首屏加载统计的几个问题梳理
前言 前端性能优化方面离不开白屏的问题,今天只是侧重复习下白屏的计算方式与系统性的记录方式。关于白屏的性能优化方面有很多,大家可以先看看下面这位老哥写的性能优化的几种方式 关于白屏 基本定义:白屏时间
哈希表(Hash Table)是编程中最常用的高效数据结构之一,几乎所有编程语言的标准库都提供了哈希表的实现(如 JavaScript 的 Map/Object、Java 的 HashMap、Python 的 dict)。它以 O(1) 平均时间复杂度 支持增删查改操作,是解决“快速键值映射”问题的首选方案。本文将从底层原理出发,拆解哈希表的核心设计,实现两种解决哈希冲突的方案,并结合实战案例(RandomizedCollection)展示哈希表的灵活应用。
哈希表的本质是用数组实现的键值映射——通过一个“哈希函数”将任意类型的 key 转化为数组的合法索引,从而借助数组 O(1) 的随机访问特性实现高效操作。
class MyHashMap {
constructor() {
// 底层存储数组
this.table = new Array(1000).fill(null);
}
// 增/改:key→索引→数组赋值
put(key, value) {
const index = this.hash(key);
this.table[index] = value;
}
// 查:key→索引→数组取值
get(key) {
const index = this.hash(key);
return this.table[index];
}
// 删:key→索引→数组置空
remove(key) {
const index = this.hash(key);
this.table[index] = null;
}
// 核心:哈希函数(key→合法索引)
hash(key) {
// 1. 计算key的哈希值(保证相同key返回相同值)
let h = key.toString().charCodeAt(0);
// 2. 保证哈希值非负(位运算效率高于算术运算)
h = h & 0x7fffffff;
// 3. 映射到数组合法索引(取模)
return h % this.table.length;
}
}
哈希函数是哈希表的“灵魂”,必须满足三个条件:
确定性:相同 key 必须返回相同索引;
高效性:计算复杂度为 O(1)(否则哈希表整体性能退化);
均匀性:尽可能让不同 key 映射到不同索引(减少冲突)。
由于哈希函数是“无穷空间→有限空间”的映射,哈希冲突(不同 key 映射到同一索引)是必然存在的。解决冲突的核心方案有两种:拉链法(主流)和 线性探查法。
数组的每个位置存储一个链表,当发生哈希冲突时,将冲突的键值对追加到链表尾部。
增删查改:先通过哈希函数找到数组索引,再操作对应链表;
优势:实现简单、支持高负载因子(链表可无限延伸);
劣势:链表遍历有轻微性能损耗(但平均仍为 O(1))。
// 链表节点:存储key-value
class HashNode {
constructor(key, val) {
this.key = key;
this.val = val;
this.next = null;
}
}
class HashTableChaining {
constructor(capacity = 10) {
this.capacity = capacity; // 数组初始容量
this.size = 0; // 实际存储的键值对数量
this.loadFactor = 0.75; // 负载因子(触发扩容的阈值)
this.table = new Array(capacity).fill(null); // 底层数组
}
// 哈希函数:key→索引
hash(key) {
let h = typeof key === 'number' ? key : key.toString().charCodeAt(0);
h = h & 0x7fffffff; // 保证非负
return h % this.capacity;
}
// 扩容:解决哈希冲突频繁的问题
resize() {
const oldTable = this.table;
this.capacity *= 2; // 容量翻倍
this.table = new Array(this.capacity).fill(null);
this.size = 0;
// 重新哈希并迁移数据
for (let node of oldTable) {
while (node) {
this.put(node.key, node.val);
node = node.next;
}
}
}
// 增/改
put(key, val) {
// 达到负载因子,先扩容
if (this.size / this.capacity >= this.loadFactor) {
this.resize();
}
const index = this.hash(key);
// 链表为空,直接新建节点
if (!this.table[index]) {
this.table[index] = new HashNode(key, val);
this.size++;
return;
}
// 链表非空:遍历查找(存在则修改,不存在则追加)
let curr = this.table[index];
while (curr) {
if (curr.key === key) {
curr.val = val; // 存在,修改值
return;
}
if (!curr.next) {
curr.next = new HashNode(key, val); // 不存在,追加到尾部
this.size++;
return;
}
curr = curr.next;
}
}
// 查
get(key) {
const index = this.hash(key);
let curr = this.table[index];
while (curr) {
if (curr.key === key) {
return curr.val;
}
curr = curr.next;
}
return null; // 未找到
}
// 删
remove(key) {
const index = this.hash(key);
let curr = this.table[index];
let prev = null;
while (curr) {
if (curr.key === key) {
// 找到节点:删除(分头部/中间节点)
if (prev) {
prev.next = curr.next;
} else {
this.table[index] = curr.next;
}
this.size--;
return true;
}
prev = curr;
curr = curr.next;
}
return false; // 未找到
}
}
// 测试拉链法哈希表
const ht = new HashTableChaining();
ht.put("a", 1);
ht.put("b", 2);
ht.put("c", 3);
console.log(ht.get("a")); // 1
ht.remove("b");
console.log(ht.get("b")); // null
不使用链表,当发生哈希冲突时,向后遍历数组找空位(到数组末尾则绕回头部):
插入:找到空位后直接存入;
查询:从哈希索引开始遍历,直到找到目标或空位;
删除:不能直接置空(会中断查询),需用占位符标记(如 DELETED)。
环形数组:遍历到数组末尾时需绕回头部;
删除逻辑:用占位符替代直接置空,避免查询中断。
class HashTableProbing {
constructor(capacity = 10) {
this.capacity = capacity;
this.size = 0;
this.loadFactor = 0.75;
this.table = new Array(capacity).fill(null);
this.DELETED = Symbol('deleted'); // 占位符:标记已删除
}
// 哈希函数
hash(key) {
let h = typeof key === 'number' ? key : key.toString().charCodeAt(0);
h = h & 0x7fffffff;
return h % this.capacity;
}
// 扩容
resize() {
const oldTable = this.table;
this.capacity *= 2;
this.table = new Array(this.capacity).fill(null);
this.size = 0;
// 迁移数据(跳过占位符)
for (let entry of oldTable) {
if (entry && entry !== this.DELETED) {
this.put(entry.key, entry.val);
}
}
}
// 查找key的索引(核心:处理冲突+占位符)
findIndex(key) {
let index = this.hash(key);
let start = index;
// 环形遍历:直到找到目标/空位/遍历完
while (this.table[index] !== null) {
// 找到目标key
if (this.table[index] !== this.DELETED && this.table[index].key === key) {
return index;
}
// 绕回头部
index = (index + 1) % this.capacity;
// 遍历完一圈仍未找到
if (index === start) {
return -1;
}
}
return index; // 返回空位索引
}
// 增/改
put(key, val) {
if (this.size / this.capacity >= this.loadFactor) {
this.resize();
}
const index = this.findIndex(key);
// 未找到:插入新值
if (index === -1 || this.table[index] === null || this.table[index] === this.DELETED) {
this.table[index] = { key, val };
this.size++;
return;
}
// 找到:修改值
this.table[index].val = val;
}
// 查
get(key) {
const index = this.findIndex(key);
if (index === -1 || this.table[index] === null || this.table[index] === this.DELETED) {
return null;
}
return this.table[index].val;
}
// 删:用占位符标记
remove(key) {
const index = this.findIndex(key);
if (index === -1 || this.table[index] === null || this.table[index] === this.DELETED) {
return false;
}
this.table[index] = this.DELETED;
this.size--;
return true;
}
}
// 测试线性探查法哈希表
const htProbe = new HashTableProbing();
htProbe.put(1, 10);
htProbe.put(11, 20); // 哈希冲突(1%10=1,11%10=1)
console.log(htProbe.get(11)); // 20
htProbe.remove(1);
console.log(htProbe.get(1)); // null
负载因子 = 已存储元素数 / 数组容量,是哈希表扩容的核心依据(通常设为 0.75):
负载因子过高:哈希冲突频繁,性能退化;
负载因子过低:数组空间浪费;
扩容逻辑:容量翻倍,重新哈希并迁移所有数据(保证后续冲突减少)。
标准哈希表的遍历顺序是无序的,若需保留插入顺序,可结合哈希表+双向链表实现:
哈希表:快速查找节点(O(1));
双向链表:维护插入顺序(删除节点 O(1))。
// 双向链表节点
class LinkedNode {
constructor(key, val) {
this.key = key;
this.val = val;
this.prev = null;
this.next = null;
}
}
class LinkedHashMap {
constructor() {
// 哨兵节点:简化链表操作
this.head = new LinkedNode(null, null);
this.tail = new LinkedNode(null, null);
this.head.next = this.tail;
this.tail.prev = this.head;
this.map = new Map(); // 哈希表:key→节点
}
// 新增节点到链表尾部
addLast(node) {
const prev = this.tail.prev;
prev.next = node;
node.prev = prev;
node.next = this.tail;
this.tail.prev = node;
}
// 移除链表节点
removeNode(node) {
const prev = node.prev;
const next = node.next;
prev.next = next;
next.prev = prev;
}
// 增/改
put(key, val) {
if (this.map.has(key)) {
const node = this.map.get(key);
node.val = val;
return;
}
const newNode = new LinkedNode(key, val);
this.addLast(newNode);
this.map.set(key, newNode);
}
// 查
get(key) {
return this.map.has(key) ? this.map.get(key).val : null;
}
// 删
remove(key) {
if (!this.map.has(key)) return;
const node = this.map.get(key);
this.removeNode(node);
this.map.delete(key);
}
// 按插入顺序遍历key
keys() {
const res = [];
let curr = this.head.next;
while (curr !== this.tail) {
res.push(curr.key);
curr = curr.next;
}
return res;
}
}
// 测试有序哈希表
const lhm = new LinkedHashMap();
lhm.put("a", 1);
lhm.put("b", 2);
lhm.put("c", 3);
console.log(lhm.keys()); // ["a", "b", "c"]
lhm.remove("b");
console.log(lhm.keys()); // ["a", "c"]
若需哈希表支持“随机返回键”且元素不重复(如 MyArrayHashMap),可结合数组+哈希表实现,核心是用数组存储键值对、哈希表映射键与下标,兼顾 O(1) 增删查与随机访问。
数组:存储 Node 实例(含 key 和 val),支持 O(1) 随机访问,保证随机返回键的等概率性;
哈希表:key→元素在数组中的下标(一一对应,因元素不重复),支持 O(1) 定位元素,规避数组遍历开销。
// 键值对节点:封装key和val
class Node {
constructor(key, val) {
this.key = key;
this.val = val;
}
}
class MyArrayHashMap {
constructor() {
// 哈希表:存储key与对应在数组中的下标,实现O(1)定位
this.map = new Map();
// 数组:存储Node实例,支持O(1)随机访问
this.arr = [];
}
/**
* 按key查询值
* @param {*} key - 要查询的键
* @return {*} 对应的值(不存在返回null)
*/
get(key) {
if (!this.map.has(key)) {
return null;
}
// 哈希表取下标,数组直接访问
return this.arr[this.map.get(key)].val;
}
/**
* 增/改键值对(元素不重复,已存在则修改值)
* @param {*} key - 键
* @param {*} val - 值
*/
put(key, val) {
if (this.containsKey(key)) {
// 已存在:通过下标修改对应节点的值
let i = this.map.get(key);
this.arr[i].val = val;
return;
}
// 新增:数组尾部添加节点,哈希表记录下标
this.arr.push(new Node(key, val));
this.map.set(key, this.arr.length - 1);
}
/**
* 按key删除键值对
* @param {*} key - 要删除的键
*/
remove(key) {
if (!this.map.has(key)) {
return;
}
const index = this.map.get(key); // 待删除元素下标
const node = this.arr[index]; // 待删除节点
const lastIndex = this.arr.length - 1;
const lastNode = this.arr[lastIndex]; // 数组最后一个节点
// 1. 交换待删除节点与最后一个节点位置(避免数组移位,保证O(1))
this.arr[index] = lastNode;
this.arr[lastIndex] = node;
// 2. 更新最后一个节点在哈希表中的下标映射
this.map.set(lastNode.key, index);
// 3. 数组删除最后一个元素(O(1)操作)
this.arr.pop();
// 4. 哈希表删除待删除节点的key
this.map.delete(node.key);
}
/**
* 随机返回一个键(等概率)
* @return {*} 随机键
*/
randomKey() {
const n = this.arr.length;
if (n === 0) return null; // 边界处理:空表返回null
const randomIndex = Math.floor(Math.random() * n);
return this.arr[randomIndex].key;
}
/**
* 判断key是否存在
* @param {*} key - 要判断的键
* @return {boolean} 存在返回true,否则false
*/
containsKey(key) {
return this.map.has(key);
}
/**
* 获取键值对数量
* @return {number} 数量
*/
size() {
return this.map.size;
}
}
// 测试(验证不重复特性、增删查及随机访问)
let map = new MyArrayHashMap();
map.put(1, 1);
map.put(2, 2);
map.put(3, 3);
map.put(4, 4);
map.put(5, 5);
console.log(map.get(1)); // 1(查询正常)
console.log(map.randomKey()); // 随机返回1-5中的一个键
map.remove(4); // 删除key=4的键值对
console.log(map.randomKey()); // 随机返回1-3、5中的一个键
console.log(map.randomKey()); // 再次随机,无重复元素干扰
Map 是接口(抽象定义),不保证时间复杂度;
HashMap 是实现(哈希表),平均 O(1);TreeMap 是实现(红黑树),O(logN)。
若 key 是可变类型(如数组、对象),修改后哈希值会变化,导致无法找到原数据,甚至内存泄漏。
| 特性 | 拉链法 | 线性探查法 |
|---|---|---|
| 实现难度 | 简单 | 复杂(需处理环形/占位符) |
| 负载因子 | 无上限(链表可延伸) | 通常≤0.75(否则性能差) |
| 性能 | 平均O(1)(链表遍历) | 平均O(1)(缓存友好) |
| 空间利用率 | 较低(链表节点开销) | 较高(无额外节点) |
哈希表的核心是“数组+哈希函数”,解决冲突的两大方案各有优劣(拉链法是主流)。实际开发中,需根据场景选择不同的哈希表变体:
普通键值映射:用标准哈希表(如 Map);
有序遍历:用哈希链表(LinkedHashMap);
随机访问+元素不重复:用数组+普通哈希表组合(如 ArrayHashMap),通过节点交换实现O(1)删除;
高性能场景:优先选择拉链法(实现简单、不易出错)。
你好,我是瓜某。
前几天群里有人问了我一个有意思的问题,就是 Figma 创建图形,它的命名规则是怎样的?
这个问题挺有趣的,不妨展开说说。
Figma 中通过绘制创建图形,图形名称会给图形类型对应的前缀,加上一个空格符,以及一个正整数序号,如 "Rectangle 6"、"Vector 3"。
绘制图形时,会找到它的图形类型,在当前画布中找到对应的最大序号。取这个序号 + 1,作为新的图形的序号。
整体的逻辑是:
prefix + ' ' + (num + 1)。绘制一个新的矩形,遍历当前图纸中的图形,匹配图形名为 /^Rectangle\s*(\d+)/ 的,拿到对应的序号,找出其中的最大值,在这个示例中是 3。然后我们加 1,得到 4,于是我们的新的矩形的 name 就是 "Rectangle 4"。
正则
/^Rectangle\s*(\d+)/ 的匹配规则是:
"Rectangle 2test" 是符合规则的,会拿到 2)。const getNumFromName = (str, prefix) => { const regex = new RegExp(`^${prefix}\\s*(\\d+)`); const match = str.match(regex); return match ? parseInt(match[1]) : undefined;}// 用法如下:getNumFromName('Rectangle 25', 'Rectangle') // 25getNumFromName(' Rectangle 25', 'Rectangle') // undefinedgetNumFromName('Rectangle 25.7', 'Rectangle') // 25getNumFromName('Rectangle 25hello', 'Rectangle') // 25
计算当前画布中特定前缀的最大序号:
const getNodesMaxNum = (nodes, prefix) => { let maxNum = 0; for (const node of nodes) { const name = node.name; const num = getNumFromName(name, prefix); if (num != undefined) maxNum = Math.max(maxNum, num); } return maxNum;}// 拿到新的图形名const num = getNodesMaxNum(getAllNodes(), 'Rectangle') + 1;const nodeName = 'Rectangle ' + num;
命名和画布中的图形的实际类型完全没关系,你可以给一个圆形图形命名为 Rectangle <num> ,这个 name 仍旧会参与计算。
如果觉得遍历画布的所有节点比较耗时,可以考虑缓存不同图形的最大序号,需要在新增图形、删除图形、更新图形名时做缓存的更新。
Figma 中复制图形,也会对图形名进行重命名,逻辑和创建不太一样。
逻辑是:
/^(.*)\s(\d+)/。如果不匹配,不重命名;如果匹配,取得前缀 prefix;获取 prefix 的方法:
const getNamePrefix = (str) => { const regex = /^(.*)\s\d+$/; const match = str.match(regex); return match ? match[1] : undefined;}
prefix 不要求是图形类型前缀,可以是任何字符。所以复制 "banana 2",也是会得到 "banana 3" 的。
有个地方要注意下,就是复制多个图形的时候,当给上一个图形计算好新的 name 后,下一个图形要把上一个图形的 name 也纳入运算,否则会出现相同的序号。
另外,如果复制了组,组下节点不会进行重命名,因为它们和复制位置不在一个层级了。
还有就是文本图形比较特殊,如果开启了 autoRename,图形名需要跟随文本内容,优先级更高,也不会重命名。
Figma 给图形加序号的好处,是 **可以一定程度对图形进行标识。**此外递增的特性,也能清晰地感知到图形的创建时间顺序,尤其是复制大量相同图形时,能清晰识别出谁是复制出来的。
缺点是,不太优雅。但我们创建了大量的图形,会发现它们的名字会带上一段很长的没有意义的狗屁膏药一般的数字。
也有一些办法可以去掉后缀。
Figma 提供了一个批量重命名的能力,选中多个图形,然后按下 Command / Ctrl + R 可唤起然后按一定的规则改名。
另外也可以安装一个 Figma 插件,叫做 No Numbers,它是一个脚本,执行一下,就能将选中的图形或画布中所有图形名的数字后缀去掉。
还有种方案是 新建图形,图形名不带数字后缀的,比如 Adobe Illustractor、Affinity。
准确来说,它们创建的图形,是没有名字的。
{ id: '1:2', type: 'RECT', name: undefined // ...}
虽然没有名字,但有 type,在 UI 层可以基于这个 type 给出一个虚假的 “图形名”。
const getUIName = (node) => { if (node.name != undefined) return node.name; return getNameFromMap(node.type); // 从映射表里拿一个 name。}
Adobe Illustractor 的图层列表显示效果:
虽然丢掉了前面说的带数字后缀的优点。
但它的 实现上会更简单一些。
此外没有名字也有一些优势:
不过如果用户手动设置了图形名字,让 name 不再是 undefined,上面这两项是不会生效的。
我是前端西瓜哥,关注我,学习更多图形编辑器知识。
今天早上醒来,发生了一件让我有点懵的事情。我前段时间为了学习 Svelte 而写的一个“练手项目”—— Zsweep,竟然冲上了 Hacker News (HN) 首页的第 5 名。
(这是后面看到时的截图,最开始上了前5,可惜没有截屏😭)
(此图为证)
(小站下午游戏时长暴涨100小时🤯)
对于独立开发者来说,HN 的首页就像是“奥斯卡红毯”。看着自己写的代码被全球各地的极客讨论, 我想趁热打铁,在掘金复盘一下这个项目的开发思路、技术栈选择,以及我为了让它“好玩”而死磕的一些技术细节。
HN:news.ycombinator.com/item?id=466…
Repo: github.com/oug-t/zswee…
简单来说,Zsweep 是一个 Vim 键位驱动的扫雷游戏。
它的灵感来源有两个:
h j k l 的肌肉记忆延伸到游戏里。所以 Zsweep 的设计哲学就是:极简 UI + 极致手速 + 全键盘操作。
作为一个全栈项目,我没有选择我最熟悉的 React,而是选择了 SvelteKit,搭配 Supabase。
Svelte 真的太爽了。在这个项目里,我深刻体会到了“Write less code”的含义。
transition 和 animate 指令,让我几行代码就实现了“踩雷”时的屏幕震动和结算界面的数字跳动效果。因为是独立开发,我不想花时间在配运维环境上。Supabase 提供了 PostgreSQL 数据库和开箱即用的 Auth(认证)服务。
虽然是扫雷,但为了追求极致体验,我在数据处理上花了不少心思。
传统的扫雷只看时间,但不同难度的雷数不一样。为了衡量玩家的真实水平,我参考了 Monkeytype 的 WPM (Words Per Minute),设计了 Mines/Min (每分钟扫雷数) 指标。
(也implement了3BV,但考虑到time mode,还需后续更新)
这里有个坑:如果是通过点击复位(重开)太快,可能会导致除以零或者时间极短的数据异常。 我在前端加了一个健壮的计算逻辑:
TypeScript
// 核心计算逻辑片段
if (timeTaken > 0) {
const minesPerMin = parseFloat(((mines / timeTaken) * 60).toFixed(1));
// 只有当成绩更优时才更新本地的最佳记录
if (!calculatedBests[cat] || minesPerMin > calculatedBests[cat].value) {
calculatedBests[cat] = {
value: minesPerMin,
date: g.created_at
};
}
}
为了做 Leaderboard,我利用 Supabase 的 Foreign Key 把 game_results 表和 profiles 表关联起来。
刚才上线后发现一个小插曲:数据库里出现了一些 0秒 的通关记录(大概是调试时的残留数据,或者是 API 被人用 Postman 刷了)。
为了保证公平,我在后端查询时加了严格的过滤器,利用 SQL 直接过滤掉异常数据:
TypeScript
const { data } = await supabase
.from('game_results')
.select('time, profiles(username)')
.eq('win', true)
.gt('time', 0) // 过滤掉 0s 的异常数据
.order('time', { ascending: true })
.limit(50);
现在,排行榜终于干净了,还能显示“Your Rank”高亮自己的排名。(下一个PR,的ploy)
这次冲上 Hacker News 第 5 名,给我最大的启示是:不要等到项目完美了才发布。
Zsweep 其实还有很多 Issues(比如之前的 Joined Date 显示 Invalid Date,刚刚才修好 😂),UI 也不够完美。但因为它解决了一个小痛点(想用 Vim 玩游戏),并且做得足够简单纯粹,就获得了很多开发者的喜爱。
目前项目完全开源,如果你对 Svelte、Vim 或者扫雷感兴趣,欢迎来 GitHub 给个 Star,或者提 PR 一起改进它!
如果你也喜欢 Vim 或者 Svelte,欢迎在评论区交流!
Vue 基于 MVVM 模式设计,核心是实现视图与数据的解耦,三者关系如下:
| 模块 | 核心职责 |
|---|---|
| Model | 数据层,负责业务数据处理(纯数据,无视图交互逻辑) |
| View | 视图层,即用户界面(仅展示内容,不处理数据逻辑) |
| ViewModel | 桥梁层,连接 View 和 Model,包含两个核心能力: ✅ DOM Listeners:监听 View 中 DOM 变化,同步到 Model ✅ Data Bindings:监听 Model 中数据变化,同步到 View |
关键:View 和 Model 不能直接通信,必须通过 ViewModel 中转,实现解耦。
| 特性 | 具体说明 | 示例/应用场景 |
|---|---|---|
| 数据驱动视图 | 数据变化自动触发视图重新渲染,无需手动操作 DOM | 修改变量值 → 页面自动更新 |
| 双向数据绑定 | 视图变化 ↔ 数据变化双向同步 | 表单输入框内容自动同步到数据变量 |
| 指令 | 分内置指令(Vue 自带)和自定义指令,以v-开头绑定到 DOM 元素 |
v-bind(单向绑定)、v-if(条件渲染)、v-for(列表渲染) |
| 插件 | 支持扩展功能,配置简单 | VueRouter(路由)、Pinia(状态管理) |
| 维度 | Vue3 变化 |
|---|---|
| 新增功能 | 组合式(Composition)API、多根节点组件、底层渲染/响应式逻辑重构(性能提升) |
| 废弃功能 | 过滤器(Filter)、$on()/$off()/$once() 实例方法 |
| 兼容性 | 兼容 Vue2 绝大多数 API,新项目推荐直接使用 Vue3 |
# Yarn 方式(推荐)
yarn create vite hello-vite --template vue
# 交互提示处理(关键步骤,不要遗漏):
# 1. 提示 "Use rolldown-vite (Experimental)?" → 回车选 No(优先使用稳定版)
# 2. 提示 "Install with yarn and start now?" → 回车选 Yes(自动安装依赖并启动项目)
# npm 方式
npm create vite@latest
# yarn 方式
yarn create vite
# 后续需手动填写项目名称、选择框架(Vue)、选择变体(JavaScript)
hello-vite/ # 项目根目录
├── node_modules/ # 第三方依赖包(自动生成)
├── dist/ # 构建产物(执行 yarn build 后生成,用于部署)
├── src/ # 源代码目录(开发核心)
│ ├── assets/ # 静态资源(图片、样式等)
│ ├── components/ # 自定义组件
│ ├── App.vue # 根组件
│ ├── main.js # 项目入口文件
│ └── style.css # 全局样式
├── index.html # 页面入口文件
└── package.json # 项目配置(依赖、脚本命令)
<!doctype html>
<html lang="en">
<head>
<meta charset="UTF-8" />
<link rel="icon" type="image/svg+xml" href="/vite.svg" />
<meta name="viewport" content="width=device-width, initial-scale=1.0" />
<title>hello-vite</title>
</head>
<body>
<!-- Vue 实例挂载容器:被 main.js 中的 Vue 实例控制 -->
<div id="app"></div>
<!-- type="module":启用 ES6 模块化语法,引入项目入口文件 -->
<script type="module" src="/src/main.js"></script>
</body>
</html>
// 从 Vue 中导入创建应用实例的核心函数
import { createApp } from 'vue'
// 导入全局样式文件
import './style.css'
// 导入根组件(App.vue)
import App from './App.vue'
// 方式1:简洁写法(创建实例 + 挂载到 #app 容器)
createApp(App).mount('#app')
// 方式2:分步写法(更易理解,效果一致)
// const app = createApp(App) // 创建 Vue 应用实例
// app.mount('#app') // 挂载实例(仅可调用一次)
<!-- script setup:Vue3 组合式 API 语法糖,简化组件编写 -->
<script setup>
// 导入子组件(HelloWorld.vue)
import HelloWorld from './components/HelloWorld.vue'
</script>
<!-- template:组件模板结构(视图部分) -->
<template>
<div>
<a href="https://vite.dev" target="_blank">
<img src="/vite.svg" class="logo" alt="Vite logo" />
</a>
<a href="https://vuejs.org/" target="_blank">
<img src="./assets/vue.svg" class="logo vue" alt="Vue logo" />
</a>
</div>
<!-- 使用子组件,传递 msg 属性 -->
<HelloWorld msg="Vite + Vue" />
</template>
<!-- style scoped:样式仅作用于当前组件(通过 Hash 隔离,不影响子组件) -->
<style scoped>
.logo {
height: 6em;
padding: 1.5em;
will-change: filter;
transition: filter 300ms;
}
.logo:hover {
filter: drop-shadow(0 0 2em #646cffaa);
}
.logo.vue:hover {
filter: drop-shadow(0 0 2em #42b883aa);
}
</style>
yarn create vite 项目名 --template vue 命令;mount() 方法仅可调用一次,挂载目标可以是 DOM 元素或 CSS 选择器(#app/.app);<style scoped> 样式仅作用于当前组件,避免样式污染;$on/$off/$once 等功能,开发时需避开。HarmonyKit 是一个基于 ArkTS + ArkUI 的 HarmonyOS 快速开发框架,内置网络、分页、数据库、状态管理、导航、屏幕适配等常用能力,支持深色模式、国际化、多端适配,欢迎一起学习交流。
如果项目对你有帮助,请给个 Star 支持 ⭐ 这对我来说很重要,能给我带来长期更新维护的动力!
项目地址:GitHub | Gitee 在线文档:harmony.dusksnow.top
💡 说明:框架提供了多种示例页面,展示各项能力的使用方式,支持手机、折叠屏、平板等多种设备形态。
HarmonyKit 采用模块化分层架构,参考官方最佳实践,从上到下分为三层:
@Builder 入口data 模块内的仓库作为统一数据入口data 负责整合 network、database、datastore
架构图来自华为官方文档:分层架构设计
| 类别 | 技术选型 | 说明 |
|---|---|---|
| 编程语言 | ArkTS | HarmonyOS NEXT 主流语言 |
| UI 框架 | ArkUI | 声明式 UI 框架 |
| 架构模式 | MVVM | View + ViewModel 分离 |
| 状态管理 | V2(ObservedV2/AppStorageV2) | 新版状态管理能力 |
| 数据库 | IBest-ORM | 本地数据库能力 |
| 组件库 | IBest-UI-V2 | 业务组件库与基础控件封装 |
基于 Axios 的网络请求封装,采用 DataSource → Repository → ViewModel 三层架构,框架自动处理错误、loading、toast 等通用逻辑。
功能特性:
使用案例:
@ObservedV2
export default class NetworkRequestViewModel extends BaseViewModel {
private repository: GoodsRepository = new GoodsRepository();
// 只需传递仓库方法,框架自动处理错误
requestGoodsDetail() {
RequestHelper.repository<Goods>(this.repository.getGoodsInfo("1"))
.loading(true) // 请求过程显示 loading
.toast(true) // 业务失败自动弹出 toast
.execute()
.then((data: Goods): void => {
// 只需处理成功逻辑
console.log("商品详情:", data);
});
}
}
单次请求场景(自动处理加载、错误、成功状态):
// ViewModel 继承 BaseNetWorkViewModel
@ObservedV2
export default class NetworkDemoViewModel extends BaseNetWorkViewModel<Goods> {
private repository: GoodsRepository = new GoodsRepository();
// 只需实现这一个方法
protected requestRepository(): Promise<NetworkResponse<Goods>> {
return this.repository.getGoodsInfo("1");
}
}
// 页面使用 BaseNetWorkView 自动处理状态
@ComponentV2
export struct NetworkDemoPage {
@Local
private vm: NetworkDemoViewModel = new NetworkDemoViewModel();
build() {
AppNavDestination({
title: "网络请求示例",
viewModel: this.vm
}) {
// 框架自动处理加载、错误、成功状态、重试逻辑
BaseNetWorkView({
uiState: this.vm.uiState,
onRetry: (): void => this.vm.retryRequest(),
content: (): void => this.NetworkDemoContent()
});
}
}
// 请求成功后渲染内容
@Builder
private NetworkDemoContent() {
Column() {
Text(this.vm.data?.title ?? "")
Text(this.vm.data?.subTitle ?? "")
}
}
}
统一封装分页列表的加载、刷新、空态、错误处理,开发者只需关心数据请求和列表渲染。
功能特性:
ViewModel 实现:
@ObservedV2
export default class NetworkListDemoViewModel extends BaseNetWorkListViewModel<Goods> {
private repository: GoodsRepository = new GoodsRepository();
// 只需实现这一个方法
protected requestListData(): Promise<NetworkResponse<NetworkPageData<Goods>>> {
const request: GoodsSearchRequest = new GoodsSearchRequest();
request.page = this.currentPage; // 框架自动管理页码
request.size = this.pageSize; // 框架自动管理每页数量
return this.repository.getGoodsPage(request);
}
}
页面使用:
@ComponentV2
export struct NetworkListDemoPage {
@Local
private vm: NetworkListDemoViewModel = new NetworkListDemoViewModel();
private listScroller: Scroller = new Scroller();
build() {
AppNavDestination({
title: "分页列表示例",
viewModel: this.vm
}) {
// 框架自动处理加载、错误、空态
BaseNetWorkListView({
uiState: this.vm.uiState,
onRetry: (): void => this.vm.retryRequest(),
content: (): void => this.NetworkListDemoContent()
});
}
}
@Builder
private NetworkListDemoContent() {
// 框架自动处理下拉刷新和上拉加载
RefreshLayout({
scroller: this.listScroller,
loading: this.vm.isLoading,
isEnableSlideUp: this.vm.isEnableSlideUp,
onRefresh: (direction): void => this.vm.onRefreshDirection(direction)
}) {
List({ space: 12, scroller: this.listScroller }) {
ForEach(this.vm.listData, (item: Goods) => {
ListItem() {
Text(item.title);
}
}, (item: Goods) => `${item.id}`);
}
.width("100%")
.height("100%");
}
}
}
使用步骤:
BaseNetWorkListViewModel<T> 并实现 requestListData()
BaseNetWorkListView 包住列表内容RefreshLayout 处理下拉刷新和上拉加载具体实现代码,请参考:分页列表文档
基于 V2 状态管理(AppStorageV2/PersistenceV2)实现全局状态共享。
功能特性:
@Trace 自动触发 UI 更新)状态定义:
// 定义状态类
@ObservedV2
export class DemoCounterState {
@Trace count: number = 0; // @Trace 标记的字段会自动触发 UI 更新
increment(): void {
this.count++;
}
}
// 获取全局状态实例
export function getDemoCounterState(): DemoCounterState {
return AppStorageV2.connect<DemoCounterState>(
DemoCounterState,
"demo_counter_state",
() => new DemoCounterState()
)!;
}
使用案例:
@ObservedV2
export default class StateManagementViewModel extends BaseViewModel {
@Trace
counterState: DemoCounterState = getDemoCounterState(); // 获取全局状态
increment(): void {
this.counterState.increment(); // 调用状态方法,UI 自动更新
}
}
具体实现代码,请参考:状态管理文档
统一管理路由注册、页面跳转、参数传递与结果回传。
功能特性:
路由定义:
// 路由常量
export const DemoRoutes = {
NavigationWithArgs: "demo/navigation-with-args",
NavigationResult: "demo/navigation-result"
};
// 参数定义
export interface DemoGoodsParam {
goodsId: number;
goodsName: Resource;
}
// 返回结果定义
export interface DemoResult {
title: string;
description: string;
}
Navigator 封装(推荐):
export class DemoNavigator {
// 带参跳转
static toNavigationWithArgs(goodsId: number, goodsName: Resource): void {
const params: DemoGoodsParam = { goodsId, goodsName };
navigateTo(DemoRoutes.NavigationWithArgs, params);
}
// 结果回传
static toNavigationResult(): Promise<DemoResult | undefined> {
return navigateToForResult<DemoResult>(DemoRoutes.NavigationResult);
}
}
使用案例:
// 发起方:跳转并等待结果
@ObservedV2
export default class CallerViewModel extends BaseViewModel {
openResultPage(): void {
DemoNavigator.toNavigationResult()
.then((result?: DemoResult): void => {
if (result) {
console.info("返回结果:", result.title);
}
});
}
}
// 目标页:获取参数
@ObservedV2
export default class TargetViewModel extends BaseViewModel {
routeParams: DemoGoodsParam = getRouteParams<DemoGoodsParam>(DemoRoutes.NavigationWithArgs);
}
// 目标页:返回结果
@ObservedV2
export default class ResultViewModel extends BaseViewModel {
submitResult(): void {
const result: DemoResult = {
title: "标题",
description: "说明"
};
navigateBackWithResult(result);
}
}
具体实现代码,请参考:导航管理文档
完整的屏幕适配方案,支持手机、折叠屏、平板等多种设备形态。
功能特性:
bp()
断点规则:
| 断点 | 说明 | 最大宽度(vp) |
|---|---|---|
XS |
超小屏 | 320 |
SM |
小屏 | 600 |
MD |
中屏 | 840 |
LG |
大屏 | Infinity |
网格布局适配:
import { bp } from "state";
@Builder
private GridSection(): void {
Grid() {
// ... 数据循环
}
// 小屏2列,中屏3列,大屏4列
.columnsTemplate(bp({ sm: "1fr 1fr", md: "1fr 1fr 1fr", lg: "1fr 1fr 1fr 1fr" }))
.width("100%");
}
文本适配:
import { bp } from "state";
@Builder
private TextAdaptSection(): void {
Text("大屏适配示例文字")
.fontSize(bp({ sm: 16, md: 20, lg: 28 }));
}
Tab 栏大屏位置调整:
import { BreakpointState, getBreakpointState } from "state";
@ComponentV2
export struct MainPage {
@Local
private breakpointState: BreakpointState = getBreakpointState();
@Builder
private MainContent(): void {
Tabs({
// 大屏时 Tab 栏在左侧,小屏时在底部
barPosition: this.breakpointState.isLG() ? BarPosition.Start : BarPosition.End,
}) {
// ... 页面内容
}
.barWidth(this.breakpointState.isLG() ? 96 : "100%")
.vertical(this.breakpointState.isLG());
}
}
安全区适配:
框架默认使用全局安全区进行页面内边距避让,AppNavDestination 已自动处理。
@ComponentV2
export struct SafeAreaDemoPage {
@Local
private vm: SafeAreaDemoViewModel = new SafeAreaDemoViewModel();
build(): void {
// AppNavDestination 默认启用安全区
AppNavDestination({
title: "安全区示例",
viewModel: this.vm
}) {
Text("内容会自动避让安全区");
};
}
}
如需自定义安全区:
AppNavDestination({
title: "自定义安全区",
viewModel: this.vm,
paddingValue: { top: 0, left: 0, right: 0, bottom: 0 }
}) {
Text("自定义内边距");
}
基于 IBest-ORM 的本地数据库能力,采用 DataSource → Repository 架构,业务层通过 Repository 访问数据库。
实体定义:
@Table({ name: "demo_items" })
export class DemoEntity {
@PrimaryKey({ autoIncrement: true })
id?: number;
@Column({ type: ColumnType.TEXT })
title?: string;
@CreatedAt()
createdAt?: string;
}
使用案例:
@ObservedV2
export default class DatabaseViewModel extends BaseViewModel {
private demoRepository: DemoRepository = new DemoRepository();
// 保存记录
async save(): Promise<void> {
await this.demoRepository.createDemo(this.titleInput, this.descInput);
}
// 获取所有记录
async fetchList(): Promise<void> {
const list = await this.demoRepository.getAll();
// 处理列表数据
}
}
具体实现代码,请参考:数据库文档 | IBest-ORM 文档
基于 Preferences 的轻量级本地存储,采用 DataSource → Repository 架构,业务层通过 Repository 访问存储数据。
使用案例:
@ObservedV2
export default class LocalStorageViewModel extends BaseViewModel {
private repository: AccountStoreRepository = new AccountStoreRepository();
// 保存账号
async saveAccount(): Promise<void> {
await this.repository.saveAccount(this.accountInput);
}
// 读取账号
async loadAccount(): Promise<void> {
this.storedAccount = await this.repository.loadAccount();
}
}
具体实现代码,请参考:本地存储文档
框架内置了常用的工具类,避免业务层重复造轮子:
具体使用方法,请参考:工具类文档
AppScope/ # 应用配置
entry/ # 应用入口模块
core/ # 核心模块
│ ├── base/ # 基类
│ ├── data/ # 数据层
│ ├── database/ # 数据库
│ ├── datastore/ # 数据存储
│ ├── designsystem/ # 设计系统
│ ├── ibestui/ # IBest UI 组件库
│ ├── model/ # 数据模型
│ ├── navigation/ # 导航
│ ├── network/ # 网络层
│ ├── result/ # 结果处理
│ ├── state/ # 全局状态
│ ├── ui/ # UI 组件
│ └── util/ # 工具类
feature/ # 功能模块
│ ├── auth/ # 认证模块
│ ├── demo/ # 示例模块
│ ├── main/ # 主模块
│ └── user/ # 用户模块
相关资源:
相关项目:
HarmonyKit 源于 青商城(HarmonyOS) 的实践,如果你想查看完整的电商业务实现:
如果这个项目对你有帮助,请给个 ⭐ Star 支持!
- GitHub:github.com/Joker-x-dev…
- Gitee:gitee.com/Joker-x-dev…
作为前端开发,npm install 天天用,但这行简单的命令背后,npm 其实按固定流程把依赖安装的事安排得明明白白!不用深究底层原理,这篇文章用最直白的话讲清核心步骤,看完秒懂,轻松解决日常安装依赖的小问题~
执行 npm install 后,npm 第一步不下载,先查找项目和系统的配置文件(比如.npmrc),确定这些关键信息:
node_modules)简单说,就是先“定规矩”,再开始干活~
这是整个安装流程的关键分叉口,npm 会先检查项目根目录有没有package-lock.json文件(依赖版本快照,记录上一次安装的精确依赖信息),分两种情况处理,核心都是为了保证版本一致、提升安装速度。
先校验版本一致性
检查lock文件里的依赖版本,是否符合package.json里的版本范围(比如package.json写^2.0.0,lock文件里2.1.0、2.2.0都算符合)。
符合:按lock文件的精确版本继续;
不符合:忽略旧lock文件,按package.json重新处理。
拉取包信息,构建并扁平化依赖树
按lock文件的信息,从镜像源获取依赖的元数据,接着构建依赖树(项目依赖的包是一级依赖,包又依赖的包是二级依赖,以此类推)。
关键操作扁平化处理:把能共享的子依赖提升到node_modules根目录,避免层级过深、重复安装,省空间又快!
缓存判断,安装依赖+更新lock文件
node_modules,不用重新下载;node_modules;
最后更新lock文件,保证快照最新。没有lock文件就简单了,直接按package.json来,步骤少了版本校验,其余和上面一致:
拉取远程包信息→构建并扁平化依赖树→缓存判断(有则解压,无则下载+存缓存)→解压到node_modules→生成全新的lock文件,为下一次安装留好精确版本快照。
输入 npm install → 查找并加载配置文件(.npmrc 等)
→ 检查项目根目录是否有 package-lock.json?
→ 是 → 校验 lock 文件与 package.json 版本是否一致?
→ 一致 → 拉取远程包信息 → 构建依赖树(扁平化)→ 检查缓存?
→ 有 → 解压缓存到 node_modules → 更新 lock 文件
→ 无 → 下载依赖 → 校验完整性 → 存入缓存 → 解压到 node_modules → 更新 lock 文件
→ 不一致 → 按 package.json 重新拉取包信息 → 构建依赖树(扁平化)→ 缓存判断与安装 → 生成/更新 lock 文件
→ 否 → 拉取远程包信息(基于 package.json)→ 构建依赖树(扁平化)→ 缓存判断与安装 → 生成 lock 文件
→ 安装完成
下
缓存是npm提速的关键,第一次下载的包会存起来,后续安装直接复用。如果遇到安装报错、包损坏,执行npm cache clean --force强制清缓存,重新安装大概率解决。
这个文件是团队协作、生产环境的“版本保障”,删了重新安装可能导致依赖版本变化,项目出问题。真要改版本,先改package.json,再重新npm install自动更新lock文件。
大家好,我是一个写了多年 TypeScript 的前端开发老鸟。今天,我要和大家分享一些关于 TypeScript 的最佳实践。这些经验都是我在无数次踩坑后总结出来的,希望能让你少走弯路,直接成为 TypeScript 的大佬。当然,分享的过程也不会枯燥无味,毕竟编程嘛,开心最重要!
如果你是第一次听说 TypeScript,可能会有点懵:“TypeScript?这名字听起来好高大上,但到底是啥?”
简单来说,TypeScript 是 JavaScript 的超集,它在 JS 的基础上增加了静态类型检查。这就像在你写代码的时候,有一个贴心的“保姆”在旁边提醒你:“嘿,这个变量类型不对哦!”或者“你确定这个函数会返回一个数字吗?”有了 TypeScript,你就可以在写代码时减少很多低级错误。
不过,TypeScript 也有一个“坑爹”的地方——它太严格了!刚开始用的时候,你可能会觉得自己被绑手绑脚。但慢慢地,你会发现,这种“严格”其实是对你的爱啊!它能帮你写出更健壮、更安全的代码。
在正式开始之前,我们先来了解几个基础概念。如果你已经是老手,可以直接跳过这一节(但我猜你不会,因为我的文章这么有趣)。
TypeScript 最核心的就是类型。它会让你的代码变得更加清晰,比如:
let age: number = 25; // age 是一个数字
let name: string = '小明'; // name 是一个字符串
let isHappy: boolean = true; // isHappy 是一个布尔值
看起来是不是很简单?但如果你写成这样:
let age: number = '25'; // 报错!字符串不能赋值给数字类型
TypeScript 会立刻跳出来:“兄弟,你是不是写错了?”这就是它的魅力——帮你在开发阶段就发现问题,而不是等到线上出 bug 再被产品经理追着打。
接口是 TypeScript 的另一大杀手锏。它可以用来定义对象的结构,比如:
interface Person {
name: string;
age: number;
}
const student: Person = {
name: '小红',
age: 18,
};
如果你少写了某个属性,比如 age,TypeScript 会立刻报警:“喂,你是不是忘了啥?”
泛型听起来很高深,但其实很好理解。它就像一个“模板”,可以让你的代码更加灵活,就像你去买衣服,商家告诉你“这衣服是均码的,胖瘦高矮都能穿”,这就是泛型的核心思想。例如:
function getArray<T>(items: T[]): T[] {
return items;
}
const numberArray = getArray<number>([1, 2, 3]);
const stringArray = getArray<string>(['a', 'b', 'c']);
是不是感觉很厉害?用泛型,你可以写出更加通用的代码。
了解了基础概念后,我们来聊聊一些实用的技巧。这些都是我踩过无数坑后总结出来的,希望对你有帮助。
TypeScript 有一个选项叫 strict,默认是关闭的。但我建议你一定要打开!为什么呢?因为严格模式会让 TypeScript 更加“挑剔”,从而帮你发现更多潜在问题。
在 tsconfig.json 中设置:
{
"compilerOptions": {
"strict": true
}
}
刚开始可能会有点痛苦,因为 TypeScript 会疯狂地指出你的错误。但相信我,这种痛苦是值得的。久而久之,你会发现自己的代码质量提升了一大截!
any,但不要滥用any 是 TypeScript 中的“万金油”类型,它可以接受任何值,比如:
let something: any = 'hello';
something = 42; // 完全没问题!
虽然 any 用起来很爽,但千万不要滥用!因为一旦用了 any,TypeScript 的类型检查就失效了。正确的姿势是:只在万不得已时才用 any,尽量用更具体的类型替代它。
TypeScript 的一个优点是,它会自动推断变量的类型。例如:
let count = 10; // TS 自动推断 count 是 number 类型
所以,很多时候你不需要显式地写出类型声明。这样不仅减少了代码量,还能让代码看起来更简洁。
有时候,一个变量可能有多种类型。比如:
function printId(id: number | string) {
if (typeof id === 'string') {
console.log('ID 是字符串:' + id.toUpperCase());
} else {
console.log('ID 是数字:' + id.toFixed(2));
}
}
这叫做联合类型,而通过 typeof 判断类型的过程叫做类型保护。它能让你的代码更加安全和灵活。
接下来,我们聊聊 TypeScript 自带的一些“黑科技”——内置类型。它们就像超市里的速食食品,直接拿来用,省时省力。以下是几个常用的“明星选手”:
Required<T>:让你的属性变得“必填”有时候,你定义了一个对象,但某些属性是可选的(用 ? 标记)。突然有一天,老板说:“不行!这些属性必须全都有!”这时候你就可以用 Required<T>。
interface User {
name?: string;
age?: number;
}
const user1: Required<User> = {
name: "小明",
age: 18,
}; // 如果少填一个属性,TS 就会报错
Required<T> 的作用就是把所有可选属性变成必填属性。老板再也不会在代码审查时拍桌子了!
Omit<T, K>:精确剪裁对象假如你有一个大对象,但有些属性你不想要(比如老板要求的数据统计字段),这时候 Omit<T, K> 就派上用场了。
interface User {
id: number;
name: string;
password: string;
}
type PublicUser = Omit<User, "password">;
const user2: PublicUser = {
id: 1,
name: "小红",
}; // password 被成功“剪掉”!
Omit<T, K> 的作用就是从对象中“剔除”某些属性。想象一下,你在剪菜叶,把不想要的部分丢掉,只留下精华部分。
Record<K, T>:快速生成对象类型你有没有遇到过这种情况:需要定义一个对象,但键和值的类型都要严格控制?这时候 Record<K, T> 就是你的救星!
type Role = "admin" | "user" | "guest";
const permissions: Record<Role, string[]> = {
admin: ["create", "read", "update", "delete"],
user: ["read", "update"],
guest: ["read"],
};
Record<K, T> 的意思是:“我有一堆键(K),每个键对应的值都是某种类型(T)。”简直就是批量生产对象类型的神器!
Partial<T>:让你的属性变得“随意”跟 Required<T> 相反,Partial<T> 可以把每个属性变成可选的。适合那种“随便填点啥”的场景。
interface User {
name: string;
age: number;
}
const user3: Partial<User> = {
name: "小刚",
}; // age 可以不写
Partial<T> 的存在,就像一碗加了水的粥——稀释了约束,但更灵活!
Pick<T, K>:精准挑选如果 Omit 是剪掉不要的东西,那 Pick 就是挑出想要的东西。比如,你只关心用户的名字和年龄,不在乎其他字段:
interface User {
id: number;
name: string;
age: number;
}
type UserInfo = Pick<User, "name" | "age">;
const user4: UserInfo = {
name: "小强",
age: 25,
};
Pick<T, K> 的作用就是从对象中精准挑出你需要的字段。就像点菜一样,只点自己爱吃的,不浪费!
虽然 TypeScript 很强大,但它也有不少坑等着你跳。以下是几个常见的“雷区”,希望你能绕开。
有时候,为了追求完美,我们可能会写出非常复杂的类型定义,比如:
type ComplexType = { a: string } & { b: number } & { c: boolean };
这种类型虽然看起来很酷,但维护起来非常麻烦!所以,尽量保持简单,别给自己挖坑。
当你使用第三方库时,如果没有为它们提供类型定义文件(.d.ts),TypeScript 就无法进行类型检查。这时候,你可以去 DefinitelyTyped 找找看有没有对应的定义文件。如果没有,就自己动手丰衣足食吧!
类型断言是告诉 TypeScript:“相信我,我知道这个变量的真实类型。”比如:
let someValue: any = 'hello';
let strLength: number = (someValue as string).length;
虽然类型断言很好用,但滥用它可能会导致灾难性的后果!所以,在使用之前,一定要确保你的断言是正确的。
TypeScript 就像一把双刃剑,用得好,它能帮你写出更优雅、更安全的代码;用得不好,它也能让你抓狂到想砸键盘。但不管怎么说,学习 TypeScript 是一个非常值得投入时间和精力的事情。
最后,我送大家一句话:“学 TypeScript 就像谈恋爱,一开始觉得麻烦,但时间久了就离不开了。”
希望这篇文章能帮到想入门 TypeScript 的同学。如果你还有其他问题,欢迎留言,我们一起交流、一起成长!
前言
在上一篇方案篇中,我们构思了“AI 逻辑沙盒”的双层宏契约:通过 define 与 apply 模式,将 AI 的破坏半径锁死在受限的环境中。
但架构设计如果不落实为自动化工具,就只是纸上谈兵。在 2026 年的开发环境下,我们追求的是 “开发态极高压约束,运行态零开销脱离” 。今天,我们进入深水区,探讨如何利用 TypeScript Compiler API、ESLint 定制规则以及编译时宏处理,将这套逻辑打造成一套闭环的自动化准入体系。
一、 自动化基石:从“宏声明”到“规则映射”
手动维护每个 AI 文件夹的配置是不可持续的。我们的目标是:架构师修改一行 TS 类型定义,工程环境自动完成“布防”。
我们需要编写一个 Node.js 脚本(利用 ts-morph 或 SWC 的解析能力),专门扫描宿主侧的权限声明。
核心逻辑:
defineEnvContext<T> 调用的位置。T 中的属性。例如,如果 T 是 Pick<Window, 'addEventListener' | 'removeEventListener'>,脚本将提取出 window 及其成对的授权属性。这种成对授权是必须的,它确保了 AI 具备清理副作用的能力,从根源规避内存泄露。
defineImportContext<T> 中定义的外部模块映射路径。脚本扫描完成后,会立即在对应的 AI 逻辑沙盒 文件夹下生成/更新两个关键的“围墙”文件:
生成 .eslintrc.js:
必须设置 root: true。这是为了彻底切断父级目录中可能存在的“宽松规则”干扰,确保沙盒规则的纯净。
javascript
// /src/ai_modules/xxx/.eslintrc.js
module.exports = {
root: true, // 核心:断绝父级规则合并,建立独立“法律体系”
env: {
browser: false, // 禁用默认环境,防止隐式逃逸
es2022: true
},
rules: {
"no-undef": "error", // 配合抹除 DOM 库,禁止直接访问全局变量
// 这里的 "error" 是等级(Severity),确保任何违规代码都无法通过编译
"no-restricted-globals": ["error", "window", "document", "location", "localStorage"],
"no-restricted-syntax": [
"error",
{
// 仅允许从我们的宏解构出的变量,禁止绕过宏直接调用
"selector": "VariableDeclarator[init.callee.name='applyEnvContext'] > ObjectPattern > Property",
"message": "解构变量未在宿主 define 宏中授权。"
}
]
}
};
请谨慎使用此类代码。
生成 tsconfig.json:
通过 compilerOptions.paths 将全局类型重定向到我们生成的受限 .d.ts 定义,确保 AI 编写时 IDE 提示仅包含被 Pick 出来的安全属性。
二、 编译时魔法:宏的“彻底消失术”
宏(Macros)的本质是“开发态的严格约束,生产态的纯净幻觉”。在构建阶段,我们需要通过编译器插件进行物理处理。
1. applyEnvContext 的运行时脱除
这是方案最优雅之处:由于宿主环境天然存在全局对象,我们只需要在编译时把宏“删掉”即可。
const { window } = applyEnvContext<GlobalApi>();
const { window } = globalThis;(或直接物理移除,让变量引用回退到原生全局访问)。2. applyImportContext 的逻辑提升
与环境宏不同,第三方模块需要真实的引入逻辑。
import debounce from 'lodash/debounce',随后删除原始宏调用行。三、 防御性审计:如何防止 AI “逃逸”?
AI 可能会尝试利用先验知识,通过 window['loc' + 'ation'] 这种手段绕过静态拦截。为此,我们在 AI 逻辑沙盒 内实施 “零信任审计” :
MemberExpression 的计算属性访问,强制要求 API 调用必须是静态可见的。import。所有依赖必须通过 applyImportContext 申请。define 授权的属性,构建将直接阻断。四、 架构总结:将权力关进“基建”的笼子
至此,我们构建了一套完整的 AI 原生工程治理流水线:
define 宏拨发微小的、经过 Pick 裁剪的权限。root: true 的 ESLint 规则与 TSConfig。apply 宏行使能力。在这种架构下,人担责的压力被降到了最低。 你不再需要死磕业务逻辑,只需要审计那几行“契约”。例如: “AI 申请了 addEventListener 但没有申请 removeEventListener,这是否会引入内存风险?” 这种基于权限边界的审计,才是真正的高效。
结语
「AI 逻辑沙盒」不仅是一套工具,它代表了我们在 2026 年对防御性编程的终极实践。
我们正处在一个分水岭:一边是 Vibe Coding 带来的生产力狂欢,一边是工程严谨性的崩塌。而这套方案试图在两者之间架起一座桥梁:用最硬核的基建,去拥抱最不确定的 AI 生产力。
感谢阅读系列文章《AI 原生工程:逻辑沙盒与零信任代码治理》。这场关于 AI 准入的革命,才刚刚开始。
本想学习下vue3 的后台管理项目, 借鉴了vbtn-admin github地址 线上地址, 颜值在线, 但是封装太骚了改代码太累。就自己额外处理了下。
做到简单易懂 开箱即用
这是一个前后端分离的 monorepo 示例项目,使用 pnpm workspace 管理前端(Vite + Tailwind + shadcn-ui)和后端(Node/Express 或自定义后端)。
.
├── 📁 backend/ # 后端项目
├── 📁 frontend/ # 前端项目
├── 📄 deploy.sh # 部署脚本
├── 📄 pnpm-lock.yaml # pnpm 锁文件
└── 📄 pnpm-workspace.yaml # pnpm 工作区配置
git clone https://github.com/hangfengnice/vite-admin-ele.git
cd vite-admin-ele
npm install -g pnpm
pnpm install
#同时启动前后端
pnpm run all
#启动前端
pnpm run dev
# 或者
pnpm --filter frontend dev
#启动后端
pnpm run back
# 或者
pnpm --filter backend dev
# 使用 chmod 添加执行权限(第一次)
chmod +x deploy.sh
# 部署
./deploy.sh
阿里云需要装
# 镜像 Ubuntu Server 24.04 LTS
# 安装 Node.js 24 LTS
curl -fsSL https://deb.nodesource.com/setup_24.x | bash -
sudo apt install -y nodejs
# 安装 PM2
sudo npm install -g pm2
# 安装 Nginx
sudo apt install -y nginx
# 安装 myswl
sudo apt install -y mysql-server
# 电脑 mac
# node -v
# v24.12.0
# pnpm -v
# 10.28.1
# 本地额外装了mysql
在 DOM 树中,Element 类型是我们交互最频繁的节点。无论是修改样式、监听焦点,还是动态插入内容,都离不开它。本文将带你系统复习 Element 的核心 API,并揭示一些在实际开发中容易忽略的细节与陷阱。
Element 表示 HTML 中的元素节点。通过 document.createElement() 可以动态创建。
nodeType: 1
nodeName: 返回大写标签名(如 "DIV")。nodeValue: 始终为 null。可以直接通过点语法(.)访问的常见属性:id、title、lang、dir语言的书写方向("ltr"表示从左到右,"rtl"表示从右到左)。
className: 对应 HTML 的 class 属性。由于 class 是 JS 关键字,故属性名做了转换。HTML5 规范了 data- 前缀的自定义属性,通过 dataset 对象可以优雅地读写。
<div id="myDiv" data-app-id="12345"></div>
const div = document.getElementById("myDiv");
// 获取:注意 camelCase 转换(data-app-id -> appId)
console.log(div.dataset.appId);
// 设置
div.dataset.userName = "Nicholas"; // 自动变为 data-user-name="Nicholas"
这是最容易混淆的地方:getAttribute 操作的是 HTML 文档中的特性,而直接赋值操作的是 JS 对象的属性。
| 方法 | 描述 | 特点 |
|---|---|---|
getAttribute(name) |
获取 HTML 特性 | 始终返回字符串;获取类名需传 "class"
|
setAttribute(name, v) |
设置 HTML 特性 | 会同步到 HTML 结构中 |
removeAttribute(name) |
彻底删除特性 | 不仅仅是清空值 |
💡 建议: 对于
id、className等标准属性,直接使用点语法性能更好;对于非标准的自定义属性,使用dataset。
innerHTML: 读写 HTML,会解析标签。注意: 存在 XSS 攻击风险。textContent: 读写纯文本。性能更好且更安全。insertAdjacentText(first,sencond)
second:插入内容first:要插入的位置
beforebegin:插入当前元素前面,作为前一个同胞节点afterbegin:插入当前元素内部,作为新的子节点或放在第一个子节点前面beforeend:插入当前元素内部,作为新的子节点或放在最后一个子节点后面afterend:插入当前元素后面,作为下一个同胞节点相比于 innerHTML += '...'(会导致整个子树重新渲染),insertAdjacentHTML 可以将字符串解析为 DOM 并精确插入,性能极高。
// 语法:element.insertAdjacentHTML(position, html)
element.insertAdjacentHTML("afterbegin", "<span>New Content</span>");
以前我们需要手动操作 className 字符串,现在有了 classList 这个神器。
add(value) : 添加类名。remove(value) : 删除类名。contains(value) : 判断是否存在。toggle(value) : 切换(有则删,无则加)。在处理滚动和布局时,这些属性非常关键。
| 属性 | 包含范围 |
|---|---|
clientWidth / clientHeight |
内容 + 内边距 (Padding) |
offsetWidth / offsetHeight |
内容 + 内边距 + 边框 (Border) |
scrollWidth / scrollHeight |
包含滚动条滚出的隐藏部分的完整尺寸 |
进阶:获取精确位置
getBoundingClientRect() 返回元素相对于浏览器视口的 top, left, right, bottom, width, height。
document.activeElement: 指向当前获得焦点的元素(如正处在输入状态的 input)。element.focus() : 强制让元素获得焦点。let button = document.getElementById("myButton");
button.focus();
console.log(document.activeElement === button); // true
isSameNode() 和 isEqualNode() 有什么区别?参考回答:
isSameNode() (等同于 ===): 检查两个变量是否引用同一个 DOM 实例。isEqualNode(): 检查两个节点是否长得一样(类型相同、属性相同、子节点结构也相同)。innerHTML 插入的 <script> 不会执行?参考回答:
这是浏览器的安全策略。如果需要执行脚本,必须通过 document.createElement('script') 手动创建并插入到文档中。
一个数对 (a,b) 的 数对和 等于 a + b 。最大数对和 是一个数对数组中最大的 数对和 。
(1,5) ,(2,3) 和 (4,4),最大数对和 为 max(1+5, 2+3, 4+4) = max(6, 5, 8) = 8 。给你一个长度为 偶数 n 的数组 nums ,请你将 nums 中的元素分成 n / 2 个数对,使得:
nums 中每个元素 恰好 在 一个 数对中,且请你在最优数对划分的方案下,返回最小的 最大数对和 。
示例 1:
输入:nums = [3,5,2,3] 输出:7 解释:数组中的元素可以分为数对 (3,3) 和 (5,2) 。 最大数对和为 max(3+3, 5+2) = max(6, 7) = 7 。
示例 2:
输入:nums = [3,5,4,2,4,6] 输出:8 解释:数组中的元素可以分为数对 (3,5),(4,4) 和 (6,2) 。 最大数对和为 max(3+5, 4+4, 6+2) = max(8, 8, 8) = 8 。
提示:
n == nums.length2 <= n <= 105n 是 偶数 。1 <= nums[i] <= 105直觉上,我们会认为「尽量让“较小数”和“较大数”组成数对,可以有效避免出现“较大数成对”的现象」。
我们来证明一下该猜想是否成立。
假定 $nums$ 本身有序,由于我们要将 $nums$ 拆分成 $n / 2$ 个数对,根据猜想,我们得到的数对序列为:
$$
(nums[0], nums[n - 1]), (nums[1], nums[n - 2]), ... , (nums[(n / 2) - 1], nums[n / 2])
$$
换句话说,构成答案的数对必然是较小数取自有序序列的左边,较大数取自有序序列的右边,且与数组中心对称。
假设最大数对是 $(nums[i], nums[j])$,其中 $i < j$,记两者之和为 $ans = nums[i] + nums[j]$。
反证法证明,不存在别的数对组合会比 $(nums[i], nums[j])$ 更优:
假设存在数对 $(nums[p], nums[q])$ 与 $(nums[i], nums[j])$ 进行调整使答案更优。
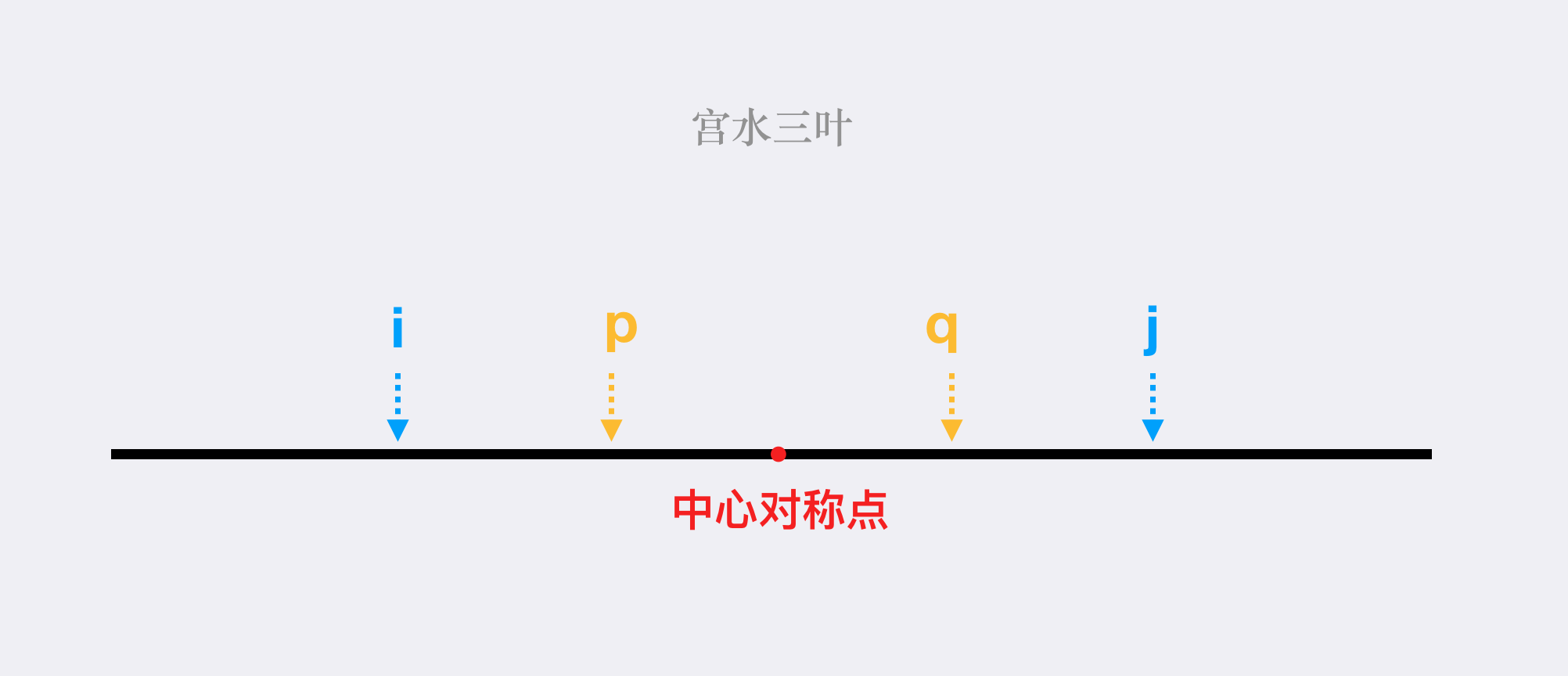
接下来分情况讨论:
上述分析可以归纳推理到每一个“非对称”的数对配对中。
至此我们得证,将原本对称的数对调整为不对称的数对,不会使得答案更优,即贪心解可取得最优解。
对原数组 $nums$ 进行排序,然后从一头一尾开始往中间组「数对」,取所有数对中的最大值即是答案。
代码:
###Java
class Solution {
public int minPairSum(int[] nums) {
Arrays.sort(nums);
int n = nums.length;
int ans = nums[0] + nums[n - 1];
for (int i = 0, j = n - 1; i < j; i++, j--) {
ans = Math.max(ans, nums[i] + nums[j]);
}
return ans;
}
}
关于「证明」部分,不少小伙伴有一些疑问,觉得挺有代表性的,特意加到题解内。
Q1. 「证明」部分是不是缺少了“非对称”得最优的情况?
A1. 并没有,证明的基本思路如下:
猜想对称组数对的方式,会得到最优解;
证明非对称数组不会被对称数对方式更优。
然后我们证明了“非对称方式”不会比“对称方式”更优,因此“对称方式”可以取得最优解。
至于非对称和非对称之间怎么调整,会更优还是更差,我不关心,也不需要证明,因为已经证明了非对称不会比对称更优。
Q2. 证明部分的图 $p$、$q$ 是在 $i$、$j$ 内部,那么其他 $p$、$q$、$i$、$j$ 大小关系的情况呢?
A2. 有这个疑问,说明没有重点理解「证明」中的加粗部分(原话):
上述分析可以归纳推理到每一个“非对称”的数对配对中。
也就是说,上述的分析是可以推广到每一步都成立的,包括第一步,当 $i$ 为排序数组的第一位原始,$j$ 为排序数组中最后一位时,任意 $p$ 和 $q$ 都是在 $i$、$j$ 内部的。
因此,「证明」对边界情况成立,同时对任意不成“对称”关系的数对也成立(其实也就是「证明」部分中的原话)。
更大白话一点是:对于任意“非对称”的数对组合,将其调整为“对称”数对组合,结果不会变差。
如果有帮助到你,请给题解点个赞和收藏,让更多的人看到 ~ ("▔□▔)/
也欢迎你 关注我 和 加入我们的「组队打卡」小群 ,提供写「证明」&「思路」的高质量题解。
所有题解已经加入 刷题指南,欢迎 star 哦 ~
{kind=link}