在我刚使用大语言模型比如 Deekseek、ChatGPT 进入对话时,我也曾一度觉得这个世界上有魔法,但实际上这背后并没有真正的魔法,或者说,所谓的魔法其实是数学的魔法;而数学计算世界的前提就是找到一种方法,将连续的真实转化为离散的模型(这里所谓的模型不在是指大模型,而是指具体事物的抽象结果),然后再运用各种数学知识去计算、去拟合。
而最好的去揭开大模型背后的魔法的方式,就是自己亲手去做一个大模型,想要在哪一层去制作大模型取决于你的目的和精力,我觉得仅仅学习一些入门的流程知识并不能满足我,但是要我从神经网络的数学公式开始研究我又没那么聪明,所以我选择利用封装后的、而且是高度封装后的代码库来完成模型的训练流程,并且试图在有限的代码中看到魔法背后更多维度的真相。
请注意,本篇仅仅是个人输出和记录分享,并不一定会详细解释每一个术语和步骤且必然存在一些个人理解错误,感谢大家理解。
背景知识
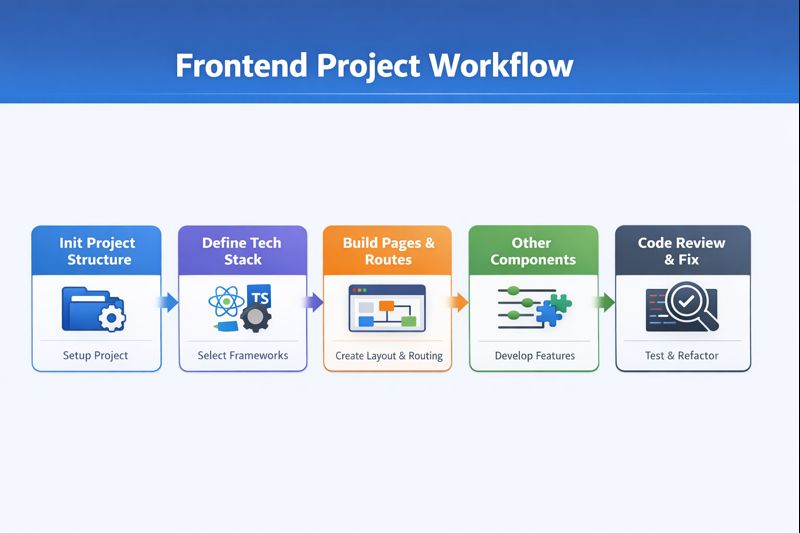
简单地用流程图表示一下一个大模型的训练流程:

-
首先,我们需要找到可最初用于训练的数据集,数据集看着很简单,但实际上它的质量会直接影响最后的大模型,所以最开始这一步也是最为关键的一步
-
有了数据集之后,我们便需要用分词算法对其进行tokenization(分词),这一步其实就是将连续的语言信息转化成离散的信息单元
-
将分词后的结构及表格同原数据集一起丢给transformer算法,耗费非常巨大的人力物力算力,最终我们可以得到一个 base/foundation model,但是目前这个模型并不会进行智能问答,因为它还没有学会如何「chat」,所以它只会基于你的话进行接龙,接龙的依据就是向量空间中各分词的相似度概率
-
如果想要基础模型变得会说话,那就需要进行 SFT(监督微调),通过喂给模型一定体量的问答结构的数据,让模型学会怎么基于 user-assistant 的模式去回答人类或进行「chat」
-
很多问题或许没有标准答案,并且人类偏好的交流模式和风格也都是有一定范围的,所以此时需要通过 RL(增强学习),或者通过更新的技术 DPO(直接偏好优化),来训练模型尽量输出更符合人类偏好和审美的回答
本次训练的模型将会按照 pretraining-SFT-DPO 这一路径来完成。
准备工作
首先技术选型具体如下:

由于我的个人电脑 GPU 非常弱,而且使用 GPU 来进行模型训练非常容易出现 OOM(内存溢出),所以我在代码中强制规定了只使用 CPU 进行各种运算;
而 CPU 运算确实特别慢,所以模型的参数、层数我都不能设置太多,以下是我的模型的一些重要参数:

其实这个参数量完全不够用,因为目前市场上成熟大模型的参数量基本都是 B 数量级起步的,所以我这顶多算做是「小」模型了,但是仅仅就 256 Vectors + 4 layers 就在我的电脑上花了很久的运算时间:
 接下来我将较为详细地演示每一步骤,如果有代码需求对应的 GitHub 地址在这里:
接下来我将较为详细地演示每一步骤,如果有代码需求对应的 GitHub 地址在这里:
github.com/Chacha-Bing…

训练模型
数据集
上面也提到过,数据集作为最原始的喂给模型训练的原油非常重要,数据集的大小与质量将会直接决定成品模型的质量。
目前大部分最先进模型的数据集都是非公开的(即使他们本身已经开源),但是我们已知的是,这些语言大模型的训练数据集的数量级已经来到了 TB 级别,而且在不远的未来几年或许就会把人类互联网已有的文字资料给训练殆尽。
但是有了各种网络数据以后并不可以直接拿来使用,因为这些网络信息中可能包含大量的重复文章、广告信息、有毒有害信息等,这些文字将会严重影响模型的偏好与训练成果,所以如何进行数据清洗和结构化是数据集中更为至关重要的一步。
但是现在优秀数据集并不难得到,比如 Huggingface 上的 FineWeb 项目(huggingface.co/datasets/Hu… 18.5T tokens,它们经由爬虫(Common Crawl)爬取数据并且做了一定的清洗,你可以很容易地就下载到其中的某些数据分片甚至是全量的数据,但真正的问题在于大多数人根本没有对应的算力资源去对如此海量的数据进行计算。

我的个人电脑也没有这么大的算力,虽然可以使用诸如 colab 之类的平台争取一些免费计算资源,但是我还是决定先在本地先行跑一个流程,所以我选取了一个非常小的关于医疗方面的数据子集(shibing624/medical,源自Huggingface:huggingface.co/datasets/sh…

预训练 [ pre-training ]
预训练是指在大规模的海量数据(通常是未标注的互联网文本)上,使用自监督学习 (Self-supervised Learning) 的方式训练模型,使其掌握通用的知识和语言规律。
预训练是大模型万丈高楼平地起的第一步,同时预训练也是 LLM 训练中最耗钱、耗力的阶段,因为这一阶段的数据集和所需算力都是最大的:比如 GPT-4 的预训练就需要数万颗 GPU 连续跑数月,消耗的电费和算力成本高达数千万美元。
预训练并不要求模型完成特定任务如翻译或分类,它的目标只有一个:猜下一个字,比如
-
输入: “床前明月光,”
-
目标: 模型预测下一个字是“疑”。
为了猜得准,模型必须学会语法、逻辑、事实知识甚至是常识,所以这也就是为什么预训练阶段需要大量的数据。
这些数据会经过分词,变成一个个有语义的 token,经过模型的训练后,这些词表中的 token 就会在 transformer 后映射成内部向量空间的高维数组,当用户输入后,这些输入也会经过内部 transformer 的各种层得到一个同维度的数组向量,而模型的下一步就是在预训练好后的向量空间内寻找与输入向量相似度「最适配」的向量,注意这里不一定是「最接近」而是「最适配」,因为这取决于我们的模型运行参数和内部使用这些参数的算法。那么找到「最适配」的向量后,我们通过逆向的办法即 unembedding 来解码出找出的这个向量是对应着什么字作为输出,然后循环往复一直「接龙」。
分词 [ tokenization ]
在我们训练语言模型之前,我们需要对数据进行分词,tokenization 是将我们的字符串转换为可做数值运算的数字的过程:我们的原始数据集仅仅是大段大段文字的集合,算法本身并不知道要如何去摄入并且训练自己理解这些长篇大论,我们必须对其进行离散化、数学化。
这里我们不展开分词的逻辑和各种算法,我们可以简单理解为分词相当于是将我们所有的语料库进行了语义切割,比如将「我爱月亮」这句话分为「我」、「爱」、「月亮」这 3 个tokens,虽然不同的算法会对同样的文字进行不同类型的分词,但是我们目前只需要知道,经过分词以后,所有的语料库就会被切割为非常大量的 tokens,其中每个 token 都会对应着自己的 tokenid,每个 tokenid 下都会有一个代表着这个 token 的向量,向量的初始值可以是随机的,向量的维度是我们自己定的,之后预训练的很大一部分工作,就是对于这些向量中的每一个参数进行微调。
我在这里使用了基于 BPE 算法的 tokenizer 即 ByteLevelBPETokenizer,用它来对我们 630MB (内含 370000 条医疗知识)的预训练数据集进行分词:

经过10min后,我们的分词结果已经完成,同时我们写一个脚本简单测试一下我们的分词成果:从上图可以看出,对于我构造的文本「患者诊断为心肌梗塞,建议服用阿司匹林。」—— 这句话基于我们的分词成果被拆分成了 8 个 tokens,将这些 tokens 做 decoded 还原没有丢失任何信息,将这些 tokens 逐个打印出来可以发现这些 token 都是有语义性的,比如「阿司匹林」被视为了一个 token 而不是视为「阿」、「司」、「匹」、「林」四个 token。
开始训练
我们调用 transformers 库,设置好合适的参数后,即开始进入漫长的预训练过程。
由于训练过程涉及到非常多的专业和数学知识,我感觉我也讲不好,所以大家想要了解还是专门去搜索相关资料比较好,或者可以进这个网站看一看:bbycroft.net/llm(这是一个用 three.js 制作的讲解 LLM 内部的动画流,对于形成概念还是挺有用的)

大概 8.4M 的参数量,我从下午3点开始训练,到半夜近2点才训练完。
在这 10h+ 的训练过程中,模型需要进行 92474 步才能将这次训练任务跑完:

可以从监视器里看到 Python 的执行已经占据了大部分 CPU 运算,同时为了不功亏一篑,所以每隔 500 步我都会让模型保留一次 checkpoint 作为快照存档。

另一方面,每隔50步我就会让模型以「我今天有点头疼,我需要」开头让它进行续写,以便能够实时看到训练成果:
刚开始训练时,模型几乎无法吐出完整的句子,loss 值为8+;



模型跑到2万步时,输出从破碎结构接近有一定逻辑,Loss降到了 5+ ;
模型 9万+ 轮全部跑完时平均 Loss 在4.7(一般来说,Loss 在2-4是比较优秀,对于我们训练小模型来说 Loss 在4-6也算够用啦)
监督微调 [ SFT ]
经过了十个半小时的集中训练,我们终于完成了这个9万步的训练过程🎉。
现在我们拥有了一个基础模型(Base/Foundation Model),但是目前的这个模型只会进行数理统计意义的词语接龙,虽然我们可以调整各种参数让它每次的输出结果不一样,但是它目前还学不会问答这套逻辑,而且只能基于医疗数据回答,让我们写个脚本测试一下:

可以看出其实它已经有了比较强的逻辑性,接下来我们就需要通过监督微调(SFT)来让这个“GPT”变成“Chat GPT”。
我们可以大致看一看用来做 SFT 的数据集样例:
{"instruction": "请描述口腔黏膜吸收的历史", "input": "", "output": "1847年,阿斯坎尼欧·索布雷罗等首先报导了硝酸甘油可以经口腔黏膜吸收进入人体血液循环系统。1879年,硝酸甘油舌下药成功地用于临床,之后陆续出现许多药物的口腔黏膜吸收相关报导。"}{"instruction": "我妈70岁,CT部位L3—S1椎间盘,结果L,无", "input": "", "output": "腰椎间盘突出症引起的症状就是有髓亥脱出刺激神经引起的痛庝,下肢反射性的痛庝,治疗的方法就是需要注意休息牵引,按摩针灸的方法治疗,口服芬必得,腰息痛胶囊。腰腿痛丸治疗,无效时射频和针刀的方法治疗一定要自己锻炼的,增强肌肉的韧性"}
这份数据是符合 Alpaca 格式的数据集,这也是目前开源社区最通用的 SFT 数据标准。
其中**instruction** (指令)是用户给模型下达的任务命令,****input **(上下文/输入):**是执行指令时所需要的额外背景信息,这个数据集没那么复杂所以 input 基本为空,而 output 就是模型需要学习的输出。
这一份数据集明显有更强烈的格式化,它能够教会模型怎样去做更符合问答结构的输出而不是去做字词接龙。
同时这一部分的数据集不用太多,正如其名称「微调」一样,我们只是想要去改变模型的一些输出模式和语气,并不想动到之前已经训练好的知识的关联,所以不需要过多的数据,否则模型可能会产生灾难性遗忘。
我从这个 SFT 数据集中随机抽取了5000条数据基于上面那个基础模型做 SFT 训练:
SFT完成截图:
从日志看,最终 train_loss 定格在 4.517。虽然数字上看起来和预训练差不多,但因为 SFT 改变了模型的输出分布,所以它现在的对话逻辑会比之前更强。

现在让我们测试一下这个经过了 SFT 的可以进行 Chat 的模型:

现在这个经过 SFT 的模型的确超越了字词接龙的门槛,但是对于「我想知道什么是口腔溃疡,你可以告诉我吗」这同一输入模型的不同表现,我们也可以看出在SFT后的答案没有SFT前的好:

这里的原因大概率就是出现了我们上面提到的「遗忘」,或者说灾难性遗忘 (Catastrophic Forgetting),这里的核心原因是因为我的模型太小了:为了迎合 SFT 的「对话格式」,而强制压制了预训练时学到的「百科知识」。
由于参数量太小(8M),模型可能无法同时兼顾「深刻的知识」和「礼貌的格式」,而最终选择了格式,丢掉了逻辑:这种「过拟合到模版」的操作挤占了原有知识的存储空间,导致它在回答时显得非常呆滞,甚至不管之前学到的逻辑而拼命输出礼貌的「你好」。
除了通过比较难实现的提高参数量以外,我们也可以通过一些措施来修正,比如
我这里就不去做更多的复杂调整了,同时,对于我的这个case,直接使用更精准一些的Prompt是个更迅速的捷径:

直接偏好优化 [ DPO ]
当模型做完微调以后,比较传统和在复杂场景下更为优越的方法其实是 RLHF(人类反馈强化学习)。
首先我们需要知道,在模型做完 SFT 后,模型的确能像个正常对话者一样,可以去和我们进行一来一回的对话了,但是这还不够,因为对于很多回答,此时的模型还并不能做出一个符合多数人预期的「好回答」,比如涉及到不同地区的习俗宗教法律的问题,又比如这个世界上大多数问题都是开放性问题,我们需要解决这些问题让模型变得更加「像人」。
比较典型的做法 RLHF 大体上分为2步:
首先我们要建立一个奖励模型 (Reward Modeling),虽然最理想的情况是根据一个指令让模型生成不同的回答然后让人类直接来标记打分,但是想想也知道这是多么大的工作量,但是我们可以通过一些人类打分的样本,去训练一个奖励模型,这个“小裁判”模型会学习人类的喜好,在后续的海量工作中它将模拟替代人类、给我们的训练模型的多个回答打分或者标记好差评。我记得之前在用 ChatGPT 时,有些时候它能生成两种回答并且会让你选择更喜欢的风格或逻辑,其实和上述的流程类似。
其次就是进行强化学习 (PPO, Proximal Policy Optimization),在这个算法中,我们让模型不断生成回答,然后让刚刚生成的“小裁判”即奖励模型打分,模型根据分数调整自己,这种算法其实也是“概率偏好优化”的一种具体实现。
但是我打算用一种更现代更简化的方式,也即 DPO:直接偏好优化 (DPO, Direct Preference Optimization)。
它直接跳过了训练“裁判”的步骤,直接用「好回答 / 坏回答」的对比对来训练模型,相对更简单、高效、省显存;比如说如果用 RLHF 的方法,那么在内存中需要同时运行数个模型:一个奖励模型、被训练的模型、基准模型、还有一些其他防止模型跑偏的附加模型,那我的电脑肯定会不堪重负,而 DPO 其实只用加载两个模型,即被训练的模型和基准模型,这个基准模型其实就是上面我们结束 SFT 后的模型,它存在的意义是用来作为某种距离计算的基准,可以防止我们的模型在做完 DPO 后离原来太远而产生劣化。
我们可以大致看一看用来做 DPO 的数据集样例:
{"question": "术后肌痛的高危因素有些什么?", "response_chosen": "琥珀胆碱", "response_rejected": "手术后疼痛是常见的并发症之一。"}{"question": "高血脂的就诊科室是什么?", "response_chosen": "内科;心内科", "response_rejected": "高血压、糖尿病等疾病患者在治疗过程中常常需要进行血液检查。"}{"question": "老年环状混合痔的并发症是什么?", "response_chosen": "冠心病;高血压病;糖尿病", "response_rejected": "老年环状混合痔的常见并发症包括:肛门狭窄、直肠脱垂和大便习惯改变。"}
这个数据结构中包含成对的数据即:同一个问题,附加一个正确的、更好答案和一个错误的、不太好的但看起来很像正确的答案,把这些数据丢给模型去训练,模型可以被训练出使回答更偏更好的答案的形态。
DPO 流程其实特别耗时,DPO 时我的电脑会承受比 SFT 阶段重 3-4 倍的计算压力
DPO 时电脑内存中发生的一些事:
-
双模型同步前向传播:在 SFT 时,电脑只需要跑一个模型。而在 DPO 的每一单步里,电脑要同时跑 Policy Model(训练模型)和 Reference Model(参考模型)。计算两次 Logits:
-
把 chosen(好回答)喂给两个模型,算概率差。
-
把 rejected(坏回答)喂给两个模型,再算概率差。
-
对数几率比(Log Odds Ratio)计算:模型需要根据这两组概率差,计算出一个损失值(Loss),这个过程涉及大量的浮点运算。

Rewards/accuracies (奖励准确率)在30%轮次时就已经高达 **0.9375,**这意味着在当前的每一个处理采样里,模型有 93% 的把握认为 chosen 确实比 rejected 更好。
看相关的参数我觉得我们这个小模型对好坏的认知已经基本定型。所以我最后决定不继续等待,而是拿最新的第**141步的checkpoint**文件作为 DPO 的训练结果,也作为我们这个「医疗大模型」的最终成果。
结果分析
我们采取最直观的方式来分析结果:写一个脚本,它用于加载不同步骤生成后的共计3个模型:预训练生成后的模型、SFT后生成的模型、DPO后生成的模型,我们只需要在命令行打一个问题,下面就会自动出现三个模型生成的回复以便进行比较:
意外但合理的结果是,我发现效果最好的反而是只经过预训练的 Base Model。


下面我们来简单分析一下,为什么 SFT 和 DPO 反而变差了?其实还是上面提到过的**「灾难性遗忘」**。
在截图里,可以清晰看到微调带来的副作用:
-
SFT(指令微调):内容变得像是在“背清单”(1...2...3...)。这是因为 SFT 数据集里有很多分条列点的格式,模型学会了这种“说话的调调”,却在模仿过程中把 Base 模型里深层的医学知识给挤掉了。
-
DPO(偏好对齐):结尾出现了大面积的“祝您早日康复!祝您早日康复!”。这是很典型的「过拟合」或「模式崩塌」:因为 DPO 强迫模型去迎合某个特定的审美,比如更有礼貌或者更像医生,结果它那仅有的 8M 「脑子」承载不了这种复杂的转变,导致它最后只学会了反复输出这种高分金句,因为这个句子模式在训练集中被认为是更被人类偏好的。
我们模型的核心矛盾就是其 8M 的大脑容量实在是有限,我们会说模型规模决定了微调的上限,你可以理解为因为参数太小所以我训练的模型在预训练阶段可能就已经没有什么冗余了,所以后续继续训练时,影响的参数绝大多数都是之前的关键参数,虽然我们可以设置学习率、梯度等参数来缓解这种改变,但是参数变了就是变了,它可能就是会对之前习得的向量空间里各个 token 的位置产生影响。
最后,我们的模型其实在预训练后成为基础模型的表现会更好,这也证明这份 Huggingface 上的医疗预训练语料质量很高; 而 SFT 和 DPO 表现出的退步,说明对于我们的 8M 模型 来说,过度的 Alignment(对齐)反而劣化了。
既然如此,我们后续更好的路径其实是:
-
使用 Base 模型作为核心。后续我们还可以做简单少量的 SFT 仅仅让模型学会一些回答的格式,但DPO可以先不考虑
-
可以继续考虑做 RAG (检索增强):我们可以让 Base 模型根据搜索到的实时专业文档进行总结,这样它就不需要继续消耗本就不多的宝贵参数量去“背诵”知识盲区和新知识了
后续我就暂不优化这个模型了,因为主要流程和核心都跑过了,RAG也在其他项目中做过了,所以这个项目至此完成。
结语
GitHub 地址:github.com/Chacha-Bing…

我在前两周还是一个对人工智能、对以上知识均一无所知的小白,到现在已经能够简单地跑通一个模型的训练流程,可以说是算已经入门了,对此还是感到非常有趣和开心的。
写这篇文章也是权把自己的一些学习心得和实验流程记录下来供大家参考,或许也有许多小白和我在各个阶段有相同的疑惑,那么就感谢各位的阅读啦,后续如果我继续做了什么有趣的小东西我会继续输出的~