在建立我们的BFF层后,我们其实就有了服务端渲染的能力。其实服务端渲染说白了也就是在做一件事情:获取用户所请求的页面模板文件,将内部所需要的数据填充好以后,汇总成HTML字符串然后发送给前端浏览器
但是单纯的依靠服务端渲染前端模板本身是有限制的,其中第一个限制就是它占用服务器资源:设想一下每个请求我们都需要单独进行IO操作读写模板,填写数据;一旦访问量过大的时候,后面的请求就会受到前面请求IO读写占用时间的影响导致响应时间过长,甚至是请求超时因此这种方式存在性能瓶颈。第二个限制就是它没有我们CSR(客户端渲染)那么灵活,CSR的页面存在各种各样前端页面级别的路由(即我们所熟知的SPA应用),它可以通过页面Hash或者浏览器History对象的状态扭转来模拟多个页面,从而创造虽然只有一个静态文件(页面)但是却有无数个页面的体验感,虽然按道理来说可以靠多个静态文件(MPA的方式)来实现这一点,不过在服务器这种存储资源寸土寸金的地方,不建议这么做。最后就是CSR具有SSR不存在的某些能力,比如与浏览器交互,在CSR中由于JS代码运行环境是在浏览器中,这就决定了它能够调用DOM和BOM等等完成对一些特定事件的交互,例如更改页面布局,调用浏览器缓存等等操作。这些能力也只有浏览器能够提供而SSR由于运行在Node环境,也就无法做到。因此综上所述,前后端分离的架构对于该项目而言是有必要实现的。
这也就引出了这篇文章的核心,如何将前后端架构分离,如何构建前端?
这些问题概括起来为一个问题,就是前端工程化
那有人可能会问了,为什么需要前端工程化,前端本身就是html,css,js这三个文件,全部放在一起不就行了吗?是的,搁在十几二十年前,静态网页盛行的那个年代这么做完全行得通。但是随着时代在变化,技术在发展,静态网页远不能满足现代社会的需求。现代网页为了能将产品的效果展示出来,会大量的运用到图片,有的甚至会上视频和音频等等,从多个感官传达给用户。同时前端开发者为了减轻开发负担,会引入各式各样的前端库,例如常见的UI库Vue、React等等,状态管理库Pinia、Redux等等。这些各种各样的文件类型,库文件等等如果不集中起来管理,最直接导致的结果就是代码难以维护。到时候HTML文件里这里一个script标签引入这个库,那里一个引入那个库,最关键的是如果库废弃了怎么办?这些都无疑增加了维护成本。其次,浏览器只认识HTML、CSS和JS三种 文件类型啊,你库里的.vue文件怎么让浏览器运行起来?因此前端工程化主要就是为了解决这两个问题而存在的
- 将前端所用到的库、静态文件等等统一管理,进而方便后续的代码维护
- 将各式各样不同类型的文件全部集中在一起编译,输出成HTML文件能识别出来的文件类型:html、js、css
知道了目的以后,接下来就是怎么做?在我们项目里如何落地?
我们不妨从之前BFF层的构建开始寻求灵感,既然后端的核心架构是利用解析引擎将项目中各个业务模块加载并收拢在一起运行在内存中进而提供服务的这种模式,那么前端能不能也借鉴这样的思想来完成这个工作呢?
可以的兄弟,一定是可以的,不然我也没必要花那么大精力来写这篇文章了。其实这个事情在前端术语中就叫做打包,如果你用过webpack、vite这类型打包工具那一定不陌生,它就是前端工程化中一个最重要的环节。
其实打包工具所做的事情就是如此,它的输入为:若干种不同类型的文件,输出为:浏览器所认识类型的文件。打包的过程其实对应的就是解析引擎所做的事情,它加载并读取各类型不同的文件,将其按照某些特定的规则,将其转化为我们 HTML、CSS、JS文件
那解析引擎是如何实现这点的?
首先是寻址,解析引擎需要先找到项目代码中所有所使用到的库和工具、代码、图片静态资源等等。这一点它是通过源代码中的import语句完成的,顺着每一行import递归去寻找,就能够把所有的项目依赖绘制成一张图。
紧接着,就是根据绘制的依赖图,一个一个的去进行文件类型转换。这个转换的过程也有专门的工具在做,这个工具叫做解析器(loader),如果你配置过Webpack估计你也不会对这个工具陌生。至于解析器是如何将对应的文件转换为HTML、JS、CSS的呢?这里就不拓展开来描述了,有兴趣的就自行百度一下。
最后就是将这些全部转换好的文件汇总并输出成为一个总的HTML、CSS、JS文件
这就是一个解析引擎的主要工作流程,但是注意它不是所有流程。市面上大部分的解析引擎都会对这个工作流程做优化,例如模块拆分、环境分流等等。
因此回到我们项目,为了实现这个打包过程,我们直接搬来webpack,就不手搓了,手搓虽然可以但是没必要。
Webpack主要配置如下
{
entry:项目入口,即前端源代码入口
output:项目输出,即打包好的产物放置的路径
modules:块加载规则,例如遇到了哪种类型的文件采用哪种类型的解析器来解析
plugins:webpack运行中的一些额外功能的拓展,贯穿着webpack项目从启动时到项目停止时的所有生命周期
optimization:打包过程中的一些优化项
}
如果你毫不在意配置出来的打包性能和拓展能力,仅仅只想维持能够打包这种程度,那么plugins和optimization不要也是可以的。甚至如果你的项目中只有HTML、CSS、JS这三种文件类型,那么你甚至可以不要modules
言归正传,因为这个项目成立之初对标的是企业级的项目,因此这里配置还是得详尽一些。项目中所有的前端页面都是由Vue所编写,因此使用了Vue-loader和Plugins
const path = require('path')
const glob = require('glob')
const { VueLoaderPlugin } = require('vue-loader')
const { ProvidePlugin, DefinePlugin } = require('webpack')
const HTMLWebpackPlugin = require('html-webpack-plugin')
const pageEntries = {};
const htmlWebpackPluginList = []
/**
* 我们约定所有页面的源代码都全部存放在app/pages下方,并且以entry.xxx.js的方式命名
* 那么我们可以依靠glob这个包来读取app/pages下方所有的目录,也就能够拿到所有的页面文件了
* 主要目的是为了快速构造webpack配置中的entry以及HtmlWebpackPlugin配置
* 因为未来我们的入口可能有一个或者多个页面,相对应的就需要配置一个或者多个HtmlwebpackPlugin。所以我们就统一在这里动态生成
*/
const entryList = path.resolve(process.cwd(), 'app', 'pages', '**', 'entry.*.js')
glob.sync(entryList).forEach((filePath) => {
const entryName = path.basename(filePath, '.js') //拿到页面文件名称
pageEntries[entryName] = filePath;
htmlWebpackPluginList.push(new HTMLWebpackPlugin({
//产物(最终模板)输出路径
filename: path.resolve(process.cwd(), 'app', 'public', 'dist', `${entryName}.tpl`),
//指定要使用的模板文件
template: path.resolve(process.cwd(), 'app', 'view', 'entry.tpl'),
//要注入的代码块,注意需要与entry中的chunks保持一致,一个入口需要声明一个HTMLWebpackPlugin,除非代码块需要注入多个entry
chunks: [entryName]
}))
})
/**
* webpack基础配置
*/
module.exports = {
//入口
entry: pageEntries,
//模块解析配置(决定了要加载解析哪些模块,以及用什么方式去解析)
module: {
rules: [
{
test: /\.vue$/,
use: {
loader: 'vue-loader'
}
},
{
test: /\.js$/,
include: [path.resolve(process.cwd(), 'app', 'pages')], //只对业务代码进行babel-loader的编译解析
use: {
loader: 'babel-loader',
}
},
{
test: /\.(png | jpe?g| gif)(\?.+)?$/,
use: {
loader: 'url-loader',
options: {
limit: 300,
esModule: false
}
}
},
{
test: /\.css$/,
use: ['style-loader', 'css-loader']
},
{
test: /\.less$/,
use: ['style-loader', 'css-loader', 'less-loader']
},
{
test: /\.(eot | svg | ttf | woff | woff2)(\?\S*)?$/,
use: 'file-loader',
}
]
},
//输出目录,留空,由环境配置自行决定(生产/开发)
output: {
},
//配置模块解析的具体行为(定义webpack在打包时如何找到并解析具体模块的路径)
resolve: {
extensions: ['.js', '.vue', '.less', '.css'],
alias: {
$pages: path.resolve(process.cwd(), 'app', 'pages'),
$common: path.resolve(process.cwd(), 'app', 'pages', 'common'),
$widget: path.resolve(process.cwd(), 'app', 'pages', 'widgets'),
$store: path.resolve(process.cwd(), 'app', 'pages', 'store'),
}
},
//webpack插件
plugins: [
/**
* 处理.vue文件,这个插件是必须的
* 它的职能是将你定义过的其他规则复制并应用到.vue文件里
* 例如,如果有一条匹配规则/\.js/的规则,那么它也会应用到.vue文件中的script板块中
*/
new VueLoaderPlugin(),
//把第三方库暴露到window context下,这个插件的主要作用是将我们指定的模块暴露给源代码使用
//例如我们在下方指定了Vue这个模块,那么这也就意味着所有源代码文件都不需要再import Vue from 'vue'了;相当于让这个模块变为了全局共享模块
new ProvidePlugin({
Vue: 'vue',
axios: 'axios',
_: 'lodash',
}),
//定义全局常量,这些全局常量在源代码中是能直接访问到的。例如在源代码entry.page1.vue中,可以直接在script标签中console.log(__VUE_OPTIONS_API__),结果为true
new DefinePlugin({
__VUE_OPTIONS_API__: 'true',//支持VUE解析options API
__VUE_PROD_DEVTOOOLS__: 'false',//禁用VUE的调试工具
__VUE_PROD_HYDRATION_MISMATCH_DETAILS__: 'false', //生产环境水合信息
}),
//构造最终渲染的页面模板
...htmlWebpackPluginList,
],
//打包输出优化(代码分割、代码合并、缓存、Treeshaking、压缩优化策略等等)
optimization: {
//分包配置
/**
* 分包配置应该自行根据项目配置和项目经验来进行,这里展示的仅仅只是演示策略
* 1.vendor:第三方lib库,基本不会改动,除非依赖版本升级
* 2.common: 业务组件代码的公共部分抽取出来,改动较少
* 3.entry.{page}:不同页面里的entry里的业务组件代码的差异部分,会经常改动
* 目的:把改动和引用频率不一样的js区分出来,以达到更好利用浏览器缓存的效果
*/
splitChunks: {
chunks: 'all', //对同步和异步模块都进行分割
maxAsyncRequests: 10, //每次异步加载的最大并行请求数
maxInitialRequests: 10, //入口点的最大并行请求数
cacheGroups: {
//第三方依赖库。
/**
* 注意如果有些module同时被多个分包策略所命中,那么这个module会被分至优先级更高的包里面。
* 假如Vue这种第三方库,被我们多个页面所引用,但是如果我们有两个分包策略,一个包vendor匹配node_modules中的模块,一个包common匹配引用次数大于等于2的模块;
* 那在这种场景下,由于Vue既属于node_modules中的包,同时也属于引用次数大于等于2的包,那么最终打包以后,生成的包会被放置在优先级更高的包里,即common包中(因为下面的配置common包优先级为-10,node_modules优先级为-20,common包更高)
*/
vendor: {
test: /[\\/]node_modules[\\/]/, //将node_modules这种第三方库单独分包到vendor中
name: 'vendor', //模块名称
priority: 20, //优先级,数字越大优先级越高
enforce: true, //是否强制执行
reuseExistingChunk: true //是否复用公共的chunks
},
//公共模块
common: {
name: 'common',
minChunks: 2, //指定最少引用的chunks,也就是说至少要有两个Chunks引用同一个代码片段,那么这个代码片段会被拆分为新包
minSize: 1, //最小分割文件大小(1 byte)
priority: 10,
reuseExistingChunk: true
},
}
},
//将webpack运行时的注入代码单独输出到一个bundle中,即runtime.js
runtimeChunk: true
}
}
这里着重讲解几个配置项和插件吧
- entry: 因为项目是多页面MPA模型,所以入口可能是多个存放在app/pages下方的模板文件,因此这里在开头就使用JS函数动态组装成了一个对象
- output:留空,因为最终产物生成路径跟你打生产包/测试包/开发包是有很大的区别的,这些个配置单独放在对应的配置文件中,这里就不展开了
- ProvidePlugin, DefinePlugins:为了开发体验加入的。ProvidePlugin用于给前端源代码全局注入一些第三方依赖,例如Vue和Axios。这样子书写源代码时就再也不用import xxx from 'vue' 或者 import xx from 'axios'了。DefinePlugins则是定义一些全局常量,禁用一下Vue的调试工具等等,同时也提供给源代码访问,即便未来要改也可以在源代码运行时中更改。
- HTMLWebpackPlugin:这个插件是重中之重,因为它决定了我们最终生成的HTML文件,包括它生成前模板从哪里来,最终生成的产物模板又该注入什么第三方库等等。按照使用规则来说,一个入口需要对应一个插件实例,因此这里也给它调整成动态生成了
- optimiation.splitChunks:这个是优化打包过程的重中之重,它决定了你代码将被拆分为几个包。在我的项目里面,我是给他拆分为了三个,分别是业务代码包、vendor(第三方库包)、common(公共模块包),如果有更好的拆分方式欢迎分享。
- 另外科普一下为什么要拆分包?因为在不拆分的情况下,你的业务代码和你的一些公共库代码是全部融合在一起的,那也就是说一旦你的业务代码发生了变更,这些公共库代码就会跟随着你的业务代码重新打一遍进而生成一个新包,这对于打包过程而言造成了性能浪费,其次最后生成的包体积也会异常庞大,最终结局使用浏览器访问你的包会加载时间特长。因此为了减少包体积,同时也为了提升打包的性能,分包是必须的。此外分包还有另一个好处,在我的项目里由于是MPA模型,多个页面间使用的都是同一个公共库包。公共库拆分出来,一旦有一个页面加载好了公共库包,其他的页面都可以共享,就不会再重新单独随着业务代码加载一遍。因为这个公共库包在第一个页面加载完成时就已经存在浏览器缓存中了,其他页面若需要使用直接从缓存中读取,不需要再单独建立HTTP请求拉取。
- 分包配置中一项重要配置为priority。这个配置决定了此项分包规则的优先级,也就继而影响我们的分包结果。例如Vue这个公共库在项目中既命中了vendor包的分包规则,同时也命中了common公共模块的分包策略:即只要两个模块以上引用了这个模块那么就会被拆分成单独的包。因此在这种情况下,优先级就很重要了,这里因为考虑到node_modules这个包分出去会复用率更高因此调高了node_modules的优先级。
生产环境配置
mode: 'production',//指定开发模式为生产环境
//产物输出路径配置,因为开发和生产环境输出不一致,所以在各自环境中进行配置
output: {
filename: 'js/[name]_[chunkhash:8].bundle.js',
path: path.join(process.cwd(), './app/public/dist/prod'), //决定了打包后产物所在的根目录;
/**
* 注意path + filename才是最终打包后js生成的目录,比如path定义为/dist,filename定义为js/xxx.js,那么最终打包后生成的js文件将落地在dist/js/xxx.js处
* 最终生成的js文件的所在路径就是代码中资源寻址的根路径,比如我们源代码中有一行代码为<img src='/assets/xxx.png'>,那么打包后,这份代码将从dist/js/xxx.js处出发去寻找/assets/xxx.png
* 通常情况下这样子是肯定寻址寻不到对应的静态资源的,所以我们会配置publicPath这么一个属性,指定代码中的静态资源的寻址根路径
* 例如指定的是/dist,那么代码中静态资源的寻址就会变成<img src="/dist/assets/xxx.png">,也就是说有了这个配置项后webpack会为我们自动补齐这个寻址前缀,因此代码会从/dist出发去寻找/assets/xxx.png
*/
publicPath: '/dist/prod',
crossOriginLoading: 'anonymous',
},
module: {
rules: [
{
test: /\.css$/,
use: [
MiniCssExtractPlugin.loader,
'happypack/loader?id=css'
]
},
{
test: /\.js$/,
include: [path.resolve(process.cwd(), 'app', 'pages')], //只对业务代码进行babel-loader的编译解析
use: 'happypack/loader?id=js'
}
]
},
performance: {
hints: false
},
plugins: [
//每次build前,清空public/dist目录
new CleanWebpackPlugin(['public/dist'], {
root: path.resolve(process.cwd(), 'app'),
exclude: [],
verbose: true,
dry: false,
}),
//提取css的公共部分,有效利用缓存,(非公共部分使用inline)
new MiniCssExtractPlugin({
chunkFilename: 'css/[name]_[contenthash:8].bundle.css',
}),
//优化并压缩CSS资源
new CSSMinimizerPlugin(),
//多进程打包JS,加快打包速度
new HappyPack({
...happyPackCommonConfig,
id: 'js',
loaders: [`babel-loader?${JSON.stringify({
presets: ['@babel/preset-env'],
plugins: ['@babel/plugin-transform-runtime']
})}`]
}),
//多进程打包CSS,加快打包速度
new HappyPack({
...happyPackCommonConfig,
id: 'css',
loaders: [{
path: 'css-loader',
options: {
importLoaders: 1
}
}]
}),
//浏览器在请求资源时不发送用户的身份凭证
new HtmlWebpackInjectAttributesPlugin({
crossorigin: 'anonymous',
})
],
optimization: {
minimize: true,
minimizer: [
//使用TerserPlugin的并发和缓存,提升压缩阶段的性能,并且清除console.log
new TerserWebpackPlugin({
cache: true, //启用缓存来加速构建过程
parallel: true, //利用多核CPU优势来加快压缩速度
terserOptions: {
compress: {
drop_console: true
}
}
})
]
}
生产环境和默认配置相比较下大同小异,就是一些优化的细微区别
- HappyPack引入进行多进程打包加速
- TerserWebpackPlugin用于混淆、压缩JS文件,同时用来删除JS中的一些console.log调试代码
- MiniCssExtractPlugin用于提取公共的CSS代码,例如一个模块a引入了custom.css,另一个模块b也引入了这个css文件,那么这个css文件在打包后会被单独提取出来为一个css文件。
开发环境和热更新
开发环境相对于生产环境和默认配置的配置来说,其实也大同小异,要区别在于开发环境加入了热更新的功能。那么什么是热更新呢?简单点来说就是本地代码一旦产生了修改,网页就会自动刷新并应用上更改后的代码的能力。举个例子就是:当我们修改了一行代码以后(比如将页面字体颜色改为红色),那么在没有热更新的功能的时候,你需要手动重新编译这份代码,然后刷新浏览器才能看到上述效果。而有了热更新以后,这个手动的过程就变成全自动了,本地代码会在你产生变更后自动重新编译,并且编译完成后自动通知浏览器刷新。热更新对于我们开发环境这种经常发生代码变动的环境来说,是一个特别实用且方便的功能。
那么如何增加热更新功能呢?
在webpack项目里,最简单的一种方式就是配置devServer这个配置项。同时呢需要安装一个webpack-dev-server这么一个依赖包。但是在这里为了理解其原理,我决定利用express手搓一个。
首先一句话来了解一下热更新原理:将打包生成的文件部署到一台服务器上,让这个服务器随时监控、监听着本地代码变更,一旦有变更后,重新编译并在编译完成后通知浏览器。这么说可能有点抽象,但其实总结成一张图也就是这样:
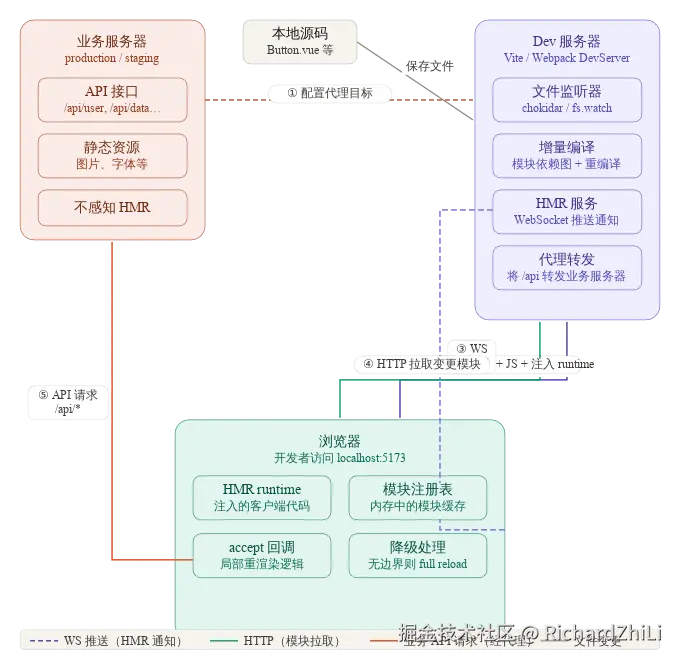
首先,我们的本地源码编译、打包后不再生成为真实的物理文件,而是变成了常驻在开发(Dev服务器)里的内存程序。当浏览器访问页面时,其实这个页面内容是由开发服务器所提供的,业务服务器此时只是单纯的变成了一个接口服务器,不再承载静态资源。这个Dev服务器内部实现了对我们本地源码文件的监听(node:fs.watch模块),同时它与浏览器建立了双向通信机制(在这张图里体现为Websocket协议即WS)。因此每当我们更改了源码文件后,监听器就会触发,随之而来的就是重新编译。当编译完成后这个开发服务器会以WS协议告知浏览器内容发生了变更,因此需要即时刷新。
- 为什么非得成立双向通信?这个图中看起来浏览器并没有向Dev服务器推送任何资源啊?使用HTTP单向协议不就行了吗?原因在于服务器不通过WS协议没法主动向浏览器推送内容,因为HTTP协议是单向的。如果使用单向协议,浏览器就必须设置轮询从而知晓Dev服务器内容是否有变动,这既会造成性能浪费,同时效果也不太好。轮询了必然有时间间隔,有时间间隔就意味着没法做到实时更新。
言归正传,实现热更新的关键点就是在于实现一台Dev服务器,这台Dev服务器既能够有监控本地文件变更的能力,同时也要有与浏览器建立双向通信的能力。依赖于Express的中间件,我们很容易能实现这一点,前者对应webpack-dev-middleware,后者对应的是webpack-hot-middleware。因此结合两个中间件,就有了下述代码
//本地开发启动devServer
const express = require('express');
const path = require('path');
const webpack = require('webpack');
const consoler = require('consoler')
const devMiddleware = require('webpack-dev-middleware');
const hotMiddleware = require('webpack-hot-middleware');
const app = express();
//从 webpack.dev.js 获取 webpack配置和 devServer 配置
const { webpackConfig, DEV_SERVER_CONFIG } = require('./config/webpack.dev')
const compiler = webpack(webpackConfig);
//指定静态文件目录
app.use(express.static(path.resolve(process.cwd(), 'app', 'public', 'dist')))
// 引用 devMiddleware中间件,监控文件改动
app.use(devMiddleware(compiler, {
//落地文件
writeToDisk: filePath => filePath.endsWith('.tpl'),
//资源路径
publicPath: webpackConfig.output.publicPath,
//headers配置
headers: {
'Access-Control-Allow-Origin': '*',
'Access-Control-Allow-Methods': 'GET,POST,PUT,DELETE,PATCH,OPTIONS',
'Access-Control-Allow-Headers': 'X-Requested-With, Content-Type,Authorization',
},
stats: {
colors: true
}
}))
// 引用hotMiddleware中间件(实现热更新)
app.use(hotMiddleware(compiler, {
path: `/${DEV_SERVER_CONFIG.HMR_PATH}`,
log: () => { }
}))
consoler.info('请等待webpack初次构建完成提示...')
//启动 dev-server
const port = DEV_SERVER_CONFIG.PORT;
app.listen(port, DEV_SERVER_CONFIG.HOST)
同时呢为了让产物文件产出并生成在dev服务器的内存中,我们还得对webpack dev环境做出如下配置
const path = require('path')
const merge = require('webpack-merge');
//基类配置
const baseConfig = require('./webpack.base.js');
const { HotModuleReplacementPlugin } = require('webpack');
//dev-server配置
const DEV_SERVER_CONFIG = {
HOST: '127.0.0.1',
PORT: 9002,
HMR_PATH: '__webpack_hmr',//官方规定
TIMEOUT: 20000,
}
//开发阶段的 entry 配置需要加入 hmr
Object.keys(baseConfig.entry).forEach(key => {
//第三方包不作为HMR入口
if (key !== 'vendor') {
baseConfig.entry[key] = [
//主入口文件
baseConfig.entry[key],
`webpack-hot-middleware/client?path=http://${DEV_SERVER_CONFIG.HOST}:${DEV_SERVER_CONFIG.PORT}/${DEV_SERVER_CONFIG.HMR_PATH}&timeout=${DEV_SERVER_CONFIG.TIMEOUT}&reload=true`
]
}
})
//生产环境webpack配置
const webpackConfig = merge.smart(baseConfig, {
mode: 'development',//指定开发模式为生产环境
//产物输出路径配置,因为开发和生产环境输出不一致,所以在各自环境中进行配置
output: {
filename: 'js/[name]_[chunkhash:8].bundle.js',
path: path.join(process.cwd(), './app/public/dist/dev'), //决定了打包后产物所在的根目录;
publicPath: `http://${DEV_SERVER_CONFIG.HOST}:${DEV_SERVER_CONFIG.PORT}/public/dist/dev/`,
globalObject: 'this',
},
devtool: 'source-map',
//开发阶段插件
plugins: [
//用于实现热模块替换,模块热替换允许在应用程序运行时替换模块,极大的提升开发效率,因为能让应用程序一直保持运行状态
new HotModuleReplacementPlugin({
multiStep: false
})
]
})
module.exports = {
//webpack配置
webpackConfig,
//devServer配置,暴露给dev.js使用
DEV_SERVER_CONFIG,
}
这样,一个简洁的具有热更新能力的webpack开发环境配置就完成了。到此为止前端工程化的内容基本上就完成了。
接下来就是一些前端的基建,都是偏向于业务代码一侧的开发了,包含MPA源码入口的书写,前端库的引入、请求库的封装等等一系列事情
app/pages/boot.js MPA的启动入口
import { createApp } from 'vue';
import Pinia from '$store'
import { createWebHashHistory, createRouter } from 'vue-router';
import ElementPlus from 'element-plus';
import 'element-plus/dist/index.css';
import './assets/custom/index.css'
/**
* vue 页面主入口 ,用于启动Vue
* @params pageComponent vue 入口组件
* @params {object} config 对应入口页面的配置项,包含routes和libs,routes表示这个页面的路由结构,libs是这个页面用到的三方包
*/
export default (pageComponent, {
routes = [], //这个页面的路由
libs = [], //用到的包
} = {}) => {
const app = createApp(pageComponent);
//引入Element-plus
app.use(ElementPlus);
//引入Pinia
app.use(Pinia);
//根据config引入三方包
if (libs?.length) {
for (let i = 0; i < libs.length; i++) {
app.use(libs[i]);
}
}
//引入路由,如果没有给定入参路由的话,那么直接挂载就行
if (!routes?.length) {
app.mount('#root');
return;
}
const router = createRouter({
history: createWebHashHistory(), //采用Hash模式,
routes,
})
app.use(router);
router.isReady().then(app.mount('#root'));
}
axios 的封装 app/pages/common/curl.js
const md5 = require('md5')
import { ElMessage } from 'element-plus';
const responseCodeHandlerMap = {
442: () => ElMessage.error('请求参数异常'),
445: () => ElMessage.error('请求不合法'),
50000: (message) => ElMessage.error(message),
}
/**
* 前端封装的 curl 方法
* @params options 请求参数
*/
export default ({
url = '',
method = 'post',
headers = {},
query = {}, //url query
data = {}, //post body
responseType = 'json',
timeout = 60000, //超时时间
errorMessage = '网络异常'
}) => {
//为接口做签名处理
const signKey = 'xxx';
const st = Date.now();
const ajaxSetting = {
url,
method,
params: query,
data,
responseType,
timeout,
headers: {
...headers,
s_t: st,
s_sign: md5(`${signKey}_${st}`),
}
}
//构造请求参数(把输入参数转为axios的配置参数)
return axios.request(ajaxSetting).then((res = {}) => {
const { data: axiosResponseDataObj } = res || {}
//后端返回API格式
const { success = false, code = 200, message = '' } = axiosResponseDataObj || {};
//失败时,根据响应代码找到对应的handler执行。同时将失败原因返回给调用方
if (!success && typeof responseCodeHandlerMap[code] === 'function') {
responseCodeHandlerMap[code](message);
return Promise.resolve({
success,
code,
message
})
}
//成功的时候,将响应数据返回给调用方
return Promise.resolve({
data: axiosResponseDataObj.data,
metadata: axiosResponseDataObj.metadata,
success
})
}).catch(err => {
const { message } = err;
if (message.match(/timeout/)) {
return Promise.resolve({
message: 'Request Timeout',
code: 504
})
}
return Promise.resolve(error);
})
}
app/pages/store/index.js 状态库
import { createPinia } from 'pinia';
const pinia = createPinia();
export default pinia;
测试页面: app/pages/page1.vue
<template>
<h1>page1</h1>
<el-input
v-model="content"
style="width:300px;"
/>
<el-table
:data="tableData"
style="width:100%"
>
<el-table-column
prop="name"
label="name"
width="180"
/>
<el-table-column
prop="desc"
label="desc"
/>
</el-table>
</template>
<script setup>
import {ref} from 'vue';
import $curl from '$common/curl'
console.log('page1 init')
const content = ref('');
const tableData = ref([{
name:'Richard',
desc:'desc'
}]);
const fetchProjectList = async () => {
try {
const {data, success= false, message = '' } = await $curl({
url:'/api/project/list',
method:'post',
data:{
proj_key:'22222'
}
})
if(!success) {
throw Error(message);
}
tableData.value = data;
}
catch(err){
console.error(err?.message ?? err)
}
}
fetchProjectList()
</script>
<style lang="less" scoped>
h1 {
color:red;
}
</style>
page1.entry.js
import boot from '$pages/boot.js';
import page1 from './page1.vue';
boot(page1);
总结:
- 服务端渲染因为相比较于客户端渲染更加浪费服务器性能、不具备操作浏览器能力,因此在制作前端页面时只能倾向于做一些交互性不强并且页面结构比较简单的页面。在这种前提背景下,将服务端渲染模式分离为客户端渲染的模式的需求也就应运而生(针对于elpis这个项目而言)
- 为了分离服务端渲染的模式为客户端渲染模式,因此需要做前端工程化建设。前端工程化建设主要解决两个痛点:一是统一管理前端所用到的库和静态资源(例如图片、CSS文件等等),这有利于未来项目扩张后的代码维护。二是确保各式各样类型的文件(例如浏览器无法识别的vue文件、scss文件、图片等)能够在浏览器里运行。前端工程化中重点之一就是打包这个环节。打包的定义是接收各种类型的文件作为输入,经过解析引擎解析后,输出为HTML、JS、CSS文件的过程。解析引擎的主要任务包含依赖寻找、解析器编译、汇总并输出解析文件三件事。在项目中我们使用了Webpack作为例子举例
- 由于该项目成立之初是对标企业级项目,因此webpack配置被拆分为了默认配置、开发环境配置以及生产环境配置三种配置。其中着重讲解了默认配置中的splitChunks分包策略以及开发环境配置项中的热更新原理。
- 业务层面上,封装了MPA项目的总入口以及axios请求器及引入了状态管理工具、路由管理工具等