从递归组件到 DSL 引擎:我造了一个让 AI 能"搭 UI"的运行时
我最初只是想用 Vue 递归组件做动态渲染,后来发现这条路的天花板比想象中低得多。这篇文章记录了我从零设计一个 Schema-Driven 渲染引擎的过程——踩过的坑、做过的取舍、以及为什么我认为这种架构天然适合 AI 时代。
一、起点:递归组件的天花板
故事的起点很简单。我要做一个低代码平台,需要根据 JSON 配置动态渲染 UI。最直觉的方案是 Vue 的递归组件:
<template>
<component :is="node.type" v-bind="node.props">
<DynamicRenderer
v-for="child in node.children"
:key="child.id"
:node="child"
/>
</component>
</template>
一开始能跑通。但随着需求复杂度上升,问题一个接一个冒出来:
性能没法深入优化——每个递归组件都是一个完整的 Vue 组件实例,有自己的生命周期、reactive 系统开销。100 个节点就是 100 个组件实例,1000 个节点时页面已经开始卡了。你没有办法跳过没变化的子树,因为 Vue 的响应式系统是按组件粒度工作的。
事件处理不好做——JSON 里写的是 { event: 'click', handler: 'submitForm' },但递归组件要把这个字符串映射成真实的函数调用,你得自己写一套 $emit 转发链,越写越像在造一个 mini 框架。
双向绑定更麻烦——v-model 在递归组件里要一层层 $emit('update:modelValue') 往上冒泡,或者搞一个全局 store 做中间层,写法又丑又容易出 bug。
表达式求值是个坑——JSON 里写 "disabled": "{{ !isValid }}",你要么 eval() 一下(安全隐患),要么自己写个表达式解析器(工作量巨大),反正递归组件本身帮不了你。
我意识到,递归组件方案的本质问题是:它还是在用"组件"的粒度思考,但 Schema 驱动的 UI 需要的是"节点"粒度的控制权。
于是我开始想:如果不用递归组件,而是直接把 Schema 编译成 VNode 呢?如果把"事件处理"抽成一个指令集虚拟机呢?如果把表达式解析做成一个安全沙箱呢?
这就是 Vario 的起点。
二、Vario 全貌:三层解耦的 Schema 渲染运行时
先交代 Vario 的完整架构。它不是一个组件库,不是一个低代码平台,是一个 Schema 渲染运行时——由 4 个包组成的 monorepo,总共约 10,000 行 TypeScript 源码,579 个单元/集成测试全部通过。
@variojs/types — 跨包共享类型(无业务逻辑,消除循环依赖)
@variojs/core — Action VM + 表达式引擎 + RuntimeContext(零 Vue 依赖)
@variojs/schema — defineSchema + 验证 + 规范化
@variojs/vue — useVario composable + VNode 渲染器
数据流是单向的:
Schema (JSON 对象)
↓ normalizeSchemaNode() 规范化(空格/格式统一,WeakMap 缓存)
↓ validateSchema() 结构验证 + 表达式 AST 白名单校验
↓
@variojs/core
↓ createRuntimeContext() 创建状态上下文(Proxy 保护系统 API)
↓ evaluate() 表达式求值(Babel AST → 白名单 → 编译/解释)
↓ execute() Action VM 执行指令序列(超时 5s,最大 10000 步)
↓
@variojs/vue
↓ useVario() Composition API 入口
↓ VueRenderer.render() Schema 递归 → VNode 树
↓ Path Memo 缓存无变化的子树 VNode
↓
Vue 3 接管渲染
关键架构约束:@variojs/core 零 Vue 依赖,这是从第一天就定下的硬性要求。Core 里的 Action VM、表达式引擎、RuntimeContext 完全不知道 Vue 的存在——这意味着将来换成 React、Solid、甚至 Node.js 服务端渲染,Core 层不需要改一行代码。
三、先看看 Vario 写出来长什么样
直接上代码。一个带交互逻辑的表单:
import { useVario } from '@variojs/vue'
const { vnode, state } = useVario({
type: 'ElForm',
props: { labelWidth: '100px' },
children: [
{
type: 'ElFormItem', props: { label: '姓名' },
children: [{ type: 'ElInput', model: 'name', props: { clearable: true } }]
},
{
type: 'ElFormItem', props: { label: '邮箱' },
children: [{ type: 'ElInput', model: 'email', props: { type: 'email' } }]
},
{
type: 'ElButton',
props: { type: 'primary', disabled: '{{ !(name && email) }}' },
events: { 'click.prevent': [{ type: 'call', method: 'submit' }] },
children: '提交'
}
]
}, {
state: { name: '', email: '' },
computed: { isValid: (s) => !!(s.name && s.email) },
methods: {
submit: ({ state }) => { console.log('提交:', state.name, state.email) }
}
})
如果你写过 Vue,你会发现:ElInput、ElButton、ElFormItem 就是 Element Plus 的组件名,model: 'name' 就是 v-model,click.prevent 就是 @click.prevent,useVario() 返回的 { vnode, state } 就是标准的 Composition API 用法。
这是有意为之的设计。
四、深入 VueRenderer——Schema 如何变成 VNode
VueRenderer 是整个渲染链的核心,638 行代码,内部采用 DI 风格拆分为 9 个专职模块:
| 模块 |
职责 |
ComponentResolver |
组件类型解析(80+ 原生 HTML 标签 Set + 全局组件 Map 缓存) |
ModelPathResolver |
model 路径解析(228 行,支持嵌套循环变量 $item 解析、路径栈拼接) |
ExpressionEvaluator |
表达式求值(桥接 @variojs/core 的 evaluate) |
EventHandler |
事件绑定(366 行,6 种事件处理器格式规范化,修饰符解析) |
AttrsBuilder |
属性构建(props 表达式求值 + model 绑定 + 事件合并) |
LoopHandler |
循环渲染(createLoopContext 对象池复用 + Fragment 包裹) |
ChildrenResolver |
子节点解析(文本插值 / 作用域插槽 / VNode 子树) |
LifecycleWrapper |
生命周期包装(6 个 Vue 生命周期钩子 + provide/inject) |
PathMemoCache |
VNode 缓存(路径 + schemaId + 依赖键三级缓存键) |
一个 createVNode() 调用的完整流程(20 个步骤):
createVNode(schema, ctx, path)
1. ─ 验证 schema.type 存在
2. ─ cond 条件渲染:表达式 falsy → return null
3. ─ show 预求值:计算可见性用于依赖追踪
4. ─ Path Memo 判断:无 loop/model/表达式的静态子树 → 直接返回缓存
5. ─ 子树组件化判断:shouldComponentize() → VarioNode 独立组件
6. ─ Loop 处理:委托 LoopHandler → Fragment(循环项VNode[])
7. ─ 组件解析:原生标签返回字符串,自定义组件 markRaw() 防响应式
8. ─ Model 路径栈更新:嵌套 model 路径拼接
9. ─ 属性构建:props 表达式求值 + model 双向绑定 + 事件处理器
10. ─ 子节点解析:递归 VNode / 插值文本 / 作用域插槽
11. ─ show 可见性:{display: 'none'} 合并到 style
12. ─ Children 格式化:原生元素用数组,组件用函数插槽
13. ─ 生命周期/provide-inject:有则创建 LifecycleWrapper 组件
14. ─ ref 绑定:attachRef 到 RefsRegistry
15. ─ 自定义指令:withDirectives() 应用
16. ─ KeepAlive 包裹
17. ─ Transition 包裹
18. ─ Teleport 包裹
19. ─ Path Memo 写入缓存
20. ─ 返回 VNode
这 20 步的排列顺序不是随意的——Teleport 必须是最外层包裹(否则内部元素不会被传送),KeepAlive 必须在 Transition 之前(Vue 的渲染约束),Path Memo 的缓存判断必须在 Loop 之前(带循环的子树不能缓存)。
双向绑定是怎么做的
createModelBinding() 是整个渲染器最复杂的单个函数(310 行),需要处理:
-
原生表单元素 (
input/textarea/select)——不同元素用不同事件名和属性名
-
Vue 3 组件——
modelValue + update:modelValue 协议
-
具名 model——
model:checked、model:value 支持一个组件绑定多个 model
-
修饰符——
.trim(去空格),.number(parseFloat),.lazy(change 替代 input)
-
lazy 模式——
setTimeout(() => isActive = true, 0) 延迟激活,挂载期间不写 state
-
自定义绑定协议——通过
registerModelConfig() 注册
ctx ↔ Vue 状态同步——ReactiveAdapter 单一数据源
早期版本中,useVario() 需要在 RuntimeContext 的 plain object 和 Vue 的 reactive state 之间维护双向同步,靠三把锁(syncing / syncingPaths / watchSyncing)防止循环触发。这套机制能跑,但脆弱且难以理解。
当前版本已经用 ReactiveAdapter 协议彻底消灭了这个问题。核心思路受 Zustand 启发——状态只有一份:
// @variojs/types 中定义协议
interface ReactiveAdapter {
get(path: string): unknown
set(path: string, value: unknown): void
getProperty(key: string): unknown
setProperty(key: string, value: unknown): void
has(key: string): boolean
keys(): string[]
}
Vue 层提供 createVueReactiveAdapter(reactiveState),内部直接操作 reactive() 对象。Core 的 createRuntimeContext 接受 adapter 参数后,_get/_set 通过 adapter 读写,Proxy 的 5 个 trap(get/set/has/ownKeys/getOwnPropertyDescriptor)也路由到 adapter。
// useVario 中,三重锁被替换为两行代码:
const adapter = createVueReactiveAdapter<TState>(reactiveState)
const ctx = createRuntimeContext<TState>({}, { adapter, onStateChange, ... })
没有双份状态 = 没有同步 = 没有循环 = 不需要锁。 ctx._set('name', 'Alice') 直接写入 Vue 的 reactive 对象,onStateChange 只做缓存失效和渲染调度,不再做状态搬运。useVario 从 636 行减到 570 行,核心同步逻辑从 ~65 行减到 ~10 行。
五、Action VM:不用 eval 的动作执行引擎
传统方案处理"交互逻辑"的方式是往框架里挂副作用——watch、reaction、onChange。Vario 走的是完全不同的路:指令集虚拟机。
当前支持 13 种指令,分 5 个类别:
| 类别 |
指令 |
例 |
| 状态 |
set |
{ type: 'set', path: 'user.name', value: '{{ input }}' } |
| 数组 |
push pop shift unshift splice
|
{ type: 'push', path: 'todos', value: { text: '{{ newText }}' } } |
| 调用 |
call |
{ type: 'call', method: 'submit', params: { id: '{{ userId }}' }, resultTo: 'result' } |
| 流控 |
if loop batch
|
{ type: 'if', cond: '{{ isValid }}', then: [...], else: [...] } |
| 通信 |
emit navigate log
|
{ type: 'navigate', to: '{{ targetUrl }}' } |
这些指令之间是正交组合的关系——if 的 then/else 分支里可以嵌套任何指令,loop 的 body 里也可以,batch 可以包裹一组指令并做错误聚合(所有指令都执行,收集所有错误,最后统一抛出 BatchError)。
执行器的核心设计:不是 switch/case——所有动作(包括内置的 13 种)通过 ctx.$methods[action.type] 统一分派。这意味着你可以注册自定义指令类型,和内置指令完全平等。
一个真实的 Todo App 中"按下 Enter 添加待办"的事件定义:
{
"events": {
"keyup": [{
"type": "if",
"cond": "{{ $event.key === 'Enter' }}",
"then": [{ "type": "call", "method": "addTodo" }]
}]
}
}
这里 $event 是运行时注入的 DOM 事件对象。if 指令先用表达式引擎求值 cond,为 true 时执行 then 分支里的 call 指令。整个过程不需要一行 JavaScript 事件处理代码。
call 指令的三种参数形式:
// 字符串表达式——整个 params 是一个表达式求值结果
{ "type": "call", "method": "search", "params": "{{ keyword }}" }
// 对象命名参数——逐属性求值
{ "type": "call", "method": "addToCart", "params": { "id": "{{ product.id }}", "qty": 1 } }
// 数组位置参数——逐元素求值
{ "type": "call", "method": "calc", "params": ["{{ a }}", "{{ b }}"] }
resultTo 字段可以把方法返回值写回状态:{ type: 'call', method: 'fetchUser', resultTo: 'currentUser' } —— 这让你可以在纯 JSON 中编排异步数据流。
安全保护:
- 超时 5 秒(AbortController + Date.now 双重保护)
- 最大执行步数 10000 步
- 独立的错误类型层级:
VarioError → ActionError / ExpressionError / ServiceError / BatchError
- 18 个标准错误码(
ACTION_TIMEOUT、SERVICE_NOT_FOUND、EXPRESSION_UNSAFE_ACCESS 等)
Schema 和 methods 的刻意分离:
这里要说清楚一个设计边界——Schema 是"做什么"(纯数据,可序列化),methods 是"怎么做"(JS 函数,在代码库里,走 git 管理)。
{ type: 'call', method: 'addTodo' } 这条指令可以存进数据库、被 AI 生成、被服务端下发。但 addTodo 这个函数本身不在 Schema 里——它是你预先注册的业务代码。这不是缺陷,这是安全边界。 如果函数也能动态下发执行,等于在数据库里存了可执行代码,这是经典的安全漏洞。
六、表达式沙箱:Babel AST + 白名单 + 编译器 + LRU 缓存
在 Schema 里你可以写表达式:
{ "children": "Hello {{ name }}" }
{ "props": { "disabled": "{{ !(name && email) }}" } }
{ "cond": "{{ user.role === 'admin' }}" }
{ "children": "{{ items.filter(i => i.active).length }} 项激活" }
表达式引擎是整个 Core 里最大的模块(1,450 行),完整的处理流水线是:
"{{ user.name || 'Guest' }}"
↓ extractExpression()
"user.name || 'Guest'"
↓ getCachedExpression() → 命中? → 直接返回
↓ parseExpression() → @babel/parser
AST: LogicalExpression { left: MemberExpression, right: StringLiteral }
↓ validateAST() → 白名单逐节点检查
↓ compileSimpleExpression() → 简单表达式? → (ctx) => ctx._get("user.name") 快速路径
↓ evaluateExpression() → 复杂表达式? → AST 解释执行(682 行完整求值器)
↓ extractDependencies() + setCachedExpression() → LRU 缓存
→ "Alice"
白名单验证——逐 AST 节点检查
允许的(17 种节点类型):MemberExpression、OptionalMemberExpression、ArrayExpression、ObjectExpression、Identifier、BinaryExpression、LogicalExpression、UnaryExpression、ConditionalExpression、CallExpression、TemplateLiteral 等。
永久禁止的(10 种节点类型):AssignmentExpression(赋值)、ArrowFunctionExpression(箭头函数)、ThisExpression、NewExpression、AwaitExpression、ImportExpression、UpdateExpression(++/--)、YieldExpression、MetaProperty、SpreadElement。
函数调用安全模型:
- 白名单全局函数:
Math.*(abs/round/floor/ceil/random/max/min)、Array.isArray、Object.is、Number.isFinite/isInteger/isNaN、Date.now
- 数组实例方法:30 个安全方法(
filter/map/find/includes/slice/concat/join/sort/at 等),push/pop/splice 等修改型方法被排除
- 全局对象访问:
window/document/global/ globalThis/self 引用被永久阻止
- 危险属性:
constructor/prototype/__proto__ 访问被禁止
- 危险函数:
eval/Function/setTimeout/setInterval 被永久禁止
编译器——简单表达式的快速路径
对于 {{ count }}、{{ user.name }}、{{ 42 }} 这种简单表达式,不需要走完整的 AST 解释器。编译器会把它们直接编译为:
// {{ count }} → (ctx) => ctx._get("count")
// {{ user.name }} → (ctx) => ctx._get("user.name")
// {{ 42 }} → () => 42
这些编译后的函数缓存在 Map<string, CompiledExpression> 中,后续调用直接执行函数,跳过 AST 解析和解释,执行耗时 <1ms。
缓存系统——按上下文隔离的 LRU
WeakMap<RuntimeContext, Map<string, ExpressionCache>>
- 每个 RuntimeContext 有独立缓存,上下文被 GC 时缓存自动回收
- 最大 100 条,超限 LRU 淘汰
- 依赖驱动失效:
invalidateCache('user.name', ctx) 会遍历缓存,清除所有依赖链中包含 user.name 或 user.* 的条目
实际的 trade-off
要诚实面对:
- 你不能在
{{ }} 里写 (() => { ... })(),因为箭头函数被禁了
- 数组的修改型方法(
push/pop)不能在表达式里用,要搬到 Action 指令或 methods 里
- 没有 Formily 的
x-reactions 那种开箱即用的联动语法
这些限制是刻意的。 如果 Schema 是开发者手写的,限制确实增加了摩擦。但如果 Schema 来自数据库、AI 生成、用户可视化配置——白名单就是最后的安全防线。
七、Path Memo——让"1000 个节点只更新 1 个"成为可能
这是我在性能优化上投入最多的部分。Vario 提供 4 层可组合的渲染优化策略:
方案 A:Path Memo(默认启用)
核心思路:缓存每个路径的 VNode,下次渲染时判断依赖有没有变,没变直接返回缓存。
Schema 树 依赖追踪
─────────── ──────────
root [](无依赖,静态容器)
├── header [](纯静态)
├── form
│ ├── input[username] ["username"]
│ ├── input[email] ["email"]
│ └── submit-btn ["isValid"]
└── footer [](纯静态)
当 username 变化时:
→ input[username] → 依赖命中 → 重渲染
→ header/footer/email/submit-btn → 依赖未变 → 走缓存 ✅
哪些子树不能缓存:三个递归检测函数——hasExpressionInSubtree()、hasLoopInSubtree()、hasModelInSubtree()。任何含动态绑定的子树都跳过缓存。
缓存键由三部分组成:path + buildSchemaId(type|cond|show|loop|childrenLen) + buildDepsKey(condValue, showValue) ——确保同一路径在不同条件分支下不会返回错误的缓存。
方案 B:LoopItemAsComponent(循环场景推荐)
循环每项渲染为独立的 LoopItemCell 组件(82 行的 defineComponent),Vue 对 props 未变的组件自动跳过 re-render。
循环上下文通过 createLoopContext() 创建——使用 Object.create(parentCtx) 原型链继承,对象池复用(maxSize=10),finally 块确保归还。
方案 C:SubtreeComponent(大规模深嵌套场景)
每个 Schema 节点(或组件边界)渲染为 VarioNode 独立 Vue 组件(350 行),shouldComponentize() 根据粒度('all' 或 'boundary')和 maxDepth 决定哪些节点升级为组件。
方案 D:SchemaFragment(实验性,精确 Schema 更新)
不给整棵 Schema 树套一个大 reactive(),而是按路径碎片化存储:path → shallowReactive(node)。patch(path, partialNode) 只触发依赖该 path 的 Vue effect。
实测数据
| 场景 |
无优化 |
Path Memo |
加速 |
| 100 静态 + 1 动态 |
全量 |
只渲 1 个 |
88x |
| 复杂嵌套表单 |
基线 |
缓存命中 |
2-15x |
| 大表格单行更新 |
基线 |
精准行更新 |
4-29x |
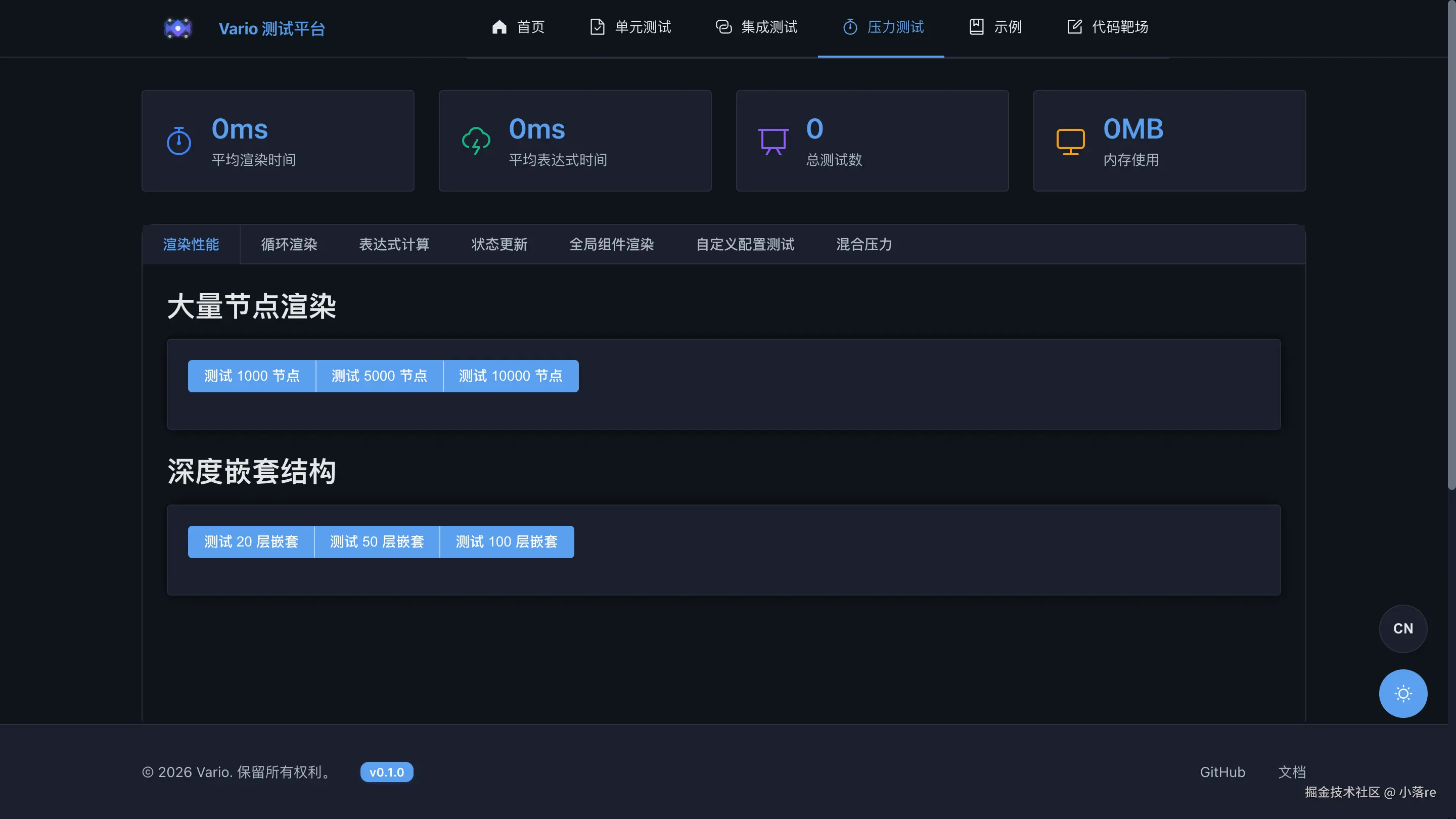
▲ 内置的性能测试仪表盘,可以对比开关各种优化策略的渲染耗时
八、Vue 开发者的上手成本——四种方案写同一个表单
这是 Vario 最在意的一件事:渐进式接入,对 Vue 开发者来说切换到 Schema 写法的心智负担应该尽可能低。
同一个表单,四种方案对比:
原生 Vue 3
<template>
<el-form label-width="100px">
<el-form-item label="姓名">
<el-input v-model="name" clearable />
</el-form-item>
<el-button @click.stop="submit" :disabled="!isValid">提交</el-button>
</el-form>
</template>
<script setup>
const name = ref('')
const isValid = computed(() => !!name.value)
const submit = () => { /* ... */ }
</script>
Formily
{
"type": "object",
"properties": {
"name": {
"type": "string",
"title": "姓名",
"x-decorator": "FormItem",
"x-component": "Input",
"x-component-props": { "clearable": true }
}
}
}
还需要 createForm()、FormProvider、SchemaField 等包裹层。组件名是 Formily 注册名(Input),不是 Element Plus 原生名。
amis
{
"type": "form",
"body": [
{ "type": "input-text", "name": "name", "label": "姓名" }
]
}
极简,但组件名是 amis 自己的类型系统(input-text)。
Vario
const { vnode, state } = useVario({
type: 'ElForm', props: { labelWidth: '100px' },
children: [
{
type: 'ElFormItem', props: { label: '姓名' },
children: [{ type: 'ElInput', model: 'name', props: { clearable: true } }]
},
{
type: 'ElButton',
props: { disabled: '{{ !isValid }}' },
events: { 'click.stop': [{ type: 'call', method: 'submit' }] },
children: '提交'
}
]
}, {
state: { name: '' },
computed: { isValid: (s) => !!s.name },
methods: { submit: ({ state }) => { /* ... */ } }
})
Vario 对齐了 Vue 的哪些概念:
| Vue 概念 |
Vario 对应 |
说明 |
v-model="name" |
model: 'name' |
一个字符串搞定 |
@click.stop.prevent |
events: { 'click.stop.prevent': [...] } |
点语法完全一致 |
ref="myInput" |
ref: 'myInput' |
模板引用同名 |
Element Plus ElInput
|
type: 'ElInput' |
直接用注册的组件名 |
:disabled="!isValid" |
props: { disabled: '{{ !isValid }}' } |
表达式换了个括号 |
computed |
computed: { isValid: (s) => ... } |
Options 风格函数 |
v-show |
show: '{{ condition }}' |
条件显示 |
v-if |
cond: '{{ condition }}' |
条件渲染 |
v-for |
loop: { items: '{{ list }}', itemKey: 'item' } |
循环渲染 |
provide/inject |
provide: {...} / inject: [...]
|
依赖注入 |
<Teleport> |
teleport: '#target' |
传送门 |
<Transition> |
transition: { name: 'fade' } |
过渡动画 |
<KeepAlive> |
keepAlive: true |
组件缓存 |
| 生命周期 |
onMounted: 'initMethod' |
6 个 Vue 生命周期钩子 |
useVario() 返回值 |
{ vnode, state, ctx, refs, error, stats, retry, find, findAll, findById } |
完整的 Composition API |
你只需要接受一个新概念:把模板写成 JS 对象。 其他所有东西——组件名、prop 名、事件名、修饰符——都跟你平时写 Vue 一模一样。
代价也要说清楚:
-
IDE 支持弱于
.vue 文件——只有类型提示,没有模板语法高亮和组件标签补全
-
比 amis 啰嗦——同样的表单 amis 4 行搞定
-
校验联动目前要手动实现——Formily 的
x-validator、x-reactions 是开箱即用的
九、为什么不直接用 h() 函数?
这个问题是理解 Vario 架构的关键。
Vue 的 h() 函数完全可以做到 Schema → VNode 的映射:
// h() 写法
const vnode = h('div', {}, [
h(ElInput, { modelValue: state.name, 'onUpdate:modelValue': v => state.name = v }),
h(ElButton, { onClick: () => submit() }, '提交')
])
渲染结果完全一样。h() 更直接,TypeScript 支持更好(完整的 prop 类型推导),性能也更好(少了一层解析)。
那 Schema 多这一层解析换来了什么?
答案是:h() 是代码,Schema 是数据。
|
h() 函数 |
Schema 对象 |
| 本质 |
函数调用——指令
|
普通 JS 对象——描述
|
能否 JSON.stringify
|
❌ 函数不可序列化 |
✅ 纯 JSON |
| 静态分析 |
❌ 必须执行才知道结构 |
✅ 不执行就能遍历、验证、转换 |
| AI 生成 |
⚠️ 要生成合法 JS |
✅ 生成 JSON,格式可约束 |
| 运行时增量修改 |
⚠️ 重新组装函数 |
✅ SchemaStore.patch('children.0.props', { disabled: true })
|
| 路径级缓存 |
❌ 每次全量重执行 |
✅ Path Memo 跳过未变子树 |
| 存数据库 / 服务端下发 |
❌ 不能下发代码 |
✅ 下发 JSON |
| 查询 / 检索 |
❌ 无法对函数调用做 findById |
✅ find(n => n.type === 'ElInput') 查询引擎 |
如果你的 Schema 永远只在 .ts 文件里手写,那 h() 确实更直接。 但如果 Schema 来自数据库、来自 AI 生成、来自可视化配置后台——"数据 vs 代码"的区别就是一切。
Path Memo、SchemaStore.patch、QueryEngine、Schema 验证器——这些能力全都依赖于"Schema 是数据"这个基础假设。
十、AI + Schema:为什么这个架构天然适合 AI 时代
这是我做 Vario 最深层的动机,也是我认为它最大的潜力所在。
现在 AI 生成代码已经很成熟了。但你让 AI 生成一个完整的 Vue SFC——template、script、style——它经常会出错:import 写错、ref 和 reactive 混淆、生命周期用错地方、组件名不存在……
但如果让 AI 生成的不是代码,而是 JSON 呢?
{
"type": "ElCard",
"children": [
{ "type": "ElInput", "model": "keyword", "props": { "placeholder": "搜索..." } },
{
"type": "div",
"loop": { "items": "{{ results }}", "itemKey": "item" },
"children": [{ "type": "span", "children": "{{ item.title }}" }]
}
]
}
这个 JSON:
-
格式可约束——你可以给 AI 一个 SchemaNode 的类型定义,生成结果一定符合格式
-
可校验——
validateSchema() 会对每个节点做结构验证 + 表达式 AST 白名单校验,不存在的组件类型、非法表达式都会被捕获
-
安全——即使这个 JSON 来自用户对话、来自远程接口,AST 白名单保证它不能执行
eval()、不能访问 window、不能 import() 动态加载
-
可增量修改——AI 不需要每次重新生成整个 UI,通过
SchemaStore.patch(path, partialNode) 做外科手术式更新,只触发依赖该 path 的 Vue effect
你可以想象这样一个工作流:
用户说:「帮我做一个商品搜索页面」
↓
AI 生成一份 Schema JSON
↓
validateSchema() 验证结构和表达式安全性
↓
Vario 运行时直接渲染
↓
用户说:「把搜索结果改成卡片布局」
↓
AI 生成一个 patch(只修改 layout 相关的节点)
↓
SchemaStore.patch() 增量更新,只有受影响的 VNode 重渲染
这个工作流中,AI 从头到尾不需要生成一行 JavaScript——它只生成 JSON 结构和指令序列。业务逻辑函数(methods)是人预先注册好的,AI 通过 { type: 'call', method: 'search' } 去调用。
方法层扮演的角色类似于 AI Agent 的 "Tools"——预定义好的能力接口,AI 只负责编排调用顺序和参数。
十一、竞品横向对比
做之前我认真看了现有的方案。这里不是要说"我比他们好"——他们是大厂几百人维护了好几年的项目,我一个人做的东西没资格这样说。但设计选择确实不同,值得讨论。
| 维度 |
Vario |
Formily(阿里) |
amis(百度) |
| GitHub Stars |
新项目 |
12.6k ⭐ |
18.8k ⭐ |
| 贡献者 |
个人 |
207 |
266 |
| 定位 |
Schema 渲染运行时 |
Schema Form 引擎 |
低代码平台 |
| 组件名 |
Vue 原生组件名 |
Formily 注册名 |
amis 类型系统 |
| 接入方式 |
渐进式(单页可用) |
需包裹 Provider |
All-in-one |
| 表单校验 |
手动 |
内置 x-validator |
内置 |
| 表达式 |
AST 白名单沙箱 |
reaction 副作用 |
公式引擎 |
| 动作模型 |
13 指令正交组合 |
x-reactions |
60+ actionType |
| 渲染优化 |
4 层可组合优化 |
React/Vue 各自机制 |
内部优化 |
| Schema 可序列化 |
✅ 纯 JSON |
✅ 基本支持 |
✅ 纯 JSON |
| Bundle 大小 |
轻量 |
中等 |
≈2MB |
| 适合谁 |
搭平台的技术团队 |
复杂表单场景 |
快速交付内部工具 |
如果你要做复杂表单,Formily 的 x-validator + x-reactions 开箱即用,比 Vario 省力得多。选 Formily。
如果你要快速交付内部运营工具,amis 的 4 行 JSON 出页面是真实的生产力。选 amis。
如果你要在自己的项目里引入 Schema 驱动能力、保持对技术栈的完全控制、或者在构建一个低代码平台需要底层渲染引擎——Vario 提供的是一个干净的、可嵌入的运行时。
十二、测试与质量
┌──────────────────────────────────────────────────────┐
│ Test Files 50 passed (50) │
│ Tests 579 passed (579) │
│ 跨 5 个包:types / core / schema / vue / cli │
│ 含 3 个集成测试文件(core↔schema / schema↔vm / vue↔element-plus)│
│ 性能基准测试覆盖 4 种优化策略对比 │
└──────────────────────────────────────────────────────┘
集成测试覆盖了三层的打通:
// basic-integration.test.ts — core 和 schema 能协作
const view = defineSchema({ state: { count: 0 }, schema() { return { type: 'div', children: [] } } })
const ctx = createRuntimeContext(view.stateType)
expect(ctx.count).toBe(0)
// schema-vm-integration.test.ts — Schema 中定义的 Action 能被 VM 执行
const instructions = view.schema.events?.click || []
await execute(instructions, ctx)
expect(ctx.count).toBe(1)
// vue-element-plus.test.ts — Vue 渲染器能正确处理 Element Plus 组件
const renderer = new VueRenderer()
const vnode = renderer.render(view.schema, ctx)
expect(vnode.props.modelValue).toBeDefined()
expect(vnode.props['onUpdate:modelValue']).toBeDefined()
十三、Demo 展示
 ▲ play 演示站首页
▲ play 演示站首页
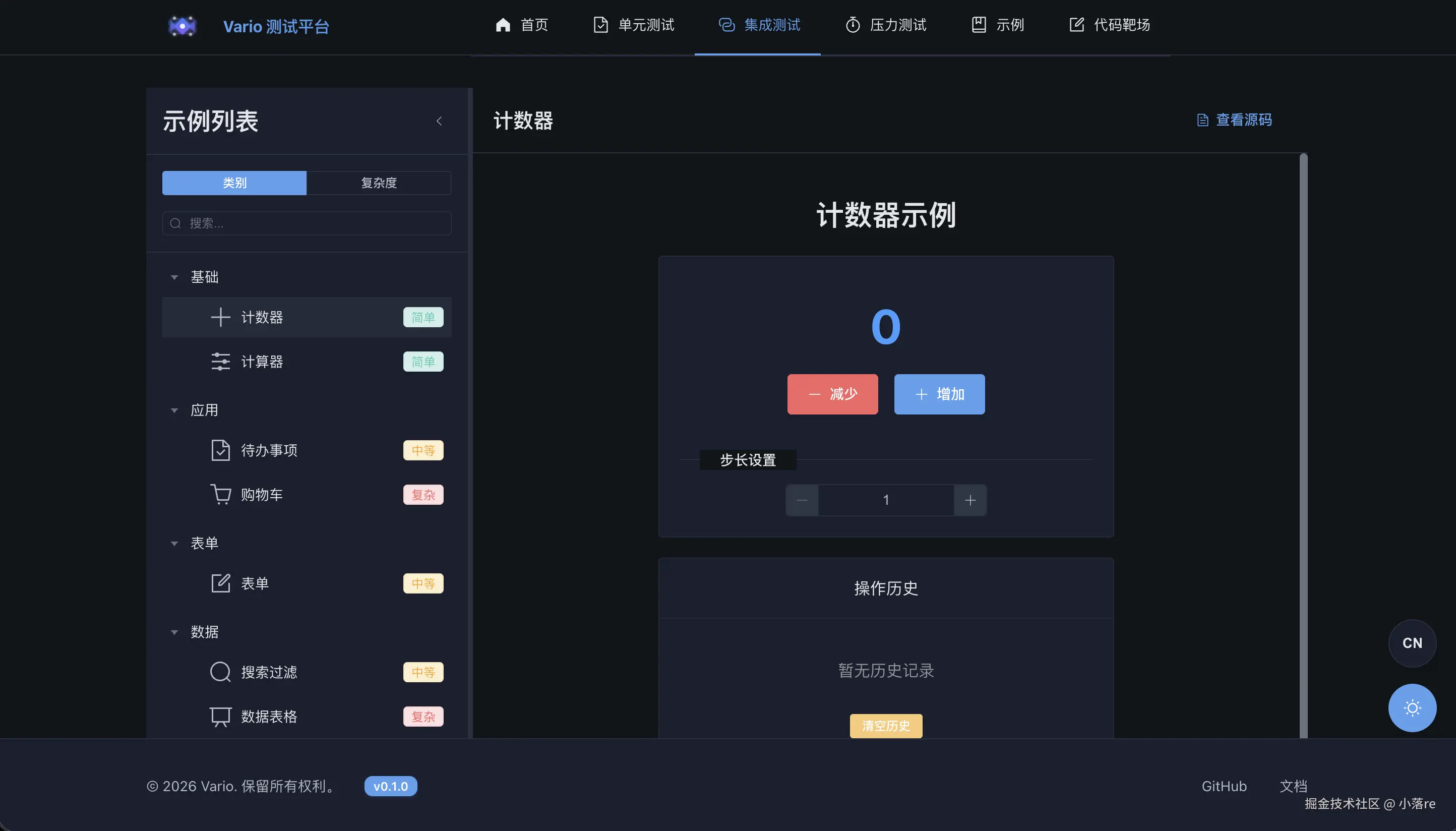 ▲ 内置了 Todo App、购物车、搜索过滤、表单、ECharts 图表等完整示例,每个示例可切换"预览"和"Schema JSON"视图
▲ 内置了 Todo App、购物车、搜索过滤、表单、ECharts 图表等完整示例,每个示例可切换"预览"和"Schema JSON"视图
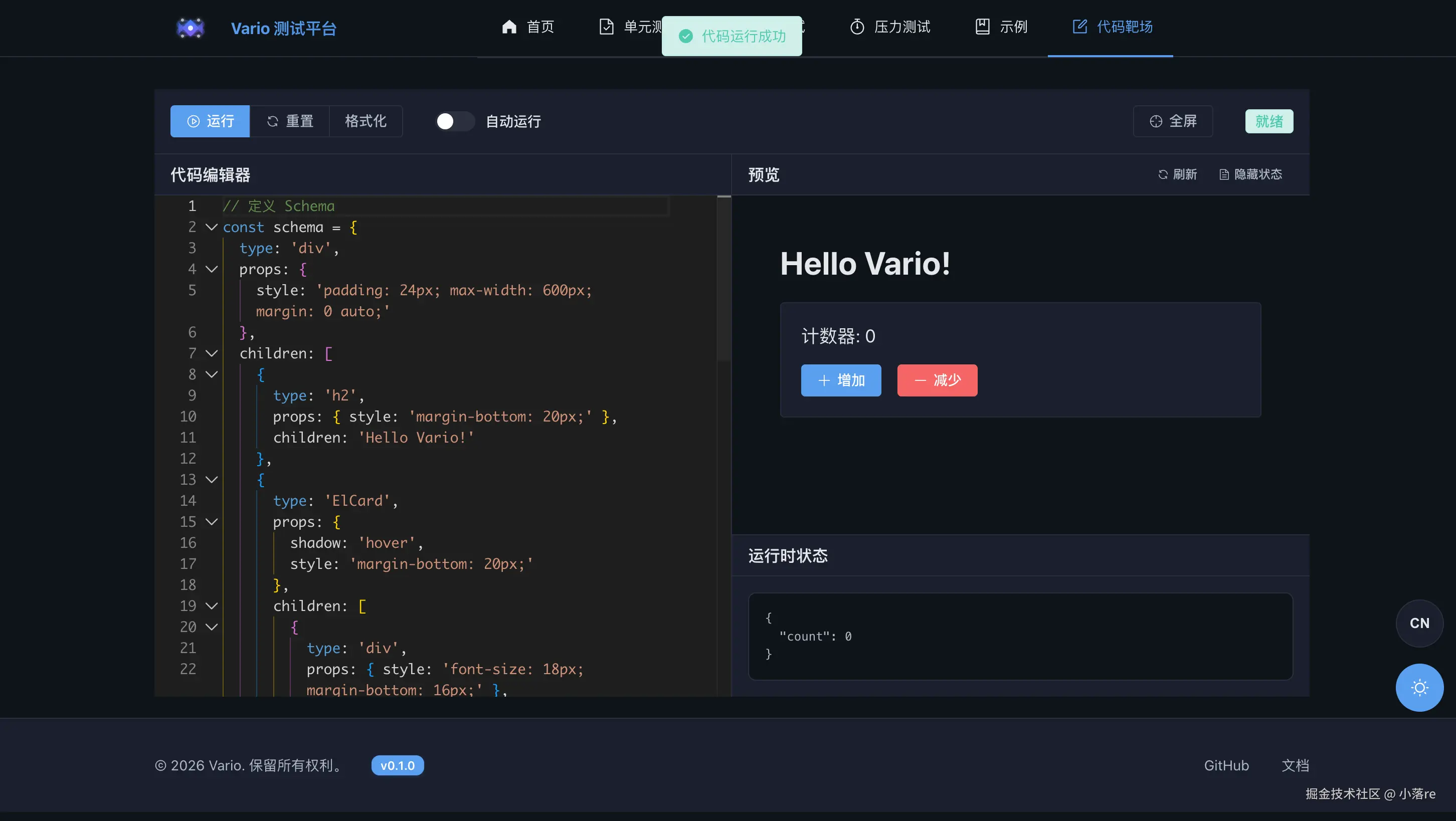
▲ 代码靶场——浏览器里直接编辑 Schema,实时预览渲染结果

▲ 独立的文档站(VitePress),覆盖 API 文档、架构说明、表达式语法、性能调优指南
十四、自问自答——预判你心里可能已经有的问题
Q1:Schema 驱动和"把 template 写成 JSON"有什么本质区别?如果只是换了个语法糖,那工程价值在哪?
这是最核心的问题。如果 Schema 只是 template 的另一种写法,那确实没有意义——反而丢掉了 SFC 的 IDE 支持、语法高亮、组件类型推导。
区别在于 Schema 是可操作的数据,template 是编译后消失的 DSL。
Vue 的 <template> 经过编译器后变成 render function,在运行时你拿不到"这里有一个 <ElInput>,它的 model 绑定到 name"这个结构信息了。但 Schema 始终存在于内存里,你可以在运行时做这些事:
-
findAll(n => n.model) ——找出所有有双向绑定的节点,自动生成表单校验规则
-
patch('children.2.props', { disabled: true }) ——服务端推送一条消息就能禁用某个按钮
-
analyzeSchema() → { nodeCount: 234, maxDepth: 8 } ——统计 Schema 复杂度,自动决定启用哪种优化策略
-
JSON.stringify(schema) → 存 DB → 下次 JSON.parse() → 直接渲染 ——零代码生成,零编译
这不是"换了个语法糖",这是从"编译时产物"变成了"运行时一等公民"的根本转变。
Q2:表达式白名单会不会过于严格?实际项目中遇到需要写复杂逻辑的表达式怎么办?
会。你不能在表达式里写 items.sort((a, b) => a.price - b.price),因为箭头函数被禁了。
设计意图是"表达式只做读取和条件判断,逻辑在 methods 和 computed 里"。 这意味着你需要:
// 不能这样写
{ children: '{{ items.sort((a, b) => a.price - b.price) }}' }
// 要这样写
computed: { sortedItems: (s) => [...s.items].sort((a, b) => a.price - b.price) }
// Schema 里用 {{ sortedItems }}
这多了一步,但换来的是:表达式永远是"安全的只读求值",不需要人工 review 每个 {{ }} 里写了什么。对于 Schema 来源不可信的场景(AI 生成、用户配置),这是刚性需求。
对于开发者手写 Schema 的场景,这确实增加了摩擦。如果你 100% 确定 Schema 只会出现在你的代码仓库里,白名单的安全价值就不那么明显了。这是一个架构赌注,赌的是 Schema 将来会来自更多来源。
Q3:双向绑定的"三重锁"是怎么被消灭的?
早期版本中,useVario 靠三把布尔锁(syncing / syncingPaths / watchSyncing)在 RuntimeContext 和 Vue reactive 之间做双向同步。能跑,但本质是 hack——三把锁意味着有三种循环路径需要手动屏蔽。
问题的根因不是"锁不够精确",而是存在两份状态本身就是错误。Core 的 RuntimeContext 维护一份 plain object,Vue 维护一份 reactive(),任何一侧修改都要同步到另一侧——这就是经典的"双写一致性"问题,在分布式系统里也没有优雅解法。
唯一真正优雅的方案是:消灭第二份状态。
受 Zustand 启发(一个 store 接口 + 各框架各自适配),当前版本引入了 ReactiveAdapter 协议,已经在源码中实现并通过全部 590 个测试:
// @variojs/types/src/runtime.ts — 真实代码
export interface ReactiveAdapter {
get(path: string): unknown // 路径读取('user.name')
set(path: string, value: unknown): void // 路径写入
getProperty(key: string): unknown // 顶层属性读(Proxy get trap)
setProperty(key: string, value: unknown): void // 顶层属性写(Proxy set trap)
has(key: string): boolean // 属性存在检查(Proxy has trap)
keys(): string[] // 所有 key(Proxy ownKeys trap)
}
改动涉及 5 个文件,核心变化:
1. @variojs/core 的 createRuntimeContext 接受可选 adapter 参数。当 adapter 存在时:
-
_get(path) → adapter.get(path),直接从 Vue reactive 读
-
_set(path, value) → adapter.set(path, value),直接写入 Vue reactive
- 初始状态不拷贝到 ctx 对象上(
adapter ? {} : initialState)
2. @variojs/core 的 Proxy 5 个 trap 全部路由到 adapter:
-
get → adapter.getProperty(key)
-
set → adapter.setProperty(key, value)
-
has → adapter.has(key)
-
ownKeys → 合并 adapter.keys() 与系统 API keys
-
getOwnPropertyDescriptor → 为 adapter 管理的 key 返回正确的描述符
3. @variojs/vue 的 createVueReactiveAdapter 将 Vue reactive() 对象适配为协议:
// packages/vario-vue/src/adapter.ts — 真实代码
export function createVueReactiveAdapter<TState extends Record<string, unknown>>(
state: TState
): ReactiveAdapter {
return {
get: (path) => getPathValue(state, path),
set: (path, value) => setPathValue(state, path, value, {
createObject: () => reactive({}),
createArray: () => reactive([]),
createIntermediate: true
}),
getProperty: (key) => state[key],
setProperty: (key, value) => { state[key] = value },
has: (key) => key in state,
keys: () => Object.keys(state)
}
}
4. useVario 从 636 行减至 570 行,删除了:
- 3 个同步锁变量(
syncing / syncingPaths / watchSyncing)
-
onStateChange 中 20 行的 setPathValue 同步逻辑
-
watch(reactiveState) 中 20 行的 syncStateToContext 反向同步
-
syncStateToContext() 函数本身(16 行 + 深度比较)
- 初始状态拷贝循环(5 行)
替换后的 onStateChange 只有 4 行——缓存失效 + 渲染调度:
onStateChange: (path, _value, runtimeCtx) => {
invalidateCache(path, runtimeCtx)
scheduleRender()
}
数据流变化:
重构前:ctx._set('x', 1) → 写入 ctx 内部 → onStateChange → setPathValue(reactive) → 触发 watch → 🔒 被锁拦截
重构后:ctx._set('x', 1) → adapter.set('x', 1) → 直接写入 reactive → onStateChange → invalidateCache + scheduleRender → 完毕
向后兼容: 当不传 adapter 时,行为与旧版完全一致——所有 153 个 Core 测试无需修改。adapter 是纯增量,不是 breaking change。
额外收益: 这个协议直接为 React Renderer 铺路(见 Q7)。React 侧只需实现一个基于不可变快照的 ReactReactiveAdapter,Core 层完全不用动。
Q4:Schema 存数据库之后,版本迁移怎么办?老版本的 Schema 在新版本的渲染引擎上能跑吗?
这是一个真实的工程问题,而且 Vario 目前没有完整的答案。
Schema 的结构由 SchemaNode 接口定义,这是一个 readonly 接口。新版本如果加了新字段(比如已经有的 transition、keepAlive),老 Schema 没有这些字段,渲染器会按默认值处理,通常不会挂。
但如果某个字段的语义变了(比如 model 从只支持字符串变成支持 { path, scope, default, modifiers } 对象),normalizeSchemaNode() 需要处理兼容性转换。当前的规范化器已经在做这件事——它处理字符串 model 和对象 model 两种形态,统一为标准格式。
真正危险的是 Action 指令集的变更。 如果某个指令的参数结构变了,存在数据库里的 Schema 中引用的旧格式指令就会执行出错。Action VM 的错误保护(超时、步数限制、类型化错误码)可以兜底不让程序崩溃,但业务逻辑会失效。
长期来看,需要的是一个 Schema 版本号 + 迁移脚本的机制(类似数据库 migration),但这目前还在规划中。
Q5:你自己在实际项目中用 Vario 了吗?踩过什么真实的坑?
用了。Vario 最初就是从实际的低代码平台项目中抽出来的。踩过的最大的坑是 model 路径在嵌套循环中的解析。
考虑这个场景:
{
"loop": { "items": "{{ categories }}", "itemKey": "cat" },
"children": [{
"loop": { "items": "{{ cat.products }}", "itemKey": "product" },
"children": [{
"type": "ElInput",
"model": "product.name"
}]
}]
}
product.name 需要解析为 categories.0.products.2.name 这样的绝对路径,才能正确写回状态。这需要一个路径栈(modelPathStack),每层循环压一层,每次解析 model 路径时从栈顶开始拼接。
ModelPathResolver 的 228 行代码大部分在处理这个问题的各种边界情况:"." 表示当前路径栈(循环项是基本类型时绑定自身)、$item 动态解析、-1 索引(动态数组追加)、表达式内嵌的 model 路径(model: '{{ dynamicField }}')。
vario-vue 有 750 行专门测试 model 路径解析的测试用例(model-path-comprehensive.test.ts),这是项目里最长的单个测试文件。
Q6:对比大厂的 Formily 和 amis,你一个人做的项目,凭什么让别人用?
这个问题的诚实答案是:如果有人问"我要选一个做生产项目用",我没有立场推荐 Vario 而不推荐 Formily。
Formily 有 207 位贡献者、多年的生产环境打磨、完整的表单验证/联动生态。amis 有百度内部大量业务场景验证、几百个内置组件类型。这些是个人项目无法比拟的。
Vario 的价值不在于"比他们好",而在于:
-
不同的抽象层次——Formily 是"表单引擎",amis 是"低代码平台",Vario 是"渲染运行时"。如果你要自己搭平台、自己做编辑器,你需要的是运行时这一层,而不是一个成品平台。
-
完全的控制权——Vario 不绑定任何组件库、不内置任何业务组件,你的组件就是你的。amis 接受就要全盘接受它的组件体系。
-
作为学习和参考——从零造一个 Schema 渲染引擎的过程中,我理解了为什么 Formily 要那样设计 x-reactions、为什么 amis 要搞 60+ 种 actionType。这个过程本身就值得分享。
如果你在选型——评估你的场景,做表单选 Formily,做内部工具选 amis,做平台底座或者想深入理解这个领域,来看看 Vario。
Q7:如果 Core 层零 Vue 依赖,那 React Renderer 真的能做出来吗?代价是什么?
架构上已经预留了。Core 层的所有 API——createRuntimeContext()、execute()、evaluate()——不依赖任何 UI 框架。但上一版的回答太保守了,只列了"React 缺什么"。深入想之后,我认为这件事比"能做但体验差"要更乐观。
VNode 创建层——映射是直接的:
Vue 的 h() 和 React 的 createElement() 在 API 层面几乎同构:
// Vue
h('div', { class: 'box', onClick: handler }, [h('span', {}, 'text')])
// React
createElement('div', { className: 'box', onClick: handler }, createElement('span', {}, 'text'))
差异只在属性名(class → className、for → htmlFor、事件名大小写),用一个 20 行的 prop adapter 就能搞定。当前 VueRenderer 的 638 行代码中,真正 Vue 特有的与其说是 h() 调用,不如说是围绕 h() 的那些 Vue 特性包裹(Teleport / Transition / KeepAlive / v-show / withDirectives)。
Vue 特性的 React 对应物——比想象中完整:
| Vue 特性 |
React 对应 |
实现复杂度 |
h() |
createElement() |
低(prop 名映射) |
Teleport |
ReactDOM.createPortal() |
低(API 对等) |
Transition |
react-transition-group 或 Framer Motion |
中(API 不同但能力对等) |
KeepAlive |
无原生等价物 |
高(需手动 display:none + 状态缓存,或用 react-activation) |
v-show |
style={{ display: 'none' }} |
低(trivial) |
v-model |
value + onChange
|
低(React 反而更简单,不需要 onUpdate:modelValue 这种协议) |
withDirectives |
无等价物 |
高(需要自实 ref callback pattern) |
provide/inject |
React.createContext + useContext
|
中(概念对等,API 不同) |
真正的难题不在 API 映射,在状态同步——而 Q3 的 ReactiveAdapter 已经落地解决了这个问题。
Core 的 createRuntimeContext 现在接受 ReactiveAdapter 参数。Vue 侧的 createVueReactiveAdapter 已经证明了这个协议的可行性(590 个测试全部通过)。React 侧只需实现同一接口的不可变快照版本:
function createReactAdapter<T>(initialState: T): ReactiveAdapter & { getSnapshot: () => T, subscribe: (l: () => void) => () => void } {
let state = structuredClone(initialState)
const listeners = new Set<() => void>()
return {
get: (path) => getPathValue(state, path),
set: (path, value) => {
// 不可变更新——新引用触发 React re-render
state = produce(state, draft => { setPathValue(draft, path, value) })
listeners.forEach(l => l())
},
getProperty: (key) => state[key],
setProperty: (key, value) => {
state = { ...state, [key]: value }
listeners.forEach(l => l())
},
has: (key) => key in state,
keys: () => Object.keys(state),
subscribe: (listener) => {
listeners.add(listener)
return () => listeners.delete(listener)
},
getSnapshot: () => state
}
}
React 侧的 useVario Hook:
function useVario(schema, options) {
const adapter = useMemo(() => createReactAdapter(options.state), [])
const state = useSyncExternalStore(adapter.subscribe, adapter.getSnapshot)
const ctx = useMemo(() => createRuntimeContext({}, { adapter }), [adapter])
return useMemo(() => {
const renderer = new ReactRenderer()
return renderer.render(schema, ctx)
}, [schema, state]) // state 引用变化时触发重渲染
}
注意 createReactAdapter 实现的 get/set/getProperty/setProperty/has/keys 与 Vue 侧的 createVueReactiveAdapter 签名完全一致——因为它们实现的是同一个 ReactiveAdapter 接口。差异只在实现策略:Vue 用可变 reactive proxy,React 用不可变快照 + useSyncExternalStore。
useSyncExternalStore(React 18+)是关键。 它是 React 官方提供的"外部状态 → React 渲染"的标准桥接方案,不需要 deep reactive proxy,也不需要 useEffect + 手动 diff。每次 set() 产生新的不可变快照,useSyncExternalStore 检测到引用变化,触发组件 re-render。
这里借鉴了 Zustand 的核心设计:store 是外部的,React 通过 useSyncExternalStore 订阅。但 Zustand 的 store 是用户手写的,Vario 的 store 是 RuntimeContext——由 Schema 驱动、Action VM 修改。
我现在的判断是:React Renderer 的工程量大约是 Vue Renderer 的 60%——不是因为 React 比 Vue 简单,而是因为 React 不需要三重锁。 Vue 的 deep reactive 带来了自动依赖追踪的便利,但也引入了双向同步的复杂度;React 的不可变模型虽然需要多写 immutable update,但状态流向是单向的——不存在回声问题。
具体的实施路线:
-
第一步:从 Core 中抽取
RendererProtocol 接口(createElement / createFragment / createPortal / wrapTransition),让 VueRenderer 和 ReactRenderer 都实现同一接口
-
第二步:实现
ReactReactiveAdapter,基于 useSyncExternalStore + 不可变快照
-
第三步:实现
ReactRenderer 基础版(createElement + 事件 + model 绑定),跳过 KeepAlive / Directive
-
第四步:补齐 Transition(react-transition-group)和 KeepAlive(react-activation 或自实现)
最大的技术风险不是"能不能做",而是性能。Vue 的 watch(state, { deep: true }) 可以精确知道哪个 path 变了(配合 Path Memo 做精准跳过),React 的不可变快照每次都是完整引用比较。在大规模 Schema(1000+ 节点)下,React 的渲染粒度控制可能不如 Vue fine-grained。这需要实际 benchmark 验证——理论推演到这一步就到极限了。
十五、欢迎参与
Vario 目前已开源,文档和示例都比较完整。但一个人做的项目终归有视野和精力的局限。如果你对 Schema 驱动 UI、AI + 低代码、渲染引擎设计这些方向感兴趣,非常欢迎参与:
🔧 提 Issue
- 发现 bug?Schema 验证/表达式引擎/双向绑定/循环渲染——任何场景的问题都欢迎报告
- 有功能建议?比如新增白名单函数、新的 Action 指令类型、更好的错误提示
- 文档不清楚的地方?告诉我哪里看不懂
🚀 提 Pull Request
-
Good First Issues 适合初次贡献
- 新的 Action 指令处理器(在
packages/vario-core/src/vm/handlers/ 下添加)
- 新的表达式白名单函数(在
packages/vario-core/src/expression/whitelist.ts 中注册)
- play 示例(在
play/src/examples/ 下添加 .vario.ts 文件)
- 文档改进(在
docs/ 下修改 Markdown)
- React Renderer(这是最大的待做项)
💬 参与讨论
- 架构决策讨论——比如"表达式白名单应不应该开放
.sort() 带回调的用法?"
- 性能优化方向——比如"SchemaFragment 方案的 API 应该怎么设计?"
- AI 集成方案——比如"怎么为 Schema 生成约束 AI 的 JSON Schema 定义文件?"
git clone https://github.com/YuluoY/vario.git
cd vario
pnpm install
pnpm start # 构建 + 启动 play(:5173) 和 docs(:5174)
pnpm test # 跑一遍 579 个测试,确认环境正常
GitHub:github.com/YuluoY/vari…
在线演示:yuluoy.github.io/vario/
文档:yuluoy.github.io/vario/docs/
5 分钟快速上手
pnpm add @variojs/vue @variojs/core @variojs/schema
<template>
<component :is="vnode" />
</template>
<script setup>
import { useVario } from '@variojs/vue'
const { vnode, state } = useVario({
type: 'div',
children: [
{ type: 'input', model: 'name', props: { placeholder: '你的名字' } },
{ type: 'p', children: 'Hello {{ name }}!' }
]
}, {
state: { name: '' }
})
</script>
就这样。没有 Provider,没有额外的 store,没有新的模板语法——Schema 即 UI,状态即数据。
更多文章