开发提效利器 - 用好Snippets
前言 snippets 意思是片段,在 vscode 中可以通过 Snippets:Configure Snippets 命令,可以定义全局级(global)、项目级(Project)、语言级(Lan
比如执行`firebase login``然后跳转浏览器,进行关联
export https_proxy=http://127.0.0.1:xxxx
export http_proxy=http://127.0.0.1:xxxx
export all_proxy=socks5://127.0.0.1:xxxx
firebase login
macOS 上开 V 只是让浏览器等应用走代理,但终端默认不走代理。终端里的命令(如 firebase)需要手动设置 http_proxy 和 https_proxy 环境变量才能走代理访问 Google 服务。
同步至个人站点:为什么在 Agent 时代,我选择了 Bun? - Bun 指南
上周三,看到 Anthropic 的一则新闻:他们宣布收购 Bun,并在文中明确写到——对 Claude Code 的用户来说,这次收购意味着更快的性能、更高的稳定性以及全新的能力。(Anthropic)
简单翻译一下就是:
我们要把整个编码 Agent 的基础设施,换成一个更快、更顺手的 JS/TS 运行时。
这条新闻对我触动很大,至少暴露出两个事实:
Agent 时代的基础设施在变化 以前我们写 CLI、写后端,Node 足够用了;但到了 Agent 这种「到处起小进程、到处跑工具」的场景里,启动速度、冷启动性能、all-in-one 工具链,突然变得非常关键。
Bun 不再只是一个「新玩具」 它已经成为一家头部 AI 公司的底层组件之一:Anthropic 早就在内部用 Bun 跑 Claude Code,现在索性直接收购,把它当作下一代 AI 软件工程的基础设施。(bun.sh)
当我再去翻 Bun 的官网时,就会发现:
这是一个集 JavaScript/TypeScript 运行时、包管理器、打包器、测试运行器 于一身的 all-in-one 工具。(bun.sh)
这和我对「传统 JS 运行时」的印象已经完全不一样了。
我平时写代码偏向两类技术栈:
很长一段时间里,我对 Node 的使用场景大概就是这几种:
ts-node / tsx + 一点配置,跑完就扔这些场景里,一个很明显的感受是:
直到我开始认真看 Bun 的文档,第一次有一种很强烈的对比感:
「哦,原来现在写 JS/TS 后端已经可以这么简单了?」
tsconfig.json(很多时候默认就很好用)bun run / bun build / bun test
再加上我最近在做 Agent 相关的东西,自然就顺势产生了一个问题:
既然我本来就想用 TS 写一个 ReAct Agent,那为什么不干脆用 Bun 来做 runtime 呢?
在开搞之前,我特地去看了一圈现在比较热门的 Agent CLI 都是怎么选技术栈的:
如果你把这些信息放在一起,会大致看到一个趋势:
而我这个人,有个很明显的偏好:
能用 TS 解决的,就先别急着上 Rust。
所以,当我看到:
那我心里那个问题就更具体了:
在「写 Agent」这个具体场景里,Bun 真的比 Node 体验更好吗?
我不太喜欢只看 benchmark,于是就决定写点实打实的东西来试试看。
为了验证这个问题,我给自己定了一个很小的练习目标:
用 Bun + TypeScript,写一个「不到百行代码」的极简 ReAct Agent Demo。
这个 Agent 不追求多复杂的功能,专注这几件事:
维护一个最小可用的 ReAct loop(思考 → 行动 → 观察 → 再思考)
内置少量工具,比如:
read:读取文件内容write:写入/更新文件整个项目尽量清爽,不做多余封装
写的过程非常「AI 化」:
结果出乎意料地顺畅:
fs 模块、各种工具库的地方,在 Bun 里可以用自己的 API 写得更简洁,比如 Bun.file()、Bun.write() 这种。(bun.sh)bun xxx 的那一套就行,几乎不需要额外配置。更关键的是:
整个 Demo 框架搭好后,我有一种「这个东西是可以往前认真维护」的感觉,而不是写完就丢。
这和我之前写很多 Node 小脚本的心理预期是完全不一样的。
周末刷 X,看到老许的帖子,如下:
这句话我很认同。 前后端统一 TS 技术栈,对个人开发者来说太友好了:
那顺着这个思路,下一步的问题就自然来了:
既然语言是 TypeScript,那运行时呢? 未来的 TS 运行时,会不会从 Node,逐渐走向 Bun(一部分场景)?
我不打算在这里给出一个结论——毕竟 Node 的体量、生态、历史沉淀摆在那里,而 Bun 目前也还只是一个「两年多一点」的新 runtime。(bun.sh)
但从我自己的体验看,有两点很值得关注:
Bun 是为「现代 JS/TS 开发」重新设计过的 它自带 bundler、test runner、包管理器,不再是「一个 runtime + 一堆第三方工具拼装」的模式。(bun.sh)
Bun 和 Agent、AI 工程这类新场景的契合度异常高
这些特性,叠加起来就会让人产生那种感觉:
「如果我要重写一遍现在手里这些 Node 脚本、工具、Agent,那好像真的可以考虑直接上 Bun。」
既然已经有了实践的契机(ReAct Agent Demo),再加上我一贯「学新东西喜欢顺手写点东西」的习惯,那干脆就开一个新专题:《Bun 指南》。
这第一篇就是引言,只回答一个问题:为什么要学 Bun?
后面的几篇,我打算按这样的节奏展开(暂定):
安装与上手:从 Node 迁移到 Bun 有多难?
bun run / bun dev
Bun 的 all-in-one 工具链
bun install vs npm/pnpmbun test:内置测试如何用bun build:打包、构建、单文件可执行用 Bun 写 HTTP 服务
Bun.serve() 的基本用法(bun.sh)文件、进程与工具脚本:Bun 的标准库体验
Bun.file() / Bun.write() 等常用 API实战篇:用 Bun + TS 写一个 ReAct Agent Demo
踩坑记录 & 迁移经验
如果你已经会写 JavaScript / Node,这个专题不会从「什么是 Promise」讲起,而会更聚焦在:
我并不打算把 Bun 神化成「Node 杀手」——至少短期内,它更像是:
一个极适合「个人开发者 / 小团队 / 新项目 / Agent 工程」尝鲜的 JS/TS 运行时。
而这个系列,就是我在这个尝试过程中的「实践笔记」:
如果你:
那欢迎一起把这个系列看下去,也欢迎你在实践中告诉我: 在你的场景里,Bun 到底是不是一个更好的选择?
从2023年成立到如今日均服务2万+直播间,百度慧播星已演进为覆盖脚本生成、实时问答、智能决策、音视频克隆的全链路AI直播平台。本文深入解读其技术架构:如何通过检索增强和强化学习生成高转化脚本;如何利用强化学习智能中控动态优化直播策略;以及如何将语音与形象克隆效率提升至“小时级”;如何构建“先验-后验”数据飞轮,让模型自主进化;。罗永浩数字人直播GMV突破5500万的案例,验证了其“超越真人”的带货能力。未来,慧播星正朝着更智能、更拟真、更高效的方向持续迭代。
电商数字人直播(慧播星)正式成立于2023年,是一款汇集了百度在视觉,语音和语言方面AI能力的原生AI应用产品,致力于打造代际领先的超越真人的直播体验。25年底日均开播直播间已达2万多个,覆盖电商、教育、健康、金融、泛知识内容等多个行业。经过两年多的产品打磨和技术突破,慧播星数字人直播已具备超越真人的能力。例如,这些能力支撑了罗永浩2025年6月15 日的数字人直播首秀,吸引了超 1300 万人次观看,GMV(商品交易总额)突破 5500 万元,这一成绩超过了其同年 5 月的真人直播首秀(GMV 5000 万)。
商家在慧播星获得带货权限后,即可自助开启数字人直播,主要包括如下流程。
1. 商品选择,可从百度直营店铺(度小店),三方电商平台(京东淘宝拼多多)和百度本地生活的海量商品中选择带货商品
△ 海量内外部商品一键挂接
△ 形象选择或定制
△ 直播间装修,丰富的模板&组件
△ 一键脚本生成
△ 音色选择或制作
6. 直播间互动配置,一键开启一言问答接管,也支持手动配置预置问答对,补充商家知识
△ 直播间互动配置
慧播星整体架构主要由商家端、视觉语音和文本各模态模型、实时渲染引擎、站内外分发系统组成。
为实现更好的直播体验,数字人采用云端生成方案,云端生成系统主要包括如下几个子系统。
1. 商品理解,为脚本,问答,互动等各种内容生成模型提供商品知识增强
2. 脚本生成,围绕商品自动生成风格化口语化的带货脚本
3. 智能问答,用户提问时实时检索商品知识,生成精准的回复,支持弹幕和口播回复
4. 智能互动,以直播效果(评论率、用户退场率、观看时长等)为目标主动向用户发起互动
5. 直播间装修,智能生成直播间背景,合成带营销内容的挂件
直播脚本水平与带货效果息息相关,优秀主播的脚本能够打动用户,循循善进引导用户成交。由于普通商家的带货营销水平有限,商家希望仅表达学习某某主播,系统自动为其生成风格相似的脚本。在此需求背景下,慧播星利用多模态商品理解富集构建商品知识库,借助EB4/turbo在电商直播语料上进行大规模预训练,结合人工专家精标数据SFT,通用和电商知识增强等手段实现一键风格化仿写。
△ 风格化脚本生成工具UI
整体技术主要包括商品理解、检索增强、强化学习风格化生成和后处理阶段。
数字人直播的内容绝大部分来自大模型生成,前期领域专家知识为生成标准,脚本、问答、互动场景的生成质量已达到普通真人主播的水平。然而人工先验知识存在主观偏差,且缺乏全面性和快速适应新变化的能力,完全依赖人工只能达到次优水平。为持续攀升超越域内外头部真人主播,需建立业务和大模型的数据飞轮,通过飞轮效应持续提升模型在数字人直播场景的后验效果。
在真实直播场景中,数字人模型最终追求的是“后验效果最优”——即用户停留、评论增长、转化提升等真实业务指标。然而后验目标往往天然伴随风险:例如激进促单、夸大效果、模糊描述等内容可能在短期内获得更高的用户反馈,却越过事实边界与平台规范,形成安全问题。因此,在模型全面对齐后验之前,必须构建一套稳健、可解释、与平台规范一致的先验对齐体系作为基础。先验奖励模型作为“守门人”,以推理专家模型为判断核心,通过结构化的偏好评分与规则奖励引导模型学习合规、高质、可控的内容风格,实现“先验对齐 → 强化学习 → 专精模型 → 回流验证”的闭环。
自动偏好合成。传统先验奖励完全依赖人工标注,成本高且存在主观性。为解决这一问题,我们集成了多个先进推理类基模型(如 EB4-4T、Deepseek-R1/V3、GPT-o 系列等),通过多模型投票、结果对比分级等方式自动合成偏好。这一自动化偏好生成机制能够模拟“专家标注”,但具备:
最终形成先验 RM(Reward Model)的核心训练数据。先验 RM 的核心职责是确保模型在任何情况下都不会突破内容安全边界,为后续后验对齐提供稳固底座。
为了让模型吸收用户的真实后验反馈,慧播星构建了一套以“内容探索 + 奖励建模”为两条主线的数据飞轮,实现模型的自主进化与持续增强。
基于后验统计的内容探索:可控、高解释的偏好数据生成链路。后验统计路径主要面向高精度、强可控、可解释性强的偏好数据生产需求,结合在线实验框架,通过真实用户反馈驱动的方式生成偏好样本。通过高频在线实验,系统不断沉淀千级规模的偏好数据,支撑后续的模型偏好对齐训练(如 DPO/IPO 等策略优化方法)。
可泛化的奖励 uplift 建模:大规模偏好数据的高效补充路径。相比基于后验统计的实验方式,uplift 建模路径旨在解决用户行为稀疏、实验成本高的问题,通过泛化模型直接对用户偏好进行预测,生成百万级的偏好数据,实现更高效的数据扩容。采用 S-Learner / T-Learner 等 uplift 方法,构建用户行为因果效应模型,直接预测“某段内容是否会提升用户的互动/评论/停留等关键指标?”
慧播星建设了一套完备的直播场景RAG系统,包括电商领域知识检索模型,通过千亿模型蒸馏的低时延生成模型(12s->2s),数据飞轮。目前已实现多模素材调度,高拟真明星问答,客户个性化表达,垂类适配,商家/商品知识库等产品能力。客户可一键开启智能问答,问答端到端可用率95%,优质率90%,客户开启率94%,运营和客户反馈较好。
△ 智能问答架构
慧播星的直播实时问答系统在工程上形成了知识整合 → 领域检索 → 低延迟生成 → 后处理 → 数据飞轮的完整闭环,为超拟真数字人提供了媲美真人的实时互动能力。
真人主播会根据直播间实时状态决策当前应发起何种动作(action),比如直播间互动氛围差的时候是应该邀评,换卖点讲解还是促单?确定动作后主播知道如何最好的的执行动作,例如怎么把邀评讲出来?说什么话,用什么语气,邀请特定观众还是所有观众。行为决策和行为内容生成两者相结合实现直播间下单,关注,留联等最大化目标。超拟真数字人需要具备上述两种核心能力,即给定一个长期目标(如每场次的订单总数,评论总数,观看时长等),要求数字人1)判断在不同直播间状态下应该做出什么行为,是切换卖点讲解,促单逼单,邀评还是多轮互动?2)确定某种行为后生成适合的的行为内容,如塑品讲解,优惠讲解,促单逼单等的具体口播内容。
智能中控架构核心由基于强化学习的决策Agent,和基于一言大模型的多任务融合两个部分组成。
行为决策的目标是在不同直播状态下选择最优动作,最大化长期目标(订单、评论、观看时长等)
上图展示了直播环境与RL决策Agent的交互流程:
这使数字人能够像真人主播一样:氛围低时发起互动,用户观望时进行促单,新观众进入时进行商品介绍。RL 的优势在于目标导向:不是优化单句话,而是优化整场直播的 KPI。
当 RL Agent 选择了一个动作后,例如“促单”,还需要生成对应的动作参数:如促单的口播内容,使用什么语气?内容是偏温和还是强节奏?是否引用当前观众的评论?实践中我们通过强化学习训练了一系列action内容生成专精模型,能够生成特定参数指定的直播内容。
未来我们将以语言模型为基座对决策和内容生成任务进行端到端训练,减少分阶段建模带来的累计误差。
普通商家原声演绎状态不佳,缺乏带货感。慧播星利用风格迁移TTS技术自动合成感染力强,拟真度高的直播音频。经过两年多的迭代TTS开播使用率从30.3%提升至92.8% ,制作时效性从1月降低到1分钟。
电商TTS发展主要经历两个阶段:
第一阶段(2023.3~2024.Q2) **:语音定制工牌麦收音,依赖大量人工传导,整个周期长达一个月
第二阶段(2024.Q3至今) **:小程序自助收音提高收音效率,自动训练架构升级,抑扬顿挫带货效果持续优化
第一阶段:工牌麦收音效率低下
第二阶段:小程序自助录制
现状:当前慧播星支持原生和激情带货两种音色克隆,客户仅需在手百小程序上录制15分钟语音,系统在1天内自动为客户生成克隆音(对比如下)。目前慧播星已制作12w多个音色,2.7w多个客户定制音色。
两种音效可选
1. 原声效果:还原本人说话特点,如语速和语调
http://blob:https://unitools.fun/fb87134d-97ec-42a5-a0a0-b74980b1cfc3
2. 激情带货效果:让整体情绪更激昂,抑扬顿挫
http://blob:https://unitools.fun/85e53903-5672-4988-85ae-19a4c867a607
未来计划利用海量直播场景的语料数据,进一步降低克隆门槛(对齐竞品的30s)、提升克隆效率(分钟级可完成克隆进行合成)、优化朗读效果(对标直播/视频/讲述/咨询等不同语境的真人) ,同时从单声音的克隆和合成成本达到业内头部领先水平。
整体架构主要包括离线声纹注册和模型训练,在线合成三个部分。
△ 形象克隆及合成架构
主播形象是直播的核心要素,高拟真形象能够提升用户观看时长,进而提升成单效果。慧播星与视觉技术部深度合作,基于2D数字人技术针对直播场景定制形象克隆和合成能力,建设了接近7800+个公共库形象,有效地支撑商家在慧播星的前期探索,为自建形象做好准备。
△ 慧播星形象制作
形象克隆技术发展主要经历了四个阶段:
第一阶段(2023.3~2023Q4) :V1版本唇形驱动方案适配电商直播场景,跑通录制约束较多的**闭嘴且无遮挡录制+**形象克隆流程,建立起第一批公共库形象
第二阶段(2024.Q4~2024.Q2) :V3V4版本唇形驱动通过数据建设和模型算法优化实现张嘴录制和更自然的唇动效果
第三阶段(2024.Q3~2025.Q2) :进一步降低录制门槛,支持录制中遮挡、大幅度侧脸和人脸出镜。
当前阶段客户仅需上传5分钟左右的自然演绎视频,系统在3小时内即可自动为客户生成克隆形象。时至25年底慧播星已累计制作32万多多个形象,8万多个客户定制形象,线上可用率95% 。
第三阶段(2025.Q3~至今):突破唇形驱动,建设多人出镜,动作驱动,表情驱动,持物驱动等下一代形象生成能力(多模协同的超级主播)。
实时场景下早期的唇动方案采用单阶段建模(如wav2lip),输入音频直接输出像素空间的唇形图片。实践中单阶段方案无法达到逼真的唇动效果,后来的商用方案几乎都采用两阶段方案:第一阶段将音频转化为2D关键点或3D人脸模型作为中间表达,第二阶段将中间表达利用GAN网络解码到像素空间。
视觉生成模型
核心由三个模型组成,3D人脸重建模型,音频到3D人脸生成模型,3D空间到像素空间人脸生模型。
模型pipeline
在线合成架构
形象合成以tts音频、底板视频帧和直播间背景为输入,通过生成模型实时合成主播嘴部区域,最后组装成视频流推送给用户。其中任务队列建立缓冲区,保障了视频流的连续性。目前已实现单卡多路流式渲染,支撑2万多直播间同时开播
在线流式合成架构
历经两年多的持续打磨与技术突破,慧播星已经从一款数字人直播工具,成长为覆盖脚本生成、实时问答、智能中控、语音克隆、形象合成等多模态全链路的原生 AI 直播平台。它不仅复刻了真人主播的内容表达与带货节奏,更通过商品理解增强、强化学习决策、先验—后验数据飞轮、大规模音视频生成模型等关键技术,实现了“超越真人”的直播能力。随着业务规模的快速扩张与技术体系的持续演进,慧播星已在日均2万+直播间、万级定制形象与音色、覆盖电商与泛行业场景的真实生产环境中验证了 AI 直播的成熟度和商业价值。未来慧播星将继续沿着“更智能、更具说服力、更高效”的方向迭代:让脚本更精准、互动更自然、视觉更逼真、声音更生动、决策更智慧,并通过持续运转的数据飞轮不断突破直播体验的天花板。
I just got back from CKCon in beautiful Chiang Mai 🌴, where I gave a talk on the Fiber Network. To help everyone wrap their heads around how Fiber (CKB’s Lightning Network) actually moves assets, I hacked a visual simulation with AI.
To my surprise, people didn’t just understand it—they loved it! 🎉
Here is the “too long; didn’t read” version. But first, go ahead and play with the dots yourself, 👉 Play the Simulation: fiber-simulation
We all love Layer 1 blockchains like Bitcoin or CKB for their security, but let’s be honest: they aren’t exactly built for speed.
Every transaction has to be shouted out to the entire world and written down by thousands of nodes. On CKB, you’re waiting about 8 seconds for a block; on Bitcoin, it’s 10 minutes! Plus, the fees can get nasty if you’re just trying to buy a coffee. ☕️
So, how do we fix this?
The Lightning Network is a scalable, low-fee, and instant micro-payment solution for P2P payments.
The secret sauce isn’t actually new. Even Satoshi Nakamoto hinted at this “high-frequency” magic in an early email:
Intermediate transactions do not need to be broadcast. Only the final outcome gets recorded by the network.
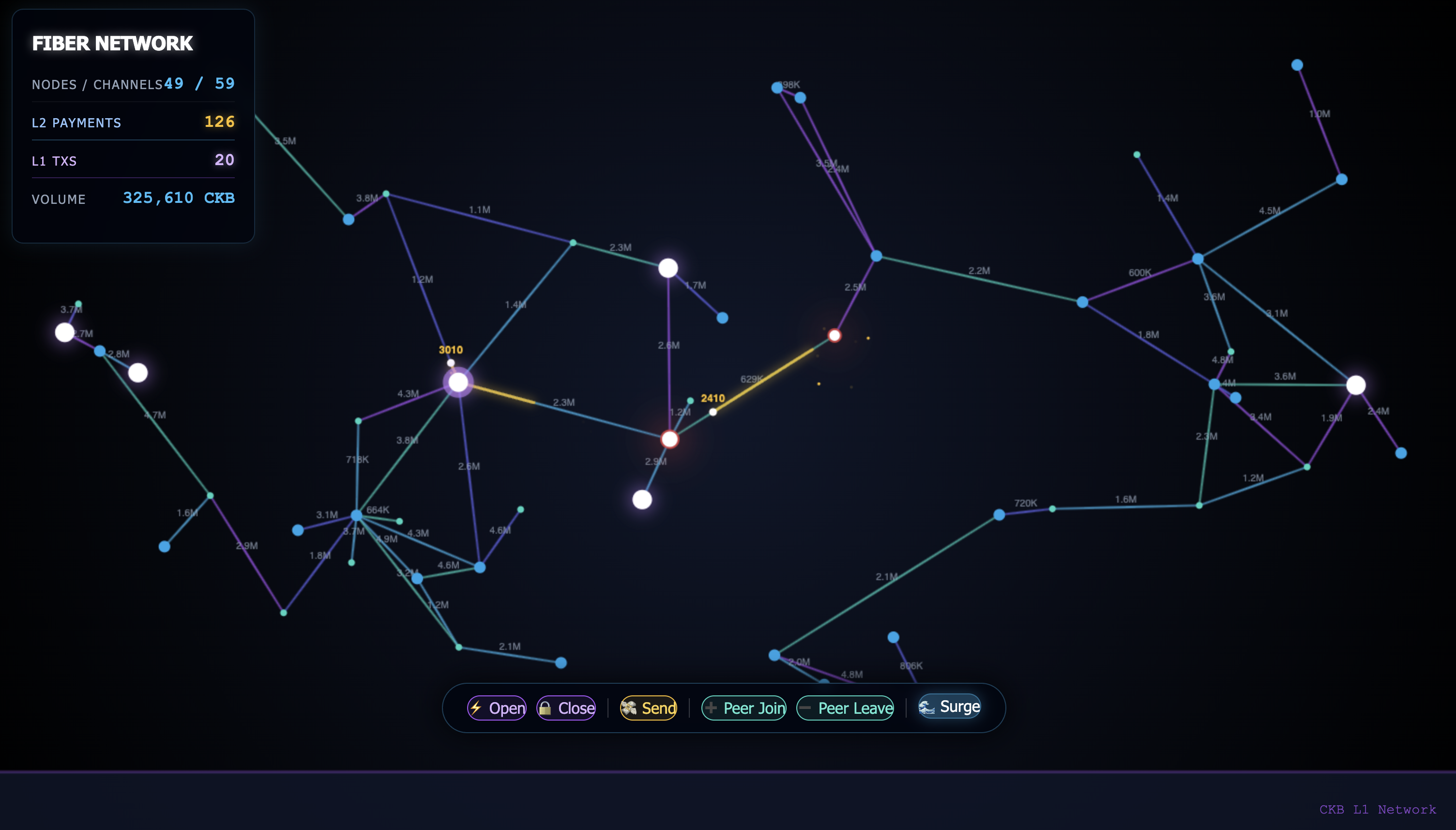
A Lightning Network consists of Peers and Channels. A peer can send, receive, or forward a payment. A Channel is used for communication between two Peers.
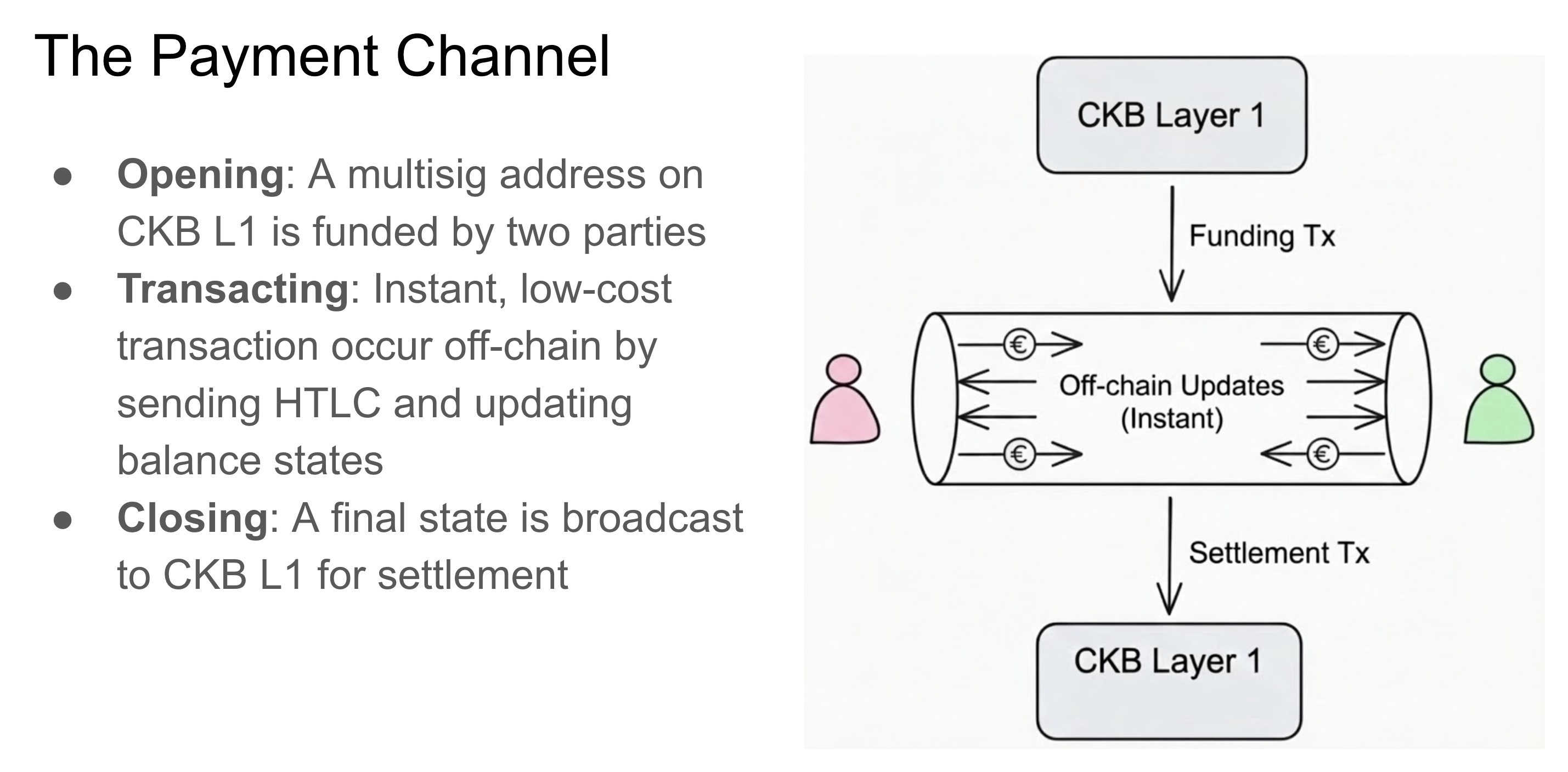
Imagine you and a friend want to trade money back and forth quickly:
Everything in the middle? That’s off-chain magic. ✨
Now, if Fiber was just about paying your direct neighbor, it would be boring. The real power comes from the Network.
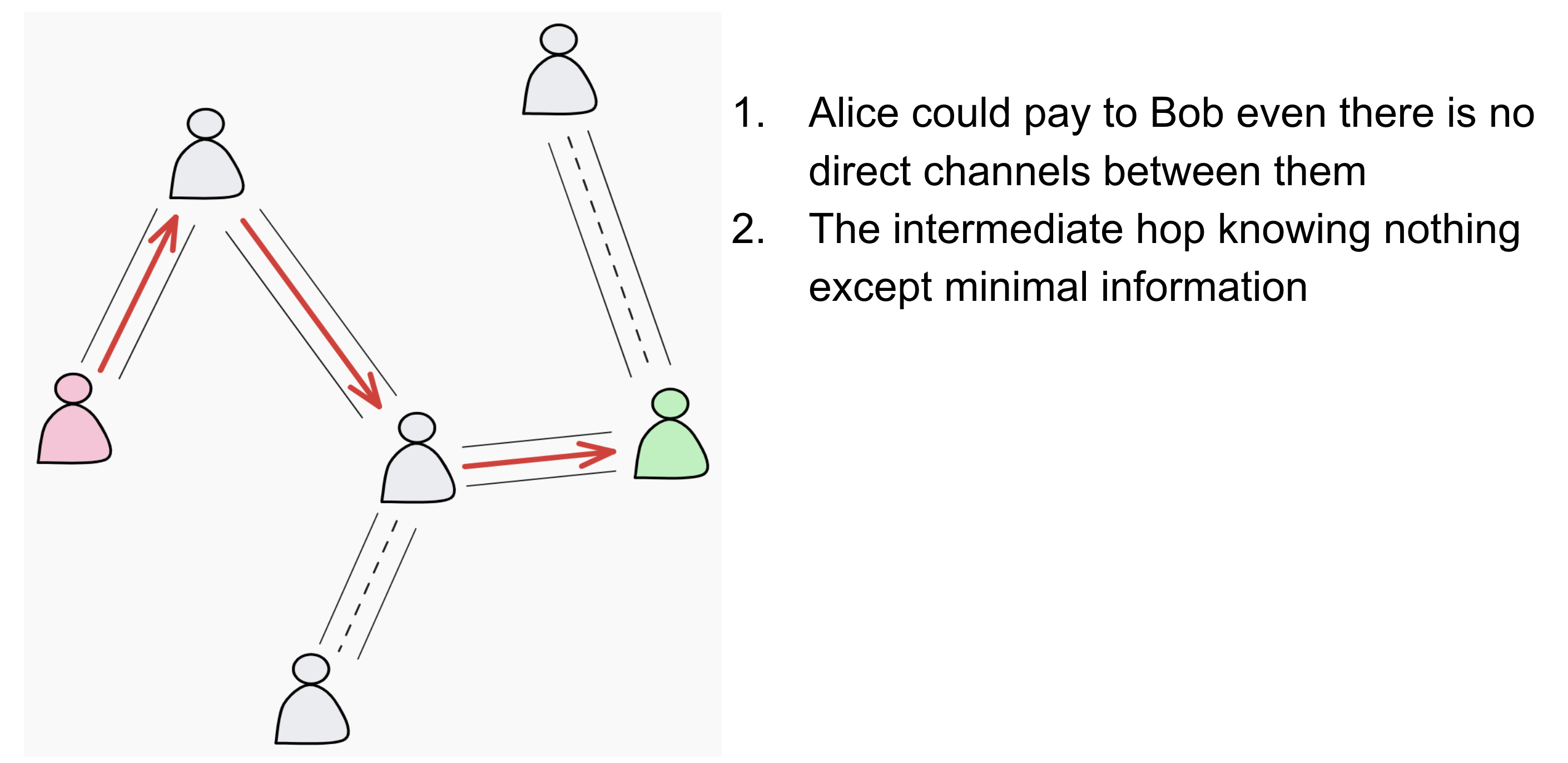
This means Alice can pay Bob even if they don’t have a direct channel between them. The payment can travel through one or more intermediate nodes. As long as there is a path with enough liquidity, the payment will reach its destination instantly.
All data is wrapped in Onion Packets (yes, like layers of an onion). The nodes in the middle serve as couriers, but they are blindfolded:
They simply follow a basic rule: they forward the Hash Time Lock, and if the payment succeeds, they earn a tiny fee for their trouble. Easy peasy.
The “Not So Easy” Part 😅
While the idea is simple, building it is… well, an engineering adventure. We’re dealing with cryptography, heavy concurrency, routing algorithms, and a whole jungle of edge cases. But hey, that’s what makes it fun!
We’ve poured the last two years into building Fiber, and I’m proud to say it’s finally GA ready.
If you want to geek out on the details, check these out:
Here is the full presentation from my talk:
CKB Fiber Network Engineering Updates
好几年没写「年终总结」,翻了下「掘金」,上一篇还停留在「2021年」,倒不是这几年没活过,也不是不想写,只是每次都止步于「拖延」。每到年底,脑子里就会蹦出的各种想法,被我零散地记录在 "大纲笔记" 中:
写这玩意挺废「时间」和「心力」,所以总想着 "找个周末,花一大块时间,好好梳理一下",结果都是一拖再拖:拖到元旦,拖到春节,拖到元宵。
然后,转念一想:"这都明年了,还写个🐣毛啊?算了,算了,明年一定!"。2022、2023、2024 就在这样的 "明年一定" 中溜走了...
人到中年,主观感觉「时间」过得越来越快,「记性」 也大不如前,很多当时觉得 "刻骨铭心" 的瞬间 (如:结婚、当爹),如今回忆起,就剩下一个 "模糊的轮廓"。不写的话,又是「摸 🐟」一年,趁着 2025 年还没过完,很多感觉还是热乎的,赶紧动笔,今年一定!!!
2025 年,对我冲击最大的当属 "AI",大到让我不得不重新审视「自己的工作和价值」。
我接触 AI 并不算晚,2024 年那会跟风玩了下 ChatGPT,后面在 GitHub Copilot (便宜盗版,30¥/月) 的协助下,快速交付了一个爬虫单子。尝到 "提效甜头" 的我,咬咬牙上了 年付正版 (100刀/年) 的车。
当时 AI 在我的眼里,只是个 "比较聪明的代码补全工具",可以帮我少些几行代码,仅此而已,因为 逻辑还得我来把控。
但到了 2025 年,事情却变得有点不一样了:
AI能读懂/分析整个项目、重构屎山代码、把一个模糊的业务需求实现得有模有样。
当然,最让我 "破防" 的还是它的 "解BUG" 能力:
按照以往的习惯,我得去 Google、翻 Stack Overflow、看源码,少说得折腾半天。现在,把 报错日志 和 相关代码 丢给它,通常几秒就能:指出问题所在,给出解决方案,甚至可以 帮我改好并测试通过。
积累多年,一度 "引以为傲" 的「编程经验」(对API的熟练程度、快速定位BUG的直觉、配置环境的熟练度等) 在 AI 的面前,变得 "不堪一击"。渐渐地,我的「工作流程」也发生了改变,"亲手" 敲下的代码越来越少,取而代之的是一套 "机械化" 的 "肌肉记忆":
代码跑通了,效率提高了,却带来了精神上的「空虚」,我似乎再也感受不到当初那种「编程的快乐」:
同时,也陷入了一种深深的「自我怀疑与迷茫」:
我深知「焦虑」无用,于是开始探寻「破局之道」,反复阅读大量资料后发现,几乎所有人都在让你「拥抱 AI」,但具体怎么拥抱法?没人说,或者说得含糊不清,有些甚至还想割我 "韭菜" 🤡 ?屏蔽这些噪音,冷静下来复盘,拨开情绪迷雾,透过现象看本质。
首先,坦诚地「接纳」肯定是没错的,历史的车轮从不因个人的意志而停止转动,当 第一次工业革命的蒸汽机 轰鸣作响时,那些坚守手工工场的匠人们,也经历着相同的困境。精细手艺 在不知疲倦、效率千倍的 机械化工厂 面前显得苍白而无力。大机器生产取代手工劳动,不是一种选择,而是一种必然的 "降维打击"。
现在,我们同样站在了 "生产力变革" 的周期节点上, "效率至上" 的底层逻辑从未改变。是选择成为被时代甩下车的 "旧时代纺织工"?还是进化为驾驭机器的 "新时代工程师"?回归「第一性原理」,剥开 "智能" 的外衣,想想 "AI 的本质是什么?" —— 「干活的工具」
所以,面对 AI,我们要做的事情就是琢磨 "如何用好这个工具? ",即:详细阅读使用说明后,在合适的场景,用合适的方式,解决合适的问题。
🐶 经常在 自媒体平台 刷到 "普通人学AI后致富/逆袭" 的 叙事,看到这些 "逆天标题" 没把我笑死:
多的不说,记住这段话就对了:
变现的核心能力从来不是使用工具,而是商业认知、市场洞察、营销推广、客户服务。AI 只是一个环节,不要高估了工具的作用,而低估了 商业常识的重要性,也不要低估了背后的 隐性成本和巨大的工作量。
这些 "AI变现教程" 的 最大问题:
让你把AI当成一个 独立的、全新的、需要从零开始的 "行业" 去卷。
对于 99% 的普通人而言,把AI看作 "能力放大器" 会更靠谱一点,即:
思考如何利用AI,帮我把我已有的技能/兴趣做得更好?
比如:
今年「Vibe Coding (氛围编程) 」很火:
用自然语言描述想要的效果,AI帮你写代码,你只负责验收结果和提修改意见,不用管具体代码怎么实现的。
编程门槛大大降低,普通人 只要能把 创意和感觉 翻译成需求,就能借助 AI 将其快速具象化为 可运行的产品。
但你会发现,绝大多数生成的作品都是 "一次性原型或玩具":灵光一现即可实现,却缺乏持续迭代、架构设计与用户验证,因此难以具备商业价值、也难形成可持续的产品形态。
真正能够利用 Vibe Coding 实现变现的,往往是具备一定 编程经验 或 产品思维 的 "专业人士"。他们不仅能用 AI 快速实现灵感,还能对作品进行持续优化、迭代和工程化打磨,从而将 "灵感原型" 进化为 "可用产品"。
再说一个自己观察到的例子,前阵子 OpenAI 发布了用于生成短视频的「Sora2」,B站 很快涌现了一堆 AI 生成的 "赛博科比" 恶搞视频。
看到一个播放量破百万的作品有点意思,点进 UP 主的主页想看下其它作品,结果发现他并不是突然爆火的 "新人",人家已经默默做了好几年视频,只是过去的播放量惨淡 (几十几百)。但他却一直坚持创作,尝试不同的方向,能清晰地看到他的剪辑、叙事和整体制作水平在一点点提高。
AI 不会让没有积累的人"平地起飞",但有可能让有准备的人"一飞冲天"。—《抠腚男孩》
看到这里,可能有人会问:
"那普通人怎么办?我没啥专业技能,也没有长期积累啊? "
简单,那就 "学" 啊!!!以前学习的最大限制是什么?
没人教、教不好、学不动、坚持难
而现在,你有了一个「全知全能、知无不言、24小时为你服务的免费老师」
当然,想要这台 "自学利器" 高效运转起来,实现 快速学习/试错/跨域 还需要掌握一些 方法论。
详细解读可以参加我之前写的《如何借助AI,高效学习,实现快速"跨域"》
🐶 2333,经常刷到 "xx公司发布新的 xx 模型/AI产品颠覆行业,xx师要失业了" 的标题,但事实真的如此吗?最近 Google 家的 Nano Banana Pro 🍌很火,号称当前 "最强AI生图" 模型,亲身体验下确实强 (本文大部分配图就是它出的),天天在群里吹爆。
某天晚上,有 "多年专业设计经验" 的老婆收到一个改图需求 (抠素材,按要求调整海报):
😄 看着简单,感觉 🍌 就能做,于是我提出和老婆 PK 下,她用 PS 改,我用 🍌 嘴遁修图,看谁出的图又快又好。结果:她10分钟不到就改完,而我跟 🍌 Battle了半个小时没搞好,最终的效果图 (左边她的,右边我的):
🤡 "甲方" 的评价 (破大防了😭):
观察仔细的读者可能会问:"你是不是漏了一个车🚗啊?",憋说了,这破车把我调麻了...
那一刻,我深刻体会到了什么叫 "不要拿你的兴趣爱好,去挑战别人的饭碗",真的是 "降维打击" 啊!
AI 确实拉低了创作的门槛,但目前还处于生成 80分 内容的阶段 (效率),最后的 10-20 分 (细节、审美、情感) 才是价值的核心。——《抠腚男孩》
后面复盘,老婆看了下我的 Prompt,说我的流程有点问题,应该让 AI 先把素材全抠出来先,再慢慢组合。后面试了下,效果确实有好一些。不过,不得不说,AI 在 自动抠图 这块确实可以:
🤣 老婆在日常设计时也会用 AI 来偷懒,比如:生成配图、提高清晰度、扩图等。
现阶段谈论 AI,其实都是在谈论 大模型 (LLM) —— 一个极其复杂的 "概率预测机器"。
通过学习海量数据的 "统计规律",逐步逼近这些数据背后的 "概率分布",从而能够在给定 "上下文" 时预测最合理的下一步输出。
不同类型产物的生成原理图解 (看不懂没关系,简单了解下即可):
① 文本
② 图片 (扩散模型 & 自回归模型)
③ 音频 (自回归模型 & Codec + Token 预测 )
④ 视频 (扩散式 & 自回归/时空Token)
LLM 擅长发现 "相关性",但难以进行真正的 "因果推理",它只是在 "模仿智能",而非 "真正地理解意图,拥有意识"。 —— 《抠腚男孩》
弄清楚 AI 的本质是 "概率预测机器" 后,接着从 "代码生成" 的角度梳理下它的 "优势 & 劣势":
了解完 AI 的 优/劣势 后,接着就可以推演「人 & AI」 的 高效协作方式:
一句话概括:
AI 负责 "生产力" (重复、繁琐、高上下文、高整合的工作),人负责 "方向与边界" (判断、创造、决策、理解组织与业务)。
一般译作 "提示词" 或 "描述词",个人认为后者更加贴切,即:描述问题/需求的 "词句组合" 。「Prompt Engineering-提示词工程」是所有人都必须掌握的 "使用AI的核心技能"。
🐶 别被几个英文单词吓倒,现在的 AI 比几年前聪明多了,普通人 只要能:
把诉求讲得清晰、完整、有逻辑,就能解决绝大多数问题。
示例:
AI输出结果 (前者输出不同城市的游玩方案,后者输出了具体的行程方案):
再往上走,就是了解一些经典的 "Prompt框架",然后再提问时套用,以提高 AI 输出的稳定性、准确性和质量。所谓的 "框架",其实就是 "结构化模板",规定问题中包含哪些 "要素",比如最经典的「CTRF」框架:
套框架示例 (填空题~):
常见的框架还有 RTF、COSTAR、SPAR、COT、APE 等等,适用于不同的场景。杰哥整合了自己知道的所有框架精华和高级技巧,弄了通用的「Prompt 最佳实践清单」
无脑套就是了,助记口诀:
也可以用故事流程来串联助记,读者可自行发挥,顺序无需固定:
让一位说书人 (角色) ,用生动的语气 (风格语气) ,给孩子们 (受众) 讲个故事 (指令) 。故事的开头 (上下文) 是...,结局 (目标) 要感人。故事的结构 (格式) 要像这样 (示例) ,但不要 (约束) 出现暴力情节。请先构思情节 (逐步思考) ,写完后再想想怎么能更精彩 (反思) 。
😄 懒得记的话,可以用我之前搭的小工具 →「CP AI Prompt助手」
配下 DeepSeek 的 Key,复制粘贴你写的 简单Prompt,它会基于上面的十个维度对提示词进行优化:
明白了怎么 "套框架" 写 "结构化的Prompt",但你可能还是会感到疑惑:
用的同样的AI,为什么别人的生成效果就是比我好?
尤其在 AI 生图 领域,看大佬分享的 Prompt,里面一堆看不懂的专业参数:
环境、构图、光影、景深、镜头、光圈、色调、氛围、胶片颗粒、对比度、主体增强、氛围灯...
能写出这么 专业的Prompt,是因为他们有 "相关领域的行业经验" 吗?
答:有加成,但不全是。高手的核心技能不是 "记这些专业知识",而是:知道如何指使 AI 给自己提供专业知识、框架、术语,然后再反向用这些框架让 AI 编写和优化 Prompt。
😄 其实思路很简单,拆解下这套方法论:
维度词 → 术语/词库 → 通用模板 → 填空得第一版Prompt → AI专家视角优化 → 迭代优化沉淀
详细玩法可以看下图:
Prompt 逆向工程(RPE,Reverse Prompt Engineering),就是:从 "输出" 反推 "是什么Prompt" 生成了它。一般用于:学习优秀案例、调试和诊断问题、构建Prompt库和模板、企业质量控制、安全审计 (防御Prompt注入攻击)。
普通人 用这个套路就够了,选个聪明点的模型 (如:GPT5 或 Gemini 3 Pro),粘贴图片,写 Prompt 让它反推:
差得有点远,描述「不满意的点」,让AI继续优化Prompt:
接着用优化后的 Prompt 来生成,可以看到效果差不多了,接着让 AI 提取一个「通用的Prompt」
拿 AI 生成的 Prompt 生图,看效果,描述问题,循环反复,直到稳定生成自己想要的效果~
🐶 其实也差不多,只是流程比较 "标准化",经常搞还能自己搭个 "工作流",适合专业选手,思路:
快速拆解 → 推断 Prompt → 提取要素 → 重建 Prompt → 优化迭代 → 模板化沉淀
详细图解:
上面是通用的,还有几个 额外功能 的玩法也罗列下:
🐶 懂点AI常识,能让你更 有的放矢 地 用好AI (装逼),比如:连 Token 都不知道的话,就有点贻笑大方了。这里只是简单罗列下相关名词,不用死记,有个大概印象即可,不影响你使用AI,跳过也没关系。😄 详细讲解,建议直接复制名词问题AI,也可移步至《AI-概念名词 & LLM-模型微调》自行查阅~
😄 最后,聊聊 AI 编程 领域的一些心得~
AI 代码写得好不好,主要看 "模型" 的 "编程能力",评估 "模型优劣" 的几个 "常见维度":
LLM 的能力很难用一句话概括,所以厂商们每次发新模型都会用一堆 Benchmark 来证明 (🐶不服,跑个分?)
① 推理与数学能力 (Reasoning)
"智能的核心指标",高分意味着能够做更复杂任务 (如:工程规划、Agent等),常见基准:GSM8K-小学奥数式数学题、MATH-高难度数学、AIME/AMC-奥林匹克数学、GPQA-博士级科学问答、BigBench Hard (BBH)-推理难题集合 等。
② 语言理解与知识能力 (Language / Knowledge)
"通用模型 IQ 测试",常见基准:MMLU-大学生多学科理解测试、MMLU-Pro - 更难版本、ARC / HellaSwag - 常识推理、OpenBookQA/TriviaQA - 事实/知识问答 等。
③ ✨编程能力 (Coding)
"商业价值极高的应用点",常见基准:HumanEval - 函数级别代码生成、MBPP / MBPP+ 简单编程题、SWE-Bench / SWE-Bench Verified✨:真实 GitHub issue + 多文件工程 (最接近真实开发场景,近两年厂商都在比这个)、Codeforces-算法比赛、CRUXEval / RepoBench-项目级分析 等。
④ 多模态能力 (Multimodal)
"下一代 AI 产品的必争之地" (做 AI 助手、看图、自动化办公等),常见基准:MathVista:带图的数学推理、ChartQA / DocVQA:文档理解、TextCaps / ImageNet:视觉场景理解、VideoMME:视频理解、V-Bench / VQAv2:视觉问答 等。
⑤ 安全性 (Safety / Robustness)
企业用户很看重 "安全合规",常见基准:Harmlessness / Truthfulness、AdvBench:对抗攻击、Red Team 红队测试、Over-Refusal 测试(不会乱拒绝)、Speculative Safety(推测生成的风险)等。
⑥ 速度/延迟/吞吐 (Performance Metrics)
"决定实际用户体验",常见指标:Tokens per second (推理速度)、First Token Latency (首字延迟)、Throughput QPS (每秒处理请求数)、Context processing speed (长文档处理速度)。
有时还会发布一些 "技术参数":
🤡 个人 "主观" 认为的 "编程模型" 能力排名:
😊 一句话概括我的 "选模型策略":
选好的模型事半功倍!工程大活 找 Claude,精细小活 (如改BUG) 用 GPT,写前端页面用 Gemini。
🐶 问:这些都是国外的模型啊,怎么才能用上?A社还锁区,经常封号?而且价格好贵啊?
答:😏 这个问题充钱可以解决.jpg,多逛下海 (xian) 鲜 (yu) 市场,国人的 "薅羊毛" 能力不是盖的,各种 "镜像站、第三方中转" 。氪金的时候注意找有 "售后" 的,随用随充,买 "短期 (如月付) ",不要买 "长期 (如年付)",这种看 LLM官方 政策的,一封就直接G了,说不定就 "卷款跑路"~
😄 一句话归纳:
普通开发者 & Vibe Coding用户 用 AI IDE/插件 居多,DevOps/后端工程师 用 CLI,团队/企业系统 用 云端Agent,AI 应用开发者 用 AI SDK 构建构建 AI 产品与 Agent 系统。
接着说下 "AI编程" 的三种演进层次~
最早期的AI开发方式,以「人主导 + AI辅助」为核心逻辑,由两种交互模式组成:
这一层的局限:
目前最前沿、最热门的阶段,AI 不再只是吐出代码片段,而是进化为 Agent (智能体),拥有了 "大脑" (规划能力) 和 "手脚" (工具使用能力),可以 "自主完成一个多步骤的开发任务"。
变成了「人定目标 + Agent 自主执行」,如:"实现一个简单的待办事项 Web 服务,要求:REST API,内存存储即可,有单元测试",Agent 可能会进行这样的任务拆解并执行:
设计目录结构 → 创建代码文件 → 写业务逻辑 → 写测试 → 运行测试并自我修复。
为了系统地应用 Agent,业界逐渐采用「 "规范"驱动的开发流程」(Spec-Driven Development):
需求 → 规范文档 → 任务分解 → Agent执行 → 验证反馈
这个流程确保了 清晰的目标定义 和 可追踪的执行过程,而不是让Agent盲目操作。开发者需要维护的 "三类规范" (规范必须比写代码更清晰):
人不再写代码 (或者少写),负责「定义 + 审核 + 授权」,人-Agent 协作 的三阶段循环:
💡 层2 关注的是「开发流程自动化」,任务的起点通常是 "已经确定好的需求/feature"。
所谓的 "AI 全栈",本质上就是 "让 AI 同时扮演多个软件开发角色",而 "一人分饰多角" 的自然实现方式就是 "多 Agents"。——《抠腚男孩》
🤔 想象一下让 "AI全栈开发一个应用" 需要经历哪些步骤?
产品需求理解 → 技术选型 → 架构设计 → API 设计 → 前后端代码生成 → 数据库 schema → 错误处理 → 文档生成 → 单测编写 → 测试执行 → 部署脚本 → CI/CD 配置。
让一个 Agent 承包上面所有的工作,会有什么问题?
记忆量爆炸、目标切换频繁、推理链拉得太长,错误积累变大、一旦一步出错,后续全崩、风格、结构、代码质量难统一、难以并行。
软件工程是 "多角色协作" 的结果:产品经理、架构师、后端、前端、测试、文档、DevOps... 如果想 "AI 模拟完整的软件开发流程",自然也需要 "让 AI 也模拟这些角色",于是就变成了这些 Agent:
即「AI 全栈 = AI 软件开发流水线 = 模拟整个软件部门 = 多 Agent 系统」,这是开发任务决定的。
"AI全栈" 需要的三大核心能力:
"AI 全栈系统" 的实现,本质就这四步:
一句话概括就是:
AI 全栈 = 一群小模型/小角色 + 一个调度关系图 + 一堆工具函数 + 一圈安全护栏
😄 弄清楚本质,以后看任何 "AI 全栈多 Agents" 方案,都可以基于这三个问题进行快速拆解:
前面AI常识部分有提到过,这里直接让🍌画个图~
🤡 上面的理论看起来简单,但对于个人来说,想要亲手实现这样 一整套多 Agents AI 全栈系统,工作量爆炸:
得自己写调度、管状态、接工具、控安全、做可视化,还要维护一堆 prompt 和配置,算完整平台工程了...
🤔 笔者认为 "个人级AI全栈" 更倾向于:
在个人可以承受的复杂度和时间成本内,让AI参与尽可能多的开发环节,而不是一次性造一个企业级AI工厂。
😄 其实,你可能已经在无形中体验 "AI 全栈" 的雏形了,现代 AI 编程工具 本身就内置了 多 Agent 编排能力~
① Claude Code Sub Agents
CC 中允许创建多个带 独立角色与上下文 的 Sub Agent (小型专属AI工作者),用法简单:
保存后,会在 .claude/agents/ 生成一个类似这样的文件:
---
name: backend-dev
description: "专门负责后端接口、服务逻辑和数据库相关代码的实现与修改"
model: sonnet
tools: [file_search, file_edit]
color: blue
---
你是一个资深后端工程师,精通 Node.js + TypeScript 和这个项目的后端架构。
你的职责:
- 只改后端相关的代码(controllers, services, repositories)
- 遵循项目现有的代码风格和结构
- 所有改动都要尽量小步、安全、可读
在给出修改时:
- 标明文件路径
- 用 patch 的风格展示修改
- 如果需要新增文件,要说明用途和引用关系
不想自动生成,可以在 .claude/agents/ 手动按照上面的格式自己写md,保存后 CC 会自动识别。还可以在命令行启动CC时添加 --agents 参数 (适用于临时挂载场景):
claude --agents '{
"log-analyzer": {
"description": "分析测试日志和错误堆栈的专用Agent",
"system_prompt": "你只负责阅读测试输出、日志,帮助定位问题和怀疑文件,不写代码",
"tools": ["file_search"]
}
}'
test-runner subagent to run the unit tests.② Cursor 2.0 多 Agent 编排
2.0 后,Cursor 界面从 "以文件为中心" 变成 "以Agent为中心",多了个 Agent Layout,切换后,侧边栏会显示当前 Agent、计划(plan)和改动,你把需求丢进去,Agent 负责读文件、计划、改代码、跑测试。
支持 同一指令 下,最多可 并行 (Parallel) 跑 8 个 Agent,每个 Agent 会在自己独立的 Git worktree / 沙盒工作区 内工作:各自改代码、build、跑测试,不会互相冲突 (🤡 就是费 Token...)。还多了一个 Plan Mode (先规划再执行),在 Agent 输入框 中按 Shift + Tab 可以切换到这个模式 (也可以手动选):
Cursor 不会直接假设你的需求,而是询问一系列澄清问题:
通过这些澄清,使 AI获得了完整的上下文,可以生成更精确的计划,避免后续的返工。接着会生成一个 plan.md 的计划文档:
你可以对文件进行编辑:增删任务、调整任务顺序、更新技术细节、调整实现方法等。确定无误后,点击 Build,Agent 会读取最新版本的 plan.md,并完成对应的任务。
🤔 与 CC Sub Agents 可编排不同,Cursor 的 Agent 更像是一个组合能力的 "大Agent",由它自动编排多个内嵌的、对用户不可见 的 Agent 来完成 用户提出的任务,收敛复杂性,只展示改动/测试结果。它的 Parallel Agents 探索不同方案,最后再汇总/合并的玩法,不算严格意义上的 "主流多 Agent 架构模式" 中的 "并行Agents模式"-支持显式地定义 / 分配 不同角色的 Agent,并让它们并行协作。
类似的支持 "多Agents" 玩法的 AI 编程工具还有:
觉得 AI编程工具 满足不了,接着就是围绕自己的开发流程,开发基于 LLM 的 API 封装一些 小脚本/小工具。
// 推进开发闭环的简单伪代码 (需求 → 修改 → 测试 → 修复)
plan = llm("你是架构师,帮我拆解这个改动需求…")
files = find_related_files(plan)
patches = llm("你是后端开发,只能改这些文件…", files + plan)
apply_patches_to_workdir(patches)
test_result = run_tests()
if test_result.failed:
fix_patches = llm("你是调试工程师,根据报错修复…",
test_result + current_code)
apply_patches_to_workdir(fix_patches)
大多数个人开发者达到这一层,基本够用了,再往上就是加:日志、可配置、一点UI、简单任务管理等,弄成一个仅为自己服务的 "AI 全栈开发小平台" (😄 此时更像是一个 Agent 工程师,搭建 "企业级AI全栈" 的基石)。
根本原则:
在一个完整开发周期里 (从想法到上线),有意识地让 AI 参与尽可能多的环节,并用 "多角色思维" 来组织这些调用,但工程复杂度要控制在个人能持续维护的范围内。
① 项目级自检
② 项目阶段拆解
③ 搭建可复用工作流
行文至此,再回看这篇拖了许久的 "年终总结",心情早已从最初面对 AI 秒解 Bug 时的 "破防" 与 "迷茫",变得平静且笃定,我们:
但归根结底,AI 带来的最大变量,不在于它替我们写了多少行代码,而在于它重塑了 "专业" 的定义。
"技术焦虑" 的解药,从来不是拒绝变化,而是成为变化的一部分。以前,我们的壁垒是 "熟练度+记忆力",以后则是 "想象力+判断力+系统工程能力",拥抱AI,在这个属于创造者的时代,进化为无所不能的 "超级个体🦸♀️"!