Harness Engineering:驾驭 AI Agent 的工程学
"任何时候当你发现一个 agent 犯了一个错误,你就花时间工程化地解决它,使得这个 agent 再也不会犯那个错误。"
— Mitchell Hashimoto(Terraform / Ghostty 作者,Harness Engineering 早期推广者之一)
换了更好的模型,只提升了 0.7%
LangChain 用一次实验把一件事说清楚了。
他们拿同一个模型参加 Terminal Bench 2.0 基准测试:默认设置跑出 52.8 分,排第 30 名;什么模型参数都没改,只调整了 agent 的运行环境——文档结构、验证回路、追踪系统——分数跳到 66.5,排名升到第 5 名,提升 26%。
对比组:换成更好的模型,提升 0.7%。
这组数字在工程师圈子里流传了很久。不是因为好看,而是因为它指向一个让人不舒服的问题:如果你的 AI 工程精力都集中在"换更好的模型"上,你可能把 99% 的注意力放在了那 0.7% 的空间里。
这就是 Harness Engineering 要解决的问题。
三次范式跃迁
AI 工程已经走过了三代。每一代工程师的焦点都不一样:
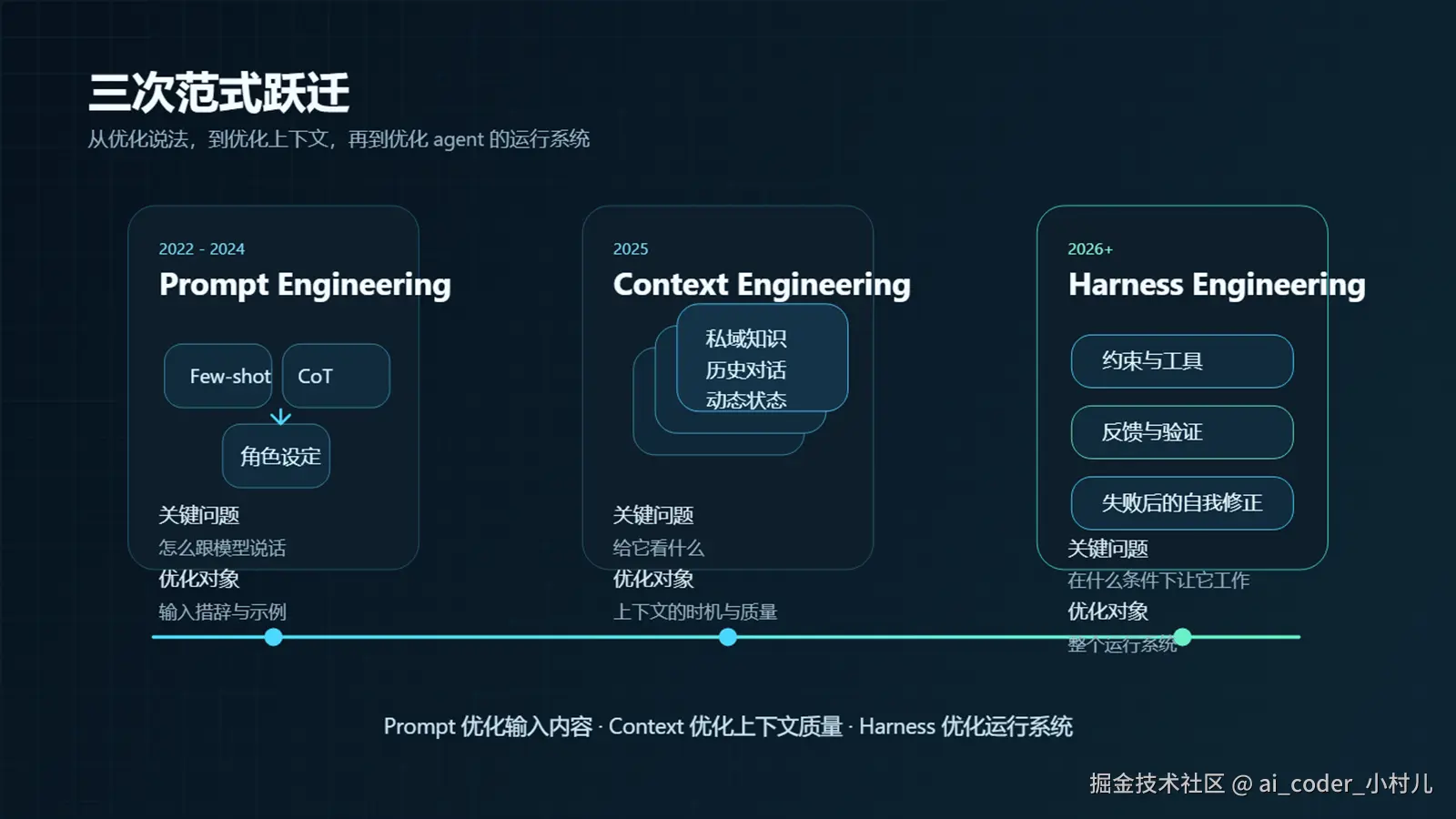
第一代:Prompt Engineering(2022-2024),问题是"怎么跟模型说话"。Few-shot、Chain-of-Thought、角色设定——工程师花大量时间打磨措辞,因为同一个问题换种说法,结果可能天差地别。
第二代:Context Engineering(2025),瓶颈转移了。影响质量的不再是怎么说,而是给它看什么。私域知识、历史对话、动态状态——怎么把正确的信息在正确的时机送进上下文窗口,成了核心工程问题。
第三代:Harness Engineering(2026 起),瓶颈再次转移。问题不再只是"给 agent 看什么",而是"在什么样的系统里让它工作"——约束、工具、反馈机制、验证回路,以及在 agent 出错时让整个系统能自我修正的能力。
Prompt Engineering → 优化说话方式
Context Engineering → 优化信息质量
Harness Engineering → 优化运行系统
OpenAI 在内部实验报告里直接说了:
"早期进展比预期慢,不是因为 Codex 能力不足,而是因为环境设计不充分。Agent 缺少可靠推进目标所需的工具、抽象和内部结构。"
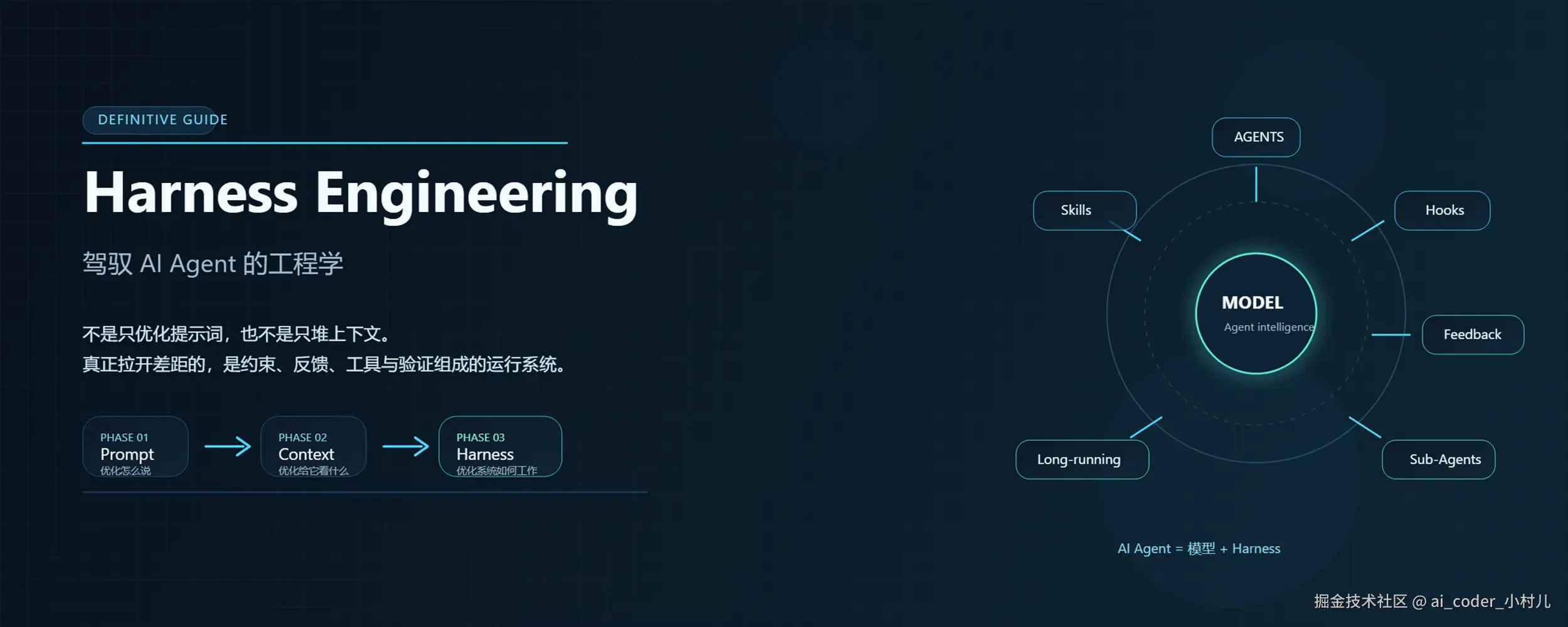
什么是 Harness Engineering?
"Harness" 来自马术——那套套在马身上、用于控制和驾驭的整套装具:笼头、缰绳、胸带、肚带。它不是让你骑马,而是让马在你设计的系统里知道该往哪走、什么时候停、哪里绝对不能踏入。
在 AI agent 的语境里,harness 指的是模型本身以外的一切:
AI Agent = 模型 + Harness
包括上下文配置、工具集、约束规则、反馈循环、子 agent 架构——所有让模型在你的具体问题域里可靠工作的工程设施。
这个概念由实践者 Viv 首创,Mitchell Hashimoto 是最早公开使用并推广它的人之一。他给出的定义极其简洁:每当发现一个 agent 犯了错,就把这个错变成物理上不可能再发生的事。不是修 prompt,不是换模型——是工程化地消灭这类失败。
Harness Engineering 不是一个框架,不是一个库,是一套工程实践哲学。
这些都不是 PPT 数字
在讨论怎么做之前,先看几个已经在生产里跑的案例:
Peter Steinberger(OpenClaw 作者):一个人,一个月 6600+ commits,同时运行 5-10 个 agent,发布的是自己没有逐行读过的代码。
OpenAI 内部团队:3 名工程师,5 个月,用 Codex 建造了一个百万行的内部产品,零行手写代码(by design)。平均每人每天 3.5 个 PR,吞吐量随团队增长持续提升。
Stripe Minions:内部 coding agent,每周合并超过 1000 个 PR。工程师在 Slack 发任务,agent 写代码、跑 CI、开 PR,全程无需人工干预。
8Lee(YEN 作者):一条命令 $zip,编译、签名、公证一个覆盖 30 种语言的 macOS 桌面应用,15 分钟完成,近 1000 次发布,零次出错。
Anthropic 内部实验:16 个 Claude 实例并行写 C 语言编译器,历经 2000 个 session、两周时间、约两万美元 API 费用,产出了 10 万行编译器代码——能编译出可以正常启动 Linux 的程序。
以上都不是 demo,都是真实规模的生产系统。让它们得以运转的,是各自精心设计的 harness。
越快越慢:AI 的速度陷阱
这里有一组让人不舒服的数字,来自 Harness 的《2026 DevOps 现代化报告》:
在每天频繁使用 AI 工具的重度用户里:
-
69% 表示 AI 生成的代码会频繁引发部署问题
- 事故恢复平均时长 7.6 小时,比轻度用户还要长
-
47% 反映下游的手工工作——QA、验证、修复——比以前更繁重
DORA 的数据从另一个角度印证了同样的问题:AI 让个人生产率提升 19%,但组织吞吐量只提升了 3%,交付稳定性甚至下降了 9%。
写代码的速度提升了,但交付系统被暴露了。就像把火车开得更快,但铁路还是按原来的时速设计的——摩擦越来越大,随时有翻车风险。
加速代码生成,不等于加速软件交付。 Harness 是连接两者的桥梁。
模型偷懒:一个比"上下文太长"更深的问题
在讲具体的工程实践之前,有一个反直觉的研究结论值得单独讲清楚,因为它影响了 harness 设计的底层逻辑。
大家都知道上下文太长会影响模型表现。但通常的解释是"模型被搞混了"。Yandex 研究员 Rodionov 的实验推翻了这个假设:
模型不是被搞混了,它是选择了少思考。
他向 Qwen 的上下文里注入 128 个随机 token 的噪音——仅仅 128 个 token。结果:
- 准确率从 74.5% 降到 67.8%
- 推理 token 数量从 28,771 降到 16,415,减少了 43%
- 推理深度下降 18%
更反直觉的:推理能力越强的模型,退化越严重。
噪音触发的不是混乱,是懒惰。模型看到上下文质量下降,会主动降低思考投入。
Anthropic 的情感研究团队在模型内部找到了这个现象的神经层面解释:他们发现了一个"desperate(绝望)"情感向量——当它激活时,模型倾向于走捷径、寻找替代路径逃避任务。对应地存在一个"calm(平静)"向量,能抑制这种倾向。
这对 harness 设计有直接影响:上下文管理的核心不只是过滤信息,而是防止信号质量下降触发模型的懒惰机制。你需要保证进入 agent 的每一条信息都是高信噪比的。
Harness Engineering 的六个核心组件

1. AGENTS.md:写给 AI 的操作手册
大多数项目有 README,但 README 是写给人类的。AGENTS.md(或 CLAUDE.md)是写给 AI 的——每次 agent 启动都会读这个文件。
AGENTS.md 的本质不是描述项目,而是记录历史失败。
Hashimoto 在他的终端模拟器 Ghostty 里观察到:这个文件里的每一行,都对应一次真实发生过的 agent 失败。它不是他预先设计的规则,是他从真实错误里提炼出来的防火墙。
# AGENTS.md(节选自实战案例)
## 代码签名规则
- **绝对不要**使用 `codesign --deep`,它会生成无效的嵌套签名
- 正确的签名顺序是从内到外:先签最内层二进制,最后签外层 app bundle
## Git 操作规则
- **绝对不要**使用 `git add -A`,除非你刚刚运行了 `git status`
- **绝对不要** force push,除非被明确要求
## 测试规则
- **绝对不要**写只测试 mock 行为的测试
- **绝对不要**因为测试失败就删除测试
写法有数据支撑。 Vlad Temian 做了 150+ 次实验测量 Claude 对指令的遵从率:
| 写法 |
遵从率 |
| 简洁强硬("NEVER do X") |
94.8% |
| 详细解释("Because of reason Y, you should consider not doing X") |
86.6% |
ETH 苏黎世的研究也发现,大多数 AGENTS.md 文件要么没用,要么有害——主要原因是太长、太模糊、包含条件性规则。让 AI 帮你生成这个文件,实际上会降低性能,还额外消耗 20% 以上的 token。
几条实践原则:
- 总长度控制在 300 行以内(HumanLayer 自己的在 60 行以下)
- 每条规则一句话,不加解释,不加"因为"
- 只放普遍适用的规则,条件性规则用技能(Skills)处理
- 手工写,每次 agent 犯错后更新
2. Hooks:把"告知"变成"拦截"
这是 Harness Engineering 里最反直觉但最有效的洞见:
强制执行远比告知可靠。
写在 AGENTS.md 里的规则,agent 可能在某个复杂的上下文里忽略掉。在命令执行之前拦截它的脚本,agent 物理上无法绕过。
#!/bin/bash
# guard-codesign-deep.sh
if echo "$TOOL_INPUT" | grep -q '\-\-deep'; then
echo "BLOCKED: codesign --deep 会产生无效的嵌套签名。"
echo "正确做法:从内到外签名,先签最内层二进制,最后签外层 app。"
exit 1
fi
这 5 行脚本比任何 prompt 都可靠。不管上下文有多长,不管 prompt 多复杂,agent 永远不会成功执行 codesign --deep。
8Lee 为 YEN 项目定义了 5 个 hook,覆盖他认为最危险的失败场景:
| Hook |
防护目标 |
block-rm.sh |
防止 rm -rf 灾难性删除 |
guard-force-push.sh |
保护 commit 历史 |
guard-codesign-deep.sh |
强制正确的签名顺序 |
guard-vendor.sh |
防止直接修改第三方库 |
guard-sensitive-file.sh |
防止 .env、.pem、.key 泄露 |
总投入:约 2 小时。收益:近千次发布零安全事故。
3. 架构即护栏:越相信 AI,越需要给它设限
OpenAI 内部团队在构建百万行产品时得出了一个反直觉的结论:
"Agent 在有严格边界和可预测结构的环境里效率最高。所以我们围绕极度刚性的架构模型构建应用。每个业务域被分成固定的几层,依赖方向经过严格验证,可接受的边集非常有限。这些约束通过自定义 linter(由 Codex 生成)和结构测试机械地强制执行。"
Thoughtworks 的 Birgitta Böckeler 把这个原则概括得很清晰:
提高对 AI 生成代码的信任,需要缩小选择空间,而不是扩大自由度。
- 架构灵活 → agent 每个决策点都有太多可能性 → 行为不可预测
- 架构刚性 → agent 每个决策点只有少数合法选项 → 行为可靠
这里有一个工程上的精妙设计:OpenAI 团队的 linter 报错同时包含修复指南:
❌ ArchViolation: service-layer 不能直接依赖 repository-layer
解决方案:通过 domain-service 接口访问,参见 docs/architecture.md#dependency-rules
工具不只在拦截,它在教 agent 下一步该怎么做。
4. Sub-Agent 架构:Context 防火墙与并发控制
Context Rot(上下文腐化)是真实的,而且比你想象的更深
Chroma 测试了 18 个模型,发现随着 context window 长度增加,模型在任务上的表现单调下降——即使是简单任务。当上下文里有低语义相关的干扰项时,下降更陡。
这还有一个更隐蔽的问题:Context Anxiety(上下文焦虑)——部分模型在感知到 context window 快满时,会主动提前收尾、跳过尚未完成的步骤。Agent 不是因为任务完成了才停,而是因为它"感觉快撑不住了"就停了。
结合前文的 Rodionov 研究,上下文问题的全貌是:质量下降触发懒惰,容量耗尽触发焦虑。两者都不是"模型被搞混了",而是模型主动选择了少做。
解决方案不是更大的 context window(那只是让稻草堆更大)。是 Sub-Agent 架构:
Main Agent(规划 + 编排,昂贵模型 Opus)
├── Sub-Agent A(代码库探索,便宜模型 Haiku)→ 只返回文件路径:行号
├── Sub-Agent B(安全审计,便宜模型 Haiku)→ 只返回漏洞列表
└── Sub-Agent C(依赖分析,便宜模型 Haiku)→ 只返回版本建议
每个 sub-agent 在隔离的 context window 里运行,只有最终浓缩的结果传回主线程。主 agent 的上下文始终保持干净、高信噪比。
并发架构:更进一步
当单个 agent 能稳定工作后,下一个问题是:能不能同时派出一百个去干活?
不能直接堆数量。 Cursor 团队的教训:让几百个 agent 共享一份大型项目,当 20 个 agent 同时工作时,有效吞吐量下降到只相当于两三个 agent。原因是上下文互相污染,加上全局资源的争抢。
成熟的并发架构是三层分工:
Planner(规划器)— 分解任务,分配工作,不写代码
└── Worker(执行器)× N — 各自在隔离环境里执行
└── Judge(裁判)— 独立验证,不参与执行
配合 DAG 引擎确保工作单向流动,防止循环依赖。
Anthropic 在并发 agent 里找到了另一个优雅的设计:GAN 启发的 Generator + Evaluator 对抗结构。评估者不只看结果,而是亲自动手验货——打开浏览器、点击页面、验证报错栈,像真实用户一样操作一遍。Generator 和 Evaluator 先协商"做完长什么样",再各自工作,形成对抗性的质量保证。
8Lee 的 $team 技能把这个思路推到了极致:8 个独立 agent 做代码评审,最后一个是 Devil's Advocate(唱反调的),专门挑战其他 7 个 agent 的所有建议。它检查严重性评级、标记假阳性、找矛盾。对抗性自我纠正,内置在 skill 结构里。
5. 长时任务 Harness:失忆实习生问题
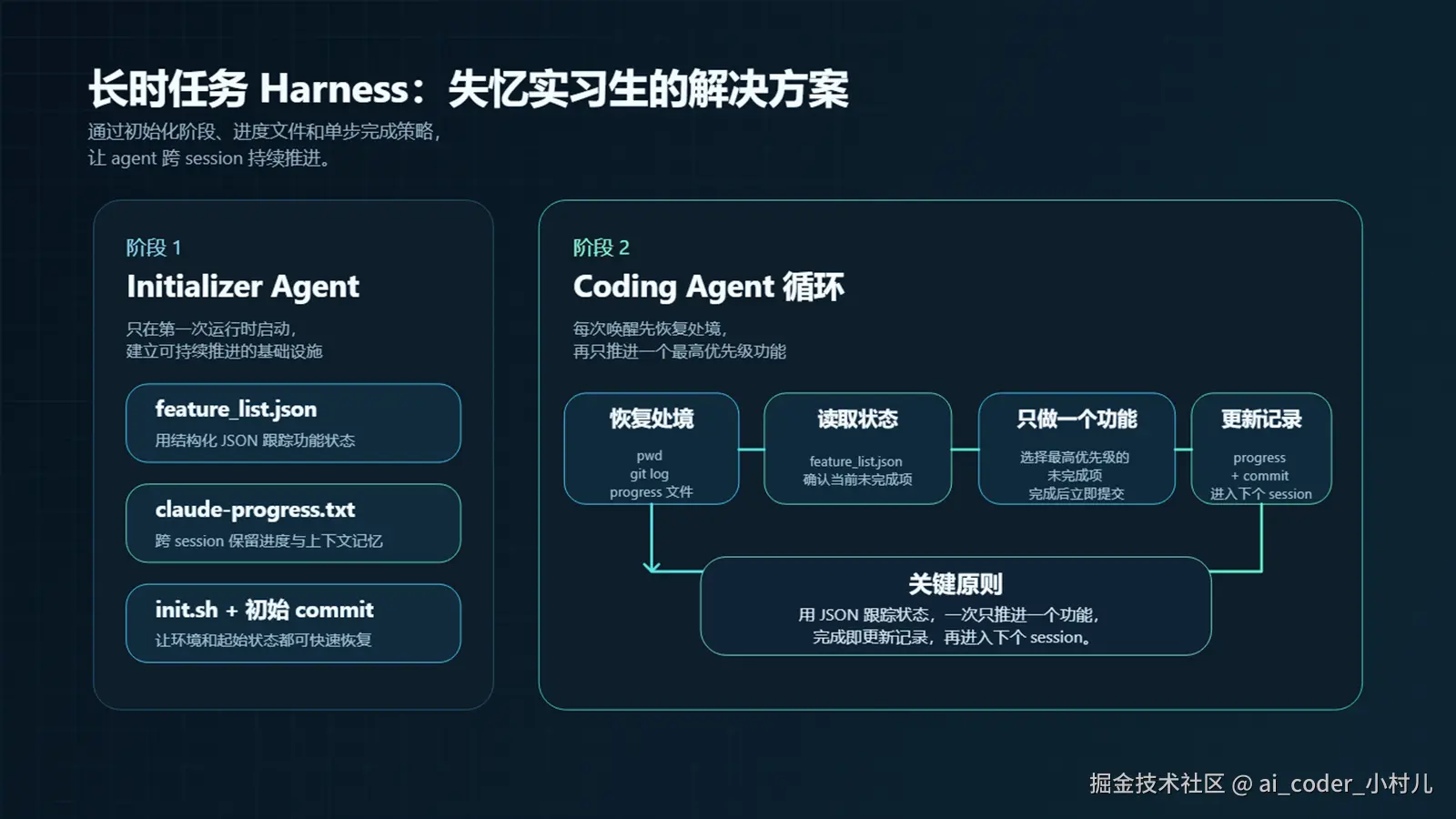
这是很多人没有意识到的一个独立问题。
长时任务的核心挑战:Agent 必须在多个 context window 里工作,而每次新的 session 开始时,它完全不记得之前发生了什么。就像一个软件项目由工程师轮班完成,每个新来的工程师对之前的工作没有任何记忆。
Anthropic 在实验中观察到了两个典型失败模式:
-
"一口气干完":agent 试图一次性完成所有功能,上下文耗尽后留下半成品,下个 session 花时间重建状态,再从头来
-
"差不多了":agent 看到一点进展就宣布"完成了",然后停工
他们的解法是双 agent 架构:
Initializer Agent(初始化 agent),只在第一次运行时启动,建立:
-
feature_list.json:完整功能列表,每项初始为 "passes": false
-
init.sh:一键启动开发服务器
-
claude-progress.txt:每个 session 都会更新的进度日志
- 初始 git commit
Coding Agent(编码 agent),后续每次 session 开始时执行固定的三步:
# 三步定位:让 agent 快速了解自己的处境
1. pwd # 确认工作目录
2. git log --oneline -20 # 了解最近发生了什么
3. cat claude-progress.txt # 看上一班留下的进度
然后读取 feature_list.json,选优先级最高的未完成功能,一次只做一个,完成即更新状态并 commit。
一个值得注意的细节:用 JSON,不用 Markdown。实验发现,模型倾向于不当地覆盖 Markdown 文件,对结构化 JSON 则克制得多——它只改 "passes" 字段的值,不会擅自删除条目。
这把每个 coding session 变成了一个纯函数:
f(功能列表 + git 历史 + 进度文件) → 完成一个功能 + 更新记录
6. Skills:按需加载,而不是全部预装
大多数人遇到问题的第一反应是:把所有信息塞进系统提示。
结果是:agent 在看完一万 token 的指令之后,剩下的可用注意力所剩无几。OpenAI 把这叫做"1000 页说明书变成陈旧规则的坟场"。
技能(Skills)的解法是按需披露:
- agent 只在需要某个能力时,才加载对应的技能文档
- 每个技能是一个目录,包含
SKILL.md 和相关资源
- 加载时,技能内容作为消息注入当前上下文
8Lee 的实现分三层:
Level 1:SKILL.md 封面(~100 tokens)——技能发现,Agent 决定是否需要
Level 2:SKILL.md 主体(~800-1000 tokens)——阶段图、协议、所有 guards
Level 3:当前阶段的参考文件(~200-600 tokens)——只加载正在执行的阶段
上下文的消耗量始终与当前任务的复杂度成正比,而不是与整个项目的复杂度成正比。
更完整的分析框架:Feedforward + Feedback

Thoughtworks 的 Birgitta Böckeler 提出了一个系统化的思考框架,把 harness 的所有控制机制划分成两个维度。
维度一:控制方向
Feedforward(前馈控制) — 在 agent 行动之前引导它:AGENTS.md 里的规则、架构约束说明、Skill 里的 how-to 指南。
Feedback(反馈控制) — 在 agent 行动之后感知并纠正:测试结果、Linter 输出、类型检查错误。
只有 Feedforward,agent 知道规则但无法验证自己是否遵守了。只有 Feedback,agent 会反复犯同类错误,因为没有预防。两者缺一不可。
维度二:执行类型
Computational(计算型) — 确定性的,CPU 执行:测试、linter、类型检查、结构分析。毫秒到秒级,结果完全可靠,便宜,可以每次提交都跑。
Inferential(推断型) — 语义分析,LLM 执行:AI 代码评审、"LLM 作裁判"。慢而贵,有不确定性,但能处理需要语义判断的场景。
组合起来:
|
Feedforward |
Feedback |
| Computational |
架构边界 linter |
结构测试、覆盖率 |
| Inferential |
AGENTS.md 规则、Skills |
AI 代码评审 |
最佳实践是:尽量用 Computational,把 Inferential 留给真正需要语义判断的场景。
三类 Harness 目标
可维护性 Harness — 最成熟:重复代码、圈复杂度、测试覆盖率、架构漂移,Computational 工具基本都能覆盖。
架构适应性 Harness — 定义和检查架构特征:性能需求前馈 + 性能测试反馈;可观测性约定 + 日志质量检查。
行为 Harness — 最难,仍是开放问题,但正在取得突破。
传统测试框架在这里遭遇根本性失败:你无法给 LLM 的输出写 assertEquals(expected, actual)——相同问题的"正确回答"可以有无数种表达。更深的矛盾是,生成式 AI 的多样性输出不是 bug,是 feature。
突破口是用 AI 测试 AI:不是比对字符串,而是判断意图。一个 AI judge 向另一个 AI 提问:"用户的登录成功了吗?"而不是"div.login-btn 是否存在?"这个 judge 每次运行时重新分析页面 DOM 和截图,给出带推理说明的判断——而非简单的 pass/fail。
PKU 和 HKU 联合推出的 Claw-Eval 基准测试进一步工程化了评估方法:Pass³ 方法论——一个任务必须在三次独立运行中全部通过才算真正通过,彻底消除"幸运运行"的干扰。同时从三个维度评分:Completion(完成度)、Safety(安全性)、Robustness(鲁棒性)。这是在把evaluation harness 本身工程化。
交付侧的 Harness:黄金标准管道

上面讨论的六个组件主要针对 coding agent 的行为控制。但 Harness Engineering 的边界不止于代码生成——从代码到生产的整个交付管道同样需要 harness 化。
Harness 平台工程师 Aditya Kashyap 提出了一个**黄金标准管道(Golden Standard Pipeline)**的四层架构:
Layer 1:治理域(Governance Domain)
└── 策略即代码(OPA)在管道执行前作为第一道关卡
└── 原则:不合规的管道不允许启动
Layer 2:集成域(Integration Domain)——内循环
└── 代码气味、lint、安全扫描并行而非串行
└── 原则:安全扫描应该让开发提速,而不是增加摩擦
Layer 3:信任域(Trust Domain)——供应链安全
└── SBOM(软件物料清单):制品的成分表
└── SLSA 证明:构建过程的不可伪造 ID
└── 加密签名(Cosign):数字封印,任何篡改都会破坏
Layer 4:交付域(Delivery Domain)——外循环
└── 不可变制品:构建一次,部署到处
└── 滚动部署 + 审批门控
其中最重要的是 Layer 1 的哲学转变:传统管道在快要部署时才做合规检查(浪费了前面 20 分钟的构建时间),黄金标准把治理移到"第零步"——不合规的管道甚至不会开始执行。
Layer 3 对应了当前软件供应链安全的核心挑战:你需要能证明"这个制品是在哪台机器上构建的、什么时间、用了哪些输入"。当下一个 Log4j 出现时,SBOM 让你不需要扫描整个世界,只需要查询你的制品库存。
实战:Skill 分类学
不是所有任务都同样脆弱。8Lee 提出了基于脆弱性的技能分类:
高脆弱性任务(签名、部署、安全操作)
└── Hard Gates + 失败即停 + 无恢复重启
└── 示例:代码签名、公证、加密操作
中脆弱性任务(质量门控)
└── Quality Gates + 失败即回滚
└── 示例:依赖更新、staging 部署
低脆弱性任务(lint、格式化)
└── 简单 pass/fail
└── 示例:代码格式化、静态检查
在低风险任务上过度约束,浪费 token。在高风险任务上约束不足,迟早出事。
验证反压:成功静默,失败才说话
HumanLayer 认为,agent 解决问题的成功率与它验证自己工作的能力高度相关。
他们建了完整的验证链路:类型检查 + 构建、Biome 格式化 + lint、Playwright 端到端测试、代码覆盖率(低于阈值时强制补写)。
但有一个容易踩的坑:让 agent 每次修改后跑完整测试套件,4000 行的通过输出会塞满上下文窗口,agent 随之开始产生幻觉。
解决方法很简单:成功时不输出任何东西,只有失败才打印详情。
# 成功无输出,失败才打印——context window 零污染
OUTPUT=$(run_build 2>&1)
if [ $? -ne 0 ]; then
echo "$OUTPUT" >&2
exit 1
fi
这条原则在所有成功的 harness 设计里反复出现:信号噪比是 context 管理的核心。
真实案例:8Lee 的 $zip 命令
这是目前公开记录最详细的 harness engineering 案例。
一条命令 $zip 触发:
├── 12 个顺序步骤(预检、vendor 门控、版本升级、同步、验证...)
├── 65 个验证检查(13 预构建 + 44 核心 + 8 后构建)
├── 5 个编译器(Zig + Swift + Xcodebuild + Go + swiftc)
├── 签名 + 公证 + DMG 打包 + Supabase 上传
├── Vercel 部署(Next.js 下载页面 + API + SEO 元数据)
└── git commit(含 SHA-256 校验文件)+ 文档更新
耗时:约 15 分钟
发布次数:近 1000 次
失败次数:0
他的结论很直接:
"我不再担心发布的正确性了。不是因为 AI 是完美的,而是因为 harness 让「我们一起在做的事」变得安全。"
Harness 应该越来越薄
大多数讨论都在讲"加什么"。但这个洞见值得单独强调:
"Harness 的每一个组件,都编码了一条关于模型做不到什么的假设。当这个假设不再成立,组件就该走了。"
Anthropic 自己做了这件事。随着 Opus 4.5 和 4.6 发布:
-
Context Reset(上下文重置机制):删掉了。新模型的上下文管理能力已经不需要这个补偿。
-
Sprint Contract(冲刺合约,用于控制 agent 执行节奏的约束):删掉了。新模型能自己把控节奏。
每加一个 harness 组件,都是在补偿"当前模型无法独立完成某件事"。每当模型进步让某个补偿变成负担,就该拆掉它。
这同时意味着:今天一些 harness 组件的必要性,来自当前模型的"懒惰"倾向(如前文 Rodionov 的研究所揭示)。Anthropic 的情感向量研究暗示,未来可能可以在模型内部调节这个状态,而不需要外部 harness 补偿——到那时,对应的组件自然退出。
真正的竞争优势不在 harness 的厚度,而在于追踪这个迁移面的速度——知道下一步该加什么,上一步该拆什么。
johng 把这叫做 Harness Engineering 的第六支柱:可拆卸性(Detachability)——以模块化设计构建 harness,让它能随模型迭代优雅退场,而不是每次模型升级都需要大规模重构。
未来三个阶段
我们不会一夜之间拥有完全自主的 SRE 团队。这个演进以三个浪潮的方式推进。
Horizon 1:增强型运营者(当下)
Agent 是工程师的"副驾"。你问"这个 Pod 为什么崩溃了",agent 查日志、关联 MemoryLimitExceeded 错误和最近的配置变更,提出修复建议。人类创建意图并批准行动。
Harness 重点:AGENTS.md + Hooks + 可观测性集成。
Horizon 2:Agent 群体与任务自主(1-2 年)
单个专业化 agent 开始在特定范围内自主处理重复任务。一个"安全 agent"发现 CVE,创建 ticket 并传给"开发 agent",后者建分支、升版本、传给"QA agent"跑测试。人类只在最后点击"合并"。
从 Human-in-the-Loop 转变为 Human-on-the-Loop——你审查输出,但不驾驶过程。
Harness 重点:多 agent 编排 + Judge 模式 + 严格权限隔离(Diagnosis Agent 只有读权限,Remediation Agent 只有目标命名空间的写权限)。
Horizon 3:自主 SRE(3-5 年)
凌晨 2 点生产延迟飙升,"SRE Agent"检测到异常、识别噪音邻居、驱逐节点、验证稳定性、向 Slack 发送事后分析。只有 agent 无法解决时才呼叫人类。
标准操作的 Human-out-of-the-Loop。人类管理策略和目标,不管任务。
Harness 重点:Constitutional AI(Policy-as-Code 通过 OPA 作为所有工具调用的第一道关卡)+ 防篡改审计日志(记录每个推理步骤和每条 CLI 命令)。
每个阶段的关键认知转变:我们不再管理服务器,我们在管理认知架构(Cognitive Architectures)。
开放的硬问题
Harness Engineering 作为一个工程学科仍然年轻。几个核心问题目前没有答案:
代码质量的慢性退化:agent 生成的代码不以人类的方式腐化——不是有 bug,而是"功能正确但逐渐不可维护"。OpenAI 在跑周期性的"垃圾清理 agent",Anthropic 在跑"Doc-gardening agent"(扫描代码和文档的脱节并发起 PR),但这些实践仍很早期。
用 AI 验证 AI 的可靠性:主要靠 AI 生成的测试来验证 AI 生成的代码,这个闭环的可信度是多少?目前没有答案。
老旧代码库的改造:几乎所有成功案例要么从零开始,要么团队在全新项目里构建 harness。把这些方法应用到有十年历史、测试参差不齐、文档残缺的存量代码库,难度是另一个量级。Böckeler 打了个比方:这就像在从未跑过静态分析的代码库上第一次跑——你会溺死在警报里。
Harness 自身的一致性:随着 harness 增长,前馈规则和反馈信号可能开始互相矛盾。当它们指向不同方向时,agent 如何做出合理权衡?如何衡量 harness 的"覆盖率",就像测试覆盖率一样评估它的完整性?目前没有工具可以回答。
概率性系统的信任问题:脚本是确定性的,同样输入永远得到同样输出。Agent 是概率性的,可能根据上下文选择不同路径。让概率性系统可信赖,答案不是消除不确定性,而是确保全程可追溯——只有能被看见的,才能被信任。
从今天开始做什么
第一周:建立基础
-
为你最常用的项目创建 AGENTS.md(或 CLAUDE.md)
- 从当前最烦的 5-10 个 agent 失败行为开始
- 每个写一条规则,一句话,不加解释
- 总长度控制在 50-100 行
-
让 agent 能操作你的项目
- 所有日常工作流写成 Makefile target(
make dev、make test、make restart)
- agent 应该能自己启动项目、看日志、跑测试
-
建立最小反馈回路
- linter + 类型检查 + 单元测试,必须能本地快速跑完
- 失败时才输出,成功时静默
第二到四周:工程化失败
-
识别前 5 个最危险的失败模式,把它们变成 hook 拦截脚本
-
如果你有跨多个 session 的长任务,建立 Initializer + Coding Agent 双 agent 模式
- 用 JSON 跟踪功能状态,不用 Markdown
- 每次 session 开始强制读进度文件和 git log
- 每次只完成一个功能,完成即 commit
-
第一个技能(Skill)——选一个每周都要做的、有多个步骤的任务
持续运转:把每一次失败变成系统
每次 agent 犯错,问自己:
- 这是 AGENTS.md 可以防止的?→ 加一条规则
- 这是 hook 可以物理阻止的?→ 写一个拦截脚本
- 这是 linter 可以检测的?→ 写一条 lint 规则
- 这是 sub-agent 可以隔离的 context 问题?→ 拆分架构
- 这是模型已经能自己处理的?→ 删掉这个 harness 组件
唯一的原则:只在 agent 真的出错后才加约束,只在模型真的不再需要时才删约束。
结语:一门关于信任的工程学
构建自动化的历史,一直在回答同一个问题:如何让复杂的多步骤过程变得可靠和可重复?
1976:make → 依赖图 + 文件时间戳
1990s:autotools → 跨平台构建
2000s:CI/CD → 远程机器运行构建
2010s:IaC → 可复现的基础设施
2020s:GitOps → 声明式期望状态
2026+:Harness → Agent 读取操作手册并执行,harness 管理和约束它
每一代解决了上一代的核心问题,同时引入了新的复杂性。这一代的问题是:如何让 AI 可靠地执行。
Böckeler 有一段话值得收在这里:
"人类开发者把技能和经验作为一种隐性 harness 带入每个代码库。我们吸收了约定和最佳实践,我们感受过复杂性带来的认知痛苦,我们知道自己的名字会出现在 commit 里。Harness 是把这些东西外显化、明确化的尝试。但它只能走到某一步。"
Harness Engineering 不是要让人类工程师消失。是要让工程师的经验、品味和判断力,以工程化的方式传递给 AI,让 agent 在你的价值观里工作。
能把自己的工程判断力编写成 harness 的人,就是这个新学科的核心建设者。
参考来源
英文一手资料
中文解析与实践
综合整理自 30+ 篇一手资料与开源项目 | 2026-04-13