LongCat-Flash:如何使用 SGLang 部署美团 Agentic 模型
SGLang 团队是业界专注于大模型推理系统优化的技术团队,提供并维护大模型推理的开源框架SGLang。近期,美团M17团队与SGLang团队一起合作,共同实现了LongCat-Flash模型在SGLang上的优化。
设计一个数字容器系统,可以实现以下功能:
请你实现一个 NumberContainers 类:
NumberContainers() 初始化数字容器系统。void change(int index, int number) 在下标 index 处填入 number 。如果该下标 index 处已经有数字了,那么用 number 替换该数字。int find(int number) 返回给定数字 number 在系统中的最小下标。如果系统中没有 number ,那么返回 -1 。
示例:
输入: ["NumberContainers", "find", "change", "change", "change", "change", "find", "change", "find"] [[], [10], [2, 10], [1, 10], [3, 10], [5, 10], [10], [1, 20], [10]] 输出: [null, -1, null, null, null, null, 1, null, 2] 解释: NumberContainers nc = new NumberContainers(); nc.find(10); // 没有数字 10 ,所以返回 -1 。 nc.change(2, 10); // 容器中下标为 2 处填入数字 10 。 nc.change(1, 10); // 容器中下标为 1 处填入数字 10 。 nc.change(3, 10); // 容器中下标为 3 处填入数字 10 。 nc.change(5, 10); // 容器中下标为 5 处填入数字 10 。 nc.find(10); // 数字 10 所在的下标为 1 ,2 ,3 和 5 。因为最小下标为 1 ,所以返回 1 。 nc.change(1, 20); // 容器中下标为 1 处填入数字 20 。注意,下标 1 处之前为 10 ,现在被替换为 20 。 nc.find(10); // 数字 10 所在下标为 2 ,3 和 5 。最小下标为 2 ,所以返回 2 。
提示:
1 <= index, number <= 109change 和 find 的 总次数 不超过 105 次。在 ES6 中,函数不仅可以通过传统方式 fn() 调用,还可以通过 标签模板(Tagged Template Literals) 的方式 fn...`` 调用。
两种调用方式的核心差异是参数传入的方式:
fn():手动传参。fn...``:由 JavaScript 自动将模板字面量分解为 静态字符串数组 和 动态表达式结果,并传递给函数。function add(a, b) {
return a + b;
}
console.log(add(2, 3)); // -> 5
👉 参数完全由调用方提供。
function tag(strings, ...values) {
console.log(strings); // 静态部分数组
console.log(values); // 插值表达式的计算结果
}
const name = "Alice";
const age = 20;
tag`Hi, my name is ${name} and next year I will be ${age + 1}`;
执行过程:
模板字面量 Hi, my name is ${name} and next year I will be ${age + 1}
JS 引擎分割为:
strings = ["Hi, my name is ", " and next year I will be ", ""]values = ["Alice", 21]调用函数:tag(strings, "Alice", 21)
👉 这说明 模板中的 ${...} 可以是任意合法表达式,不仅仅是变量。
| 特性 |
fn() 调用 |
fn...`` 调用 |
|---|---|---|
| 参数来源 | 显式传入 | 模板字面量分解自动传入 |
| 动态表达式支持 | 需手动写表达式并传参 | 模板内部直接写 ${...},自动求值 |
| 可读性 | 适合逻辑函数 | 更适合描述文本/DSL 场景 |
| 典型应用 | 算法、业务逻辑 | SQL 构造、HTML 渲染、国际化、CSS-in-JS |
function sql(strings, ...values) {
// 将插值安全转义(演示用,真实情况需更严格处理)
const safeValues = values.map(v => `'${v}'`);
// 拼接完整 SQL
return strings.reduce((result, str, i) => result + str + (safeValues[i] ?? ""), "");
}
const table = "users";
const minAge = 18;
const maxAge = 30;
// 模板中可直接放表达式:范围查询
const query = sql`SELECT * FROM ${table} WHERE age BETWEEN ${minAge} AND ${maxAge + 5}`;
console.log(query);
// 输出: SELECT * FROM 'users' WHERE age BETWEEN '18' AND '35'
👉 注意 ${maxAge + 5} 就是 表达式,计算后再传入函数。
function i18n(strings, ...values) {
const dict = { "Hello": "你好", "years old": "岁" };
return strings.reduce((res, str, i) => {
const translated = dict[str.trim()] || str;
return res + translated + (values[i] ?? "");
}, "");
}
const user = { name: "小明", birth: 2000 };
const currentYear = 2025;
// 模板中写表达式:年龄 = 当前年份 - 出生年份
console.log(i18n`Hello ${user.name}, you are ${currentYear - user.birth} years old`);
// 输出: 你好 小明, you are 25 岁
👉 模板里的 ${currentYear - user.birth} 表达式先求值,再传给标签函数。
GraphQL
import { gql } from "@apollo/client";
const query = gql`
query {
user(id: ${42}) {
name
}
}
`;
👉 gql 就是一个标签函数,接收模板片段并解析为 AST。
CSS-in-JS(styled-components)
const Button = styled.button`
background: ${props => props.primary ? "blue" : "gray"};
color: white;
`;
👉 通过 ${表达式} 可以根据组件属性动态生成 CSS。
${func()} 内部函数若有副作用,模板调用时可能引发隐式执行。fn() 调用:传统传参,适合业务逻辑。fn...`` 调用:标签模板调用,自动传入 字面量片段数组 + 表达式求值结果,不仅能传变量,还能传 任意 JS 表达式。作为基于react.js的全栈框架next.js在现在不可谓不热门,我个人也上手用了一段时间,体验上面来说还是不错的。所以在这里,给大家分享一下next.js的入手指南!
如果有理解不到位的地方,还请指正!
该篇落简单介绍next.js是什么,和react.js的关系,以及怎么创建一个next.js的项目。
这一篇落,我们来认识一下什么是next.js,为什么要使用它来进行开发。
首先,我们要了解next.js这个框架,就要知道一个点,那就是next.js是基于react.js之上构建的一个全栈框架,也可以说是react.js的框架。
并且,在react.js的基础上,next.js增加了更多的附加功能和其他优化。
既然next.js也是基于react.js的,那为啥用next.js而不是直接用react.js呢?
这是因为next.js它本身就有几个react.js默认没有的优点:
SSR和SSG,有着更好的SEO和首屏加载速度;react-router;API系统,例如博客这类简单的后端功能甚至直接可以用next.js完成;这是我认为next.js相比react.js下,体现出来的优点,当然也还有其他的地方。
这是我们经常能听到的两个名词:SSR和SSG,他们对应的中文翻译叫做:服务端渲染和静态站点渲染。区别就是在于一个是实时渲染,一个是构建时预渲染,具体区别如下:
| 方式 | SSR | SSG |
|---|---|---|
| 渲染时机 | 请求的时候 | 构建的时候 |
| 响应速度 | 快 | 很快 |
| 服务器压力 | 中 | 小 |
| 适合场景 | 需展示最新的数据 | 固定显示的内容 |
这一篇落,我们来说一下如何用next.js官方的脚手架创建一个项目并且简单介绍目录结构的功能。
创建next.js的项目,我们需要使用create-next-app来进行项目搭建,打开终端,输入以下命令:
npx create-next-app@latest demo
此时,可以看到界面询问我们创建next.js需要选择的功能,这个按个人需求来选择,选择完成后最终效果如下图:
此时,项目已经创建完毕,使用VSCode打开该项目。默认情况下,目录结构下的内容并不多,这里我们需要了解的是几个地方:
next.js的框架配置文件,功能很多也很重要eslint的配置文件现在,我们着重关注的应该是src目录,之后的许多工作如业务代码编写,都会在该目录下进行。
从这一篇落起,就一直在提到目录,是因为在
next.js项目中,目录非常重要。在
next.js中,有着默认的约定,例如这里:src/app目录下就对应页面目录,每一个以page.tsx命令的文件就是一个页面。我们要严格遵循
next.js的目录约定,否则会有意想不到的问题产生!
目录结构是next.js的一个重点,因为next.js的目录命名是约定式的,即不同的目录命令可能对应着不同的功能,若使用错误,则会导致意想不到的问题产生。
在next.js的目录中,包括布局、页面、中间件等等功能的命名约定...后面我们说的理论内容,也基本都和每个目录或文件有关。
对于静态文件,通常在public目录下进行存放,例如图片这一类的资源,当需要访问时,直接通过/即可。
例如:在public目录下有一张图片logo.png,访问方式如下:
<Image src="/logo.png" alt="logo" width={32} height={32} />
在next.js中,命名为layout.tsx的文件就叫布局。他的功能在于,定义公共部分的UI,该部分UI不会受路由的切换而更新,通常用于导航栏、侧边栏或者底部。
例如下面的布局中,当我们切换路由时,变化的是main标签里面的内容,而header和footer标签内容不会改变。
export default function RootLayout({
children,
}: Readonly<{
children: React.ReactNode;
}>) {
return (
<html lang="en">
<body
className={`${geistSans.variable} ${geistMono.variable} antialiased`}
>
<header>Header</header>
<main>
{/* 当路由切换,这里的内容将进行更新 */}
{children}
</main>
<footer>Footer</footer>
</body>
</html>
);
}
另外,除了默认的根布局以外,我们还可以在app下每一个页面目录重新创建layout.tsx来定义子布局,以此来创建出更多的布局效果。
如果需要创建多个根布局,那就需要用到“组”概念,我们后续来谈。
页面是next.js的第二个核心功能,每一个页面我们都由page.tsx来命名。在next.js中,默认已经存在首页,即src/app/page.tsx文件。通过访问/根路径,我们将看到此页面。
如果想创建新的页面,那就需要新建一个新的目录,并且添加page.tsx文件。例如,这里我们在src/app目录下面,新建hello/page.tsx文件,编写如下代码:
function HelloPage() {
return (
<div>
HelloPage
</div>
);
}
export default HelloPage;
此时,我们就已经成功创建了一个页面,如何访问这个页面呢?还记得前面说的next.js重在约定嘛,在app目录下面的每一个目录命名,即代表页面路由的命名。
所以这里的hello目录名对应的路由即为/hello,此时访问/hello可以看到如下内容:
通过上面的例子可以实现页面和路由创建,那假如此时有这样一个新需求:通过访问hello/a或者hello/b或者hello/xxxx都能匹配到同一个页面,并根据匹配不同的路径来显示不同的内容。
这里就需要使用到next.js的动态路由功能了,动态路由以中括号[...]来命名,根据上面例子我们则需要更改hello目录为hello/[slug]/page.tsx。
这里的[slug]就表示动态匹配(slug不是必须这个格式,但是获取参数需要根据对应名称来获取)。
此时修改hello/[slug]/page.tsx代码如下:
async function HelloPage({ params }: { params: Promise<{ slug: string }>}) {
const { slug } = await params;
return (
<div>
Hello:{ slug }
</div>
);
}
export default HelloPage;
此时再访问/hello/a时,将会看到如下内容:
如何匹配多层动态路由
当需要捕获多层动态路由时,例如:/hello/a/b/c,此时就需要通过[...slug]这种方式命名目录,更改hello/[slug]/page.tsx为hello/[...slug]/page.tsx,修改为如下代码:
async function HelloPage({ params }: { params: Promise<{ slug: string[] }>}) {
const { slug } = await params;
return (
<div>
Hello:{...slug}
</div>
);
}
export default HelloPage;
此时再访问/hello/a/b/c将会看到如下页面:
这里的params是固定的写法,与searchParams不同,通过params来获取的是动态路由上面的参数!
[...slug]和[[...slug]]
动态路由的命名方式有两种,一种就是刚刚使用的[...slug],还有一种就是[[...slug]]。他们的区别就是在于,是否有匹配的动态参数。
例如当访问/hello时,[...slug]会出现404,而[[...slug]]依然呈现页面,只是没有参数。
除了动态路由的方式能获取参数以外,还可以通过路径后面的?追加参数并获取,例如当访问hello/a?name=cola时,此时可以通过下面方式获取参数:
async function HelloPage({
params,
searchParams
}: {
params: Promise<{ slug: string[]}>,
searchParams: Promise<Record<string, string>>
}) {
const { slug } = await params;
const { name } = await searchParams;
return (
<div>
Hello:{...slug},{name}
</div>
);
}
export default HelloPage;
此时页面将会更新为:
默认创建的页面都是服务端渲染的页面,即不能使用react.js的useState或者useEffect这类依赖浏览器类的api,需要定义变量直接在函数里面定义即可,也不需理会生命周期等元素,例如:
async function HelloPage({
params,
searchParams
}: {
params: Promise<{ slug: string[]}>,
searchParams: Promise<Record<string, string>>
}) {
const { slug } = await params;
const { name } = await searchParams;
const animals = ['松鼠', '大象', '老虎'];
// const [animals] = useState(['松鼠', '大象', '老虎'];); 不能使用,会报错
return (
<div>
<p>Hello:{...slug},{name}</p>
<p>{animals}</p>
</div>
);
}
export default HelloPage;
倘若我们需要页面进行客户端渲染而不是服务端渲染,此时则需要再page.tsx文件顶部添加'use client;'来进行标记,此时next.js将对该文件进行客户端渲染。
当使用客户端渲染时,此时就要用到react.js里面的useState或者useEffect这类钩子函数,而不是像服务端组件那样直接定义变量。
另外,在客户端组件中,因为不能使用async来定义函数,所以获取参数的方式也有变化,其改变如下代码所示:
'use client';
import { useSearchParams } from "next/navigation";
import { use } from "react";
function HelloPage({
params,
}: {
params: Promise<{ slug: string[]}>,
searchParams: Promise<Record<string, string>>
}) {
const { slug } = use(params);
const name = useSearchParams().get('name');
const animals = ['松鼠', '大象', '老虎'];
return (
<div>
<p>Hello:{...slug},{name}</p>
<p>{animals}</p>
</div>
);
}
export default HelloPage;
动态路由的参数params通过React.use来获取,而路径参数则通过useSearchParams方法获取之后,再通过get或者getAll获取参数。
注意事项
即使是使用了客户端渲染的页面,也可能出现window is not defined这类问题产生,这可能是由于引入的第三库直接就使用了window的原因。而next.js的页面呈现,也会在node环境下进行,所以导致该类问题产生。
解决方案:考虑在useEffect钩子函数里面动态引入。
在next.js目录中,我们可以用not-found.tsx文件来命名404页面,不过情况又分为两种。
路径404页面是指我们访问不存在的路由时,展示出来的页面。一般来说,当访问不存在的路由时,都会返回app目录下的not-found.tsx文件。
逻辑404页面是指,在页面中可能遇到不存在的情况时,需要通过代码来跳转到404页面。例如:动态路由需要传递[id],但此时获得了不为数字的id时,就可以通过执行notFound方法来跳转。
逻辑跳转会从当前目录的not-found.tsx文件开始查找,直到根目录下的not-found.tsx文件。
加载页面即loading.tsx是在数据还在请求或者组件正在挂载时,展示的页面。它也可以放在根目录或者其他页面目录下,其原理就等同于Suspense组件。
app/
dashboard/
page.tsx
loading.tsx
// 框架内部伪代码
<Suspense fallback={<DashboardLoading />}>
<DashboardPage />
</Suspense>
组和私有目录都是在app目录下,但不会被next.js识别为页面的两种命名形式。
组通过(...)来命名,可以用于多级根布局的实现,例如有模块A和模块B两个模块,需要不同的布局。此时,创建两个目录(A)和(B),然后分别在其目录下创建新的layout.tsx布局文件。
私有目录通过_来命名,可以用于表示存放组件的目录,例如页面pageA下需要创建一些只用于该页面的组件时,就可以在pageA目录下创建_components目录来存放。
并行路由和拦截路由都是不被next.js识别为页面的两种命名方式,拦截路由依托于并行路由来实现效果。
先来说一下并行路由,并行路由是在页面目录下通过@xxx/page.tsx命名的文件,该页面也可以像children一样通过layout.tsx展示,方式如下:
// pageB/@top/page.tsx
function PageBTop() {
return (
<div>
PageBTop
</div>
);
}
export default PageBTop;
// pageB/layout.tsx
import { ReactNode } from "react";
function LayoutB({
children,
top,
}: {
children: ReactNode,
top: ReactNode,
}) {
return (
<div className="border border-red-400">
<div>LayoutB-Header</div>
<div>{top}</div>
<div>{children}</div>
<div>LayoutB-Footer</div>
</div>
);
}
export default LayoutB;
其展示的页面如下:
对比写到一个page.tsx文件的好处就是,并行路由可以单独的写其他逻辑,例如loading.tsx和not-found.tsx等文件,甚至也可以在并行路由下创建新的路由。
注意:创建并行路由没有生效时,删除.next文件重新启动。
拦截路由是用于,当点击某个会进行路由跳转的UI(图片、按钮等)时,不进行页面跳转,而是在当前页面中进行显示,写法为:
(.)匹配同一级别的段
(..)匹配上一级的段
(..)(..)匹配上两级的段
(...)匹配根 app目录中的段现在修改pageB目录,将@top/目录为@top/(..)pageA/page.tsx,此时当在pageB目录下的进行点击跳转到/pageA路由时,将会弹出@top/(..)pageA/page.tsx下的文件,如下:
// @top/(..)pageA/page.tsx
function PageA() {
return (
<div className="fixed left-1/2 top-1/2 -translate-1/2 w-lg aspect-[3/2] border border-gray-100 bg-white shadow-md p-3 rounded-md">
PageA
</div>
);
}
export default PageA;
提示
上面记得要在@top目录下创建一个default.tsx文件,否则会出现404问题,内容如下即可:
// @top/default.tsx
function Page() {
return null;
}
export default Page;
// pageB/layout.tsx
import Link from "next/link";
import { ReactNode } from "react";
function LayoutB({
children,
top,
}: {
children: ReactNode,
top: ReactNode,
}) {
return (
<div className="border border-red-400">
<div>LayoutB-Header</div>
<div>
{children}
<Link href="/pageA">拦截路由</Link>
</div>
<div>LayoutB-Footer</div>
{top}
</div>
);
}
export default LayoutB;
点击拦截路由跳转时,页面效果如下:
提示
拦截路由不会影响直接在浏览器中输入路由的操作,意味着输入/pageA路由时依然展示为pageA页面。
建议
如果不是非得使用拦截路由和并行路由的话,暂时不建议。我在一些论坛上看到挺多人提出问题的,自己在学习这部分时也有问题,有时需要删除.next重新启动服务才能解决。
在next.js中,中间件一般是用来做路由拦截、响应或者鉴权来使用的。通过在src或者根目录下创建文件middleware.ts来使用,并且需要默认导出一个函数,如下:
// src/middleware
export default function middleware() {
console.log('middleware.');
}
当刷新页面后,可以看到终端打印如下,输入了很多'middleware'语句:
这是因为middleware处理的不仅仅只是路由请求,还有其他资源请求,修改代码如下,再刷新页面可以看到:
// src/middleware
import { NextRequest } from "next/server";
export default function middleware(req: NextRequest) {
console.log(req.url + ':middleware.');
}
如果需要对指定路径进行处理的话,就需要使用匹配器,其使用方法如下:
// src/middleware
import { NextRequest } from "next/server";
export default function middleware(req: NextRequest) {
console.log(req.url + ':middleware.');
}
export const config = {
matcher: ['/pageB'],
}
此时只有当请求路径为/pageB的路径才会被中间件处理,刷新页面后打印效果如下:
所以,通过中间件功能我们也可以实现鉴权等功能,例如:
// src/middleware
import { NextResponse } from 'next/server';
import type { NextRequest } from 'next/server';
export function middleware(req: NextRequest) {
const token = req.cookies.get('token');
if (!token) {
return NextResponse.redirect(new URL('/login', req.url));
}
}
export const config = { matcher: ['/dashboard/:path*'] };
中间件的功能还是比较丰富的,就不一一赘述了,具体可以看文档:next.js中间件
在next.js中可以通过在app目录下创建api目录来作为后端接口,进行响应。
目录名称api是固定写法,可以通过next.config.ts配置文件进行修改。
在api目录下,可以新建新的目录进行api接口命名,类似页面那样,例如在api目录新建hello/route.ts文件,就代表接口为:/api/hello。
现在已经知道怎么创建一个api了,如何创建对应的响应呢?通过next.js提供的写法来实现,如下:
// src/app/hello/route.ts
import { NextResponse } from "next/server"
export const GET = () => {
return NextResponse.json({
code: 0,
data: 'this is data',
}, { status: 200 });
}
上面的GET方法就表示为/api/hello的Get请求处理逻辑,其他请求类型写法也一样。此时,打开浏览器访问http://localhost:3000/api/hello,可以看到显示如下:
在next.js中,元数据其实就是通过js对象来管理head标签的一种方式,其作用包含对SEO的优化等,分为两种情况。
静态元数据,即固定显示的,无需动态修改。通过导出一个metadata对象即可,例如:
import { Metadata } from "next";
export const metadata: Metadata = {
title: 'PageC',
description: 'PageC description.'
}
function PageC() {
return (
<div>
PageC
</div>
);
}
export default PageC;
上面我们定义了title和description两个元数据,此时再看页面可以发现:
当元数据需要动态添加时,此时就不能直接用对象的方式定义,而是通过函数generateMetadata来实现,如下:
import { Metadata } from "next";
export const generateMetadata = async (): Promise<Metadata> => {
const getMetaData = () => new Promise<{ title: string, description: string }>(resolve => setTimeout(() => {
resolve({
title: 'Async PageC',
description: 'Async PageC description.'
})
}, 1e3));
const { title, description } = await getMetaData();
return {
title,
description
}
}
function PageC() {
return (
<div>
PageC
</div>
);
}
export default PageC;
此时在页面上可以看到动态添加的属性,如下图:
元数据的配置还有很多,具体可以看:next.js元数据
在next.js中内置了经过优化的Image图像组件,使用该组件时需满足以下任意一条:
width和height属性;fill属性;例如:
function PageC() {
return (
<div>
PageC
<Image src="/cover.jpg" alt="img" width={80} height={120} />
<div className="w-[80px] h-[120px] relative">
<Image src="/cover.jpg" alt="img" fill />
</div>
</div>
);
}
export default PageC;
倘若使用远程图片的话,则需要在next.config.ts中进行配置,否则构建阶段可能出现意想不到的问题,具体配置可以看:next.js内置图像组件。
在next.js中,请求接口一般采用fetch方法,并在next.js对于fetch方法进行了扩展,增加了缓存的功能,而且缓存不仅与请求,对于页面来说next.js也进行了缓存功能的实现。
在使用fetch时,当我们添加了如下参数,即进行了缓存:
// 此时在一分钟内的请求都会返回缓存的数据
fetch('https://...', { next: { revalidate: 60 } });
如果说不需要缓存功能的话,则用如下方式请求:
fetch('https://...', { cache: 'no-store' });
另外,在扩展的fetch请求中还可以通过打上tag来强制刷新,例如:
fetch('https://...', { next: { tags: ['test'] } });
当执行revalidateTag('test')后,下一次带有test标签的请求将会获取最新的数据。
在页面中,可以通过定义revalidate属性来配置缓存效果,例如:
export const revalidate = 60;
function PageC() {
return (
<div>
PageC
</div>
);
}
export default PageC;
此时,当通过next build构建时,将会预渲染这个页面,并且能缓存60s的时间,当过了缓存时间后再请求新的页面数据,该配置有3种:
SSG模式,不再对页面进行动态渲染;SSR来渲染页面;默认来说,在next.js中是通过静态生成+SSR方式来进行构建的,也就是所谓的ISR增量静态再生。
对于样式来说,第一个推荐直接使用css文件,然后在页面或者组件中直接引入,类似默认next.js项目引入global.css一样。
第二个就是推荐创建next.js时,可选安装的tailwindcss工具,这个工具是一个原子化CSS的写法,用起来非常方便和简洁。
在创建next.js时,也可选用eslint工具,此时会在根目录生成eslint.config.mjs文件,内容如下:
import { dirname } from "path";
import { fileURLToPath } from "url";
import { FlatCompat } from "@eslint/eslintrc";
const __filename = fileURLToPath(import.meta.url);
const __dirname = dirname(__filename);
const compat = new FlatCompat({
baseDirectory: __dirname,
});
const eslintConfig = [
...compat.extends("next/core-web-vitals", "next/typescript"),
{
ignores: [
"node_modules/**",
".next/**",
"out/**",
"build/**",
"next-env.d.ts",
],
},
];
export default eslintConfig;
如果需要自定义规则的话,可以修改上述代码,例如:
const eslintConfig = [
...compat.config({
extends: ['next/core-web-vitals', 'next/typescript'],
// 自定义插件
plugins: ['simple-import-sort'],
// 自定义规则
rules: {
'semi': ['warn', 'always'],
'quotes': ['error', 'single'],
'simple-import-sort/imports': 'error',
'simple-import-sort/exports': 'error'
}
}),
{
ignores: [
'node_modules/**',
'.next/**',
'out/**',
'build/**',
'next-env.d.ts',
'src/components/ui/**'
],
},
];
这里推荐一个工具:shadcn,他不是单纯的UI库,而是将radix-ui、tailwindcss、theme、icon等整合的一个工具平台,安装也很简单,如下:
npx shadcn@latest init
具体细节可以看:shadcn文档
以上就是next.js的常用基础概念,因为其概念比较多,不能都详细说明,当然这也是优秀强大的框架带来的学习成本。其生态技术远不止这些,感兴趣的话可以通过论坛、视频等再进行学习!
2025年9月16日,人人可用的开源BI工具DataEase正式发布v2.10.13 LTS版本。
重要更新:AI智能问数能力全面升级
DataEase v2.10.13 LTS版本重磅引入全新的开源智能问数系统SQLBot(*github.com/dataease/SQ… *),完全替代DataEase原有的Copilot功能。SQLBot是基于大语言模型和RAG(Retrieval Augmented Generation,检索增强生成)的开源智能问数系统,帮助用户实现数据的即问即答,有效提升数据查询的智能化水平。
与同类产品相比,SQLBot的优势体现在以下方面:
■ 更快速:通过自然语言即可快速生成复杂的SQL查询;
■ 更精准:智能理解业务意图,大幅减少查询错误;
■ 更开放:基于开源架构,支持社区贡献和自定义扩展。
DataEase嵌入SQLBot后将全面升级用户的智能问数体验,辅助用户高效挖掘数据价值,让数据分析变得更加简单和直观。
DataEase v2.10.13 LTS版本的其他功能变动包括:查询组件方面,日期查询组件增加快捷选项;仪表板/数据大屏方面,通用配色增加斑马纹配色;系统设置方面,系统变量值支持设置别名。
X-Pack增强包的功能变动包括:数据填报方面,内置数据源增加支持数据填报功能配置。
■ feature(系统参数):支持SQLBot嵌入设置;
■ feature(仪表板、数据大屏):通用配色增加斑马纹配色;
■ feature(查询组件):日期查询组件增加快捷选项;
■ feature(系统设置):系统变量值支持设置别名(#16713);
■ feature(X-Pack,数据填报):内置数据源增加支持数据填报功能配置。
■ refactor(图表):优化移动端跳转问题;
■ refactor(数据大屏、仪表板):资源发布时,清理无用数据(#16749);
■ refactor(X-Pack,定时报告):定时报告页面增加额外等待时间设置;
■ refactor(X-Pack,用户管理):创建用户API接口返回数据增加用户ID(#16825);
■ refactor(X-Pack,同步管理):使用Quartz统一管理任务调度;
■ refactor(X-Pack,同步管理):对Elasticsearch数据源时间类型字段进行优化,默认映射为Doris的String类型;
■ refactor(X-Pack,同步管理):优化任务状态刷新机制;
■ refactor(X-Pack,同步管理):优化同步日志提示信息;
■ refactor(X-Pack,同步管理):优化同步配置参数传递逻辑;
■ refactor:更新移动端样式。
■ fix(图表):修复放大Tab中图表并执行导出图片操作后,轮播提示显示异常的问题;
■ fix(图表):修复明细表合并单元格后,维度存在空值时导出失败的问题(#16777);
■ fix(图表):修复明细表基础样式勾选“自动换行”选项后,表头会出现部分信息不显示的问题(#16804);
■ fix(图表):修复明细表字段全都是维度时,导出的Excel文件中单元格合并失效的问题;
■ fix(图表):修复水波图标签被裁剪的问题(#16798);
■ fix(图表):修复查询组件首选项会影响跳转条件的问题;
■ fix(图表):修复透视表列维度为空时,带格式导出会失败的问题;
■ fix(图表):开启轮播提示的图表启用缩略轴时,禁用轮播提示;
■ fix(图表):修复透视表自定义汇总时,通过搜索添加字段会报错的问题;
■ fix(图表):修复地图中福州与福清、平潭的连线出现多余连接线的问题(#16877);
■ fix(图表):字段自定义排序去除空值(#16307);
■ fix(图表):修复明细表隐藏列后,导出数据出现错乱的问题(#16785);
■ fix(查询组件):修复设置默认值和必填项,同时隐藏查询按钮时,输入任意值回车后均会重置为默认值的问题(#16750);
■ fix(查询组件):修复手动输入型选项值在查看时,默认值显示为未勾选状态的问题(#16709);
■ fix(查询组件):修复开启首选项时未关闭查询按钮,导致查询按钮失效的问题(#16894);
■ fix(查询组件):修复文本搜索需两次回车才能返回结果,首次触发显示“暂无数据”的问题;
■ fix(查询组件):修复时间范围组件默认值提示“超出日期筛选范围”的问题(#16914);
■ fix(查询组件):修复行权限与过滤组件“首项”默认值同时使用时,会导致过滤功能失效的问题;
■ fix(仪表板):修复手动输入型查询组件出现样式错位的问题;
■ fix(仪表板):修复仪表板缩放模式切换为“按组件比例缩放”后,保存发布再次查看不生效问题(#16885);
■ fix(数据大屏):修复Tab及内部组件的右键菜单定位偏移问题;
■ fix(仪表板、数据大屏):修复设置图表背景图时出现多余滚动条问题;
■ fix(数据源):修复调整浏览器窗口大小时,Excel字段选择器的选中状态被隐藏的问题;
■ fix(数据源):修复无数据源时点击“创建数据集”按钮,页面卡死且控制台报错的问题(#16831);
■ fix(数据源):修复飞书渠道查看更新记录提示异常的问题;
■ fix(数据源):修复SQL Server数据过滤异常的问题;
■ fix(数据源):修复Calcite转SQL Server时CONCAT函数异常的问题(#16860);
■ fix(数据源):修复SQL Server下拉树组件报错问题;
■ fix(数据集):修复字段表达式引用新建计算参数失效的问题;
■ fix(数据集):修复自定义SQL未保存直接关闭时缺少提示信息的问题;
■ fix(系统设置):修复三方嵌入配置仅保存不验证时,错误触发应用状态变更的问题;
■ fix(系统设置):修复弹窗层级显示异常的问题;
■ fix(X-Pack,同步管理):修复SQL查询验证错误;
■ fix(X-Pack,同步管理):修复SQL Server表名含@符号时任务创建失败的问题;
■ fix(X-Pack,同步管理):修复下次执行时间计算错乱问题;
■ fix(X-Pack,同步管理):修复数据源异常时同步日志丢失的问题;
■ fix(X-Pack,同步管理):修复SQL Server uniqueidentifier字段导致定时任务创建失败的问题;
■ fix(X-Pack,同步管理):修复字段数量过多导致任务创建失败的问题;
■ fix(X-Pack):修复“权限配置”→“按用户配置”时,用户量过大导致页面卡顿的问题;
■ fix(X-Pack):修复移动仪表板后,后台缓存未即时刷新的问题;
■ fix(X-Pack):修复在“组织管理”模块中修改名称需刷新浏览器才能生效的问题(#16751);
■ fix(漏洞):修复DB2 LDAP存在的SSRF漏洞(CVE-2025-58045);
■ fix(漏洞):修复Impala数据源JDBC攻击漏洞(CVE-2025-58046);
■ fix(漏洞):修复Redshift JDBC绕过漏洞(CVE-2025-58748);
■ fix:修复模板市场地址提示错误(#16858);
■ fix:统一数据大屏与仪表板事件触发规则,编辑状态下禁止触发;
■ fix:修复存储单位判断脚本中非GB单位的处理问题。
大家好,我是唐某人~ 我非常乐意与大家分享我在AI领域的经验和心得。我的目标是帮助更多的前端工程师以及其他开发岗位的朋友,能够以一种轻松易懂的方式掌握AI应用开发的技能。希望我们能一起学习,共同进步!
在前文《教你如何用 JavaScript 实现 Agent 系统(一)—— Agentic System 概览》中,我详细介绍了Agent系统的基本概念,并探讨了构建一个基础的单体Agent的方法。
最近一个月,我写了多篇关于人工智能的文章,并总结了一些经验。首先文章不宜过长,否则写作费劲,阅读也累,容易失去思路。其次,使用实际例子比过多理论更有效,这样不仅吸引人,还能带来成就感,内容也更生动具体、易于接受。
回顾和总结后,我计划将未来的内容分为四个部分来写,以提高效率并保证每部分都有深度。然后,我会通过实现一个“深度搜索”的应用来引导大家实践,希望能激发大家动手实践的兴趣。
未来的内容的核心是:学习四种主流的 Agent 设计模式,并且用这些模式实现四个不同版本的 “深度搜索”。
所以本篇的目的:
在实践之前,我们先来了解一下什么是深度搜索?这里给大家演示两个产品,你自己也可要去体验一下。
千问会基于用户提出的问题,首先生成一个研究分析框架。随后,它会在整个互联网范围内自动搜集相关信息,并通过持续的信息检索、分析与综合处理,最终产出一份详尽且全面的问题分析报告。
可以根据用户的问题,自动规划研究、全网搜集资料并进行综合分析,最终提供一份分析报告。
它的本质是通过 LLM 与搜索工具结合来解决问题。具体步骤如下:
比起让大模型只用预训练时的数据来回答问题,这种“深度搜索”方式在时效性和准确性上表现更好。所以,在处理学术研究、时事新闻、金融分析等领域的问题时,它特别合适。
官方的说,ReAct(由Yao在2023年提出)是一种让 LLM 理通过思考、行动、观察的循环来完成任务的框架。简单的说,它就是一种提示词工程和代码实现的设计模式。其工作流程如下:
为了让大家对这个流程有一个更直观的理解,我准备了一张流程图供大家参考。
首先,我们需要明确两个关键角色以及它们的关键组成部分:
简化后的内容如下:
好的,我们已经掌握了理论基础,接下来就进入实战阶段吧!我们将通过构建一个 ReAct 版本的“深度搜索”项目,来更直观地体验和理解ReAct模式的工作原理。希望这个过程能让你有更深的体会!
首先还是老套路,构建 Agent 的三个基础是 LLM、对话记忆、工具调用,所以我们得封装一个增强版本的 LLM。核心是功能:
因为这些内容在上一篇详细讲过,下面只展示一下核心代码,完整代码请看 github.com/zixingtangm… 的实现。
export class Block {
// 其他属性……
// 对话内容
private messages: Message[] = [];
constructor(config: BlockConfig) {
// 初始化
}
// 对话
public async invoke(messages?: Message[]): Promise<AssistantMessage> {
const { model, apiKey, baseUrl, response_format } = this.llmBaseConfig;
// 记录用户对话
if (messages) {
this.messages.push(...messages);
}
// 调用 LLM API
const res = await fetch();
// LLM 回复的文本内容
let assistantMessage = '';
// 工具调用指令
let tools: Record<number, ToolCall> = {};
const reader = res.body?.getReader();
const decoder = new TextDecoder();
while (true) {
// 流式的存储 LLM 的回复以及工具调用指令
}
// 最终回复
let message: AssistantMessage;
// 没有工具调用,会直接回复
if (assistantMessage && Object.keys(tools).length === 0) {
message = new AssistantMessage(assistantMessage);
this.messages.push(message);
}
// 有工具调用,需要调用工具,自动触发一轮新的对话
if (Object.keys(tools).length > 0) {
// 提取参数
const tool_calls = Object.values(tools).map((tool) => tool);
// 记录 LLM 的工具调用指令
this.messages.push(message);
// 执行全部的工具
const callToolTasks = Object.values(tools).map(async (tool) => {
let result = '';
try {
result = await this.tools.call(tool.function.name, JSON.parse(tool.function.arguments));
} catch (error) {
result = `${tool.function.name} 执行异常`;
}
return JSON.stringify(result);
});
const toolResults = await Promise.all(callToolTasks);
// 每个工具的结果,创建一个 tool message 存入对话上下文中
const toolResultMessages = toolResults.map((result, index) => {
console.table([{ node: this.name, type: 'tool', json: JSON.stringify(result) }]);
return new ToolMessage(result, tools[index].id);
});
this.messages.push(...toolResultMessages);
// 触发新一轮的对话
return await this.invoke();
}
return message;
}
}
有了 Block 基础类之后,接下来就可以开始设计提示词了。提示词的设计主要围绕以下三点展开:
const prompt = `
你是一个专业的搜索研究助理,你需要搜集到准确、实时的信息,然后通过总结和分析来解决用户的问题。
以下是可用的工具和使用场景:
1.Thought: 用于观察现有的上下文内容,思考是否具备回答问题的条件,如不满足则思考接下来还要搜集什么信息、分析什么信息
2.TavilySearch: 用于搜索互联网的相关内容
3.GetCurrentDate: 获取当前的时间,以保证搜集、分析、回答的内容是与用户期望的时间相差不远的
注意:
1. 你必须在调用 TavilySearch、GetCurrentDate 工具的前后调用 Thought 工具,用于观察现有上下文的内容,思考后续的步骤
2. 所有的工具不能并行调用,必须按顺序,逐一的调用
3. 你需要一步一步的思考
`;
声明一个 ReActAgent 类,在初始化的时候创建 Block 实例并设定系统提示词
export class ReActAgent {
private agent: Block;
constructor() {
this.agent = new Block({
name: 'agent',
instruction: prompt,
});
}
}
想让 Agent 解决特定领域的问题,就得给它准备好解决问题需要的工具。下面是我们必须提供的几个工具:
简单来说,就是给 Agent 配备好“思考”、“查资料”和“看时间”的能力,让它能更高效地完成任务。
强制 LLM 把思考的过程,通过工具调用的形式输出到对话的上下文中
export const thoughtTool: Tool = {
type: 'function',
function: {
name: 'Thought',
description: '用于输出用于思考解决用户的问题,需要做什么以及这么做的原因',
parameters: {
type: 'object',
properties: {
thought: {
type: 'string',
description: '思考的内容',
},
},
required: ['thought'],
},
},
func: async (args: { [key: string]: any }) => {
return `Thought: ${args.thought}`;
},
};
可以先去 www.tavily.com/ 申请一个 API KEY,会有一定的免费调用额度。
申请完 API KEY 以后,在项目中配置这个 KEY,并下载 @tavily/core 这包就可以使用了。
import { tavily } from '@tavily/core';
const tvly = tavily({ apiKey: process.env.TAVILY_API_KEY! });
export const tavilySearchTool: Tool = {
type: 'function',
function: {
name: 'TavilySearch',
description: '用于搜索互联网的相关内容',
parameters: {
type: 'object',
properties: {
query: {
type: 'string',
description: '搜索的查询内容',
},
},
required: ['query'],
},
},
func: async (args: { [key: string]: any }) => {
try {
const res = await tvly.search(args.query);
const data = res.results.map(({ title, url, content }) => ({
title,
url,
content,
}));
return JSON.stringify(data);
} catch (error) {
return 'Error: Tavily 搜索失败';
}
},
};
获取当前的时间。核心是为了确保 LLM 回答问题的时效性,让 LLM 知道当前的时间。
export const getCurrentDateTool: Tool = {
type: 'function',
function: {
name: 'GetCurrentDate',
description: '获取当前日期',
},
func: async () => {
return new Date().toLocaleDateString();
},
};
将相关的工具配置好。完成代码看这里:github.com/zixingtangm…
import { getCurrentDateTool } from '../tools/get-current-date';
import { tavilySearchTool } from '../tools/tavily-search';
import { thoughtTool } from '../tools/thought';
export class ReActAgent {
private agent: Block;
constructor() {
this.agent = new Block({
name: 'agent',
instruction: prompt,
tools: new Tools([thoughtTool, tavilySearchTool, getCurrentDateTool]),
});
}
}
这里我们来测试一下,询问“今天关于 AI 的热点新闻有哪些?”
你可以看到,现在的 LLM 已经学会了一种“先想后做”的方式来一步步解决我们的问题。它会先用 Thought 工具把自己的思考过程写出来,然后调用 GetCurrentDate 来获取当前时间,接着再用 TavilySearch 去查找我们需要的信息……
其实这就是 ReAct 的运行流程,非常的简单。当然,你还可以尝试问更多有意思的问题 😏
现在你已经能够基于 ReAct 模式开发一个“深度搜索”的智能体应用了。但是不知道你是否发现,我们的设计存在一定的问题。你是否有想过,如果 LLM 一直认为搜索的信息还不够,然后不停的迭代搜索会出现哪些问题呢?
先思考,我们下一篇会详细讲解这个问题。
最后我们再来总结一下本篇的内容。
下一遍会继续分享 Agent 的设计模式——如何用 Plan And Execute 模式实现深度搜索。如果你觉得内容对你有帮助,请关注我,我会持续更新~
原创不易,转载请私信我。
我们结合上一篇文章React 执行阶段与渲染机制详解(基于 React 18+ 官方文档)React 执行阶段与渲染机制详解(基于 Rea - 掘金梳理的 React 执行阶段(Render Phase, Commit Phase, Passive Effect Phase)和状态管理机制,来深入剖析 useState 产生的 setState 的完整执行流程。
理解 setState 的行为是掌握 React 状态管理的核心。它远非简单的“设置一个值”,而是一个触发复杂协调和渲染流程的起点。
useState 与 setState 的核心概念首先,明确几个关键点:
useState 是 Hook:在函数组件首次渲染时调用,返回一个状态变量和一个 setState 函数。setState 是调度器 (Scheduler):调用 setState 不会立即更新状态,也不会立即触发重新渲染。它只是向 React 的调度系统“请求”一次状态更新。setState 调用合并成一次更新,尤其是在事件处理器中。state 快照。setState 会安排下一次渲染使用新的状态。setState 的详细执行流程当您在组件中调用 setState(newValue) 时,以下流程被触发:
setScore(score + 1) 或 setScore(prev => prev + 1)。state 变量的值在当前函数作用域内依然保持旧值。setState 传递的是函数(如 setScore(prev => prev + 1)),React 会按顺序调用这些函数,将上一个函数的返回值作为下一个函数的参数,最终得到一个新值。setScore(5)),则直接使用该值(如果多次调用,后面的会覆盖前面的,除非是函数形式)。useState Hook 会返回这个新的状态值。state 和 props 生成新的 JSX(Virtual DOM)。useLayoutEffect 的清理函数(来自上一次渲染),然后执行本次渲染的 useLayoutEffect 创建函数。这些是同步执行的,发生在浏览器绘制之前,可以用来读取或同步修改刚刚更新的 DOM。useEffect 的清理函数(来自上一次渲染)。useEffect 创建函数。function Counter() {
const [count, setCount] = useState(0);
const handleClick = () => {
setCount(count + 1); // 请求更新 1
setCount(count + 1); // 请求更新 2 (基于旧的 count)
// 最终 count 只会 +1,因为两次都基于同一个旧值
// React 可能会将这两次更新合并,只触发一次重新渲染
};
const handleClickCorrect = () => {
setCount(prev => prev + 1); // 请求更新 1 (基于上一次的状态)
setCount(prev => prev + 1); // 请求更新 2 (基于更新 1 后的状态)
// 最终 count 会 +2,因为每次更新都基于最新的状态
// 即使合并,函数也会按顺序执行
};
return (
<div>
<p>Count: {count}</p>
<button onClick={handleClick}>Bad Update</button>
<button onClick={handleClickCorrect}>Good Update</button>
</div>
);
}
setState(prev => newValue))。这能确保你总是基于最新的状态进行计算,避免因异步和批量更新导致的竞态条件。在组件函数执行期间(Render Phase),你拿到的 state 是一个固定的快照。任何在 Render Phase 中对 state 的“修改”尝试都是徒劳的,因为下一次渲染会带来新的快照。
function MyComponent() {
const [value, setValue] = useState(0);
// ❌ 错误:在渲染过程中直接修改 state 是无意义的,并且违反了纯函数原则
// setValue(value + 1); // 这会导致无限循环!
// ✅ 正确:在事件处理器或 Effect 中更新 state
const handleClick = () => {
setValue(value + 1);
};
return <button onClick={handleClick}>Increment</button>;
}
正如前面文章所述,React 通过组件在树中的位置来决定是否保留状态。setState 更新的是当前组件实例的状态。
function App() {
const [show, setShow] = useState(true);
return (
<div>
<Counter /> {/* 这个 Counter 的状态始终保留 */}
{show && <Counter />} {/* 这个 Counter 在 show 为 false 时会被卸载,状态丢失;show 为 true 时重新挂载,状态重置 */}
<button onClick={() => setShow(!show)}>
Toggle Second Counter
</button>
</div>
);
}
function Counter() {
const [score, setScore] = useState(0); // 每次挂载都会初始化为 0
return (
<div>
<h1>{score}</h1>
<button onClick={() => setScore(score + 1)}>Add one</button>
</div>
);
}
调用第二个 Counter 的 setScore 只会影响它自己的状态。当它被卸载时,其状态会被销毁。重新挂载时,useState(0) 会再次执行,状态重置为初始值。
setState 生命周期图谱[用户点击按钮]
↓
[调用 setState(newValue/UpdaterFn)] → (更新入队,标记 Fiber)
↓
[React Scheduler 触发 Render Phase]
├──> [计算新状态] (处理更新队列)
├──> [重新执行组件函数] (拿到新 state)
├──> [生成新 Virtual DOM]
└──> [Reconciliation (Diff)]
↓
[Commit Phase]
├──> [Mutation: 更新真实 DOM]
├──> [Layout: 执行 useLayoutEffect]
└──> [浏览器绘制]
↓
[Passive Effect Phase]
└──> [执行 useEffect]
↓
[等待下一次 setState 或事件...]
理解这个流程,能帮助你:
setState 是 React 响应式更新的引擎,掌握其背后的机制,是成为 React 高手的关键一步。
React 的工作流程基于 Fiber 架构,将任务拆分为可中断的单元,核心分为 Render Phase(渲染阶段) 和 Commit Phase(提交阶段),并辅以 副作用阶段 和 卸载阶段。以下是详细解析:
useState/useReducer
forceUpdate)props、state、全局变量)。function Counter({ time }) {
// 纯函数:相同输入返回相同 JSX
return (
<>
<h1>{time}</h1>
<input /> {/* 用户输入不会因父组件重渲染而丢失 */}
</>
);
}
将 Render Phase 计算出的变更同步应用到真实 DOM,确保用户界面即时更新。
getSnapshotBeforeUpdate(类组件)useLayoutEffect 的清理函数
useLayoutEffect 的创建函数
componentDidMount/componentDidUpdate
input 值等用户交互状态不丢失。在浏览器完成布局和绘制后,异步执行副作用(如网络请求、订阅)。
useEffect 的创建函数和清理函数componentDidMount/componentDidUpdate/componentWillUnmount 中的异步操作useLayoutEffect 的区别| Hook | 执行时机 | 是否阻塞渲染 | 适用场景 |
|---|---|---|---|
useEffect |
Passive Phase | ❌ 否 | 数据获取、日志、非关键副作用 |
useLayoutEffect |
Commit Phase(Layout 阶段) | ✅ 是 | 同步 DOM 操作(如测量尺寸) |
组件从 DOM 中移除(如条件渲染切换、列表项删除)。
useEffect/useLayoutEffect 的副作用componentWillUnmount
state。key 标识列表项,避免位置变化导致的状态重置。function App() {
const [isFancy, setIsFancy] = useState(false);
return (
<div>
{isFancy ? <Counter isFancy={true} /> : <Counter isFancy={false} />}
</div>
);
}
上述示例中,
<Counter />的位置不变,因此score状态会保留。
getDerivedStateFromError:同步执行,用于渲染降级 UI。componentDidCatch:提交阶段执行,用于记录错误日志。setTimeout)、服务端渲染(SSR)中的错误。React.memo、useMemo、useCallback 等工具。React.memo 包裹子组件。useMemo/useCallback 缓存。用户交互 / 状态更新
↓
[Render Phase](协调)
↓
[Commit Phase]
├── Before Mutation → useInsertionEffect / getSnapshotBeforeUpdate
├── Mutation → DOM 更新
└── Layout → useLayoutEffect / componentDidMount/Update
↓
[Passive Effect Phase] → useEffect
↓
[Unmount Phase] → 清理副作用
掌握这一流程,能帮助你编写更符合 React 设计哲学的代码,避免常见陷阱(如非纯函数、滥用 useLayoutEffect),并充分利用 React 的并发能力提升应用性能。
在前面的章节中,我们讲到了快速构建一个Electron的应用,但实际使用起来,对开发者来说,可以说是隔靴搔痒
下面我来将一个新型的构建工具 Electron-Vite
废话不多说,直接开始构建Electron应用
1.1 我们随便找一个文件夹,开始创建我们的项目
1.2 然后打开终端,输入指令
npm create @quick-start/electron@latest
输入 y ,继续执行
这里是输入我们的项目名称,这里我就输入了 “study-electron"
这里是选择我们项目的响应式框架,我这里选择了vue框架
这里是选择是否加入TypeScript支持,我选择了是
后面的一些选项,直接选择是即可
1.3 最终会生成这样一个文件夹
进入文件夹,我们会发现文件结构是这个样子
我们用VS Code打开这个项目
2.1 安装依赖
我们打开VS Code的终端,然后在终端里面输入
npm i
等待npm的安装,最后安装成功的界面如下
2.2 运行
我们打开项目里面package.json文件
可以看到electron-vite已经为我们配置了相当多的命令
然后我们在终端里面输入
npm run dev
我们的电脑桌面就会弹出来这样一个窗口,如下图所示
这个就是我们的Electron应用
相对于原生的Electron创建应用,我们使用的Electron-Vite构建工具要更加的方便,快捷
下面我们来看一下我们的项目文件结构,并一一解释
我们先认识一下主进程和渲染进程是什么
在 Electron 中,主进程和渲染进程是两大核心概念,分工明确:
main.js),负责管理整个应用的生命周期(启动、关闭等)、创建和控制窗口、处理系统级事件(如菜单、对话框),以及与操作系统交互。打个比方:
在主进程中,我们可以随意的操作文件系统,比如说随意删除D盘的某个文件,获取系统信息,监听端口号等等
但是在渲染进程中,我们无法做到上面的事情,渲染进程就和网页端开发一模一样
如果我们需要在渲染进程里面去操作文件系统,就需要进行主进程渲染进程通信
在项目里面
main文件夹就相当于我们的主进程
renderer文件夹就相当于我们的渲染进程
我们先让我们的项目变得干净一些,找到我们的App.vue
删除多余内容,修改成如下内容
找到渲染进程下面的main.ts
删除多余代码,变成下面的样子
最后我们的项目页面,就会是这个样子,一片干净整洁
第一步:修改我们主进程下面的index.ts文件
主要是将局部变量mainWindow提取出来,变成全局变量
import { app, shell, BrowserWindow, ipcMain } from 'electron'
import { join } from 'path'
import { electronApp, optimizer, is } from '@electron-toolkit/utils'
import icon from '../../resources/icon.png?asset'
export let mainWindow: BrowserWindow
function createWindow(): void {
// Create the browser window.
mainWindow = new BrowserWindow({
width: 900,
height: 670,
show: false,
autoHideMenuBar: true,
...(process.platform === 'linux' ? { icon } : {}),
webPreferences: {
preload: join(__dirname, '../preload/index.js'),
sandbox: false
}
})
mainWindow.on('ready-to-show', () => {
mainWindow.show()
})
mainWindow.webContents.setWindowOpenHandler((details) => {
shell.openExternal(details.url)
return { action: 'deny' }
})
// HMR for renderer base on electron-vite cli.
// Load the remote URL for development or the local html file for production.
if (is.dev && process.env['ELECTRON_RENDERER_URL']) {
mainWindow.loadURL(process.env['ELECTRON_RENDERER_URL'])
} else {
mainWindow.loadFile(join(__dirname, '../renderer/index.html'))
}
}
// This method will be called when Electron has finished
// initialization and is ready to create browser windows.
// Some APIs can only be used after this event occurs.
app.whenReady().then(() => {
// Set app user model id for windows
electronApp.setAppUserModelId('com.electron')
// Default open or close DevTools by F12 in development
// and ignore CommandOrControl + R in production.
// see https://github.com/alex8088/electron-toolkit/tree/master/packages/utils
app.on('browser-window-created', (_, window) => {
optimizer.watchWindowShortcuts(window)
})
// IPC test
ipcMain.on('ping', () => console.log('pong'))
createWindow()
app.on('activate', function () {
// On macOS it's common to re-create a window in the app when the
// dock icon is clicked and there are no other windows open.
if (BrowserWindow.getAllWindows().length === 0) createWindow()
})
})
// Quit when all windows are closed, except on macOS. There, it's common
// for applications and their menu bar to stay active until the user quits
// explicitly with Cmd + Q.
app.on('window-all-closed', () => {
if (process.platform !== 'darwin') {
app.quit()
}
})
// In this file you can include the rest of your app's specific main process
// code. You can also put them in separate files and require them here.
第二步:然后在我们的主进程文件夹下面创建一个文件 toRendererMsg.ts
文件内容如下
import { mainWindow } from '.'
export const toMsg = (): void => {
setInterval(() => {
//获取当前的标准时间
const date = new Date()
mainWindow.webContents.send('toMsg', date.toLocaleTimeString())
}, 1000)
}
这个代码的意思是,每隔一秒钟,我就要向渲染进程发一次消息
第三步:然后我们将这个方法放在index.ts里面执行
第四步:回到我们的App.vue里面,编写下面的程序
<template>
<span>主进程发过来的消息</span>
<span>{{ msg }}</span>
</template>
<script setup lang="ts">
import { onMounted, ref } from 'vue'
const msg = ref('')
onMounted(() => {
window.electron.ipcRenderer.on('toMsg', (e, data) => {
msg.value = data
})
})
</script>
在上面的程序里面,我们定义了一个msg的变量,用来接收主进程发过来的消息内容
然后我们在钩子函数里面,定义了监听方法
在主进程里面,我们是通过 toMsg 窗口来发消息的
所以在渲染进程里面,我们就需要通过 监听 toMsg 窗口来获取到消息
接下来我们来运行项目
在终端里面执行
npm run dev
效果如下,可以看到时间在变化
第一步:还是回到我们的App.vue文件里面,将程序替换成下面的内容
<template>
<div @click="handleClick">向主进程发消息</div>
</template>
<script setup lang="ts">
const handleClick = (): void => {
window.electron.ipcRenderer.send('toMain', 'hello world')
}
</script>
我们定义了一个div,然后定义了一个点击事件
通过这个点击事件,我们可以直接向主进程发消息
第二步:然后我们回到主进程,在主进程文件夹下面创建一个新的文件 monitorEvent.ts
文件内容如下
import { ipcMain } from 'electron'
export const monitorEvent = (): void => {
ipcMain.on('toMain', (e, data) => {
console.log(data)
})
}
然后将这个方法放入到index.ts里面
第三步:运行项目
我们点击这个文字
在我们的vs code的终端里面就会出现我们预期的结果
在4.3 中,我们渲染进程的消息发给了主进程,但是这消息是单程消息,发出去就没有后续了,如果我们想发出消息,并获得处理的结果,就需要双向通信了
第一步:还是修改我们的App.vue
<template>
<div @click="handleClick">获取D盘文件目录</div>
<template v-for="(item, index) in fileList" :key="index">
<p>{{ item }}</p>
</template>
</template>
<script setup lang="ts">
import { ref } from 'vue'
const fileList = ref<string[]>([])
const handleClick = async (): Promise<void> => {
const res = await window.electron.ipcRenderer.invoke('getFileList', 'D')
fileList.value = res
}
</script>
第二步:完善一下我们的monitorEvent.ts
改成下面内容
import { ipcMain } from 'electron'
import fs from 'fs/promises'
export const monitorEvent = (): void => {
ipcMain.on('toMain', (e, data) => {
console.log(data)
})
ipcMain.handle('getFileList', async (e, data) => {
if (data === 'D') {
//获取D盘文件列表
const rootPath = 'D:/' // D盘根目录路径
try {
// 读取目录,withFileTypes: true 可以获取文件类型信息
const entries = await fs.readdir(rootPath, { withFileTypes: true })
// 分离文件和目录
const directories = [] as string[]
const files = [] as string[]
for (const entry of entries) {
if (entry.isDirectory()) {
directories.push(entry.name)
} else if (entry.isFile()) {
files.push(entry.name)
}
}
console.log('D盘根目录下的目录:')
console.log(directories)
console.log('\nD盘根目录下的文件:')
console.log(files)
return [...directories, ...files]
} catch (err) {
console.error('读取目录失败:', err)
throw err // 可以根据需要处理错误
}
}
})
}
第三步:点击触发事件
当我们点击这个文字时
渲染进程就会向主进程发消息,然后主进程整理D盘下面所有文件及目录的名称,返回给渲染进程
在 4.4 里面,渲染进程向主进程通信时,需要 async/await 处理,那假如说我现在不想要异步通信,想要同步通信,可以做到吗?
这是当然的,不过弊端就在于主进程在处理数据时,会阻碍渲染进程
第一步:这时我们就需要用到预加载(preload)里面的文件了
找到下面的文件
然后修改成下面的内容
import { contextBridge, ipcRenderer } from 'electron'
import { electronAPI } from '@electron-toolkit/preload'
// Custom APIs for renderer
export const api = {
getFileList: (path: string): string[] => {
return ipcRenderer.sendSync('getFileList', path)
}
}
// Use `contextBridge` APIs to expose Electron APIs to
// renderer only if context isolation is enabled, otherwise
// just add to the DOM global.
if (process.contextIsolated) {
try {
contextBridge.exposeInMainWorld('electron', electronAPI)
contextBridge.exposeInMainWorld('api', api)
} catch (error) {
console.error(error)
}
} else {
// @ts-ignore (define in dts)
window.electron = electronAPI
// @ts-ignore (define in dts)
window.api = api
}
第二步:然后再找到与index.ts相邻的index.d.ts,修改内容如下
第三步:我们回到monitorEvent.ts文件里面
将原有的handle改为on
第四步:回到App.vue里面,修改内容如下
<template>
<div @click="handleClick">获取D盘文件目录</div>
<template v-for="(item, index) in fileList" :key="index">
<p>{{ item }}</p>
</template>
</template>
<script setup lang="ts">
import { ref } from 'vue'
const fileList = ref<string[]>([])
const handleClick = (): void => {
const res = window.api.getFileList('D')
fileList.value = res
}
</script>
我们可以看到,handleClick方法原先的async/await 不见了,这表示我们可以进行同步通信
效果就不再展示,大家自行查验
如果大家自己做了一遍4.5的内容,就已经知道主进程向渲染进程返回数据时,怎么暴露数据类型了
如下图所示
我们在预加载ts里面,写了一个方法 getFileList,然后这个方法我们也暴露了返回值的类型,那之后我们在前端接收的时候,就会被告知返回类型是什么
如下图所示,我们可以看到我们用来接收数据的res变量,数据类型是一个string[]
如果我们不通过预加载TS,直接主进程和渲染进程通信,那么我们是无法获取返回值的类型,只能得到一个any类型的返回值
通过预加载TS,可以进行同步通信,也可以获取返回值的类型
本章重点讲解electron-vite中,主进程和渲染进程之间的通信,后续我会给大家带来更多实用的小技巧
我先打开并浏览 src/views/wlhy/baidumap/bf9-16-2.vue,梳理其与 Map.vue 的差异点和事件绑定、销毁、输入处理等实现,以便做对照复盘。
[1 tool called]
我先通读了 src/views/wlhy/baidumap/bf9-16-2.vue,对照今天在 Map.vue 的修复点,做一次聚焦性的复盘与改进建议。
AMap 的抽屉式地图选点;带搜索框、搜索按钮、结果面板 panel、地图标记与定位等能力。Map.vue 不同的实现策略。:id="mapContainerId" 与 :id="tipInputId" 的动态容器与输入框 ID,理论上可以避免 DOM 复用导致的实例绑定陈旧问题。@afterVisibleChange 驱动初始化,配合 MutationObserver、反复 resize()、甚至“移除并重建地图容器”的兜底路径,增强了在复杂布局/动画场景下的渲染稳定性。panel”交互,用户心智简单,便于定位问题。initAMapPlugins() 内完成 AutoComplete、PlaceSearch、ToolBar 初始化与事件绑定。AutoComplete 未使用动态 ID,实际绑定仍然是硬编码 'tipinput'
<input ... :id="tipInputId" ...>
document.getElementById('tipinput')、input: 'tipinput'
tipInputId 变化时,AutoComplete 可能绑定到不存在或旧的节点,导致选择事件丢失。document.getElementById(this.tipInputId) 和 input: this.tipInputId。方法重复定义,存在覆盖与维护风险
getCurrentPosition 定义了两次(L193 与 L1090 附近),后者会覆盖前者。handleKeywordInput 定义了两次(L242 与 L765 附近),后者会覆盖前者。资源释放方式与兼容性
this.autoComplete.destroy()、this.placeSearch.destroy()(L408、L409、L889、L890、L1295、L1303),在某些版本/构造器上可能没有 destroy(),导致报错(这正是 Map.vue 中出现过的警告来源之一)。typeof ...destroy === 'function' 守卫,或使用事件解绑 + 置空的方式收尾。事件模型混用
PlaceSearch 使用了 .on('complete')/.on('error')(L705、L706),也使用了 search(kw, callback) 的回调风格(L249)。API 版本不同事件模型不同,容易引发“双通道回调”或空回调。过度复杂的渲染兜底路径
MutationObserver、多次 resize()、定时器兜底、甚至“删除并重建地图容器”(L443-L451、L589-L663、L878-L926)。虽然鲁棒,但复杂度较高,后续维护成本与副作用(例如插件状态丢失)上升。细节一致性
visible 监听中会条件初始化地图或强制重绘(L169-L176),同时 afterDrawerVisibleChange 也负责初始化(L455-L545),实际存在两处入口的竞态可能。afterVisibleChange 统一入口。Map.vue 的修复重心:
AutoComplete.on('select', ...) + PlaceSearch Fallback;destroy();keyword(而你明确说明此文件无需同步这一点)。bf9-16-2.vue 更偏“工程兜底型”:
initAMapPlugins() 中
document.getElementById('tipinput') → document.getElementById(this.tipInputId)
input: 'tipinput' → input: this.tipInputId
getCurrentPosition 与 handleKeywordInput,只保留一份。destroy():
destroy() 改为先判断类型,或仅做 事件解绑 + 置空。PlaceSearch 只保留一种回调方式(建议保留 .on('complete')/.on('error') 或 search(kw, cb) 二选一)。AutoComplete 与 PlaceSearch,按钮搜索可见 panel。afterDrawerVisibleChange + 观察器重试能恢复地图;若不改动 ID 硬编码,select 有概率因节点不匹配而不触发。destroy() 的情况下,可能产生控制台警告。如果你愿意,我可以按“最小修正”帮你把上述四点直接在 bf9-16-2.vue 中落地,保持交互不变,仅提升稳定性与一致性。
AutoComplete 的 select 事件;关闭后再次打开,输入关键词搜索,select 事件不再触发。keyword。id="tipinput" 在抽屉反复打开/关闭后,旧 DOM 被销毁但 AutoComplete 仍引用旧节点。on/choose/complete/addListener 等并行方案,进一步引发重复绑定、误判、竞态。data: 新增 tipInputId: 'tipinput-' + Date.now()。template: 关键词输入框改为 :id="tipInputId"。show(): 每次打开生成新 ID:this.tipInputId = 'tipinput-' + Date.now();
initMap():
mapGD。AMap.plugin 内部初始化 AutoComplete 与 PlaceSearch。AutoComplete 仅保留核心:this.autoComplete.on('select', this.onAutocompleteSelect)。complete 后标记 mapInitialized=true 并执行 checkAndLocate()。close():
AutoComplete 的 select 事件(off('select', ...)),将实例置空。currentMarker,销毁 mapGD,重置状态变量。keyword/location/inputLng/inputLat)。onAutocompleteSelect(e): 优先直接用 e.poi.location 定位、打点、更新 addrInfo,无 location 时再走 placeSearch。handlePOISelection(poi): 封装“根据 POI 更新地图与地址信息”,兼容多种 location 结构。handleManualSelection(selectedText) 以便在极端情况下根据文本触发 placeSearch。show() 首行清空关键词:this.keyword = '',满足“每次进入清空”的需求。visible 变化时触发 map.resize(),避免首次渲染尺寸为 0 导致白屏。select 正常触发。tipInputId 更新,AutoComplete 绑定到全新 DOM,select 可持续触发。keyword,会在后续逻辑中覆盖为传入值(兼容业务场景)。destroy():所有销毁调用前均做了类型检查或改为安全置空。close() 中集中清理,且默认不再附加额外 DOM 监听,避免重复与干扰。complete 事件做选择:统一以 select 为主,placeSearch 为 fallback。autoComplete.setCity() 与 placeSearch.setCity()。placeSearch.search(keyword),避免全局 DOM 监听。show() 中生效,不影响传参覆盖。Map.vue 处于可复现、可维护、行为稳定的状态。我先复盘,再给出可执行的修复要点与自检清单。
id/DOM 还没渲染就初始化),引发搜索正常但地图未刷新中心或未重绘。visible 改变时调用 resize,时机过早,抽屉动画未结束,仍为 0 尺寸。@afterVisibleChange 和 MutationObserver 监听容器尺寸,尺寸有效时再 initMap(),否则等待。div#mapContainerId 并挂回父节点,再初始化地图。mapGD.resize(),并在插件加载后再次 resize()。AutoComplete 与 PlaceSearch 每次初始化都销毁旧实例,绑定到当前 mapGD,并保证输入框、面板 DOM 存在后再初始化。.map-gaode-container 配置固定高度(如 500px),抽屉内布局不要依赖内容自适应高度。afterVisibleChange(true) → 容器尺寸检测通过 → new AMap.Map(...) → 插件加载 → resize() → 定位/打点。mapGD 和插件、移除容器或清空容器;打开时按上面流程重建。#mapContainerId 的 offsetWidth/offsetHeight 是否 > 0?container.querySelector('canvas') 是否存在,canvas 宽高是否为 0?mapGD.getSize() 是否非 0?mapGD.resize() 是否被调用过(并在抽屉动画后调用)?mapGD,输入框/面板 DOM 是否已渲染后再初始化?destroy(),二次打开是否复用旧 DOM/实例?如果你更倾向“不用动态样式”,我可以把目前 watch 里设置容器内联样式的逻辑改成纯 CSS 类方式,并保留上述延后初始化与 resize 策略。你要我直接改成纯 CSS 版本吗?
大家好,我是不如摸鱼去,wot-ui的主要维护者,欢迎来到我的 uni-app 分享专栏。
在移动端跨平台开发中,数据可视化是一个常见需求。而 ECharts 作为百度开源的强大图表库,在 Web 端有着广泛的应用,我们在技术栈选择的时候往往倾向于选择这种应用广泛,解决方案完善的库。
但在 uni-app 中直接使用 ECharts 会遇到各种兼容性问题,特别是在小程序端。幸运的是,有很库可以帮助我们在 uni-app 中使用 Echarts,例如 uni-echarts、lime-echart 等插件,为我们提供了相应的解决方案。
今天我们将会在 wot-starter 中,探索 uni-app 接入 Echarts 的方案,并针对小程序,对其超级庞大的体积进行优化。
uni-echarts 是一个适用于 uni-app 的 Apache ECharts 组件(仅支持Vue 3),具有以下优势:
基于以上,选择使用 uni-echarts 作为我们的图表库,当然也可以选择 lime-echart 。
首先安装必要的依赖包:
pnpm add echarts uni-echarts
# 或者
npm install echarts uni-echarts
在我们的项目中,package.json 已经包含了这些依赖:
{
"dependencies": {
"echarts": "^6.0.0",
"uni-echarts": "^1.1.2"
}
}
在 vite.config.ts 中添加必要的配置:
import { defineConfig } from 'vite'
import Uni from '@dcloudio/vite-plugin-uni'
import UniHelperComponents from '@uni-helper/vite-plugin-uni-components'
import { UniEchartsResolver } from 'uni-echarts/resolver'
export default defineConfig({
optimizeDeps: {
exclude: process.env.NODE_ENV === 'development' ? ['wot-design-uni', 'uni-echarts'] : [],
},
plugins: [
// 组件自动导入
UniHelperComponents({
resolvers: [UniEchartsResolver()],
dts: 'src/components.d.ts',
}),
Uni(),
],
})
这样配置后,uni-echarts 组件就可以在项目中自动导入使用了,更多信息参见 Uni ECharts 快速开始。
让我们以项目中的 BarChart.vue 为例,看看如何创建一个基础的柱状图:
<script setup lang="ts">
import { BarChart } from 'echarts/charts'
import { DatasetComponent, GridComponent, LegendComponent, TooltipComponent } from 'echarts/components'
import * as echarts from 'echarts/core'
import { CanvasRenderer } from 'echarts/renderers'
import { provideEcharts } from 'uni-echarts/shared'
// 🚨 重要:由于 npm 插件编译机制问题,需要手动提供 echarts 实例
provideEcharts(echarts)
// 注册需要的组件
echarts.use([
GridComponent,
LegendComponent,
TooltipComponent,
DatasetComponent,
BarChart,
CanvasRenderer,
])
// 图表配置
const option = ref({
tooltip: {
trigger: 'axis',
axisPointer: {
type: 'shadow',
},
},
legend: {
data: ['销售额', '利润'],
top: 30,
},
grid: {
left: '3%',
right: '4%',
bottom: '3%',
containLabel: true,
},
xAxis: {
type: 'category',
data: ['1月', '2月', '3月', '4月', '5月', '6月'],
},
yAxis: {
type: 'value',
},
series: [
{
name: '销售额',
type: 'bar',
data: [120, 200, 150, 80, 70, 110],
itemStyle: {
color: '#5470c6',
},
},
{
name: '利润',
type: 'bar',
data: [20, 40, 30, 15, 12, 22],
itemStyle: {
color: '#91cc75',
},
},
],
})
</script>
<template>
<uni-echarts custom-class="h-300px" :option="option" />
</template>
<uni-echarts> 标签渲染图表更多图表类型见 Echarts 和 Uni ECharts,当然你也可以使用 AI 工具帮助你编写想要的图表配置,它非常善于处理这个事情。
引入 Echarts 后,体积暴增 800KB ,怎么办?
有办法,我们曾在 Vue3 uni-app 主包 2 MB 危机?1 个插件 10 分钟瘦身 一文中介绍过 @uni-ku/bundle-optimizer,它是解决微信小程序超包的利器,我们现在使用它的分包优化和分包异步化能力,来优化引入 Echarts 后暴增的小程序体积。
这是我们的项目结构,在 subEcharts 分包中实现 Echarts 相关组件,在 subAsyncEcharts 分包中演示分包异步化效果:
src/
├── pages/ # 主包页面
├── subEcharts/ # ECharts 组件分包
│ └── echarts/
│ └── components/
├── subAsyncEcharts/ # 异步 ECharts 演示分包
│ └── asyncEcharts/
└── subPages/ # 其他功能分包
pnpm add -D @uni-ku/bundle-optimizer
# 或者
npm install -D @uni-ku/bundle-optimizer
在我们的项目中,package.json 已经包含了这个依赖:
{
"devDependencies": {
"@uni-ku/bundle-optimizer": "1.3.15-beta.2"
}
}
在 vite.config.ts 中配置插件:
import { defineConfig } from 'vite'
import Uni from '@dcloudio/vite-plugin-uni'
import Optimization from '@uni-ku/bundle-optimizer'
export default defineConfig({
plugins: [
Uni(),
// 分包优化插件
Optimization({
logger: true, // 开启日志输出
}),
],
})
在 manifest.json 中开启分包优化:
{
"mp-weixin": {
"optimization": {
"subPackages": true
}
}
}
如果你使用了 @uni-helper/vite-plugin-uni-manifest 插件,那么需要在 manifest.config.ts 中开启分包优化:
export default defineManifestConfig({
'mp-weixin': {
optimization: {
subPackages: true,
},
},
})
配置完成后,重新构建,我们会发现主包少了 200+KB ,还剩 500KB 在主包中,可以期待 @uni-ku/bundle-optimizer 未来可以传送组件到分包中,到时会将把大部分构建产物都打包进入分包中。
这里配合 lime-echart 的话,应该可以将 echarts.min.js 完全放入分包,各位可以自行探索。
在我们的项目中,subAsyncEcharts 分包可以异步引用 subEcharts 分包中的组件:
<!-- src/subAsyncEcharts/asyncEcharts/index.vue -->
<script setup lang="ts">
// 跨分包异步导入组件
import BarChart from '@/subEcharts/echarts/components/BarChart.vue?async'
import DonutChart from '@/subEcharts/echarts/components/DonutChart.vue?async'
import FunnelChart from '@/subEcharts/echarts/components/FunnelChart.vue?async'
import GaugeChart from '@/subEcharts/echarts/components/GaugeChart.vue?async'
import LineChart from '@/subEcharts/echarts/components/LineChart.vue?async'
import LiquidFillChart from '@/subEcharts/echarts/components/LiquidFillChart.vue?async'
import MiniLineChart from '@/subEcharts/echarts/components/MiniLineChart.vue?async'
import PieChart from '@/subEcharts/echarts/components/PieChart.vue?async'
import RadarChart from '@/subEcharts/echarts/components/RadarChart.vue?async'
import ScatterChart from '@/subEcharts/echarts/components/ScatterChart.vue?async'
import StackedBarChart from '@/subEcharts/echarts/components/StackedBarChart.vue?async'
</script>
前后2个页面,一个在 subEcharts 分包中,一个在 subAsyncEcharts 分包中,其中 subAsyncEcharts 中的页面打包后几乎不存在体积的增大。
更多信息参见 @uni-ku/bundle-optimizer: github.com/uni-ku/bund… 。
在每个使用 ECharts 的组件中,都必须调用 provideEcharts(echarts):
import * as echarts from 'echarts/core'
import { provideEcharts } from 'uni-echarts/shared'
// 🚨 这一行是必须的
provideEcharts(echarts)
为了减小打包体积,建议按需导入需要的图表类型和组件:
// 只导入需要的图表类型
import { BarChart, LineChart, PieChart } from 'echarts/charts'
// 只导入需要的组件
import { GridComponent, TooltipComponent, LegendComponent } from 'echarts/components'
// 导入渲染器
import { CanvasRenderer } from 'echarts/renderers'
使用 custom-class 属性设置图表容器的尺寸:
<template>
<!-- 使用 UnoCSS/Tailwind 类名 -->
<uni-echarts custom-class="h-300px w-full" :option="option" />
<!-- 或者使用自定义 CSS 类 -->
<uni-echarts custom-class="chart-container" :option="option" />
</template>
<style>
.chart-container {
width: 100%;
height: 300px;
}
</style>
当需要动态更新图表数据时,直接修改 option 对象即可:
const option = ref({
// 初始配置
})
// 更新数据
function updateData() {
option.value.series[0].data = [/* 新数据 */]
}
可以通过 provideEchartsTheme 来设置自定义主题:
import { provideEcharts, provideEchartsTheme } from 'uni-echarts/shared'
import * as echarts from 'echarts/core'
provideEcharts(echarts)
// 设置自定义主题
provideEchartsTheme({
color: ['#5470c6', '#91cc75', '#fac858', '#ee6666', '#73c0de'],
backgroundColor: 'transparent',
// 更多主题配置...
})
我们在 wot-starter 中 使用 uni-echarts 结合 @uni-ku/bundle-optimizer 为 uni-app 开发者提供了一个完整的高性能 ECharts 解决方案。通过合理的配置和规范的使用方式,我们可以在各个平台上实现丰富的数据可视化效果,同时保证应用的性能和用户体验。
关键要点回顾:
echarts、uni-echarts 和 @uni-ku/bundle-optimizer 依赖provideEcharts(echarts)
<uni-echarts> 组件渲染图表?async 后缀实现组件异步加载当年偷偷玩小霸王,现在偷偷用 Trae Solo 复刻坦克大战
告别 HBuilderX,拥抱现代化!这个模板让 uni-app 开发体验起飞
Vue3 uni-app 主包 2 MB 危机?1 个插件 10 分钟瘦身
欢迎评论区沟通、讨论👇👇
message({
mode: 'mode',
text: 'text',
onClose: function () {},
duration: 3000,
});
message('text');
message('text', function () {});
message('text', 'mode');
message('text', 'mode', 3000);
message('text', 3000);
message('text', 3000, function () {});
export default {};
message 用法有很多。
// ts 的用法
function message(
param1: string | object,
param2?: number | Function | string
): void {
// Function implementation goes here
}
为什么会有ts函数重载?
因为如果没有重载,永远只是很宽泛的类型,any来any去。太多any要ts就没意思了。
function message(params1: string | object, param2?: any): void
有重载时,编辑器IDE就能提供更精确的提示:
message('text')
message('text', 'mode')
// 没有重载时,这些错误调用不会被检测到
message('text', 'invalid', 'wrong') // 不会报错
message(123, 'mode') // 不会报错
// 有重载时,TypeScript 会准确报错
message('text', 'invalid', 'wrong') // 错误:第三个参数类型不匹配
message(123, 'mode') // 错误:第一个参数必须是字符串或对象
完整代码:
function message(text: string): void;
function message(text: string, onClose: () => void): void;
function message(text: string, mode: string): void;
function message(text: string, mode: string, duration: number): void;
function message(text: string, duration: number): void;
function message(text: string, duration: number, onClose: () => void): void;
function message(options: {
mode: string;
text: string;
onClose?: () => void;
duration?: number
}): void;
function message(
param1: string | object,
param2?: number | Function | string,
param3?: number | Function
): void {
// Function implementation goes here
if (typeof param1 === 'object') {
// 对象形式调用: message({ mode: 'mode', text: 'text', onClose: function () {}, duration: 3000 })
const options = param1;
// 处理选项
} else {
const text = param1;
if (typeof param2 === 'function') {
// message('text', function () {})
const onClose = param2;
} else if (typeof param2 === 'string') {
// message('text', 'mode')
const mode = param2;
if (typeof param3 === 'number') {
// message('text', 'mode', 3000)
const duration = param3;
}
} else if (typeof param2 === 'number') {
// message('text', 3000) 或 message('text', 3000, function () {})
const duration = param2;
if (typeof param3 === 'function') {
// message('text', 3000, function () {})
const onClose = param3;
}
}
}
}
export default {};
非常经典的Android开发问题-mipmap图标目录和drawable图标目录的区别和适用场景实战举例-优雅草卓伊凡
mipmap 目录中。drawable 目录中。这是Google自Android Studio 1.0版本后官方推荐的最佳实践。
mipmap ****目录下的资源进行缩放。无论你的应用安装在哪一种屏幕密度的设备上,Launcher(桌面)都会获取到为该设备分辨率精确匹配的 mipmap 资源,从而确保应用图标始终清晰、无锯齿。ic_launcher 或 ic_launcher_round 等。这些图标会显示在手机桌面、应用列表、设置界面以及分享菜单中。mipmap 中,系统不会缩放它们,你在布局中引用时可能需要自己处理尺寸,反而增加麻烦。而且这违背了该目录的设计初衷。drawable 目录下的图片进行缩放,以适配不同屏幕。系统会选择最接近的密度版本,然后缩放至合适大小。在早期Android版本中,所有图片资源都放在 drawable 目录下。但这样做有一个问题:
当设备屏幕密度很高(比如xxhdpi)而你的应用只提供了低密度(比如mdpi)的应用图标时,系统会从 drawable 目录中获取这个低清图标,并放大它来显示在桌面上。放大必然导致图标模糊、失真,用户体验很差。
为了解决这个问题,Android引入了 mipmap 目录。mipmap 一词源自计算机图形学,指的是一组预先生成的、不同精度的纹理图片。系统可以精确地为设备选择最合适的那一个,而无需进行缩放。
因此,将应用图标单独放入 mipmap 目录,确保了桌面Launcher总能拿到最精确尺寸的图标,与设备DPI完美匹配。而应用内部的UI元素因为布局复杂,缩放是不可避免的,所以继续留在 drawable 目录中由系统处理。
一个标准的项目资源目录结构看起来是这样的:
src/main/res/
├── drawable/ // 默认drawable目录(通常放xml资源,如selector, shape)
├── drawable-hdpi/ // 为hdpi屏幕准备的png/jpg图片
├── drawable-xhdpi/ // 为xhdpi屏幕准备的png/jpg图片
├── drawable-xxhdpi/ // 为xxhdpi屏幕准备的png/jpg图片
├── mipmap-hdpi/ // 只放应用图标 ic_launcher.png
├── mipmap-xhdpi/ // 只放应用图标 ic_launcher.png
├── mipmap-xxhdpi/ // 只放应用图标 ic_launcher.png
├── mipmap-xxxhdpi/ // 只放应用图标 ic_launcher.png (建议提供,作为高分辨率设备的基准)
├── layout/
└── values/
| 特性 |
mipmap****目录
|
drawable****目录
|
||
|---|---|---|---|---|
| 主要用途 | 应用启动器图标(App Launcher Icon) | 应用内所有其他UI元素和图片 | ||
| 系统缩放 | 永不缩放,保证图标清晰 | 会根据设备dpi进行缩放 | ||
| 包含内容 | `ic_launcher(.webp | .png | .xml)` | 按钮图标、背景、位图、选择器、形状等 |
| 最佳实践 | 所有密度版本都应提供该图标 | 为不同密度提供相应的图片以优化性能和效果 |
记住这个黄金法则:
mipmap ****for the app icon, ****drawable ****for everything else.
(mipmap放应用图标,drawable放其他所有东西。)
实际项目举例
看到这两个图标了没,一个是默认页面的背景图,另一个是被选中按钮激活后的选项背景图
这两个资源都属于“应用内其他图片资源”,都应该放在 ****drawable ****目录中。
drawable 目录drawable 目录这个背景是应用内部UI交互的一部分。它可能是一个图片(.png, .jpg, .webp),也可能是一个用XML定义的选择器(Selector) 或形状(Shape) 。
btn_selected_bg.png):drawable-xhdpi/, drawable-xxhdpi/ 等。系统会根据设备屏幕密度自动选择最合适的一个,并在需要时进行缩放,以保证在不同设备上显示比例正确。btn_selected_bg.xml,里面可能是 <selector> 或 <shape>):drawable/ ****目录(不带密度后缀)。因为XML是矢量性的,系统可以根据描述在任何密度下完美地绘制出图形,无需为不同密度提供多个版本。放置路径示例:
res/drawable/btn_selected_bg.xml (XML选择器)res/drawable-xhdpi/btn_selected_bg.png (XHDPI密度图片)res/drawable-xxhdpi/btn_selected_bg.png (XXHDPI密度图片)这个背景同样是应用内部的装饰性图片,不属于应用图标。它通常是一张较大的图片(如 bg_home.jpg)。
drawable-dpi 目录中。例如,为高密度设备提供更高分辨率的背景图,可以避免在大屏手机上被拉伸而模糊。放置路径示例:
res/drawable-mdpi/bg_home.jpg (通常不需要,但遵循规范的话应该提供)res/drawable-hdpi/bg_home.jpgres/drawable-xhdpi/bg_home.jpgres/drawable-xxhdpi/bg_home.jpg (这是目前最主流的基准尺寸)mipmap?回顾一下 mipmap 的核心特性:系统永不缩放。
如果你把主页背景图 bg_home.jpg 放在 mipmap-xxhdpi/ 目录下,然后在一个 hdpi 的设备上运行:
mipmap-hdpi/ 找,但你没提供这个版本。drawable 那样自动缩放 mipmap-xxhdpi 里的图来适配。mipmap-xxhdpi/ 里的原图,这张图在 hdpi 设备上会显得非常大,可能超出屏幕,导致显示异常。把按钮背景放在 mipmap 里也会有类似的问题,因为系统不会帮你做任何缩放适配,你需要自己写代码去控制大小,这完全违背了Android资源适配的初衷。
| 资源类型 | 推荐目录 | 原因 |
|---|---|---|
| 应用图标 (ic_launcher) | mipmap-*dpi/ |
确保桌面启动器获取未缩放的清晰图标 |
| 按钮背景 (图片或XML) |
drawable/或 drawable-*dpi/
|
属于应用内UI,需要系统进行密度适配 |
| 页面背景图 | drawable-*dpi/ |
属于应用内装饰性图片,需要系统进行密度适配 |
| XML选择器/形状 |
drawable/(无密度后缀) |
XML可自适应不同密度,一份资源即可 |
简单记忆:只要不是那个会被手机桌面用到的图标,统统扔进 drawable 。
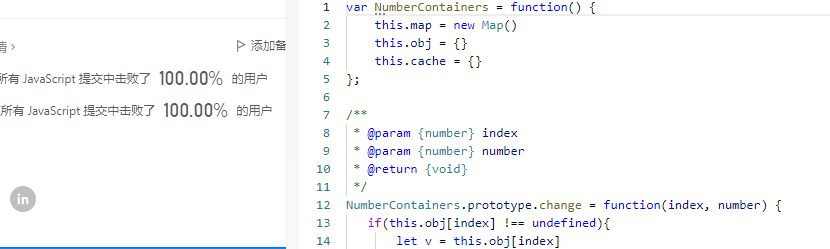
var NumberContainers = function() {
this.map = new Map()
this.obj = {}
this.cache = {}
};
NumberContainers.prototype.change = function(index, number) {
if(this.obj[index] !== undefined){
let v = this.obj[index]
let set = this.map.get(v)
if(set) set.delete(index)
delete this.cache[v]
}
this.obj[index] = number
this.map.set(number, (this.map.get(number) || new Set()).add(index))
delete this.cache[number]
};
NumberContainers.prototype.find = function(number) {
if(this.cache[number]) return this.cache[number]
let set = this.map.get(number),ret
if(!set || set.size === 0) ret = -1
else ret = Math.min(...set)
this.cache[number] = ret
return ret
};
为了实现 $\texttt{find}$,我们需要对每个 $\textit{number}$ 创建一个有序集合,维护这个 $\textit{number}$ 对应的所有下标。用有序集合可以快速地获取最小下标。
对于 $\texttt{change}$,如果 $\textit{index}$ 处有数字,我们需要先删除旧的数字,所以还需要知道每个 $\textit{index}$ 对应的 $\textit{number}$ 是多少,这可以用一个哈希表记录。
具体来说,创建一个哈希表 $\textit{indexToNumber}$,以及一个哈希表套有序集合 $\textit{numberToIndices}$。
对于 $\texttt{change}$:
对于 $\texttt{find}$,获取 $\textit{numberToIndices}[\textit{number}]$ 中的最小元素即可。
class NumberContainers:
def __init__(self):
self.index_to_number = {}
# from sortedcontainers import SortedSet
self.number_to_indices = defaultdict(SortedSet)
def change(self, index: int, number: int) -> None:
# 移除旧数据
old_number = self.index_to_number.get(index, None)
if old_number is not None:
self.number_to_indices[old_number].discard(index)
# 添加新数据
self.index_to_number[index] = number
self.number_to_indices[number].add(index)
def find(self, number: int) -> int:
indices = self.number_to_indices[number]
return indices[0] if indices else -1
class NumberContainers {
private final Map<Integer, Integer> indexToNumber = new HashMap<>();
private final Map<Integer, TreeSet<Integer>> numberToIndices = new HashMap<>();
public void change(int index, int number) {
// 移除旧数据
Integer oldNumber = indexToNumber.get(index);
if (oldNumber != null) {
numberToIndices.get(oldNumber).remove(index);
}
// 添加新数据
indexToNumber.put(index, number);
numberToIndices.computeIfAbsent(number, _ -> new TreeSet<>()).add(index);
}
public int find(int number) {
TreeSet<Integer> indices = numberToIndices.get(number);
return indices == null || indices.isEmpty() ? -1 : indices.first();
}
}
class NumberContainers {
unordered_map<int, int> index_to_number;
unordered_map<int, set<int>> number_to_indices;
public:
void change(int index, int number) {
// 移除旧数据
auto it = index_to_number.find(index);
if (it != index_to_number.end()) {
number_to_indices[it->second].erase(index);
}
// 添加新数据
index_to_number[index] = number;
number_to_indices[number].insert(index);
}
int find(int number) {
auto it = number_to_indices.find(number);
return it == number_to_indices.end() || it->second.empty() ? -1 : *it->second.begin();
}
};
// import "github.com/emirpasic/gods/v2/trees/redblacktree"
type NumberContainers struct {
indexToNumber map[int]int
numberToIndices map[int]*redblacktree.Tree[int, struct{}]
}
func Constructor() NumberContainers {
return NumberContainers{map[int]int{}, map[int]*redblacktree.Tree[int, struct{}]{}}
}
func (n NumberContainers) Change(index, number int) {
// 移除旧数据
if oldNumber, ok := n.indexToNumber[index]; ok {
n.numberToIndices[oldNumber].Remove(index)
}
// 添加新数据
n.indexToNumber[index] = number
if n.numberToIndices[number] == nil {
n.numberToIndices[number] = redblacktree.New[int, struct{}]()
}
n.numberToIndices[number].Put(index, struct{}{})
}
func (n NumberContainers) Find(number int) int {
indices, ok := n.numberToIndices[number]
if !ok || indices.Empty() {
return -1
}
return indices.Left().Key
}
$\textit{numberToIndices}$ 改成哈希表套最小堆。
对于 $\texttt{change}$,不删除旧数据。
对于 $\texttt{find}$,查看堆顶是否等于 $\textit{number}$,若不相同,则意味着堆顶是之前没有删除的旧数据,弹出堆顶;否则堆顶就是答案。
class NumberContainers:
def __init__(self):
self.index_to_number = {}
self.number_to_indices = defaultdict(list)
def change(self, index: int, number: int) -> None:
# 添加新数据
self.index_to_number[index] = number
heappush(self.number_to_indices[number], index)
def find(self, number: int) -> int:
indices = self.number_to_indices[number]
while indices and self.index_to_number[indices[0]] != number:
heappop(indices) # 堆顶货不对板,说明是旧数据,删除
return indices[0] if indices else -1
class NumberContainers {
private final Map<Integer, Integer> indexToNumber = new HashMap<>();
private final Map<Integer, PriorityQueue<Integer>> numberToIndices = new HashMap<>();
public void change(int index, int number) {
// 添加新数据
indexToNumber.put(index, number);
numberToIndices.computeIfAbsent(number, _ -> new PriorityQueue<>()).offer(index);
}
public int find(int number) {
PriorityQueue<Integer> indices = numberToIndices.get(number);
if (indices == null) {
return -1;
}
while (!indices.isEmpty() && indexToNumber.get(indices.peek()) != number) {
indices.poll(); // 堆顶货不对板,说明是旧数据,删除
}
return indices.isEmpty() ? -1 : indices.peek();
}
}
class NumberContainers {
unordered_map<int, int> index_to_number;
unordered_map<int, priority_queue<int, vector<int>, greater<int>>> number_to_indices;
public:
void change(int index, int number) {
// 添加新数据
index_to_number[index] = number;
number_to_indices[number].push(index);
}
int find(int number) {
auto& indices = number_to_indices[number];
while (!indices.empty() && index_to_number[indices.top()] != number) {
indices.pop(); // 堆顶货不对板,说明是旧数据,删除
}
return indices.empty() ? -1 : indices.top();
}
};
type NumberContainers struct {
indexToNumber map[int]int
numberToIndices map[int]*hp
}
func Constructor() NumberContainers {
return NumberContainers{map[int]int{}, map[int]*hp{}}
}
func (n NumberContainers) Change(index, number int) {
// 添加新数据
n.indexToNumber[index] = number
if _, ok := n.numberToIndices[number]; !ok {
n.numberToIndices[number] = &hp{}
}
heap.Push(n.numberToIndices[number], index)
}
func (n NumberContainers) Find(number int) int {
indices, ok := n.numberToIndices[number]
if !ok {
return -1
}
for indices.Len() > 0 && n.indexToNumber[indices.IntSlice[0]] != number {
heap.Pop(indices) // 堆顶货不对板,说明是旧数据,删除
}
if indices.Len() == 0 {
return -1
}
return indices.IntSlice[0]
}
type hp struct{ sort.IntSlice }
func (h *hp) Push(v any) { h.IntSlice = append(h.IntSlice, v.(int)) }
func (h *hp) Pop() any { a := h.IntSlice; v := a[len(a)-1]; h.IntSlice = a[:len(a)-1]; return v }
见下面数据结构题单的「§5.6 懒删除堆」。
欢迎关注 B站@灵茶山艾府