从原子CSS到TailwindCSS:现代前端样式解决方案全解析
引言
在长期的前端开发中,我们经常面临这样的困扰:
- 写了一个按钮样式,想在另一个地方复用,却发现类名冲突、样式覆盖难以维护。
- 为了一个细微的样式调整,不得不新建一个CSS类,导致CSS文件迅速膨胀。
- 在HTML和CSS文件之间来回切换,打断开发心流。
- 响应式设计需要写多套媒体查询,代码臃肿。
直到我遇到了原子CSS(Atomic CSS)和它的集大成者——TailwindCSS,这些问题迎刃而解。本文将结合代码实例,带你从零开始,循序渐进地掌握TailwindCSS,理解它的设计哲学,并能在实际项目中熟练运用。
第一章 从传统CSS到原子CSS——思想演变
1.1 传统CSS的痛点
回顾我们早期的写法(参考 1.html 中的注释部分):
<style>
.primary-btn {
padding: 8px 16px;
background: blue;
color: white;
border-radius: 6px;
}
.default-btn {
padding: 8px 16px;
background: #ccc;
color: #000;
border-radius: 6px;
}
</style>
<button class="primary-btn">提交</button>
<button class="default-btn">默认</button>
效果图
 每个类都包含了大量的样式规则,虽然可以工作,但存在明显的缺点:
每个类都包含了大量的样式规则,虽然可以工作,但存在明显的缺点:
-
样式冗余:
.primary-btn 和 .default-btn 都定义了相同的 padding 和 border-radius,重复代码。
-
难以复用:假如我想实现一个带圆角的卡片,无法直接使用
.primary-btn,必须新建类。
-
命名困难:类名需要反映用途,随着项目变大,命名变得困难且容易冲突。
1.2 面向对象的CSS(OOCSS)思想
OOCSS 提倡将可复用的样式拆分成独立的“基类”,再通过组合的方式实现具体样式(参考 1.html 中的改进部分):
<style>
.btn {
padding: 8px 16px;
border-radius: 6px;
cursor: pointer;
}
.btn-primary {
background: blue;
color: white;
}
.btn-default {
background: #ccc;
color: #000;
}
</style>
<button class="btn btn-primary">提交</button>
<button class="btn btn-default">默认</button>
效果图
这里 .btn 封装了按钮的基础样式(内边距、圆角、指针),.btn-primary 和 .btn-default 只负责颜色主题的变化。这种“组合类”的方式,就是原子CSS的雏形。
1.3 原子CSS的诞生
原子CSS将每一个独立的样式属性(如 padding: 8px 16px、color: white)都拆分成一个单独的类,开发者通过组合这些类来构建界面。例如:
<button class="p-2 bg-blue-500 text-white rounded">提交</button>
这就是TailwindCSS的写法。它的优点显而易见:
-
高度复用:所有类都是单一职责,可以在任何地方组合。
-
无需命名:不用再苦思冥想类名,直接用功能类描述样式。
-
可预测:类名和样式一一对应,没有副作用。
-
易于维护:修改样式只需调整HTML中的类名,无需修改CSS文件。
第二章 快速搭建TailwindCSS开发环境
TailwindCSS 可以集成到任何前端项目中。这里我们以 Vite + React 为例,演示如何搭建环境。
2.1 创建项目
npm create vite@latest tailwind-demo -- --template react
cd tailwind-demo
npm install
2.2 安装TailwindCSS及相关插件
根据官方文档,我们需要安装 tailwindcss、@tailwindcss/vite 插件以及 postcss(Vite 已内置支持):
npm install tailwindcss @tailwindcss/vite
2.3 配置Vite插件
修改 vite.config.js(参考你提供的文件):
import { defineConfig } from 'vite'
import react from '@vitejs/plugin-react'
import tailwindcss from '@tailwindcss/vite'
export default defineConfig({
plugins: [
react(),
tailwindcss(),
],
})
2.4 引入TailwindCSS
在项目的主CSS文件(如 index.css)中,只需要一行代码:
@import 'tailwindcss';
TailwindCSS 会自动注入所有基础样式和工具类。
2.5 验证环境
修改 App.jsx,写入一些Tailwind类:
export default function App() {
return (
<div className="text-center p-4 text-blue-600">
Hello TailwindCSS!
</div>
)
}
运行 npm run dev,如果看到蓝色居中文字,说明环境搭建成功。
效果图

第三章 基础实用工具类(Utilities)
TailwindCSS 提供了数千个实用类,覆盖了 CSS 的方方面面。我们通过一个按钮和卡片示例来快速掌握最常用的类。
3.1 盒模型与排版
参考 我的代码中App2.jsx 中的按钮:
<button className="px-4 py-2 bg-blue-600 text-white rounded-md hover:bg-blue-700">
提交
</button>
-
内边距:
px-4 表示左右内边距为 1rem(默认单位),py-2 表示上下内边距为 0.5rem。
-
背景色:
bg-blue-600 使用预定义的蓝色色阶。
-
文字颜色:
text-white 白色文字。
-
圆角:
rounded-md 中等圆角。
-
悬停效果:
hover:bg-blue-700 表示鼠标悬停时背景色变深。
3.2 字体与尺寸
另一个按钮示例:
<button className="px-4 py-2 bg-gray-300 text-black rounded-md hover:bg-gray-400">
默认
</button>
-
bg-gray-300、text-black 控制背景和文字颜色。
- 字体大小可以通过
text-sm、text-lg 等控制,权重用 font-bold。
3.3 卡片组件演示
再看一个文章卡片(来自 App2.jsx 中的 ArticleCard):
const ArticleCard = () => {
return (
<div className="p-4 bg-white rounded-xl shadow hover:shadow-lg transition">
<h2 className="text-lg font-bold">Tailwindcss</h2>
<p className="text-gray-500 mt-2">
用utility class快速构建UI
</p>
</div>
)
}
-
shadow 添加默认阴影,hover:shadow-lg 悬停时阴影变大,transition 让变化平滑。
-
mt-2 添加上边距。
- 整体卡片通过组合类快速实现,完全不需要写一行自定义CSS。
效果图

第四章 布局利器——Flexbox与Grid
Tailwind 提供了完备的 Flexbox 和 Grid 工具类,可以轻松构建各种布局。
4.1 Flex 基础
看 App.jsx 中的响应式布局示例:
<div className="flex flex-col md:flex-row gap-4">
<main className="bg-blue-100 p-4 md:w-2/3">主内容</main>
<aside className="bg-green-100 p-4 md:w-1/3">侧边栏</aside>
</div>
-
flex 开启 Flex 布局。
-
flex-col 设置主轴方向为列(垂直排列),默认是 flex-row。
-
gap-4 设置子元素之间的间距。
-
md:flex-row 表示在中等屏幕以上(≥768px)时改为行排列。
-
md:w-2/3 和 md:w-1/3 分别设置宽度为父容器的 2/3 和 1/3。
4.2 深入理解移动优先(Mobile First)设计
细心的读者可能会问:为什么没有 md: 前缀时,布局是垂直的?这正是 Tailwind 移动优先设计思想的体现。
在移动优先的策略下,所有不带断点前缀的实用类默认应用于所有屏幕尺寸,即从最小屏开始生效。然后通过 sm:、md:、lg: 等带前缀的类在更大的屏幕上去覆盖或添加样式。
去除md效果图

当我们把浏览器界面模式切换成moblie形式时
- 不清楚的点击按F12然后点击这个按钮

- 效果图
 我们可以看到此时又
我们可以看到此时又
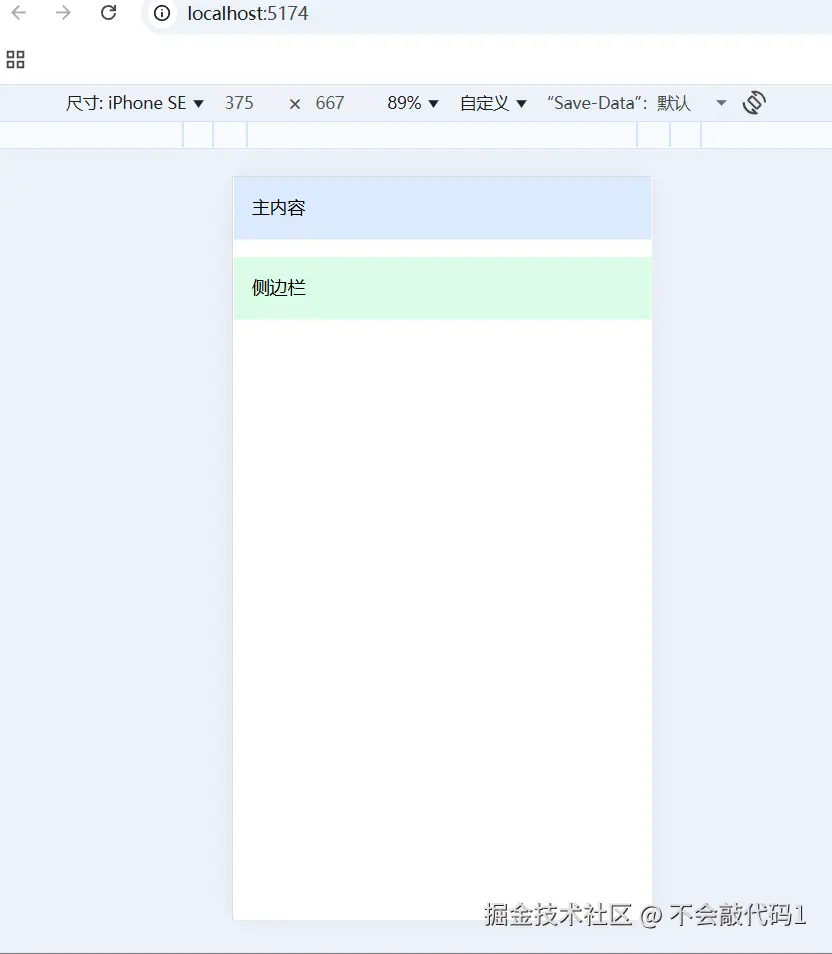
加上md效果图

当我们把浏览器界面模式切换成moblie形式时
- 不清楚的点击按F12然后点击这个按钮
- 效果图
我们可以看到此时又变成了上下式布局
所以在上面的例子中:
-
flex flex-col 是基础样式,对所有设备生效,因此移动端自然是垂直排列。
-
md:flex-row 是一个条件覆盖:当屏幕宽度达到 md 断点(768px)及以上时,将 flex-col 覆盖为 flex-row,从而变成水平排列。
这种模式非常符合现代Web开发“内容优先,移动先行”的理念。开发者只需先为小屏写好布局,再逐步为大屏添加增强样式,无需编写复杂的媒体查询。
如果不加 md:flex-row,那么所有屏幕上都会保持垂直排列,也就实现了单纯的移动端布局。通过添加断点前缀,我们可以精确控制布局在哪个尺寸发生变化。
4.3 Flex 对齐与分布
常用的对齐类:
-
justify-center:主轴居中
-
items-center:交叉轴居中
-
justify-between:两端对齐
-
self-start:单个项目对齐到起点
例如一个居中的容器:
<div className="flex justify-center items-center h-screen">
<div className="bg-red-500 p-8">居中块</div>
</div>
4.4 Grid 布局
Tailwind 也支持 Grid,例如一个三列网格:
<div className="grid grid-cols-3 gap-4">
<div>1</div>
<div>2</div>
<div>3</div>
</div>
通过 grid-cols-3 快速创建三列,gap-4 设置间距。
第五章 响应式设计
Tailwind 采用移动优先的响应式策略,内置了五个断点:
| 断点 |
最小宽度 |
说明 |
| sm |
640px |
小屏 |
| md |
768px |
中屏 |
| lg |
1024px |
大屏 |
| xl |
1280px |
超大 |
| 2xl |
1536px |
2倍超大 |
5.1 响应式前缀
在任意实用类前加上 sm:、md: 等前缀,即可指定该样式生效的最小断点。例如:
<div className="text-sm md:text-base lg:text-lg">
响应式字体
</div>
在移动端字体为 sm,中屏及以上变为 base,大屏及以上变为 lg。
5.2 响应式布局实战
回顾 App.jsx 中的布局:
<div className="flex flex-col md:flex-row gap-4">
<main className="bg-blue-100 p-4 md:w-2/3">主内容</main>
<aside className="bg-green-100 p-4 md:w-1/3">侧边栏</aside>
</div>
移动端:上下排列(flex-col),主内容和侧边栏各占100%宽度。
平板及以上:左右排列(md:flex-row),主内容占2/3,侧边栏占1/3。
这种写法简洁且符合移动优先的设计原则。
5.3 自定义断点
如果内置断点不满足需求,可以在 tailwind.config.js 中自定义:
module.exports = {
theme: {
screens: {
'tablet': '640px',
'laptop': '1024px',
'desktop': '1280px',
},
},
}
第六章 状态与交互
Tailwind 提供了多种状态变体,让我们能轻松处理交互样式。
6.1 常用的伪类变体
-
hover: 鼠标悬停
-
focus: 元素获得焦点
-
active: 元素被激活(如点击时)
-
disabled: 禁用状态
示例(来自 App2.jsx 按钮):
<button className="px-4 py-2 bg-blue-600 text-white rounded-md hover:bg-blue-700 focus:outline-none focus:ring-2 focus:ring-blue-300">
提交
</button>
-
hover:bg-blue-700:悬停时背景变深。
-
focus:outline-none:移除焦点轮廓。
-
focus:ring-2 focus:ring-blue-300:焦点时显示蓝色外发光。
6.2 组悬停(Group Hover)
当需要根据父容器悬停来改变子元素样式时,可以使用 group 和 group-hover:
<div className="group p-4 border rounded hover:bg-gray-50">
<h3 className="text-lg group-hover:text-blue-600">标题</h3>
<p className="text-gray-500 group-hover:text-gray-700">描述</p>
</div>
父容器添加 group 类,子元素使用 group-hover: 前缀,即可在父容器悬停时改变子元素样式。
第七章 组件化开发与TailwindCSS
在实际 React 项目中,我们通常将 UI 拆分为可复用的组件,TailwindCSS 在这种模式下表现优异。
7.1 在组件中使用Tailwind
创建一个 Button 组件,接收 variant 参数来改变样式:
function Button({ children, variant = 'primary' }) {
const baseClasses = 'px-4 py-2 rounded-md font-semibold focus:outline-none';
const variants = {
primary: 'bg-blue-600 text-white hover:bg-blue-700',
secondary: 'bg-gray-300 text-black hover:bg-gray-400',
};
return (
<button className={`${baseClasses} ${variants[variant]}`}>
{children}
</button>
);
}
这样既保持了灵活性,又复用了 Tailwind 的类。
7.2 性能优化:Fragment 的妙用
在 React 中,组件必须返回单个根元素。如果直接返回多个并列元素,会导致语法错误。传统做法是用一个额外的 <div> 包裹,但这会引入不必要的 DOM 节点,可能破坏布局(尤其是使用 Flexbox 或 Grid 时)并增加渲染负担。
React 提供了 <Fragment> 组件(简写为 <>...</>)来解决这个问题:它允许你组合多个子元素而不在 DOM 中添加额外节点。
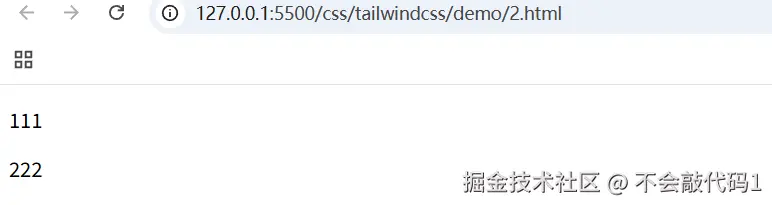
例如 下面的写法:
export default function App() {
return (
<>
<h1>111</h1>
<h2>222</h2>
<Button>提交</Button>
<ArticleCard />
</>
)
}
编译后,这些元素会直接作为父容器的子元素,中间没有多余的包裹层。
7.3 Fragment 的灵感来源:DocumentFragment
你可能好奇:为什么 React 会设计这样一个特殊组件?其实,它的思想直接来源于浏览器原生的 DocumentFragment。
让我们看我的 2.html 中的代码:
<script>
const container = document.querySelector('.container');
const p1 = document.createElement('p');
p1.textContent = '111';
const p2 = document.createElement('p');
p2.textContent = '222';
const fragment = document.createDocumentFragment();
fragment.appendChild(p1);
fragment.appendChild(p2);
container.appendChild(fragment); // 一次性添加,只触发一次重绘
</script>
效果图
DocumentFragment 是一个轻量的文档片段,它就像是一个虚拟的“临时容器”。我们将多个新节点先放入这个片段中,然后将整个片段添加到 DOM 树,这样只会触发一次重绘/重排,显著提升性能。更重要的是,片段本身不会出现在最终 DOM 中,它的子节点被直接移入目标容器。
React 的 Fragment 正是借鉴了这一理念:
- 它充当一个虚拟的父节点,允许组件返回多个元素。
- 在渲染时,这些元素会被直接展开到父组件中,不产生额外 DOM 节点。
- 它也隐式地提供了性能优化:避免了额外 div 带来的嵌套层级和样式干扰。
可以说,DocumentFragment 为 React 的组件化设计提供了重要的思路。理解这一点,能让我们更深刻地认识到 React 对原生 DOM 操作的抽象和优化。
7.4 提取重复的类组合
如果一个组件的类名组合经常重复,可以提取为一个新的组件或使用 @apply 指令在 CSS 中定义复合类(但官方更推荐组件化方案)。
第八章 进阶技巧与优化
8.1 使用 @apply 提取自定义样式
如果你希望在某些场景下复用一组 Tailwind 类,但又不想在 HTML 中写一长串,可以使用 @apply 在 CSS 中组合:
.btn-primary {
@apply px-4 py-2 bg-blue-600 text-white rounded-md hover:bg-blue-700;
}
然后在 HTML 中直接使用 btn-primary 类。但注意:过度使用 @apply 会让你回到传统 CSS 的命名和维护困境,因此官方建议仅在必要时(如第三方库限制)使用。
8.2 配置自定义主题
Tailwind 允许在 tailwind.config.js 中自定义颜色、间距、字体等。例如添加自定义颜色:
module.exports = {
theme: {
extend: {
colors: {
brand: '#ff6600',
},
},
},
}
之后就可以使用 bg-brand、text-brand 等类。
8.3 生产环境优化
Tailwind 内置了 PurgeCSS 机制,通过扫描你的文件,只保留用到的类,从而大幅减小 CSS 体积。在 tailwind.config.js 中配置 content 选项:
module.exports = {
content: ['./index.html', './src/**/*.{js,jsx,ts,tsx}'],
// ...
}
构建时,未使用的类会被自动移除。
第九章 总结与展望
通过本文的学习,我们见证了从传统 CSS 到原子 CSS 的思想演进,掌握了 TailwindCSS 的安装配置、基础实用类、布局响应式、状态交互以及组件化开发的最佳实践。
TailwindCSS 之所以流行,不仅因为它提升了开发效率,更因为它改变了我们编写样式的方式——把关注点从“给这个元素起什么类名”转移到“这个元素应该有什么样式”,让开发者更专注于 UI 本身。
值得一提的是,随着 AI 生成代码的兴起,TailwindCSS 的类名语义化、原子化的特点使其成为 AI 生成界面的绝佳选择(如参考笔记中提到的)。通过简单的 prompt 描述,AI 就能生成带有 Tailwind 类的 HTML 结构,极大加速原型开发。
当然,TailwindCSS 也有学习曲线,但一旦熟悉,你会发现它带来的愉悦感是传统 CSS 无法比拟的。希望本文能帮助你开启高效、愉悦的样式开发之旅。
参考资料
如果你觉得本文对你有帮助,欢迎点赞、收藏、关注,也欢迎在评论区交流你的 Tailwind 使用心得!
