回填展示
2. 资料修改、表单提交逻辑
3. 信息更新相关业务交互
本阶段代码
<template>
<div class="profile-page page-card">
<div class="avatar-section">
<el-avatar :size="96">
</el-avatar>
<div class="avatar-actions">
<div class="avatar-title">用户头像</div>
<el-input placeholder="请输入头像图片链接(可选)" clearable style="width: 320px" />
<div class="avatar-tip">不填写时将显示用户名首字母。</div>
</div>
</div>
<el-divider />
<el-form label-width="90px" class="profile-form">
<el-form-item label="用户名">
<el-input readonly />
</el-form-item>
<el-form-item label="昵称">
<el-input placeholder="请输入昵称" />
</el-form-item>
<el-form-item label="邮箱">
<el-input placeholder="请输入邮箱" />
</el-form-item>
<el-form-item label="手机号">
<el-input placeholder="请输入手机号" />
</el-form-item>
<el-form-item>
<el-button type="primary">保存修改</el-button>
</el-form-item>
</el-form>
</div>
</template>
<script setup>
// 本阶段仅搭建页面布局结构,暂不编写数据绑定、表单校验、保存逻辑
</script>
<style scoped lang="scss">
.profile-page {
padding: 20px;
}
.avatar-section {
display: flex;
gap: 16px;
align-items: center;
}
.avatar-actions {
display: flex;
flex-direction: column;
gap: 8px;
}
.avatar-title {
color: #2f5b96;
font-size: 15px;
font-weight: 600;
}
.avatar-tip {
color: #87a2c7;
font-size: 12px;
}
.profile-form {
max-width: 560px;
}
</style>
至此,项目所有页面、路由、状态仓库基础骨架全部开发完毕。
接下来进入文章最后一大环节:统一回填所有业务逻辑、联动功能、页面交互,把之前所有搁置的逻辑全部补齐,项目正式完整闭环。、
Layout布局页面 业务逻辑回填
一、template 模板部分改动
页面整体布局、侧边栏、菜单、路由容器、外层结构全部保留不变
只在头部 header-right 区域新增用户信息展示、退出登录按钮、绑定事件
1.头部右侧区域结构扩充
原有空标签
<div class="header-right"></div>
修改回填后
<!-- 展示当前登录用户名 -->
<span class="username">{{ userInfo.nickname }}</span>
<!-- 退出登录点击事件 -->
<el-button type="text" icon="Logout" @click="handleLogout">退出登录</el-button>
- 侧边菜单:结构完全不动,保留原有路由跳转
- 路由容器 router-view:无任何修改
- 仅页面头部右上角新增用户名称展示、退出按钮、点击退出事件
二,script 脚本逻辑
模块1:新增图标依赖导入
引入退出图标
import { Logout } from '@element-plus/icons-vue'
模块2:引入路由、用户仓库全局状态
import { useRouter } from 'vue-router'
import { useUserStore } from '@/store/modules/user'
作用:
获取路由实例、获取全局登录用户信息、操作用户登录状态
模块3:实例声明与用户信息获取
const router = useRouter()
const userStore = useUserStore()
// 从全局仓库获取当前登录用户信息
const userInfo = userStore.userInfo
模块4:核心退出登录业务方法
const handleLogout = () => {
// 清空本地用户登录信息
userStore.clearUserInfo()
// 跳转回登录页面
router.push('/login')
}
逻辑流程:
点击退出 → 清空用户登录数据 → 页面跳转至登录页
三、逻辑回填完成 · Layout完整最终代码
<template>
<div class="layout">
<aside class="sidebar">
<div class="logo">Admin sys</div>
<el-menu
:default-active="activeMenu"
class="menu"
router
background-color="transparent"
text-color="#cfe3ff"
active-text-color="#ffffff"
>
<el-menu-item index="/home">
<el-icon><House /></el-icon>
<span>首页</span>
</el-menu-item>
<el-menu-item index="/books">
<el-icon><Reading /></el-icon>
<span>图书管理</span>
</el-menu-item>
<el-menu-item index="/profile">
<el-icon><User /></el-icon>
<span>个人中心</span>
</el-menu-item>
</el-menu>
</aside>
<section class="main">
<header class="header page-card">
<div class="crumb">{{ currentTitle }}</div>
<div class="header-right">
<span class="welcome">你好,{{ userStore.userInfo.username || '管理员' }}</span>
<el-button type="primary" plain @click="handleLogout">退出登录</el-button>
</div>
</header>
<main class="content">
<router-view />
</main>
</section>
</div>
</template>
<script setup>
import { computed } from 'vue'
import { useRoute, useRouter } from 'vue-router'
import { ElMessage, ElMessageBox } from 'element-plus'
import { House, Reading, User } from '@element-plus/icons-vue'
import { useUserStore } from '@/store/modules/user'
const route = useRoute()
const router = useRouter()
const userStore = useUserStore()
const activeMenu = computed(() => route.path)
const currentTitle = computed(() => route.meta.title || '后台管理')
const handleLogout = async () => {
try {
await ElMessageBox.confirm('确认退出当前账号吗?', '提示', {
type: 'warning'
})
userStore.logout()
ElMessage.success('已退出登录')
router.push('/login')
} catch {
// 用户取消退出时保持当前页面
}
}
</script>
<style scoped lang="scss">
.layout {
display: flex;
width: 100%;
height: 100%;
}
.sidebar {
width: 220px;
padding: 20px 14px;
background: linear-gradient(180deg, #72a8f7 0%, #4f84d4 100%);
}
.logo {
height: 52px;
margin-bottom: 16px;
color: #fff;
font-size: 24px;
font-weight: 700;
line-height: 52px;
text-align: center;
letter-spacing: 1px;
background: rgba(255, 255, 255, 0.12);
border-radius: 12px;
}
.menu {
border-right: none;
}
:deep(.el-menu-item) {
margin: 6px 0;
border-radius: 10px;
}
:deep(.el-menu-item.is-active) {
background: rgba(255, 255, 255, 0.2);
}
.main {
display: flex;
flex: 1;
flex-direction: column;
padding: 18px 18px 16px;
}
.header {
display: flex;
align-items: center;
justify-content: space-between;
height: 64px;
padding: 0 18px;
}
.crumb {
color: #2f5b96;
font-size: 18px;
font-weight: 700;
}
.header-right {
display: flex;
gap: 12px;
align-items: center;
}
.welcome {
color: #5578a8;
font-size: 14px;
}
.content {
flex: 1;
padding-top: 16px;
overflow: auto;
}
</style>
登录页面业务逻辑回填
一、template 模板部分改动
整体 HTML 结构、标签、布局、文字完全不删除、不修改
只新增绑定属性与点击事件,具体改动如下:
1. el-form 表单标签
新增表单实例、数据双向绑定、表单校验规则
<!-- 新增 ref表单实例 :model数据绑定 :rules校验规则 -->
<el-form ref="loginFormRef" :model="loginForm" :rules="loginRules">
2. 用户名输入框
新增数据双向绑定
<!-- 新增 v-model 绑定表单数据 -->
<el-input v-model="loginForm.username" placeholder="请输入用户名"></el-input>
3. 密码输入框
新增数据双向绑定
<!-- 新增 v-model 绑定表单数据 -->
<el-input v-model="loginForm.password" type="password" placeholder="请输入密码"></el-input>
4. 登录按钮
新增点击登录触发事件
<!-- 新增 v-model 绑定表单数据 -->
<el-input v-model="loginForm.password" type="password" placeholder="请输入密码"></el-input>
二、script 脚本逻辑
模块1:引入项目依赖
导入vue工具、提示组件、路由、用户状态管理仓库
import { ref, reactive } from 'vue'
import { ElMessage } from 'element-plus'
import { useRouter } from 'vue-router'
import { useUserStore } from '@/store/modules/user'
作用:提供页面跳转、消息提示、全局用户信息管理能力
模块2:创建基础实例对象
import { ref, reactive } from 'vue'
import { ElMessage } from 'element-plus'
import { useRouter } from 'vue-router'
import { useUserStore } from '@/store/modules/user'
作用:
- router:控制页面路由跳转
- userStore:操作全局用户登录信息
- loginFormRef:获取表单DOM,用于表单校验
模块3:定义登录表单数据与校验规则
// 登录表单双向绑定数据
const loginForm = reactive({
username: '',
password: ''
})
// 表单非空校验
const loginRules = {
username: [{ required: true, message: '请输入用户名', trigger: 'blur' }],
password: [{ required: true, message: '请输入密码', trigger: 'blur' }]
}
作用:接收用户输入账号密码,判断输入内容是否为空
模块4:核心登录业务方法
const handleLogin = async () => {
// 1.执行表单校验
await loginFormRef.value.validate()
// 2.判断账号密码是否正确
if (loginForm.username === 'admin' && loginForm.password === '123456') {
// 3.登录成功,保存用户信息
userStore.setUserInfo({
username: 'admin',
nickname: '管理员'
})
ElMessage.success('登录成功')
// 4.跳转到系统首页
router.push('/home')
} else {
// 5.账号错误提示
ElMessage.error('用户名或密码错误')
}
}
功能完整流程:
表单校验 → 账号密码判断 → 存储用户信息 → 登录提示 → 页面跳转
三、逻辑回填完成 · 页面完整代码
<template>
<div class="login-page">
<div class="login-box page-card">
<h2 class="title">后台管理系统</h2>
<p class="sub-title">图书管理</p>
<el-form
ref="formRef"
:model="form"
:rules="rules"
label-position="top"
class="login-form"
>
<el-form-item label="账号" prop="username">
<el-input v-model="form.username" placeholder="请输入账号" clearable />
</el-form-item>
<el-form-item label="密码" prop="password">
<el-input
v-model="form.password"
type="password"
placeholder="请输入密码"
show-password
@keyup.enter="handleLogin"
/>
</el-form-item>
<el-button class="submit-btn" type="primary" :loading="loading" @click="handleLogin">
登录
</el-button>
</el-form>
<div class="tips">演示账号:admin | 演示密码:123456</div>
</div>
</div>
</template>
<script setup>
import { ref, reactive } from 'vue'
import { ElMessage } from 'element-plus'
import { useRouter } from 'vue-router'
import { useUserStore } from '@/store/modules/user'
const router = useRouter()
const userStore = useUserStore()
const formRef = ref(null)
const loading = ref(false)
const form = reactive({
username: 'admin',
password: '123456'
})
const rules = {
username: [
{ required: true, message: '请输入账号', trigger: 'blur' },
{ min: 3, max: 20, message: '账号长度 3-20 位', trigger: 'blur' }
],
password: [
{ required: true, message: '请输入密码', trigger: 'blur' },
{ min: 6, max: 20, message: '密码长度 6-20 位', trigger: 'blur' }
]
}
const handleLogin = async () => {
if (!formRef.value) return
await formRef.value.validate()
loading.value = true
setTimeout(() => {
userStore.login(form)
loading.value = false
ElMessage.success('登录成功')
router.push('/home')
}, 400)
}
</script>
<style scoped lang="scss">
.login-page {
display: flex;
align-items: center;
justify-content: center;
width: 100%;
height: 100%;
background: linear-gradient(145deg, #edf5ff 0%, #dbeaff 100%);
}
.login-box {
width: 420px;
padding: 34px 30px 28px;
}
.title {
margin: 0;
color: #2f5b96;
font-size: 28px;
text-align: center;
}
.sub-title {
margin: 8px 0 24px;
color: #6e8ab2;
font-size: 14px;
text-align: center;
}
.submit-btn {
width: 100%;
margin-top: 4px;
}
.tips {
margin-top: 16px;
color: #84a0c5;
font-size: 12px;
text-align: center;
}
</style>
图书管理页面 books 业务逻辑回填
一、template 模板改动说明
页面整体三层结构:搜索区域、表格区域、弹窗区域DOM结构完全不变
只新增数据绑定、渲染属性、点击事件、插槽内容、表单校验属性
1. 顶部搜索表单改动
<el-form :inline="true">
<el-input />
<el-select>
<el-option label="在库" />
<el-option label="借出" />
</el-select>
<el-button>查询</el-button>
<el-button>重置</el-button>
<el-button>新增图书</el-button>
回填新增内容
- form 添加 :model="queryForm" 表单数据绑定
- 输入框、下拉框添加 v-model 双向绑定、提示文字、清空属性
- option 补充 value 值
- 三个按钮分别绑定点击查询、重置、打开新增弹窗事件
<el-form :inline="true" :model="queryForm">
<el-input v-model="queryForm.keyword" placeholder="请输入书名关键字" clearable />
<el-select v-model="queryForm.status" placeholder="全部状态" clearable style="width: 140px">
<el-option label="在库" value="in" />
<el-option label="借出" value="out" />
</el-select>
<el-button type="primary" @click="handleSearch">查询</el-button>
<el-button @click="handleReset">重置</el-button>
<el-button type="success" @click="openAddDialog">新增图书</el-button>
2. el-table 表格整体改动
- 表格添加 :data="pagedList" 绑定分页渲染数据
- 每一列添加 prop 字段,绑定对应图书属性
- 价格、状态、时间列新增插槽,自定义页面展示格式
- 操作按钮绑定编辑弹窗、删除数据点击事件
3. 分页组件改动
<el-pagination
v-model:current-page="pagination.page"
v-model:page-size="pagination.pageSize"
:page-sizes="[5, 10, 20]"
layout="total, sizes, prev, pager, next, jumper"
:total="filteredList.length"
/>
4. 新增编辑弹窗 dialog 改动
- 弹窗添加 v-model 显示隐藏控制、动态标题
- 内部表单添加 ref 、 :model 、 :rules 校验规则
- 所有表单项添加 v-model 数据绑定、校验prop
- 底部取消、确认按钮绑定关闭弹窗、提交表单事件
二、script 脚本新增
骨架script为空,本次全部逻辑分为 8大功能模块
模块1:导入vue工具与消息组件
import { ref, reactive, computed } from 'vue'
import { ElMessage, ElMessageBox } from 'element-plus'
作用:提供响应式数据、计算属性、弹窗提示、删除确认弹窗
模块2:初始化图书模拟数据
const defaultBooks = [图书数组数据]
const books = ref(defaultBooks)
作用:存放所有图书列表基础数据,页面表格渲染来源
模块3:查询条件、分页、弹窗、表单基础数据
// 搜索条件
const queryForm = reactive({ keyword: '', status: '' })
// 分页信息
const pagination = reactive({ page: 1, pageSize: 10 })
// 弹窗控制
const dialogVisible = ref(false)
const isEdit = ref(false)
// 图书表单数据
const bookForm = reactive({...})
// 表单校验规则
const bookRules = {...}
模块4:筛选过滤 + 分页计算属性
// 根据关键词、状态筛选图书
const filteredList = computed(()=>{})
// 对筛选后数据进行分页切割
const pagedList = computed(()=>{})
功能:实现模糊搜索、状态筛选、表格分页展示
模块5:搜索与重置方法
const handleSearch = () => {
pagination.page = 1
}
const handleReset = () => {
queryForm清空,页码重置
}
作用:点击查询刷新数据,点击重置清空所有搜索条件
模块6:弹窗打开、表单重置逻辑
// 打开新增弹窗
const openAddDialog = ()=>{}
// 打开编辑弹窗,回填当前行数据
const openEditDialog = (row)=>{}
// 清空表单
const resetBookForm = ()=>{}
模块7:删除图书业务逻辑
const handleDelete = async (id) => {
弹出删除确认
过滤删除对应id数据
删除成功提示
}
模块8:新增 / 编辑提交表单逻辑
const handleSubmit = async () => {
表单校验
判断是编辑还是新增
编辑:修改原有数据
新增:插入新图书、自动生成时间id
关闭弹窗、提示成功
}
模块9:时间格式化工具方法
const formatDate = (dateTime) => {}
作用:把时间戳格式化成年月日时分秒标准格式
三、回填完成 · 完整最终代码
<template>
<div class="books-page">
<!-- 顶部搜索区域 -->
<div class="search-panel page-card">
<el-form :inline="true" :model="queryForm">
<el-form-item label="书名">
<el-input v-model="queryForm.keyword" placeholder="请输入书名关键字" clearable />
</el-form-item>
<el-form-item label="状态">
<el-select v-model="queryForm.status" placeholder="全部状态" clearable style="width: 140px">
<el-option label="在库" value="in" />
<el-option label="借出" value="out" />
</el-select>
</el-form-item>
<el-form-item>
<el-button type="primary" @click="handleSearch">查询</el-button>
<el-button @click="handleReset">重置</el-button>
<el-button type="success" @click="openAddDialog">新增图书</el-button>
</el-form-item>
</el-form>
</div>
<!-- 表格区域 -->
<div class="table-panel page-card">
<el-table :data="pagedList" stripe>
<el-table-column prop="name" label="书名" min-width="180" />
<el-table-column prop="author" label="作者" min-width="140" />
<el-table-column prop="category" label="分类" min-width="120" />
<el-table-column prop="price" label="价格" width="100">
<template #default="{ row }">¥{{ row.price }}</template>
</el-table-column>
<el-table-column prop="status" label="状态" width="100">
<template #default="{ row }">
<el-tag :type="row.status === 'in' ? 'success' : 'warning'">
{{ row.status === 'in' ? '在库' : '借出' }}
</el-tag>
</template>
</el-table-column>
<el-table-column prop="createdAt" label="创建时间" min-width="160">
<template #default="{ row }">{{ formatDate(row.createdAt) }}</template>
</el-table-column>
<el-table-column label="操作" width="180" fixed="right">
<template #default="{ row }">
<el-button link type="primary" @click="openEditDialog(row)">编辑</el-button>
<el-button link type="danger" @click="handleDelete(row.id)">删除</el-button>
</template>
</el-table-column>
</el-table>
<div class="pager">
<el-pagination
v-model:current-page="pagination.page"
v-model:page-size="pagination.pageSize"
:page-sizes="[5, 10, 20]"
layout="total, sizes, prev, pager, next, jumper"
:total="filteredList.length"
/>
</div>
</div>
<!-- 新增编辑弹窗 -->
<el-dialog v-model="dialogVisible" :title="isEdit ? '编辑图书' : '新增图书'" width="520px">
<el-form ref="bookFormRef" :model="bookForm" :rules="bookRules" label-width="80px">
<el-form-item label="书名" prop="name">
<el-input v-model="bookForm.name" placeholder="请输入书名" />
</el-form-item>
<el-form-item label="作者" prop="author">
<el-input v-model="bookForm.author" placeholder="请输入作者" />
</el-form-item>
<el-form-item label="分类" prop="category">
<el-input v-model="bookForm.category" placeholder="请输入分类" />
</el-form-item>
<el-form-item label="价格" prop="price">
<el-input-number v-model="bookForm.price" :min="1" :precision="2" />
</el-form-item>
<el-form-item label="状态" prop="status">
<el-radio-group v-model="bookForm.status">
<el-radio label="in">在库</el-radio>
<el-radio label="out">借出</el-radio>
</el-radio-group>
</el-form-item>
</el-form>
<template #footer>
<el-button @click="dialogVisible = false">取消</el-button>
<el-button type="primary" @click="handleSubmit">确认</el-button>
</template>
</el-dialog>
</div>
</template>
<script setup>
import { ref, reactive, computed } from 'vue'
import { ElMessage, ElMessageBox } from 'element-plus'
const defaultBooks = [
{ id: 1, name: 'Vue 3 实战进阶', author: '王明', category: '前端', price: 88, status: 'in', createdAt: '2026-04-10 10:20:33' },
{ id: 2, name: 'Node.js 企业开发', author: '张华', category: '后端', price: 79, status: 'out', createdAt: '2026-04-11 11:03:12' },
{ id: 3, name: '数据结构与算法', author: '李雷', category: '基础', price: 65, status: 'in', createdAt: '2026-04-12 08:28:46' },
{ id: 4, name: 'MySQL 性能优化', author: '陈晨', category: '数据库', price: 72, status: 'in', createdAt: '2026-04-12 16:12:05' },
{ id: 5, name: 'TypeScript 从入门到实战', author: '赵阳', category: '前端', price: 92, status: 'out', createdAt: '2026-04-13 09:44:38' },
{ id: 6, name: 'Linux 运维手册', author: '杨帆', category: '运维', price: 69, status: 'in', createdAt: '2026-04-14 14:05:20' },
{ id: 7, name: '微服务架构设计', author: '刘洋', category: '架构', price: 99, status: 'in', createdAt: '2026-04-15 17:20:08' },
{ id: 8, name: 'JavaScript 高级程序设计', author: '周涛', category: '前端', price: 85, status: 'out', createdAt: '2026-04-16 10:10:10' },
{ id: 9, name: 'Python 自动化办公', author: '何琳', category: '工具', price: 58, status: 'in', createdAt: '2026-04-17 13:31:52' },
{ id: 10, name: 'Redis 高并发实战', author: '吴迪', category: '缓存', price: 74, status: 'in', createdAt: '2026-04-18 09:18:26' },
{ id: 11, name: 'Nginx 配置指南', author: '宋佳', category: '运维', price: 66, status: 'out', createdAt: '2026-04-18 18:40:37' },
{ id: 12, name: '前端工程化实践', author: '林北', category: '前端', price: 89, status: 'in', createdAt: '2026-04-19 07:58:41' }
]
const books = ref(defaultBooks)
const queryForm = reactive({ keyword: '', status: '' })
const pagination = reactive({ page: 1, pageSize: 10 })
const dialogVisible = ref(false)
const isEdit = ref(false)
const bookFormRef = ref(null)
const bookForm = reactive({
id: null,
name: '',
author: '',
category: '',
price: 1,
status: 'in'
})
const bookRules = {
name: [{ required: true, message: '请输入书名', trigger: 'blur' }],
author: [{ required: true, message: '请输入作者', trigger: 'blur' }],
category: [{ required: true, message: '请输入分类', trigger: 'blur' }],
price: [{ required: true, message: '请输入价格', trigger: 'blur' }]
}
const filteredList = computed(() => {
const keyword = queryForm.keyword.trim().toLowerCase()
return books.value.filter((item) => {
const matchedKeyword =
!keyword ||
item.name.toLowerCase().includes(keyword) ||
item.author.toLowerCase().includes(keyword) ||
item.category.toLowerCase().includes(keyword)
const matchedStatus = !queryForm.status || item.status === queryForm.status
return matchedKeyword && matchedStatus
})
})
const pagedList = computed(() => {
const start = (pagination.page - 1) * pagination.pageSize
return filteredList.value.slice(start, start + pagination.pageSize)
})
const handleSearch = () => {
pagination.page = 1
}
const handleReset = () => {
queryForm.keyword = ''
queryForm.status = ''
pagination.page = 1
}
const resetBookForm = () => {
bookForm.id = null
bookForm.name = ''
bookForm.author = ''
bookForm.category = ''
bookForm.price = 1
bookForm.status = 'in'
}
const openAddDialog = () => {
isEdit.value = false
dialogVisible.value = true
resetBookForm()
}
const openEditDialog = (row) => {
isEdit.value = true
dialogVisible.value = true
Object.assign(bookForm, row)
}
const handleDelete = async (id) => {
await ElMessageBox.confirm('确认删除这条图书数据吗?', '提示', { type: 'warning' })
books.value = books.value.filter((item) => item.id !== id)
ElMessage.success('删除成功')
}
const handleSubmit = async () => {
if (!bookFormRef.value) return
await bookFormRef.value.validate()
if (isEdit.value) {
books.value = books.value.map((item) =>
item.id === bookForm.id ? { ...item, ...bookForm } : item
)
ElMessage.success('编辑成功')
} else {
books.value.unshift({
...bookForm,
id: Date.now(),
createdAt: new Date().toISOString().replace('T', ' ').slice(0, 19)
})
ElMessage.success('新增成功')
}
dialogVisible.value = false
pagination.page = 1
}
const formatDate = (dateTime) => {
const date = new Date(dateTime)
const year = date.getFullYear()
const month = String(date.getMonth() + 1).padStart(2, '0')
const day = String(date.getDate()).padStart(2, '0')
const hour = String(date.getHours()).padStart(2, '0')
const minute = String(date.getMinutes()).padStart(2, '0')
return `${year}-${month}-${day} ${hour}:${minute}`
}
</script>
<style scoped lang="scss">
.books-page {
display: flex;
flex-direction: column;
gap: 16px;
}
.search-panel,
.table-panel {
padding: 16px;
}
.pager {
display: flex;
justify-content: flex-end;
margin-top: 16px;
}
</style>
个人中心 profile 页面业务逻辑回填
一、template 模板改动说明
页面整体布局、头像区域、分割线、表单结构完全保留原始骨架,不增删任何标签
只回填数据绑定、插槽内容、表单属性、点击事件
1. 头像标签改动
回填后
<!-- 绑定头像地址 + 用户名首字母默认展示 -->
<el-avatar :size="96" :src="form.avatar">
{{ avatarText }}
</el-avatar>
2. 头像输入框
新增双向数据绑定
<el-input v-model="form.avatar" placeholder="请输入头像图片链接(可选)" clearable style="width: 320px" />
3. 外层表单整体回填属性
<!-- 新增表单实例、数据绑定、校验规则 -->
<el-form ref="formRef" :model="form" :rules="rules" label-width="90px" class="profile-form">
4. 各个表单项回填
- 用户名输入框:新增 :model-value 数据回显
- 昵称、邮箱、手机号输入框:全部添加 v-model 双向绑定、表单校验prop
- 保存按钮:新增点击保存事件 @click="handleSave"
二、script 脚本新增逻辑
模块1:导入项目依赖
import { computed, reactive, ref } from 'vue'
import { ElMessage } from 'element-plus'
import { useUserStore } from '@/store/modules/user'
作用:引入vue响应式API、消息提示、全局用户信息仓库
模块2:获取用户仓库与表单实例
const userStore = useUserStore()
const formRef = ref(null)
模块3:回填用户信息表单数据
从全局仓库读取登录用户信息,赋值给表单
const form = reactive({
username: userStore.userInfo.username || 'admin',
nickname: userStore.userInfo.nickname || '',
email: userStore.userInfo.email || '',
phone: userStore.userInfo.phone || '',
avatar: userStore.userInfo.avatar || ''
})
模块4:头像默认文字计算属性
const avatarText = computed(() => (form.username ? form.username.slice(0, 1).toUpperCase() : 'U'))
功能:没有头像链接时,自动展示用户名第一个大写字母
模块5:表单校验规则
const rules = {
nickname: [{ required: true, message: '请输入昵称', trigger: 'blur' }],
email: [
{ required: true, message: '请输入邮箱', trigger: 'blur' },
{ type: 'email', message: '邮箱格式不正确', trigger: 'blur' }
],
phone: [
{ required: true, message: '请输入手机号', trigger: 'blur' },
{ pattern: /^1\d{10}$/, message: '手机号格式不正确', trigger: 'blur' }
]
}
作用:校验昵称、邮箱、手机号格式与非空
模块6:个人信息保存核心方法
const handleSave = async () => {
// 表单校验
await formRef.value.validate()
// 更新全局用户信息
userStore.updateUserInfo({
nickname: form.nickname,
email: form.email,
phone: form.phone,
avatar: form.avatar
})
ElMessage.success('个人信息保存成功')
}
执行流程:
表单校验 → 提交数据 → 更新仓库用户信息 → 保存成功提示
三、回填完成 · 个人中心完整最终代码
<template>
<div class="profile-page page-card">
<div class="avatar-section">
<el-avatar :size="96" :src="form.avatar">
{{ avatarText }}
</el-avatar>
<div class="avatar-actions">
<div class="avatar-title">用户头像</div>
<el-input
v-model="form.avatar"
placeholder="请输入头像图片链接(可选)"
clearable
style="width: 320px"
/>
<div class="avatar-tip">不填写时将显示用户名首字母。</div>
</div>
</div>
<el-divider />
<el-form ref="formRef" :model="form" :rules="rules" label-width="90px" class="profile-form">
<el-form-item label="用户名">
<el-input :model-value="form.username" readonly />
</el-form-item>
<el-form-item label="昵称" prop="nickname">
<el-input v-model="form.nickname" placeholder="请输入昵称" />
</el-form-item>
<el-form-item label="邮箱" prop="email">
<el-input v-model="form.email" placeholder="请输入邮箱" />
</el-form-item>
<el-form-item label="手机号" prop="phone">
<el-input v-model="form.phone" placeholder="请输入手机号" />
</el-form-item>
<el-form-item>
<el-button type="primary" @click="handleSave">保存修改</el-button>
</el-form-item>
</el-form>
</div>
</template>
<script setup>
import { computed, reactive, ref } from 'vue'
import { ElMessage } from 'element-plus'
import { useUserStore } from '@/store/modules/user'
const userStore = useUserStore()
const formRef = ref(null)
const form = reactive({
username: userStore.userInfo.username || 'admin',
nickname: userStore.userInfo.nickname || '',
email: userStore.userInfo.email || '',
phone: userStore.userInfo.phone || '',
avatar: userStore.userInfo.avatar || ''
})
const avatarText = computed(() => (form.username ? form.username.slice(0, 1).toUpperCase() : 'U'))
const rules = {
nickname: [{ required: true, message: '请输入昵称', trigger: 'blur' }],
email: [
{ required: true, message: '请输入邮箱', trigger: 'blur' },
{ type: 'email', message: '邮箱格式不正确', trigger: 'blur' }
],
phone: [
{ required: true, message: '请输入手机号', trigger: 'blur' },
{ pattern: /^1\d{10}$/, message: '手机号格式不正确', trigger: 'blur' }
]
}
const handleSave = async () => {
if (!formRef.value) return
await formRef.value.validate()
userStore.updateUserInfo({
nickname: form.nickname,
email: form.email,
phone: form.phone,
avatar: form.avatar
})
ElMessage.success('个人信息保存成功')
}
</script>
<style scoped lang="scss">
.profile-page {
padding: 20px;
}
.avatar-section {
display: flex;
gap: 16px;
align-items: center;
}
.avatar-actions {
display: flex;
flex-direction: column;
gap: 8px;
}
.avatar-title {
color: #2f5b96;
font-size: 15px;
font-weight: 600;
}
.avatar-tip {
color: #87a2c7;
font-size: 12px;
}
.profile-form {
max-width: 560px;
}
</style>
Pinia User.js业务逻辑补全
分步补充 + 每一步说明新增作用
第1步:定义本地存储常量
新增:
// 本地存储key常量,统一管理
const TOKEN_KEY = 'admin_token'
const USER_INFO_KEY = 'admin_user_info'
作用:
把 token、用户信息存在 localStorage 的键名抽成常量,后期改名字只改一处就行。
第2步:重构 state 状态,扩充字段 + 读取本地缓存
原来state只有 username、isLogin
替换完善后:
state: () => ({
// 登录令牌,从本地缓存读取
token: localStorage.getItem(TOKEN_KEY) || '',
// 完整用户信息,无缓存给默认空对象
userInfo: JSON.parse(localStorage.getItem(USER_INFO_KEY) || 'null') || {
username: '',
nickname: '',
email: '',
phone: '',
avatar: ''
}
})
新增&改动说明:
1. 删掉简陋的 isLogin 字面变量
2. 新增 token 作为登录身份凭证
3. 新增 userInfo 存放全套个人资料(用户名、昵称、邮箱、手机号、头像)
4. 初始化自动从 localStorage 读取,刷新页面登录状态不丢失
第3步:新增 getters 计算属性
getters: {
// 通过是否有token,统一判断是否登录
isLogin: (state) => Boolean(state.token)
}
作用:
- 统一封装登录判断逻辑
- 后面路由守卫、layout页面直接用 userStore.isLogin ,不用重复写判断token
第4步:补全 actions 三个核心方法
4.1 新增 login 登录方法
login(loginForm) {
// 模拟后端生成token
const mockToken = `token_${Date.now()}`
this.token = mockToken
// 赋值用户信息
this.userInfo = {
username: loginForm.username,
nickname: '系统管理员',
email: 'admin@example.com',
phone: '13800138000',
avatar: ''
}
// 状态持久化到本地
localStorage.setItem(TOKEN_KEY, mockToken)
localStorage.setItem(USER_INFO_KEY, JSON.stringify(this.userInfo))
}
作用:
登录页调用 → 保存token、用户信息到Pinia + 本地缓存
4.2 新增 updateUserInfo 更新个人信息方法
updateUserInfo(payload) {
// 合并原有信息和新修改的字段
this.userInfo = {
...this.userInfo,
...payload
}
// 同步更新本地缓存
localStorage.setItem(USER_INFO_KEY, JSON.stringify(this.userInfo))
}
作用:
个人中心页面保存修改时调用 → 局部更新用户资料,不覆盖原有字段
4.3 logout 退出登录方法
logout() {
// 清空pinia状态
this.token = ''
this.userInfo = {
username: '',
nickname: '',
email: '',
phone: '',
avatar: ''
}
// 清空本地存储
localStorage.removeItem(TOKEN_KEY)
localStorage.removeItem(USER_INFO_KEY)
}
作用:
Layout头部退出按钮调用 → 清空登录状态、清空本地缓存
完整 Pinia 最终代码
import { defineStore } from 'pinia'
// 本地存储key常量
const TOKEN_KEY = 'admin_token'
const USER_INFO_KEY = 'admin_user_info'
export const useUserStore = defineStore('user', {
state: () => ({
token: localStorage.getItem(TOKEN_KEY) || '',
userInfo: JSON.parse(localStorage.getItem(USER_INFO_KEY) || 'null') || {
username: '',
nickname: '',
email: '',
phone: '',
avatar: ''
}
}),
getters: {
isLogin: (state) => Boolean(state.token)
},
actions: {
// 登录:保存token和用户信息
login(loginForm) {
const mockToken = `token_${Date.now()}`
this.token = mockToken
this.userInfo = {
username: loginForm.username,
nickname: '系统管理员',
email: 'admin@example.com',
phone: '13800138000',
avatar: ''
}
localStorage.setItem(TOKEN_KEY, mockToken)
localStorage.setItem(USER_INFO_KEY, JSON.stringify(this.userInfo))
},
// 更新个人资料
updateUserInfo(payload) {
this.userInfo = { ...this.userInfo, ...payload }
localStorage.setItem(USER_INFO_KEY, JSON.stringify(this.userInfo))
},
// 退出登录
logout() {
this.token = ''
this.userInfo = {
username: '',
nickname: '',
email: '',
phone: '',
avatar: ''
}
localStorage.removeItem(TOKEN_KEY)
localStorage.removeItem(USER_INFO_KEY)
}
}
})
router路由配置业务逻辑补全
分步增补改造
步骤1:引入 Pinia 用户仓库
在顶部新增导入:
import { useUserStore } from '@/store/modules/user'
作用
路由守卫需要读取 isLogin 登录状态,做页面访问权限拦截。
步骤2:路由统一改成「懒加载」+ 补充 name、meta 元信息
1. 所有页面都改成路由懒加载 () => import() ,减小首屏体积
2. 给每个路由加 name 命名,便于编程式跳转
3. 新增 meta: { title: '页面名称' } ,用来动态设置浏览器标签标题
改造后单个路由示例:
{
path: '/login',
name: 'Login',
component: () => import('@/views/login/index.vue'),
meta: { title: '登录' }
}
步骤3:新增 404 兜底路由
加到 routes 最后一项:
{
path: '/:pathMatch(.*)*',
redirect: '/home'
}
作用
访问不存在的地址,自动跳转到首页,避免空白页。
步骤4:新增全局路由守卫 beforeEach
router.beforeEach((to) => {
const userStore = useUserStore()
const hasToken = userStore.isLogin
// 未登录:除登录页外全部拦截,跳登录
if (!hasToken && to.path !== '/login') {
return '/login'
}
// 已登录:禁止再进入登录页,直接跳首页
if (hasToken && to.path === '/login') {
return '/home'
}
// 动态设置浏览器网页标题
if (to.meta?.title) {
document.title = `${to.meta.title} - 图书后台管理系统`
} else {
document.title = '图书后台管理系统'
}
return true
})
三大核心功能:
1. 登录权限拦截:没登录只能看登录页
2. 重复登录拦截:已登录不能回登录页
3. 动态网页标题:根据路由 meta 自动改标签名
完整路由代码
import { createRouter, createWebHistory } from 'vue-router'
// 引入pinia用户仓库,用于路由守卫权限控制
import { useUserStore } from '@/store/modules/user'
const routes = [
{
path: '/login',
name: 'Login',
component: () => import('@/views/login/index.vue'),
meta: { title: '登录' }
},
{
path: '/',
component: () => import('@/layout/index.vue'),
redirect: '/home',
children: [
{
path: 'home',
name: 'Home',
component: () => import('@/views/home/index.vue'),
meta: { title: '首页' }
},
{
path: 'books',
name: 'Books',
component: () => import('@/views/books/index.vue'),
meta: { title: '图书管理' }
},
{
path: 'profile',
name: 'Profile',
component: () => import('@/views/profile/index.vue'),
meta: { title: '个人中心' }
}
]
},
// 404兜底路由
{
path: '/:pathMatch(.*)*',
redirect: '/home'
}
]
const router = createRouter({
history: createWebHistory(),
routes
})
// 全局路由守卫
router.beforeEach((to) => {
const userStore = useUserStore()
const hasToken = userStore.isLogin
// 未登录拦截
if (!hasToken && to.path !== '/login') {
return '/login'
}
// 已登录禁止进入登录页
if (hasToken && to.path === '/login') {
return '/home'
}
// 设置网页标题
if (to.meta?.title) {
document.title = `${to.meta.title} - 图书后台管理系统`
} else {
document.title = '图书后台管理系统'
}
return true
})
export default router
收尾调试与项目现存可优化点总结
调试部分
业务逻辑代码虽然全部写完了,但编码完成不等于项目可用,还需要做一轮基础调试自检:
对于这个小项目主要简单验证这几块就行:
- 路由跳转、登录拦截是否正常生效
- 刷新页面,登录状态、用户信息是否持久化保留
- 图书新增、编辑、删除、查询分页流程是否通顺无报错
- 个人中心修改信息后,全局状态是否同步更新
简单跑一遍核心流程,确保没有明显 Bug、逻辑能正常闭环就行,不用做专业级测试用例。
项目现存不足 & 可优化点
目前项目虽然功能完整,但偏业务实现版,工程化复用和封装还比较初级,主要不足有这些:
1. 组件没有抽离封装
搜索栏、表格、新增编辑弹窗都写在页面内部,没有抽成公共组件,复用性差。
2. 业务逻辑没做抽离
所有逻辑都写在页面 script setup 里,没有用 Vue3 自定义 Hook 拆分,后期不好维护。
3. 模拟数据、工具方法散落页面
图书模拟数据、时间格式化方法直接写在页面,没有统一抽离到 mock、utils 目录管理。
4. 没有封装统一请求层
目前都是前端本地模拟数据,没有封装 axios 统一请求,后续对接后端还要大改。
5. Pinia 和路由偏基础用法
只用了基础登录状态管理,没有按业务拆分仓库;路由只有基础登录拦截,没做动态菜单、细粒度权限控制。
6. 很多写法偏硬编码
状态标识、文字、配置都直接写死在页面里,没有抽离全局常量管理。
图书后台管理系统 整体总结
至此,这个简易Vue3 图书后台管理系统 主体开发全部完成。
项目遵循先页面骨架、后业务逻辑、最后底层架构的开发思路,依次完成登录、布局、首页、图书管理、个人中心页面搭建;实现图书查询、筛选、分页、增删改查全业务,以及个人信息编辑、表单校验等功能;再配合 Pinia 状态管理 和 Vue Router 路由守卫,实现登录持久化、路由权限拦截,整套系统业务流程完全闭环。
经过核心流程简易调试,主干功能运行稳定。目前虽已满足图书管理基础使用,但仍存在组件未封装、逻辑未抽离、工程化复用性不高等问题,后续可从公共组件抽取、业务Hook拆分、接口封装、权限细化等方向继续优化迭代。
通过这个图书后台管理系统的完整梳理,不仅熟练了 Vue3 组合式 API、Pinia 状态管理、Vue Router 路由守卫在实战中的落地用法,也锻炼前端项目拆分开发、分层构建、先功能后优化的思维模式,不管是作为练手实战、项目案例,还是后续二次扩展开发,都具备一定的参考价值。