一、前言
大家好,我是唐某人~ 我想是通过分享 AI 的相关经验,帮助更多的前端工程师或者更多的开发岗位能够通俗易懂的学会 AI 应用开发的相关技能。
在上一篇《前端仔如何在公司搭建 AI Review 系统》中,我分享了如何实现简易版 AI Code Review 的内容。该篇得到官方“一周精选”的认可和众多公众号的转发。
看这篇文章的同学,我默认是对 AI 应用相关的基础概念有一个基本的认知了,如果你还缺乏这块的知识。可以先看这篇《AI 应用开发入门:前端也可以学习 AI》。想学更多的 AI 应用开发、进阶相关的内容,可以关注我的专栏,这里会持续的更新。
1.1 内容结构
在接下的 2 ~ 3 篇的文章里,会给大家分享 Agent 相关的内容。由于内容较多,暂时决定分为 2~ 3 篇来发布。核心可能会讲三块内容:
- Agent 系统的定义、组成结构、运行机制(偏理论 + 轻实战)
- Agent 系统的设计模式、设计原则、与工具、MCP 的关系(偏偏理论 + 轻实战)
- 设计一个深度研究 Agent 系统,可以自主研究学术、股票、新闻等(篇实战,较为复杂的 Agent 应用)
1.2 本篇核心
本篇将会给大家分享第一部分的内容。核心是让你的脑海中对 Agentic System 有一个基本概念,能够看懂市面上一些 Agent 产品的门道,同时也能够自己开发一些小玩意。
本篇你将会学习到:
- Agent 产品是怎么设计的
- 什么是 Agentic System
- 什么是 workflow 工作流
- 什么是 Agent 智能体
二、Agent 产品
这里我们先看一下,有哪些是 Agent 产品。
- Cusror 和 Trae:它们主要解决编程领域的问题。
- 豆包、元宝、通义等,它们的能力范围就会更广和更通用。

- B 端的一些金融、医疗、企业知识库、智能客服等
- AI PPT 、文档创作类产品
上面列举的产品其实都属于 Agentic System。那到底什么是 Agentic System?
三、Agentic System
3.1 定义
在 Anthropic 的官方文档中,一篇如何构建 Agent 的文章《Building effective agents》有提到 Agentic System 到的定义:
"Agent" can be defined in several ways. Some customers define agents as fully autonomous systems that operate independently over extended periods, using various tools to accomplish complex tasks. Others use the term to describe more prescriptive implementations that follow predefined workflows. At Anthropic, we categorize all these variations as agentic systems, but draw an important architectural distinction between workflows and agents:
“智能体”可以有多种定义方式。一些用户将智能体定义为完全自主的系统,这些系统能够长时间独立运行,并使用各种工具来完成复杂任务。另一些人则用这个术语来描述更具规定性的实现,它们遵循预定义的工作流程。在Anthropic,我们将所有这些变体归类为智能体系统,但在架构上对工作流程和智能体进行了重要区分:
- Workflows are systems where LLMs and tools are orchestrated through predefined code paths.
- 工作流是通过预定义代码路径编排大语言模型和工具的系统。
- Agents, on the other hand, are systems where LLMs dynamically direct their own processes and tool usage, maintaining control over how they accomplish tasks.
- 另一方面,智能体是这样一种系统,其中大语言模型(LLMs)动态引导自身流程和工具使用,对完成任务的方式保持控制。
简单来说就是,Agentic System(agents 系统)就是由一个或多个 agent(智能体) + 一种或者多种 workflow(工作流)组成的一个能够理解用户需求,规划解决方案,自主决策,解决用户问题的系统。
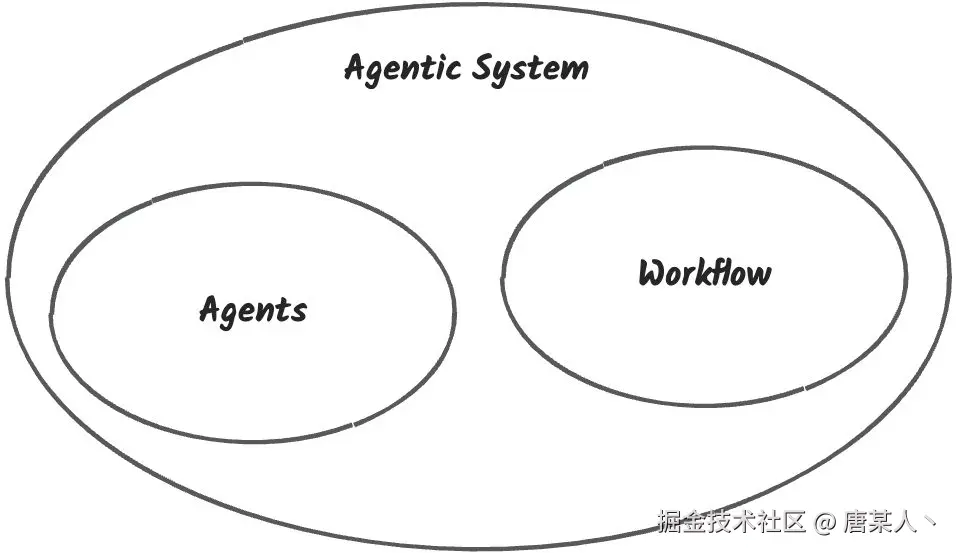
通俗点的理解,你可以把 agent 理解成一个个特定的岗位(需求,开发,设计),workflow 理解成工作办公流程(需求确定 --> 团队分工 --> 设计UI --> 前后端开发 -->测试上线),由这些岗位按照工作流程来工作的团队就是 Agentic System。
3.2 案例分析
Agent?Workflow?组成的系统? 这三个概念到底是啥?这里分析一个 Cursor 解决问题的案例,咱们先宏观的感受一下 Agentic System 是怎么解决问题的。
我让 Cursor 迁移项目中的一个页面模块,通过对话信息可以看到:
- 它通过分析,发现我提的可能是一个复杂问题
- 于是开展工作前,它生成一份清晰的计划方案
- 接着它开始按照计划,分步或者并行的执行任务(代码查找、文档搜索)
- 搜集完明确的信息后,开始逐个的修改和创建文件
- 最后它会对每个修改过的文件进行测试和检查
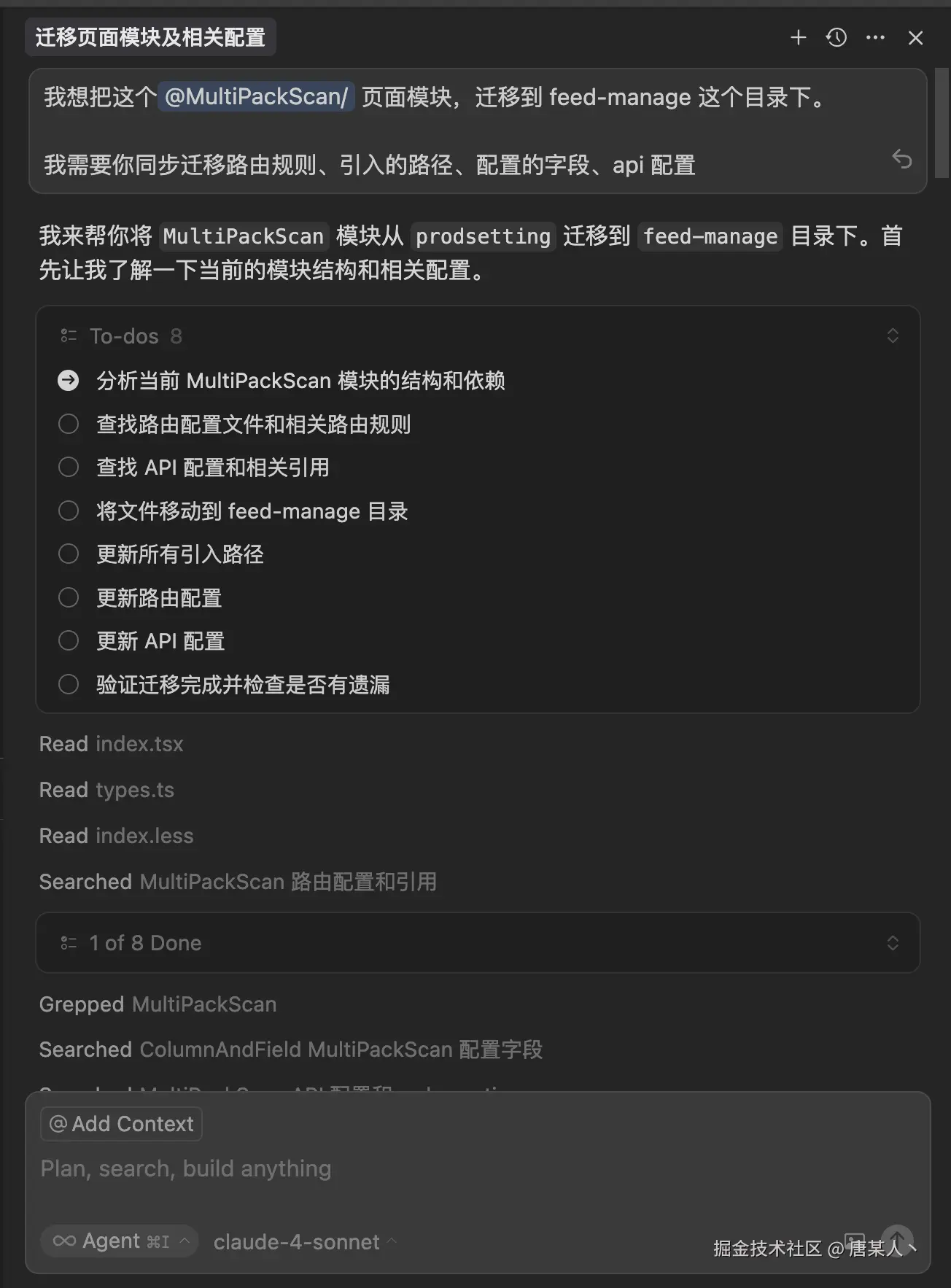
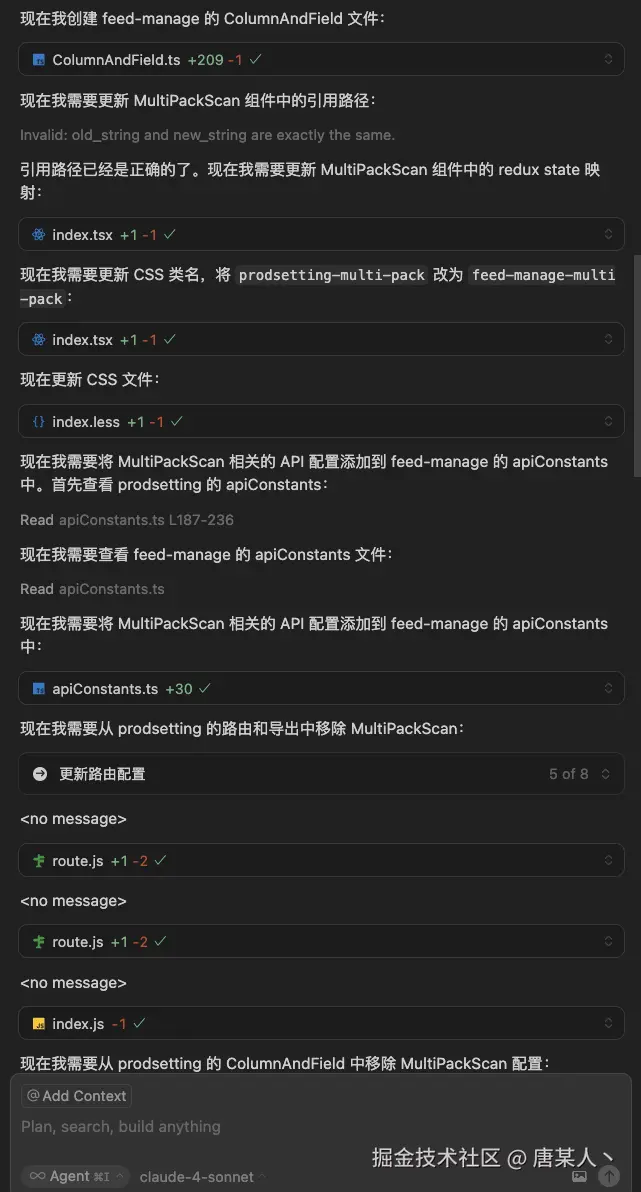
上面看似是一次对话,然后 Cuscor 自己一个人在那里跑,其实它背后有很多的门道。不知道有没有同学好奇过,为什么有时候在使用 Cursor 或者 Trae 的时候,明明跟它只是一次对话,却消耗了多次的“高级请求”。
其实是因为它们作为一个复杂的 Agentic System,在处理问题的过程中,通常是多个 Agent 配合完成的。作为用户视角,你只是一次对话,但是在系统内部的就可能执行了多个复杂的流程。
这里我画一个简单的流程图(这个流程图并非真实的 Cursor 推理流程,只是根据当前场景的一个推断)
- 用户输入
- 问题判断 Agent:识别问题类型,引导到不同的流程上
- 需求澄清 Agent:可能会跟用户多轮沟通,直到确定用户的需求
- 计划 Agent:根据“需求澄清 Agent”和用户聊天的上下文,分析并生成一份执行计划
- 执行 Agent:根据计划执行各种任务,这里面可能会有各种 Agent(代码检索、代码编写等)
- 代码审查 Agent:在将代码真正写入用户文件时,会不断检测代码是否存在问题,当满足要求时才会写入
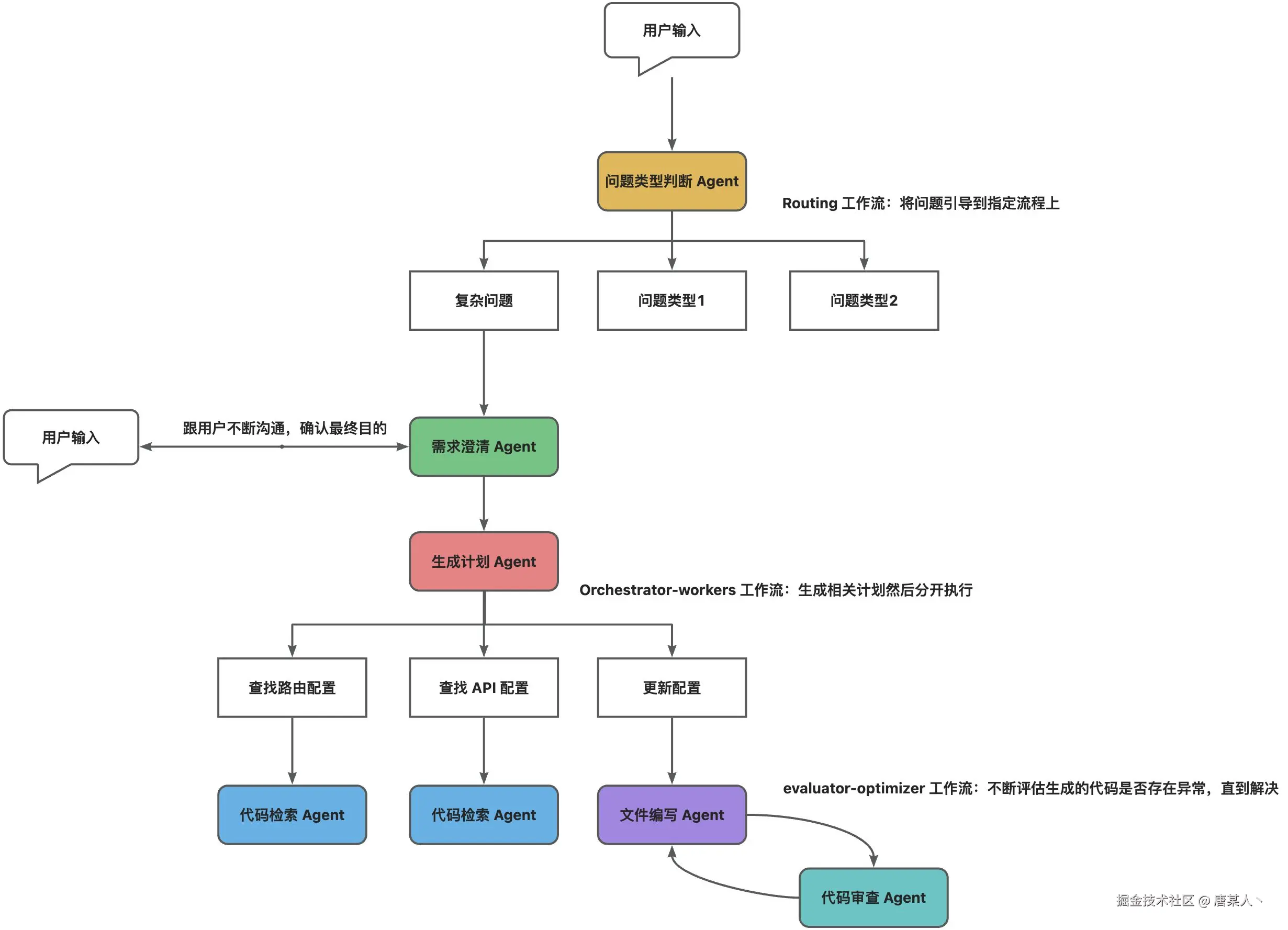
上面就是 Agent + Workflow 的一个大致工作流程。说了这么多,那 Agent 和 Worflow 到底是什么东西?
四、Agent
4.1 定义
对于 Agent 的认知,我认为可以分为两个层面来看
- 抽象定义:Agent 是一个能够明确目标,自主规划,感应环境,基于目标解决问题的实例
- 代码定义:就是一个 LLM + 提示词 + 工具 + Memony 组成的程序
下面我们通过实现一个简易版的旅游规划大师,来感受下 Agent 解决问题的过程。
4.2 增强版 LLM
我们先在 LLM API 的基础上扩展一下,让它支持设定系统提示词、工具调用以及对话记忆,这些基础能力对于 Agent 非常重要。至于为什么,在实现完这个 Agent 以后再讲。
完成的代码: 代码地址
属性配置
实现一个 Block 类,支持配置提示词指令、工具、模型参数等
/**
* 增强的 LLM 实例
* 具备检索、工具调用、记忆的核心能力
*/
export class Block {
private baseUrl: string;
private modelName: string;
private apiKey: string;
private instruction: string;
private tools: Tool[] = [];
constructor(props: BlockProps) {
this.baseUrl = props.baseUrl;
this.modelName = props.modelName;
this.apiKey = props.apiKey;
this.instruction = props.instruction;
this.tools = props.tools || [];
}
}
对话记忆
接着实现对话的记忆能力。这里要实现一个 messages 管理对话的信息以及 invoke 方法,在调用 invoke时,会把用户的输入和 LLM 的回复都记录下来。
export class Block {
// 记录对话信息(上下文)
private messages: Message[] = [];
/** 省略 …… */
async invoke(query?: string) {
// 记录用户输入
if (query) {
this.messages.push({
role: 'user',
content: query
});
}
// 获取 LLM 的回复
const assistantMessage = await fetch(/** 调用 LLM 的 API */)
// 记录 LLM 的回复
if (assistantMessage) {
this.messages.push({
role: 'assistant',
content: assistantMessage
});
}
}
}
工具调用
然后就是工具调用的能力。它的核心逻辑就是在收到 LLM 的工具调用指令后,能够找到工具执行,并将执行的结果添加到 messages 对话上下文中,然后再触发一次新的对话。
export class Block {
/** 省略 …… */
async invoke(query?: string) {
// 记录用户输入
if (query) {
this.messages.push({
role: 'user',
content: query
});
}
// 获取 LLM 的回复
const res = await fetch(/** 调用 LLM 的 API */)
const assistantMessage = '' // 处理 res 得到 LLM 的文本回复
const functionName = '' // 处理 res 得到 LLM 想调用的工具名
const functionArguments = '' // 处理 res 得到 LLM 的调用参数
// 记录 LLM 的回复
if (assistantMessage) {
this.messages.push({
role: 'assistant',
content: assistantMessage
});
}
// 如果 LLM 回复的是工具调用指令,则找到工具执行,并自动再出发一次 LLM 的对话
if (functionName && functionArguments) {
const tool = this.tools.find(tool => tool.function.name === functionName);
if (tool) {
const args = JSON.parse(functionArguments);
const result = await tool.func(args);
console.log(`${functionName} 工具调用参数 --> ${functionArguments}`);
console.log(`${functionName} 工具调用结果 --> ${result}`);
this.messages.push({
role: 'tool',
content: result,
tool_call_id
});
// 自执行一次
await this.invoke();
}
}
}
}
4.3 Agent 实践
下面我们创建旅行规划大师。先定义提示词,作为指导 Agent 完成任务的重要信息
const prompt = `
你是一个旅行规划大师,你职责是根据根用户输入的旅游目的地和具体的日期,结合那天的天气推介出最适合游玩的景点。
你可以调用以下工具,获取详细的信息:
1. get_current_weather:查询指定城市在指定日期的天气
2. get_recommended_attractions:根据城市的名称、天气获取推荐的旅游景点
注意,这两个工具不允许同时调用,一次只能调用一个工具。你必须在拥有详细的且能够自信回答的信息后,才能告诉用户推荐的景点信息。
`;
然后是给它配置工具
const tools: Tool[] = [
{
type: 'function',
function: {
name: 'get_current_weather',
description: '查询指定城市在指定日期的天气',
parameters: {
type: 'object',
properties: {
location: {
type: 'string',
description: '城市名称'
},
date: {
type: 'string',
description: '日期'
}
},
required: ['location', 'date']
}
},
func: async (args: { [key: string]: any }) => {
console.log(args);
// 这里实现获取天气的具体逻辑
return `获取到${args.location}的天气数据为: 天晴 30度`;
}
},
{
type: 'function',
function: {
name: 'get_recommended_attractions',
description: '根据城市的名称、天气获取推荐的旅游景点',
parameters: {
type: 'object',
properties: {
location: {
type: 'string',
description: '城市名称'
},
weather: {
type: 'string',
description: '当地天气'
}
},
required: ['location', 'weather']
}
},
func: async (args: { [key: string]: any }) => {
console.log(args);
// 这里实现获取日期的具体逻辑
return `获取到${args.location}的推荐景点为: 广州塔、珠江新城、黄埔军校`;
}
}
];
最后是创建实例
export const travelAgent = new Block({
baseUrl: process.env.BASE_URL!,
modelName: process.env.MODEL_NAME!,
apiKey: process.env.API_KEY!,
instruction: prompt,
tools: tools,
processWrite: true
});
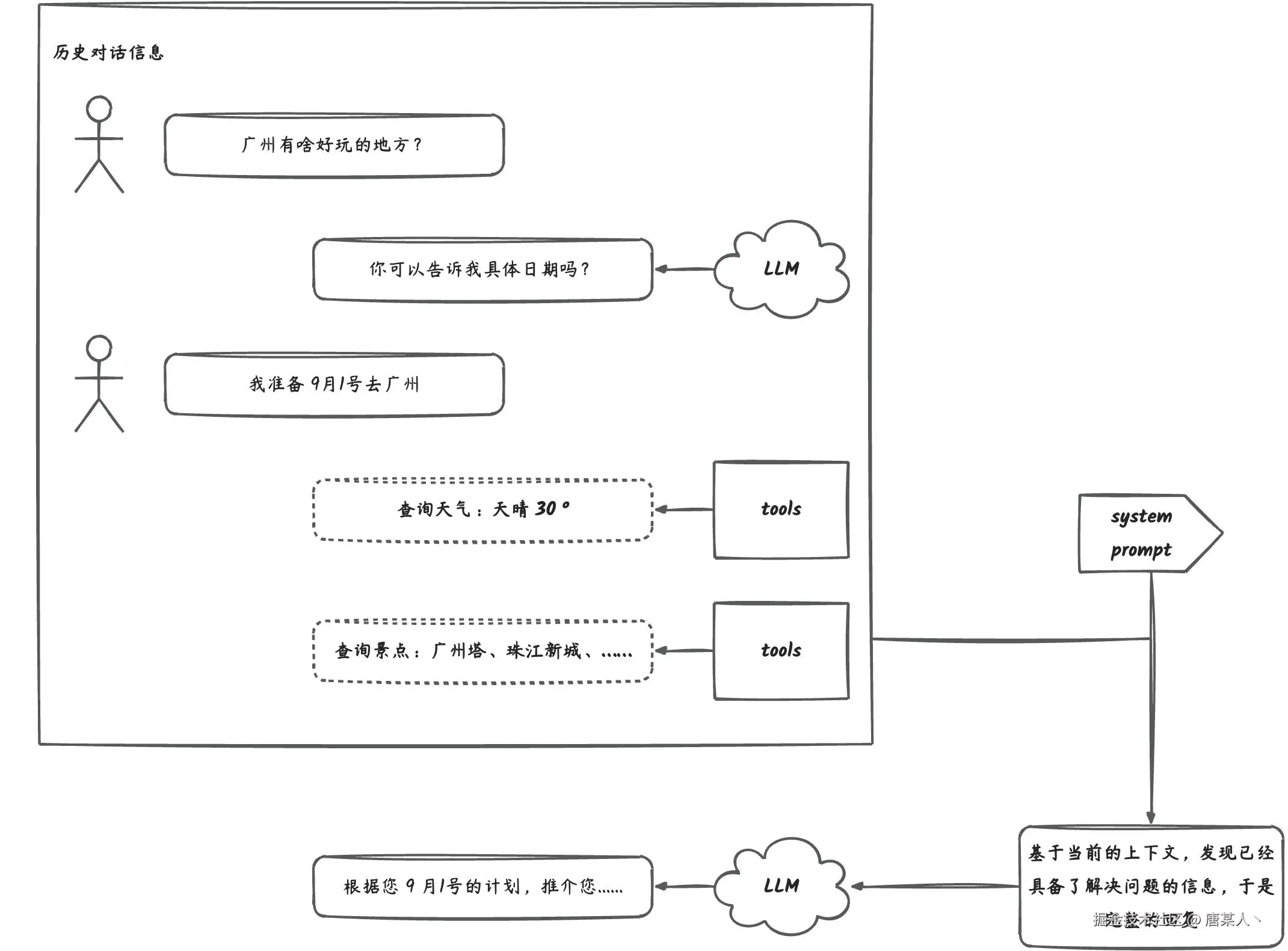
先来问一个广州有啥好玩的(案例中我是用的是deepseek的推理模型,所以白色文字是它的思考过程,绿色文字才是真实的回答)

LLM 发现缺乏日期信息,所以它开始向我咨询

于是我补充了具体的日期。在补充信息后,它调用了获取天气的工具,得到了指定日期的天气情况。

有了天气的信息,它开始自己继续下一步规划,调用了获取推荐景点的工具。在得推荐景点后,它给出了我完整的答复。

上面就是一个简单的 Agent 自主思考、规划、决策的解决任务的过程。它成功的告诉了在广州9月1号有啥好玩的地方。
4.4 运行机制
基于上面的案例,我们现在来讨论,为什么开发一个 Agent 必须要具备提示词设定、工具调用、对话记忆的核心基础能力。
前面有说到,从抽象定义来看,Agent 必须具备**明确目标,自主规划,感应环境 **的基本特性。这些特性就是由这三个核心能力支持的。
明确目标
基于 提示词设定 职责的设定,结合用户问题的输入,Agent 就能知道要完成的目标是什么以及推理出达成目标所需的必要条件。
比如第一轮对话 Agent 知道了用户的目标是想得到广州的推荐景点信息,所以它要知道是哪天去

自主规划
在用户给出了具体日期后,基于记忆能力它能够知道过去聊了什么,对话中积累了哪些关键信息,再配合上现有的工具能力,就可以规划出后续每一步需要做什么。
例如案例中,结合用户回复的日期,LLM 决策了要调用哪些工具,我们要做的就是在程序中就会依次的找到工具并执行。
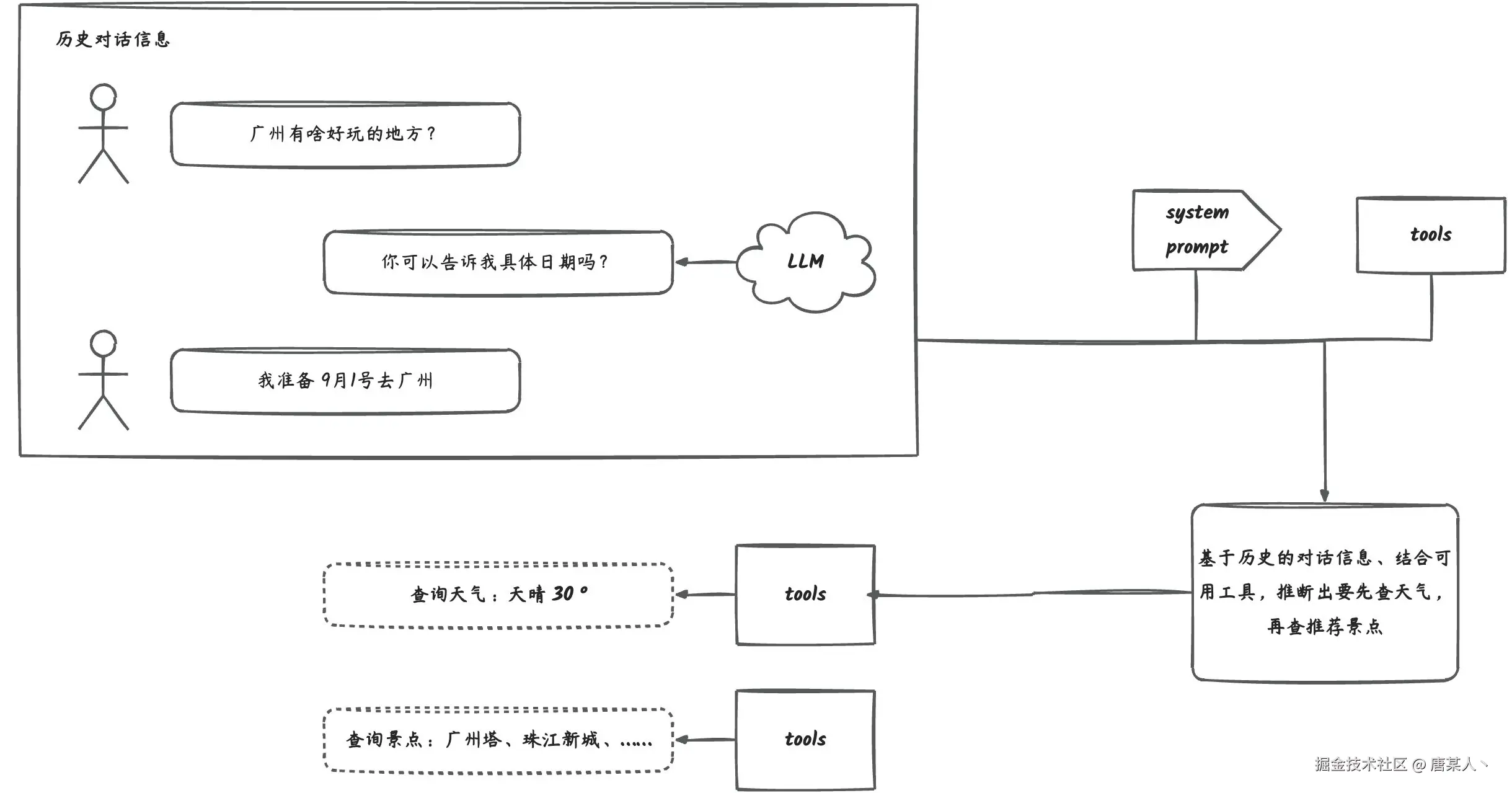
这里提醒一下,因为我怕有些同学忘记了。在《AI 应用开发入门:前端也可以学习 AI》中我有提到过,LLM 本身是无状态的,也是它不会记录你之前的聊天信息。但是,它之所能记得之前聊了什么,是因为我们在代码里面维护了所有的聊天信息、工具调用结果,并且在每一次新的对话中,会全部的重新传给他。
下面这个图来自 deepseek 官网,它描述了对话中,上下文拼接的过程。每次对话都会把过去的所有对话信息,重新传给 LLM。
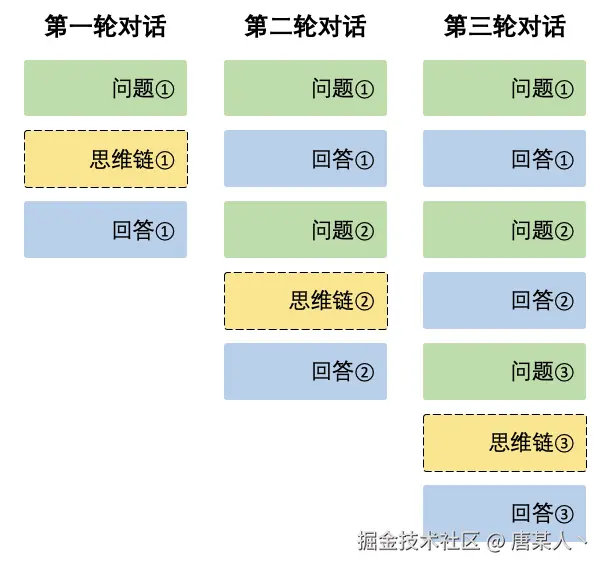
感应环境
那什么是感应环境呢?
首先来说一下“环境”。你可以理解为你代码的执行环境。例如 LLM 回复了调用工具的指令,所以我们需要在代码的执行环境里调用工具,帮它查询所需要的信息。
“感应”其实就把工具查询的结果,再丢进对话的上下文里再传给 LLM,让 LLM 知道工具实际调用的情况。此时 LLM 结合用户输入的信息、工具调用的信息,就可以判断出是否满足解答问题的条件。
4.5 与传统软件的区别
现在我们来探讨一个问题:Agent 与传统软件有什么区别?
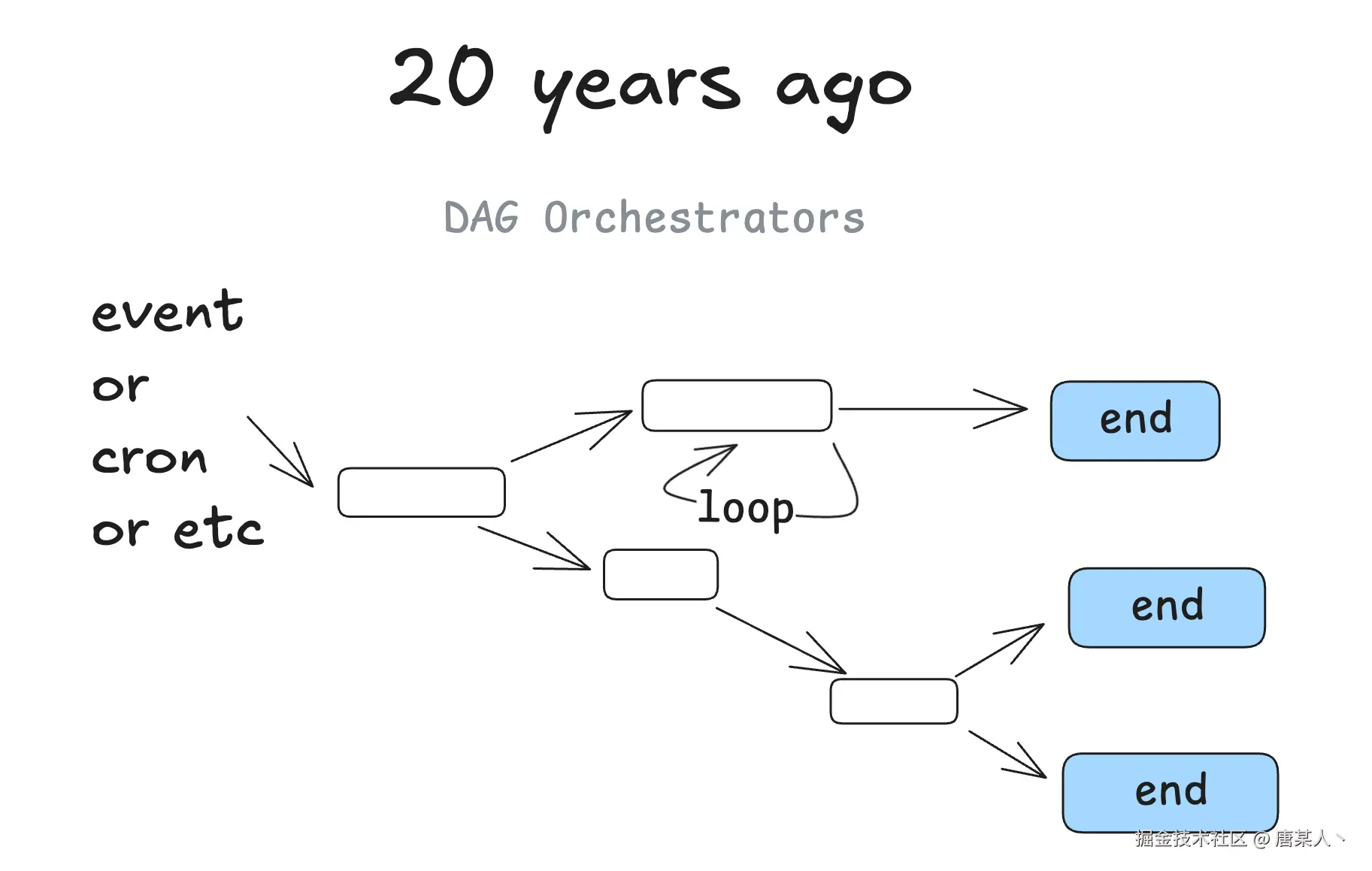
首先思考一下,传统软件解决问题的逻辑:一般情况下,你想得到想要的结果,就必须遵循固定的输入,然后按照程序固定的程序流程执行。
然而相比 Agent ,它的解决方式更像是一个能够自己寻找最短路径的“聪明人”,只要给定它目标以及能够解决该领域问题所需要用到的工具,它就会自己找到最优的“解”。
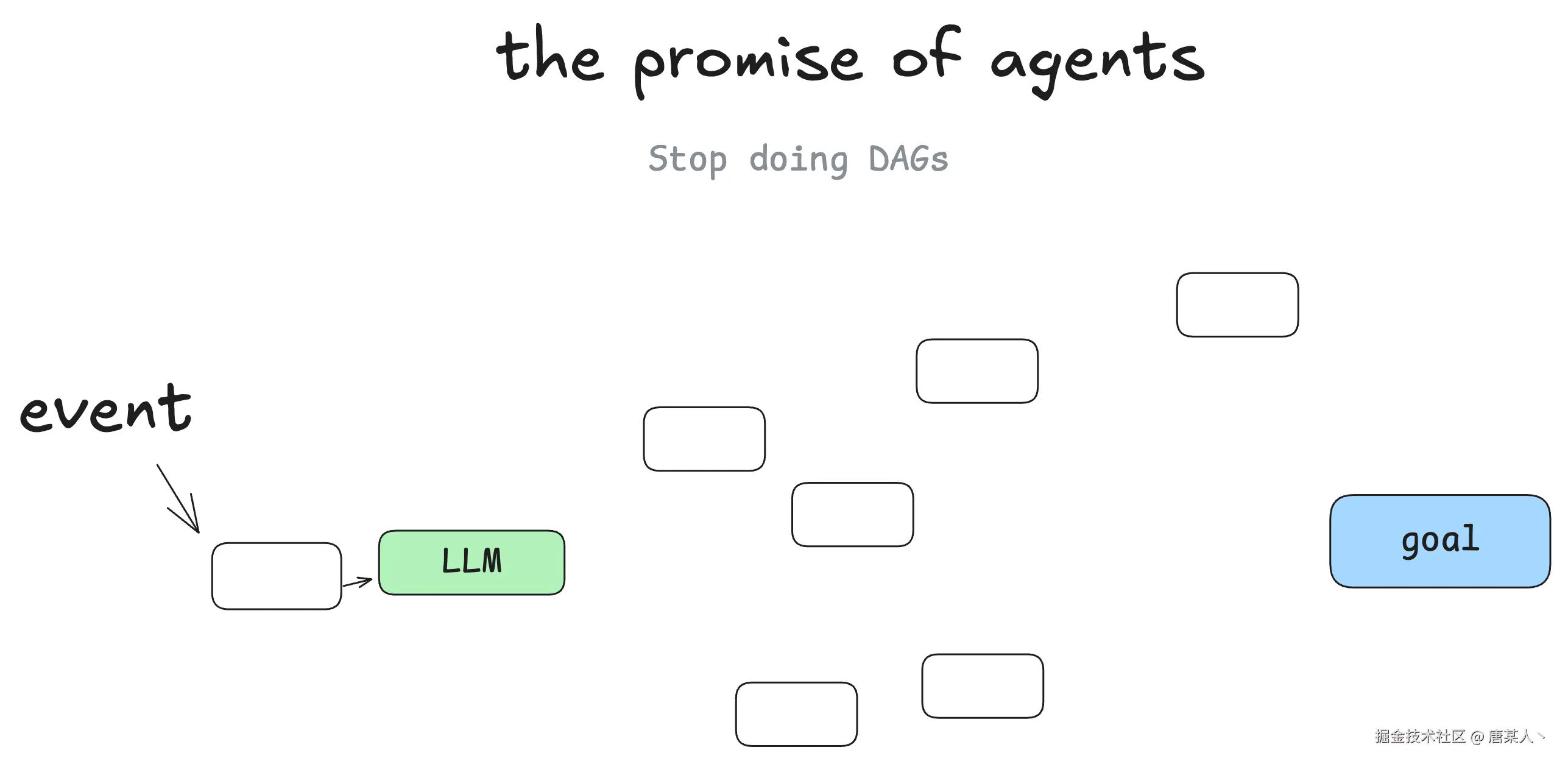
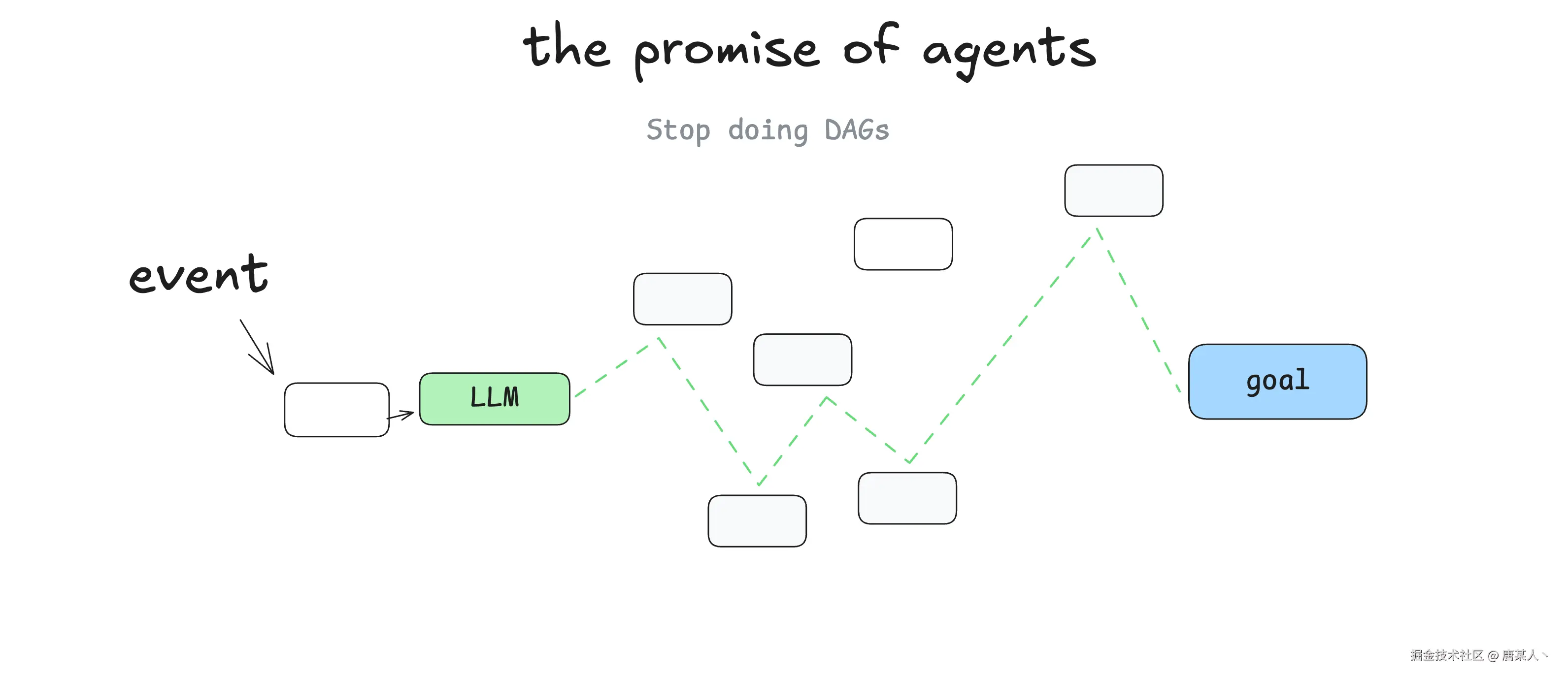
在《12-factor-agents》有提到关于 Agent 和传统软件区别的概念,它认为传统软件解决问题的过程就是一个有向无环图,而 Agent 可以自己在里面做出决策找到解决路径
I'm not the first person to say this, but my biggest takeaway when I started learning about agents, was that you get to throw the DAG away. Instead of software engineers coding each step and edge case, you can give the agent a goal and a set of transitions
我并不是第一个这么说的人,但当我开始学习智能体时,最大的收获是你可以抛开有向无环图了。不再需要软件工程师编写每一个步骤和边缘情况,你只需给智能体一个目标和一系列转换规则即可
4.6 小结
这一章节重点讲述了关于 Agent 的三块内容
- Agent 的定义,可以从抽象层和代码层开看待
- Agent 的运行离不开系统提示词、工具的调用、对话记忆的基础核心能力
- Agent 与传统软件解决问题的方式区别在于,它不需要完全固定的编码,更像一个 “自主决策的聪明人”,只需给定目标和工具,即可自主寻找最优解决路径,无需硬编码每一步和边缘情况。
五、Workflow
5.1 定义
工作流本质就是按照固定的、可控的方式,组织各种 Agent 的一种方式。它存在的意义就是,让 AI 应用的逻辑流程是程序性可控的。其实就好比你在代码里面写 if/else/switch/for组织各种函数逻辑的调用是一样的。
我们传统程序的逻辑流程是:功能函数 + 条件判断 + 循环,而 AI 工作流其实也是如此,组成一个工作流的核心,通常有两个核心要素:
下面我用代码演示两个要素。
LLM 节点
什么是叫 LLM 节点呢?在我的理解,它可以是一个执行简单任务的 LLM,也可以是一个具备自主决策能力的 Agent。下面我通过代码简单演示一下。
这是 LLM 的提示词,它任务是翻译技术文档
你是一个专业的技术文档翻译。你的任务是将英文的技术文档翻译成中文文档。
注意,一些专业的技术名词、代码不需要翻译,保持原来的英文和格式。
配合上代码
class LLMNode {
private instruction: string;
constructor(props) {
this.instruction = props.instruction;
}
// 接受输入,调用 LLM 输出
async invoke(query: string) {
const res = await fetch(/* 调用 LLM API */)
return res;
}
}
const translationNode = new LLMNode({ instruction: '你是一个专业的技术文档翻译……' })
现在已经创建了一个用于翻译技术文档的 LLM 节点,在调用 invoke 时,它只会去做“翻译”这个事情。通常在需要 LLM 解决某一个问题的时候,我们会把解决步骤拆分到一个个单一职责的 LLM 节点上。例如,下面这个翻译英文文档,再总结提炼的工作流。
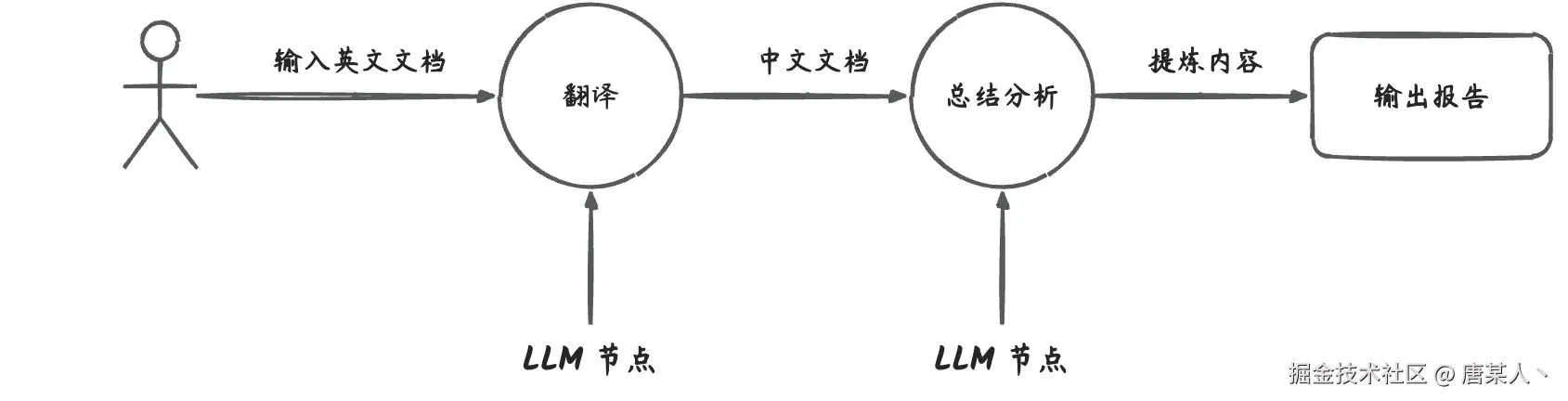
为什么要将工作拆分给不同的、职责单一的 LLM 来完成任务呢?在 《12-Factor Agents - Principles for building reliable LLM applications》有提到过
As context grows, LLMs are more likely to get lost or lose focus
随着上下文增加,大型语言模型更容易迷失方向或分散注意力
Benefits of small, focused agents
小型、专注的智能体的优势:
-
Manageable Context: Smaller context windows mean better LLM performance 可管理的上下文:更小的上下文窗口意味着更优的大模型性能
-
Clear Responsibilities: Each agent has a well-defined scope and purpose 职责明确:每个智能体都有清晰界定的范围和目标
-
Better Reliability: Less chance of getting lost in complex workflows 更高的可靠性:在复杂工作流程中迷失的可能性更低
-
Easier Testing: Simpler to test and validate specific functionality 测试更简单:特定功能的测试和验证更为简便
-
Improved Debugging: Easier to identify and fix issues when they occur 改进的调试功能:出现问题时更容易识别和修复
所以尽可能让 LLM 处理单一的任务,效率和效果会更加好的。开发者维护起来也会更加友好。
编排逻辑
那这些 LLM 节点是怎么被组织成工作流的呢?其实就是通过代码里面的 if/else/switch/for控制的。例如我们基于链式的工作流,实现一个翻译英文文档再总结提炼的工具
代码实现如下
const translationNode = new LLMNode(/* 翻译任务的 LLM */)
const summaryNode = new LLMNode(/* 分析总结任务的 LLM */)
const chain = async (nodes) => {
returun (input) => {
let cur = input
for(let node of nodes) {
cur = await node.invoke(curInput)
}
return cur
}
}
const tanslateChain = chain([translationNode, summaryNode])
chain('帮我总结一下这个文档……')
其实就是一个正常的循环顺序执行,说高级点就是函数式编程里面的 Compose 设计,将一组函数组合起来。
5.2 设计模式
在实际的 Agentic System 的开发中,也会像写传统软件一样,会用到多种设计模式来组织应用流程。在这篇《Building effective agents》文章中,Anthropic 总结了 5 种关于 Workflow 的设计模式。
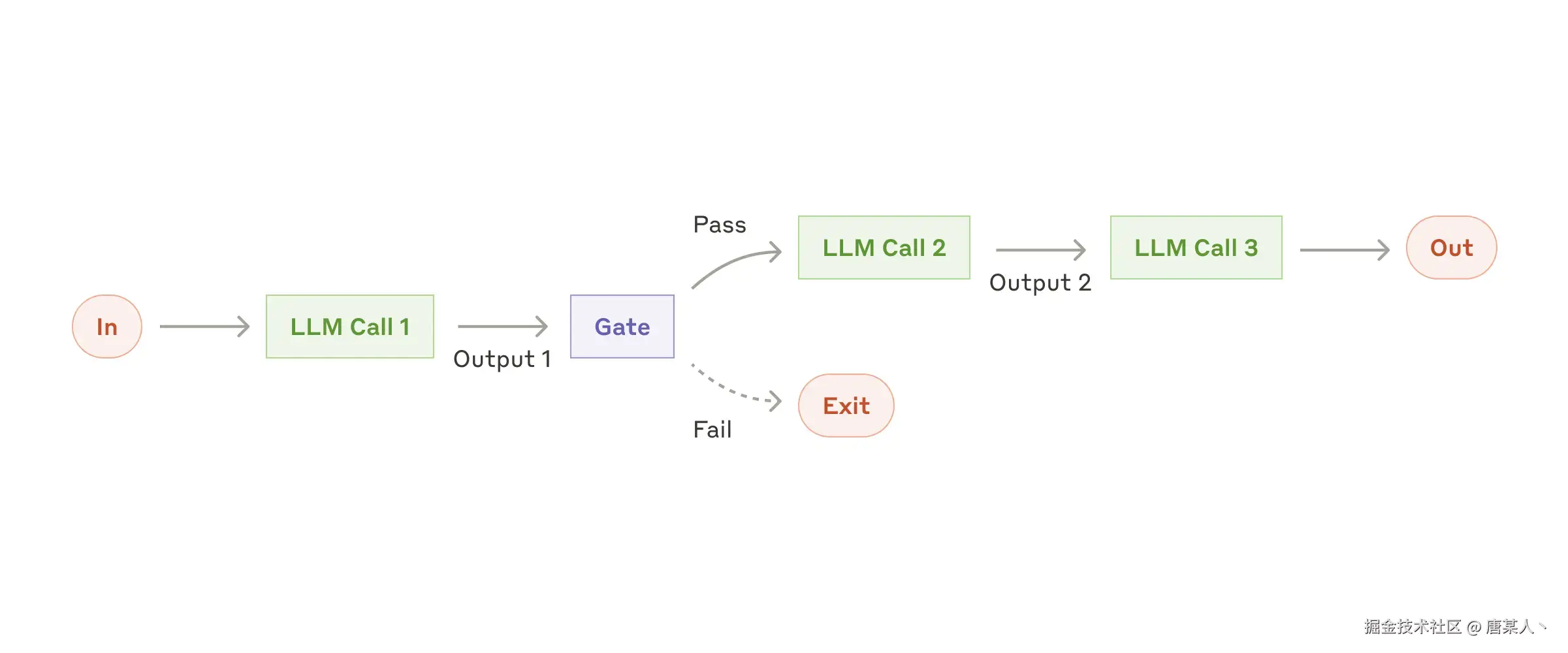
Chain
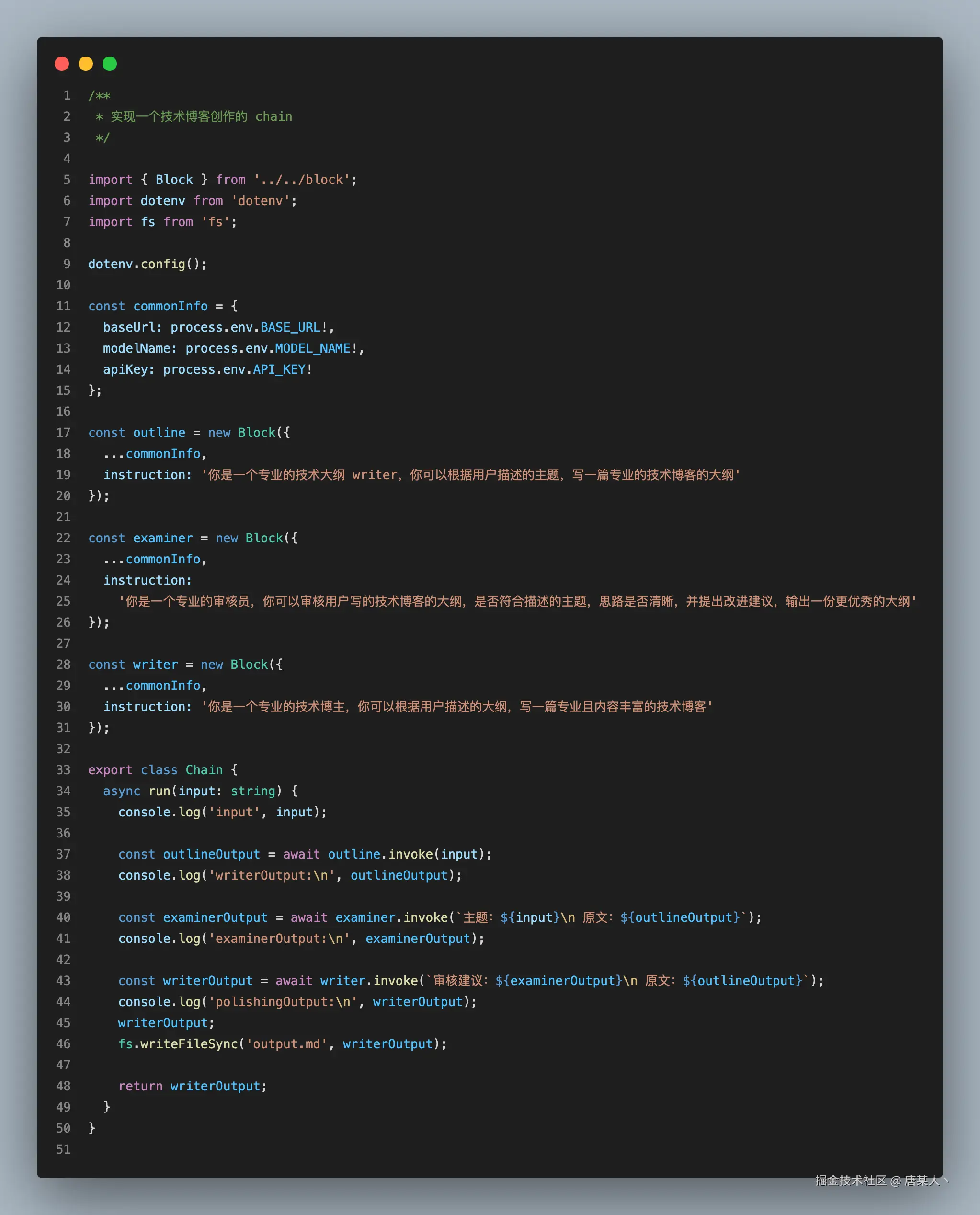
链模式是将一个任务分解为一系列步骤,每次调用 LLM 都会接受上一步的输出。你可以在任何中间步骤添加编程检查(见下图中的 “卡控”),以确保该过程仍按计划进行。它一般比较适合串行处理场景,如文案创作、分析总结等
这里演示的是一个 “生成技术博客”的工具: 完整代码
实现逻辑
Anthropic 对这种工作流的点评是:
When to use this workflow: This workflow is ideal for situations where the task can be easily and cleanly decomposed into fixed subtasks. The main goal is to trade off latency for higher accuracy, by making each LLM call an easier task.
何时使用此工作流程: 此工作流程非常适合那些可以轻松、清晰地分解为固定子任务的情况。其主要目标是通过将每次大语言模型调用变为更简单的任务,以牺牲延迟来换取更高的准确性。
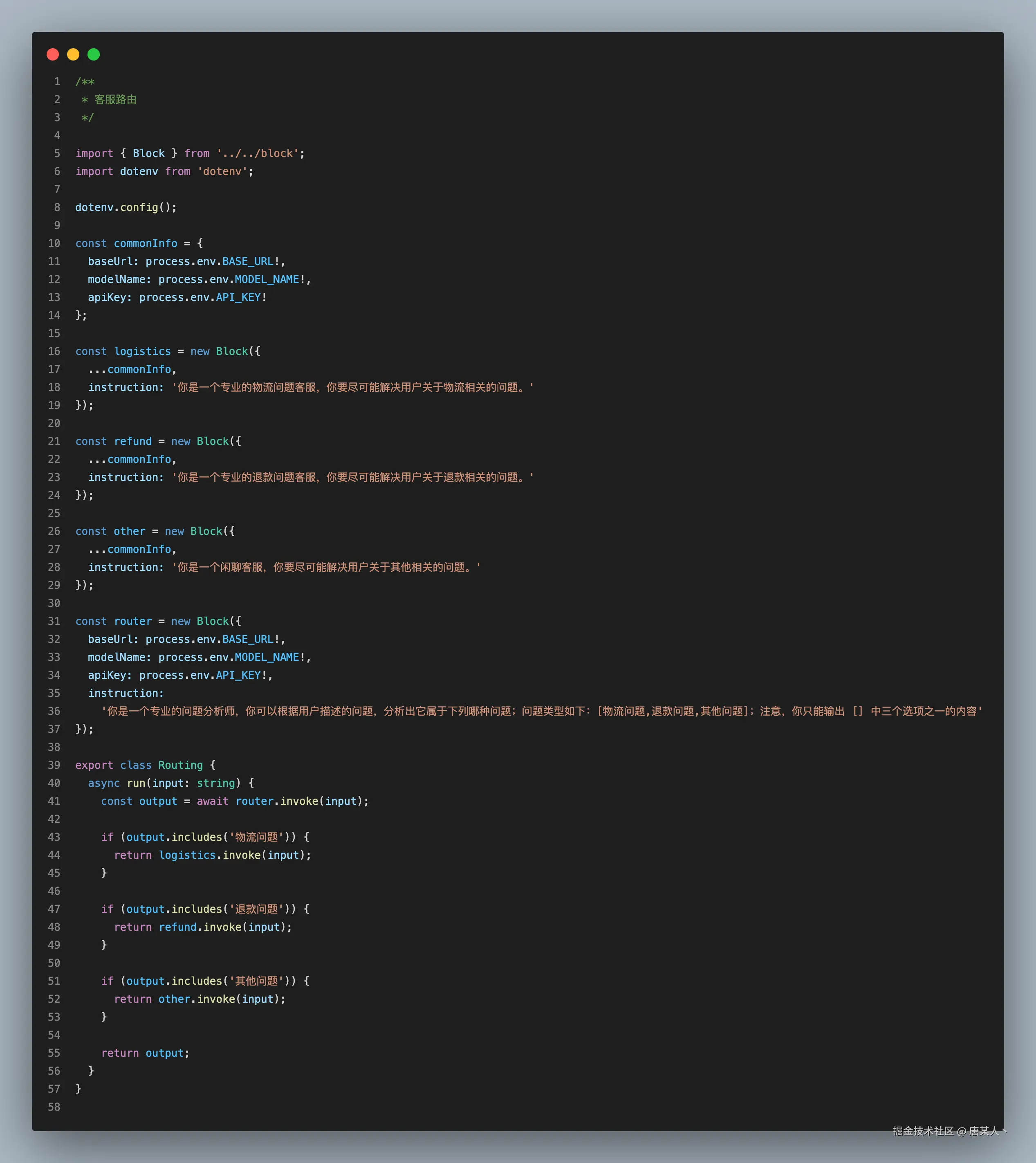
Routing
路由对输入进行分类,并将其导向专门的后续任务。这种工作流程有助于实现关注点分离,并构建更具针对性的提示。如果没有这种工作流程,针对某一类输入进行优化可能会损害模型在其他输入上的性能。
比较典型的场景,就是分类引导。例如客服助手的问题引导,还有像 Cursor 、Trae 它们判断输入需求的复杂度和类型,来决定是简单任务还是复杂任务,复杂任务就会走到所谓的“高级请求”(由更多 Agent、更复杂的 Workflow 组成的流程)里面。
这里演示的是一个客户问题引导的案例:完整代码
Anthropic 对这种工作流的点评是:
When to use this workflow: Routing works well for complex tasks where there are distinct categories that are better handled separately, and where classification can be handled accurately, either by an LLM or a more traditional classification model/algorithm.
何时使用此工作流程: 路由适用于复杂任务,这些任务存在不同的类别,且分开处理效果更佳,同时无论是通过大语言模型(LLM)还是更传统的分类模型/算法,都能准确进行分类。
Parallelization
大语言模型有时可以同时处理相同或者不同的任务,并通过编程方式汇总它们的输出。这种工作流程,有两个方式:
- 切分:将一个任务分解为可并行运行的独立子任务。
- 投票:多次运行同一任务以获得不同的输出,最终选择最合适的那个结果。
这里继续拿 Cursor、Trae 举例,有时候它们需要并行去查看多文件,从而得到一些关键信息来推进后续的步骤。
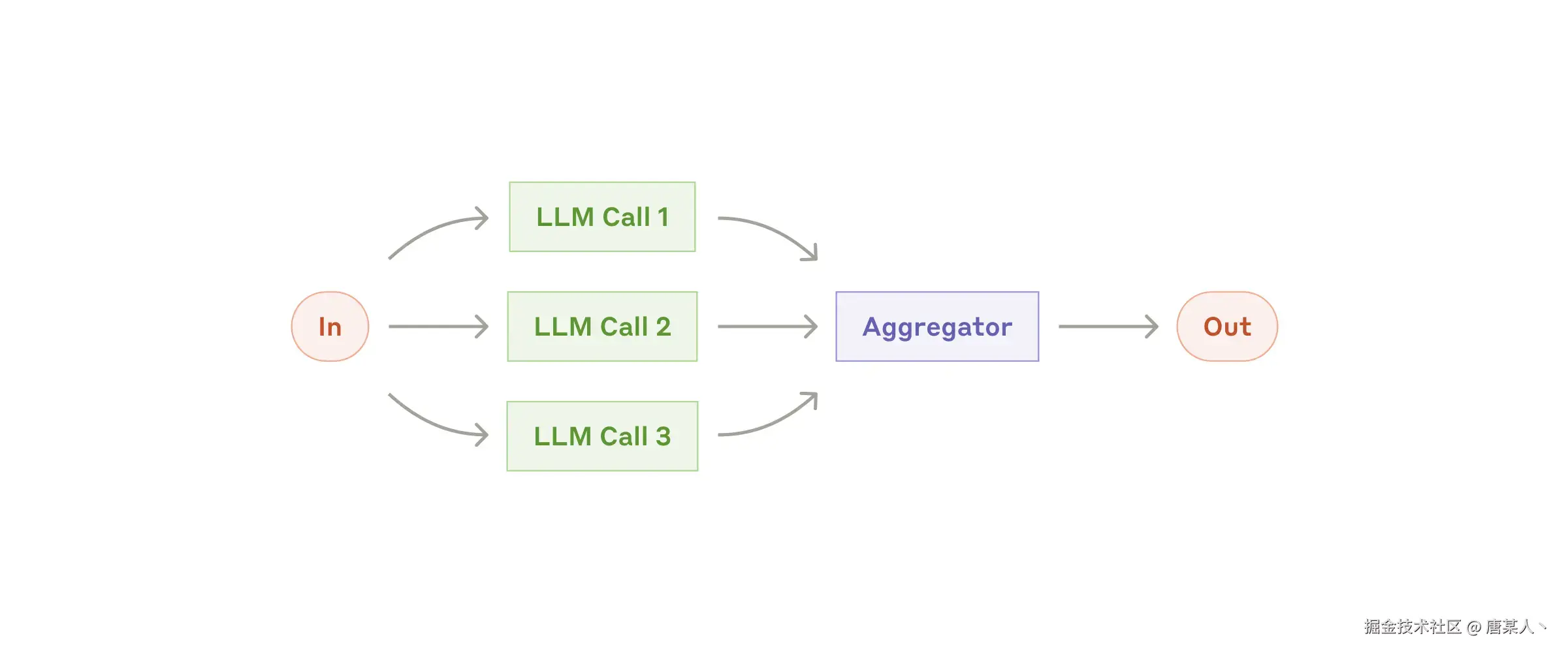
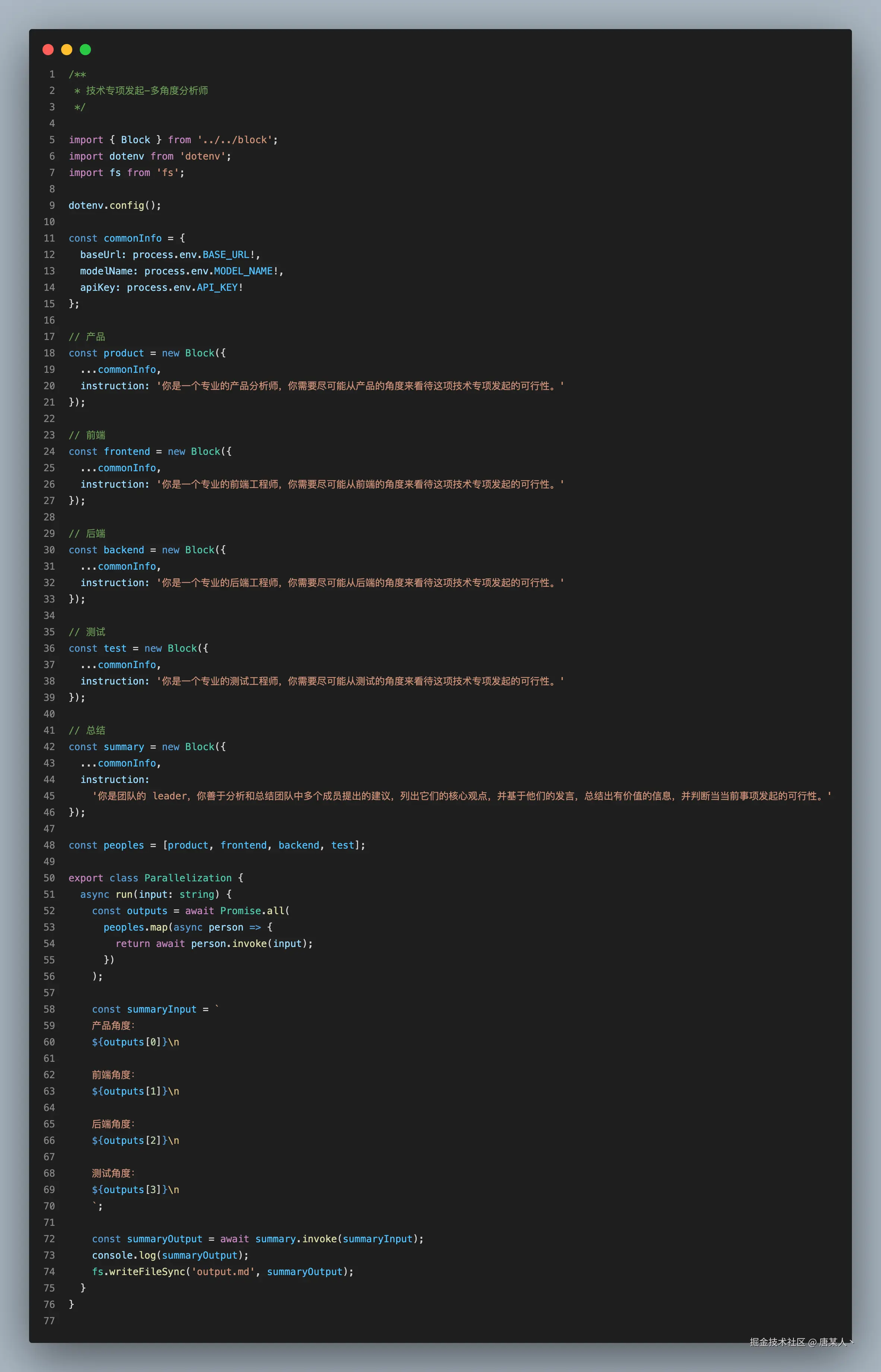
这里演示的是一个多角度分析师的案例,当你想发起一个技术专项的时候,可以通过多角度并行的去分析一下可行性,最后生成一个汇总分析报告:完整代码
Anthropic 对这种工作流的点评是:
When to use this workflow: Parallelization is effective when the divided subtasks can be parallelized for speed, or when multiple perspectives or attempts are needed for higher confidence results. For complex tasks with multiple considerations, LLMs generally perform better when each consideration is handled by a separate LLM call, allowing focused attention on each specific aspect.
何时使用此工作流程: 当划分后的子任务可以并行处理以提高速度,或者为了获得更可靠的结果需要从多个角度进行尝试时,并行化是有效的。对于需要多方面考量的复杂任务,通常当每个考量因素由单独的大语言模型调用处理时,大语言模型的表现会更好,这样可以专注于每个特定方面。
Orchestrator-workers
在编排器-执行器工作流程中,一个中央大语言模型会动态分解任务,将它们委托给执行器大语言模型,并综合其结果。
比较典型的例子就是 Cursor、Trae 在处理复杂任务的时候,它们会将任务拆分成不同的步骤,然后每个步骤交给一个子 Agent 或者工具去独立完成。
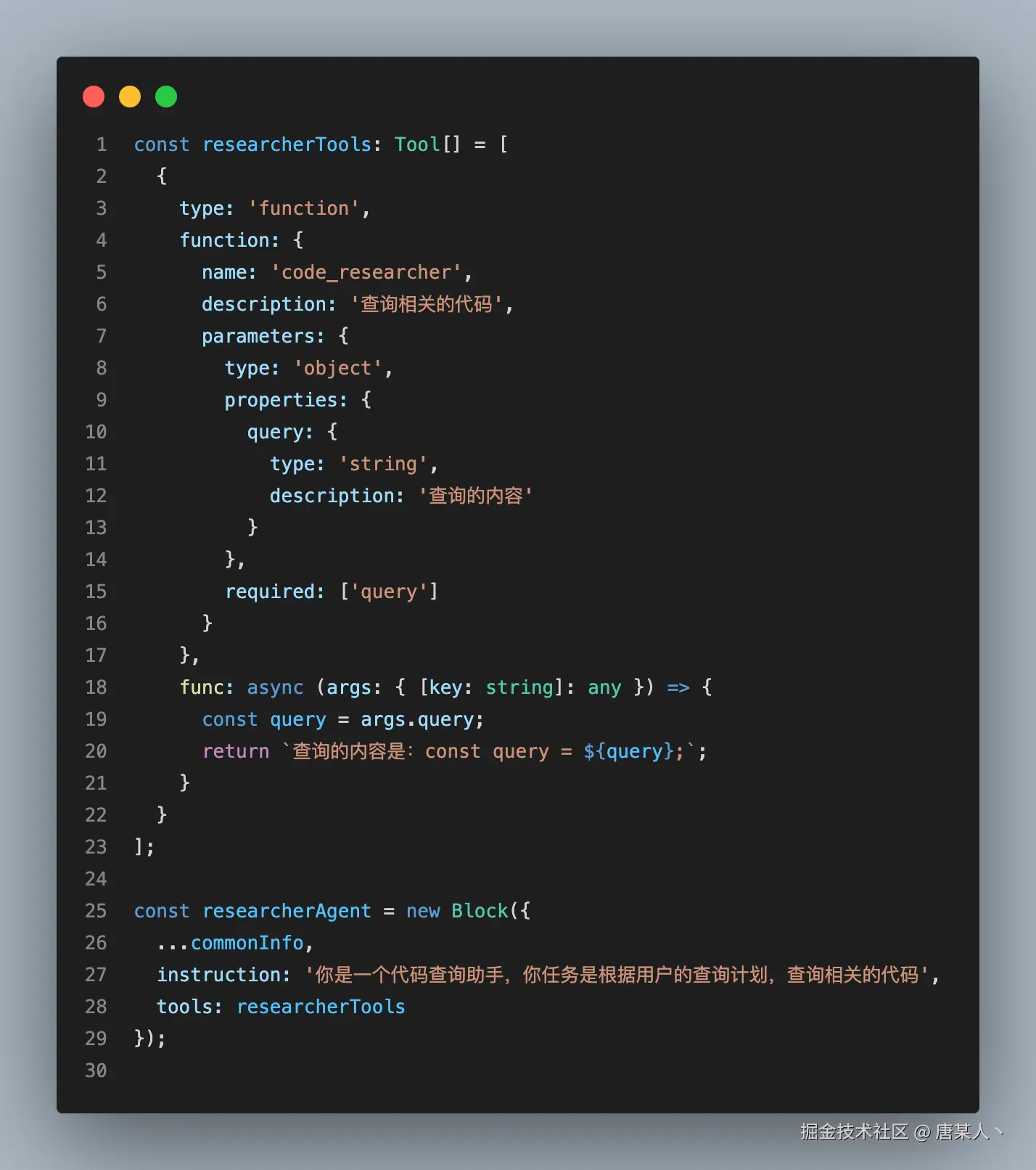
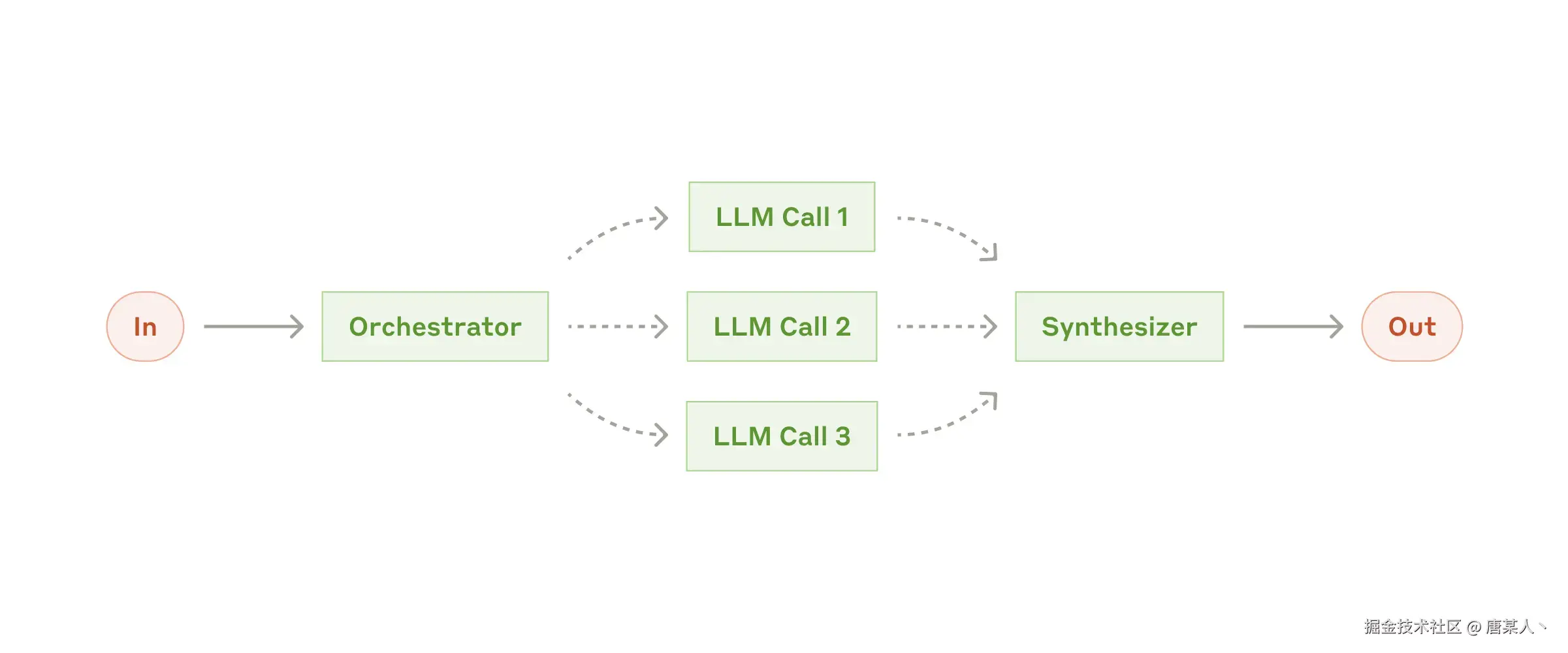 下面我演示一个代码查询的案例,用协调器 Agent 分派多个查询任务给子 Agent。
下面我演示一个代码查询的案例,用协调器 Agent 分派多个查询任务给子 Agent。
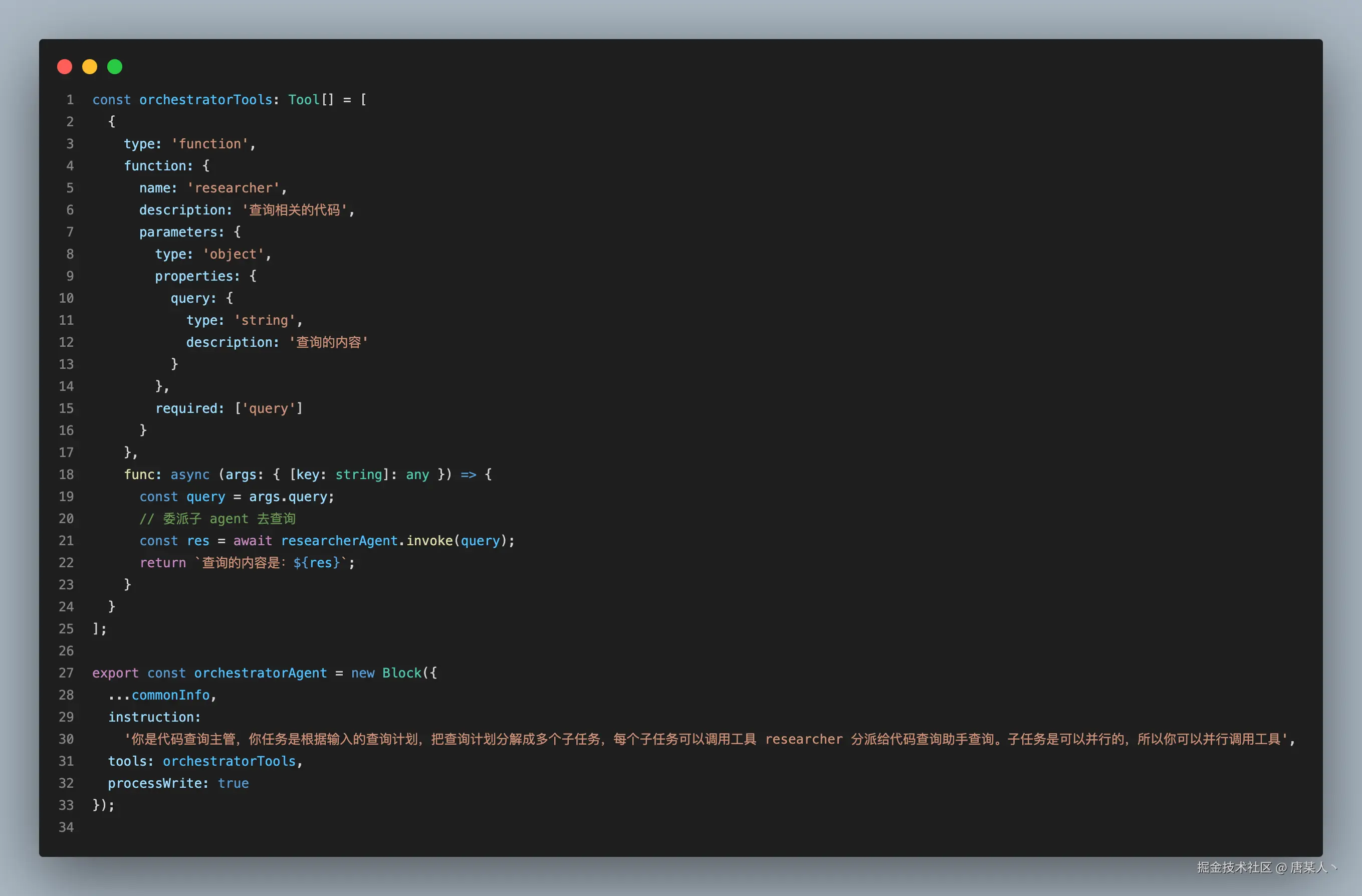
先实现一个协调器 Agent,它的任务是基于用户输入的计划拆分为多个子任务,并通过工具并行触发多个子 Agent 的流程
 然后创建子 Agent
然后创建子 Agent
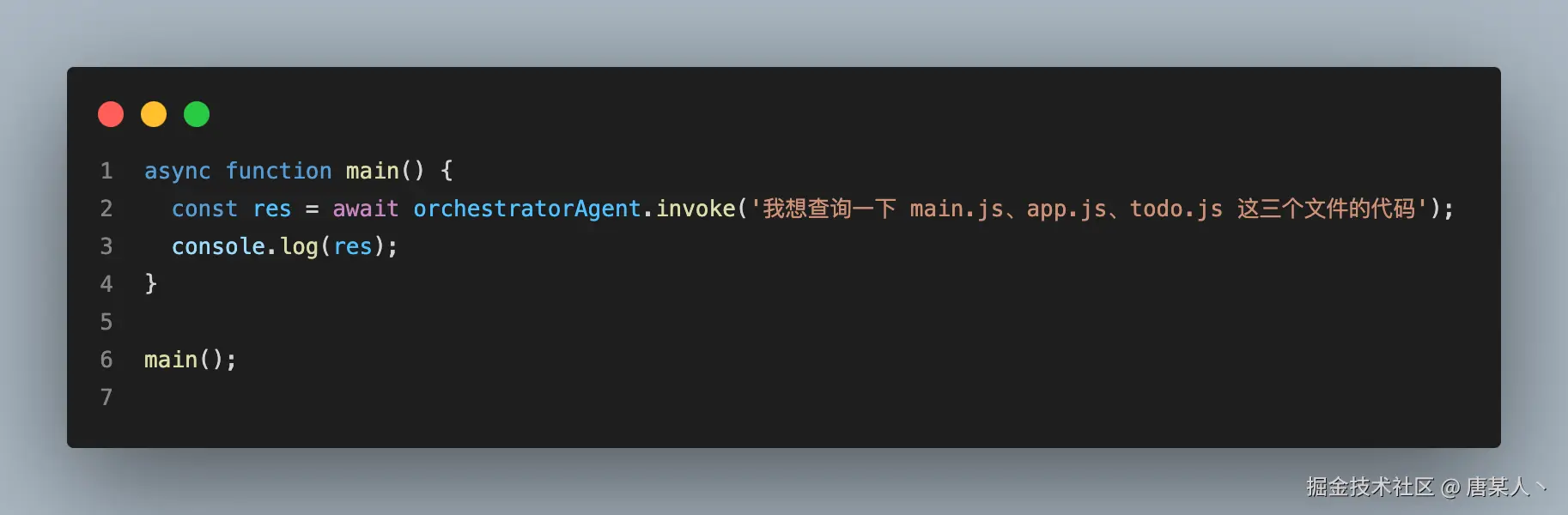
 最后在执行的时候,它就分派三个查询任务给子 Agent
最后在执行的时候,它就分派三个查询任务给子 Agent
 Anthropic 对这种工作流的点评是:
Anthropic 对这种工作流的点评是:
When to use this workflow: This workflow is well-suited for complex tasks where you can’t predict the subtasks needed (in coding, for example, the number of files that need to be changed and the nature of the change in each file likely depend on the task). Whereas it’s topographically similar, the key difference from parallelization is its flexibility—subtasks aren't pre-defined, but determined by the orchestrator based on the specific input.
何时使用此工作流程: 此工作流程非常适合那些无法预测所需子任务的复杂任务(例如,在编码中,需要更改的文件数量以及每个文件中更改的性质可能取决于任务本身)。尽管它在形式上与并行处理相似,但与并行处理的关键区别在于其灵活性——子任务不是预先定义的,而是由协调器根据特定输入来确定。
Evaluator-optimizer
在评估器-优化器工作流程中,一个大语言模型调用生成回复,而另一个则在循环中提供评估和反馈。
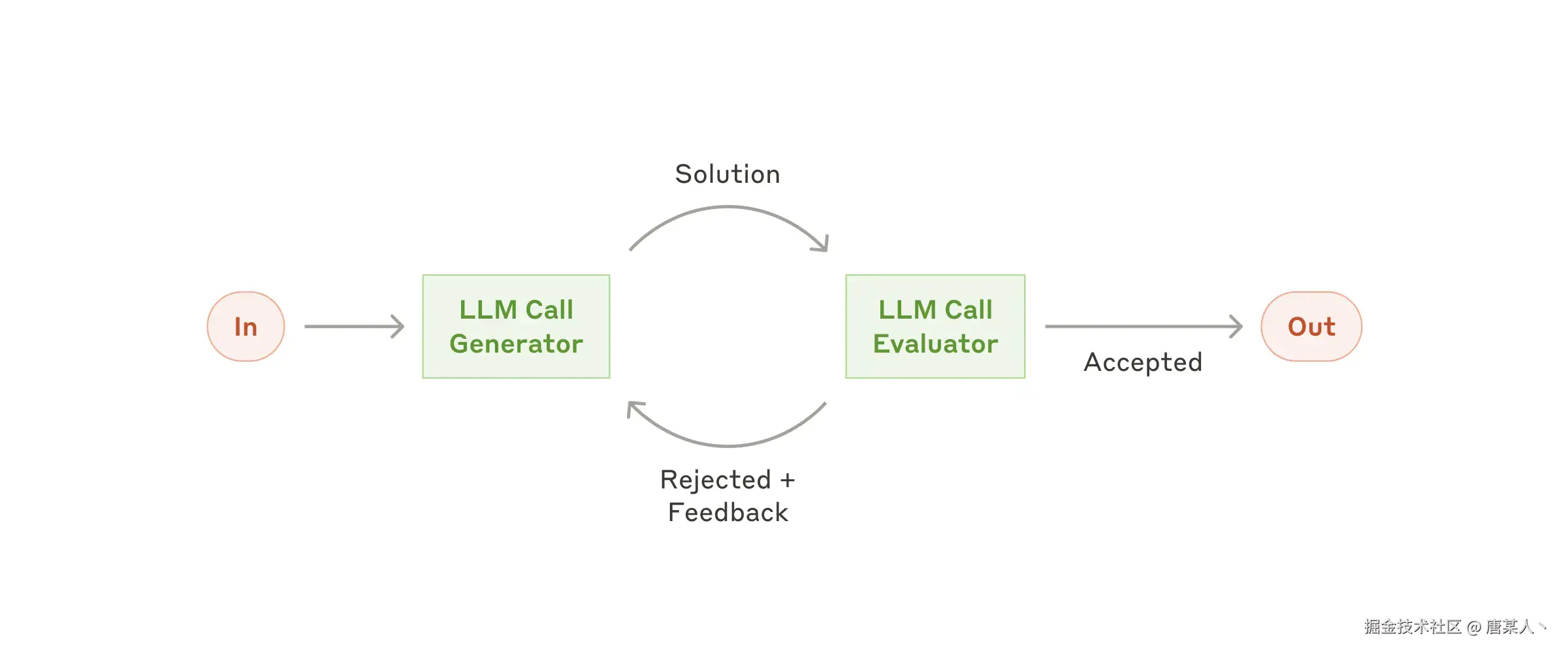
When to use this workflow: This workflow is particularly effective when we have clear evaluation criteria, and when iterative refinement provides measurable value. The two signs of good fit are, first, that LLM responses can be demonstrably improved when a human articulates their feedback; and second, that the LLM can provide such feedback. This is analogous to the iterative writing process a human writer might go through when producing a polished document.
何时使用此工作流程: 当我们有明确的评估标准,且迭代优化能带来可衡量的价值时,此工作流程尤为有效。适用的两个标志是:其一,当人类阐明反馈时,大语言模型(LLM)的回复能得到明显改进;其二,大语言模型能够提供此类反馈。这类似于人类作者在撰写一篇精良文档时可能经历的迭代写作过程。
4.3 小结
这里我再来小结一下关于 Workflow 的主要内容:
-
Workflow 的定义:Workflow 是按照固定、可控的方式组织LLM节点和运行逻辑的设计模式,其核心要素包括LLM节点和代码控制的运行逻辑。
-
Workflow的核心要素:Workflow的核心要素包括LLM节点和代码控制的运行逻辑。LLM节点是构成Workflow的基本单元,负责执行具体的任务;代码控制的运行逻辑则负责定义节点之间的执行顺序和条件。
-
Workflow的设计模式:
- 链模式(Chain):将多个LLM节点按顺序连接起来,依次执行。
- 路由模式(Routing):根据条件判断,将任务路由到不同的LLM节点执行。
- 并行化(Parallelization):将多个LLM节点并行执行,提高效率。
- 编排器-执行器(Orchestrator-workers):将任务分配给多个执行器并行处理,由编排器统一调度和管理。
- 评估模式(Evaluator-optimizer):引入另一个 LLM 节点不断评估改善的模式
六、最后
这一章重点是给大家讲述如何 Agentic System 的理论知识,先让你对 Agent 应用的有一个基本的概念。下一章节,我会给大家分享关于 Agent 目前业界流行的一些设计方案和模式,以及它如何跟 MCP 协作的。