ESTree 是一套用于描述 ECMAScript(JavaScript)代码抽象语法树(AST)的标准化规范。ESTree 规范并非一成不变,而是跟随 ECMAScript 官方版本迭代,分为多个阶段的规范:
- ES5 规范:最早的 ESTree 规范,仅支持 ES5 语法(如 var、普通函数、
if/for 等)。
- ES6+ 规范:新增 ES6 及后续版本的语法节点(如
ArrowFunctionExpression 箭头函数、ClassDeclaration 类、ImportDeclaration 模块导入等)。
- ESNext 规范:支持尚未正式纳入 ECMAScript 标准的实验性语法(如装饰器、管道运算符等),供工具提前适配。
语法节点类型
根节点唯一 (Program)
{
"type": "Program", // 节点类型,`Program` 表示整个程序。
"start": 0, // 在源码中的开始索引
"end": 9, // 在源码中的结束索引,这里原代码长度为 9,即共 9 个字符
"body": [ ... ], // 程序体,是一个语句数组
"sourceType": "script" // "script" 表示源码是普通脚本(非模块),如果是 `"module"`,则支持 `import`/`export`
}
声明节点
- VariableDeclaration 变量声明(统一包裹const/let/var)
- FunctionDeclaration 函数声明(具名函数,提升)
- ClassDeclaration 类声明(具名类,提升)
- ImportDeclaration 模块导入声明(仅模块环境)
- ExportDeclaration 模块导出声明(仅模块环境,含命名 / 默认)
- ExportNamedDeclaration命名导出
- ExportDefaultDeclaration默认导出
- ExportAllDeclaration全部导出
语句节点
- BlockStatement 块语句({}包裹的代码块)
- ExpressionStatement 表达式语句(包裹单个表达式作为语句执行)
- IfStatement 条件判断语句
- ForStatement for 循环语句
- WhileStatement while 循环语句
- ReturnStatement 返回语句(函数内)
- TryStatement 异常捕获语句
- BreakStatement 中断循环语句
- ContinueStatement 继续循环语句
表达式节点
- Identifier标识符(变量名、函数名、属性名等
- Literal字面量(直接写死的值)
- BinaryExpression 二元表达式(双操作数运算)
- UnaryExpression 一元表达式(单操作数运算)
- AssignmentExpression 赋值表达式
- CallExpression 函数调用表达式
- MemberExpression 成员访问表达式
- ArrowFunctionExpression 箭头函数表达式
- ObjectExpression 对象字面量表达式
- ArrayExpression 数组字面量表达式
其他节点
- TryStatementtry...catch 语句
- TemplateLiteral模板字符串
- TaggedTemplateExpression带标签的模板字符串
- SpreadElement扩展运算符
- RestElement剩余参数
Acorn
Acorn 是一个轻量、快速的 JavaScript 解析器,能将代码转换为 ESTree 标准的抽象语法树(AST)。
它主要提供三大核心 API
-
parse(input, options) :解析一段完整的 JavaScript 程序。成功返回 ESTree AST,失败抛出包含位置信息的 SyntaxError 对象
-
parseExpressionAt(input, pos, options) :解析一个独立的 JavaScript 表达式。适用于解析模板字符串内的内嵌表达式等混合内容
-
tokenizer(input, options) :返回一个迭代器,逐个生成代码的 Token。可用于自定义的语法高亮或极简解析器。
parseExpressionAt
const code = 'const x = 10; const y = 20; x + y * 2;'
const result = acorn.parseExpressionAt(code, code.indexOf('x + y'),{
ecmaVersion: 2020,
sourceType: 'module',
});
console.log(result);

tokenizer
示例
const result = acorn.tokenizer('let a = "hello";',{
ecmaVersion: 2020,
sourceType: 'module',
});
console.log(result);
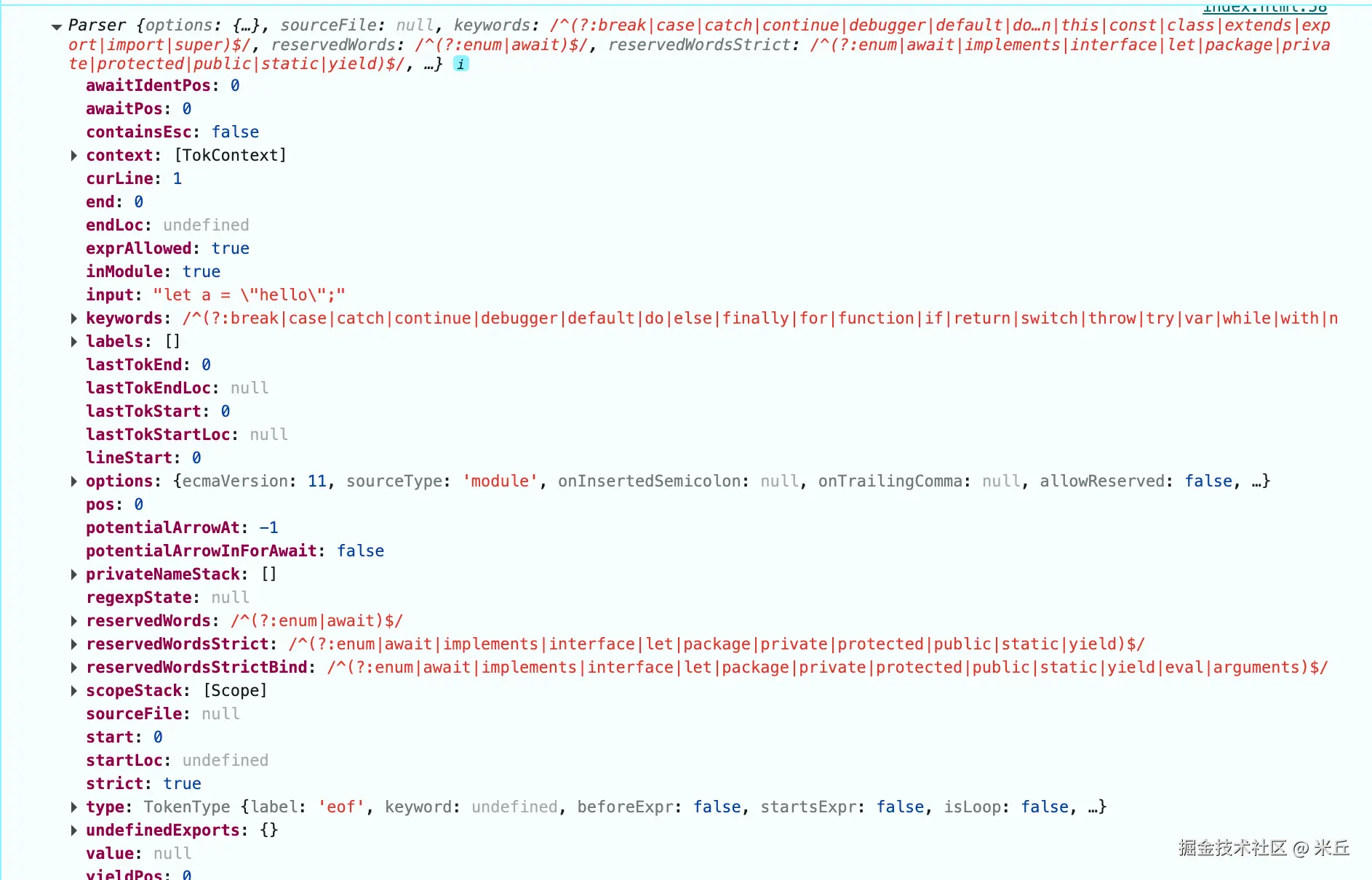
关键字(可用于代码高亮)
^(?:break|case|catch|continue|debugger|default|do|else|finally|for|function|if|return|switch|throw|try|var|while|with|null|true|false|instanceof|typeof|void|delete|new|in|this|const|class|extends|export|import|super)$
示例
const result = acorn.tokenizer('let a = "hello";',{
ecmaVersion: 2020,
sourceType: 'module',
});
console.log(result);
for(let token of result){
console.log('token',token);
}

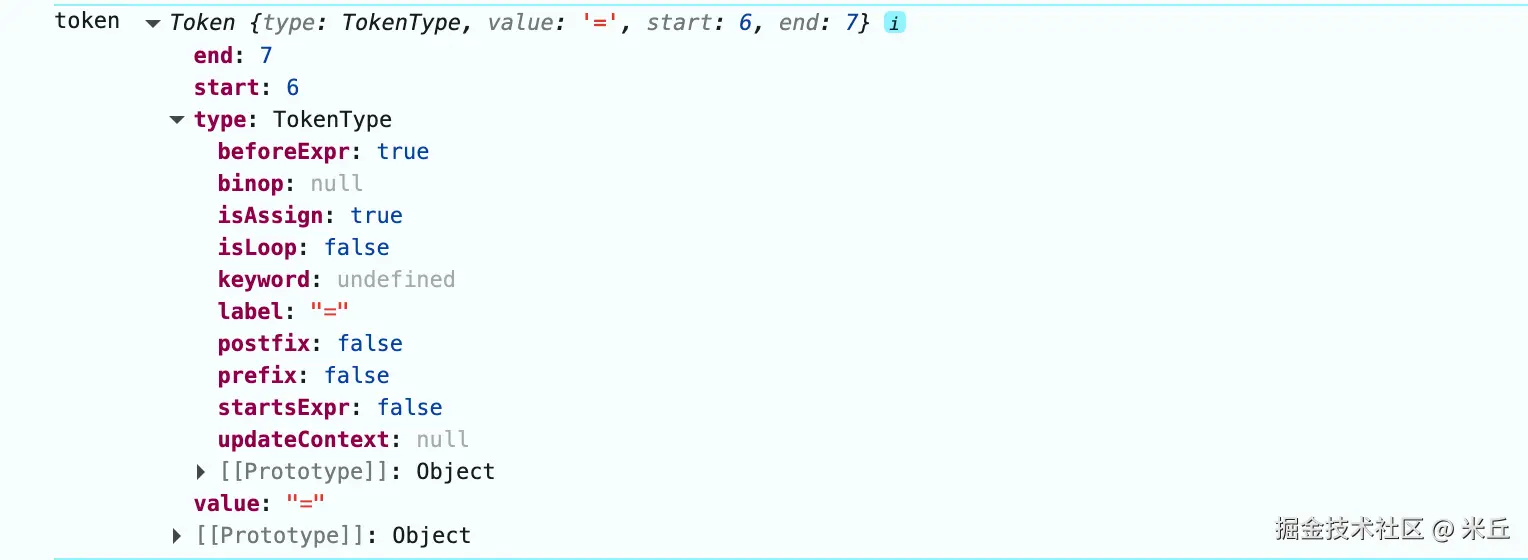
每个 Token 对象都会包含一个 type 属性,指向这样的类型描述对象。
{
"label": "string", // Token 类型的人类可读名称
"beforeExpr": false, // 该 Token 类型是否可以在表达式之前出现
"startsExpr": true, // 该 Token 类型是否作为表达式的开始
"isLoop": false, // 是否为循环关键字(如 for, while, do)
"isAssign": false, // 是否为赋值操作符(如 =, +=, -=)
"prefix": false, // 是否为前缀操作符(如 ++, --, !, ~)
"postfix": false, // 是否为后缀操作符(如 ++, --)
"binop": null,// 如果是二元操作符,这里会有一个优先级数值;否则为 null
"updateContext": null // 可选函数,用于在解析时更新上下文(通常为 null)
}
声明变量
例1 声明一个变量(基本类型)
const ast = acorn.parse(`let a = 1`, {
ecmaVersion: 2020,
});
console.log(JSON.stringify(ast, null, 2));
{
"type": "Program",
"start": 0,
"end": 9,
"body": [
{
"type": "VariableDeclaration", // 变量声明符
"start": 0,
"end": 9,
"declarations": [
{
"type": "VariableDeclarator",
"start": 4,
"end": 9,
// 标识符节点,即变量名。
"id": {
"type": "Identifier", // 变量名标识符
"start": 4,
"end": 5,
"name": "a" // 变量名
},
// 初始化表达式节点,即等号右边的值
"init": {
"type": "Literal", // 字面量
"start": 8,
"end": 9,
"value": 1, // 运行时的值,这里是数字 1
"raw": "1" // 源码中的原始字符串表示 "1"
}
}
],
"kind": "let" // 表示使用 let 关键字声明
}
],
"sourceType": "script"
}
例2 声明一个变量(数组)
const ast = acorn.parse(`const arr = [1,2]`, {
ecmaVersion: 2020,
});
console.log(JSON.stringify(ast, null, 2));
{
"type": "Program",
"start": 0,
"end": 17,
"body": [
{
"type": "VariableDeclaration",
"start": 0,
"end": 17,
"declarations": [
{
"type": "VariableDeclarator",
"start": 6,
"end": 17,
"id": {
"type": "Identifier",
"start": 6,
"end": 9,
"name": "arr"
},
"init": {
"type": "ArrayExpression",
"start": 12,
"end": 17,
"elements": [
{
"type": "Literal",
"start": 13,
"end": 14,
"value": 1,
"raw": "1"
},
{
"type": "Literal",
"start": 15,
"end": 16,
"value": 2,
"raw": "2"
}
]
}
}
],
"kind": "const"
}
],
"sourceType": "script"
}
例3 声明一个变量(对象)
const ast = acorn.parse(`const arr = {a: 1, b: 2}`, {
ecmaVersion: 2020,
});
console.log(JSON.stringify(ast, null, 2));
{
"type": "Program",
"start": 0,
"end": 24,
"body": [
{
"type": "VariableDeclaration",
"start": 0,
"end": 24,
"declarations": [
{
"type": "VariableDeclarator",
"start": 6,
"end": 24,
"id": {
"type": "Identifier",
"start": 6,
"end": 9,
"name": "arr"
},
"init": {
"type": "ObjectExpression",
"start": 12,
"end": 24,
"properties": [
{
"type": "Property",
"start": 13,
"end": 17,
"method": false,
"shorthand": false,
"computed": false,
"key": {
"type": "Identifier",
"start": 13,
"end": 14,
"name": "a"
},
"value": {
"type": "Literal",
"start": 16,
"end": 17,
"value": 1,
"raw": "1"
},
"kind": "init"
},
{
"type": "Property",
"start": 19,
"end": 23,
"method": false,
"shorthand": false,
"computed": false,
"key": {
"type": "Identifier",
"start": 19,
"end": 20,
"name": "b"
},
"value": {
"type": "Literal",
"start": 22,
"end": 23,
"value": 2,
"raw": "2"
},
"kind": "init"
}
]
}
}
],
"kind": "const"
}
],
"sourceType": "script"
}
例4 三元表达式
const ast = acorn.parse(`const flag = a > b ? true : false`, {
ecmaVersion: 2020,
});
console.log(JSON.stringify(ast, null, 2));
{
"type": "Program",
"start": 0,
"end": 33,
"body": [
{
"type": "VariableDeclaration",
"start": 0,
"end": 33,
"declarations": [
{
"type": "VariableDeclarator",
"start": 6,
"end": 33,
"id": {
"type": "Identifier",
"start": 6,
"end": 10,
"name": "flag"
},
"init": {
"type": "ConditionalExpression",
"start": 13,
"end": 33,
"test": {
"type": "BinaryExpression",
"start": 13,
"end": 18,
"left": {
"type": "Identifier",
"start": 13,
"end": 14,
"name": "a"
},
"operator": ">",
"right": {
"type": "Identifier",
"start": 17,
"end": 18,
"name": "b"
}
},
"consequent": {
"type": "Literal",
"start": 21,
"end": 25,
"value": true,
"raw": "true"
},
"alternate": {
"type": "Literal",
"start": 28,
"end": 33,
"value": false,
"raw": "false"
}
}
}
],
"kind": "const"
}
],
"sourceType": "script"
}
例5 声明变量(逻辑运算符)
const code = 'let name = jon || "hello";'
const result = acorn.parse(code, {
ecmaVersion: 2020,
});
console.log(JSON.stringify(result, null, 2));
{
"type": "Program",
"start": 0,
"end": 26,
"body": [
{
"type": "VariableDeclaration",
"start": 0,
"end": 26,
"declarations": [
{
"type": "VariableDeclarator",
"start": 4,
"end": 25,
// 声明标识
"id": {
"type": "Identifier",
"start": 4,
"end": 8,
"name": "name"
},
// 声明初始化内容
"init": {
"type": "LogicalExpression",// 逻辑表达式
"start": 11,
"end": 25,
"left": {
"type": "Identifier",
"start": 11,
"end": 14,
"name": "jon"
},
"operator": "||",// 操作符
"right": {
"type": "Literal",
"start": 18,
"end": 25,
"value": "hello",
"raw": "\"hello\""
}
}
}
],
"kind": "let"
}
],
"sourceType": "script"
}
函数
例1 箭头函数
const ast = acorn.parse(`const getFlag = (a, b) => a + b`, {
ecmaVersion: 2020,
});
console.log(JSON.stringify(ast, null, 2));
{
"type": "Program",
"start": 0,
"end": 31,
"body": [
{
"type": "VariableDeclaration",
"start": 0,
"end": 31,
"declarations": [
{
"type": "VariableDeclarator",
"start": 6,
"end": 31,
"id": {
"type": "Identifier",
"start": 6,
"end": 13,
"name": "getFlag"
},
"init": {
"type": "ArrowFunctionExpression",
"start": 16,
"end": 31,
"id": null,
"expression": true,
"generator": false,
"async": false,
"params": [
{
"type": "Identifier",
"start": 17,
"end": 18,
"name": "a"
},
{
"type": "Identifier",
"start": 20,
"end": 21,
"name": "b"
}
],
"body": {
"type": "BinaryExpression",
"start": 26,
"end": 31,
"left": {
"type": "Identifier",
"start": 26,
"end": 27,
"name": "a"
},
"operator": "+",
"right": {
"type": "Identifier",
"start": 30,
"end": 31,
"name": "b"
}
}
}
}
],
"kind": "const"
}
],
"sourceType": "script"
}
例2 普通函数 含有返回值
const ast = acorn.parse(`function getFlag(a, b) { return a + b } `, {
ecmaVersion: 2020,
});
console.log(JSON.stringify(ast, null, 2));
{
"type": "Program",
"start": 0,
"end": 41,
"body": [
{
"type": "FunctionDeclaration",
"start": 0,
"end": 39,
"id": {
"type": "Identifier",
"start": 9,
"end": 16,
"name": "getFlag"
},
"expression": false,
"generator": false,
"async": false,
"params": [
{
"type": "Identifier",
"start": 17,
"end": 18,
"name": "a"
},
{
"type": "Identifier",
"start": 20,
"end": 21,
"name": "b"
}
],
"body": {
"type": "BlockStatement",
"start": 23,
"end": 39,
"body": [
{
"type": "ReturnStatement",
"start": 25,
"end": 37,
"argument": {
"type": "BinaryExpression",
"start": 32,
"end": 37,
"left": {
"type": "Identifier",
"start": 32,
"end": 33,
"name": "a"
},
"operator": "+",
"right": {
"type": "Identifier",
"start": 36,
"end": 37,
"name": "b"
}
}
}
]
}
}
],
"sourceType": "script"
}
例3 函数调用
const ast = acorn.parse(`function getFlag(a, b) { return a + b } getFlag(1, 2)`, {
ecmaVersion: 2020,
});
console.log(JSON.stringify(ast, null, 2));
{
"type": "Program",
"start": 0,
"end": 53,
"body": [
{
"type": "FunctionDeclaration",
"start": 0,
"end": 39,
"id": {
"type": "Identifier",
"start": 9,
"end": 16,
"name": "getFlag"
},
"expression": false,
"generator": false,
"async": false,
"params": [
{
"type": "Identifier",
"start": 17,
"end": 18,
"name": "a"
},
{
"type": "Identifier",
"start": 20,
"end": 21,
"name": "b"
}
],
"body": {
"type": "BlockStatement",
"start": 23,
"end": 39,
"body": [
{
"type": "ReturnStatement",
"start": 25,
"end": 37,
"argument": {
"type": "BinaryExpression",
"start": 32,
"end": 37,
"left": {
"type": "Identifier",
"start": 32,
"end": 33,
"name": "a"
},
"operator": "+",
"right": {
"type": "Identifier",
"start": 36,
"end": 37,
"name": "b"
}
}
}
]
}
},
{
"type": "ExpressionStatement",
"start": 40,
"end": 53,
"expression": {
"type": "CallExpression",
"start": 40,
"end": 53,
"callee": {
"type": "Identifier",
"start": 40,
"end": 47,
"name": "getFlag"
},
"arguments": [
{
"type": "Literal",
"start": 48,
"end": 49,
"value": 1,
"raw": "1"
},
{
"type": "Literal",
"start": 51,
"end": 52,
"value": 2,
"raw": "2"
}
],
"optional": false
}
}
],
"sourceType": "script"
}
例4 条件语句
const ast = acorn.parse(`function getFlag(a, b) { if(a > b) { return true } } getFlag(1, 2)`, {
ecmaVersion: 2020,
});
console.log(JSON.stringify(ast, null, 2));
{
"type": "Program",
"start": 0,
"end": 66,
"body": [
{
"type": "FunctionDeclaration",
"start": 0,
"end": 52,
"id": {
"type": "Identifier",
"start": 9,
"end": 16,
"name": "getFlag"
},
"expression": false,
"generator": false,
"async": false,
"params": [
{
"type": "Identifier",
"start": 17,
"end": 18,
"name": "a"
},
{
"type": "Identifier",
"start": 20,
"end": 21,
"name": "b"
}
],
"body": {
"type": "BlockStatement",
"start": 23,
"end": 52,
"body": [
{
"type": "IfStatement",
"start": 25,
"end": 50,
"test": {
"type": "BinaryExpression",
"start": 28,
"end": 33,
"left": {
"type": "Identifier",
"start": 28,
"end": 29,
"name": "a"
},
"operator": ">",
"right": {
"type": "Identifier",
"start": 32,
"end": 33,
"name": "b"
}
},
"consequent": {
"type": "BlockStatement",
"start": 35,
"end": 50,
"body": [
{
"type": "ReturnStatement",
"start": 37,
"end": 48,
"argument": {
"type": "Literal",
"start": 44,
"end": 48,
"value": true,
"raw": "true"
}
}
]
},
"alternate": null
}
]
}
},
{
"type": "ExpressionStatement",
"start": 53,
"end": 66,
"expression": {
"type": "CallExpression",
"start": 53,
"end": 66,
"callee": {
"type": "Identifier",
"start": 53,
"end": 60,
"name": "getFlag"
},
"arguments": [
{
"type": "Literal",
"start": 61,
"end": 62,
"value": 1,
"raw": "1"
},
{
"type": "Literal",
"start": 64,
"end": 65,
"value": 2,
"raw": "2"
}
],
"optional": false
}
}
],
"sourceType": "script"
}
类
声明一个空类
{
"type": "Program",
"start": 0,
"end": 11,
"body": [
{
"type": "ClassDeclaration", // 类声明
"start": 0,
"end": 11,
// 类名,是一个 Identifier 节点
"id": {
"type": "Identifier",
"start": 6,
"end": 9,
"name": "Cat"
},
// 父类 ,如果有 extends 关键字,这里会是表达式节点
"superClass": null,
// 包含类的所有成员(方法、属性等)
"body": {
"type": "ClassBody",
"start": 9,
"end": 11,
"body": []
}
}
],
"sourceType": "module"
}
带构造函数的类
{
"type": "Program",
"start": 0,
"end": 50,
"body": [
{
"type": "ClassDeclaration",
"start": 0,
"end": 50,
"id": {
"type": "Identifier",
"start": 6,
"end": 9,
"name": "Cat"
},
"superClass": null,
"body": {
"type": "ClassBody",
"start": 9,
"end": 50,
"body": [
{
"type": "MethodDefinition",
"start": 11,
"end": 49,
"static": false,
"computed": false,
"key": {
"type": "Identifier",
"start": 11,
"end": 22,
"name": "constructor"
},
"kind": "constructor",
"value": {
"type": "FunctionExpression",
"start": 22,
"end": 49,
"id": null,
"expression": false,
"generator": false,
"async": false,
"params": [
{
"type": "Identifier",
"start": 23,
"end": 27,
"name": "name"
}
],
"body": {
"type": "BlockStatement",
"start": 28,
"end": 49,
"body": [
{
"type": "ExpressionStatement",
"start": 30,
"end": 47,
"expression": {
"type": "AssignmentExpression",
"start": 30,
"end": 46,
"operator": "=",
"left": {
"type": "MemberExpression",
"start": 30,
"end": 39,
"object": {
"type": "ThisExpression",
"start": 30,
"end": 34
},
"property": {
"type": "Identifier",
"start": 35,
"end": 39,
"name": "name"
},
"computed": false,
"optional": false
},
"right": {
"type": "Identifier",
"start": 42,
"end": 46,
"name": "name"
}
}
}
]
}
}
}
]
}
}
],
"sourceType": "module"
}
截取片段this.name = name
{
"body": [
{
"type": "ExpressionStatement", // 表达式语句
"start": 30,
"end": 47,
// 真正的表达式
"expression": {
"type": "AssignmentExpression", // 赋值表达式
"start": 30,
"end": 46,
"operator": "=",
"left": {
"type": "MemberExpression", // 属性访问表达式
"start": 30,
"end": 39,
// 被访问的对象
"object": {
"type": "ThisExpression", // this
"start": 30,
"end": 34
},
// 属性
"property": {
"type": "Identifier",
"start": 35,
"end": 39,
"name": "name"
},
// 表示使用点号 . 访问属性(而非 [计算属性名])
"computed": false,
// 可选链操作符 ?.
"optional": false
},
"right": {
"type": "Identifier",
"start": 42,
"end": 46,
"name": "name"
}
}
}
]
}
继承
const code = 'class Cat extends Animal { constructor(name){ super(name); }}'
const result = acorn.parse(code, {
ecmaVersion: 2020,
sourceType: 'module',
});
console.log(JSON.stringify(result, null, 2));
{
"type": "Program",
"start": 0,
"end": 61,
"body": [
{
"type": "ClassDeclaration",
"start": 0,
"end": 61,
"id": {
"type": "Identifier",
"start": 6,
"end": 9,
"name": "Cat"
},
"superClass": {
"type": "Identifier",
"start": 18,
"end": 24,
"name": "Animal"
},
"body": {
"type": "ClassBody",
"start": 25,
"end": 61,
"body": [
{
"type": "MethodDefinition",
"start": 27,
"end": 60,
"static": false,
"computed": false,
"key": {
"type": "Identifier",
"start": 27,
"end": 38,
"name": "constructor"
},
"kind": "constructor",
"value": {
"type": "FunctionExpression",
"start": 38,
"end": 60,
"id": null,
"expression": false,
"generator": false,
"async": false,
"params": [
{
"type": "Identifier",
"start": 39,
"end": 43,
"name": "name"
}
],
"body": {
"type": "BlockStatement",
"start": 44,
"end": 60,
"body": [
{
"type": "ExpressionStatement",
"start": 46,
"end": 58,
"expression": {
"type": "CallExpression",
"start": 46,
"end": 57,
"callee": {
"type": "Super",
"start": 46,
"end": 51
},
"arguments": [
{
"type": "Identifier",
"start": 52,
"end": 56,
"name": "name"
}
],
"optional": false
}
}
]
}
}
}
]
}
}
],
"sourceType": "module"
}
截取片段分析 super(name)
{
"type": "ExpressionStatement",
"start": 46,
"end": 58,
"expression": {
"type": "CallExpression",//调用表达式
"start": 46,
"end": 57,
// 被调用的函数或方法
"callee": {
"type": "Super", // super关键字
"start": 46,
"end": 51
},
// 参数列表
"arguments": [
{
"type": "Identifier",
"start": 52,
"end": 56,
"name": "name"
}
],
"optional": false
}
}
模块
命名导入
const ast = acorn.parse(`import { add } from './utills.js'`, {
ecmaVersion: 2020,
sourceType: "module",
});
console.log(JSON.stringify(ast, null, 2));
{
"type": "Program",
"start": 0,
"end": 33,
"body": [
{
"type": "ImportDeclaration", // 导入声明
"start": 0,
"end": 33,
"specifiers": [
{
"type": "ImportSpecifier", // 导入语句
"start": 9,
"end": 12,
// 模块导入的名称
"imported": {
"type": "Identifier",
"start": 9,
"end": 12,
"name": "add"
},
// 本地使用的名称
"local": {
"type": "Identifier",
"start": 9,
"end": 12,
"name": "add"
}
}
],
// 源
"source": {
"type": "Literal",
"start": 20,
"end": 33,
"value": "./utills.js", // 运行中
"raw": "'./utills.js'" // 代码中保留了引号
}
}
],
"sourceType": "module"
}
命名导入
const ast = acorn.parse(`import { add } from './utills.js';const result = add(1, 2);`, {
ecmaVersion: 2020,
sourceType: "module",
});
console.log(JSON.stringify(ast, null, 2));
{
"type": "Program",
"start": 0,
"end": 59,
"body": [
{
"type": "ImportDeclaration",
"start": 0,
"end": 34,
"specifiers": [
{
"type": "ImportSpecifier",
"start": 9,
"end": 12,
"imported": {
"type": "Identifier",
"start": 9,
"end": 12,
"name": "add"
},
"local": {
"type": "Identifier",
"start": 9,
"end": 12,
"name": "add"
}
}
],
"source": {
"type": "Literal",
"start": 20,
"end": 33,
"value": "./utills.js",
"raw": "'./utills.js'"
}
},
{
"type": "VariableDeclaration",
"start": 34,
"end": 59,
"declarations": [
{
"type": "VariableDeclarator",
"start": 40,
"end": 58,
"id": {
"type": "Identifier",
"start": 40,
"end": 46,
"name": "result"
},
"init": {
"type": "CallExpression",
"start": 49,
"end": 58,
"callee": {
"type": "Identifier",
"start": 49,
"end": 52,
"name": "add"
},
"arguments": [
{
"type": "Literal",
"start": 53,
"end": 54,
"value": 1,
"raw": "1"
},
{
"type": "Literal",
"start": 56,
"end": 57,
"value": 2,
"raw": "2"
}
],
"optional": false
}
}
],
"kind": "const"
}
],
"sourceType": "module"
}
别名导入
const ast = acorn.parse(`import { add as addFun} from './utills.js'`, {
ecmaVersion: 2020,
sourceType: "module",
});
console.log(JSON.stringify(ast, null, 2));
{
"type": "Program",
"start": 0,
"end": 42,
"body": [
{
"type": "ImportDeclaration",
"start": 0,
"end": 42,
"specifiers": [
{
"type": "ImportSpecifier",
"start": 9,
"end": 22,
"imported": {
"type": "Identifier",
"start": 9,
"end": 12,
"name": "add"
},
"local": {
"type": "Identifier",
"start": 16,
"end": 22,
"name": "addFun"
}
}
],
"source": {
"type": "Literal",
"start": 29,
"end": 42,
"value": "./utills.js",
"raw": "'./utills.js'"
}
}
],
"sourceType": "module"
}
命名导出一个 变量声明
const ast = acorn.parse(`export const Max_Size = 100;`, {
ecmaVersion: 2020,
sourceType: "module",
});
console.log(JSON.stringify(ast, null, 2));
{
"type": "Program",
"start": 0,
"end": 28,
"body": [
{
"type": "ExportNamedDeclaration", // 表示一个命名导出
"start": 0,
"end": 28,
// 被导出的声明节点
"declaration": {
"type": "VariableDeclaration",
"start": 7,
"end": 28,
"declarations": [
{
"type": "VariableDeclarator",
"start": 13,
"end": 27,
"id": {
"type": "Identifier",
"start": 13,
"end": 21,
"name": "Max_Size"
},
"init": {
"type": "Literal",
"start": 24,
"end": 27,
"value": 100,
"raw": "100"
}
}
],
"kind": "const"
},
"specifiers": [],
"source": null // 从其他模块重导出
}
],
"sourceType": "module"
}
命名导出一个 函数声明
const ast = acorn.parse(`export function add(a, b) {return a + b;}`, {
ecmaVersion: 2020,
sourceType: "module",
});
console.log(JSON.stringify(ast, null, 2));
{
"type": "Program",
"start": 0,
"end": 41,
"body": [
{
"type": "ExportNamedDeclaration",
"start": 0,
"end": 41,
"declaration": {
"type": "FunctionDeclaration",
"start": 7,
"end": 41,
"id": {
"type": "Identifier",
"start": 16,
"end": 19,
"name": "add"
},
"expression": false,
"generator": false,
"async": false,
"params": [
{
"type": "Identifier",
"start": 20,
"end": 21,
"name": "a"
},
{
"type": "Identifier",
"start": 23,
"end": 24,
"name": "b"
}
],
"body": {
"type": "BlockStatement",
"start": 26,
"end": 41,
"body": [
{
"type": "ReturnStatement",
"start": 27,
"end": 40,
"argument": {
"type": "BinaryExpression",
"start": 34,
"end": 39,
"left": {
"type": "Identifier",
"start": 34,
"end": 35,
"name": "a"
},
"operator": "+",
"right": {
"type": "Identifier",
"start": 38,
"end": 39,
"name": "b"
}
}
}
]
}
},
"specifiers": [],
"source": null
}
],
"sourceType": "module"
}
命名导出一个变量
const ast = acorn.parse(`const Max_Size = 100;export { Max_Size };`, {
ecmaVersion: 2020,
sourceType: "module",
});
console.log(JSON.stringify(ast, null, 2));
export { Max_Size };这是一个命名导出语句,但它不包含声明(declaration: null),而是通过 specifiers 列表来指定要导出的已有变量。
{
"type": "Program",
"start": 0,
"end": 41,
"body": [
{
"type": "VariableDeclaration",
"start": 0,
"end": 21,
"declarations": [
{
"type": "VariableDeclarator",
"start": 6,
"end": 20,
"id": {
"type": "Identifier",
"start": 6,
"end": 14,
"name": "Max_Size"
},
"init": {
"type": "Literal",
"start": 17,
"end": 20,
"value": 100,
"raw": "100"
}
}
],
"kind": "const"
},
{
"type": "ExportNamedDeclaration",
"start": 21,
"end": 41,
"declaration": null, // 没有内联声明
// 导出说明符列表
"specifiers": [
{
"type": "ExportSpecifier",
"start": 30,
"end": 38,
// 当前模块本地名称
"local": {
"type": "Identifier",
"start": 30,
"end": 38,
"name": "Max_Size"
},
// 导出后名称
"exported": {
"type": "Identifier",
"start": 30,
"end": 38,
"name": "Max_Size"
}
}
],
"source": null // 不是从其他模块中导出
}
],
"sourceType": "module"
}
命名导出一个函数
const ast = acorn.parse(`function add(a, b) {return a + b;} export { add };`, {
ecmaVersion: 2020,
sourceType: "module",
});
console.log(JSON.stringify(ast, null, 2));
{
"type": "Program",
"start": 0,
"end": 50,
"body": [
{
"type": "FunctionDeclaration",
"start": 0,
"end": 34,
"id": {
"type": "Identifier",
"start": 9,
"end": 12,
"name": "add"
},
"expression": false,
"generator": false,
"async": false,
"params": [
{
"type": "Identifier",
"start": 13,
"end": 14,
"name": "a"
},
{
"type": "Identifier",
"start": 16,
"end": 17,
"name": "b"
}
],
"body": {
"type": "BlockStatement",
"start": 19,
"end": 34,
"body": [
{
"type": "ReturnStatement",
"start": 20,
"end": 33,
"argument": {
"type": "BinaryExpression",
"start": 27,
"end": 32,
"left": {
"type": "Identifier",
"start": 27,
"end": 28,
"name": "a"
},
"operator": "+",
"right": {
"type": "Identifier",
"start": 31,
"end": 32,
"name": "b"
}
}
}
]
}
},
{
"type": "ExportNamedDeclaration",
"start": 35,
"end": 50,
"declaration": null,
"specifiers": [
{
"type": "ExportSpecifier",
"start": 44,
"end": 47,
"local": {
"type": "Identifier",
"start": 44,
"end": 47,
"name": "add"
},
"exported": {
"type": "Identifier",
"start": 44,
"end": 47,
"name": "add"
}
}
],
"source": null
}
],
"sourceType": "module"
}
默认导出字面量
const ast = acorn.parse(`export default 12;`, {
ecmaVersion: 2020,
sourceType: "module",
});
console.log(JSON.stringify(ast, null, 2));
{
"type": "Program",
"start": 0,
"end": 18,
"body": [
{
"type": "ExportDefaultDeclaration",
"start": 0,
"end": 18,
"declaration": {
"type": "Literal",
"start": 15,
"end": 17,
"value": 12,
"raw": "12"
}
}
],
"sourceType": "module"
}
默认导出 变量(基本类型)
const ast = acorn.parse(`var Max_Size = 100;export default Max_Size ;`, {
ecmaVersion: 2020,
sourceType: "module",
});
console.log(JSON.stringify(ast, null, 2));
{
"type": "Program",
"start": 0,
"end": 45,
"body": [
{
"type": "VariableDeclaration",
"start": 0,
"end": 19,
"declarations": [
{
"type": "VariableDeclarator",
"start": 4,
"end": 18,
"id": {
"type": "Identifier",
"start": 4,
"end": 12,
"name": "Max_Size"
},
"init": {
"type": "Literal",
"start": 15,
"end": 18,
"value": 100,
"raw": "100"
}
}
],
"kind": "var"
},
{
"type": "ExportDefaultDeclaration",
"start": 19,
"end": 45,
"declaration": {
"type": "Identifier",
"start": 35,
"end": 43,
"name": "Max_Size"
}
}
],
"sourceType": "module"
}
默认导出变量 (函数)
const ast = acorn.parse(`function a(){} export default a;`, {
ecmaVersion: 2020,
sourceType: "module",
});
console.log(JSON.stringify(ast, null, 2));
{
"type": "Program",
"start": 0,
"end": 32,
"body": [
{
"type": "FunctionDeclaration",
"start": 0,
"end": 14,
"id": {
"type": "Identifier",
"start": 9,
"end": 10,
"name": "a"
},
"expression": false,
"generator": false,
"async": false,
"params": [],
"body": {
"type": "BlockStatement",
"start": 12,
"end": 14,
"body": []
}
},
{
"type": "ExportDefaultDeclaration",
"start": 15,
"end": 32,
// 被导出的声明或表达式
"declaration": {
"type": "Identifier",
"start": 30,
"end": 31,
"name": "a"
}
}
],
"sourceType": "module"
}
默认导出 对象表达式
const ast = acorn.parse(`function add(a, b) {return a + b;} export default { add };`, {
ecmaVersion: 2020,
sourceType: "module",
});
console.log(JSON.stringify(ast, null, 2));
{
"type": "Program",
"start": 0,
"end": 58,
"body": [
{
"type": "FunctionDeclaration",
"start": 0,
"end": 34,
"id": {
"type": "Identifier",
"start": 9,
"end": 12,
"name": "add"
},
"expression": false,
"generator": false,
"async": false,
"params": [
{
"type": "Identifier",
"start": 13,
"end": 14,
"name": "a"
},
{
"type": "Identifier",
"start": 16,
"end": 17,
"name": "b"
}
],
"body": {
"type": "BlockStatement",
"start": 19,
"end": 34,
"body": [
{
"type": "ReturnStatement",
"start": 20,
"end": 33,
"argument": {
"type": "BinaryExpression",
"start": 27,
"end": 32,
"left": {
"type": "Identifier",
"start": 27,
"end": 28,
"name": "a"
},
"operator": "+",
"right": {
"type": "Identifier",
"start": 31,
"end": 32,
"name": "b"
}
}
}
]
}
},
{
"type": "ExportDefaultDeclaration", // 默认导出声明
"start": 35,
"end": 58,
"declaration": {
"type": "ObjectExpression",
"start": 50,
"end": 57,
// 对象属性
"properties": [
{
"type": "Property", // 对象属性节点
"start": 52,
"end": 55,
"method": false,
"shorthand": true,
"computed": false,
"key": {
"type": "Identifier",
"start": 52,
"end": 55,
"name": "add"
},
"value": {
"type": "Identifier",
"start": 52,
"end": 55,
"name": "add"
},
// 表示普通数据属性,非getter、setter
"kind": "init"
}
]
}
}
],
"sourceType": "module"
}
默认导出 函数声明
const ast = acorn.parse(`export default function fn() {}`, {
ecmaVersion: 2020,
sourceType: "module",
});
console.log(JSON.stringify(ast, null, 2));
{
"type": "Program",
"start": 0,
"end": 31,
"body": [
{
"type": "ExportDefaultDeclaration",
"start": 0,
"end": 31,
"declaration": {
"type": "FunctionDeclaration",
"start": 15,
"end": 31,
"id": {
"type": "Identifier",
"start": 24,
"end": 26,
"name": "fn"
},
"expression": false,
"generator": false,
"async": false,
"params": [],
"body": {
"type": "BlockStatement",
"start": 29,
"end": 31,
"body": []
}
}
}
],
"sourceType": "module"
}
最后
- ESTree 规范
-
在线查看代码片段的AST语法结构