背景 eslint-plugin-tailwindcss插件的no-unnecessary-arbitrary-value无法对所有的任意值进行校验,比如h-[48px]、text-[#f5f5f5]无法校验出来。但tailwindcss的预设值太多了,一个不小心可能就又写了一个没有必要的任意值。为了避免这种情况,我们需要自己实现一个检测任意值的eslint插件。
首先来看下效果
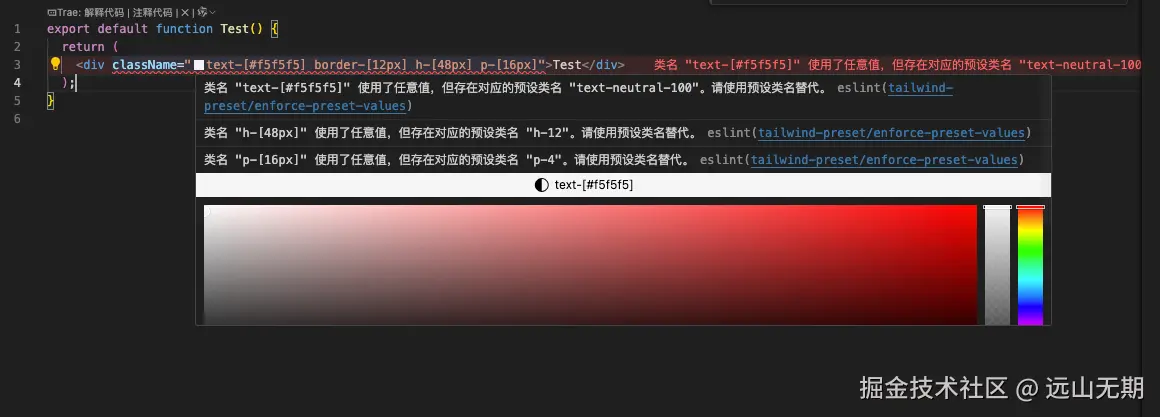
no-unnecessary-arbitrary-value 无法检测的情况

使用自定义的:eslint-plugin-tailwind-no-preset-class插件,完美完成了校验
创建eslint插件标准目录结构
npm install -g yo
- 安装Yeoman generator-eslint
npm install -g generator-eslint
mkdir eslint-plugin-my-plugin
yo eslint:plugin
生成目录结构如下:
eslint-plugin-my-plugin/
├── lib/ # 核心源代码目录
│ ├── index.js # 插件的入口文件,在这里导出所有规则
│ └── rules/ # 存放所有自定义规则的目录
│ └── my-rule.js # 生成器为你创建的一条示例规则文件
├── tests/ # 测试文件目录
│ └── lib/
│ └── rules/
│ └── my-rule.js # 示例规则对应的测试文件
├── package.json # 项目的 npm 配置文件,依赖和元信息都在这里
└── README.md # 项目说明文档
根据实际项目的tailwindcss配置文件和tailwindcss默认配置生成全量定制化配置,用于后续eslint插件的校验依据
实现配置文件生成并加载方法:
// lib/tailwind-config-loader.js
// 配置文件生成
...
...
// 动态加载 Tailwind 预设配置
let tailwindPresetConfig = null;
...
async function generateTailwindConfig(projectRootPath) {
try {
// 动态导入tailwindcss
const resolveConfigModule = await import('tailwindcss/lib/public/resolve-config.js');
const resolveConfig = resolveConfigModule.default.default
// 尝试加载项目配置
let projectConfig = {};
try {
const projectConfigPath = join(projectRootPath||process.cwd(), 'tailwind.config.js');
const projectConfigModule = await import(projectConfigPath);
projectConfig = projectConfigModule.default || projectConfigModule;
} catch (error) {
console.log('⚠️ 未找到项目 tailwind.config.js,使用默认配置');
throw error;
}
// 使用tailwindcss的resolveConfig函数
const finalConfig = resolveConfig(projectConfig);
console.log('✅ Tailwind preset config generated successfully!');
return finalConfig;
} catch (error) {
console.error('❌ 生成Tailwind配置失败:', error.message);
throw error;
}
}
// 加载配置到内存中
async function loadTailwindPresetConfig(projectRootPath) {
if (configLoading) {
console.log('⏳ 配置正在加载中,跳过重复请求');
return;
}
configLoading = true;
try {
// 直接动态生成配置
tailwindPresetConfig = await generateTailwindConfig(projectRootPath);
console.log('✅ Tailwind 预设配置已动态生成并加载');
onConfigLoaded();
} catch (error) {
console.error('❌ 动态生成 Tailwind 预设配置失败:', error.message);
onConfigLoadFailed(error);
throw error;
}
}
...
// 导出配置
export const TailwindConfigLoader = {
getConfig: () => tailwindPresetConfig,
isLoaded: () => configLoaded,
ensureLoaded: ensureConfigLoaded,
reload: loadTailwindPresetConfig,
generateConfig: generateTailwindConfig
};
...
...
创建校验规则函数
...
// 使用 WeakMap 来跟踪每个文件的已报告类名,避免重复报告
const reportedClassesMap = new WeakMap();
...
// 检查并报告
async function checkAndReport(context, node, className) {
// 如果配置尚未加载,尝试等待加载
if (!TailwindConfigLoader.isLoaded()) {
try {
const projectRootPath = context.getCwd();
console.log(`正在等待加载配置文件 ${projectRootPath}...`);
const loaded = await TailwindConfigLoader.ensureLoaded(projectRootPath);
if (!loaded) {
console.warn('⚠️ Tailwind 预设配置尚未加载,跳过检查');
return;
}
} catch (error) {
console.warn('⚠️ 配置加载失败,跳过检查');
return;
}
}
const filePath = context.getFilename();
const filePathWrapper = new FilePathWrapper(filePath);
if (!reportedClassesMap.has(filePathWrapper)) {
reportedClassesMap.set(filePathWrapper, new Set());
}
const reportedClasses = reportedClassesMap.get(filePathWrapper);
if (reportedClasses.has(className)) {
return;
}
const propertyInfo = extractProperty(className);
if (!propertyInfo) {
return;
}
const { property, value, originalPrefix } = propertyInfo;
// 只检查任意值
if (isArbitraryValue(value)) {
const arbitraryValue = value.slice(1, -1);
const presetClass = findPresetClass(property, arbitraryValue);
if (presetClass) {
reportedClasses.add(className);
// 使用原始前缀显示正确的类名格式(如 h-14 而不是 height-14)
const suggestedClass = `${originalPrefix}${presetClass}`;
context.report({
node,
message: `类名 "${className}" 使用了任意值,但存在对应的预设类名 "${suggestedClass}"。请使用预设类名替代。`,
});
}
}
}
- 实现属性提取,将classname解析为tailwindcss的property和value
// 提取属性值
function extractProperty(className) {
// 处理响应式前缀(如 max-md:, md:, lg: 等)
const responsivePrefixes = [
'max-sm:',
'max-md:',
'max-lg:',
'max-xl:',
'max-2xl:',
'max-',
'min-',
'sm:',
'md:',
'lg:',
'xl:',
'2xl:',
];
// 移除响应式前缀,保留核心类名
let coreClassName = className;
let responsivePrefix = '';
for (const prefix of responsivePrefixes) {
if (className.startsWith(prefix)) {
responsivePrefix = prefix;
coreClassName = className.slice(prefix.length);
break;
}
}
// 按前缀长度降序排序,优先匹配更长的前缀
const sortedPrefixes = Object.keys(prefixToProperty).sort(
(a, b) => b.length - a.length
);
for (const prefix of sortedPrefixes) {
if (coreClassName.startsWith(prefix)) {
return {
property: prefixToProperty[prefix],
value: coreClassName.slice(prefix.length),
originalPrefix: responsivePrefix + prefix, // 包含响应式前缀
};
}
}
return null;
}
- 将提取的property和前面生成的全量的tailwindcss进行映射
// 简化属性映射,只保留常用的属性
const prefixToProperty = {
// 尺寸相关
"w-": "width",
"h-": "height",
"min-w-": "minWidth",
"min-h-": "minHeight",
"max-w-": "maxWidth",
"max-h-": "maxHeight",
// 间距相关
"m-": "margin",
"mt-": "marginTop",
"mr-": "marginRight",
"mb-": "marginBottom",
"ml-": "marginLeft",
"mx-": "margin",
"my-": "margin",
"p-": "padding",
"pt-": "paddingTop",
"pr-": "paddingRight",
"pb-": "paddingBottom",
"pl-": "paddingLeft",
"px-": "padding",
"py-": "padding",
// 边框相关(新增)
"border-": "borderWidth;borderColor",
"border-t-": "borderWidth;borderColor",
"border-r-": "borderWidth;borderColor",
"border-b-": "borderWidth;borderColor",
"border-l-": "borderWidth;borderColor",
"border-x-": "borderWidth;borderColor",
"border-y-": "borderWidth;borderColor",
// 圆角相关(新增)
"rounded-": "borderRadius",
"rounded-t-": "borderRadius",
"rounded-r-": "borderRadius",
"rounded-b-": "borderRadius",
"rounded-l-": "borderRadius",
"rounded-tl-": "borderRadius",
"rounded-tr-": "borderRadius",
"rounded-br-": "borderRadius",
"rounded-bl-": "borderRadius",
// 文字相关
"text-": "fontSize;color",
"leading-": "lineHeight",
"tracking-": "letterSpacing",
"font-": "fontWeight",
// 背景相关
"bg-": "backgroundColor",
// SVG相关
"fill-": "fill",
"stroke-": "stroke",
"stroke-w-": "strokeWidth",
// 定位相关
"z-": "zIndex",
"inset-": "inset",
"top-": "top",
"right-": "right",
"bottom-": "bottom",
"left-": "left",
// 布局相关(新增)
"gap-": "gap",
"gap-x-": "gap",
"gap-y-": "gap",
"space-x-": "gap",
"space-y-": "gap",
// 透明度
"opacity-": "opacity",
// 变换相关(新增)
"scale-": "scale",
"scale-x-": "scale",
"scale-y-": "scale",
"rotate-": "rotate",
"translate-x-": "translate",
"translate-y-": "translate",
"skew-x-": "skew",
"skew-y-": "skew",
// 阴影相关(新增)
"shadow-": "boxShadow",
// 网格相关(新增)
"grid-cols-": "gridTemplateColumns",
"grid-rows-": "gridTemplateRows",
"col-": "gridColumn",
"row-": "gridRow",
"col-start-": "gridColumnStart",
"col-end-": "gridColumnEnd",
"row-start-": "gridRowStart",
"row-end-": "gridRowEnd",
// Flexbox相关(新增)
"flex-": "flex",
"basis-": "flexBasis",
"grow-": "flexGrow",
"shrink-": "flexShrink",
"order-": "order",
// 动画相关(新增)
"duration-": "transitionDuration",
"delay-": "transitionDelay",
"ease-": "transitionTimingFunction",
// 其他(新增)
"aspect-": "aspectRatio",
"cursor-": "cursor",
};
// 动态构建支持的 Tailwind 属性映射
function getSupportedProperties() {
const config = TailwindConfigLoader.getConfig();
if (!config) {
return {};
}
return {
width: config.theme.width,
height: config.theme.height,
minWidth: config.theme.minWidth,
minHeight: config.theme.minHeight,
maxWidth: config.theme.maxWidth,
maxHeight: config.theme.maxHeight,
margin: config.theme.margin,
marginTop: config.theme.margin,
marginRight: config.theme.margin,
marginBottom: config.theme.margin,
marginLeft: config.theme.margin,
padding: config.theme.padding,
paddingTop: config.theme.padding,
paddingRight: config.theme.padding,
paddingBottom: config.theme.padding,
paddingLeft: config.theme.padding,
fontSize: config.theme.fontSize,
lineHeight: config.theme.lineHeight,
borderRadius: config.theme.borderRadius,
color: config.theme.colors,
backgroundColor: config.theme.backgroundColor,
borderColor: config.theme.borderColor,
fill: config.theme.fill,
stroke: config.theme.stroke,
borderWidth: config.theme.borderWidth,
zIndex: config.theme.zIndex,
gap: config.theme.gap,
inset: config.theme.inset,
top: config.theme.spacing,
right: config.theme.spacing,
bottom: config.theme.spacing,
left: config.theme.spacing,
opacity: config.theme.opacity,
};
}
整体实现流程
graph TD
A[ESLint 执行插件] --> B[遍历代码中的类名]
B --> C{是否为 Tailwind 类名?}
C -->|否| D[跳过检查]
C -->|是| E{是否包含任意值?}
E -->|否| F[使用预设值 通过检查]
E -->|是| G[提取类名前缀和任意值]
G --> H[通过 prefixToProperty 映射到CSS属性]
H --> I[检查Tailwind配置是否已加载]
I -->|已加载| J[获取支持的属性预设值]
I -->|未加载| K[加载项目Tailwind配置]
K --> L[读取项目tailwind.config.js]
L --> M{配置是否存在?}
M -->|不存在| N[使用Tailwind默认配置]
M -->|存在| O[解析项目配置]
O --> P[合并默认配置和项目配置]
N --> P
P --> Q[生成全量Tailwind配置]
Q --> R[缓存配置到内存]
R --> J
J --> S{判断属性类型}
S -->|颜色相关| T[调用 findColorPreset]
S -->|数值相关| U[调用 findNumericPreset]
T --> V{是否匹配预设?}
U --> V
V -->|是| W[找到对应预设类名]
V -->|否| X[未找到预设类名]
W --> Y[生成建议消息]
X --> Z[通过检查 无匹配预设]
Y --> AA[报告建议]
Z --> BB[检查完成]
AA --> BB
