Swift 新并发框架之 async/await
1. 为什么需要 async/await 在移动开发里,“并发/异步”几乎无处不在:网络请求、图片下载、文件读写、数据库操作……它们都有一个共同特点: 耗时(如果你在主线程里死等,会卡 UI) 结果稍

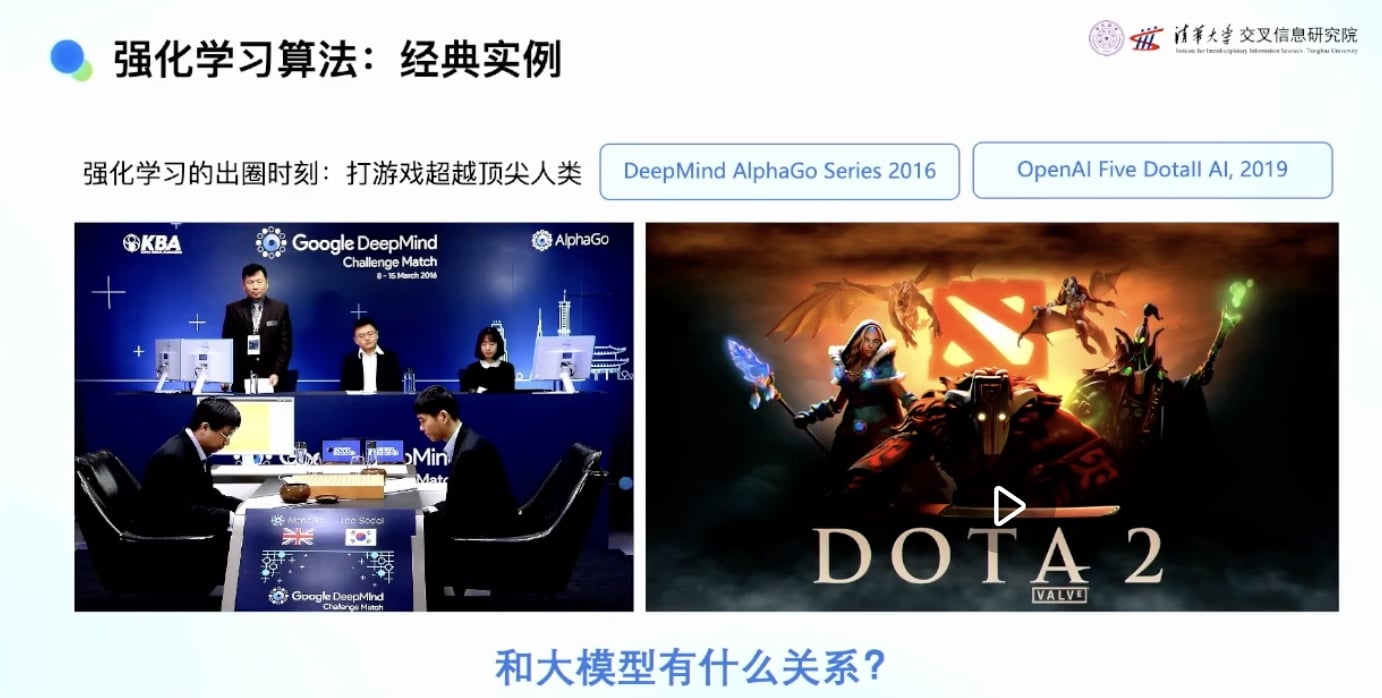
大多数人对强化学习的认知来源于:
当年的强化学习智能体主要都是打游戏的,与大模型驱动的AGI时代似乎没有太大关系。
2020-2022年的关键变化
GPT-3 API的问题:
注: “Next Token Prediction”(下一个 token 预测)是大语言模型(LLM)的核心机制。简单来说,它的意思是:给定一段文本的前面部分,模型预测接下来最可能出现的“token”是什么。
RLHF技术的突破:
注: RLHF(Reinforcement Learning from Human Feedback,基于人类反馈的强化学习)是一种用于对齐大语言模型(LLM)的技术。它的核心目标是:让模型的输出更符合人类的偏好、价值观和意图,而不仅仅是“语法正确”或“统计上常见”。
第一阶段:2022年ChatGPT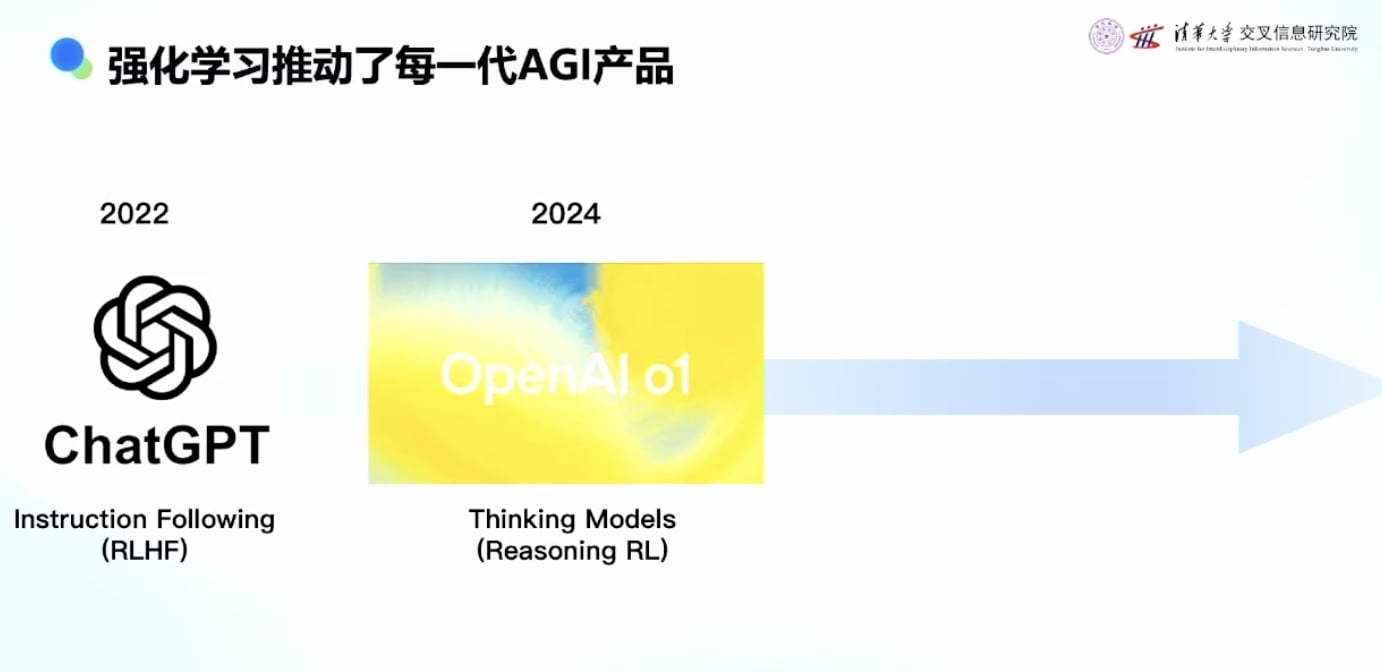
第二阶段:2024年推理模型(Reasoning Model)
第三阶段:2025年Agent模型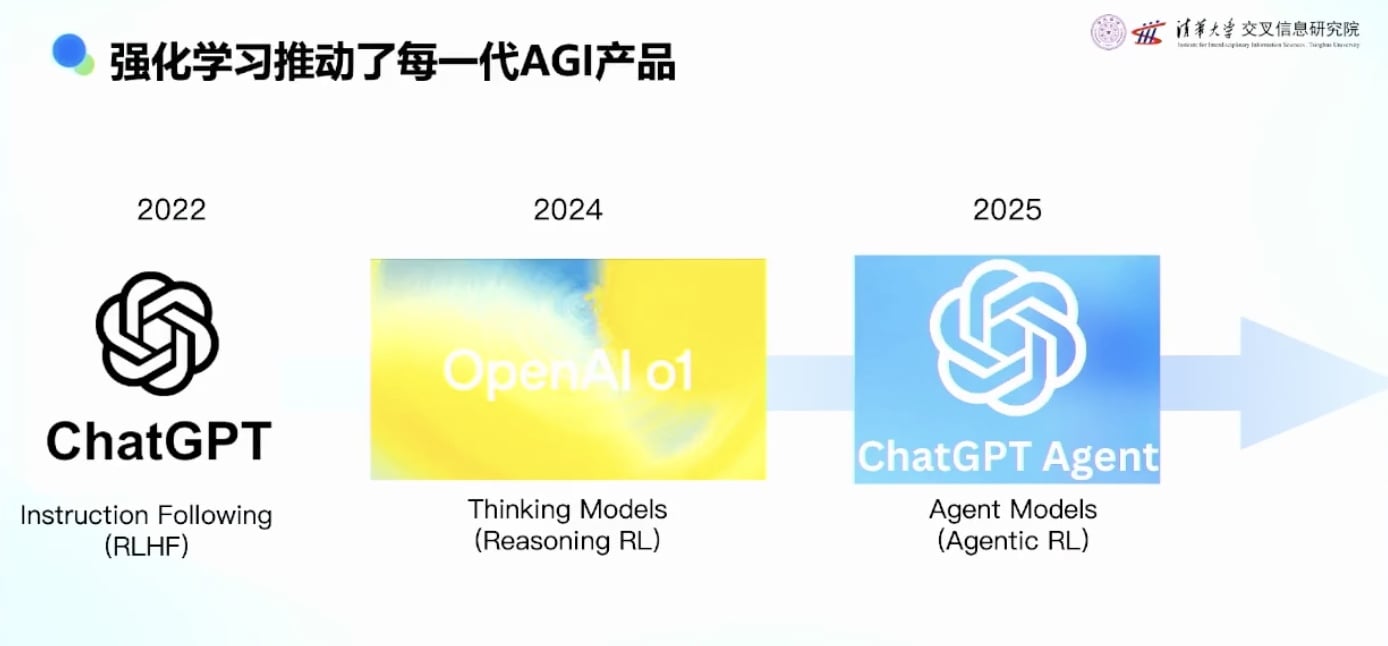
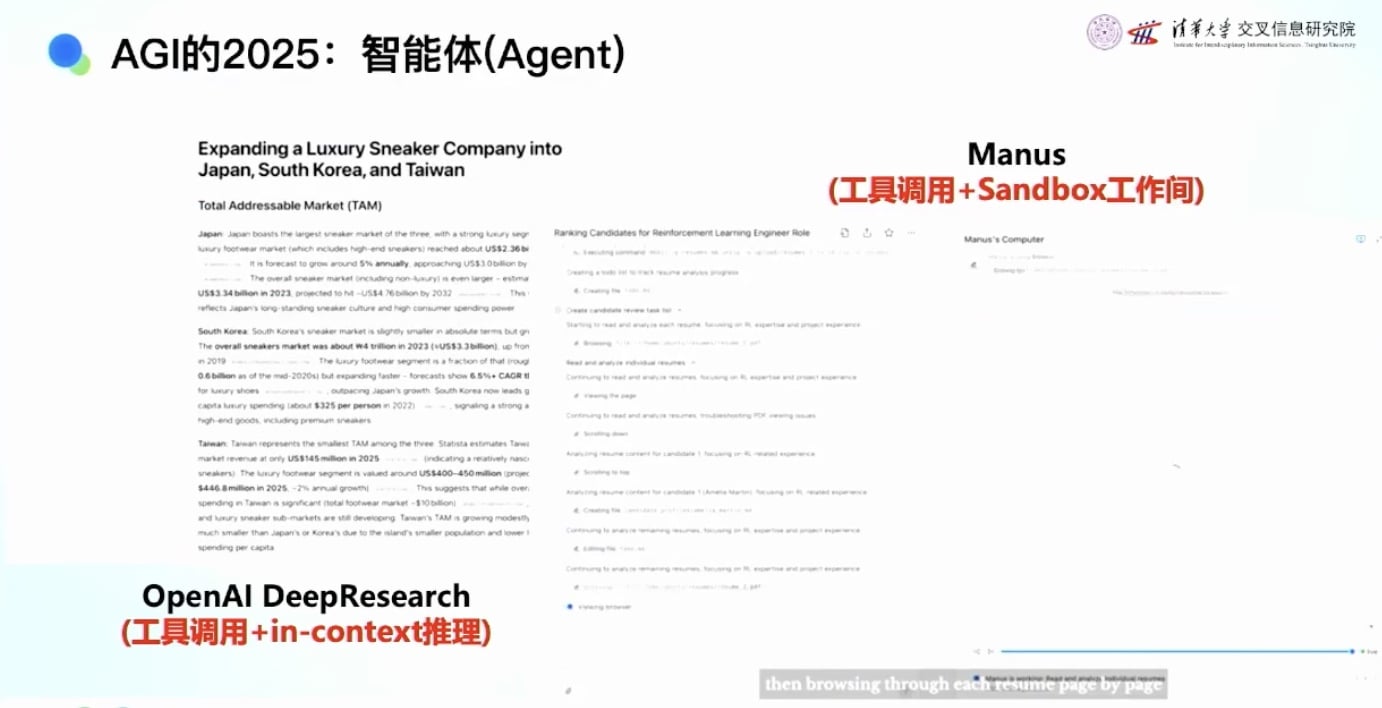

从Deep Research到Manus的发展体现了Agent能力的进步:
AI的能力演进:
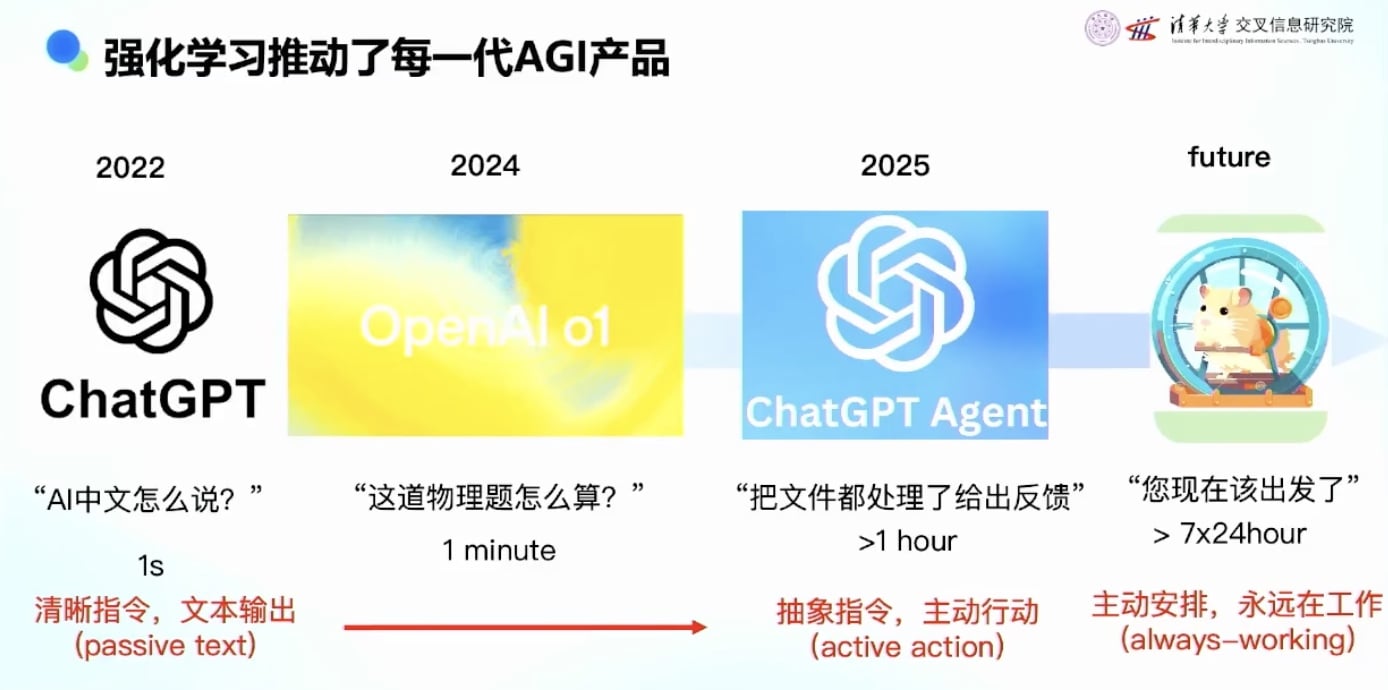

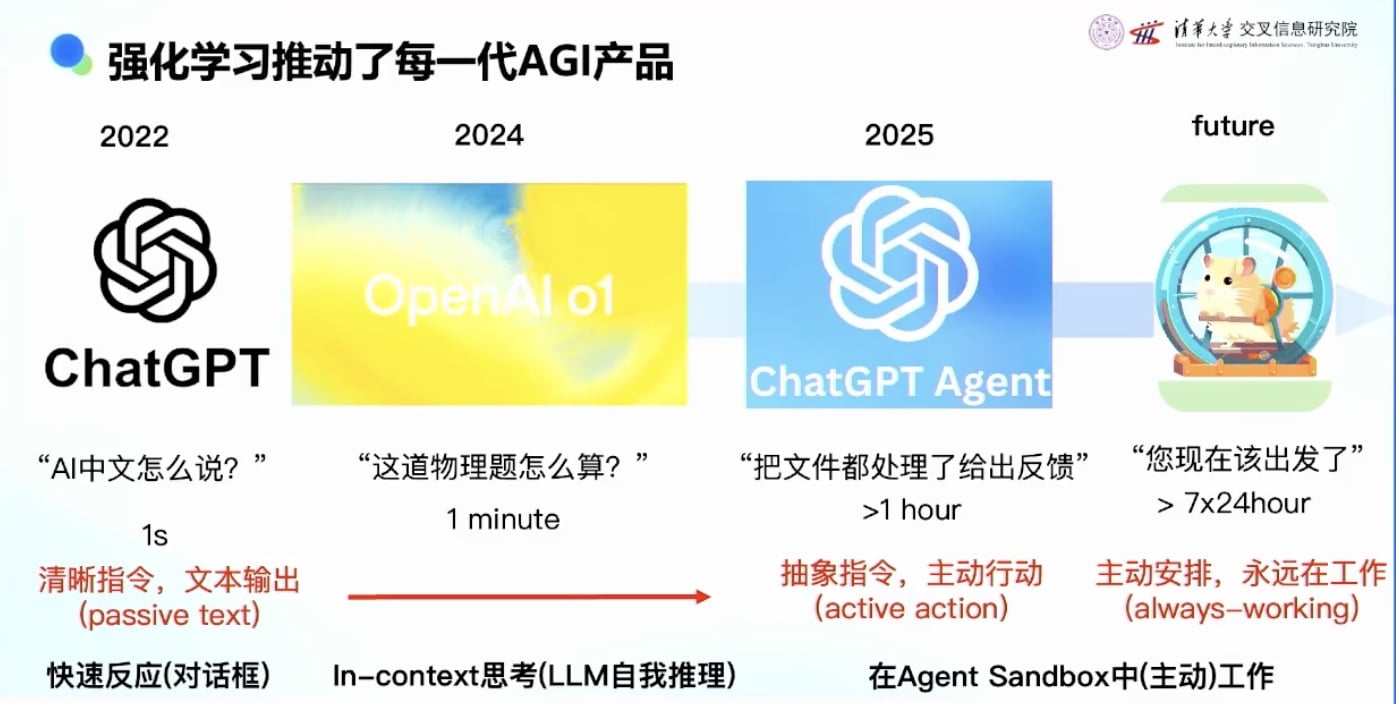
理想的AI助手具体技术化来讲:

市面上Agent 有各种 framework, 这些框架主要通过拖拉拽的方式构建Agent工作流,但对于复杂的Agent问题存在局限性。

案例:阿里CTO是谁?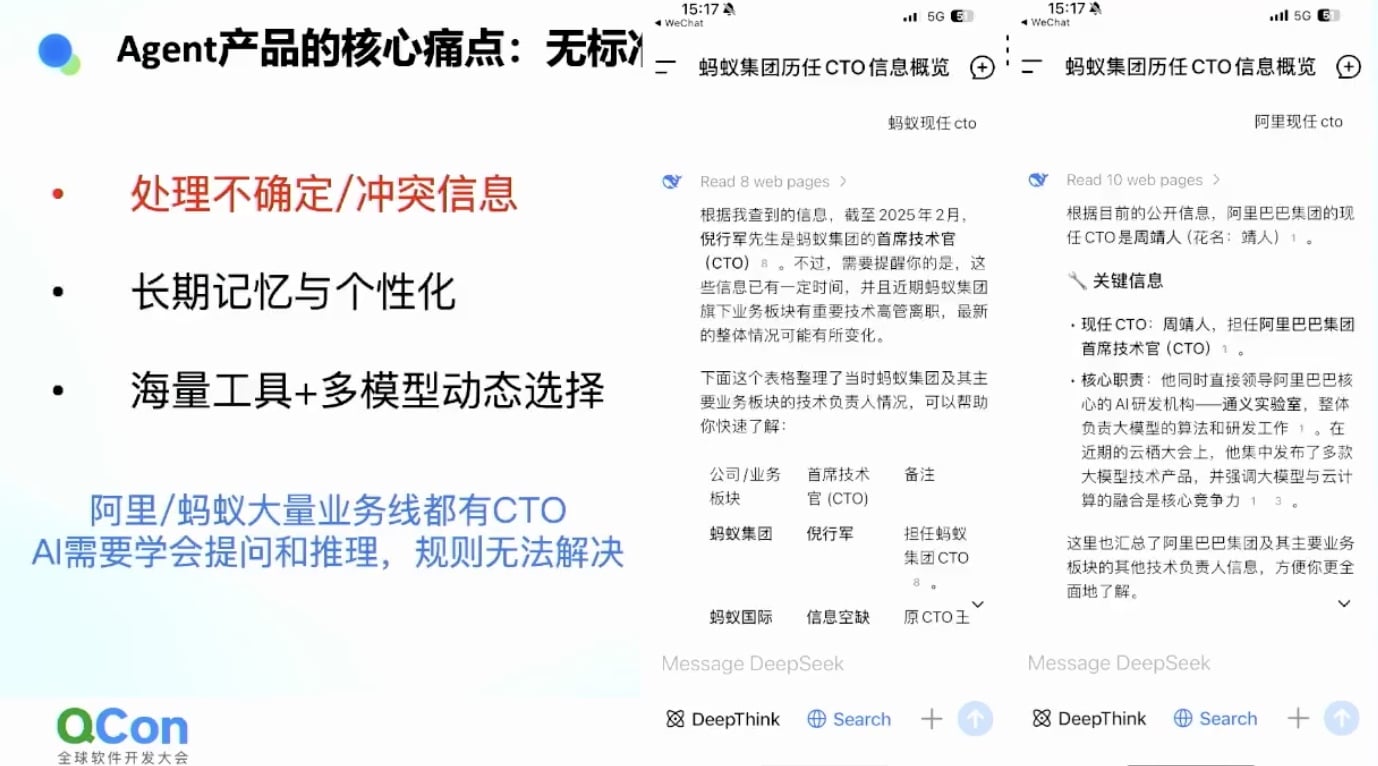
案例:退票问题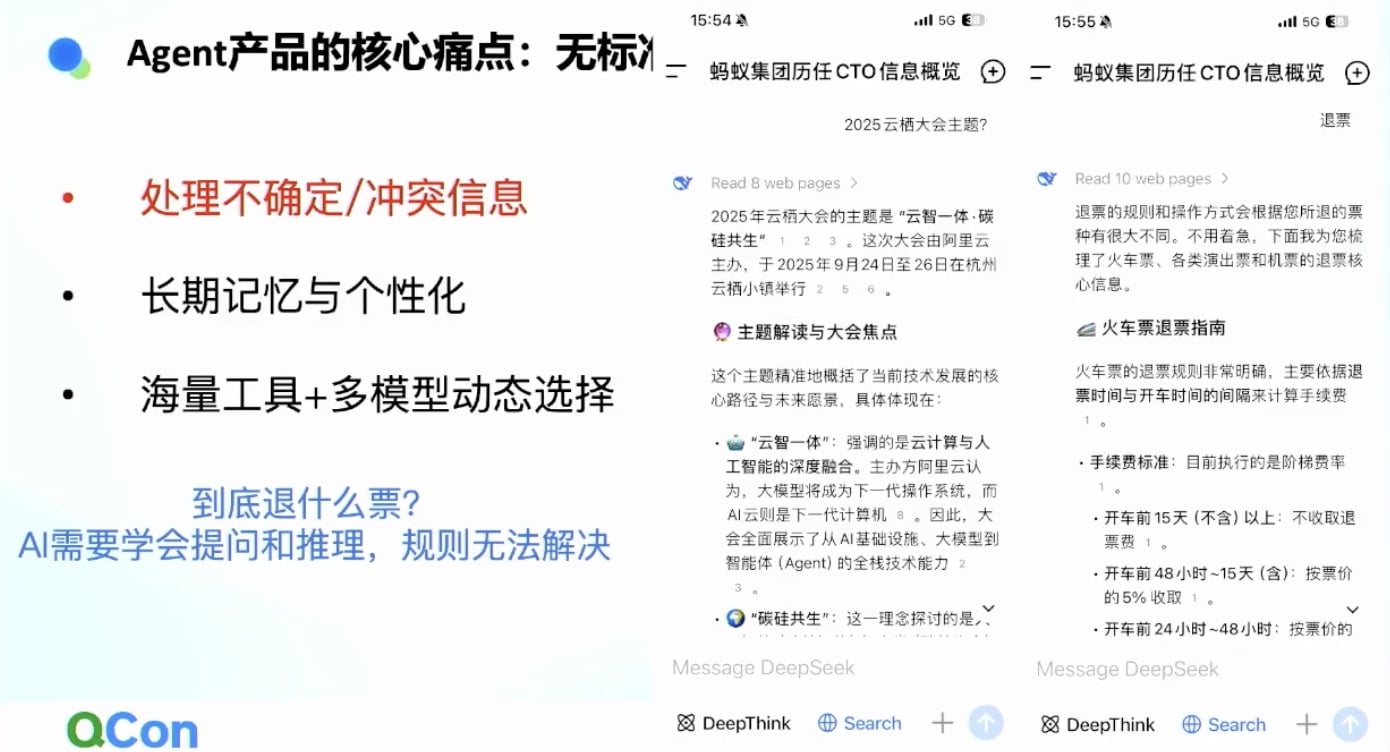

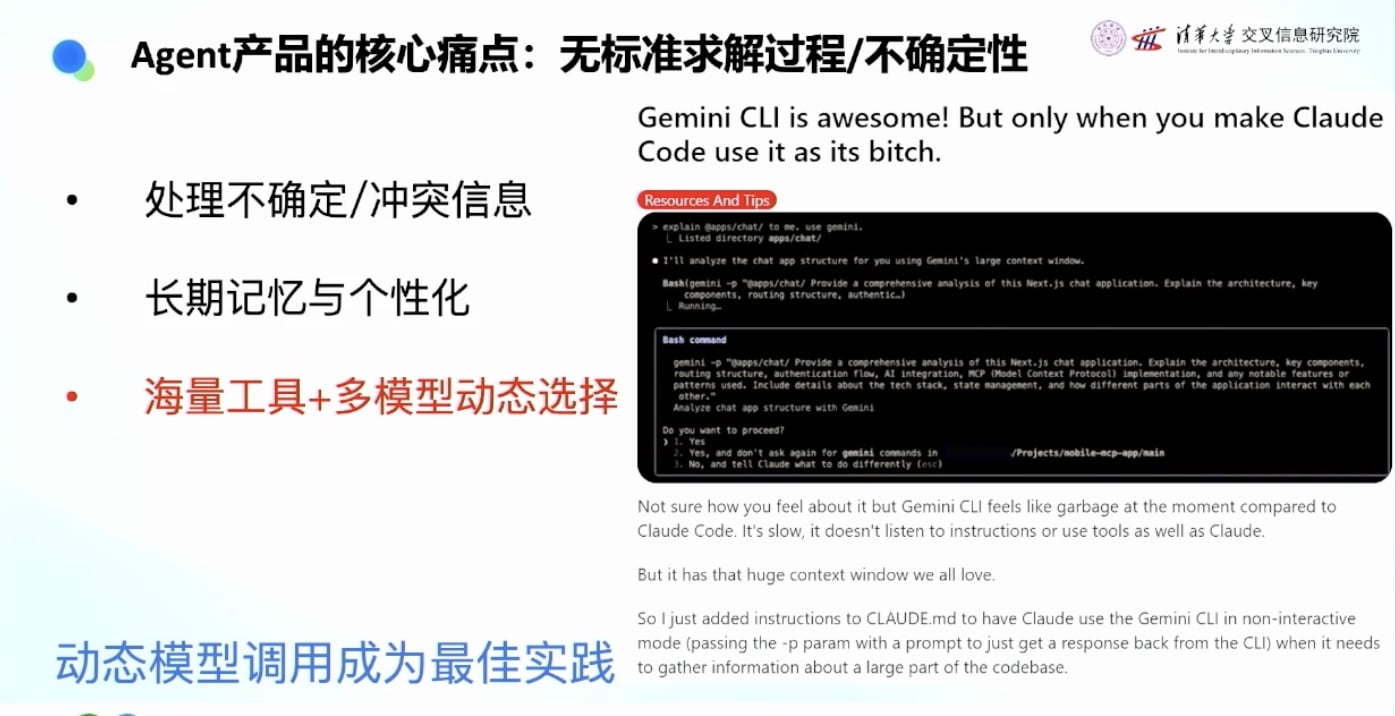
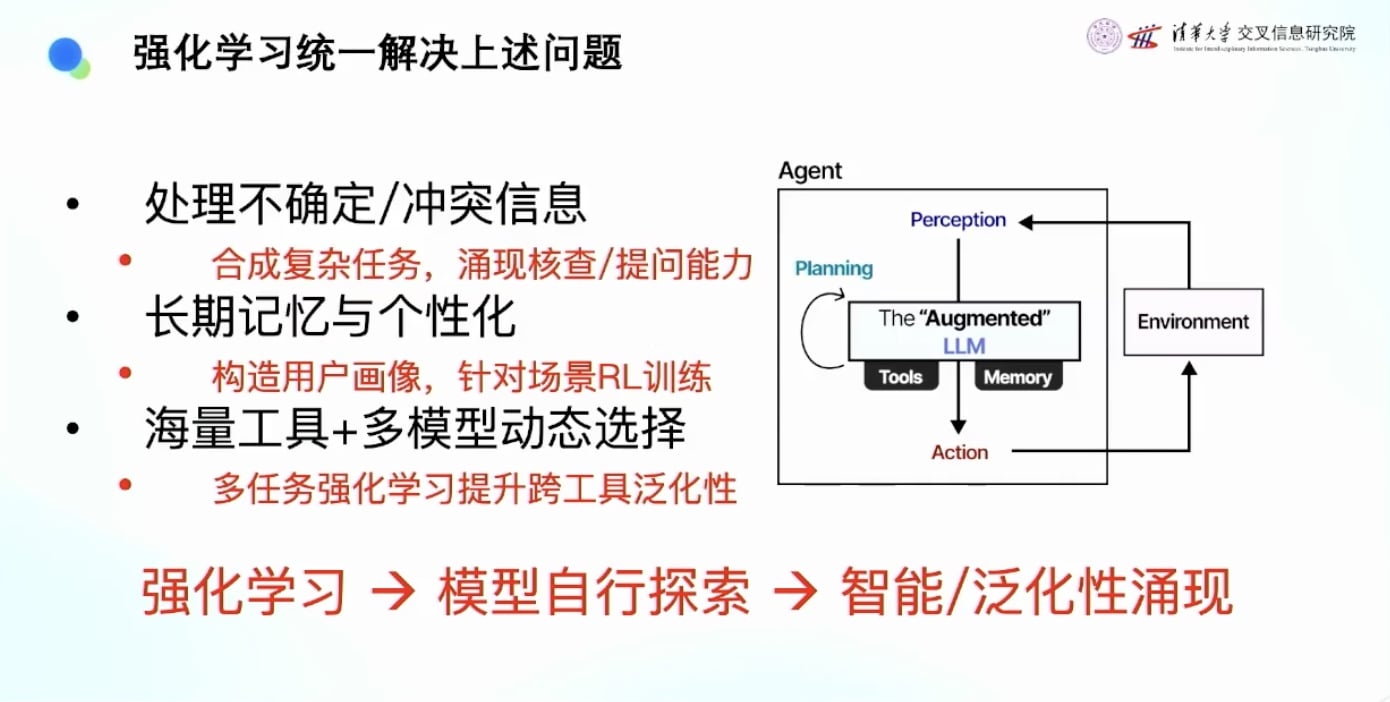
强化学习可以用统一的框架解决这些复杂问题:
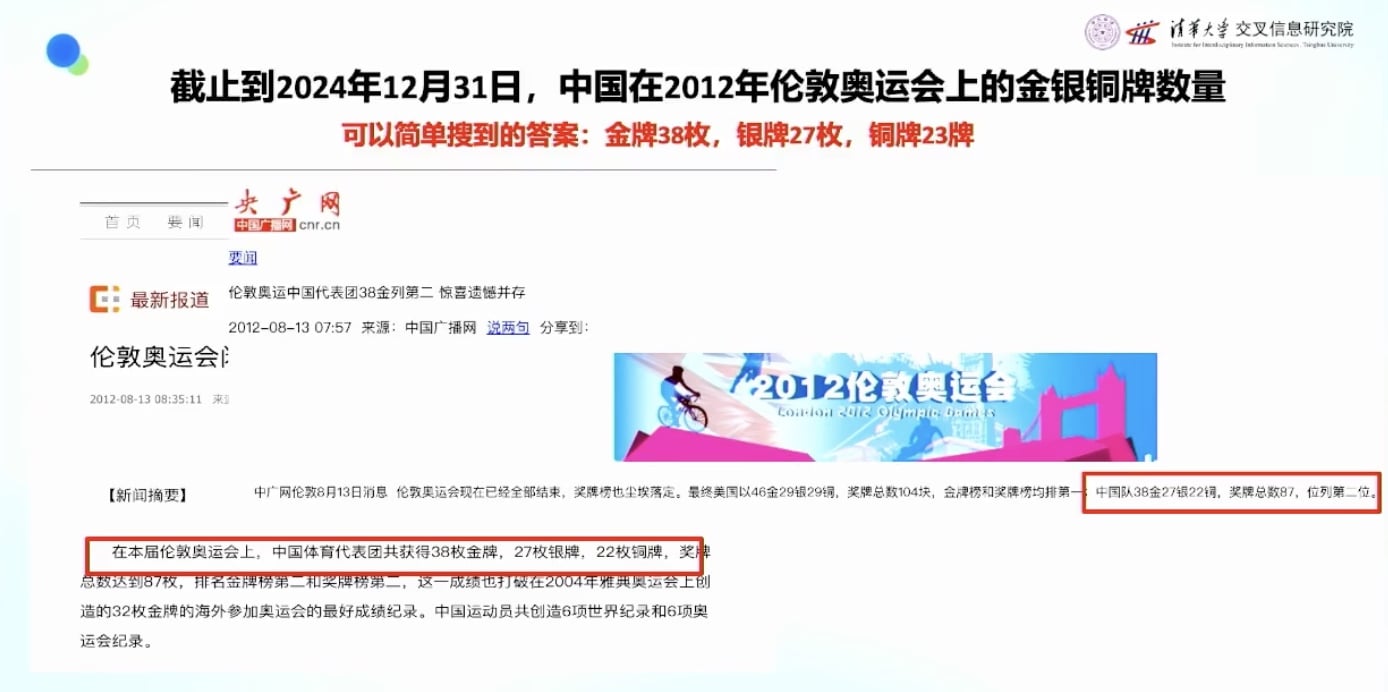
表面上的简单:
实际的复杂性:
现有产品的表现
测试了多个产品:
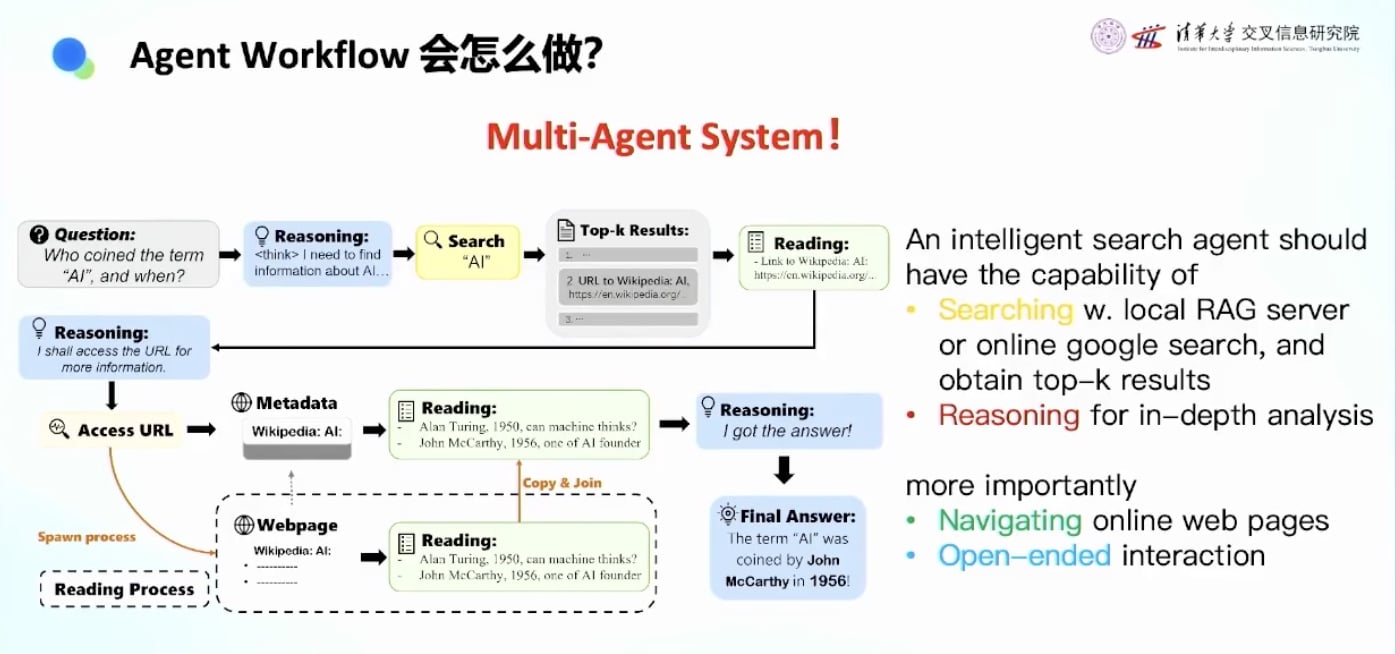
需要构建复杂的多智能体系统:
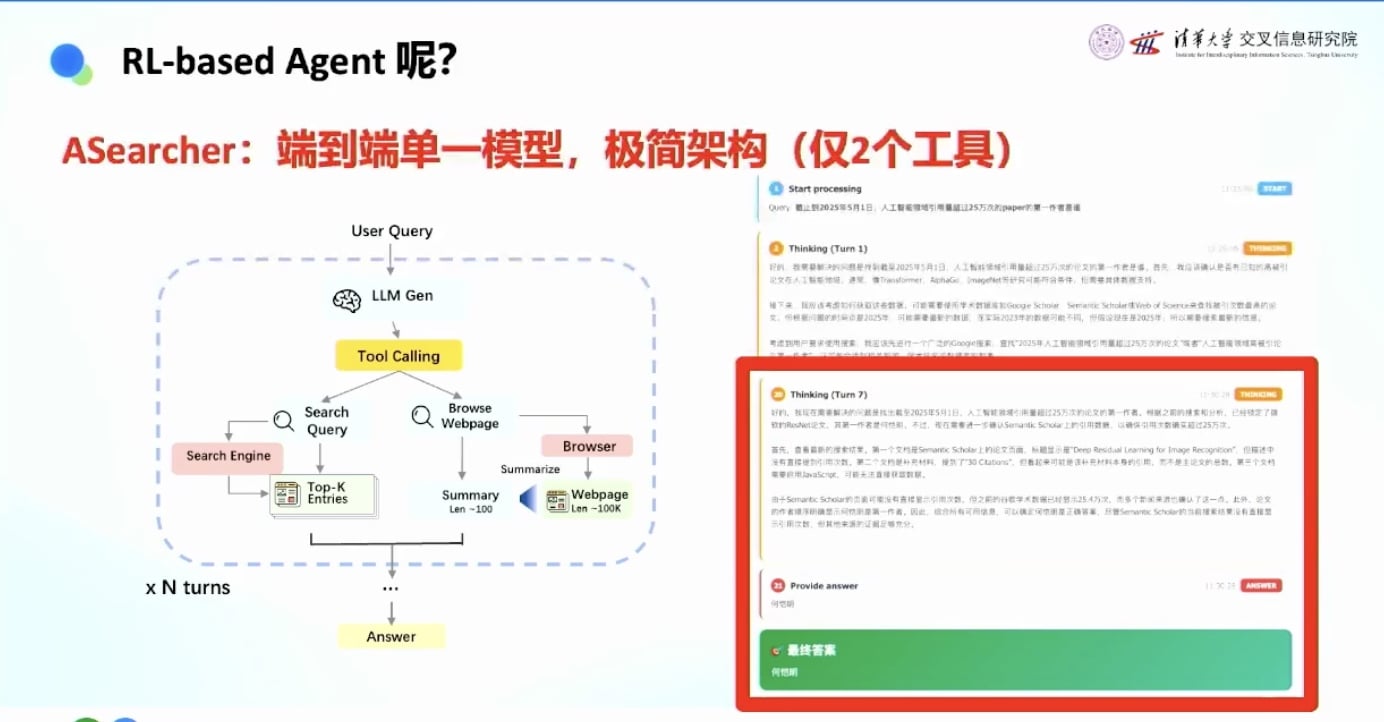
极简设计:
实际效果: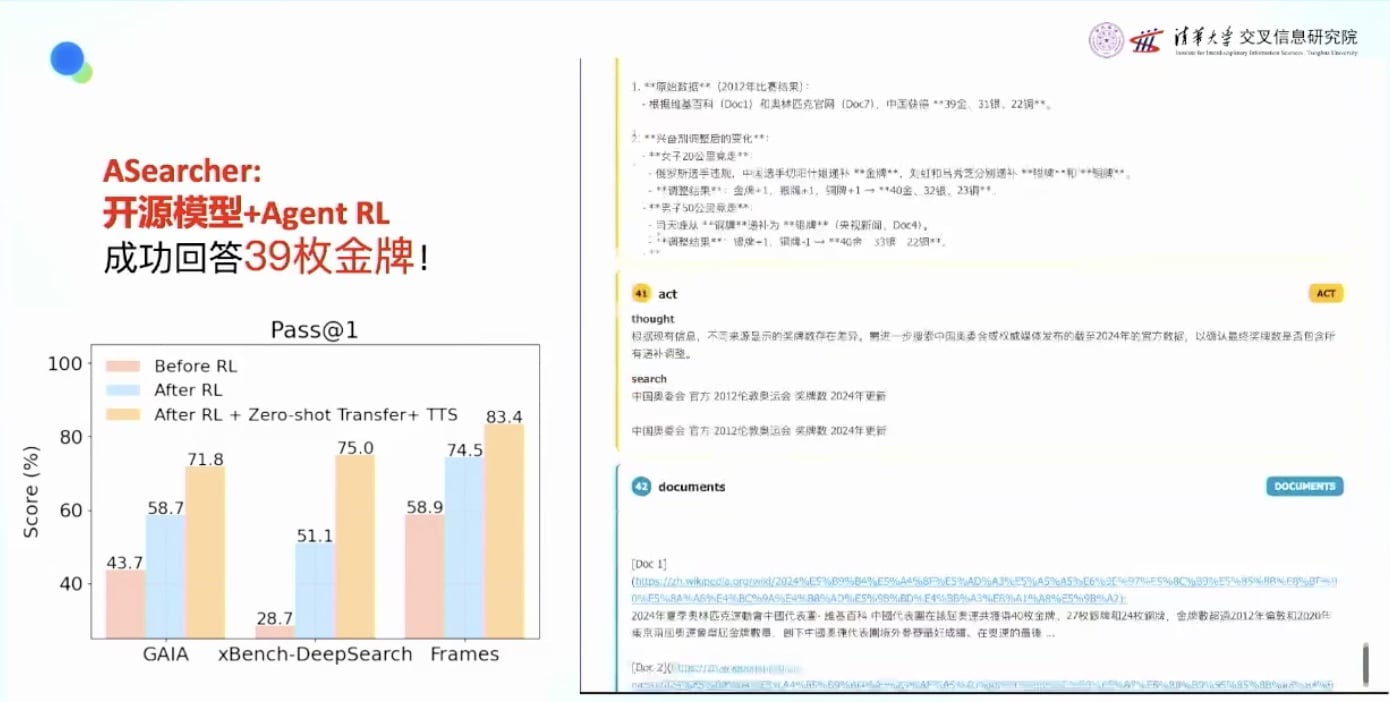


要做好强化学习,必须解决三个问题:
如何全栈解决 Agent RL 的难点
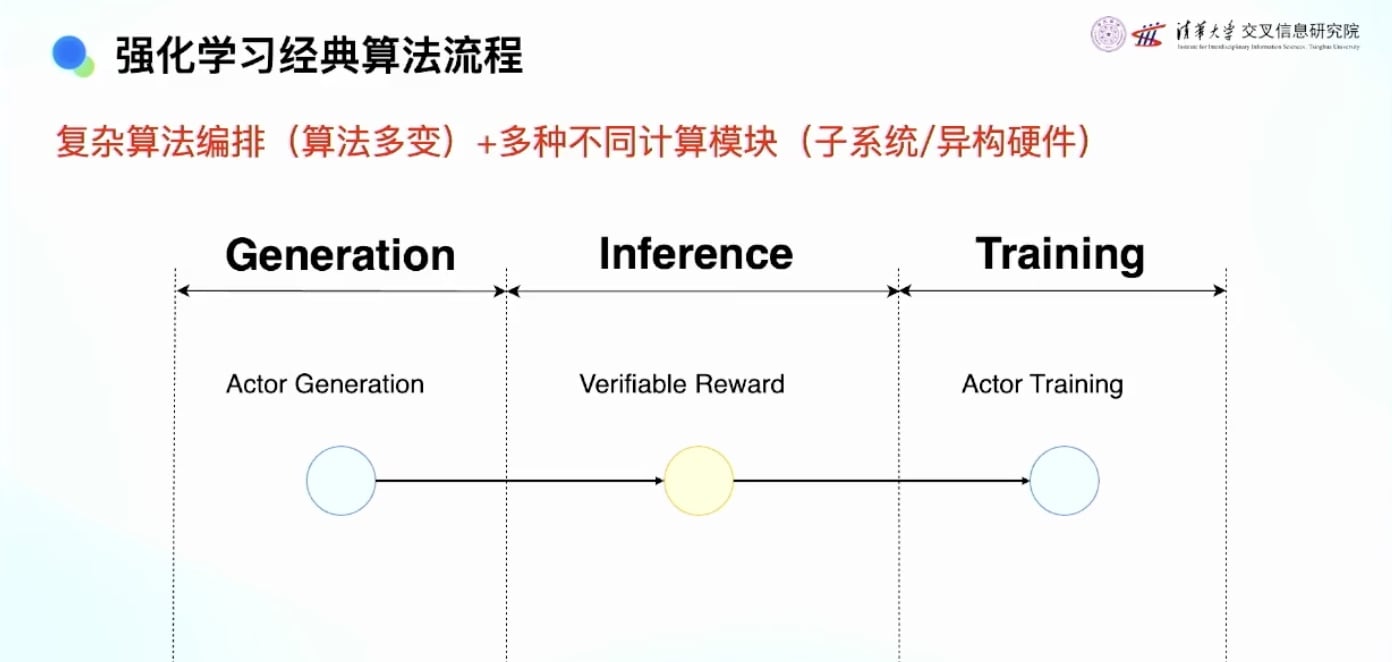
强化学习的三个流程:
复杂性分析:
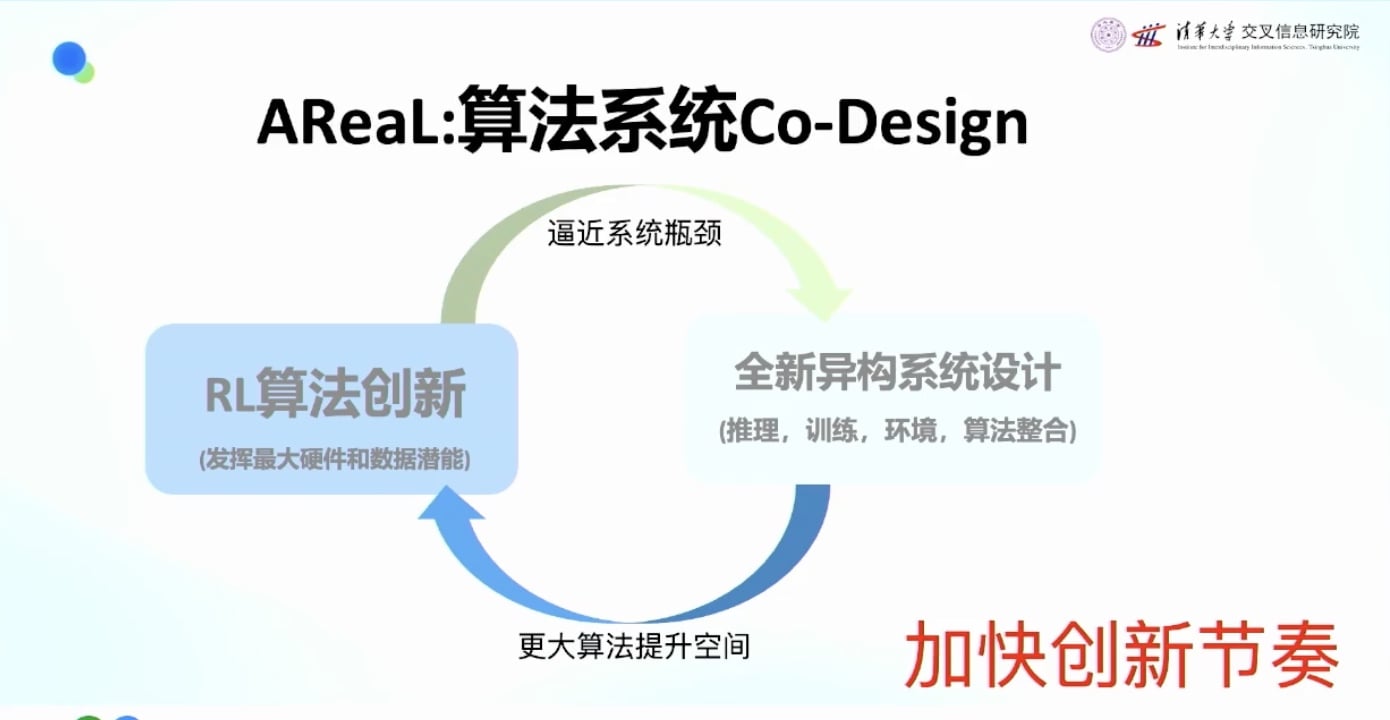
为什么需要协同设计:
团队组织建议:
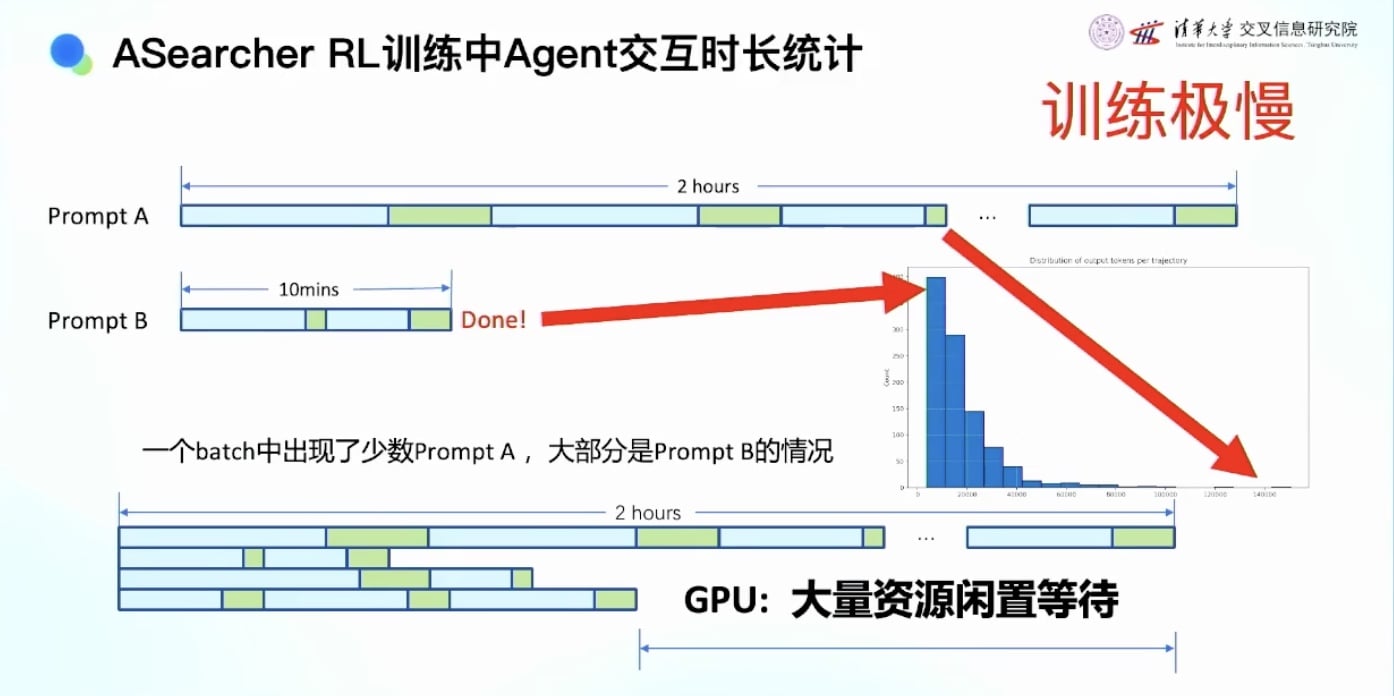
搜索智能体的统计数据:
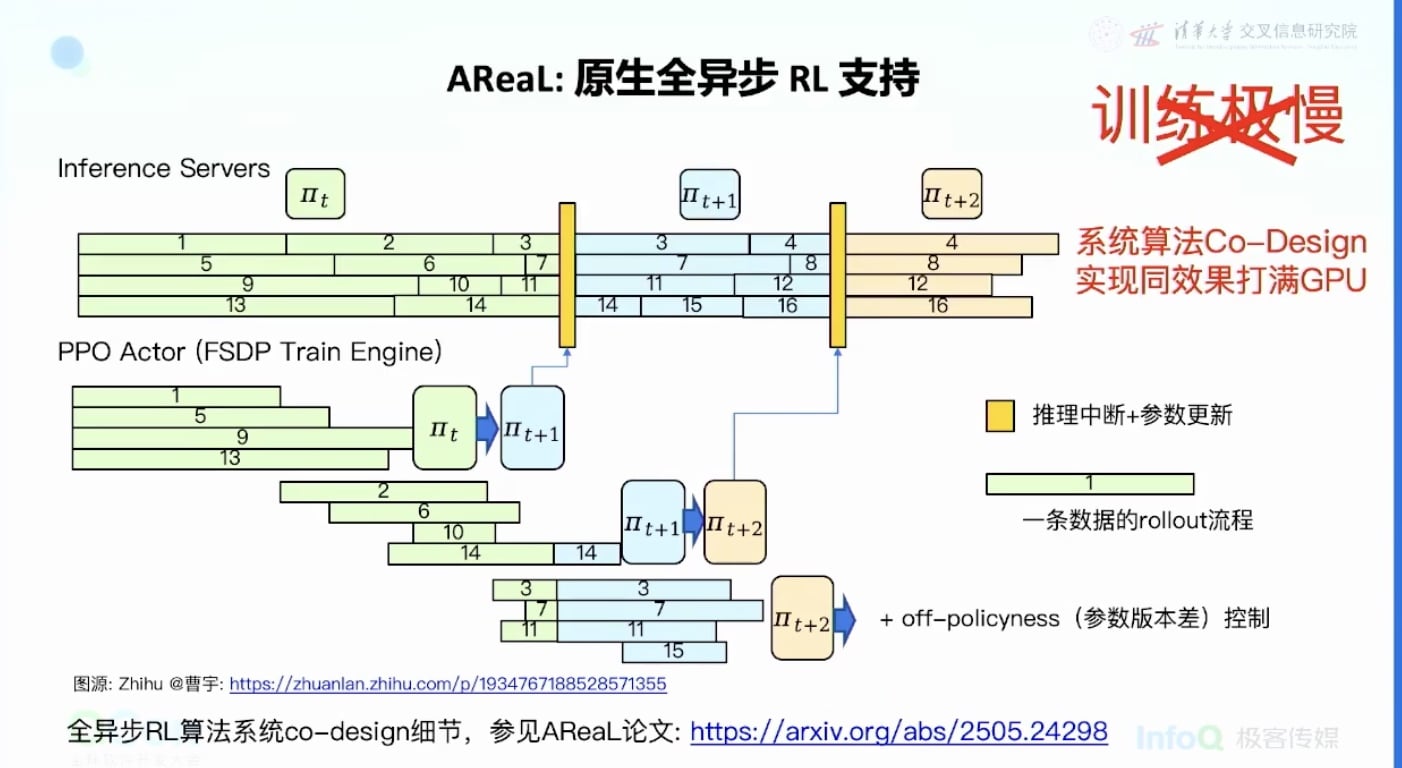
核心思想:推理不能等
技术创新:

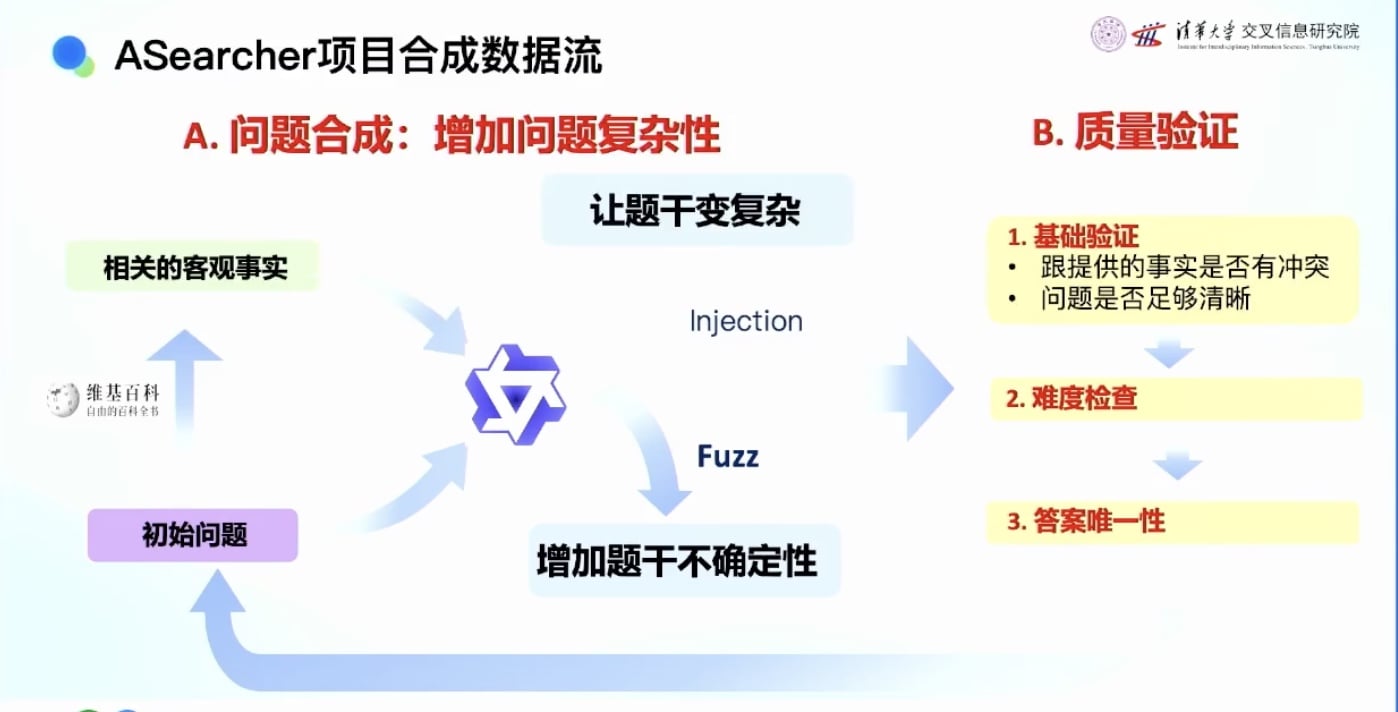
Agenic合成数据方法:
开源贡献:
让更多人用 RL 训练更好的 Agent

回到原点的循环:
技术需要两个条件才能发挥价值:
团队理念:
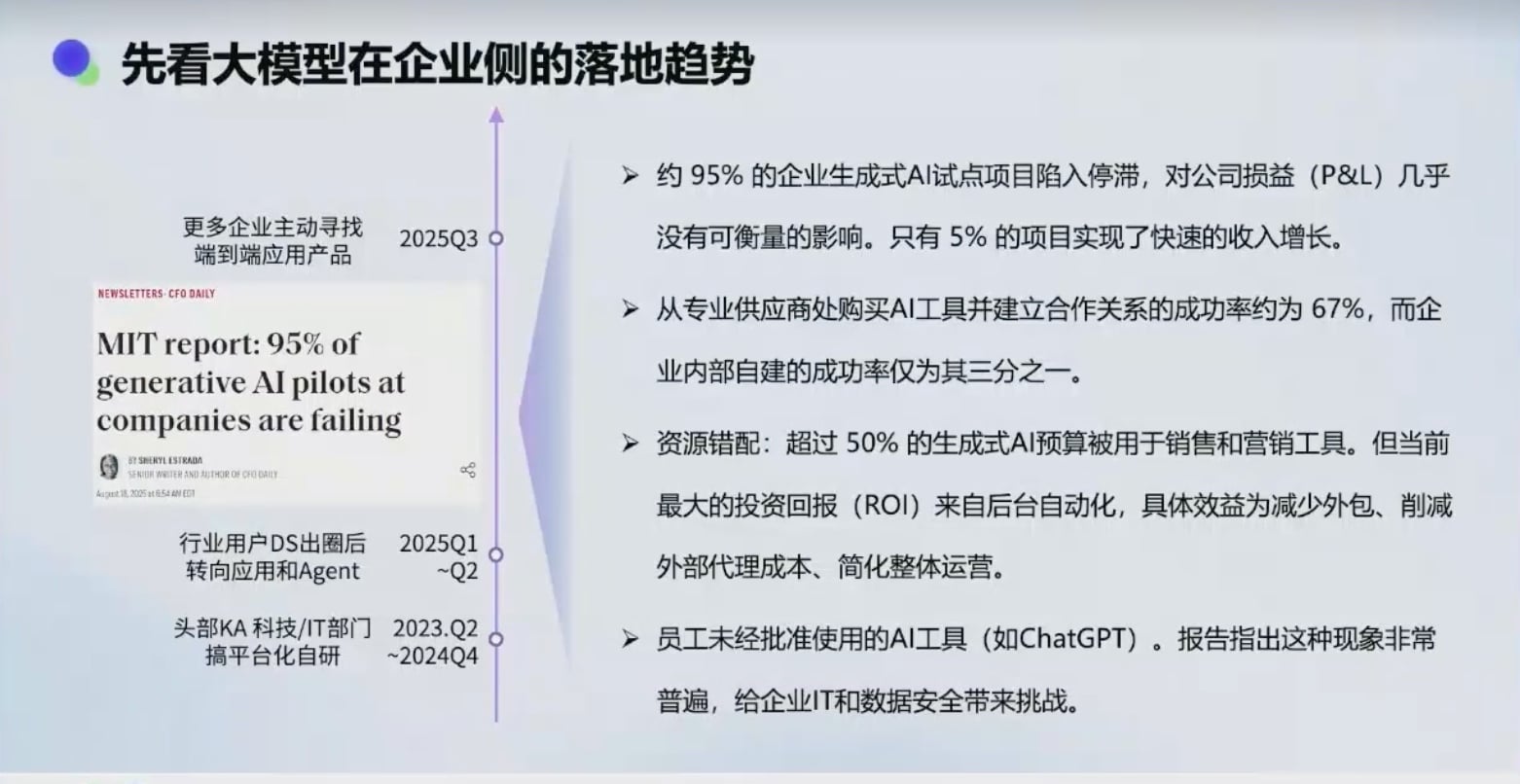
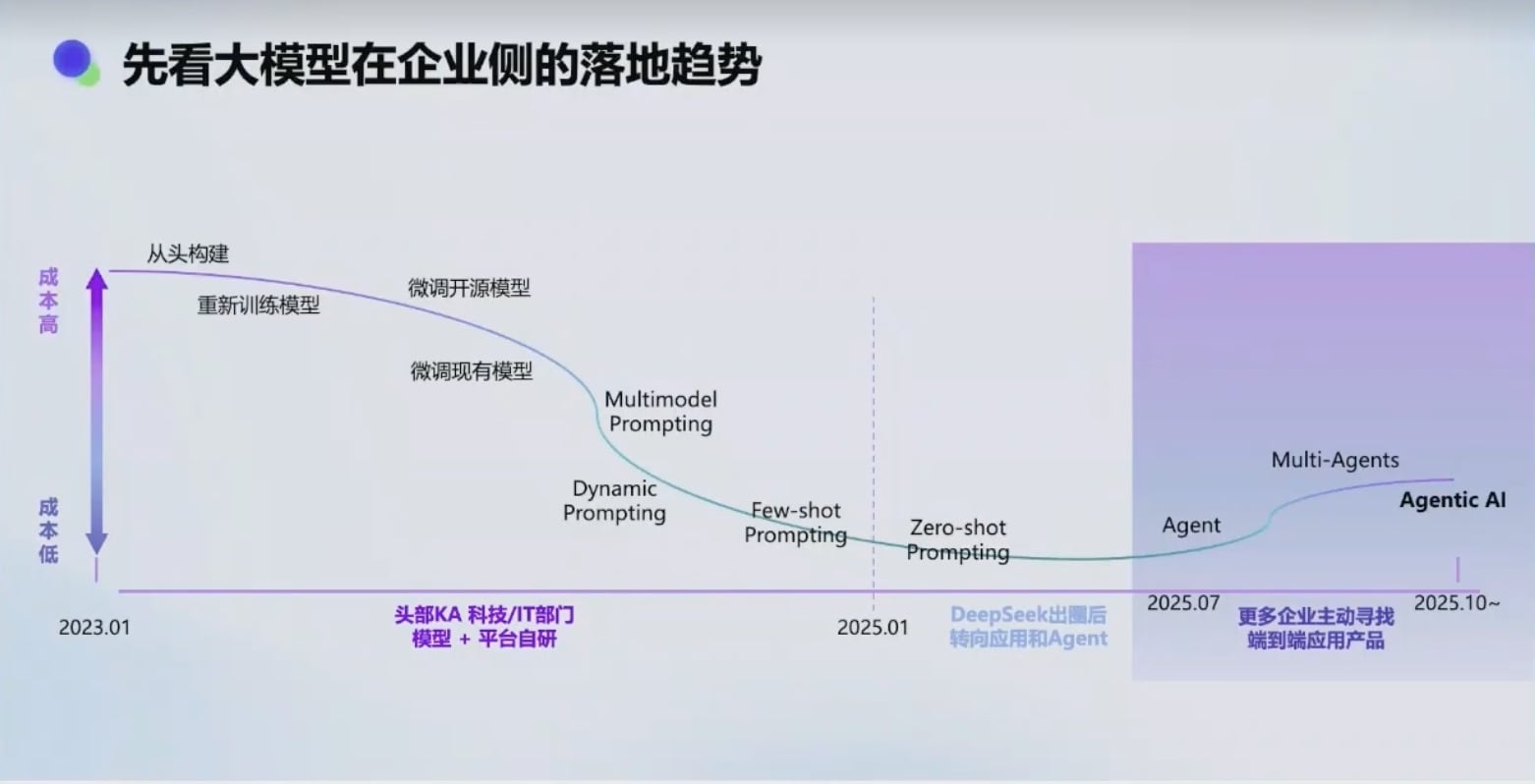

C 端与 B 端的差异
Agent 看上去效果很好, 但是要抽卡, C 端声量高,但企业侧落地率低
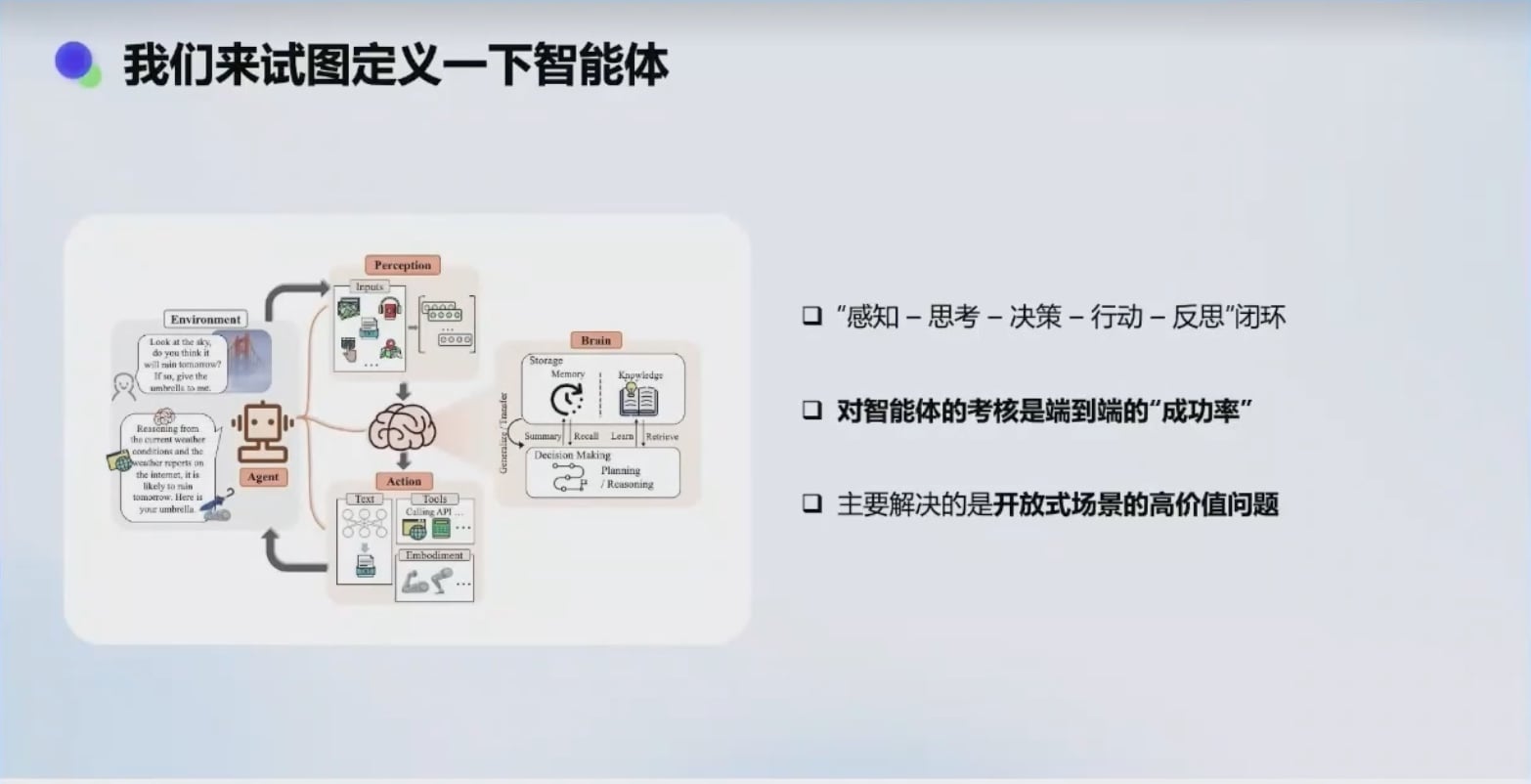
大模型解决的核心问题

企业 AI 价值价值是什么?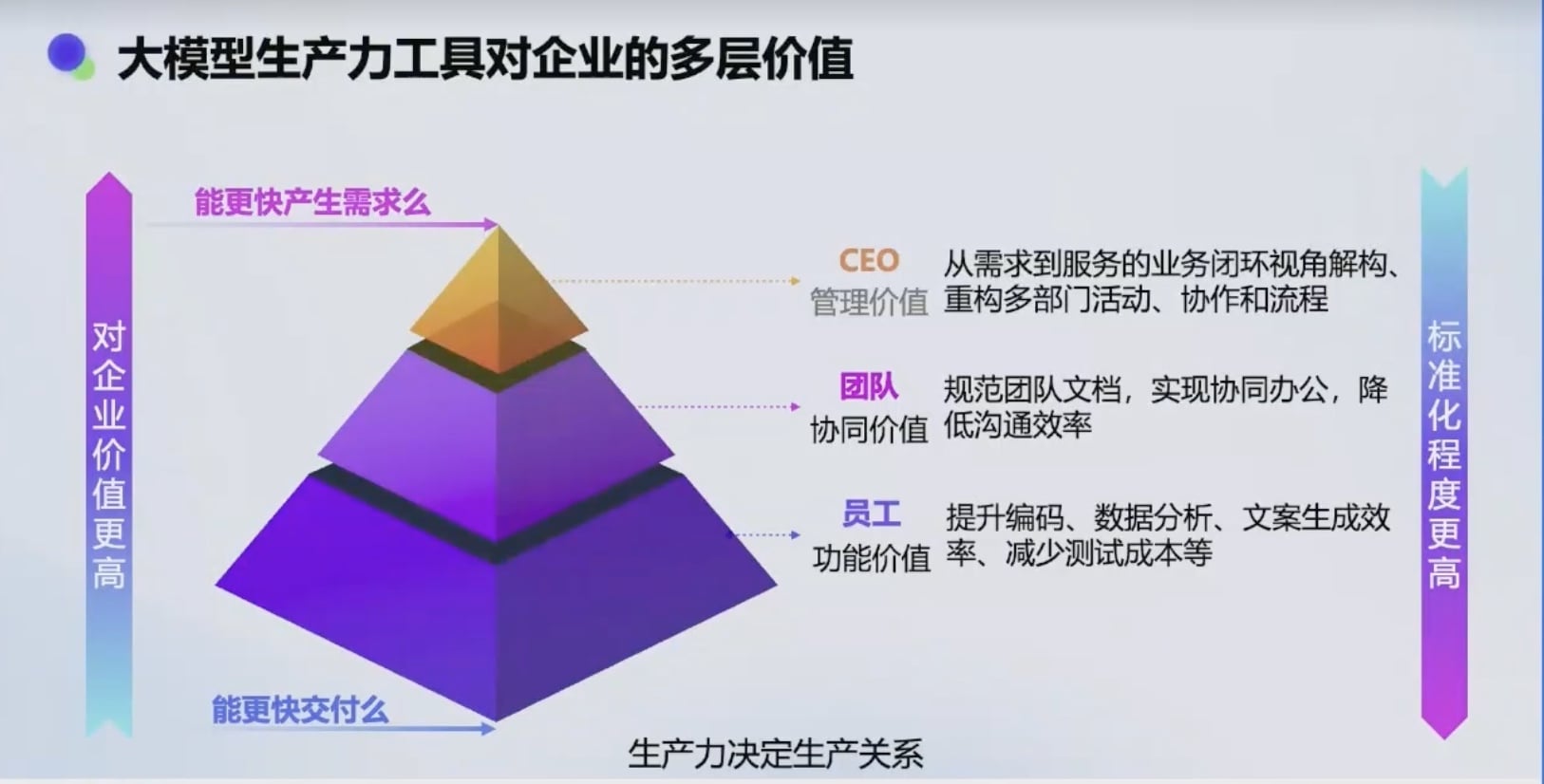
从下到上, AI 对企业的价值越高; 从上到下, 标准化程度越高
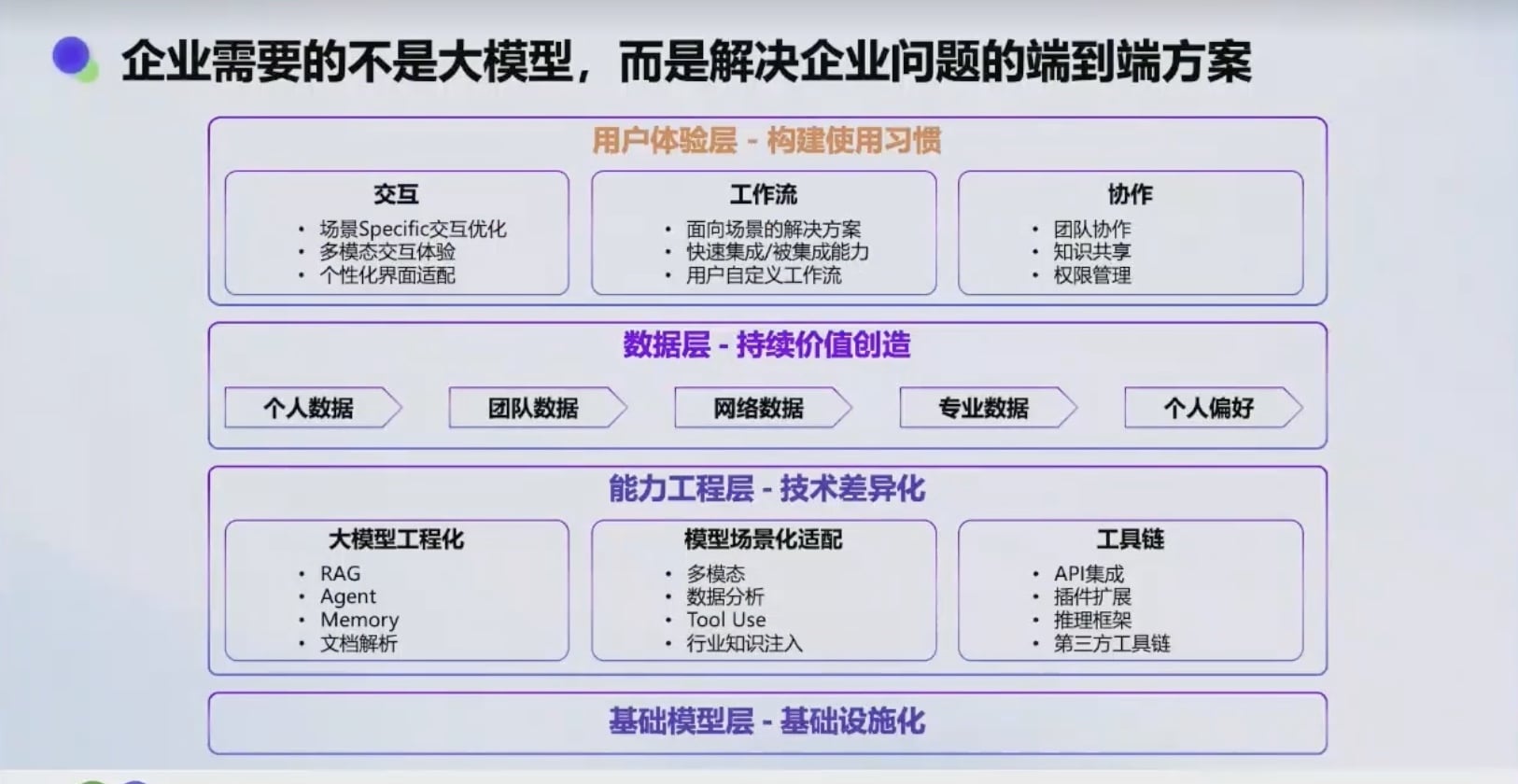
中国开源模型发展迅速,许多企业开始自己部署开源模型(如文心一言、千问等)
商汤的 AI 原生产品策略
合作伙伴策略
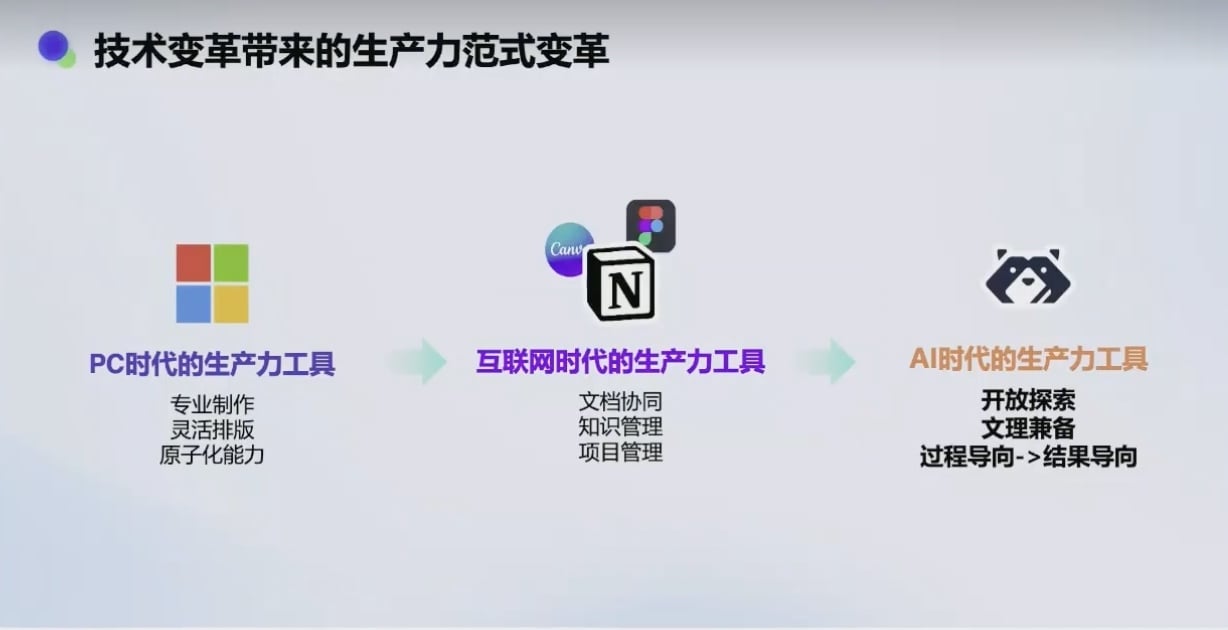
AI 时代的特点
产品整体图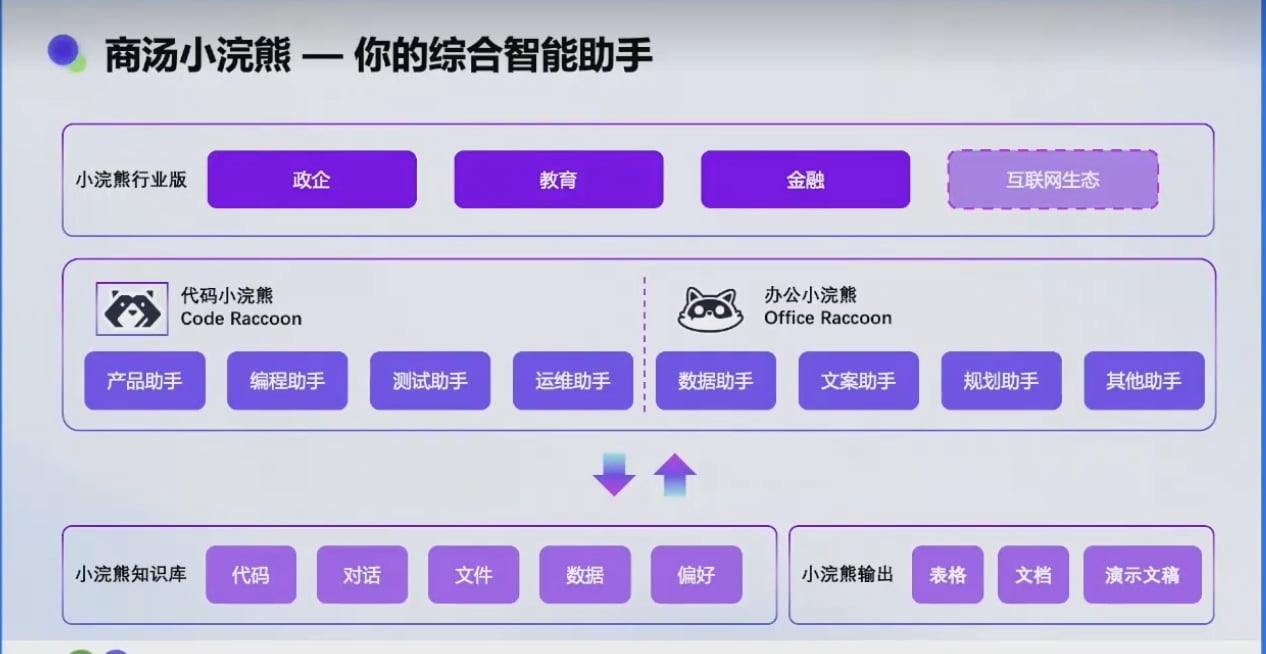
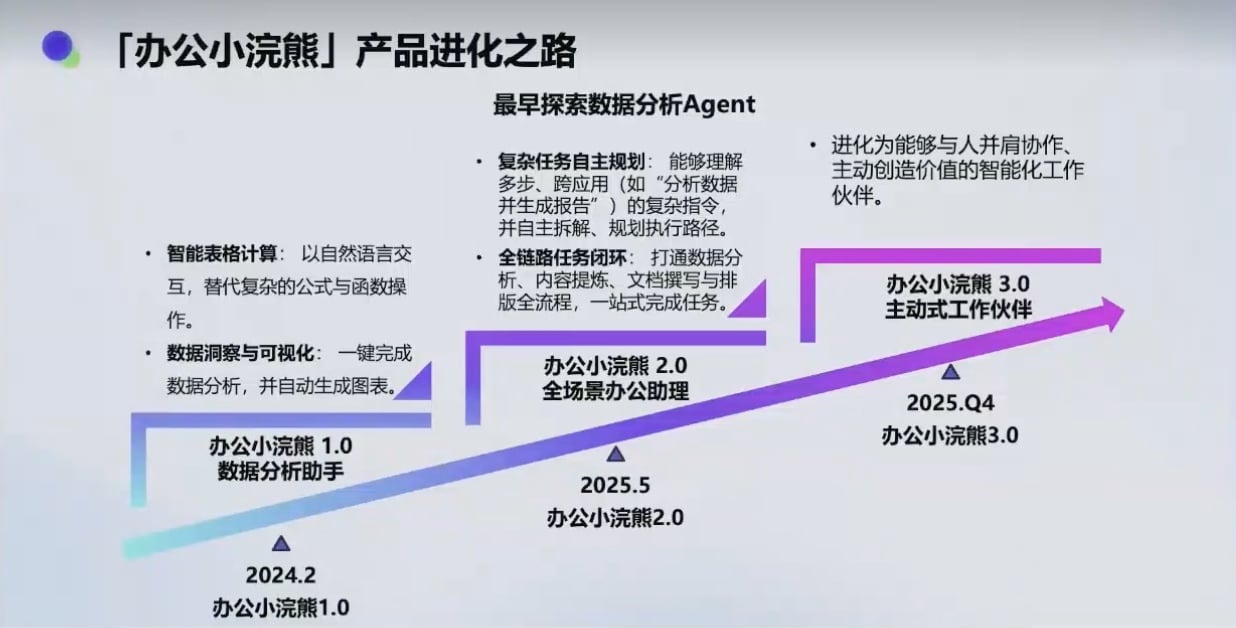
给跟大模型离的不是那么近的用户群体做推广

为什么不选择 ChatBI/Text2SQL:
对于企业用户推广:
C 端到 B 端的转化路径
突破传统模式
技术精度突破
企业问题解决
金融公司财务部门推广失败:
传统 BI 的问题

二次编辑能力
用户体验优化, 相比精度提升 1-2 个点,快速编辑功能用户感知更强, 显著提高用户黏性

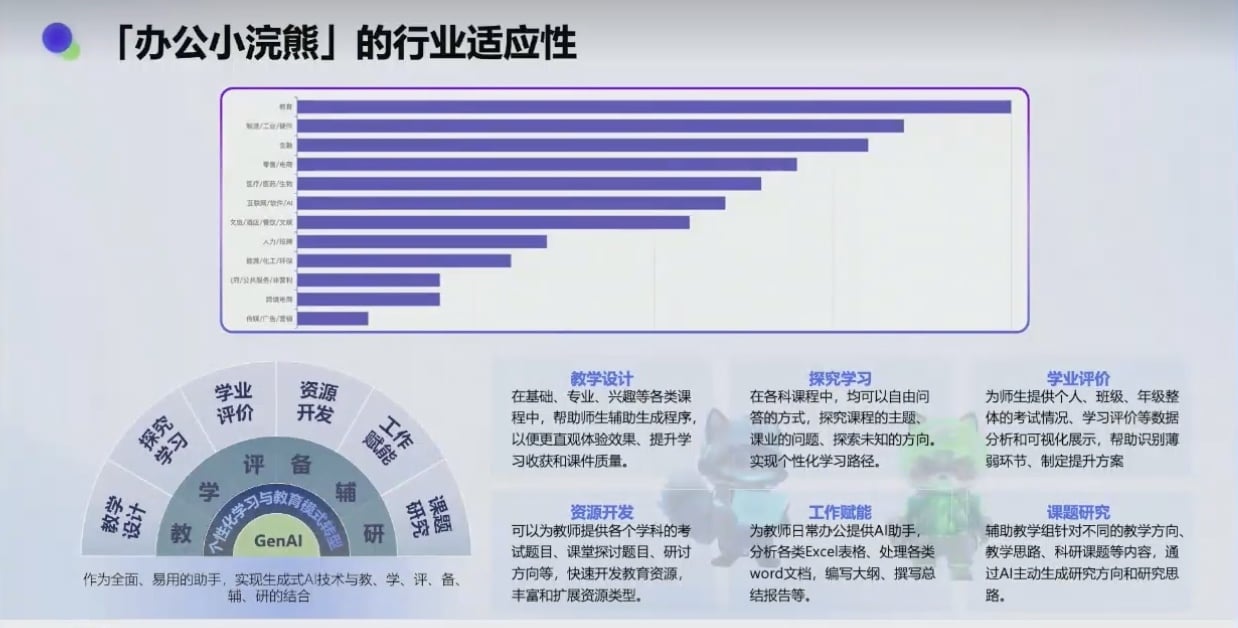
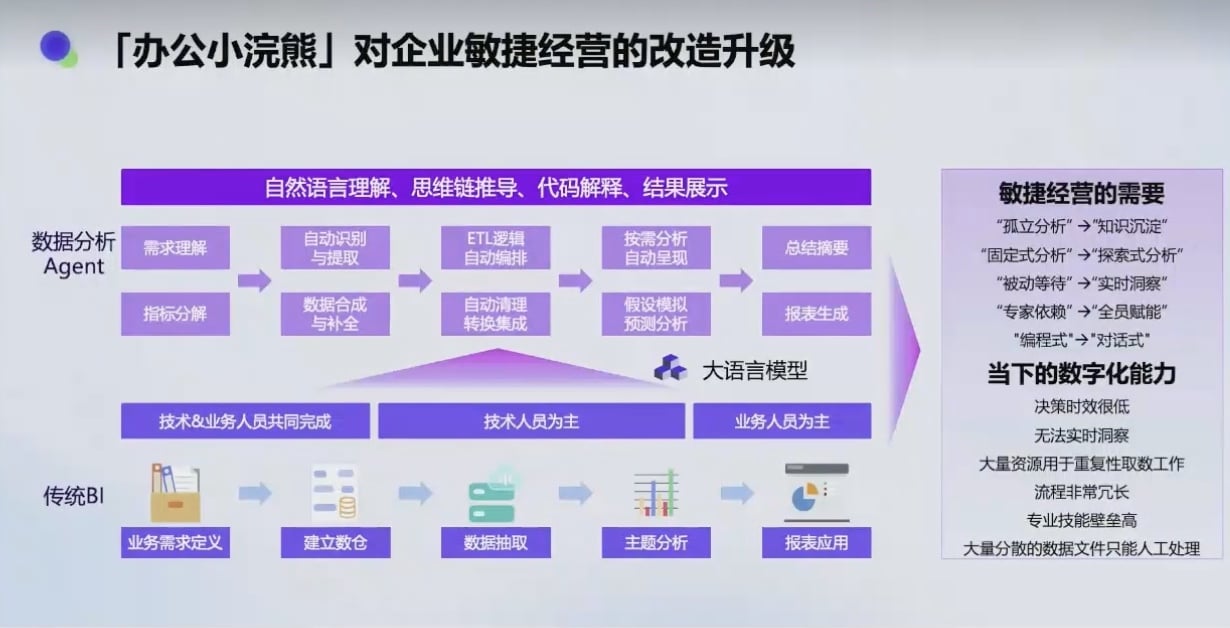
解决的问题:

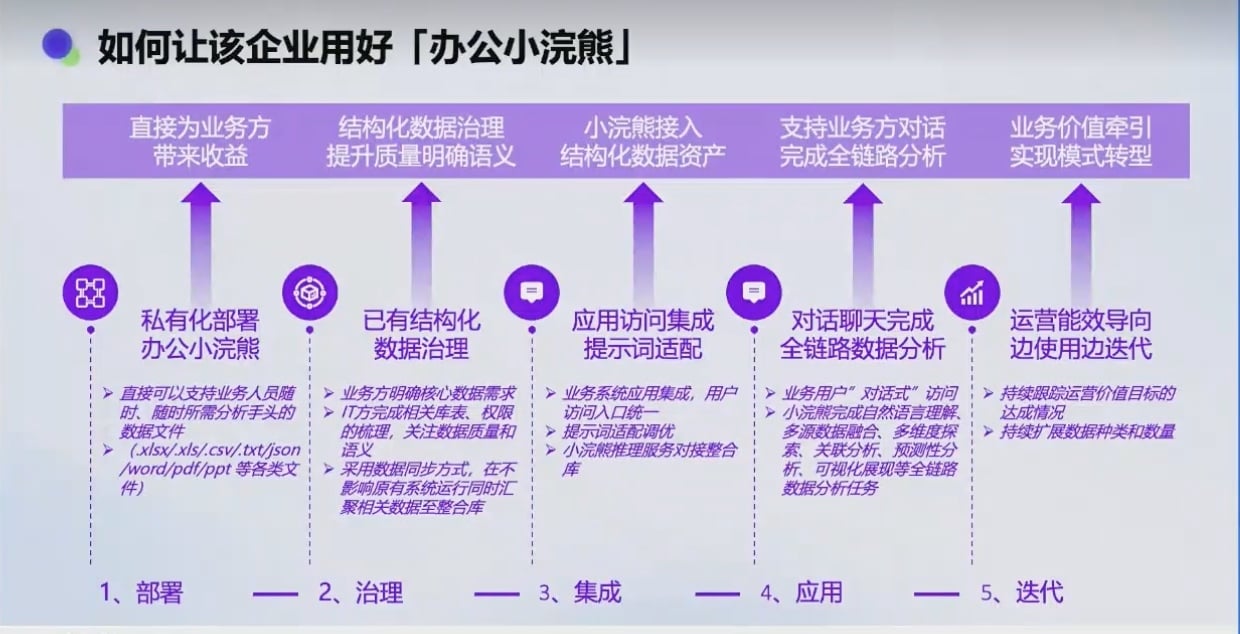
时间优化, 从最早的 3 个月缩短到最快 2 个月, 但私有化还是很难
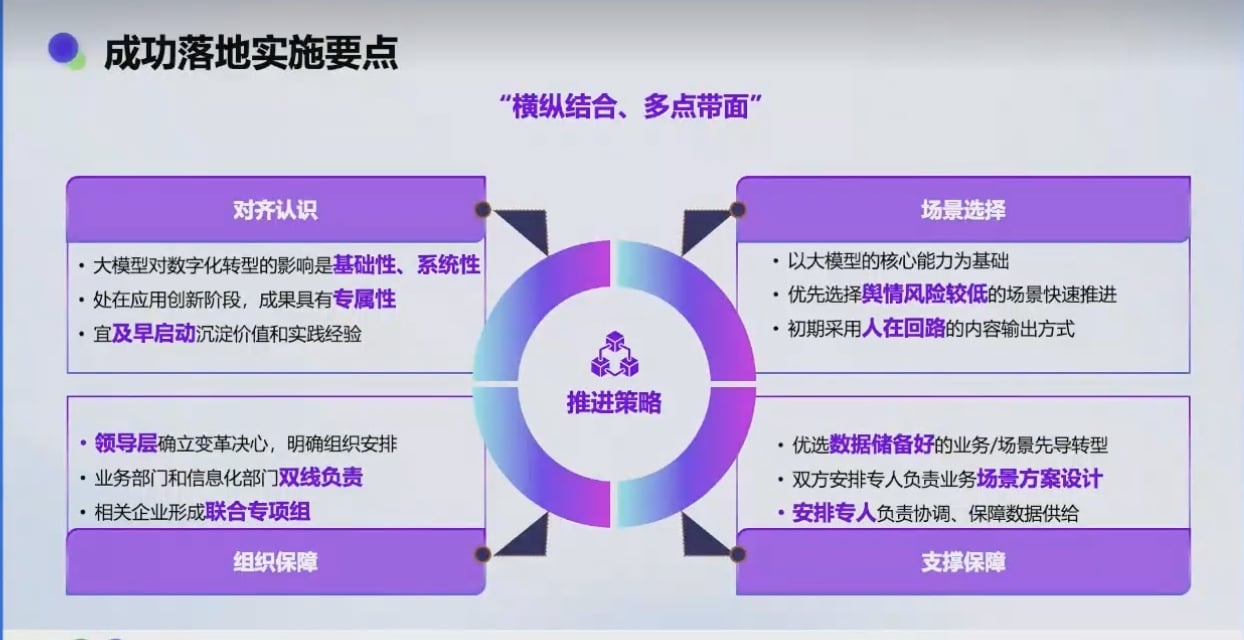
客户沟通重点
客户选择标准
市场推广节奏
Lua 5.5.0 已经正式发布。所以,skynet 的 Lua 版本也随之升级。
skynet 维护了一份修改版的 Lua ,允许在多个虚拟机之间共享函数原型。这可以节省初始化 Lua 服务的时间,减少内存占用。
跨虚拟机共享函数原型最困难的部分是函数原型会引用常量字符串,而 Lua 在处理短字符串时,需要在虚拟机内部做 interning 。所以 skynet 的这个 patch 主要解决的是正确处理被 interning 的短字符串和从外部导入的函数原型中包含的字符串共存的问题。具体方法记录在这篇 blog 中。
这个 patch 的副产品是允许在多个 Lua VM 间共享常量表。打了这个 patch 后,就可以使用 skynet.sharetable 这个库共享只读常量表了。
这次 Lua 5.5 的更新引入了 external strings 这个特性,已经大幅度提升了 Lua 加载字节码的速度。我比较倾向于在未来不再依赖额外的 patch 减少维护成本。所以建议新项目避免再使用共享常量表,减少对 patch 过的 Lua 版本的依赖。
Lua 5.5 基本上兼容 Lua 5.4 ,我认为绝大多数 skynet 项目都不需要特别改动。但在升级后,还是建议充分测试。注意:更新仓库后,需要用 make cleanall 清除 lua 的编译中间文件,强制 Lua 重新编译。直接 make clean 并不清理它们。
Lua 5.5 有几处更新我认为值得升级:
增加了 global 关键字。对减少拼写错误引起的 bug 很有帮助。skynet 自身代码暂时还没有使用,但后续会逐步添加。
分代 GC 的主流程改为步进式进行。过去版本如果采用分代模式,对于内存占用较大的服务,容易造成停顿。所以这类服务往往需要切换为步进模式。升级到 Lua 5.5 后,应该就不需要了。
新的不定长参数语法 ...args 可以用 table 形式访问不定长参数列表。以后可以简化一部分 skynet 中 Lua 代码的实现。
做独立产品这件事,说起来容易,真动手了才知道水有多深。这是一个独立开发者将职场小需求变成主力产品的真实故事。我们将跟随 Zipic 作者十里的视角,一起回顾产品从 0 到 1 的全过程。本篇聚焦产品设计与决策思考。
Mac App Store 固然使用简单,但可能并不适合所有的产品。本文中,我们将跟随 Zipic 作者十里的视角,来解决一款 macOS 独立应用的分发与售卖问题。
图片压缩软件还有什么技术难点?本文充满了硬核、实用的 macOS 开发经验,从 SwiftUI 的组件适配到 Core Graphics 的底层应用,从 Raycast 扩展的集成到 PDF 压缩的实现,不仅解决了性能瓶颈,更让原生体验达到了极致。
近期AI赛道异常“内卷”,硅谷甚至出现了“996”乃至“007”的新闻。AI在编码(如Cursor、Anthropic)和解决复杂问题(如ACM竞赛夺冠、IMO金牌水平)上的表现,似乎已超越大部分程序员。
这引发了一个普遍的焦虑:AI coding + AI debug 是否将形成一个完美闭环,从而替代程序员?
然而,在快手这样拥有亿级日活(DAU)的复杂业务场景中,我们的实践表明,需要冷静看待这一议题。AI并非替代者,而是团队产出的放大器。今天的分享,将围绕快手在性能稳定性领域如何利用AI进行智能诊断与实践,揭示AI在真实工业场景中扮演的角色。
快手移动端稳定性建设经历了四个清晰的阶段: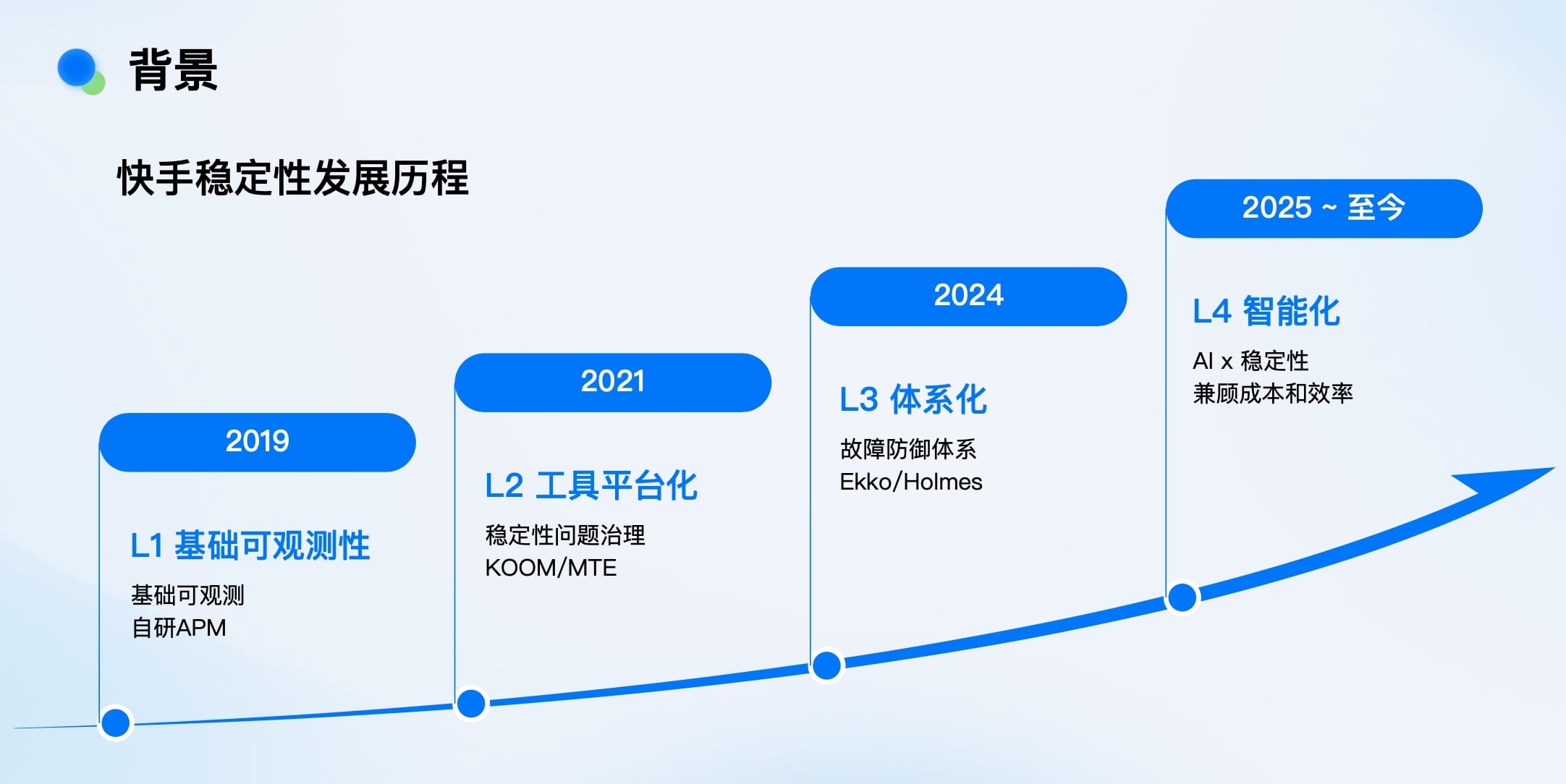
每个阶段都基于上一阶段的成果进行迭代,这与移动互联网发展的节奏同步。
尽管硬件性能(如iPhone)已提升百倍,软件架构(如GMPC)演进多年,但大前端的性能稳定性问题远未解决。复杂性体现在多个维度: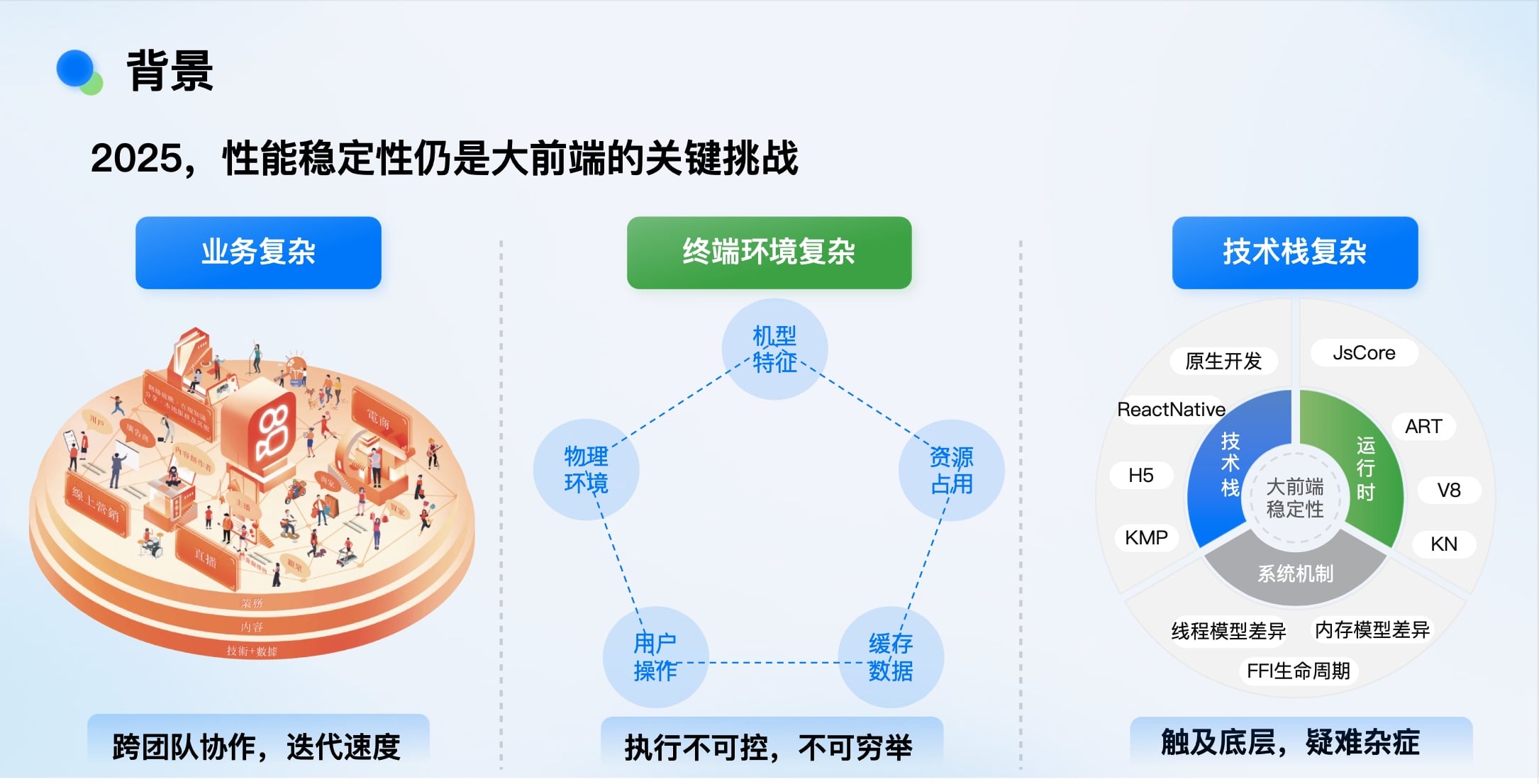
从算法复杂度视角看,我们解决问题的“算法”本质未变,但“输入”却因业务增长和技术栈扩张(如新增鸿蒙)而急剧增加,导致问题规模(年报警事件超150起,必解问题超2000个)庞大。
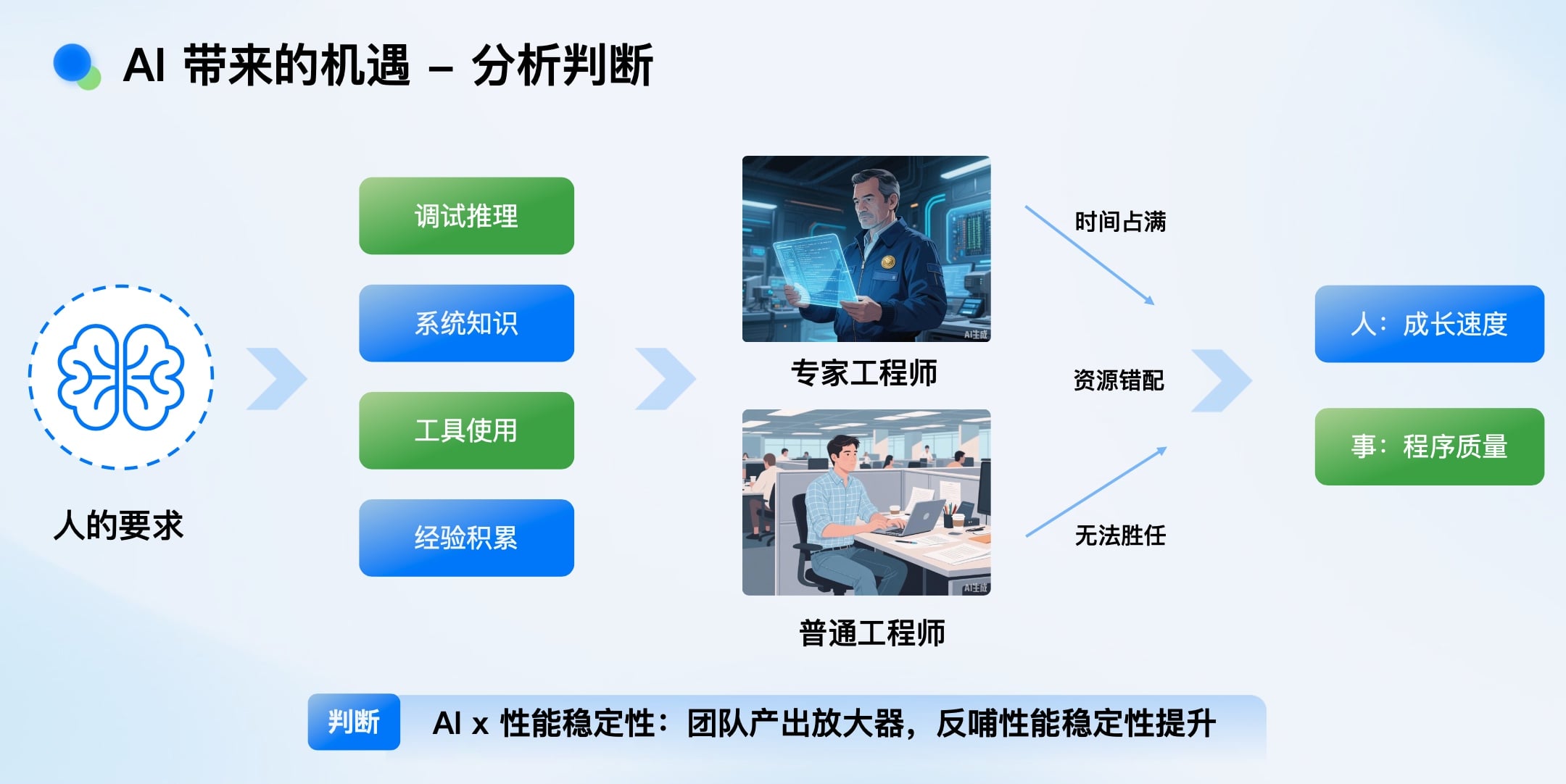
我们观察到团队中一个普遍的困境:
AI的机遇正在于此——它有望成为打破这一循环的放大器,将专家经验沉淀和复制,赋能整个团队。
AI x 稳定性:整体策略与架构设计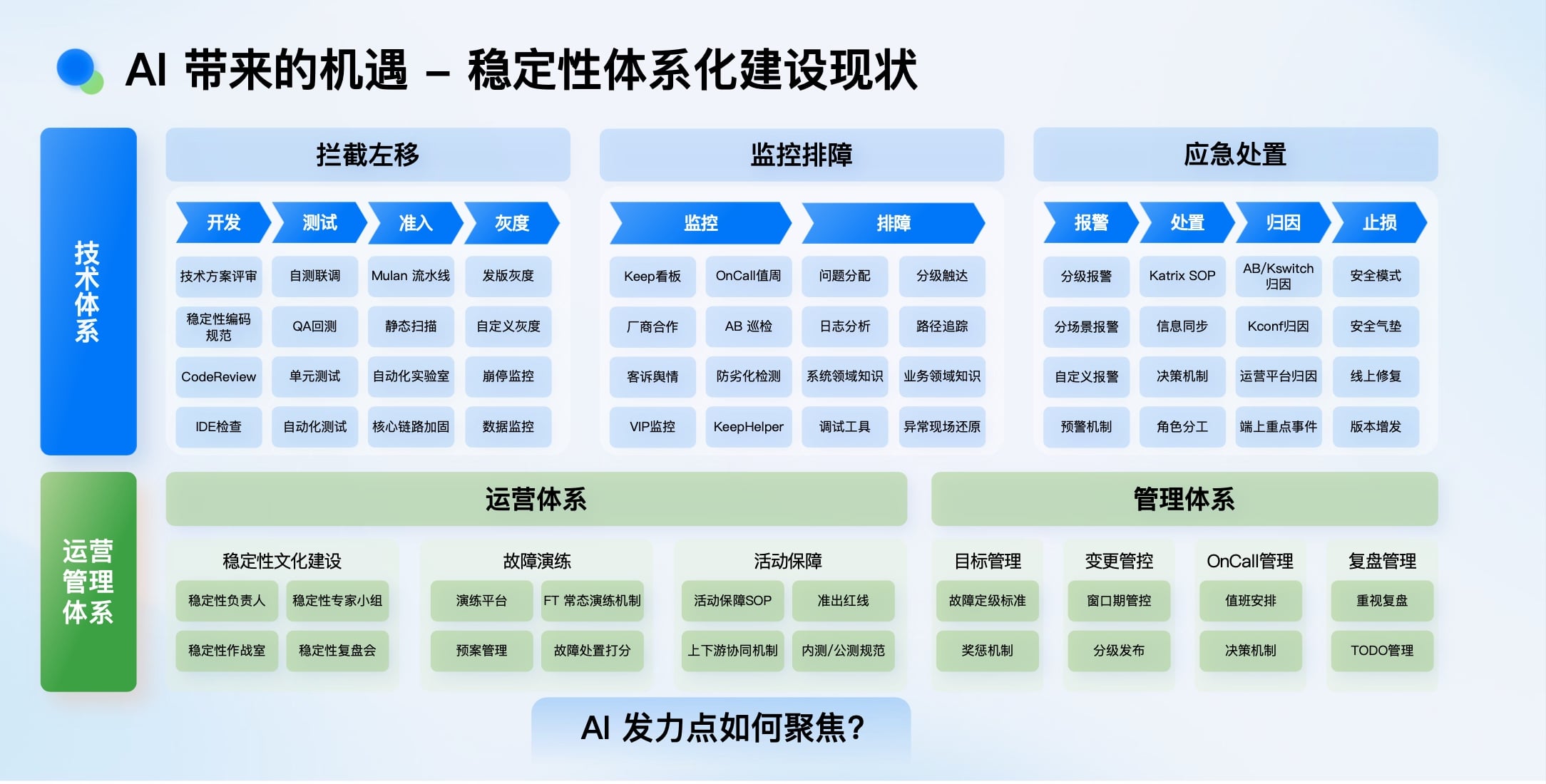
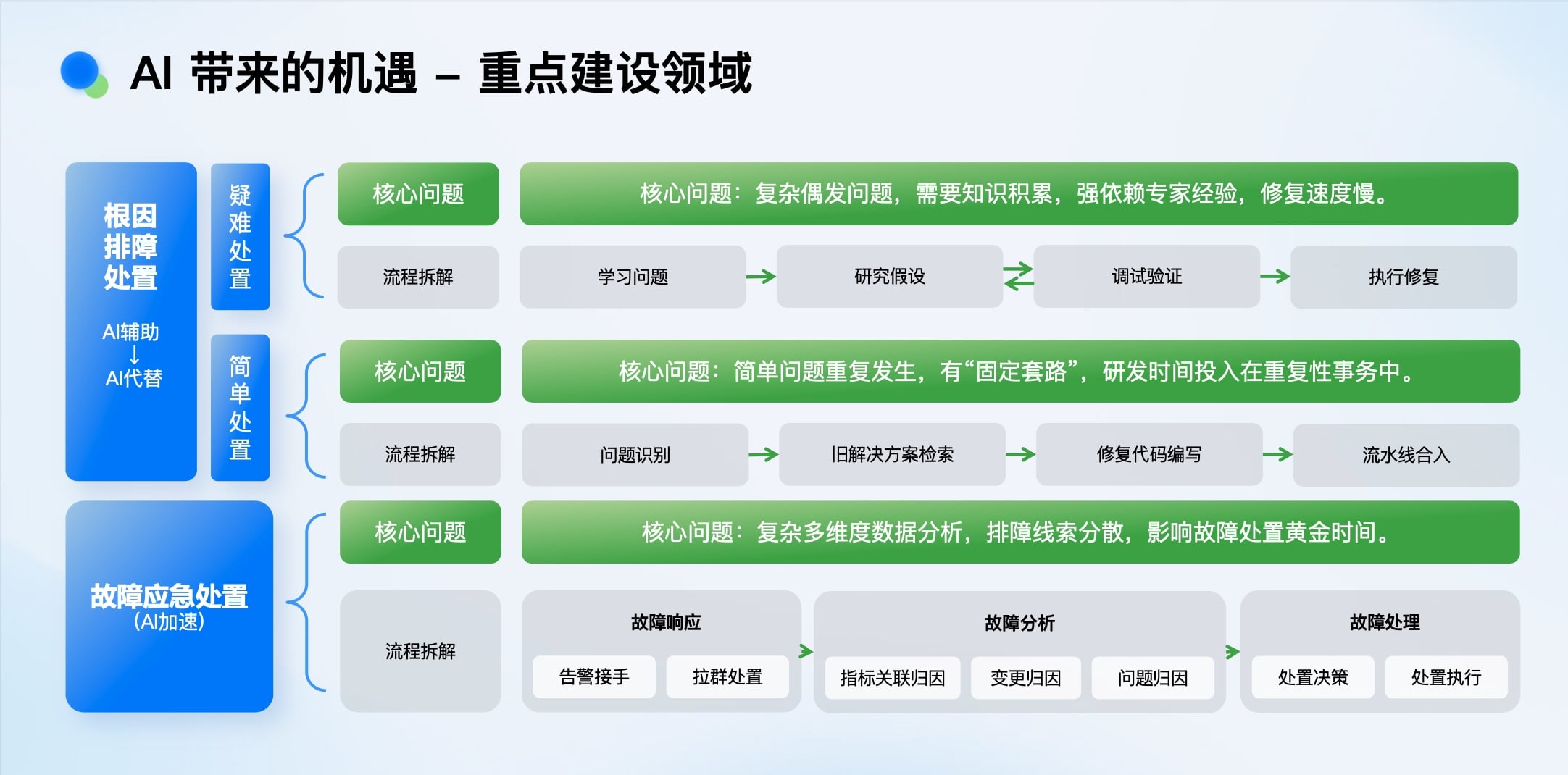
稳定性体系覆盖研发生命周期多个环节(开发、测试、监控、排障、应急处置)。我们选择从 “问题处置” 切入,因为这里是消耗研发时间最多的“重灾区”。问题处置又可细分为:
我们判断,AI在工程领域的落地形态将是 “Agent(智能体)” 。因此,我们从一开始就以可扩展的Agent框架为基础进行架构设计。
我们的性能稳定性Agent架构分为四层:
AI辅助根因排障——从“破案”到“自动修复”

一个典型的NPE(空指针)崩溃,堆栈全是系统代码,无业务逻辑。它仅在特定活动场景下偶发,现场信息缺失,线下难以复现。直接将此堆栈扔给ChatGPT,它能解决吗? 实践表明,非常困难。
调研数据显示,96%的研发认为日常排障有痛点,其中69%认为现场信息太少,50%认为日志太多。行业数据也指出,开发者35-50%的时间花在调试验证上。这印证了我们的新范式:“Code is cheap, show me the (bug-free) fix.”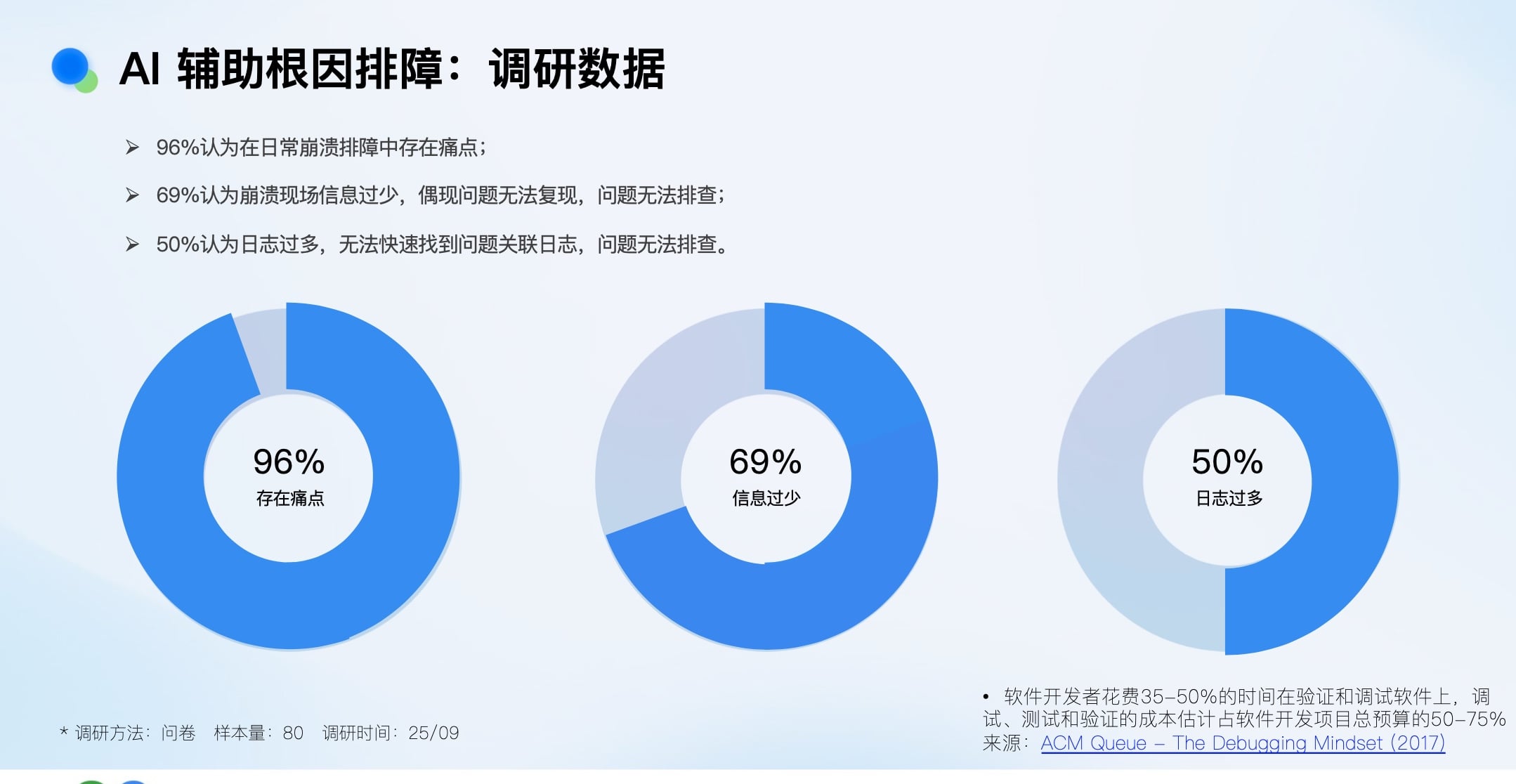
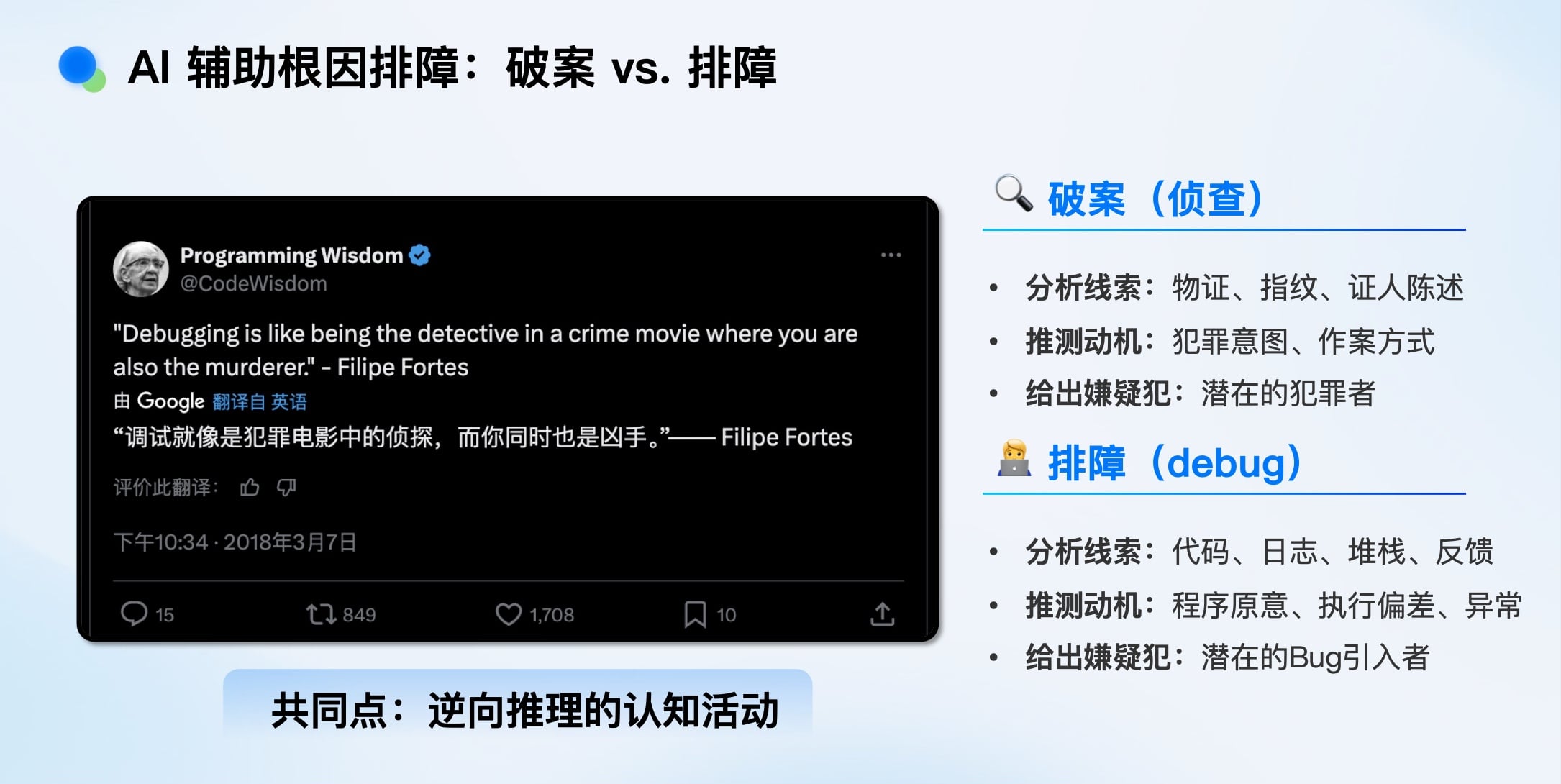
排障本质上是逆向推理的认知活动,与侦探破案高度相似: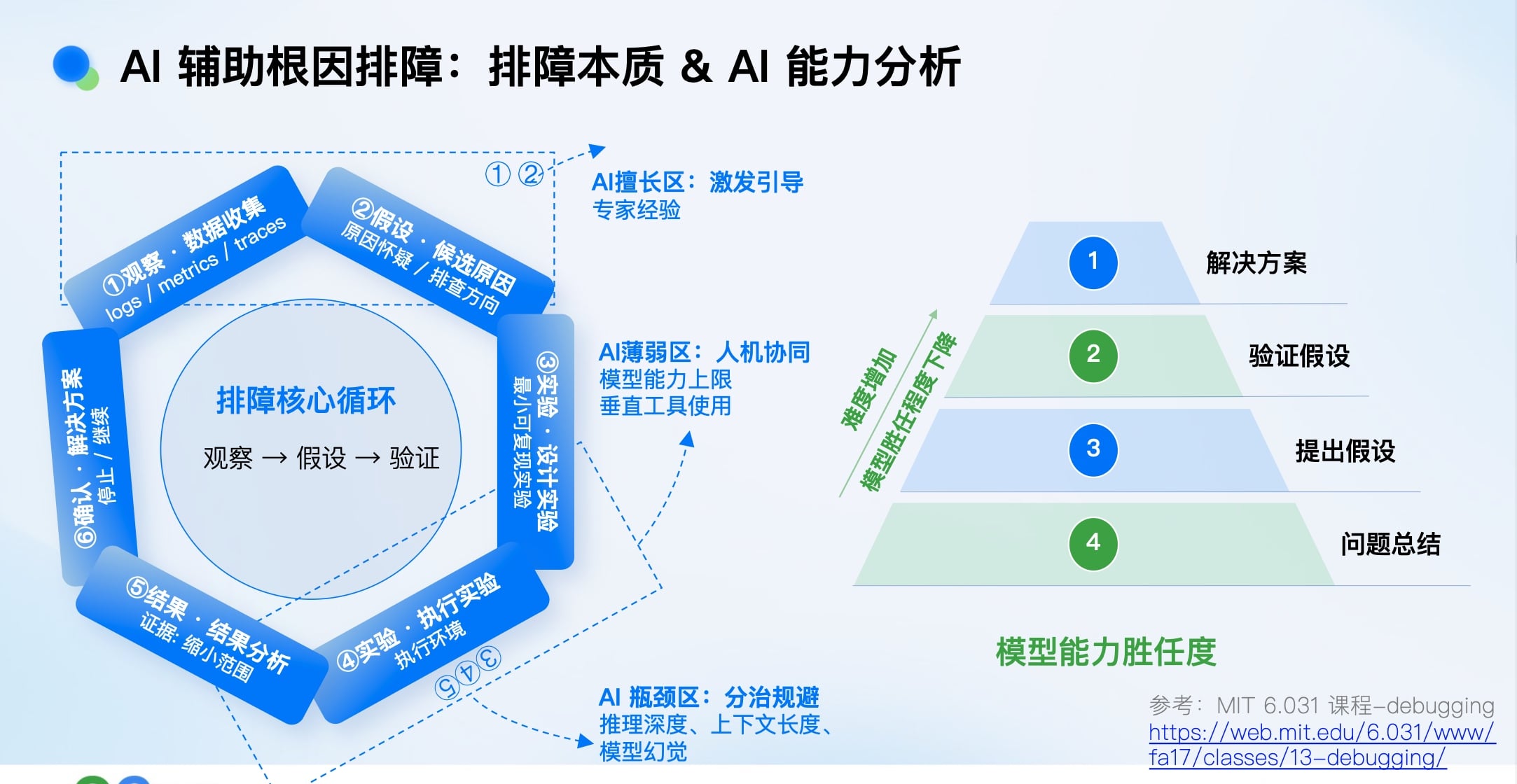
AI的能力在此链条上并非均匀:
我们自研了Holmes排障工具,核心思路是动静结合: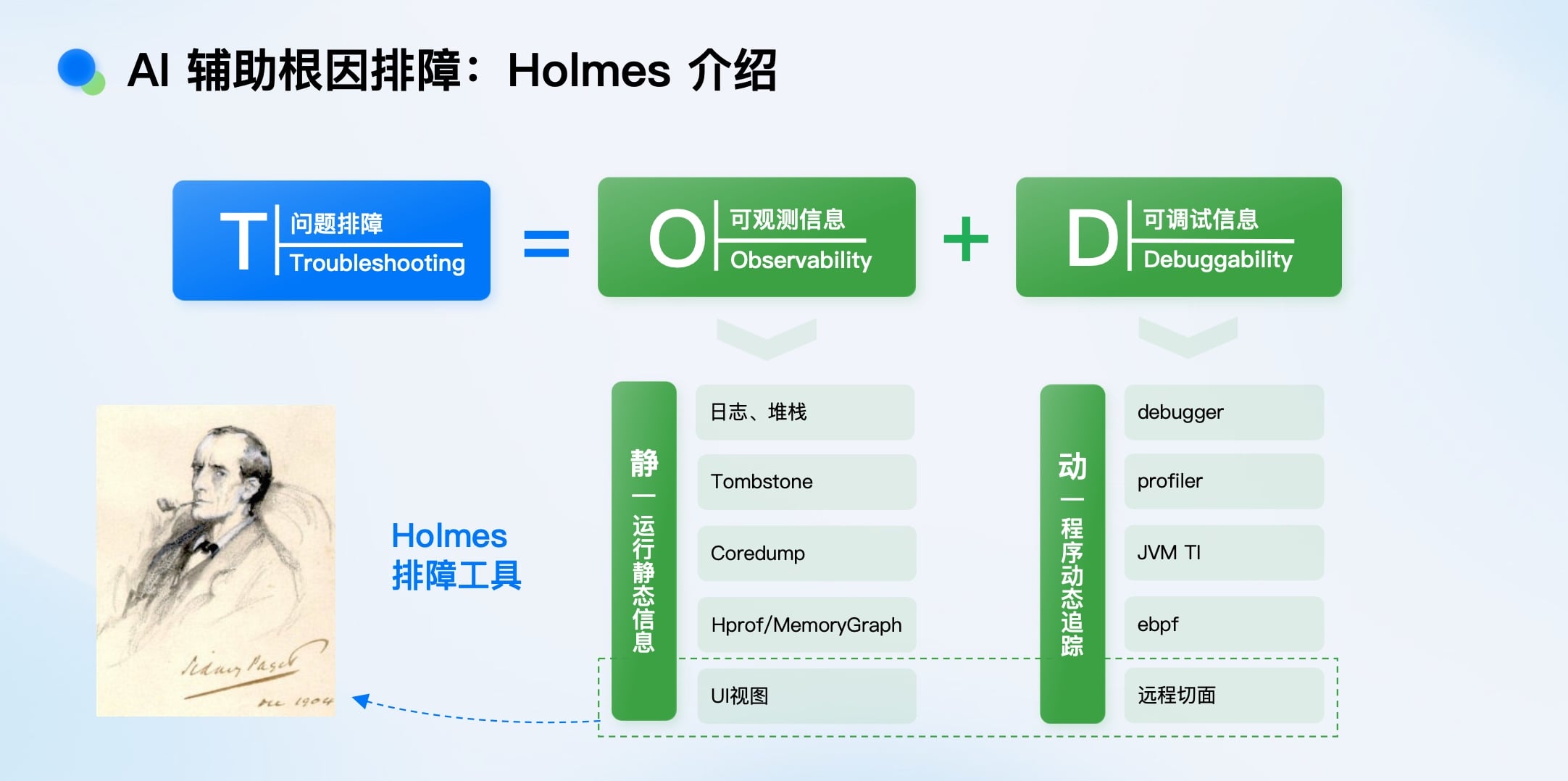
特别是Holmes UI视图,它能在崩溃时捕获: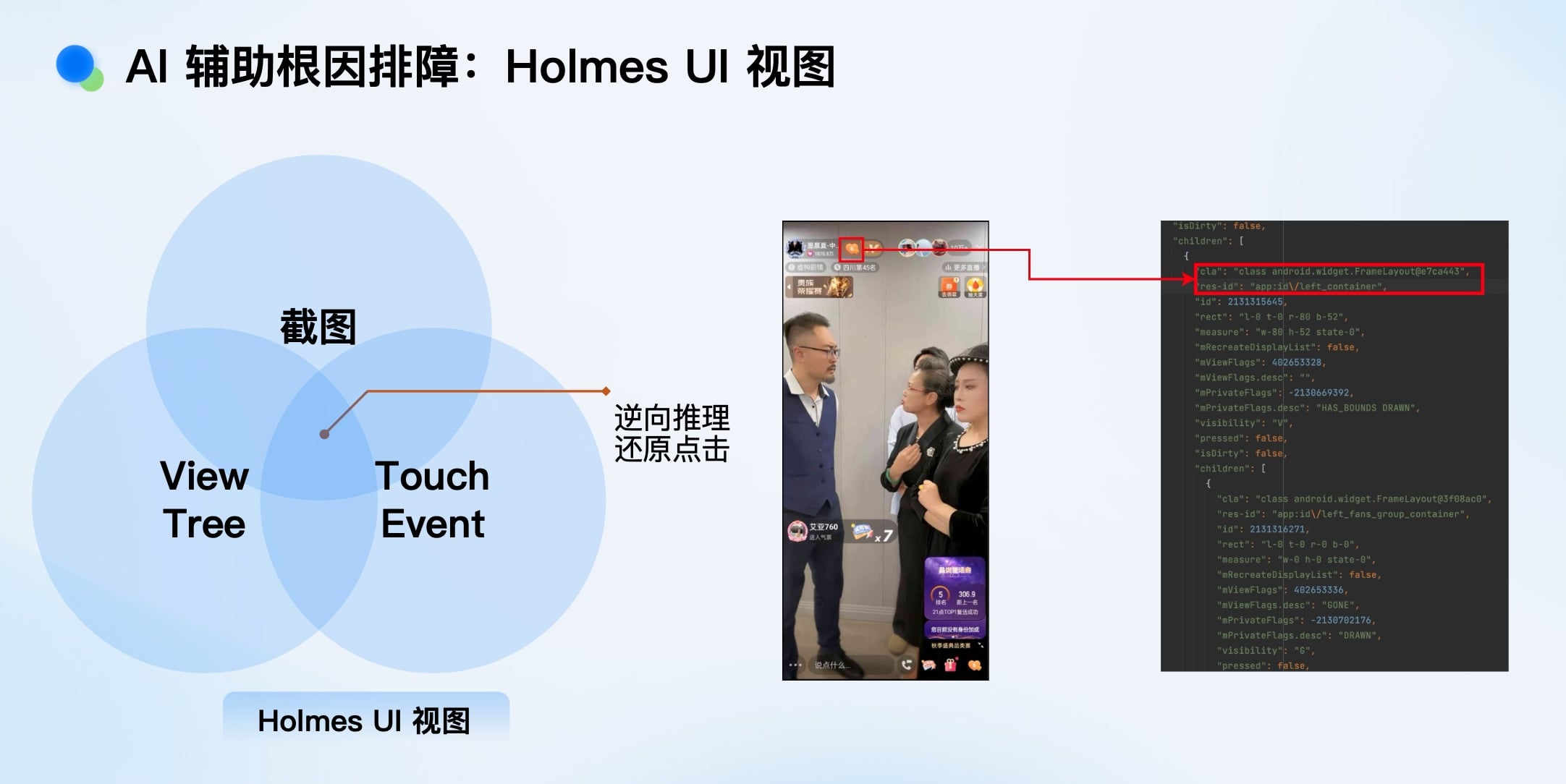
面对Holmes采集的海量、复杂信息,我们通过Agent编排来让AI消化: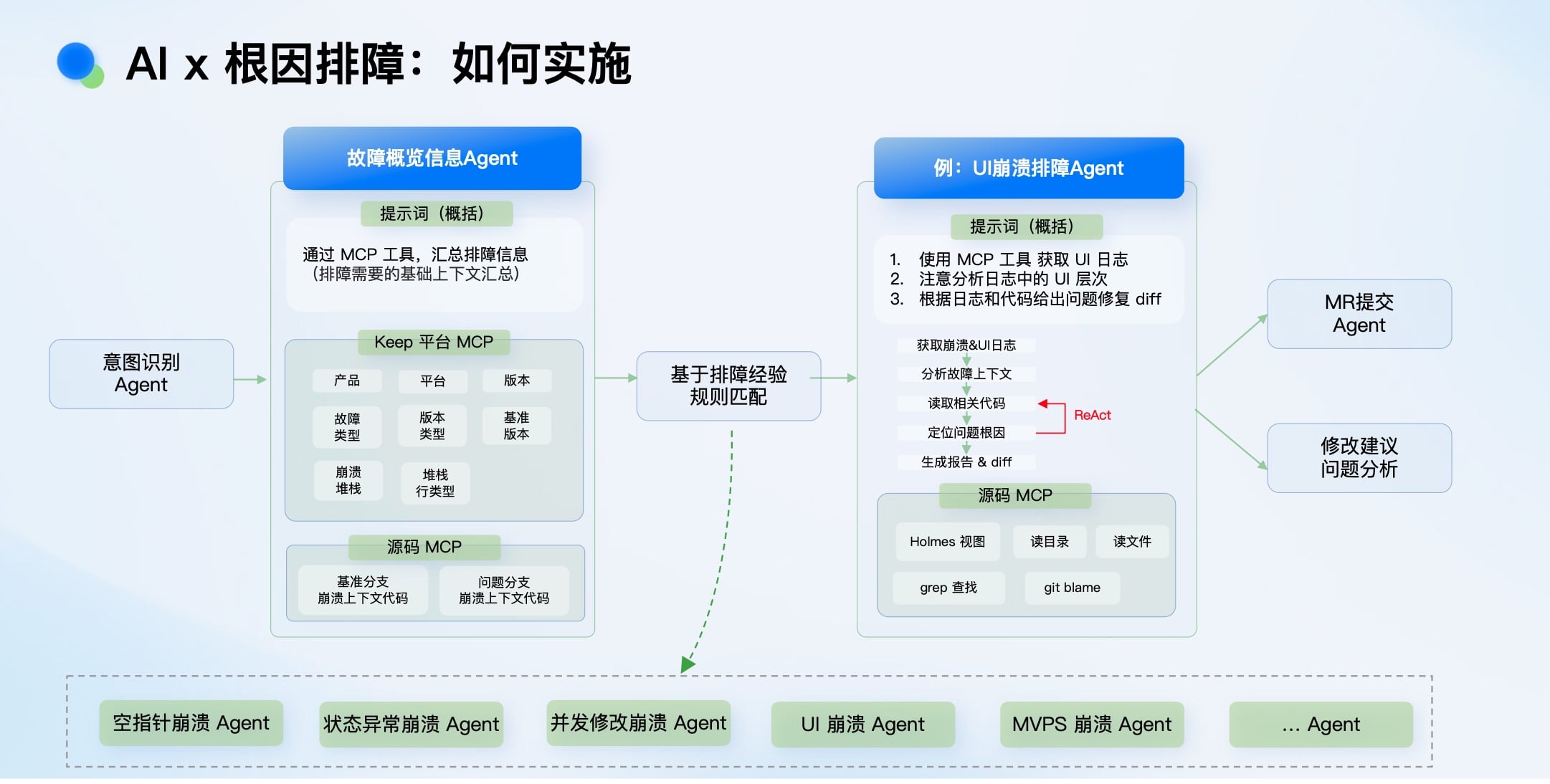
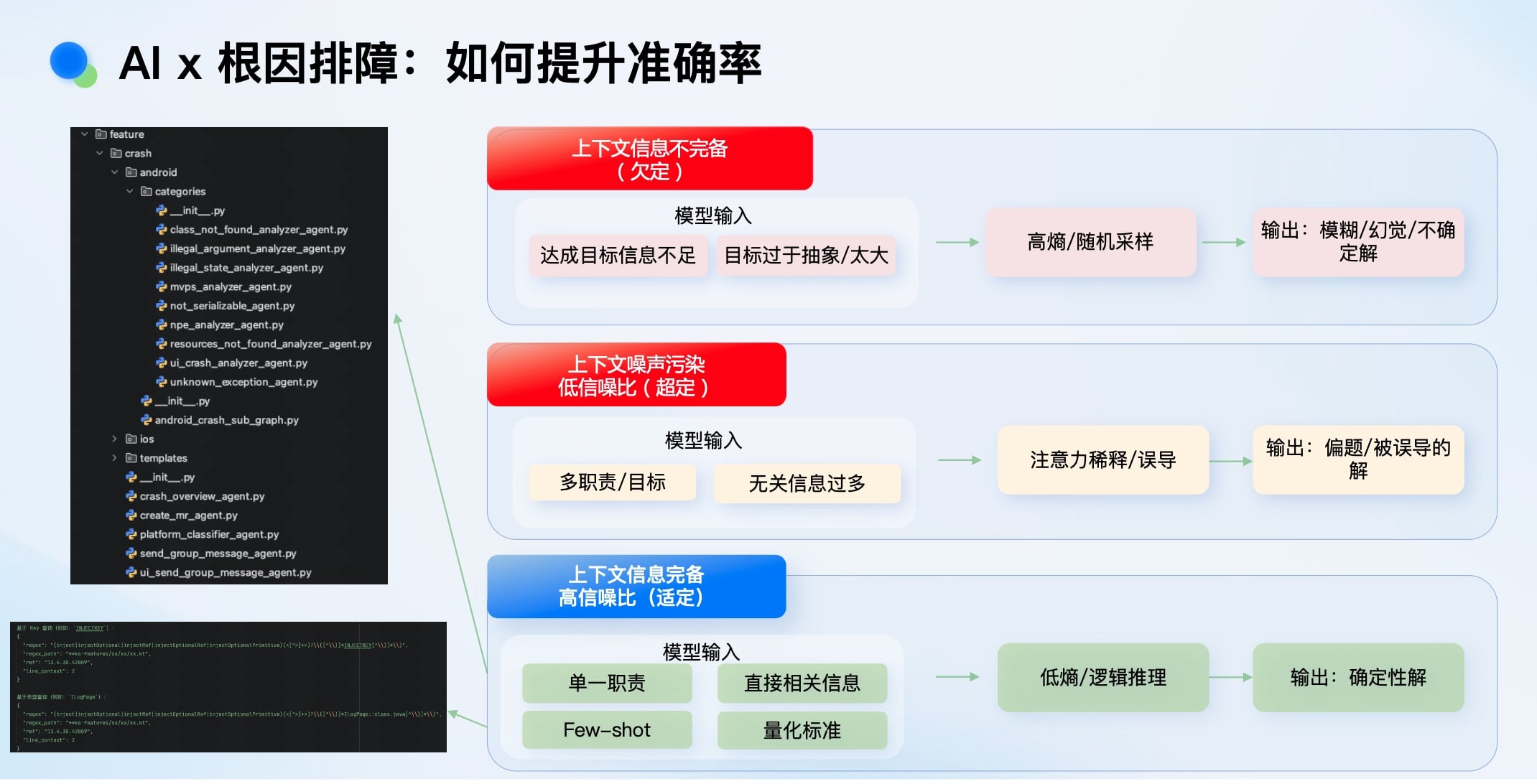
提升准确率的关键在于“上下文工程”,目标是达到“适定问题”状态:
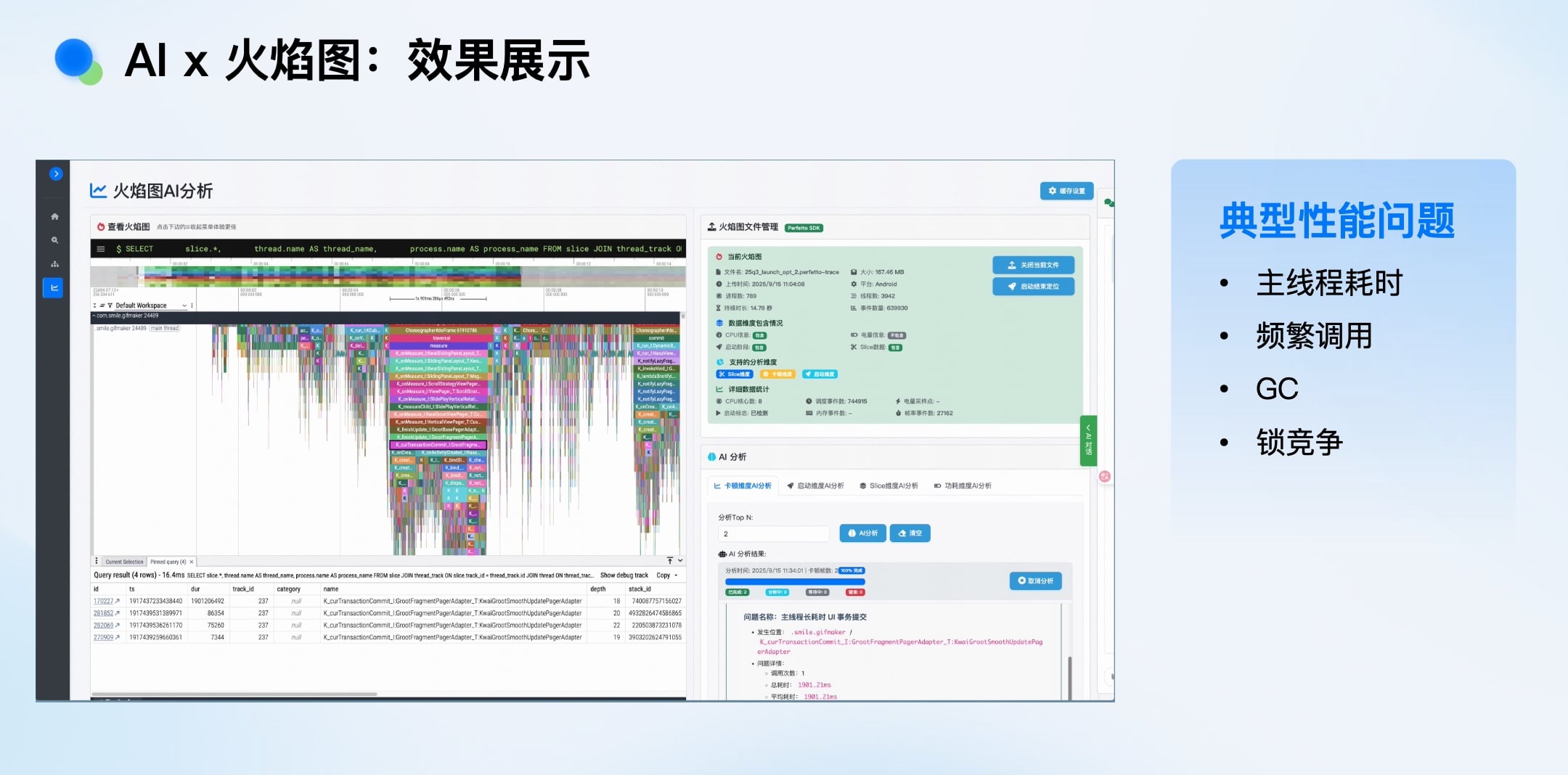
AI x 根因排障:效果展示

性能分析的火焰图数据量巨大(十几秒可能产生60MB数据),分析门槛高、效率低、易遗漏。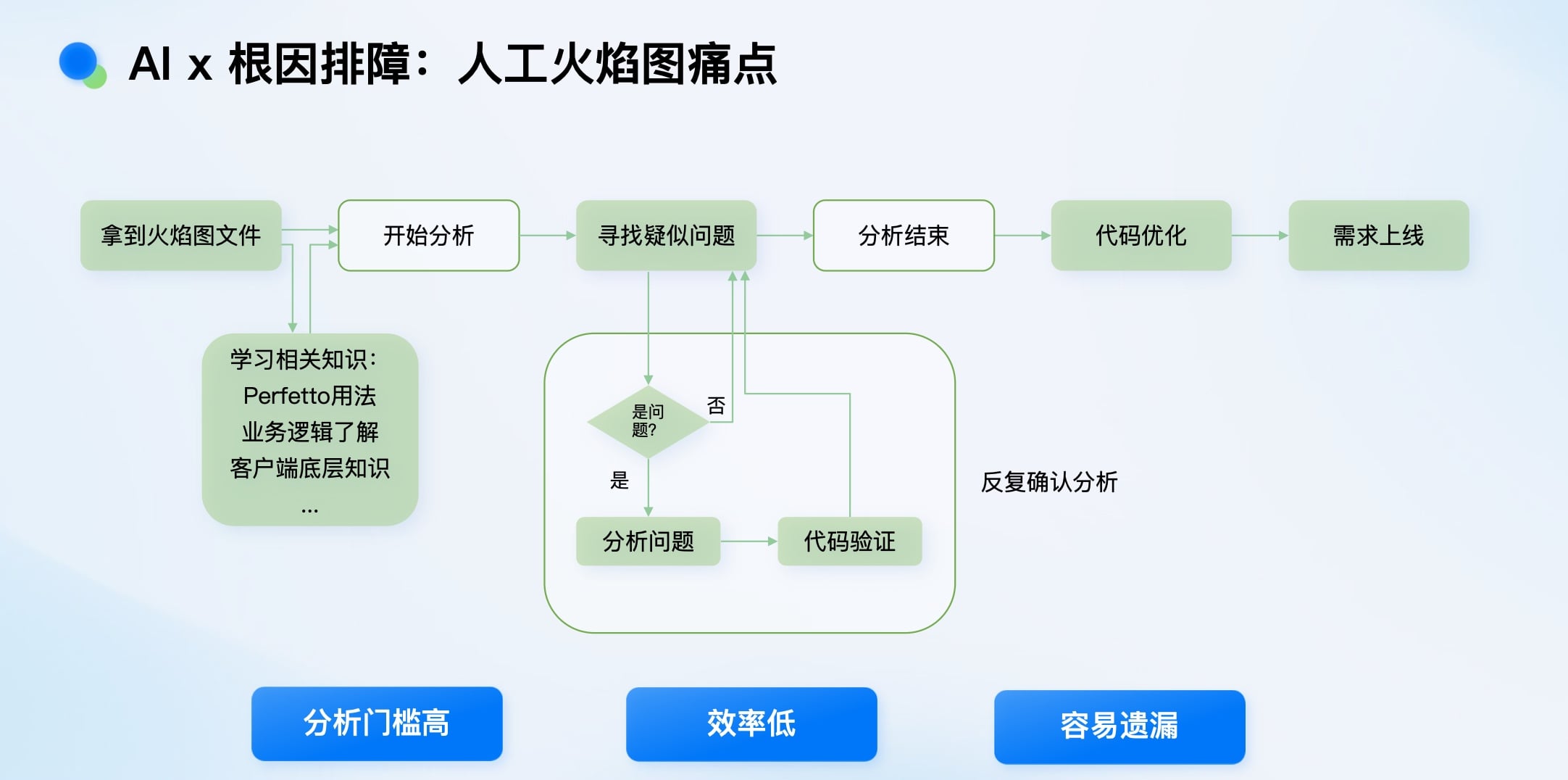
我们的方案是: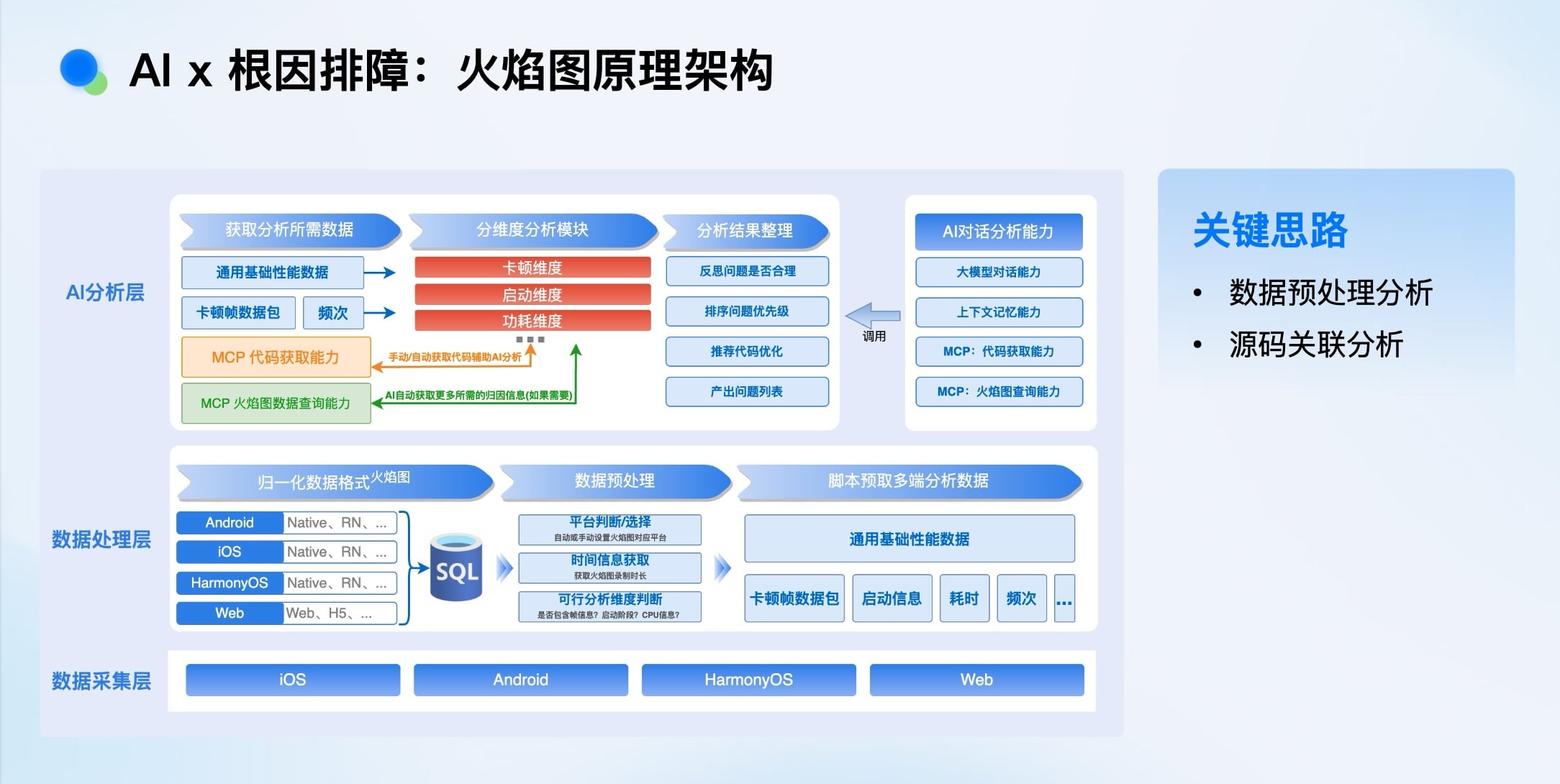
AI加速故障应急处置——与时间赛跑

以iOS 26升级导致大量历史版本App崩溃为例。传统手段各有局限: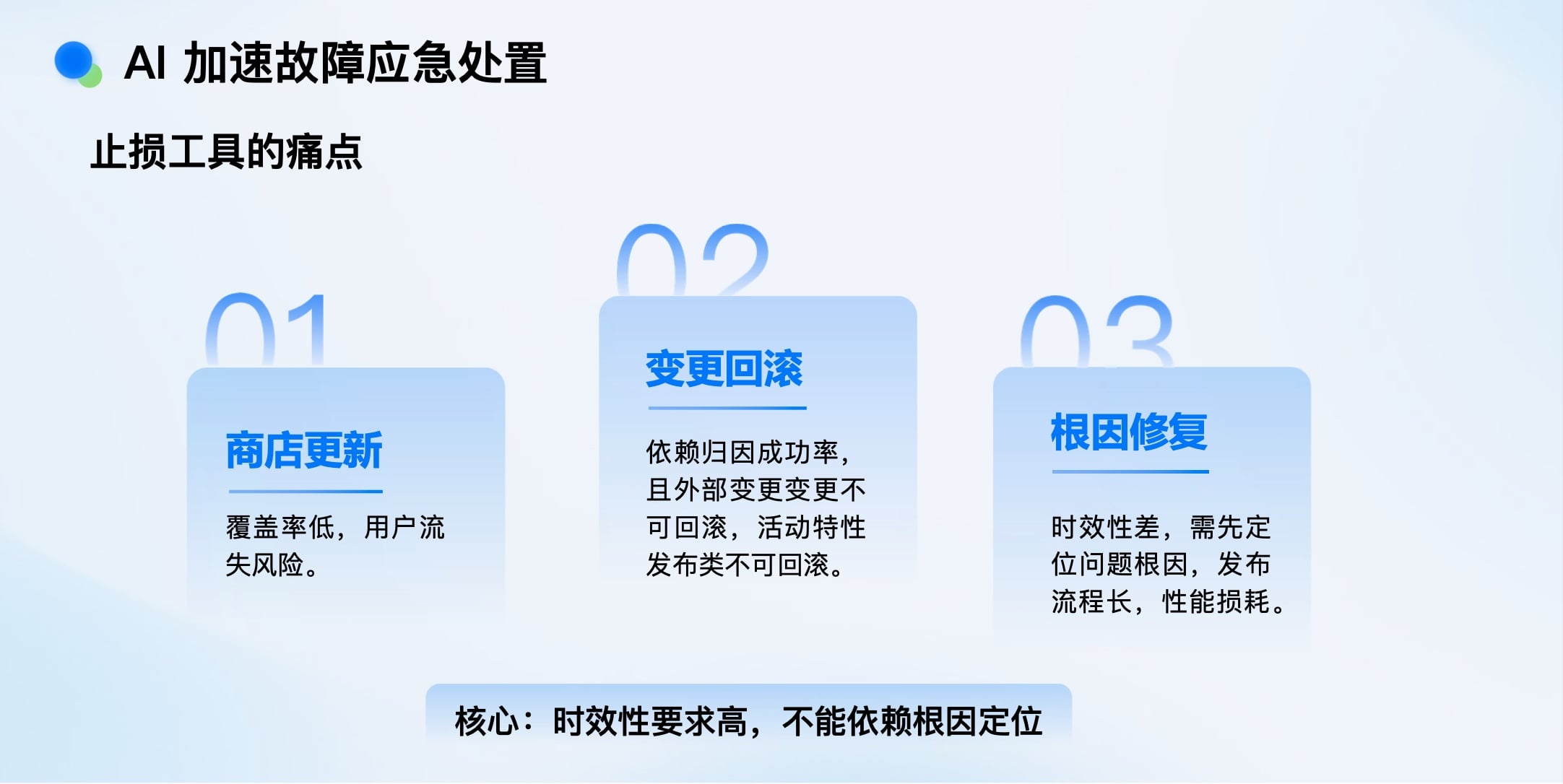
应急处置的核心在于时效性,必须与故障扩散赛跑。
我们自研了Ekko安全气垫系统,其核心思想是:在崩溃发生后、应用闪退前,动态修改程序执行流,让其“跳回”安全状态继续执行,实现类似游戏“R技能”的时光倒流效果。
Ekko 崩溃阻断:覆盖所有崩溃类型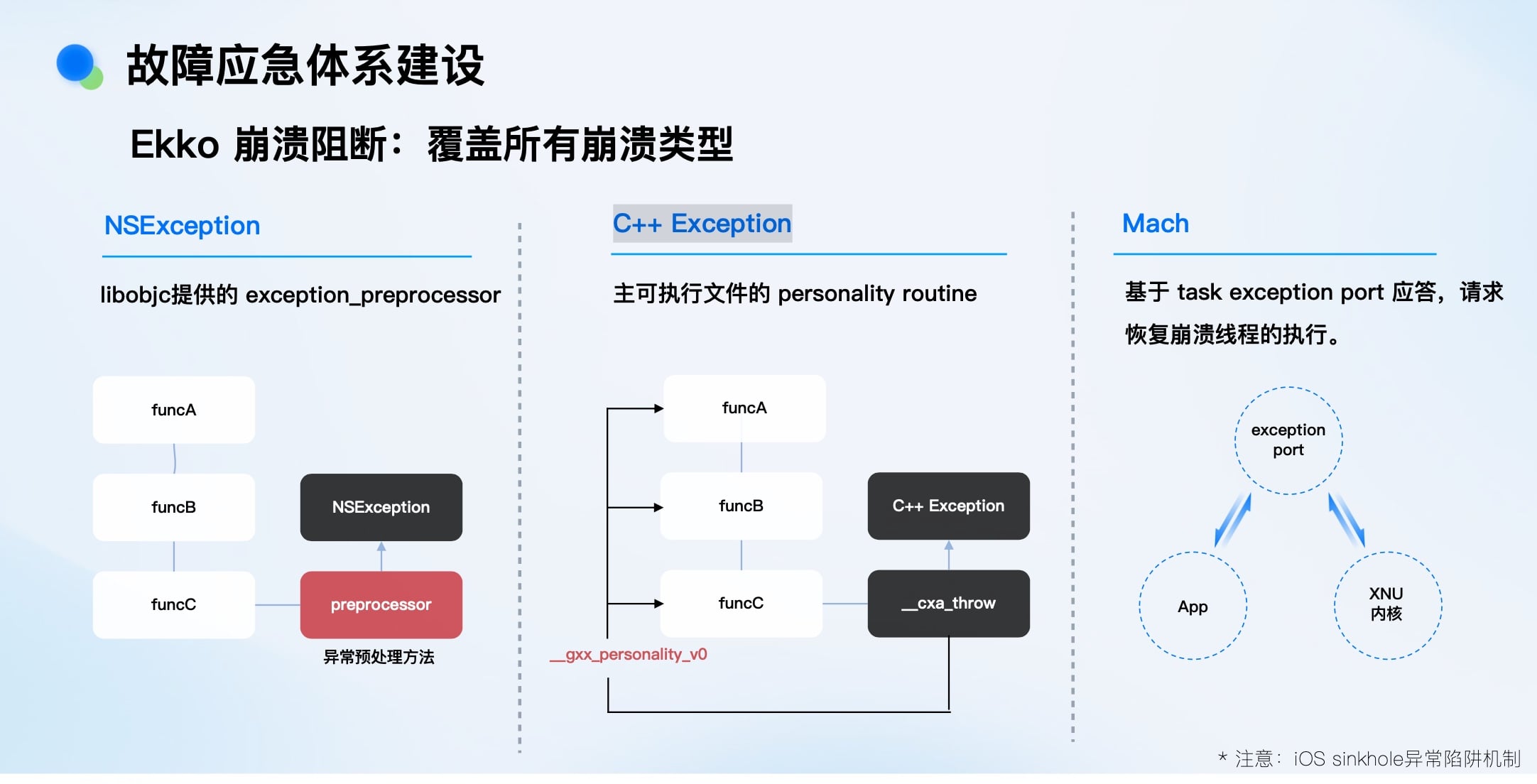
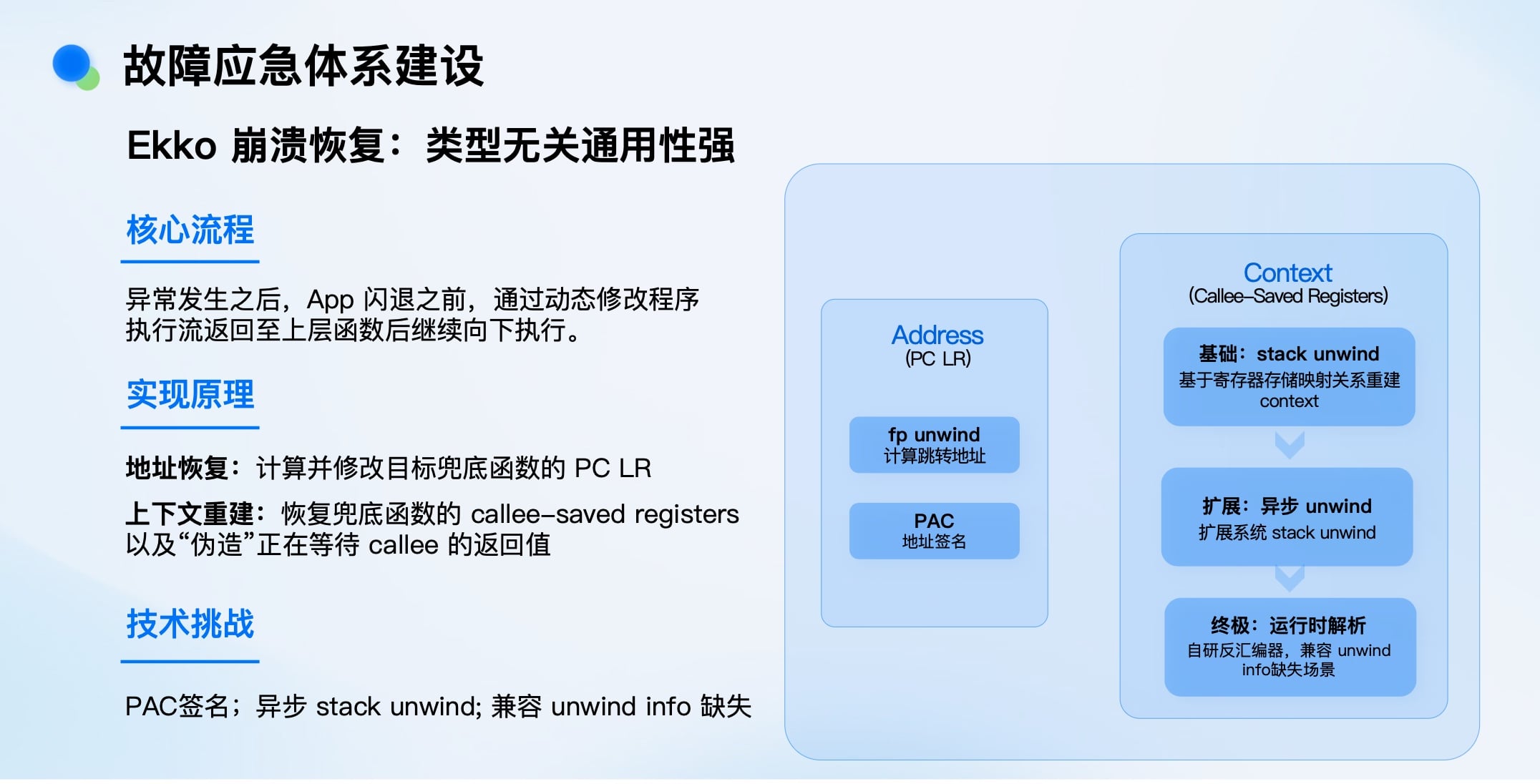
Ekko是 “售后方案” ,只在崩溃发生时触发,避免了无异常用户端的性能损耗,保证了安全性。
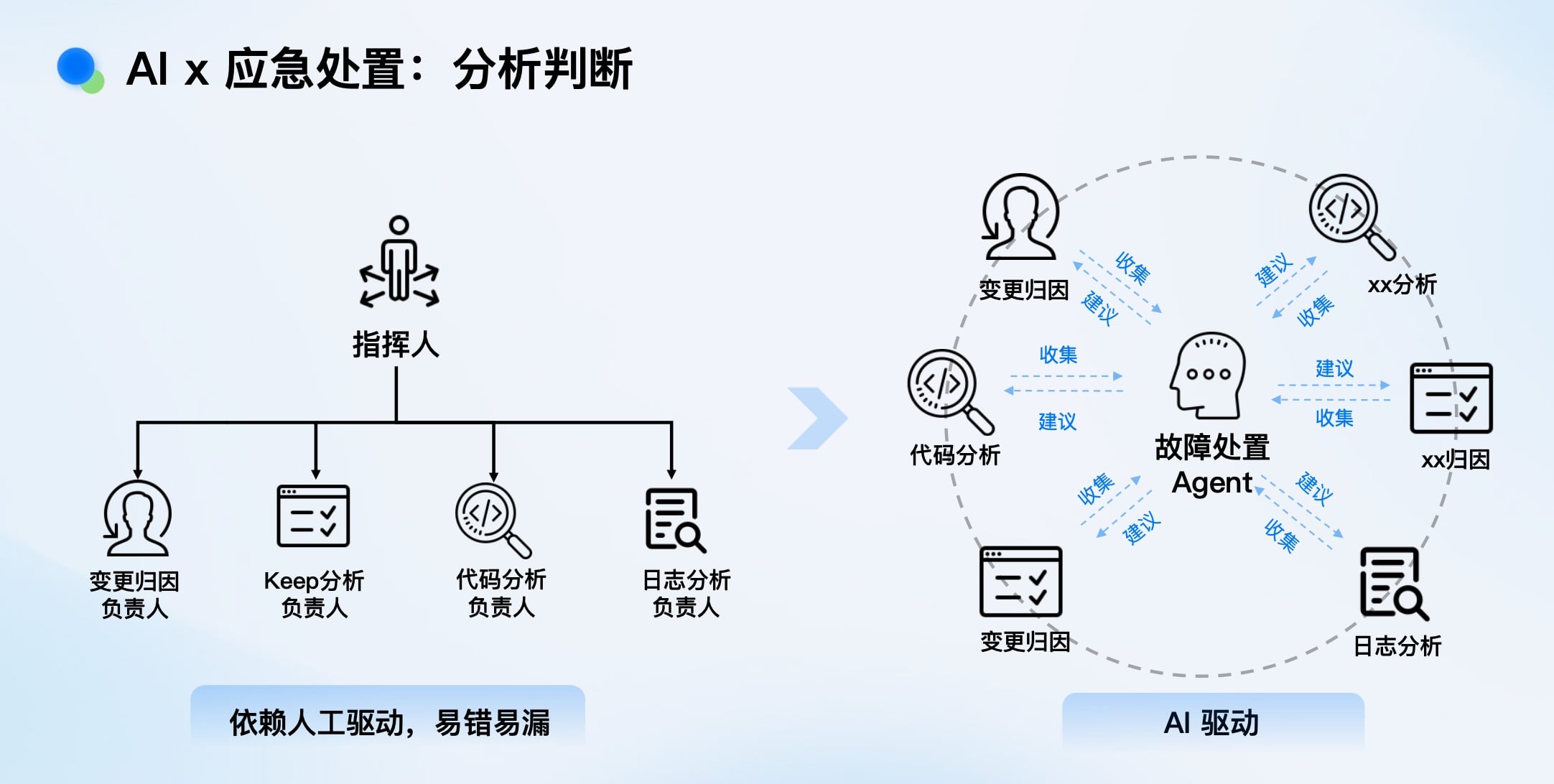
即使有了Ekko,配置和使用它依然复杂(需指定跳转地址、恢复上下文等),在紧急状态下人工操作易出错、易遗漏。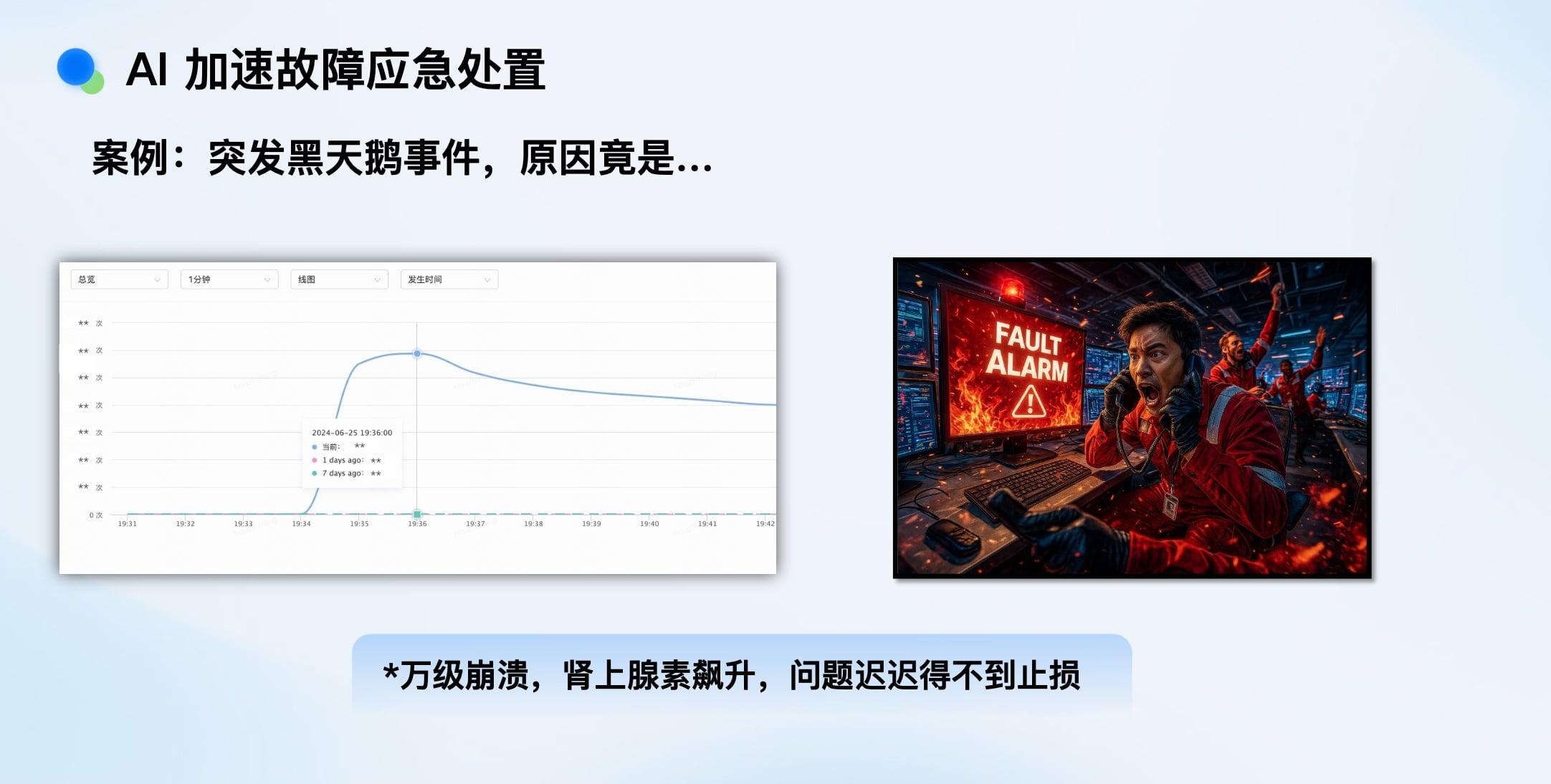
我们引入故障应急处置Agent,实现:
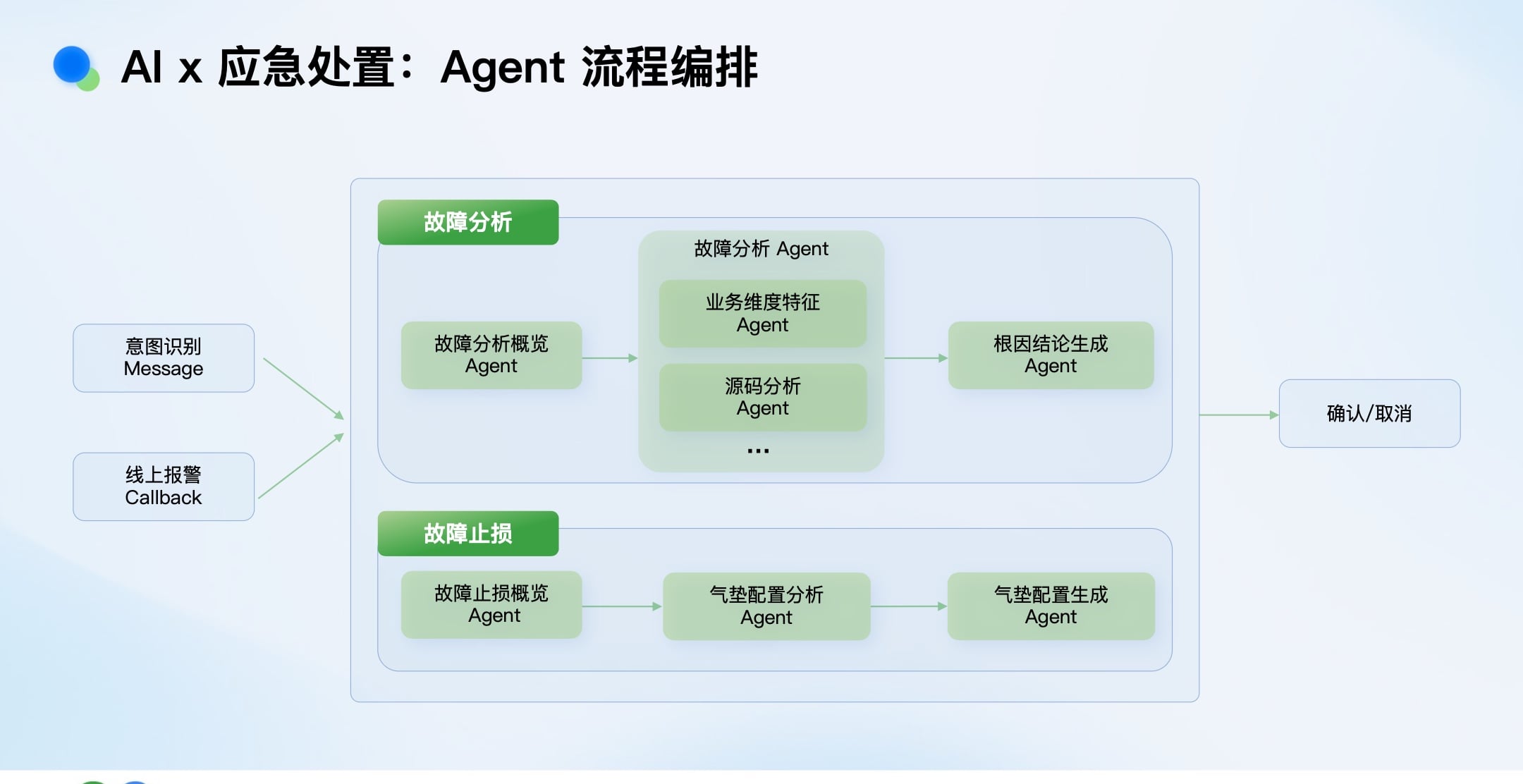
在“黑天鹅”事件中(如某次误操作导致千万级崩溃),AI冷静、全面的分析能力,能有效避免人在高压下的决策失误。

回到最初的焦虑,Linus Torvalds的观点值得深思:“代码的审查和维护本身就充满挑战。” AI不会改变这一本质,而是帮助我们更好地应对它。
我们的结论是:
在快手亿级DAU的复杂战场上,AI × 性能稳定性的探索刚刚启航。未来将是人机协同(Human in/on the Loop) 的深度结合。我们应积极拥抱AI,将其作为强大的杠杆,释放工程师的创造力,共同应对大前端领域越发复杂的稳定性挑战,奔赴星辰大海。