CDE:一次让 Core Data 更像现代 Swift 的尝试
在上一篇文章中,我聊了聊 Core Data 在当下项目中的一些现实处境。在本文中,我将介绍我的一个实验性项目 Core Data Evolution,探索能不能让 Core Data 在现代 Swift 项目中以一种更自然的方式继续存在下去?
在上一篇文章中,我聊了聊 Core Data 在当下项目中的一些现实处境。在本文中,我将介绍我的一个实验性项目 Core Data Evolution,探索能不能让 Core Data 在现代 Swift 项目中以一种更自然的方式继续存在下去?
“全面解析WhatsApp Web抓包:原理、工具与安全”
1. WhatsApp Web的基本原理与架构
WhatsApp Web是WhatsApp的一个网页版应用,它允许用户通过浏览器与手机端的WhatsApp进行同步,实现信息的发送与接收。其基本原理主要依赖于二维码扫描和端到端加密技术。
首先,WhatsApp Web的工作流程始于用户在浏览器中访问WhatsApp Web的官方网站。用户会看到一个二维码,接下来需要用手机上的WhatsApp应用进行扫描。通过扫描二维码,手机端的WhatsApp应用与网页版建立了一个安全的连接。这个二维码实际上包含了一个临时的会话令牌,确保只有经过授权的设备才能访问用户的消息。
WhatsApp Web的架构基于客户端-服务器模型。用户的手机是主要的客户端,负责处理消息的接收和发送,而浏览器则充当另一个客户端。两者之间通过WebSocket协议进行实时通信。WebSocket是一种在单个TCP连接上进行全双工通信的协议,允许数据在客户端与服务器之间快速传输。这种设计的优势在于可以实现即时消息推送,确保用户在网页版上能够及时接收到来自手机端的消息。
在安全性方面,WhatsApp Web采用了端到端加密技术。这意味着消息在发送时会被加密,只有发送者和接收者能够解密查看。这种加密机制确保了即使数据在传输过程中被截获,第三方也无法读取消息内容。此外,WhatsApp Web的连接是基于HTTPS协议的,进一步增强了数据传输的安全性。
除了消息的发送与接收,WhatsApp Web还支持多种功能,包括查看联系人、发送图片和文件、以及进行语音和视频通话等。这些功能的实现同样依赖于与手机端的实时同步,确保用户在不同设备上获得一致的使用体验。
总的来说,WhatsApp Web通过二维码扫描实现设备间的快速连接,利用WebSocket协议实现实时数据传输,并通过端到端加密保障消息的安全性。这种设计不仅提升了用户体验,也确保了用户的隐私安全,为现代通讯方式提供了一个创新的解决方案。
2. 抓包工具的选择与使用方法
抓包工具的选择与使用方法是进行WhatsApp Web分析的关键步骤。首先,常用的抓包工具有Fiddler、Charles Proxy和Wireshark等,这些工具能够帮助用户捕获网络请求并分析数据。 Sniffmaster作为一款全平台抓包工具,支持HTTPS、TCP和UDP协议,可在iOS/Android/Mac/Windows设备上实现无需代理、越狱或root的抓包操作,特别适合移动应用如WhatsApp Web的分析。
在选择工具时,用户需考虑其操作系统的兼容性以及工具的功能特点。例如,Fiddler和Charles Proxy对HTTP/HTTPS流量的支持非常好,适合初学者使用,而Wireshark则适合需要深入分析网络流量的用户,Sniffmaster好上手。
在实际使用过程中,用户需要先配置代理,确保抓包工具能够捕获到WhatsApp Web的流量。在此过程中,注意要能上外网,以便能够顺利连接到WhatsApp的服务器。安装和配置工具后,用户可以通过浏览器访问WhatsApp Web,抓包工具将实时显示网络请求和响应数据,用户可以根据需要分析特定的请求,查看其中的参数和数据内容。这对理解WhatsApp Web的工作原理以及数据传输方式非常有帮助。在进行数据分析时,用户还需关注隐私安全问题,确保不泄露个人信息或敏感数据。在抓包过程中,建议保持对数据的保密性,避免将抓取的数据公开或分享给不信任的第三方。
3. 数据分析与隐私安全的考虑
在进行WhatsApp Web的抓包分析时,数据的隐私安全问题是一个不可忽视的重要方面。随着网络安全威胁的不断增加,用户的个人信息和通信内容面临着潜在的风险。因此,在进行数据分析时,我们需要充分考虑以下几个方面。
首先,抓包过程中获取的数据通常包含用户的消息内容、联系人信息以及媒体文件等敏感数据。这些数据如果落入不法分子之手,可能会导致用户隐私泄露、身份盗窃等严重后果。因此,在使用抓包工具时,务必遵循相关法律法规,确保只在合法范围内进行数据分析,并且要获得相关人员的同意。
其次,进行数据分析时,使用的工具和方法也需谨慎选择。当前市场上存在多种抓包工具,如Fiddler、Charles等,这些工具虽功能强大,但若不加以妥善使用,可能会引发安全隐患。例如,某些抓包工具可能会在未授权的情况下存储用户数据,或是通过不安全的网络传输数据,从而导致数据被窃取。因此,选择可靠的工具,并定期更新其安全补丁,是保护数据安全的有效措施。
然后,在数据分析过程中,建议对敏感信息进行脱敏处理。通过对数据进行加密、匿名化或是只提取必要信息,可以在一定程度上降低数据泄露的风险。同时,分析结果应仅限于内部使用,避免将敏感数据以任何形式公开或分享,确保用户隐私不被侵犯。
此外,用户自身在使用WhatsApp Web时,也应加强安全意识。定期更新密码、启用双重身份验证、避免在公共网络环境下使用WhatsApp Web等都是提升个人信息安全的有效手段。用户应时刻保持警惕,关注账户的异常活动,一旦发现可疑行为,应立即采取措施保护自己的账户安全。
最后,数据分析的结果应有助于提升WhatsApp Web的安全性。通过对抓取的数据进行深入分析,可以识别潜在的安全漏洞和风险点,从而为开发者提供改进产品安全性的依据。这不仅有助于保护用户的隐私安全,也能增强用户对平台的信任,推动整个社交网络环境的健康发展。
综上所述,在进行WhatsApp Web的抓包与数据分析时,隐私安全问题不容忽视。通过合法合规的方式、选择合适的工具、进行数据脱敏处理以及增强用户安全意识,我们能够在享受便捷通信服务的同时,有效保护个人隐私与信息安全。
最近一直在弄一个睡眠记录 App,名字叫
SleepDiary / 睡眠声音日记。
已经上架 App Store 了,直接搜名字可以搜到。
这东西我其实做了挺久了,中间一直在反复改。
最近才慢慢觉得,差不多到了一个能发出来聊聊的阶段。
最开始想做,原因也不复杂。
就是我自己之前看过一些睡眠类产品,总觉得不太顺手。
要么广告很多,要么功能特别杂。
本来只是想看看晚上有没有鼾声、睡得怎么样,结果经常还得被一些很重的流程打断。
所以我做这个的时候,想法一直挺简单的:
打开就能录,醒来能看,别整太复杂。
我自己这段时间已经连续用了很多晚,边用边改。
首页、历史、单晚详情这些地方都来回调了很多次。
尤其是单晚详情,我自己会比较在意。
因为如果只是告诉你“昨晚有鼾声”,其实没什么意思。
但如果能大概看到什么时间段更明显,和整晚记录能对起来,那这个东西至少会更像个能参考的工具。
还有就是,这类 App 本来就比较私人。
毕竟会涉及睡眠、声音这些东西。
所以我自己做的时候,鼾声识别都是用的端侧模型,不会上传。
不一定一步到位,但至少会一直往这个方向抠。
发出来主要也是想看看,这里会不会有人对这种东西有兴趣。
不是想听“看起来不错”这种话,主要还是想知道更实际一点的:
你会不会真的用睡眠记录类 App?
你到底会看什么?
是看单晚,还是看一段时间的变化?
如果是鼾声、梦话这种信息,你会希望它怎么给你看,才算有用?
有想法都可以聊聊。
核心差异:能不能 Strip 未使用代码,静态库 — 链接器只拉入你实际用到的 .o,没用到的直接丢弃:
静态库是在编译链接阶段被完整拷贝到可执行文件中的代码集合。链接完成后,静态库文件本身不再被需要。
文件格式:
.a — 传统静态库(archive 文件,本质是 .o 目标文件的打包).framework — 可以是静态 framework(Xcode 从 iOS 8 起支持)动态库在运行时由动态链接器(dyld)加载到进程地址空间中,不会被拷贝到可执行文件里,而是以独立文件形式存在于 App Bundle 中。
文件格式:
.dylib — 传统动态库(系统库使用,第三方不可提交 App Store).tbd — 动态库的文本描述文件(text-based stub),Xcode 链接系统库时使用.framework — 可以是动态 framework(iOS 8+ 支持嵌入式动态 framework)注意:
.framework本身只是一种打包格式(目录结构),它既可以是静态的也可以是动态的,取决于内部二进制的 Mach-O 类型。
源代码 (.m/.swift)
↓ 编译器 (clang/swiftc)
目标文件 (.o)
↓ 归档工具 (ar)
静态库 (.a)
↓ 链接器 (ld) 将用到的 .o 拷贝进最终二进制
可执行文件 (Mach-O executable)
关键点:
.o 文件链接进来(粒度是 .o,不是函数)-ObjC flag 时会链接所有包含 ObjC 类的 .o(解决 Category 不生效的问题)-all_load 会强制链接所有 .o
-force_load <path> 可以对特定静态库强制全部链接源代码 (.m/.swift)
↓ 编译 + 链接
动态库 (.dylib / .framework)
↓ 嵌入 App Bundle 的 Frameworks/ 目录
↓ 运行时 dyld 加载
进程地址空间
关键点:
dyld 在 App 启动时(或按需 dlopen)将动态库映射到进程地址空间install_name,指示 dyld 去哪里找它install_name 通常是 @rpath/XXX.framework/XXX
┌─────────────────────────────────────────────────────┐
│ 编译期 │
│ │
│ 静态库:代码被拷贝 ──────→ 合并到主二进制 │
│ 动态库:只记录依赖关系 ──→ 主二进制仅保存引用 │
│ │
├─────────────────────────────────────────────────────┤
│ 运行期 │
│ │
│ 静态库:不存在了,代码已在主二进制中 │
│ 动态库:dyld 加载 → rebase → bind → 映射到进程空间 │
│ │
└─────────────────────────────────────────────────────┘
无论静态库还是动态库,最终都与 Mach-O 格式密切相关。
Mach-O 文件结构:
┌──────────────────────┐
│ Header │ ← 魔数、CPU 类型、文件类型
│ │ MH_EXECUTE (可执行文件)
│ │ MH_DYLIB (动态库)
│ │ MH_OBJECT (目标文件,静态库内的 .o)
├──────────────────────┤
│ Load Commands │ ← 描述 segment 布局、依赖的动态库列表、入口点等
│ │ LC_LOAD_DYLIB 记录依赖的动态库
│ │ LC_RPATH 指定运行时搜索路径
├──────────────────────┤
│ __TEXT Segment │ ← 只读:机器码、字符串常量、Swift metadata
├──────────────────────┤
│ __DATA Segment │ ← 可读写:全局变量、ObjC 元数据、GOT (全局偏移表)
├──────────────────────┤
│ __LINKEDIT Segment │ ← 符号表、字符串表、代码签名信息
└──────────────────────┘
静态库(.a)的本质:不是 Mach-O 文件,而是多个 .o(Mach-O Object)的归档包。链接器从中提取需要的 .o 合并到最终的 Mach-O 可执行文件中。
动态库的本质:是一个完整的 Mach-O 文件(类型为 MH_DYLIB),有自己的 Header、Load Commands、Segments,运行时被 dyld 独立加载。
| 维度 | 静态库 | 动态库 |
|---|---|---|
| 链接时机 | 编译期,链接器完成 | 运行期,dyld 完成 |
| 代码位置 | 拷贝进主 Mach-O | 独立文件,位于 .app/Frameworks/
|
| 主二进制大小 | 更大(包含库代码) | 更小(只记录依赖引用) |
| App Bundle 总大小 | 通常更小(Strip 掉未用代码) | 可能更大(整个库都打包) |
| 启动速度 | 快,无额外加载开销 | 慢,dyld 需要 load → rebase → bind |
| 内存 | 每个引用者各有一份拷贝 | 系统库多进程共享;嵌入式库不共享 |
| 符号可见性 | 合并到主二进制的全局符号表 | 保持独立符号表,符号隔离 |
| 符号冲突风险 | 高,容易 duplicate symbols | 低,各库符号空间独立 |
| ObjC Category | 需 -ObjC flag 才能加载 |
自动加载 |
| 链接时优化 (LTO) | 支持,编译器可跨库优化 | 不支持,库边界是优化屏障 |
| 增量编译 | 改库需重新链接整个 App | 改库只需重编该库 |
| 代码签名 | 无需单独签名 | 每个动态库需独立签名 |
| Xcode 配置 | Do Not Embed | Embed & Sign |
pre-main 阶段零额外开销.o,未用代码不会进入最终二进制dylib not found / image not found 崩溃duplicate symbol 错误.framework 文件即可更新逻辑(App Store 不允许,仅企业包/调试可用)dlopen App Bundle 外的动态库App 进程创建
↓
1. Load dylibs 递归加载主二进制依赖的所有动态库(及其传递依赖)
↓ 每个库:mmap 到虚拟内存 → 验证签名 → 注册
2. Rebase ASLR (地址空间布局随机化) 导致实际加载地址与编译地址不同
↓ 遍历所有内部指针,加上随机偏移量 (slide)
3. Bind 解析跨库的外部符号引用
↓ lazy binding: 首次调用时才解析(大部分函数)
↓ non-lazy binding: 启动时立即解析(ObjC 元数据、C++ 虚表)
4. ObjC Runtime Setup 注册所有 ObjC 类到 runtime
↓ 插入 Category 的方法到类的方法列表
↓ 确保 selector 唯一性
5. Initializers 执行 +load 方法
↓ 执行 C/C++ __attribute__((constructor))
↓ 执行 Swift 全局变量的初始化器
↓
main() 被调用
| 阶段 | 耗时原因 | 与动态库数量的关系 |
|---|---|---|
| Load | 磁盘 I/O + 签名验证 | 线性正相关,库越多越慢 |
| Rebase | 遍历 __DATA 段所有内部指针 |
与库的数据段大小相关 |
| Bind | 符号查找(哈希表查询) | 与跨库符号引用数量相关 |
| ObjC Setup | 类注册 + Category 合并 | 与 ObjC 类/Category 总数相关 |
| Initializers | 执行用户代码 | 与 +load 和 constructor 数量相关 |
| 特性 | dyld 2 (iOS 12 及以前) | dyld 3 (iOS 13+) |
|---|---|---|
| 解析时机 | 每次启动都在进程内完整解析 | 首次解析后缓存为 launch closure |
| 安全性 | 在 App 进程内解析(可被攻击) | 解析移到进程外守护进程 |
| 缓存 | 无 | closure 缓存后,后续启动跳过解析 |
| 冷启动 | 慢 | 首次略慢(多了写缓存),后续显著加速 |
| 热启动 | 中等 | 直接读取 closure,非常快 |
| 动态库数量 | 大致额外 pre-main 耗时 (iPhone 8 级别) |
|---|---|
| 1-5 个 | ~5-20ms |
| 10-20 个 | ~50-150ms |
| 50+ 个 | ~300ms+ |
| 100+ 个 | 可能超过 400ms watchdog 阈值 (冷启动) |
Apple 官方建议:嵌入式动态 framework 控制在 6 个以内。
静态库的代码在编译期已经合并进主二进制:
Load dylibs 的数量Bind 的符号数量mmap 主二进制的时间微增(可忽略)主程序引用 _doSomething (未定义符号 U)
↓
链接器在静态库中搜索
↓
找到 MyModule.o 中定义了 _doSomething (符号类型 T)
↓
将整个 MyModule.o 拷贝进主二进制
↓
符号变为已定义 (resolved)
.o 文件:即使只用了 .o 中的一个函数,整个 .o 都会被链接.m 文件中,以减少无用代码主程序引用 _doSomething (标记为 external, lazy)
↓
编译时:链接器确认动态库中存在该符号 → 通过
↓
运行时:首次调用 _doSomething
↓
dyld 在动态库的符号表中查找 → 写入 GOT/lazy pointer
↓
后续调用直接走 GOT,无需再次查找
__DATA 段指针等在启动时立即解析静态库:同名符号 → duplicate symbol 编译错误(严格)
ld: duplicate symbol '_MyFunction' in:
libA.a(module.o)
libB.a(module.o)
动态库:同名符号 → 运行时 "先加载者胜"(flat namespace)或各自独立(two-level namespace,iOS 默认)
Two-Level Namespace (iOS 默认):
调用 libA 的 _MyFunction → 解析到 libA 内部
调用 libB 的 _MyFunction → 解析到 libB 内部
不会混淆
┌─────────── 静态库场景 ──────────────┐
│ │
│ App 进程内存: │
│ ┌──────────────────┐ │
│ │ 主二进制 (__TEXT) │ ← 含库A代码 │
│ │ 主二进制 (__DATA) │ ← 含库A数据 │
│ └──────────────────┘ │
│ │
│ Extension 进程内存: │
│ ┌──────────────────┐ │
│ │ Extension (__TEXT) │ ← 又一份库A │
│ │ Extension (__DATA) │ ← 又一份库A │
│ └──────────────────┘ │
│ │
│ → 库A代码存在两份 (磁盘 + 内存) │
└────────────────────────────────────┘
┌─────────── 动态库场景 ──────────────┐
│ │
│ App 进程内存: │
│ ┌──────────────────┐ │
│ │ 主二进制 │ │
│ │ 库A.framework │ ←──┐ __TEXT │
│ └──────────────────┘ │ 页共享 │
│ │ │
│ Extension 进程内存: │ │
│ ┌──────────────────┐ │ │
│ │ Extension │ │ │
│ │ 库A.framework │ ←──┘ 同一物理页│
│ └──────────────────┘ │
│ │
│ → __TEXT 段可跨进程共享物理内存页 │
│ → __DATA 段每个进程各自 copy-on-write│
└────────────────────────────────────┘
| 因素 | 静态库 | 动态库 |
|---|---|---|
| 未使用代码 | 链接器丢弃未引用的 .o
|
整个库都打进 Bundle |
| LTO 死代码消除 | 支持,可消除未使用的函数 | 不支持跨库消除 |
| 多 Target 场景 | 代码重复(每个 Target 一份) | 代码只存一份 |
| Strip | 链接后可全局 Strip | 只能 Strip 库自身的调试符号 |
| 压缩 (App Thinning) | 主二进制参与整体压缩 | 每个 framework 独立压缩 |
| 维度 | 胜出方 | 说明 |
|---|---|---|
| 启动速度 | 静态库 | 不增加 dyld 加载开销 |
| 包体积 (单 Target) | 静态库 | 死代码消除 + LTO 优化 |
| 包体积 (多 Target) | 动态库 | 代码共享避免重复 |
| 编译速度 | 动态库 | 增量编译不影响主二进制 |
| 符号安全 | 动态库 | Two-Level Namespace 隔离 |
| 运行时稳定性 | 静态库 | 无 image not found 风险 |
| 部署复杂度 | 静态库 | 无需管签名和 Embed |
| 代码优化程度 | 静态库 | 支持跨库 LTO |
核心原则:除非有明确的跨 Target 代码共享需求(如 App Extension),否则优先选择静态库。iOS 嵌入式动态库不具备系统级共享优势,带来的启动开销往往得不偿失。
matrix 是腾讯微信团队开源的一套移动端性能监控与分析框架,核心目标是帮助开发者定位、解决移动端(iOS/Android)应用的性能问题,是微信内部大规模验证过的成熟工具,本文通过阅读源码,详细介绍了针对卡顿日志获取的核心原理。
Matrix 通过周期性采集主线程堆栈并保存在循环数组中,在检测到卡顿时,使用 Point Stack 算法找出最有可能导致卡顿的堆栈。
时间流逝
↓
每 50ms 采集一次主线程堆栈
↓
保存到循环数组(固定大小,如 20 个)
↓
检测到卡顿时
↓
分析循环数组,找出 Point Stack(最可能导致卡顿的堆栈)
↓
生成卡顿报告
| 目标 | 实现方式 |
|---|---|
| 及时性 | 每 50ms 采集一次,不错过卡顿过程 |
| 完整性 | 保存一个周期内的所有堆栈(通常 20 个) |
| 准确性 | 通过算法找出真正导致卡顿的堆栈 |
| 高效性 | 固定大小循环数组,避免内存膨胀 |
| 低开销 | CPU 占用 < 3%,不影响用户体验 |
// 1. RunLoop 超时阈值(卡顿判定阈值)
static useconds_t g_RunLoopTimeOut = 2000000; // 2000ms = 2秒
// 作用:超过此时间判定为卡顿
// 2. 检查周期(单次采集周期)
static useconds_t g_CheckPeriodTime = 1000000; // 1000ms = 1秒
// 作用:一轮堆栈采集的总时间,通常为超时阈值的一半
// 3. 堆栈采集间隔
static useconds_t g_PerStackInterval = 50000; // 50ms
// 作用:每次堆栈采集之间的时间间隔
┌────────────────────────────────────────────────┐
│ g_RunLoopTimeOut (2秒) - 卡顿判定阈值 │
└────────────────────────────────────────────────┘
│
├─ 一半
↓
┌────────────────────────────────────────────────┐
│ g_CheckPeriodTime (1秒) - 检查周期 │
└────────────────────────────────────────────────┘
│
├─ 除以
↓
┌────────────────────────────────────────────────┐
│ g_PerStackInterval (50ms) - 堆栈间隔 │
└────────────────────────────────────────────────┘
↓
┌────────────────────────────────────────────────┐
│ g_MainThreadCount = 1000ms / 50ms = 20 │
│ (循环数组大小 = 一个周期内采集的堆栈数量) │
└────────────────────────────────────────────────┘
时间线(以2秒卡顿为例):
T=0ms 开始监控
|
T=50ms 采集第1个堆栈 ← S0
|
T=100ms 采集第2个堆栈 ← S1
|
T=150ms 采集第3个堆栈 ← S2
|
...
|
T=950ms 采集第19个堆栈 ← S18
|
T=1000ms 采集第20个堆栈 ← S19 ← 完成一轮采集
| ↓
| 检查是否卡顿(检查RunLoop执行时间)
| 如果未卡顿,进入下一轮采集
|
T=1050ms 采集第21个堆栈 ← S20(覆盖S0)
|
...
|
T=2000ms 检查发现 RunLoop 执行超过 2秒
| ↓
| 触发卡顿检测
| ↓
| 分析循环数组中的 20 个堆栈
| ↓
| 找出 Point Stack(最可能导致卡顿的堆栈)
| ↓
| 生成卡顿报告
┌──────────────────────────────────────────┐
│ 监控线程主循环 │
│ while (YES) { │
│ check(); // 检测卡顿 │
│ recordCurrentStack(); // 采集堆栈 │
│ } │
└──────────────────────────────────────────┘
↓
┌──────────────────────────────────────────┐
│ recordCurrentStack() 方法 │
│ │
│ 外层循环:遍历检查周期 │
│ nTotalCnt = m_nIntervalTime / │
│ g_CheckPeriodTime │
│ 通常 = 1000ms / 1000ms = 1次 │
│ │
│ 内层循环:在一个周期内多次采集 │
│ intervalCount = g_CheckPeriodTime / │
│ g_PerStackInterval │
│ 通常 = 1000ms / 50ms = 20次 │
│ │
│ 每次循环: │
│ 1. usleep(50ms) // 等待 │
│ 2. 获取主线程堆栈 │
│ 3. 添加到循环数组 │
└──────────────────────────────────────────┘
// 在 WCBlockMonitorMgr 的 start 方法中
- (void)start {
// 计算循环数组大小
g_MainThreadCount = g_CheckPeriodTime / g_PerStackInterval;
// 例如:1000ms / 50ms = 20
// 创建主线程堆栈处理器
m_pointMainThreadHandler = [[WCMainThreadHandler alloc]
initWithCycleArrayCount:g_MainThreadCount];
// g_MainThreadCount = 20
// 意味着循环数组可以保存 20 个堆栈
}
- (void)recordCurrentStack {
// ================================================================
// 外层循环:决定执行几个检查周期
// ================================================================
// 正常情况:m_nIntervalTime = 1000ms
// 退火情况:m_nIntervalTime = 2000ms, 3000ms, 5000ms...
unsigned long nTotalCnt = m_nIntervalTime / g_CheckPeriodTime;
for (int nCnt = 0; nCnt < nTotalCnt && !m_bStop; nCnt++) {
// 记录本轮开始时间(用于检测系统挂起)
gettimeofday(&m_recordStackTime, NULL);
if (g_MainThreadHandle) {
// ========================================================
// 内层循环:在一个检查周期内多次采集
// ========================================================
// intervalCount = 1000ms / 50ms = 20
int intervalCount = g_CheckPeriodTime / g_PerStackInterval;
for (int index = 0; index < intervalCount && !m_bStop; index++) {
// 1️⃣ 等待 50ms
usleep(g_PerStackInterval); // 50000 微秒 = 50ms
// 2️⃣ 分配内存
size_t stackBytes = sizeof(uintptr_t) * g_StackMaxCount;
uintptr_t *stackArray = (uintptr_t *)malloc(stackBytes);
if (stackArray == NULL) {
continue; // 内存分配失败,跳过本次
}
// 3️⃣ 初始化
__block size_t nSum = 0;
memset(stackArray, 0, stackBytes);
// 4️⃣ 获取主线程堆栈
[WCGetMainThreadUtil
getCurrentMainThreadStack:^(NSUInteger pc) {
stackArray[nSum] = (uintptr_t)pc; // 保存程序计数器
nSum++;
}
withMaxEntries:g_StackMaxCount // 最大100个栈帧
withThreadCount:g_CurrentThreadCount];
// 5️⃣ 添加到循环数组
[m_pointMainThreadHandler addThreadStack:stackArray
andStackCount:nSum];
// 注意:stackArray 的所有权转移给 m_pointMainThreadHandler
}
}
// ============================================================
// 检测是否被系统挂起
// ============================================================
struct timeval tvCur;
gettimeofday(&tvCur, NULL);
unsigned long long diff = [WCBlockMonitorMgr diffTime:&m_recordStackTime
endTime:&tvCur];
if (diff > DETECTION_THREAD_JUDGE_SUSPEND_THRESHOLD) {
// 实际消耗时间 > 10秒,说明被挂起了
gettimeofday(&g_tvRun, NULL); // 更新时间,避免误报
MatrixInfo(@"挂起后运行,差值 %llu", diff);
return;
}
}
}
// WCGetMainThreadUtil 内部使用 backtrace
+ (void)getCurrentMainThreadStack:(StackCallback)callback
withMaxEntries:(size_t)maxEntries
withThreadCount:(NSUInteger)threadCount {
// 1. 获取主线程
thread_t mainThread = pthread_mach_thread_np(pthread_main_thread_np());
// 2. 暂停主线程(非常短暂,微秒级)
thread_suspend(mainThread);
// 3. 获取线程状态
_STRUCT_MCONTEXT machineContext;
mach_msg_type_number_t state_count = THREAD_STATE_COUNT;
kern_return_t kr = thread_get_state(mainThread,
THREAD_STATE,
(thread_state_t)&machineContext.__ss,
&state_count);
// 4. 回溯堆栈
if (kr == KERN_SUCCESS) {
uintptr_t backtraceBuffer[maxEntries];
size_t backtraceLength = ksbt_backtraceLength(&machineContext);
// 遍历堆栈帧
for (size_t i = 0; i < backtraceLength && i < maxEntries; i++) {
uintptr_t pc = ksbt_framePointer(&machineContext, i);
callback(pc); // 回调传递每个栈帧的地址
}
}
// 5. 恢复主线程
thread_resume(mainThread);
}
@interface WCMainThreadHandler {
// ================================================================
// 循环数组配置
// ================================================================
int m_cycleArrayCount; // 数组大小,例如 20
// ================================================================
// 循环数组(核心存储结构)
// ================================================================
uintptr_t **m_mainThreadStackCycleArray; // 二维数组
// 第一维:堆栈索引 [0, 19]
// 第二维:堆栈地址数组 uintptr_t[]
size_t *m_mainThreadStackCount; // 每个堆栈的深度
// 例如:[50, 48, 52, ..., 45]
uint64_t m_tailPoint; // 尾指针,指向下一个写入位置
// ================================================================
// 分析数据(用于 Point Stack 算法)
// ================================================================
size_t *m_topStackAddressRepeatArray; // 栈顶地址连续重复次数
// 例如:[0, 1, 2, 0, 1, 0, ...]
int *m_mainThreadStackRepeatCountArray; // Point Stack 地址总重复次数
// 动态分配,在找到 Point Stack 后创建
}
初始化状态(m_cycleArrayCount = 5):
索引: 0 1 2 3 4
┌─────┬─────┬─────┬─────┬─────┐
数组: │NULL │NULL │NULL │NULL │NULL │
└─────┴─────┴─────┴─────┴─────┘
↑
m_tailPoint = 0
添加第 1 个堆栈(S0):
索引: 0 1 2 3 4
┌─────┬─────┬─────┬─────┬─────┐
数组: │ S0 │NULL │NULL │NULL │NULL │
└─────┴─────┴─────┴─────┴─────┘
↑
m_tailPoint = 1
添加第 2-5 个堆栈:
索引: 0 1 2 3 4
┌─────┬─────┬─────┬─────┬─────┐
数组: │ S0 │ S1 │ S2 │ S3 │ S4 │
└─────┴─────┴─────┴─────┴─────┘
↑
m_tailPoint = 0 (回绕)
添加第 6 个堆栈(S5,覆盖 S0):
索引: 0 1 2 3 4
┌─────┬─────┬─────┬─────┬─────┐
数组: │ S5 │ S1 │ S2 │ S3 │ S4 │
└─────┴─────┴─────┴─────┴─────┘
↑
m_tailPoint = 1
时间顺序:S1 → S2 → S3 → S4 → S5(最新)
- (void)addThreadStack:(uintptr_t *)stackArray
andStackCount:(size_t)stackCount {
if (stackArray == NULL) {
return;
}
pthread_mutex_lock(&m_threadLock);
// ================================================================
// 1. 将堆栈写入循环数组
// ================================================================
// 如果当前位置已有堆栈,先释放旧的
if (m_mainThreadStackCycleArray[m_tailPoint] != NULL) {
free(m_mainThreadStackCycleArray[m_tailPoint]);
}
// 保存新堆栈
m_mainThreadStackCycleArray[m_tailPoint] = stackArray;
m_mainThreadStackCount[m_tailPoint] = stackCount;
// ================================================================
// 2. 统计栈顶地址连续重复次数(核心!)
// ================================================================
// 计算上一个位置的索引
uint64_t lastTailPoint = (m_tailPoint + m_cycleArrayCount - 1) % m_cycleArrayCount;
// 获取上一个堆栈的栈顶地址
uintptr_t lastTopStack = 0;
if (m_mainThreadStackCycleArray[lastTailPoint] != NULL) {
lastTopStack = m_mainThreadStackCycleArray[lastTailPoint][0];
}
// 获取当前堆栈的栈顶地址
uintptr_t currentTopStackAddr = stackArray[0];
// 比较栈顶地址
if (lastTopStack == currentTopStackAddr) {
// 栈顶地址相同,累加重复次数
size_t lastRepeatCount = m_topStackAddressRepeatArray[lastTailPoint];
m_topStackAddressRepeatArray[m_tailPoint] = lastRepeatCount + 1;
} else {
// 栈顶地址不同,重置重复次数
m_topStackAddressRepeatArray[m_tailPoint] = 0;
}
// ================================================================
// 3. 移动尾指针
// ================================================================
m_tailPoint = (m_tailPoint + 1) % m_cycleArrayCount;
pthread_mutex_unlock(&m_threadLock);
}
假设连续采集到以下堆栈(简化为栈顶地址):
时间: T0 T50 T100 T150 T200 T250 T300 T350 T400
索引: 0 1 2 3 4 5 6 7 8
堆栈: S0 S1 S2 S3 S4 S5 S6 S7 S8
栈顶: A B C C C C C D D
m_topStackAddressRepeatArray 的值:
[0, 0, 0, 1, 2, 3, 4, 0, 1]
↑ ↑ ↑ ↑ ↑ ↑ ↑ ↑ ↑
A B C C重 C重 C重 C重 D D重
首次 首次 首次 复2 复3 复4 复5 首次 复2
分析:
- S6(索引6)的栈顶地址 C 连续重复了 4 次(从 S2 到 S6)
- 说明主线程在函数 C 上停留了 5 × 50ms = 250ms
- S6 就是最有可能导致卡顿的堆栈(Point Stack)
Point Stack(关键堆栈) 是指在一个检查周期内,最有可能导致卡顿的主线程堆栈。
| 变量名 | 类型 | 说明 |
|---|---|---|
m_cycleArrayCount |
int |
循环数组大小(例如:20) |
m_tailPoint |
uint64_t |
循环数组尾指针,指向下一个写入位置 |
pthread_mutex_t |
m_threadLock |
线程锁,保护循环数组的并发访问 |
循环数组原理:
数组大小 = 检查周期 / 堆栈间隔
例如:1000ms / 50ms = 20
索引: 0 1 2 3 4 ... 19
┌────┬────┬────┬────┬────┬ ─ ─ ┬────┐
堆栈: │ S0 │ S1 │ S2 │ │ │ │ │
└────┴────┴────┴─▲──┴────┴ ─ ─ ┴────┘
│
m_tailPoint
当数组满时,从头开始覆盖(FIFO)
| 变量名 | 类型 | 维度 | 说明 |
|---|---|---|---|
m_mainThreadStackCycleArray |
uintptr_t ** |
[cycleArrayCount][stackDepth] | 堆栈地址二维数组 |
m_mainThreadStackCount |
size_t * |
[cycleArrayCount] | 每个堆栈的深度数组 |
数据结构示意:
m_mainThreadStackCycleArray:
[0] → [0x1000, 0x2000, 0x3000, ...] // 第0个堆栈,深度=3
[1] → [0x1000, 0x2000, 0x3000, ...] // 第1个堆栈,深度=3
[2] → [0x1000, 0x2000, 0x4000, ...] // 第2个堆栈,深度=3
...
[19] → NULL // 尚未写入
m_mainThreadStackCount:
[0] = 3 // 第0个堆栈深度
[1] = 3 // 第1个堆栈深度
[2] = 3 // 第2个堆栈深度
...
[19] = 0 // 尚未写入
| 变量名 | 类型 | 说明 |
|---|---|---|
m_topStackAddressRepeatArray |
size_t * |
每个堆栈的栈顶地址连续重复次数 |
用途: 找出 Point Stack(栈顶重复次数最多的堆栈)
数据示例:
假设连续采集的堆栈栈顶地址:
索引: 0 1 2 3 4
栈顶: A A A B B
m_topStackAddressRepeatArray:
[0] [1] [2] [3] [4]
0 1 2 0 1
解释:
- 索引0: 第一次出现A,重复0次
- 索引1: 第二次出现A(与前一个相同),重复1次
- 索引2: 第三次出现A(与前一个相同),重复2次
- 索引3: 出现B(改变了),重复0次
- 索引4: 第二次出现B(与前一个相同),重复1次
结果:索引2的重复次数最多(2次),所以索引2是Point Stack
| 变量名 | 类型 | 说明 |
|---|---|---|
m_mainThreadStackRepeatCountArray |
int * |
Point Stack中每个地址的总重复次数(动态分配) |
用途: 统计 Point Stack 中每个地址在所有堆栈中的总出现次数,识别热点函数
数据示例:
假设有4个堆栈,Point Stack是索引2:
Stack 0: Stack 1: Stack 2(Point): Stack 3:
0x1000 0x1000 0x1000 0x1000
0x2000 0x2000 0x2000 0x2000
0x3000 0x3000 0x3000 0x4000
0x4000 0x5000 0x6000
Point Stack (索引2) 的地址:
[0] = 0x1000
[1] = 0x2000
[2] = 0x3000
统计结果 m_mainThreadStackRepeatCountArray:
[0] = 4 // 0x1000 在4个堆栈中都出现
[1] = 4 // 0x2000 在4个堆栈中都出现
[2] = 3 // 0x3000 在3个堆栈中出现
符号化后:
[0] main (4次) ← 所有堆栈都有,基础函数
[1] viewDidLoad (4次) ← 所有堆栈都有,入口函数
[2] heavyWork (3次) ← 75%的时间在这里,瓶颈!⚠️
开始
↓
1. 查找最大重复次数
↓
2. 按时间顺序找出第一个等于最大值的堆栈索引
↓
3. 复制 Point Stack
↓
4. 计算 Point Stack 中每个地址的总重复次数
↓
5. 创建 KSStackCursor 并返回
↓
结束
目的: 找出 m_topStackAddressRepeatArray 中的最大值。
size_t maxValue = 0;
BOOL trueStack = NO;
// 第一次遍历:只找最大值(不记录索引)
for (int i = 0; i < m_cycleArrayCount; i++) {
size_t currentValue = m_topStackAddressRepeatArray[i];
if (currentValue >= maxValue) {
maxValue = currentValue;
trueStack = YES;
}
}
if (!trueStack) {
return NULL; // 没有有效堆栈
}
目的: 按时间顺序(从新到旧)找第一个重复次数等于 maxValue 的堆栈。
size_t currentIndex = (m_tailPoint + m_cycleArrayCount - 1) % m_cycleArrayCount;
// 第二次遍历:按时间顺序(从新到旧)
for (int i = 0; i < m_cycleArrayCount; i++) {
// 计算真实索引
int trueIndex = (m_tailPoint + m_cycleArrayCount - i - 1) % m_cycleArrayCount;
// 找到第一个等于最大值的
if (m_topStackAddressRepeatArray[trueIndex] == maxValue) {
currentIndex = trueIndex;
break; // 找到最新的,立即停止
}
}
索引计算公式:
trueIndex = (m_tailPoint + m_cycleArrayCount - i - 1) % m_cycleArrayCount
参数说明:
- m_tailPoint: 下一个要写入的位置
- i: 遍历变量(0 = 最新,1 = 次新,...)
- m_cycleArrayCount: 数组大小(如20)
例子:
假设 m_tailPoint = 1, m_cycleArrayCount = 5
i=0: trueIndex = (1+5-0-1) % 5 = 0 → 最新堆栈
i=1: trueIndex = (1+5-1-1) % 5 = 4 → 次新堆栈
i=2: trueIndex = (1+5-2-1) % 5 = 3 → 第三新堆栈
i=3: trueIndex = (1+5-3-1) % 5 = 2 → 第四新堆栈
i=4: trueIndex = (1+5-4-1) % 5 = 1 → 最旧堆栈(空)
size_t stackCount = m_mainThreadStackCount[currentIndex];
size_t pointThreadSize = sizeof(uintptr_t) * stackCount;
uintptr_t *pointThreadStack = (uintptr_t *)malloc(pointThreadSize);
// 复制堆栈地址
for (size_t idx = 0; idx < stackCount; idx++) {
pointThreadStack[idx] = m_mainThreadStackCycleArray[currentIndex][idx];
}
三层循环统计:
// 分配重复次数数组
m_mainThreadStackRepeatCountArray = (int *)malloc(stackCount * sizeof(int));
memset(m_mainThreadStackRepeatCountArray, 0, stackCount * sizeof(int));
// 外层循环:遍历 Point Stack 的每个地址
for (size_t i = 0; i < stackCount; i++) {
uintptr_t targetAddress = m_mainThreadStackCycleArray[currentIndex][i];
// 中层循环:遍历循环数组中的每个堆栈
for (int innerIndex = 0; innerIndex < m_cycleArrayCount; innerIndex++) {
size_t innerStackCount = m_mainThreadStackCount[innerIndex];
// 内层循环:遍历当前堆栈的每个地址
for (size_t idx = 0; idx < innerStackCount; idx++) {
// 比较是否匹配
if (targetAddress == m_mainThreadStackCycleArray[innerIndex][idx]) {
m_mainThreadStackRepeatCountArray[i] += 1;
}
}
}
}
算法分析:
KSStackCursor *pointCursor = (KSStackCursor *)malloc(sizeof(KSStackCursor));
kssc_initWithBacktrace(pointCursor, pointThreadStack, (int)stackCount, 0);
return pointCursor;
作用: 将原始堆栈数组包装成 KSCrash 能使用的标准格式。
至于堆栈的获取,可以参考我的另一篇文章ARM64 调用栈回溯原理
随着智能手机的普及,移动应用程序(App)已经成为人们日常生活中必不可少的一部分。而将自己的App上架到应用商店则是许多开发者的梦想,因为这意味着他们的作品可以被更多人看到、下载和使用。本文将介绍App上架到应用商店的原理和详细步骤。
一、App上架的原理
App上架到应用商店的原理可以简单概括为:开发者将开发好的App上传到应用商店,应用商店审核通过后将App发布到应用商店。在这个过程中,开发者需要遵守应用商店的规定和要求,以确保App能够通过审核并成功上架。
具体来说,开发者需要准备好以下内容:
应用商店账号:开发者需要在目标应用商店注册一个账号,并遵守该应用商店的规定和要求。
App信息:开发者需要提供App的名称、描述、图标、版本号、支持的设备类型等信息。
App安装包:开发者需要将App打包成符合应用商店要求的安装包,并上传到应用商店。对于iOS应用,可以使用AppUploader等工具在Windows、Linux或Mac系统中上传IPA文件到App Store,无需Mac电脑即可操作,比传统方法更高效。
证书和签名:开发者需要使用证书和签名对App进行加密和验证,以确保App的安全性和可靠性。使用工具如AppUploader可以简化iOS证书的申请和签名过程,支持多电脑协同,无需钥匙串助手。
测试和调试:开发者需要对App进行测试和调试,以确保App的质量和稳定性。
二、App上架的详细步骤
开发者需要在目标应用商店注册一个账号,以便上传App和管理App的信息。不同的应用商店可能有不同的注册流程和要求,开发者需要仔细阅读应用商店的注册指南,并提供必要的信息和证明文件。
开发者需要准备好App的名称、描述、图标、版本号、支持的设备类型等信息。这些信息将在应用商店中展示,并影响用户对App的印象和选择。
开发者需要将App打包成符合应用商店要求的安装包,并上传到应用商店。不同的应用商店可能有不同的安装包要求,开发者需要仔细阅读应用商店的指南,并使用合适的工具和方法进行打包。AppUploader支持快速上传IPA文件,并内置工具查看和编辑相关文件内容。
开发者需要使用证书和签名对App进行加密和验证,以确保App的安全性和可靠性。证书和签名的获取和使用也可能因应用商店的不同而有所差异,开发者需要仔细阅读应用商店的指南,并按照要求进行操作。利用AppUploader,开发者可以直接创建和管理iOS证书,简化流程。
开发者需要对App进行测试和调试,以确保App的质量和稳定性。测试和调试的过程可能会涉及多个设备和操作系统,开发者需要尽可能模拟用户的使用场景,并记录和解决问题。AppUploader提供USB和二维码安装测试功能,方便在iOS设备上验证应用。
开发者需要将准备好的App信息、安装包、证书和签名上传到应用商店,并提交审核。审核的过程可能需要几天甚至几周的时间,开发者需要耐心等待,并及时响应应用商店的反馈和要求。
审核通过后,应用商店会将App发布到应用商店,供用户下载和使用。开发者需要及时更新App的信息和版本,并处理用户的反馈和问题。
总之,将App上架到应用商店需要开发者投入大量时间和精力,需要遵守应用商店的规定和要求,并保证App的质量和安全性。只有经过认真准备和审核,才能让自己的App在应用商店中脱颖而出,成为用户喜爱的产品。
在终端执行(端口如 7890 按自己改):
export https_proxy=http://127.0.0.1:7890
export http_proxy=http://127.0.0.1:7890
cd /path/to/your/project
xcodebuild -resolvePackageDependencies
错误里会带类似 FloatingPanel-f92b491a 的路径,删掉该缓存再重试:
rm -rf ~/Library/Caches/org.swift.swiftpm/repositories/FloatingPanel-f92b491a
多个包都报错就清空整个缓存:
rm -rf ~/Library/Caches/org.swift.swiftpm/repositories/*
然后重新执行 xcodebuild -resolvePackageDependencies。
在 64 位设备上,指针只需要 36~40 位就能表示所有内存地址。苹果觉得剩下的位浪费了,于是把 isa 设计成了一个 union(联合体) ,把类指针和一堆标志位都塞进了这 64 位里。
这叫 Tagged Pointer / Non-pointer ISA 技术。
// 文件:objc-private.h
union isa_t {
isa_t() { }
isa_t(uintptr_t value) : bits(value) { }
uintptr_t bits; // 原始的 64 位值
private:
Class cls; // 类指针(只在 non-pointer isa 关闭时使用)
public:
#if defined(ISA_BITFIELD)
struct {
ISA_BITFIELD; // 展开后是一堆位域定义
};
...
};
// 这是 ARM64 的位域定义
uintptr_t nonpointer : 1; // bit 0
uintptr_t has_assoc : 1; // bit 1
uintptr_t has_cxx_dtor : 1; // bit 2
uintptr_t shiftcls : 33; // bit 3~35 ← 类指针在这里!
uintptr_t magic : 6; // bit 36~41
uintptr_t weakly_referenced : 1; // bit 42
uintptr_t unused : 1; // bit 43
uintptr_t has_sidetable_rc : 1; // bit 44
uintptr_t extra_rc : 19; // bit 45~63
uintptr_t nonpointer : 1;
含义: 这个 isa 是不是 "non-pointer isa"(优化过的 isa)。
0:纯指针,整个 64 位就是类地址(老设备/某些特殊情况)1:non-pointer isa,64 位里藏了很多信息现代 iOS 设备全是 1。
uintptr_t has_assoc : 1;
含义: 这个对象是否有关联对象(Associated Object)。
关联对象就是你用 objc_setAssociatedObject 给对象动态绑定的数据。
为什么需要这一位?
has_assoc == 0 → 跳过关联对象清理,直接释放,更快uintptr_t has_cxx_dtor : 1;
含义: 这个类(或它的父类)是否有 C++ 析构函数,或者 OC 的 .cxx_destruct 方法。
.cxx_destruct 是编译器自动生成的方法,用来清理带有 __strong 修饰的成员变量(ARC 下自动 release)。
为什么需要这一位?
.cxx_destruct 调用uintptr_t shiftcls : 33;
含义: 这 33 位才是真正的类指针(右移 3 位存储,取的时候左移 3 位还原)。
为什么只用 33 位?因为 ARM64 的内存对齐保证类地址的低 3 位永远是 0,可以省掉。
如何取出类指针?
// runtime 内部的取法
Class getClass() const {
return (Class)(shiftcls << 3); // 左移3位还原真实地址
}
uintptr_t magic : 6;
含义: 固定的魔数,值是 0b011010(十进制 26)。
用途: 调试用。当你看到一个 isa,如果 magic 值不对,说明这个对象已经被释放或内存被踩了(野指针)。Xcode 和 runtime 的断言会检查这个值。
uintptr_t weakly_referenced : 1;
含义: 这个对象是否被弱引用(__weak 指针)指向过。
为什么需要这一位?
SideTable(全局散列表)里把那些弱引用都清零(避免 dangling pointer)weakly_referenced == 0 → 跳过 SideTable 查找,直接释放uintptr_t unused : 1;
含义: 目前未使用,预留位。
uintptr_t has_sidetable_rc : 1;
含义: 引用计数是否溢出到了 SideTable。
正常情况下,引用计数存在 isa 的 extra_rc 里(19位,最大能存 2^19 - 1 = 524287)。如果引用计数超过了这个值,has_sidetable_rc = 1,多出来的部分存在全局的 SideTable 里。
uintptr_t extra_rc : 19;
含义: 存储对象的引用计数 - 1。
为什么是减 1?因为对象存活时引用计数至少为 1,存 0 代表计数是 1,节省一点空间。
实际的引用计数 = extra_rc + 1(如果 has_sidetable_rc == 0)
// objc-object.h
inline Class objc_object::getIsa() {
if (fastpath(!isTaggedPointer())) {
return ISA();
}
// ... TaggedPointer 的特殊处理
}
inline Class objc_object::ISA(bool authenticated) {
ASSERT(!isTaggedPointer());
#if SUPPORT_INDEXED_ISA
// 某些架构用索引
...
#else
// ARM64 主路径:取 shiftcls 位,左移3位还原地址
return (Class)(isa.bits & ISA_MASK);
#endif
}
其中 ISA_MASK 在 ARM64 是 0x0000000ffffffff8ULL,作用就是取 bit 3~35。
这是 OC 最难理解的概念之一,但其实逻辑非常自洽。
在 OC 里,"一切皆对象"——包括类本身也是对象。
[NSString class] // 这返回的是一个对象
[NSString stringWithString:@"hello"] // 这是给"类对象"发消息
既然类也是对象,那类对象的 isa 指向哪里?
答案就是:元类(metaclass) 。
元类是"类的类"。它存储的是类方法(+ 方法),就像普通类存储实例方法(- 方法)一样。
| 普通类(Class) | 元类(Metaclass) | |
|---|---|---|
| 本质 |
objc_class 结构体 |
也是 objc_class 结构体 |
| 方法列表里存的 | 实例方法(-) |
类方法(+) |
| isa 指向 | 元类 | 根元类(NSObject 的元类) |
| superclass 指向 | 父类 | 父类的元类 |
这是 OC 里最经典的一张图,一定要理解它:
isa isa isa
实例对象(inst) --------→ 类(MyClass) --------→ 元类(Meta-MyClass) ──→ 根元类
│
superclass superclass superclass │ isa(自指)
MyClass ───────→ NSObject Meta-MyClass ──────→ Meta-NSObject─┘
│ │
│ superclass = nil │ superclass
↓ ↓
(nil) NSObject(不是元类!)
用文字描述:
实例对象.isa → MyClass(类)MyClass.isa → Meta-MyClass(元类)Meta-MyClass.isa → Meta-NSObject(根元类)Meta-NSObject.isa → Meta-NSObject(自指!根元类的 isa 指向自己)继承链:
MyClass.superclass → NSObject
NSObject.superclass → nil
Meta-MyClass.superclass → Meta-NSObject(元类也有继承链)Meta-NSObject.superclass → NSObject(元类继承链的终点是 NSObject 类,不是 nil! )这个设计让你可以在任何类方法里调用 NSObject 的实例方法(比如 respondsToSelector:)。
// 这为什么能工作?
[MyClass respondsToSelector:@selector(doSomething)];
+respondsToSelector: 是 NSObject 的实例方法(- 方法),存在 NSObject 类里。
当你给 MyClass 发这个消息,runtime 查找路径:
Meta-MyClass(没有)
→ Meta-NSObject(没有)
→ NSObject(在这找到了!)
因为 Meta-NSObject.superclass = NSObject,所以元类链最终能访问到 NSObject 的实例方法。优雅!
不是所有"对象"都是真正的对象(有 isa 的结构体)。
对于一些小值对象(比如 NSNumber、NSDate、小字符串),苹果直接把值编码进指针本身,不分配堆内存。
NSNumber *num = @42;
// 在 64 位下,这个指针可能长这样:
// 0xb000000000000162 (不是真实的堆地址!)
// 最高位 1 = TaggedPointer 标志
// 低位存了 42 这个值
static inline bool _objc_isTaggedPointer(const void * _Nullable ptr) {
return ((uintptr_t)ptr & _OBJC_TAG_MASK) == _OBJC_TAG_MASK;
}
// ARM64: _OBJC_TAG_MASK = (1UL<<63),最高位为1就是 TaggedPointer
alloc 时不走 malloc
当 isa 的 extra_rc 不够用,或者有弱引用时,数据存在 SideTable 里。
struct SideTable {
spinlock_t slock; // 自旋锁,保证线程安全
RefcountMap refcnts; // 引用计数表(散列表)
weak_table_t weak_table; // 弱引用表
};
全局有 8 个(或 64 个)SideTable,通过对象地址取模来分配,减少锁竞争。
struct weak_table_t {
weak_entry_t *weak_entries; // 弱引用条目数组
size_t num_entries;
...
};
struct weak_entry_t {
DisguisedPtr<objc_object> referent; // 被指向的对象
// 指向该对象的所有 __weak 指针地址的集合
union {
struct { weak_referrer_t *referrers; ... };
struct { weak_referrer_t inline_referrers[WEAK_INLINE_COUNT]; };
};
};
对象 dealloc
↓
检查 isa.weakly_referenced
↓(== 1)
去 SideTable 找 weak_entry_t
↓
遍历所有指向该对象的 __weak 指针
↓
全部置 nil
↓
从 weak_table 删除该条目
这就是为什么 __weak 指针在对象释放后自动变成 nil,而不会变成野指针——runtime 帮你清零了。
| 概念 | 本质 | 存在哪里 |
|---|---|---|
| isa | 64位 union,含类指针+引用计数+标志位 | 每个对象的第一个字段 |
| 元类 | 存类方法的 objc_class | 全局静态区 |
| TaggedPointer | 值直接编码进指针,无堆对象 | 栈/寄存器 |
| extra_rc | 引用计数(-1)的快速存储 | isa 的高19位 |
| SideTable | 溢出引用计数 + 弱引用表 | 全局散列表 |
下一篇:延伸问题 Q&A——消息发送、方法查找、Swizzle、dealloc 全流程等
从 objc_class 开始,是因为它是整个 Runtime 的基础数据结构。Runtime 管的事很多——消息发送、方法查找、内存管理、Category 加载……但这些行为最终都要落在"类长什么样"上面。搞清楚 objc_class,后面的东西才能接得上。
下面是从 Apple 开源的 objc4 里提取的核心结构体,我做了适度精简,保留所有关键字段。
建议先整体扫一遍,有个印象,后面逐个解释。
// ============================================================
// 文件:objc-runtime-new.h(objc4-818.2)
// 源码地址:https://opensource.apple.com/source/objc4/
// ============================================================
// -------------------- 1. objc_object --------------------
// 所有 OC 对象的基类,只有一个字段:isa
struct objc_object {
private:
isa_t isa; // 64位,包含类指针+引用计数+标志位
public:
Class ISA(bool authenticated = false);
Class getIsa();
// ... 省略其他方法
};
// -------------------- 2. objc_class --------------------
// 这就是"类"的底层结构,继承自 objc_object
struct objc_class : objc_object {
// 注意:isa 字段继承自 objc_object,这里不重复写
Class superclass; // 父类指针
cache_t cache; // 方法缓存(哈希表)
class_data_bits_t bits; // 指向 class_rw_t 的指针+标志位
// 取出真正的数据
class_rw_t *data() const {
return bits.data();
}
// ... 省略其他方法
};
// -------------------- 3. class_data_bits_t --------------------
// 这是 objc_class.bits 的类型,用来存储指向 class_rw_t 的指针 + 几个标志位
struct class_data_bits_t {
private:
uintptr_t bits; // 就是一个 64 位整数,低位藏标志位,高位存指针
public:
// 用掩码取出真正的 class_rw_t 指针
class_rw_t *data() const {
return (class_rw_t *)(bits & FAST_DATA_MASK);
}
// 各种标志位的读取方法
bool isSwiftLegacy() const {
return getBit(FAST_IS_SWIFT_LEGACY);
}
bool isSwiftStable() const {
return getBit(FAST_IS_SWIFT_STABLE);
}
// ... 其他方法
};
// ARM64 下的掩码和标志位定义:
// FAST_DATA_MASK = 0x00007ffffffffff8UL (取 bit 3~46,即真正的指针)
// FAST_IS_SWIFT_LEGACY = 1 << 0 (bit 0: 是否是旧版 Swift 类)
// FAST_IS_SWIFT_STABLE = 1 << 1 (bit 1: 是否是新版 Swift 类)
// FAST_HAS_DEFAULT_RR = 1 << 2 (bit 2: 是否有默认的 retain/release)
// -------------------- 4. cache_t --------------------
// 方法缓存,加速方法查找
struct cache_t {
private:
explicit_atomic<uintptr_t> _bucketsAndMaybeMask; // 桶数组地址
union {
struct {
explicit_atomic<mask_t> _maybeMask; // 桶数量-1(用于哈希取模)
uint16_t _flags;
uint16_t _occupied; // 已使用的桶数
};
explicit_atomic<preopt_cache_t *> _originalPreoptCache;
};
public:
// ... 省略查找、插入方法
};
// 单个缓存桶
struct bucket_t {
private:
explicit_atomic<SEL> _sel; // 方法名(选择子)
explicit_atomic<uintptr_t> _imp; // 函数指针(方法实现地址)
};
// -------------------- 5. class_rw_t --------------------
// 运行时可读写数据(Category 方法会合并到这里)
struct class_rw_t {
uint32_t flags;
uint16_t witness;
uint16_t index;
explicit_atomic<uintptr_t> ro_or_rw_ext; // 指向 class_ro_t 或扩展数据
Class firstSubclass; // 第一个子类
Class nextSiblingClass; // 兄弟类(形成链表)
// 获取方法/属性/协议列表
const method_array_t methods() const;
const property_array_t properties() const;
const protocol_array_t protocols() const;
// 获取只读数据
const class_ro_t *ro() const;
};
// -------------------- 6. class_ro_t --------------------
// 编译期只读数据(源码里写死的方法、变量、属性)
struct class_ro_t {
uint32_t flags;
uint32_t instanceStart; // 实例变量起始偏移
uint32_t instanceSize; // sizeof(实例),对象占多少字节
const uint8_t * ivarLayout; // 强引用 ivar 的内存布局
const char * name; // 类名字符串,如 "NSString"
WrappedPtr<method_list_t, method_list_t::Ptrauth> baseMethods; // 方法列表
protocol_list_t * baseProtocols; // 协议列表
const ivar_list_t * ivars; // 实例变量列表
const uint8_t * weakIvarLayout; // 弱引用 ivar 的内存布局
property_list_t *baseProperties; // 属性列表
};
// -------------------- 7. method_t --------------------
// 单个方法的描述
struct method_t {
SEL name; // 方法名(选择子),本质是 const char *
const char *types; // 类型编码,如 "v16@0:8"
IMP imp; // 函数指针(真正的代码地址)
};
// -------------------- 8. ivar_t --------------------
// 单个实例变量的描述
struct ivar_t {
int32_t *offset; // 偏移量指针(Non-Fragile ABI 用)
const char *name; // 变量名,如 "_name"
const char *type; // 类型编码,如 "@"NSString""
uint32_t alignment_raw;// 对齐方式
uint32_t size; // 占多少字节
};
// -------------------- 9. isa_t --------------------
// isa 的真正定义(union,64位里塞了很多信息)
union isa_t {
uintptr_t bits; // 原始64位值
// ARM64 位域展开(iOS 真机):
struct {
uintptr_t nonpointer : 1; // bit 0: 是否是优化过的 isa
uintptr_t has_assoc : 1; // bit 1: 有关联对象?
uintptr_t has_cxx_dtor : 1; // bit 2: 有 C++ 析构?
uintptr_t shiftcls : 33; // bit 3-35: 类指针(右移3位存储)
uintptr_t magic : 6; // bit 36-41: 固定值 0x1a,调试用
uintptr_t weakly_referenced : 1; // bit 42: 被弱引用?
uintptr_t unused : 1; // bit 43: 未使用
uintptr_t has_sidetable_rc : 1; // bit 44: 引用计数溢出到 SideTable?
uintptr_t extra_rc : 19; // bit 45-63: 引用计数-1
};
};
objc_class(一个类在内存里的样子)
┌─────────────────────────────────────┐
│ isa (继承自 objc_object) │ ← isa_t union,64位
├─────────────────────────────────────┤
│ superclass │ ← 指向父类的 objc_class
├─────────────────────────────────────┤
│ cache │ ← cache_t 结构体
│ └── bucket_t[] 数组 │ 每个桶存 { SEL, IMP }
├─────────────────────────────────────┤
│ bits │ ← class_data_bits_t(指针+标志位)
│ └── data() ───────────────────────────→ class_rw_t(运行时可写)
│ │ ├── methods()
│ │ ├── properties()
│ │ ├── protocols()
│ │ └── ro() ────────→ class_ro_t(只读)
│ │ ├── name
│ │ ├── baseMethods
│ │ │ └── method_t[]
│ │ ├── ivars
│ │ │ └── ivar_t[]
│ │ └── baseProperties
└─────────────────────────────────────┘
接下来按源码出现的顺序,逐个讲解每个结构体、每个字段的含义。
struct objc_object {
private:
isa_t isa;
};
这是 OC 里所有对象的底层表示。不管是 NSString、UIView、还是你自定义的 MyClass 实例,底层都是 objc_object。
| 字段 | 类型 | 含义 |
|---|---|---|
isa |
isa_t |
"is a" 的缩写,标识"这个对象是什么类型"。是一个 64 位的 union,里面藏了类指针 + 引用计数 + 各种标志位。isa_t 的详细结构会在第二篇展开讲解。 |
因为 objc_object 是最小公共祖先。每个对象只需要知道"我是什么类型"(isa),其他的成员变量由具体的类定义,紧跟在 isa 后面存储。
一个 MyClass 实例的内存:
┌────────────────┐ ← 对象起始地址
│ isa │ 8 字节(objc_object 的字段)
├────────────────┤
│ _name │ 8 字节(MyClass 自己的 ivar)
├────────────────┤
│ _age │ 4 字节(MyClass 自己的 ivar)
└────────────────┘
struct objc_class : objc_object {
Class superclass;
cache_t cache;
class_data_bits_t bits;
class_rw_t *data() const {
return bits.data();
}
};
这是 OC 里类的底层表示。每个 @interface MyClass 在运行时都对应一个 objc_class 结构体实例。
注意它继承自 objc_object,所以"类也是对象"——类对象有自己的 isa(指向元类)。
| 字段 | 类型 | 含义 |
|---|---|---|
isa |
isa_t(继承来的) |
类对象的 isa 指向它的元类(metaclass)。isa_t 的详细结构见第二篇。 |
superclass |
Class |
父类指针。Class 是 objc_class * 的 typedef,即指向另一个 objc_class 的指针。NSObject 的 superclass 是 nil。; |
cache |
cache_t |
方法缓存,哈希表结构。最近调用的方法会缓存在这里,加速后续调用。 |
bits |
class_data_bits_t |
一个 64 位整数,低 3 位是标志位,高位是 class_rw_t 指针。 |
// objc.h
typedef struct objc_class *Class;
Class 就是 objc_class * 的别名,一个指向类对象的指针。你代码里写的所有 Class 都只是这个指针,没有额外结构:
Class cls = [MyClass class]; // 拿到 MyClass 的 objc_class * 指针
Class superCls = [cls superclass]; // 拿到父类的 objc_class * 指针
同理,id 也是:
typedef struct objc_object *id; // id = objc_object *,指向任意实例对象
实现继承。当在当前类找不到方法时,runtime 会沿着 superclass 链往上找。
调用 [myObj doSomething]
↓
在 MyClass 的方法列表里找
↓ 找不到
通过 superclass 到 NSObject 里找
↓ 还找不到
触发消息转发
struct class_data_bits_t {
private:
uintptr_t bits; // 64 位整数
public:
class_rw_t *data() const {
return (class_rw_t *)(bits & FAST_DATA_MASK);
}
};
就是 objc_class.bits 的类型。它不是简单的指针,而是把 class_rw_t 指针 和 几个标志位 打包进同一个 64 位整数里。
因为 class_rw_t 在内存里是 8 字节对齐的,所以它的地址的低 3 位永远是 000。苹果就把这 3 位拿来存标志位,不浪费。
class_data_bits_t.bits(64位)
63 3 2 1 0
┌────────────────────────────────┬──┬──┬──┐
│ class_rw_t 指针 (bit 3~63) │ 2│ 1│ 0│
└────────────────────────────────┴──┴──┴──┘
│ │ │
│ │ └─ FAST_IS_SWIFT_LEGACY (是旧版Swift类?)
│ └──── FAST_IS_SWIFT_STABLE (是新版Swift类?)
└─────── FAST_HAS_DEFAULT_RR (有默认retain/release?)
// ARM64
#define FAST_DATA_MASK 0x00007ffffffffff8UL
// 二进制:...11111111111111111111111111111111111111000
// 作用:与运算后,低 3 位清零,剩下的就是真正的 class_rw_t 地址
class_rw_t *data() const {
return (class_rw_t *)(bits & FAST_DATA_MASK);
// bits & 掩码 → 把低 3 位标志位清掉 → 得到纯净的 class_rw_t 指针
}
class_data_bits_t 和 isa_t 的设计思路一样——充分利用内存对齐带来的空闲位,一个 64 位整数里塞多种信息,省内存。
struct cache_t {
private:
explicit_atomic<uintptr_t> _bucketsAndMaybeMask;
union {
struct {
explicit_atomic<mask_t> _maybeMask;
uint16_t _flags;
uint16_t _occupied;
};
explicit_atomic<preopt_cache_t *> _originalPreoptCache;
};
};
struct bucket_t {
private:
explicit_atomic<SEL> _sel;
explicit_atomic<uintptr_t> _imp;
};
每次调用方法都去 class_rw_t 的方法列表里遍历查找,太慢了。cache_t 是一个哈希表,把最近调用过的方法缓存起来。
| 字段 | 含义 |
|---|---|
_bucketsAndMaybeMask |
哈希桶数组的起始地址 |
_maybeMask |
桶数量 - 1,用于哈希取模(hash & mask) |
_occupied |
当前已使用的桶数量 |
单个缓存条目,存储 SEL(方法名)和 IMP(函数指针)的映射。
| 字段 | 类型 | 含义 |
|---|---|---|
_sel |
SEL |
方法选择子(方法名),如 @selector(viewDidLoad)
|
_imp |
uintptr_t |
方法实现的函数地址 |
[obj doSomething]
↓
计算 @selector(doSomething) 的哈希值
↓
hash & _maybeMask → 得到桶的索引
↓
取出 bucket_t,比较 _sel 是否等于 @selector(doSomething)
↓
相等 → 直接调用 _imp,结束(命中缓存,极快)
不相等 → 去 class_rw_t 里慢速查找
method_exchangeImplementations(Method Swizzle)后失效时 runtime 会调用 flushCaches() 清空缓存。
struct class_rw_t {
uint32_t flags;
uint16_t witness;
uint16_t index;
explicit_atomic<uintptr_t> ro_or_rw_ext;
Class firstSubclass;
Class nextSiblingClass;
const method_array_t methods() const;
const property_array_t properties() const;
const protocol_array_t protocols() const;
const class_ro_t *ro() const;
};
rw = read-write(可读写)。这里存放运行时可以修改的数据,比如 Category 添加的方法会合并到这里。
| 字段 | 含义 |
|---|---|
flags |
各种标志位(是否已初始化、是否有 C++ 构造函数等) |
ro_or_rw_ext |
指向 class_ro_t(只读数据),或扩展数据 |
firstSubclass |
指向第一个子类,形成子类链表 |
nextSiblingClass |
指向下一个兄弟类(同一个父类的其他子类) |
const method_array_t methods() const; // 返回方法列表(含 Category 方法)
const property_array_t properties() const; // 返回属性列表
const protocol_array_t protocols() const; // 返回协议列表
这些方法返回的是合并后的列表——源码里写的 + Category 加进来的。
返回 class_ro_t 指针,取出编译期确定的只读数据。
struct class_ro_t {
uint32_t flags;
uint32_t instanceStart;
uint32_t instanceSize;
const uint8_t * ivarLayout;
const char * name;
WrappedPtr<method_list_t, ...> baseMethods;
protocol_list_t * baseProtocols;
const ivar_list_t * ivars;
const uint8_t * weakIvarLayout;
property_list_t *baseProperties;
};
ro = read-only(只读)。这里存放编译时就确定的数据,运行时不能修改。
| 字段 | 类型 | 含义 |
|---|---|---|
flags |
uint32_t |
标志位 |
instanceStart |
uint32_t |
实例变量在对象内存中的起始偏移(通常是 8,跳过 isa) |
instanceSize |
uint32_t |
一个实例对象占多少字节(sizeof) |
ivarLayout |
const uint8_t * |
描述哪些 ivar 是强引用(ARC 用) |
name |
const char * |
类名字符串,如 "UIViewController"
|
baseMethods |
method_list_t * |
源码里定义的方法列表(不含 Category) |
baseProtocols |
protocol_list_t * |
源码里遵循的协议列表 |
ivars |
ivar_list_t * |
实例变量列表 |
weakIvarLayout |
const uint8_t * |
描述哪些 ivar 是弱引用 |
baseProperties |
property_list_t * |
源码里定义的属性列表 |
| class_ro_t | class_rw_t | |
|---|---|---|
| 全称 | read-only | read-write |
| 什么时候确定 | 编译期(写进 Mach-O 二进制文件) | 运行时(启动时构造) |
| 能修改吗 | ❌ 不能 | ✅ 能 |
| 存什么 | 源码里写死的方法、属性、变量 | 动态添加的方法、Category 合并的方法 |
因为 Category 是运行时加载的。编译期不知道会有哪些 Category,所以:
class_ro_t
class_rw_t
查找方法时,先查 class_rw_t(含 Category),它内部会访问 class_ro_t。
struct method_t {
SEL name;
const char *types;
IMP imp;
};
| 字段 | 类型 | 含义 | 例子 |
|---|---|---|---|
name |
SEL |
方法选择子(方法名) | @selector(viewDidLoad) |
types |
const char * |
类型编码(返回值+参数的类型) | "v16@0:8" |
imp |
IMP |
函数指针,指向方法的真正实现 |
0x100001234(代码段地址) |
typedef struct objc_selector *SEL;
本质是一个唯一化的 C 字符串。同名方法在整个程序里 SEL 值相同(指针相等),所以比较方法名只需要比较指针,极快。
SEL sel1 = @selector(doSomething);
SEL sel2 = @selector(doSomething);
// sel1 == sel2(指针相等,不是字符串比较)
typedef void (*IMP)(id, SEL, ...);
函数指针,前两个参数固定是:
id self:消息接收者SEL _cmd:方法选择子这解释了为什么 OC 方法里能直接用 self 和 _cmd——它们是函数的隐藏参数。
// 你写的:
- (void)doSomething {
NSLog(@"%@", self);
}
// 编译器眼里的:
void doSomething(id self, SEL _cmd) {
NSLog(@"%@", self);
}
以 - (NSString *)nameWithPrefix:(NSString *)prefix 为例,types 是 @24@0:8@16:
@ → 返回值是 id(对象)
24 → 所有参数总共占 24 字节
@ → 第1个参数是 id(self)
0 → 从第 0 字节开始
: → 第2个参数是 SEL(_cmd)
8 → 从第 8 字节开始
@ → 第3个参数是 id(prefix)
16 → 从第 16 字节开始
这套编码叫 Type Encoding,runtime 靠它做方法签名校验。
struct ivar_t {
int32_t *offset;
const char *name;
const char *type;
uint32_t alignment_raw;
uint32_t size;
};
| 字段 | 类型 | 含义 | 例子 |
|---|---|---|---|
offset |
int32_t * |
偏移量的指针(不是值!) | 指向存储偏移量的内存 |
name |
const char * |
变量名 | "_name" |
type |
const char * |
类型编码 | "@"NSString"" |
alignment_raw |
uint32_t |
内存对齐方式 | 通常是 3(2^3 = 8 字节对齐) |
size |
uint32_t |
占多少字节 | 指针占 8 字节 |
这是 Non-Fragile ABI(非脆弱 ABI)的设计。
假设父类 NSObject 有 8 字节的 isa,子类 MyClass 的 _name 变量在 offset 8。
如果 Apple 在新系统里给 NSObject 加了一个成员变量(变成 16 字节),按老 ABI,MyClass 的 _name 还在 offset 8,就会和 NSObject 新增的变量重叠——程序崩溃。
Non-Fragile ABI 的解决方案:
offset 是指针,不是值旧系统:NSObject 8字节,MyClass._name 在 offset 8
↓ Apple 升级系统
新系统:NSObject 16字节
↓ runtime 自动修正
MyClass._name 的 offset 从 8 改成 16
// 伪代码
id value = *(id *)((char *)obj + *ivar->offset);
// 1. 取出 offset 指针指向的偏移值
// 2. 对象地址 + 偏移值 = ivar 的内存地址
// 3. 解引用得到 ivar 的值
union isa_t {
uintptr_t bits;
struct {
uintptr_t nonpointer : 1;
uintptr_t has_assoc : 1;
uintptr_t has_cxx_dtor : 1;
uintptr_t shiftcls : 33;
uintptr_t magic : 6;
uintptr_t weakly_referenced : 1;
uintptr_t unused : 1;
uintptr_t has_sidetable_rc : 1;
uintptr_t extra_rc : 19;
};
};
在 64 位系统上,指针只需要约 40 位就能表示所有内存地址。剩下的位"浪费"了,苹果就把引用计数和各种标志位塞进去,省内存。
这叫 Non-pointer ISA(优化过的 isa)。
| 位域 | 位数 | 含义 |
|---|---|---|
nonpointer |
1 | 是否是优化过的 isa(现代设备都是 1) |
has_assoc |
1 | 对象是否有关联对象(objc_setAssociatedObject) |
has_cxx_dtor |
1 | 是否有 C++ 析构函数或 ARC 的 .cxx_destruct
|
shiftcls |
33 | 类指针(右移 3 位存储,取时左移还原) |
magic |
6 | 固定值 0x1a,调试用(值不对说明内存被踩了) |
weakly_referenced |
1 | 是否被 __weak 指针指向过 |
unused |
1 | 未使用,预留 |
has_sidetable_rc |
1 | 引用计数是否溢出到 SideTable |
extra_rc |
19 | 存储引用计数 - 1(最大 2^19 - 1 = 524287) |
Class cls = (Class)(isa.bits & ISA_MASK);
// ISA_MASK = 0x0000000ffffffff8ULL
// 掩码取出 bit 3~35,然后隐含左移还原
把所有结构体串起来,一个类在内存里长这样:
objc_class 实例(代表 MyClass 这个类)
┌─────────────────────────────────────────────────────┐
│ isa (64位 isa_t) │ → 指向 Meta-MyClass(元类)
├─────────────────────────────────────────────────────┤
│ superclass (8字节) │ → 指向 NSObject
├─────────────────────────────────────────────────────┤
│ cache (cache_t) │
│ _bucketsAndMaybeMask → [ bucket_t, bucket_t... ] │ 每个桶: { SEL, IMP }
│ _maybeMask = N-1 │
│ _occupied = 已用桶数 │
├─────────────────────────────────────────────────────┤
│ bits (class_data_bits_t) │ ← 低3位是标志位,高位是指针
│ data() ──────────────────────────────────────────│──→ class_rw_t
│ │ ├── methods() → [method_t, ...]
│ │ ├── properties()→ [property_t, ...]
│ │ ├── protocols() → [protocol_t, ...]
│ │ └── ro() ───────→ class_ro_t
│ │ ├── name = "MyClass"
│ │ ├── instanceSize = 24
│ │ ├── baseMethods
│ │ │ ├── method_t { SEL, types, IMP }
│ │ │ └── method_t { ... }
│ │ └── ivars
│ │ ├── ivar_t { offset*, "_name", "@", 3, 8 }
│ │ └── ivar_t { offset*, "_age", "i", 2, 4 }
└─────────────────────────────────────────────────────┘
| 结构体 | 可否运行时修改 | 存放什么 |
|---|---|---|
objc_class |
不直接改 | 类的容器,持有 superclass/cache/bits |
isa_t |
部分可改(引用计数位) | 类指针 + 引用计数 + 标志位,全塞在 64 位里 |
class_data_bits_t |
不直接改 | class_rw_t 指针 + 3 个标志位,又一个"指针+标志"混合体 |
cache_t |
是(每次调用方法后更新) | 最近调用的方法 SEL → IMP 映射 |
class_rw_t |
是 | 运行时合并后的方法、属性、协议 |
class_ro_t |
否 | 编译期确定的方法、变量、属性,写死在二进制里 |
method_t |
IMP 可以换(Swizzle) | 一个方法的名字、类型编码、实现地址 |
ivar_t |
offset 可改(Non-Fragile ABI) | 一个实例变量的名字、类型、偏移量 |
下一篇:isa 指针深度解析、元类体系、完整继承链图
再有不到半个月,Apple 将迎来 50 岁生日。Tim Cook 也发表了一篇短文,致敬过去半个世纪的历程。不过,由于苹果一直以来始终引领潮流的形象,很多人并没有意识到它已经是 IT 产业中名副其实的元老。与它年龄相当的 IT 巨头,如今仍留在一线牌桌上的寥寥无几。
作为一个只比苹果大一岁的科技爱好者,从 Apple II 到如今的 iPhone、MacBook,苹果的产品几乎伴随我走过了大半人生。严格来说,我并不算真正的果粉——不会因为没能第一时间买到新品而遗憾,也几乎不再熬夜看发布会,更说不出新产品的具体参数。但回顾过去,在每一个人生节点上,我都会很自然地选择苹果的产品,并在近几年成为了苹果开发生态中的一员。
其实我也没有完全想明白,苹果对我持久的吸引力究竟来自哪里。是因为很早就开始使用它的产品?是它的创新、体验和气质?还是 Jobs 的人格魅力?说实话,如今的选择已经完全出于习惯和本能,就像老友间的默契,早已不需要什么特别的理由。
当然,苹果的成长之路并非一帆风顺,其间也有过低谷。但有一点必须承认:它在过去 50 年间的企业定位几乎没变——为个人和社会创造强大的工具。即便在最新一轮 AI 浪潮中,苹果看似失去了先机,但作为连接人与数字世界的“最后一厘米”的核心参与者,它仍然具备在 AI 时代留在牌桌中央的资本。毕竟,我们生活在物质世界中,需要实打实的硬件设备和个人化服务来享受技术进步的成果。
50 岁的苹果或许能给更多企业带来启示:与其模仿它“炫酷”、“创新”的外表,不如学习它的专注与坚持。成为与用户长久互相陪伴的伙伴,或许才是它成功的真正密码。
大概率再过十年,当苹果 60 岁、我 61 岁的时候,我仍然用着一台苹果电脑。
生日快乐,苹果!
到 2026 年,Core Data 已经问世 21 年,尽管仍有不少开发者在使用它,但在今天的 Swift 项目里,它越来越像个“时代遗留”。并发得靠 perform 一层层套,模型声明堆满样板代码,字符串谓词随时等你踩坑。这篇文章不是要为 Core Data 辩护,也不是要说服新的开发者回到 Core Data。它更像是一篇问题整理:在 2026 年,为什么仍有人坚持使用 Core Data;而如果要继续使用它,我们今天真正需要解决的问题又是什么。
一个原生应用,100+ AI 模型,支持 Mac、iOS 和 Android。极速响应、键盘驱动、非 Electron。使用码 FATBOBMAN25 立享 25% OFF。
在苹果开发者中心举办的一场安全专题活动中,多位苹果工程师围绕应用安全与内存安全进行了近六小时的分享与问答,内容涵盖现代应用面临的安全挑战,以及 Apple 平台提供的一系列防护技术。Anton Gubarenko 将这场活动中的大量开发者问答整理成文,讨论了第三方库安全评估、UserDefaults 与 plist 数据存储的风险、Keychain 与文件保护策略、Swift unsafe API 的使用边界,以及如何在 Xcode 中启用 Enhanced Security 等能力。对于希望了解 Apple 平台安全机制与实践建议的开发者来说,这是一份信息密度很高的问答整理,其中包含不少来自苹果工程师的一手信息。
为应用添加订阅功能本身并不复杂,但在 App Store Connect 与 RevenueCat 两个后台之间来回配置,过程往往相当繁琐。Rudrank Riyam 介绍了一种更高效的做法:使用 ASC CLI 在终端中一次性创建订阅产品,再让 AI 代理通过 RevenueCat 的 MCP Server 自动完成 entitlements、offerings 与 paywall 的配置,从而将原本依赖控制台点击的流程迁移到 CLI + AI Agent 的自动化工作流中。
JetBrains 最近发布了一份面向 Swift 开发者的调研问卷,邀请开发者分享当前使用的开发工具、工作流程以及在 Swift 生态中的痛点。尽管官方并未说明调研的具体用途,但社区中已经出现不少猜测:这项调查可能与 JetBrains 重新评估 Swift 开发工具支持有关。
在 JetBrains 于 2022 年宣布停止维护 AppCode 之后,Swift 开发者基本回到了以 Xcode 为核心的工具链。此次调研也引发了一些讨论——有人期待 JetBrains 重新探索 Swift tooling 的可能性,也有人认为这更可能与 Kotlin Multiplatform 或 Swift 构建工具链相关。如果你对 Swift 开发工具生态的未来方向感兴趣,不妨参与这份调查。
在 Swift 项目中,Protocol 几乎无处不在,但如果不依赖编译器或完整构建环境,仅通过源码文本判断一个文件是否定义或使用了协议,结果会有多可靠?Xiangyu Sun 在这篇文章中系统评估了多种检测策略,例如使用 SourceKit/LSP、SwiftSyntax AST、关键字正则匹配,以及通过 extension Foo: Bar、any / some 等语法信号进行启发式判断,并对这些方法的准确率与适用场景进行了比较。
文章最有意思的部分在于作者发现:简单的命名约定可以显著提升静态分析效果。如果团队统一使用 *Protocol 后缀命名协议类型(如 PaymentServiceProtocol),很多原本存在歧义的检测方法都会变得更加可靠。作者还进一步讨论了这种约定在 AI 辅助开发中的价值:通过在文件级别预分类协议文件,可以在向 LLM 提供上下文时显著减少 token 消耗,并提高分析效率,这是一个颇具启发性的视角。
从 GCD 迁移到 Swift Concurrency 并非简单的语法替换。在这篇文章中,Soumya Ranjan Mahunt 指出:Swift Concurrency 在任务调度、执行顺序以及并发语义上与 GCD 存在一些关键差异,例如 Task 的调度并不保证与 GCD 相同的 FIFO 执行顺序,而 actor 也并不是 DispatchQueue 的直接替代,其执行行为可能受到任务优先级和调度策略的影响。此外,文中还讨论了一些在实际迁移过程中容易被忽视的问题,例如 DispatchGroup 在 Swift Concurrency 中并没有完全等价的 API,以及在旧系统版本中使用 assumeIsolated 可能遇到的兼容性问题。
随着 AI Agent 在开发工作流中的应用越来越广泛,如何为 Agent 设计合适的“技能”(Skill / Tool)也逐渐成为一个新的工程问题。Antoine van der Lee 提出了一个用于判断何时应该为 Agent 创建技能的九步框架,帮助开发者在自动化能力、可维护性以及系统复杂度之间取得平衡。Antoine 指出,并非所有任务都适合直接交给 LLM,也并非所有能力都需要实现为 Agent 工具。文章从任务确定性、执行成本、可复用性以及安全性等角度出发,提供了一套相对系统的评估思路。
这是一个很有意思的开源项目,由 Anferne Pineda 开发。它基于 SwiftData 的自定义 store 能力,在保留 SwiftData 上层开发体验的同时,重新实现了一套面向 SQLite 的底层存储后端,包括从 SwiftData 模型、谓词到 SQLite schema、SQL、快照与持久化历史的映射和执行。
DataStoreKit 提供了一些值得关注的特性,例如支持对数组、字典等集合类型数据进行谓词查询,底层以 JSON 形式映射到 SQLite;同时也提供了 SQL 直通能力,让开发者在 #Predicate 之外,能够直接利用 SQLite 的能力完成查询或维护操作。
这是目前为数不多、且实现深度较高的 SwiftData DataStore 自定义实践,展示了 SwiftData 作为数据表现层而非完整持久化引擎的另一种可能性。项目目前仍处于较早期阶段,API 和能力边界可能还会继续调整,但已经非常值得持续关注。
Miguel Piedrafita 开发的 swift-playwright,将 Playwright 这套成熟的浏览器自动化能力带入了 Swift 生态。开发者可以直接使用 Swift 代码驱动 Chromium、Firefox 和 WebKit,完成页面导航、点击、输入、截图、执行 JavaScript 等常见操作,整体 API 风格也尽量贴近官方 Playwright。
从实现方式上看,它并不是重新实现一套浏览器自动化框架,而是在 Swift 侧封装了 Playwright 协议,底层依然通过 Node.js 的 Playwright driver 与浏览器通信。对于希望使用 Swift 构建测试工具、CLI,甚至 AI Agent 的开发者来说,这个项目提供了一个颇具吸引力的切入点。
如果你是开发者、设计师、产品经理、创作者,还是对 AI 和未来科技感兴趣的探索者,都很值得来逛逛。
如果本期周报对你有帮助,请:
🚀 拓展 Swift 视野
- 📮 邮件订阅 | weekly.fatbobman.com 获取独家技术洞察
- 👥 开发者社区 | Discord 实时交流开发经验
- 📚 原创教程 | fatbobman.com 学习 Swift/SwiftUI 最佳实践
再有不到半个月,Apple 将迎来 50 岁生日。Tim Cook 也发表了一篇短文,致敬过去半个世纪的历程。不过,由于苹果一直以来始终引领潮流的形象,很多人并没有意识到它已经是 IT 产业中名副其实的元老。与它年龄相当的 IT 巨头,如今仍留在一线牌桌上的寥寥无几。
现在已经完成了对 Xcode 的安装,所以开发环境已经安装完成了,接下来就需要开始真正的 iOS 开发了。对于 iOS 开发,这里使用了目前苹果比较推荐初学者入门的方式,使用 Swift 语言进行编程,并且使用苹果推荐的 SwiftUI。
1. 新建项目: 首先点击 Xcode 图标打开 Xcode,这时候会出现 Xcode 的初始界面,在这里点击 Create New Project... 创建一个新的项目。
2. 创建一个 iOS 项目: 之后需要选择开发什么类型的项目,需要开发的是 iOS 平台的 App,所以在对话框中,选择 Applocation 中的 App 选项,再点击 Next 按钮。
3. 选择项目的详细信息: 点击 Next 之后,就能看到配置具体的项目信息的选项,填写项目的基础信息。
然后点击 Next,之后选择保存的目录,就能创建出一个最基础的 iOS App 的项目了。
完成了最基础的项目创建,可以得到一个简单的 iOS 的项目代码和目录结构,并且右侧会展示我们当前页面的预览。这是一个基于 Swift UI 的 iOS App 项目。
下面可以分析一下创建出来的这个新项目项目。
在 Xcode 中,左侧显示了项目目录结构,可以看到,我们的项目中包含三部分:
接下来进代码可以分析一下这两个文件都做了些什么:
import SwiftUI // 导入 Swift UI 包
@main // 这里表示这里是main,作为入库,相当于我们其他编程中的 main 函数
struct TestDemoApp: App { // 定义了一个结构体
var body: some Scene {
WindowGroup {
ContentView() // 把 ContentView 放进来执行
}
}
}
这个入口文件,定义使用 @main 定义了入口,并且调用了 ContentView。那接下来看看 ContentView 的代码。
import SwiftUI
struct ContentView: View { // 定义结构体
var body: some View {
VStack { // 使用布局方式 竖排布局
Image(systemName: "globe") // 展示图片
.imageScale(.large) // 设置大小
.foregroundStyle(.tint) // 设置样式
Text("Hello, world!") // 展示文字
}
.padding() // 这个布局外加上边距
}
}
#Preview { // 通过设个代码,可以再右侧看到当前的预览
ContentView()
}
这两段代码中,可以认识到 Swift 结构和一些知识。
Swift 结构体是一种通用且灵活的构造体,我们可以理解为一种组织代码的方式,如果有其他编程经验,相信对结构体和类并不陌生。
在 Swift 中结构体可以定义属性和方法,这个和其他编程语言中的 class—— 类很像。 Swift 中,也存在数据类型类的定义,类和结构体有部分相同之处,也有一些不一样的地方,后续使用到的时候再详细介绍。
从这里可以看出,结构体可以定义一些变量,同时也能定义一些常量和方法。(这里不太懂的同学可以先不急着了解,下一节会详细介绍 Swift 语言编程的基础知识)例如,定义一个结构体:
struct TestStruct {
var number: Int
}
这就定义了一个有属性的结构体,同时,定义属性的时候,也可以对其初始化。
struct TestStruct {
var number: Int = 1
}
定义好了结构体,就可以对结构体进行实例化,可以看到示例代码中,已经有对结构体进行实例化的例子,在 #Preview处。对于已经初始化变量的结构体,我们可以再初始化的时候,不带参数:
struct TestStruct {
var number: Int = 1
}
TestStruct()
然而,在未初始化的结构体中,则必须在实例化的时候,带上参数,不然会发生报错:
struct TestStruct {
var number: Int
}
TestStruct(number: 1)
这里,就完成创建出了一个最简单的 iOS App 项目。同时也对 Swift 的结构体有了一定的了解。

老司机 iOS 周报,只为你呈现有价值的信息。
你也可以为这个项目出一份力,如果发现有价值的信息、文章、工具等可以到 Issues 里提给我们,我们会尽快处理。记得写上推荐的理由哦。有建议和意见也欢迎到 Issues 提出。
26 年 3 月 15 日(消费者权益保护日)起,大陆 iAP 的抽成从 30% -> 25%,小开发者与小程序的抽成从 15% -> 12% 。抽成降低是大势所趋,毕竟其他地区还允许侧载等。同时 Google Play 商店的抽成也将从 30% -> 20% 。
今年的 Let's Vision 大会将在 3 月 28~29 日在上海漕河泾举办,会有大量嘉宾莅临,对详情感兴趣可以查看推送次条,通过链接购买有优惠券提供。我们也将在评论区抽出 5 张展览票(22 日开奖)。
@EyreFree:文章先从类型安全、LLM 友好接口、自我修复、人工介入、性能优化五大维度,讲解高可用 Agent Tools 的设计要点与方法;针对企业落地中工具碎片化、复杂化、黑盒化痛点,演示了依赖火山引擎 AgentKit 解决这类问题的方式,其 Gateway 可高效将存量 API 转为 MCP 工具,搭配企业级 Skills 管理与零信任鉴权体系,实现工具的高效治理与安全调用;还结合零售、金融科技行业实战案例。正在开发这类业务的同学可以参考。
@Smallfly:这篇文章把 SDK 错误设计讲得很实用,提出用 struct + Code enum 组合来同时保证「错误码稳定」与「错误信息可读」。文中覆盖 LocalizedError、CustomNSError、模式匹配 catch 和上下文 userInfo 的完整实践,既方便客户端做分支处理,也方便监控系统长期追踪。对团队来说,这是一套很适合沉淀为工程规范的错误治理方案。
@Kyle-Ye: 文章介绍了在 SwiftUI 中实现反向遮罩的技巧——从视图中"挖出"形状以露出底层内容。核心方案是利用 .destinationOut blend mode 配合 .compositingGroup() 修饰符,将遮罩形状覆盖的区域从目标视图中擦除。文章封装了一个简洁的 reversedMask View 扩展,无需借助 Core Graphics 即可实现诸如毛玻璃镂空、网格卡片符号裁切等富有层次感的 UI 效果。对 SwiftUI 自定义视觉效果感兴趣的开发者值得一读。
@Damien: 研究员 wh1te4ever 利用苹果私有 Virtualization.framework 和 PCC 固件中的隐藏组件,在 Apple Silicon Mac 上实现了拥有 root 权限的 iOS 26 虚拟机(vphone)。与传统越狱不同,vphone 没有 Cydia 等文件特征,能透明绕过传统风控检测,且支持批量克隆和快照回滚,对黑产构成规模化威胁。为应对此挑战,作者提出 CloudPhoneRiskKit 3.0 四层防御体系,通过硬件指纹识别、多路径一致性校验、IMU 传感器行为熵分析和服务端动态策略进行纵深防御。该体系的核心思想是不追求单一"不可绕过"的检测,而是让攻击者的 patch 行为本身成为最强的风险信号,构建"绕过成本大于收益"的防御机制。
@david-clang:maderix/ANE 通过逆向私有 API,绕过 CoreML 框架,直接在 ANE 上进行神经网络的训练和推理调用,发现 ANE 宣传的 38 TOPS 实为 INT8 反量化至 FP16 的“数字游戏”。
maderix 经测试发现 ANE 本质上是一个内置约 32MB SRAM 的“卷积加速器”。1x1 卷积能走“专用超车道”,而矩阵乘法只能走低效的“备用通道”,导致两者吞吐量相差 3 倍。此外,ANE 的 16 个核心是基于深度流水线设计的,因此一次性打包提交包含数十个操作的“计算图”远比提交单个操作效率高。
另外,ANE 拥有极为强悍的硬件级电源门控(Power Gating)技术,它在空闲状态下,并非进入低功耗待机模式,而是做到完全断电、零泄漏,功耗为绝对的 0mW,这也解释了其在移动端设备上极佳的能效表现。有趣的是,可以看到 XNU 内核源码(osfmk/mach/coalition.h)也定义了 ane_energy_nj 字段统计 ANE 能耗。
@含笑饮砒霜:这个仓库主要是把 iOS 无障碍开发经验,整理成一个可供 AI 调用的“专家型 Skill ”,帮助 AI 更专业地给出 UIKit / SwiftUI 的无障碍实现建议、测试建议和设计判断。 它最大的价值不是“自动修复 accessibility ”,而是让 AI 回答这类问题时更像一个有经验的 iOS Accessibility reviewer。
@zhangferry:这个仓库是由 Swift 领域知名开发者 Paul Hudson(Hacking with Swift 博主)开源的 SwiftUI Pro Agent Skill 插件,主要功能是为 Agent 提供专业的 SwiftUI 开发能力。它主要包括这些能力:无障碍功能适配;使用规范 API 并能替换 deprecated API;基于 HIG 设计规范;导航功能设计规范;高性能的 SwiftUI 代码;数据流设计和管理的规范;视图结构和动画实现技巧。
如果使用 Claude 或 Codex 命令行工具仅执行安装指令就够了,如果是 Xcode(26.3 或以上) 还稍微有些特别。当前 Xcode 内的 Agent 仅 Codex 可以识别全局 Skill,Claude 的话还需要在 ~/Library/Developer/Xcode/CodingAssistant/ClaudeAgentConfig 这个目录下新建一个 skills 文件夹,手动把对应的 Skill 内容复制过去才能生效。
@阿权:HealthQL 是一款开源 Swift 库,简化 Apple HealthKit 数据查询:支持 SQL 语法和 Swift DSL(类型安全、链式调用)两种查询方式,覆盖步数、心率等常见健康数据,支持聚合、分组等操作,可通过 Swift Package Manager 安装,避免原生 HealthKit 的繁琐样板代码。
@Barney:这是一个面向 iOS 26 Liquid Glass 风格的自定义 Tab Bar 组件,重点不只是“做得像”,而是补上系统 Tab Bar 无法优雅承载悬浮主操作按钮的问题。作者指出,把 FAB 硬塞成一个 .search tab 虽然实现简单,但会带来语义错误、VoiceOver 识别不准,以及状态切换时的交互竞态。这个库对外提供 SwiftUI 接口,内部借助 UISegmentedControl 复用原生玻璃态反馈,再补齐悬浮按钮、安全区适配、重复点击回调和按状态隐藏等能力。代价是实现依赖 UIKit 私有层级细节,未来系统更新后可能失效,部分原生无障碍行为也难做到完全一致。适合想跟进 iOS 26 视觉风格,同时又对底部主操作入口有更强控制需求的项目参考。
重新开始更新「iOS 靠谱内推专题」,整理了最近明确在招人的岗位,供大家参考
具体信息请移步:https://www.yuque.com/iosalliance/article/bhutav 进行查看(如有招聘需求请联系 iTDriverr)
我们是「老司机技术周报」,一个持续追求精品 iOS 内容的技术公众号,欢迎关注。
关注有礼,关注【老司机技术周报】,回复「2024」,领取 2024 及往年内参

同时也支持了 RSS 订阅:https://github.com/SwiftOldDriver/iOS-Weekly/releases.atom 。
🚧 表示需某工具,🌟 表示编辑推荐
预计阅读时间:🐎 很快就能读完(1 - 10 mins);🐕 中等 (10 - 20 mins);🐢 慢(20+ mins)
本文是 为大型 iOS 工程补充单元测试方法论 的补充篇。前文提供了"画链路 → 选节点 → 写测试 → 融入迭代"的完整框架,覆盖了基础的 Mock 策略和用例设计原则。
本文聚焦以下问题:
传统的"从零覆盖"思路是:遍历方法的所有分支,为每个分支写用例。而在实际业务迭代中,更常见的场景是你刚修改了一段逻辑,需要快速验证变更的正确性。
变更驱动测试的核心思路:
识别本次变更引入的新分支或行为差异
为新分支写正向用例(验证新行为)
为旧分支写回归用例(验证未被破坏)
如果变更引入了新的数据源排除/包含逻辑,为排除和包含各写至少一条用例
当一次变更由特性开关(Feature Flag)控制时,同一个方法在 flag=true 和 flag=false 下有不同行为。此时必须成对测试:
| 用例类型 | 目的 | 示例 |
|---|---|---|
| flag=true 正向 | 验证新行为生效 |
shouldCountUnreadByCell=true 时 notice groups 被跳过,unreadCount 仅含 interactor 贡献 |
| flag=false 回归 | 验证旧行为未被破坏 |
shouldCountUnreadByCell=false 时 notice groups 仍参与累加 |
| flag=true 复合 | 新行为 + 多种过滤条件叠加 | flag=true + muted groups + shop groups + redPoint groups → 全部被跳过,仅剩 interactor |
关键原则:回归用例的重要性不低于正向用例。开发者常犯的错误是只测了新路径而遗漏了旧路径的回归验证,有可能改坏了旧路径的功能而未及时发现。
BizScenarioItemInboxTabNumber.checkHasNoticeTabbarUnreadCount: 在引入 shouldCountUnreadByCell 分支后,新增了 4 条用例:flag=true 跳过 notice groups、flag=true 时 cellCount 不受影响、flag=false 包含 notice groups(回归)、flag=true 复合场景。每条用例的 assertion message 都明确标注了 flag 状态和预期计算过程。
在 Service Locator 架构中,模块间的依赖通过协议(Protocol)解耦。被测代码通过 GET_CLASS(IMModuleService) 获取另一个模块提供的 Class,再调用其类方法。这带来了一个 Mock 难题:
IMModuleService 是协议,不是类,无法直接 swizzleGET_CLASS 返回 nilSwiftTestCase 的 serviceBehavior = .newCenter 会为每个测试创建隔离的 Service Center。利用基类提供的 mockGetStatelessProtocolService(_:andReturn:) 方法,将一个轻量 Mock 类注册到该 Center 中:
// 定义只实现所需类方法的 Mock 类
private class MockIMModuleServiceTrue: NSObject {
@objc class func shouldCountUnreadByCell() -> Bool { return true }
}
// 在测试中注册
if let proto = NSProtocolFromString("IMModuleService") {
mockGetStatelessProtocolService(proto, andReturn: MockIMModuleServiceTrue.self)
}
工作原理:
被测代码: [GET_CLASS(IMModuleService) shouldCountUnreadByCell]
↓
GET_CLASS 查询 Service Center → 返回 MockIMModuleServiceTrue.class
↓
[MockIMModuleServiceTrue shouldCountUnreadByCell] → YES
| 维度 | Runtime Swizzle | Service Center Mock |
|---|---|---|
| 适用场景 | 目标类已知且已链接 | 目标是协议,实现类不可见或位于其他模块 |
| 隔离性 | 全局替换,需手动恢复 | 仅在测试的隔离 Service Center 内生效,自动还原 |
| tearDown 负担 | 必须手动调用 restore()
|
无需手动清理 |
| 限制 | 需要已知类名和方法签名 | 仅适用于通过 GET_CLASS / Service Locator 解析的依赖 |
当被测方法通过以下宏/方式获取依赖时,优先使用 Service Center Mock:
GET_CLASS(Protocol) / GET_PROTOCOL(Protocol)
ServiceCenter.defaultCenter.getStatelessProtocolService()某些组件通过一个宽接口的 "Context" 协议获取运行时环境(数据字典、配置管理器、事件分发器等)。直接构造真实 Context 需要初始化整个管理器链路,测试成本极高。
private class MockUnreadCountContext: NSObject, UnreadCountContext {
var mockEntranceCountModelDict: [String: InboxEntranceUnreadCountModel] = [:]
var checkNeedUpdateCalled = false
var lastCheckScene: BizScenarioItemCheckScene = []
func entranceCountModelDict() -> [String: InboxEntranceUnreadCountModel]? {
return mockEntranceCountModelDict
}
func checkNeedUpdate(_ scene: BizScenarioItemCheckScene) {
checkNeedUpdateCalled = true
lastCheckScene = scene
}
// 其余方法空实现
}
| 要点 | 说明 |
|---|---|
| 只实现被测路径依赖的方法 | 非必需方法留空实现,降低维护成本 |
用 var 暴露可控数据 |
测试通过直接修改 mockEntranceCountModelDict 来控制输入 |
| Spy 能力 | 添加 checkNeedUpdateCalled / lastCheckScene 等标记,验证被测方法是否正确触发了 Context 上的副作用 |
| 弱引用安全 | Context 属性通常为 weak,确保 Mock 对象在测试期间被持有(存为实例属性) |
前文的"协议 Mock 对象"聚焦于数据提供者(如 NoticeUnreadCountItemProtocol),每个 Mock 只需返回数值。Fake Environment 聚焦于运行时环境,需要同时提供数据字典、触发副作用(如 checkNeedUpdate:)、并可能被多个被测方法共享。
聚合方法有两种常见语义,外部签名几乎相同,但行为差异大:
| 语义 | 含义 | 示例方法 |
|---|---|---|
| Sum | 将所有符合条件的项的值相加 |
countForNumber: → 返回 5 + 3 = 8 |
| Count | 统计符合条件且值 > 0 的项的个数 |
countForUnreadCell: → 返回 2(有 2 项非零) |
如果未来开发者误将 Count 语义改为 Sum 语义(或反过来),逻辑上仍然"能跑通",但业务含义错误。
构造让 Sum 和 Count 结果必然不同的测试数据,使得任何语义变更都会导致断言失败:
// count 为 5 和 3 → Sum = 8, Count = 2
// 如果断言 Count == 2,则改为 Sum 后结果变为 8,测试失败
func test_countForUnreadCell_countsEntrancesNotSumsCount() {
mockContext.mockEntranceCountModelDict = [
combinedKey(1): makeEntranceModel(entranceID: 1, count: 5),
combinedKey(2): makeEntranceModel(entranceID: 2, count: 3),
]
XCTAssertEqual(item.count(forUnreadCell: nil), 2,
"Cell count = number of entrances with unread, not sum of counts")
}
关键:选择每项 count > 1 的数据。如果所有 count 都为 1,则 Sum 和 Count 结果相同,无法区分语义。
此方法适用于所有存在语义歧义的聚合操作:
当同一份业务数据通过两个独立渠道到达聚合点时(如 notice_count 和 entrance_count 都包含通知未读数),需要在特定条件下去重,否则会出现重复计算。
构造"两个渠道都有数据"的场景,验证在去重开关开启时只有一路生效:
dataSource (notice groups) = { group100: 10, group200: 3 }
interactor (entrance items) = countForNumber: 5
shouldCountUnreadByCell=true → result = 5 (只用 interactor,跳过 dataSource)
shouldCountUnreadByCell=false → result = 18 (dataSource 13 + interactor 5)
设计要点:
底层数据的变更(标记已读、静音)需要正确传播到上层的聚合结果中。仅测试"model.count 被置 0"是不够的,因为聚合层可能因为缓存、过滤条件等原因未感知到变更。
在一个测试用例中同时操作底层和观察上层,形成"垂直切片":
func test_updateMuteStatus_muteExcludesFromCount() {
// 底层:构造 model
let model = makeEntranceModel(entranceID: 1, count: 5)
setUpEntranceModels([combinedKey(1): model])
// 上层:构造 aggregation item,共享同一个 model
let countItem = InboxEntranceUnreadCountItem()
let ctx = MockUnreadCountContext()
ctx.mockEntranceCountModelDict = [combinedKey(1): model]
countItem.context = ctx
XCTAssertEqual(countItem.count(forNumber: nil), 5, "Before mute")
// 执行变更
service.updateMuteStatus(true, forEntranceID: 1, subEntranceKey: nil)
// 验证传播:上层聚合结果反映了底层变更
XCTAssertEqual(countItem.count(forNumber: nil), 0, "After mute, excluded from count")
}
垂直切片测试严格来说介于单元测试和集成测试之间。在大型工程中,它的性价比很高:不需要启动完整的 Service 链路,但能验证两层之间的契约是否正确。推荐在以下情况使用:
某些遍历方法在找到第一个匹配项后会 stop(*stop = YES),不再继续遍历。如果去掉 stop,方法签名和大部分行为不变,但在存在多个同类型 item 时会错误地累加。
func test_countForNumberWithType_stopsAfterFirstMatch() {
addMockItem(showType: .number, countForNumber: 10, itemType: .entranceCountItem)
addMockItem(showType: .number, countForNumber: 5, itemType: .entranceCountItem)
XCTAssertEqual(
interactor.count(forNumber: nil, withUnreadCountItemType: .entranceCountItem), 10,
"Should stop after first matching item"
)
}
如果 stop 被移除,结果会变为 15,测试失败。
enumerateObjectsUsingBlock: + *stop = YES 的 ObjC 代码| 场景 | 推荐模式 | 本文章节 |
|---|---|---|
| 验证一次代码变更 | 变更驱动测试 + 双态 Flag 测试 | 二 |
| 被测方法依赖跨模块协议(通过 Service Locator) | Service Center Protocol Mock | 三 |
| 被测对象通过宽接口 Context 获取环境 | Fake Environment 模式 | 四 |
| 聚合方法的 Sum/Count 语义容易被误改 | 聚合语义测试 | 五 |
| 同一数据有两个来源、需条件性去重 | 数据源去重测试 | 六 |
| 底层变更需传播到上层聚合结果 | Mutation-Aggregation 垂直切片 | 七 |
| 遍历方法有 stop/短路行为 | 短路行为测试 | 八 |
这些模式与前文的基础方法论互补使用。基础方法论解决"测什么"和"怎么 Mock"的问题,本文解决"改了代码后怎么精准验证"和"复杂依赖场景下怎么构造可控环境"的问题。

最近读完近期研读了哈佛大学进化生物学教授丹尼尔·利伯曼的著作《锻炼》,该书从进化生物学的视角,系统阐述了人类运动的本质及其对现代健康的重要性。本文将对书中核心观点进行梳理与总结。
利伯曼教授在书中开篇即指出,从进化角度看,锻炼在某种程度上是“反人性”的。人类基因在漫长的演化过程中,倾向于节约能量以应对生存挑战,如应对饥荒或繁殖需求,而非主动追求高强度体力活动。
然而,随着现代社会工具的普及,体力劳动显著减少,而人类的生理机制尚未完全适应这种快速变化的环境。因此,为了弥补体力活动不足带来的健康赤字,有意识的“锻炼”成为现代人维持健康的必要手段。值得注意的是,作者强调锻炼与娱乐性体育活动并非等同概念。
所以,我们需要接纳现在的自己,并意识到锻炼是反人性的。
长期处于静态或低活动状态,可能引发慢性炎症反应,其机制主要包括:
运动可以有效的抑制以上炎症反应。
人体主要通过三磷酸腺苷(ATP)水解释放能量。ATP水解生成二磷酸腺苷(ADP)和磷酸,并释放能量和氢离子。ADP可通过“充电”过程,即利用糖分子和脂肪分子的化学反应,重新转化为ATP。
在运动过程中,能量供应遵循一定顺序:
在静息状态下,身体约70%的能量来源于脂肪的缓慢燃烧。然而,随着运动强度的增加,对糖的燃烧需求也随之增加。当运动强度超过有氧能力极限时,能量供应将完全依赖于糖的无氧分解。
肌肉由大量长而薄的细胞组成,称为肌纤维,每个肌纤维由数千个肌原纤维组成。再细分,肌原纤维包含数千个名为肌节的带状组织。肌节由两种重要蛋白质组成,一种细,一种粗,彼此交错,就像双手合十时手指那样。这种结构可以生成拉力,当神经向肌肉发出电信号时,就像两队拔河的人拉绳子一样,肌肉收缩的动作就发生了。
人体的肌肉纤维分为慢肌纤维和快肌纤维。
人体很多肌肉的快肌纤维与慢肌纤维的比例大约都是 1:1。但是对于三头肌等用来发力的肌肉,快肌纤维比例就会达到 70%,而对于那些用来走路的肌肉,比如小腿的肌肉,慢肌纤维的比例就会到达 85%。
多数心脏相关疾病源于心脏自身病变或血管问题。
动脉粥样硬化是动脉硬化的起始阶段,表现为动脉壁内斑块积聚。这些斑块由脂肪、胆固醇和钙等物质混合而成。为应对斑块对动脉壁的刺激和损伤,白细胞会启动炎症反应,将这些物质包裹并使其硬化,导致斑块逐渐增大。斑块若完全阻塞动脉或脱落后阻塞其他部位小动脉,均可导致严重后果。
高血压对心脏构成慢性损伤。长期高血压状态下,心脏为维持正常功能会增厚心肌壁,但增厚的心肌壁会逐渐硬化并被疤痕组织取代,最终导致心功能下降。
心肺训练被普遍认为是维护心血管系统的最佳运动方式。
胆固醇检测通常测量血液中三种分子的水平:
低密度脂蛋白(LDL): 常被称为“坏胆固醇”。肝脏生成的气球状分子,负责在血液中运输脂肪和胆固醇。然而,某些LDL分子可能破坏并侵入动脉壁,尤其在高血压状态下,引发炎症反应并形成斑块。
高密度脂蛋白(HDL): 有时被称为“好胆固醇”。这些微小颗粒能清除LDL,并将其运回肝脏进行代谢。
甘油三酯: 自由漂浮在血液中的脂肪颗粒,是代谢综合征的重要标志物。
作者建议,成年人每周应至少进行5次,每次至少30分钟的中等强度至高强度有氧训练。
最大心率的估算方法通常为220减去年龄。根据作者研究,达到上述锻炼时长可将全因死亡率降低一半。即使进一步延长锻炼时间,全因死亡率仍会下降,但下降幅度趋缓(如下图)。
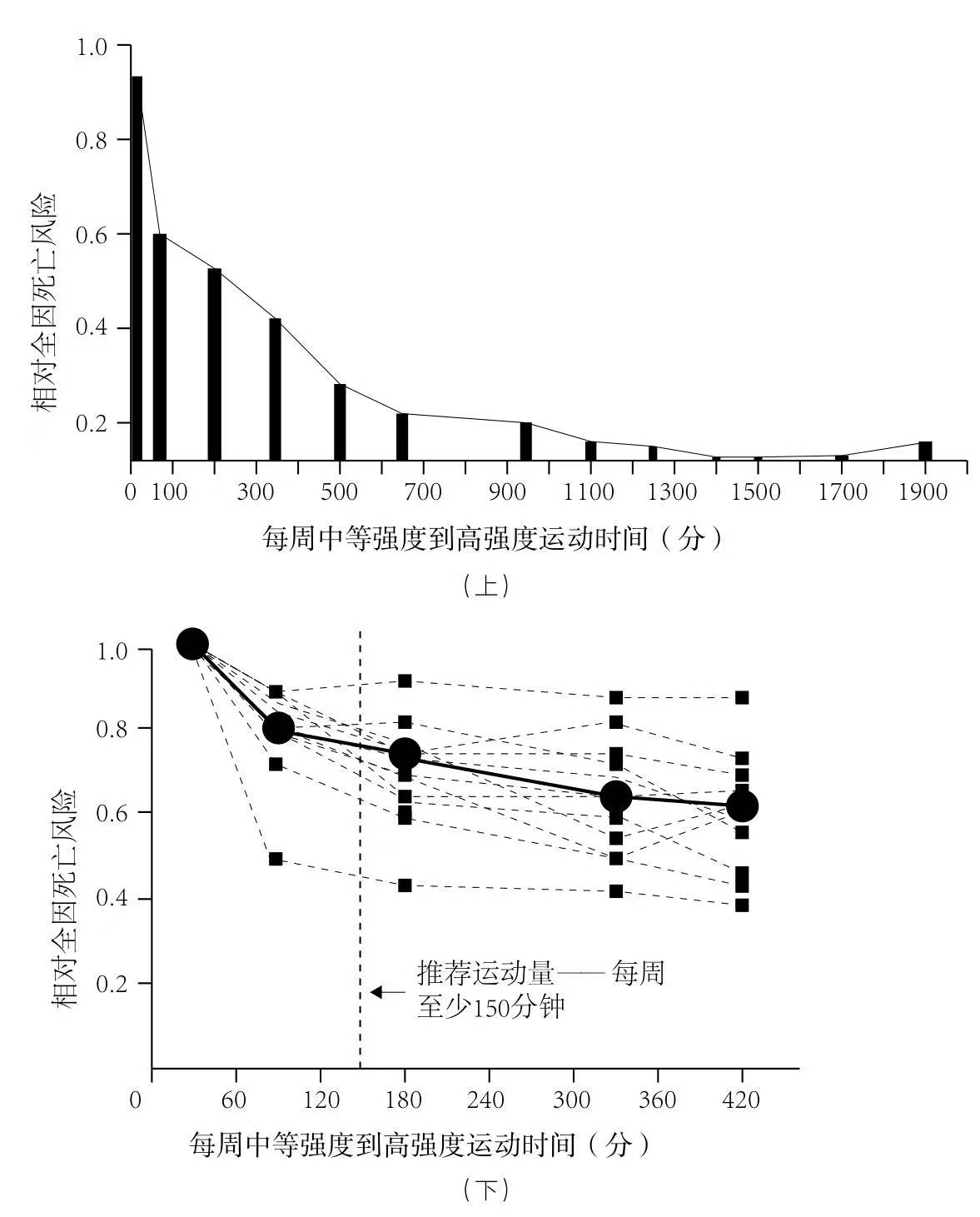
此外,作者还建议每周进行两次肌肉力量增强训练,涵盖所有大肌肉群(包括腿、臀、背、核心、肩和臂),并确保每次训练后有足够的恢复时间。每个部位重复练习8~12次,进行2到3组。
《锻炼》一书深刻阐明了运动对人体健康的科学益处,尤其强调了训练强度和时长的重要性。书中提出的每周150分钟有氧训练加两次力量训练的目标,为我们提供了长期健康管理的重要指引。期望读者能从中汲取知识,并将其融入日常生活中,以期实现更健康的生活方式。
SwiftUI 动画非常简单,只需添加 .animation:
struct AnimationView: View {
@State private var isExpanded = false
var body: some View {
VStack {
RoundedRectangle(cornerRadius: isExpanded ? 50 : 10)
.fill(isExpanded ? Color.blue : Color.red)
.frame(
width: isExpanded ? 300 : 100,
height: isExpanded ? 300 : 100
)
.animation(.spring(response: 0.3, dampingFraction: 0.5), value: isExpanded)
Button("切换") {
isExpanded.toggle()
}
}
}
}
**动画类型: **
.default - 默认动画
.linear - 线性
.easeIn / .easeOut / .easeInOut - 缓动
.spring() - 弹性动画
.interactiveSpring() - 交互式弹性
struct GestureView: View {
@State private var offset: CGSize = .zero
@State private var scale: CGFloat = 1.0
@State private var rotation: Angle = .zero
var body: some View {
Image(systemName: "star.fill")
.font(.system(size: 100))
.foregroundColor(.yellow)
.offset(offset)
.scaleEffect(scale)
.rotationEffect(rotation)
.gesture(
DragGesture()
.onChanged { gesture in
offset = gesture.translation
}
.onEnded { _ in
withAnimation {
offset = .zero
}
}
)
.gesture(
MagnificationGesture()
.onChanged { scale = $0 }
)
.gesture(
RotationGesture()
.onChanged { rotation = $0 }
)
}
}
import SwiftUI
struct TodoItem: Identifiable, Codable {
let id: UUID
var title: String
var isCompleted: Bool
var createdAt: Date
}
class TodoStore: ObservableObject {
@Published var todos: [TodoItem] = []
private let saveKey = "todos"
init() {
load()
}
func add(_ title: String) {
let todo = TodoItem(
id: UUID(),
title: title,
isCompleted: false,
createdAt: Date()
)
todos.append(todo)
save()
}
func toggle(_ todo: TodoItem) {
if let index = todos.firstIndex(where: { $0.id == todo.id }) {
todos[index].isCompleted.toggle()
save()
}
}
func delete(at offsets: IndexSet) {
todos.remove(atOffsets: offsets)
save()
}
// UserDefaults 存储
private func save() {
if let encoded = try? JSONEncoder().encode(todos) {
UserDefaults.standard.set(encoded, forKey: saveKey)
}
}
private func load() {
if let data = UserDefaults.standard.data(forKey: saveKey),
let decoded = try? JSONDecoder().decode([TodoItem].self, from: data) {
todos = decoded
}
}
}
想象一个场景:
用户点击按钮
App 需要从网络加载图片
如果用同步方式,界面会卡住,直到图片加载完成
用户看到"假死",体验极差
**并发让 App 能同时做多件事: **
主线程:响应用户操作、更新界面
后台线程:网络请求、文件读写、复杂计算
// 旧的写法(仍然有效,但不推荐新代码使用)
DispatchQueue.global().async {
// 后台线程执行耗时操作
let data = try! Data(contentsOf: url)
DispatchQueue.main.async {
// 主线程更新 UI
imageView.image = UIImage(data: data)
}
}
**问题: **
嵌套层级深(回调地狱)
错误处理麻烦
代码难以阅读和维护
// 定义异步函数
func fetchImage(from url: URL) async throws -> UIImage {
let (data, _) = try await URLSession.shared.data(from: url)
guard let image = UIImage(data: data) else {
throw ImageError.invalidData
}
return image
}
// 调用异步函数
func loadImage() async {
do {
let image = try await fetchImage(from: imageURL)
imageView.image = image
} catch {
print("加载失败: \(error)")
}
}
**代码看起来像同步的,实际上是异步执行的! **
struct AsyncImageView: View {
@State private var image: UIImage?
@State private var isLoading = false
let url: URL
var body: some View {
Group {
if let image = image {
Image(uiImage: image)
.resizable()
.aspectRatio(contentMode: .fit)
} else if isLoading {
ProgressView()
} else {
Image(systemName: "photo")
.font(.largeTitle)
.foregroundColor(.gray)
}
}
.onAppear {
loadImage()
}
}
private func loadImage() {
isLoading = true
Task {
do {
let (data, _) = try await URLSession.shared.data(from: url)
await MainActor.run {
self.image = UIImage(data: data)
self.isLoading = false
}
} catch {
await MainActor.run {
self.isLoading = false
}
}
}
}
}
**Task: **创建异步任务的环境
**MainActor: **确保代码在主线程执行(用于 UI 更新)
// 顺序执行(慢)
func fetchSequentially() async throws -> [User] {
let user1 = try await fetchUser(id: 1)
let user2 = try await fetchUser(id: 2)
let user3 = try await fetchUser(id: 3)
return [user1, user2, user3]
}
// 并行执行(快!)
func fetchConcurrently() async throws -> [User] {
async let user1 = fetchUser(id: 1)
async let user2 = fetchUser(id: 2)
async let user3 = fetchUser(id: 3)
return try await [user1, user2, user3]
}
// 使用 TaskGroup 处理动态数量的任务
func fetchUsers(ids: [Int]) async throws -> [User] {
try await withThrowingTaskGroup(of: User.self) { group in
for id in ids {
group.addTask {
try await fetchUser(id: id)
}
}
var users: [User] = []
for try await user in group {
users.append(user)
}
return users
}
}
**async let: **启动并行任务
**withTaskGroup: **管理一组动态任务
// 异步序列
let stream = AsyncStream<Int> { continuation in
Task {
for i in 1...5 {
try? await Task.sleep(for: .seconds(1))
continuation.yield(i)
}
continuation.finish()
}
}
// 遍历
for await number in stream {
print("收到: \(number)")
}
class UnsafeCounter {
var count = 0
func increment() {
count += 1 // 非线程安全!
}
}
let counter = UnsafeCounter()
// 从多个线程同时增加
DispatchQueue.concurrentPerform(iterations: 1000) { _ in
counter.increment()
}
// 结果可能小于 1000!
print(counter.count)
原因: count += 1 实际上分三步:
读取 count 的值
加 1
写回 count
如果两个线程同时执行,可能都读到 5,都变成 6,结果只增加了 1。
actor SafeCounter {
private var count = 0
func increment() {
count += 1 // 线程安全!
}
func getCount() -> Int {
return count
}
}
let counter = SafeCounter()
await withTaskGroup(of: Void.self) { group in
for _ in 0..<1000 {
group.addTask {
await counter.increment()
}
}
}
let finalCount = await counter.getCount()
print(finalCount) // 1000
**Actor 的特点: **
同一时间只有一个线程能访问 actor 内部
自动防止数据竞争
访问 actor 的属性和方法需要 await
@MainActor
class ViewModel: ObservableObject {
@Published var items: [Item] = []
func load() async {
items = await fetchItems() // await 切到后台
// 自动回到主线程
}
}
// 或者只标记某个方法
class ViewModel2: ObservableObject {
@Published var items: [Item] = []
@MainActor
func updateUI() {
// 确保在主线程执行
items.append(newItem)
}
}
// 安全的值类型,可以跨 actor 传递
struct UserData: Sendable {
let id: UUID
let name: String
}
// 类也可以遵循 Sendable,但需要是 final 且属性都是 Sendable
final class SafeClass: Sendable {
let value: Int
init(value: Int) {
self.value = value
}
}
**Swift 6 会强制检查: **如果类型不是 Sendable,不能跨 actor 传递。
第一次做分享,期待更优秀的你~
SwiftUI 是 Apple 在 2019 年推出的声明式 UI 框架,用来替代 UIKit。它的核心理念是:
**告诉 SwiftUI "你想要什么界面",而不是 "怎么创建界面"。 **
对比:
**UIKit(命令式) **:创建视图 → 添加到父视图 → 设置约束 → 手动更新
**SwiftUI(声明式) **:描述界面状态,SwiftUI 自动处理更新
在 Xcode 中创建 SwiftUI 项目,替换 ContentView.swift:
import SwiftUI
struct ContentView: View {
var body: some View {
Text("Hello, World!")
.font(.largeTitle)
.foregroundColor(.blue)
.padding()
}
}
#Preview {
ContentView()
}
**关键概念: **
View 协议:所有 UI 元素都遵循这个协议
body:计算属性,返回视图层级
修饰符(modifier):用 . 链式调用,修改视图样式
SwiftUI 中,视图是函数:输入相同的状态,输出相同的界面。
struct CounterView: View {
// @State 标记可变状态
@State private var count = 0
var body: some View {
VStack(spacing: 20) {
Text("Count: \(count)")
.font(.largeTitle)
Button("Increment") {
count += 1 // 修改状态,自动刷新界面
}
.buttonStyle(.borderedProminent)
}
}
}
** @State 的特点: **
用于视图内部状态
SwiftUI 自动管理存储
值改变时自动重绘视图
struct LayoutDemoView: View {
var body: some View {
VStack(spacing: 20) { // 垂直堆栈
Text("上方")
HStack(spacing: 20) { // 水平堆栈
Text("左")
.frame(maxWidth: .infinity)
.background(Color.red.opacity(0.3))
Text("中")
.frame(maxWidth: .infinity)
.background(Color.green.opacity(0.3))
Text("右")
.frame(maxWidth: .infinity)
.background(Color.blue.opacity(0.3))
}
ZStack { // 重叠堆栈
Circle()
.fill(Color.yellow)
.frame(width: 100, height: 100)
Text("Z")
.font(.largeTitle)
}
Text("下方")
}
.padding()
}
}
**三种 Stack: **
VStack - 垂直排列
HStack - 水平排列
ZStack - 前后叠加
struct ControlsView: View {
@State private var text = ""
@State private var isOn = false
@State private var sliderValue = 50.0
@State private var selectedDate = Date()
@State private var selectedColor = Color.red
var body: some View {
Form { // 表单,自动处理滚动和布局
Section("输入") {
TextField("请输入", text: $text)
SecureField("密码", text: $text) // 密码输入
TextEditor(text: $text) // 多行文本
}
Section("选择") {
Toggle("开关", isOn: $isOn)
Slider(value: $sliderValue, in: 0...100) {
Text("滑动条")
}
DatePicker("日期", selection: $selectedDate)
ColorPicker("颜色", selection: $selectedColor)
}
Section("按钮") {
Button("普通按钮") {}
Button(action: {}) {
Label("带图标的按钮", systemImage: "star.fill")
}
Button("主要按钮") {}
.buttonStyle(.borderedProminent)
Button("胶囊按钮") {}
.buttonStyle(.bordered)
.controlSize(.large)
.tint(.green)
}
}
}
}
注意 **$** 符号: $text 是 text 的绑定(Binding),双向数据流。
// 数据模型
struct Restaurant: Identifiable {
let id = UUID()
let name: String
let cuisine: String
let rating: Double
}
struct RestaurantRow: View {
let restaurant: Restaurant
var body: some View {
HStack {
VStack(alignment: .leading) {
Text(restaurant.name)
.font(.headline)
Text(restaurant.cuisine)
.font(.subheadline)
.foregroundColor(.secondary)
}
Spacer()
HStack {
Image(systemName: "star.fill")
.foregroundColor(.yellow)
Text(String(format: "%.1f", restaurant.rating))
}
}
}
}
struct RestaurantListView: View {
let restaurants = [
Restaurant(name: "川味轩", cuisine: "川菜", rating: 4.5),
Restaurant(name: "金鼎轩", cuisine: "粤菜", rating: 4.2),
Restaurant(name: "日料屋", cuisine: "日料", rating: 4.8)
]
var body: some View {
NavigationView {
List(restaurants) { restaurant in
NavigationLink(destination: RestaurantDetailView(restaurant: restaurant)) {
RestaurantRow(restaurant: restaurant)
}
}
.navigationTitle("餐厅列表")
}
}
}
struct RestaurantDetailView: View {
let restaurant: Restaurant
var body: some View {
VStack(spacing: 20) {
Image(systemName: "fork.knife.circle.fill")
.resizable()
.frame(width: 100, height: 100)
.foregroundColor(.orange)
Text(restaurant.name)
.font(.largeTitle)
Text(restaurant.cuisine)
.font(.title2)
.foregroundColor(.secondary)
HStack {
ForEach(0..<Int(restaurant.rating), id: \.self) { _ in
Image(systemName: "star.fill")
.foregroundColor(.yellow)
}
}
Spacer()
}
.padding()
.navigationTitle("详情")
}
}
**关键概念: **
Identifiable 协议:让数据可以被列表唯一标识
List:自动处理行、分隔线、滑动删除
NavigationView + NavigationLink:页面跳转
当子视图需要修改父视图的状态时:
// 子视图
struct ToggleView: View {
@Binding var isOn: Bool // 绑定,不是自己的状态
var body: some View {
Toggle("开关", isOn: $isOn)
}
}
// 父视图
struct ParentView: View {
@State private var lightOn = false
var body: some View {
ToggleView(isOn: $lightOn) // 传递绑定
}
}
对于复杂数据模型,使用 ObservableObject:
import Combine
class TaskStore: ObservableObject {
@Published var tasks: [Task] = []
@Published var filter: TaskFilter = .all
var filteredTasks: [Task] {
switch filter {
case .all: return tasks
case .active: return tasks.filter { !$0.isCompleted }
case .completed: return tasks.filter { $0.isCompleted }
}
}
func addTask(_ title: String) {
tasks.append(Task(title: title))
}
func toggleTask(_ task: Task) {
if let index = tasks.firstIndex(where: { $0.id == task.id }) {
tasks[index].isCompleted.toggle()
}
}
}
struct TaskListView: View {
@StateObject private var store = TaskStore() // 创建可观察对象
var body: some View {
List {
ForEach(store.filteredTasks) { task in
TaskRow(task: task) {
store.toggleTask(task)
}
}
}
}
}
** @StateObject vs @ObservedObject: **
@StateObject:创建并持有对象(用这个视图创建的数据)
@ObservedObject:引用外部传入的对象
struct ContentView: View {
@Environment(\.colorScheme) var colorScheme
@Environment(\.dismiss) var dismiss
var body: some View {
VStack {
Text(colorScheme == .dark ? "Dark Mode" : "Light Mode")
Button("关闭") {
dismiss() // 关闭当前页面
}
}
}
}
SwiftUI 动画非常简单,只需添加 .animation:
struct AnimationView: View {
@State private var isExpanded = false
var body: some View {
VStack {
RoundedRectangle(cornerRadius: isExpanded ? 50 : 10)
.fill(isExpanded ? Color.blue : Color.red)
.frame(
width: isExpanded ? 300 : 100,
height: isExpanded ? 300 : 100
)
.animation(.spring(response: 0.3, dampingFraction: 0.5), value: isExpanded)
Button("切换") {
isExpanded.toggle()
}
}
}
}
**动画类型: **
.default - 默认动画
.linear - 线性
.easeIn / .easeOut / .easeInOut - 缓动
.spring() - 弹性动画
.interactiveSpring() - 交互式弹性
struct GestureView: View {
@State private var offset: CGSize = .zero
@State private var scale: CGFloat = 1.0
@State private var rotation: Angle = .zero
var body: some View {
Image(systemName: "star.fill")
.font(.system(size: 100))
.foregroundColor(.yellow)
.offset(offset)
.scaleEffect(scale)
.rotationEffect(rotation)
.gesture(
DragGesture()
.onChanged { gesture in
offset = gesture.translation
}
.onEnded { _ in
withAnimation {
offset = .zero
}
}
)
.gesture(
MagnificationGesture()
.onChanged { scale = $0 }
)
.gesture(
RotationGesture()
.onChanged { rotation = $0 }
)
}
}
import SwiftUI
struct TodoItem: Identifiable, Codable {
let id: UUID
var title: String
var isCompleted: Bool
var createdAt: Date
}
class TodoStore: ObservableObject {
@Published var todos: [TodoItem] = []
private let saveKey = "todos"
init() {
load()
}
func add(_ title: String) {
let todo = TodoItem(
id: UUID(),
title: title,
isCompleted: false,
createdAt: Date()
)
todos.append(todo)
save()
}
func toggle(_ todo: TodoItem) {
if let index = todos.firstIndex(where: { $0.id == todo.id }) {
todos[index].isCompleted.toggle()
save()
}
}
func delete(at offsets: IndexSet) {
todos.remove(atOffsets: offsets)
save()
}
// UserDefaults 存储
private func save() {
if let encoded = try? JSONEncoder().encode(todos) {
UserDefaults.standard.set(encoded, forKey: saveKey)
}
}
private func load() {
if let data = UserDefaults.standard.data(forKey: saveKey),
let decoded = try? JSONDecoder().decode([TodoItem].self, from: data) {
todos = decoded
}
}
}
2026年3月12日,苹果突然宣布中国区AppStore官方抽成从 30% 改为 25%,小型开发者抽成从15% 改为 12%。2026年3月15日生效。来源
想必,今天大家都被这个截图刷屏了吧。
为什么说“紧急”呢?
1、“根据与中国监管部门的沟通”,写得很清楚,是中国监管部门推动的;
2、“自3月15日起”,约等于立刻生效,对比谷歌的三个月后生效,凸显一个“急”;
3、“调整无需开发者在此之前签署新条款”,手续流程都免了,直接生效!
2、“更新版协议的简体中文版将于一个月内在 Apple开发者网站上线”,流程后面再补,先上线!
不知道苹果发生了什么,但是感觉很爽。有种苹果被工信部发了违规整改通知的感觉(DDDD),让苹果也尝尝工信部的厉害,马上整改,立刻上线!哈哈哈。
中国开发者什么都不用做,代码都不用改,就额外增(bai)加(piao) 3%~5% 的收益。
感谢那些为此做出贡献的人!
补充:有律师说出了苹果紧急“降税”的真相 ,有兴趣的可以点开看看。
苹果紧急降低抽成除了迫于监管压力,估计也迫于竞争对手的压力。
早在3月4日,谷歌在安卓开发者网站发布了一篇博客《选择和开放的新时代》,宣布将陆续在全球降低抽成,开放第三方支付,并且后续除了《小型开发者计划》外,还会新推出《应用体验计划》和《游戏升级计划》来让利开发者。
《应用体验计划》《游戏升级计划》的本质:质量换费率。通过经济激励(降低费率)来引导开发者提升应用和游戏的整体品质。开发者必须达到相应的技术集成和体验标准,来满足计划条件,才能获得费率减免。举例说明,比如,游戏类必须集成 Play Games Services 功能(如成就系统、现代玩家个人资料认证)。Play Console 中的“Android Vitals”指标,确保应用在崩溃率、ANR(无响应)率等方面符合谷歌的健康度标准。
计划的具体内容,谷歌尚未公布。
谷歌将现有的抽成拆成了两部分:
Google商店服务费:标准20%、参加上述新计划15%、小型开发者10%、订阅10%(取最小值)
Google支付服务费:约5%(每个地区可能不一样)
在美国、英国和欧洲经济区 (EEA),支付服务费为 5%。其他地区的支付服务费详情谷歌后续公布。
商店服务费,只要你在谷歌商店上架就要交,不管你用谷歌支付还是三方支付;
支付服务费,用谷歌支付就要交,用三方支付不交。
谷歌最终抽成比例:
官方支付抽成:15%~25%
三方支付抽成:10%~20%
谷歌新政策全球上线后,官方支付和三方支付只差5%,三方支付还得加上3%左右的通道费,和官方支付相比,三方支付毫无竞争力,这也是为什么谷歌敢在全球开放三方支付的原因。
需要注意的是,这次费率变化并非即刻生效,而是将分时间、逐步在全球不同地区推广:
| 各区域的推出日期 | 地区 | 《应用体验计划》《游戏升级计划》上线地区 |
|---|---|---|
| 2026年6月30日 | 欧洲经济区、英国、美国 | |
| 2026年9月30日 | 澳大利亚 | 澳大利亚、欧洲经济区、英国、美国 |
| 2026年12月31日 | 日本、韩国 | 日本、韩国 |
| 2027年9月30日 | 世界其他地区 | 世界其他地区 |
目前,谷歌和苹果,在全球都面临着反垄断、三方支付、三方商店的压力,革命一旦发起,就像星星之火一样会传递到全世界,一会这个国家闹,一会那个国家闹。面对这样的情况,谷歌和苹果却走出了不一样的应对路数。
谷歌,将在2026年到2027年陆续在全球执行统一的新标准,开放三方支付、开放三方商店。
Google商店服务费:标准20%、参加上述新计划15%、小型开发者10%、订阅10%(取最小值)
Google支付服务费:约5%(每个地区可能不一样)
官方支付抽成:15%~25%
三方支付抽成:10%~20%
全球实行时间线:
| 各区域的推出日期 | 地区 | 《应用体验计划》《游戏升级计划》上线地区 |
|---|---|---|
| 2026年6月30日 | 欧洲经济区、英国、美国 | |
| 2026年9月30日 | 澳大利亚 | 澳大利亚、欧洲经济区、英国、美国 |
| 2026年12月31日 | 日本、韩国 | 日本、韩国 |
| 2027年9月30日 | 世界其他地区 | 世界其他地区 |
从目前来看,苹果是按闹施政,谁闹我就便宜点,不闹就维持原样。但感觉不是长久之计,说不定苹果后续也会像谷歌那样统一标准。目前情况来看,谷歌还是眼光更长远一些,走在了前面,胸襟更大。
以下是苹果当前(2026.3.13)全球费率情况
| 地区 | 官方内购参考佣金 | 三方支付苹果抽成 | 备注 |
|---|---|---|---|
| 欧盟 | 13% - 20%,官方文档 | 15%~20% | 欧盟计费很复杂,还会按安装量抽成 |
| 日本 | 15% - 26%,官方文档 | 10%~15%,外部链接购买 10%~21%,应第三方购买 | |
| 韩国 | 15% ~ 30% | 11% ~ 26% | |
| 美国 | 15% - 30% | 0%,外部链接购买 | 海外公司可以申请;必须同时提供内购作为备选;仍然向苹果上报收入用于审计 |
| 中国 | 12% ~ 25%,官方文档 | 不允许三方支付 | |
| 其它 | 15% ~ 30% | 不允许三方支付 |
和谷歌一样,苹果也把抽成拆了商店服务费+支付服务费,从上表可以看到三方支付和官方支付比也没有优势。
美国外链支付比较特殊,可以做到0%费率,但同样要满足三方支付的苛刻条件:必须接入官方内购作为备选、有苹果警告弹窗、仍然需要上报三方收入给苹果审计。
如果你对三方支付感兴趣可以看看我往期文档《三方支付真的香吗?日本iOS、Google三方支付调研报告 》,这篇虽然讲得是日本,但三方支付的接入流程和要求,全球都是一样的。